Flume-HDFS Sink的壓縮方式
老程式員:小伙子,別用LZO,去把組態檔改成Snappy
我:為啥?(你不會不知道Snappy不能切片吧)
老程式員:LZO壓縮率沒Snappy高,你不知道?
我:但是LZO能切片啊.(理直氣壯)
老程式員:你Flume組態檔里都寫了128M滾動一次了,還切啥

我:(茅廁頓開)對對對.思維定式了.騷瑞騷瑞
Hbase手動自動磁區
老程式員:上班嚴禁摸魚,你維度表創建完了?
我:好了啊,咱們需求這么簡單我連RowKey都不用設計,美滋滋

老程式員:磁區規劃做了嗎?
我:(??)不是有自動磁區嗎,256M它會自己切一次啊
老程式員:(我刀呢)自動磁區會不會資料傾斜?快去改.
我:維度資料也沒多少啊.問題不大吧...(小聲逼逼),而且我們的需求不就是根據id查單條維度資料來進行關聯嗎
老程式員:(好像說的有點道理,有點沒面子)那你也不能摸魚啊.來來來我來問你個問題
我:康忙
老程式員:Memstore默認的刷寫時機?
我:128M或者一個小時
老程式員:那我九點半寫一條,十點寫一條,其他時間都沒寫入,啥時候刷寫?

我:應該是十一點(不知道為什么)
老程式員:從底層說說看?
我:說句實話,俺不會(理不直氣也壯)
老程式員:是有一個變數名字叫lastEdit,可以見名知義了沒?
我:就是說最后一次編輯的時間過了一個小時,才會自動刷寫.哦,跟我想的差不多

Hbase洗掉標記
老程式員:(還嘴硬?)那我再問問你,知道Hbase客戶端有啥bug嗎?
我:在客戶端中洗掉某id的某一個列族的某一列的資料,它只會洗掉當前最大版本的一條資料,不會洗掉一整列,再次查詢竟然能查到小版本的資料,完全是坑人

老程式員:(驚!)還不錯,那你怎么解決的?最后發現原因了嗎?
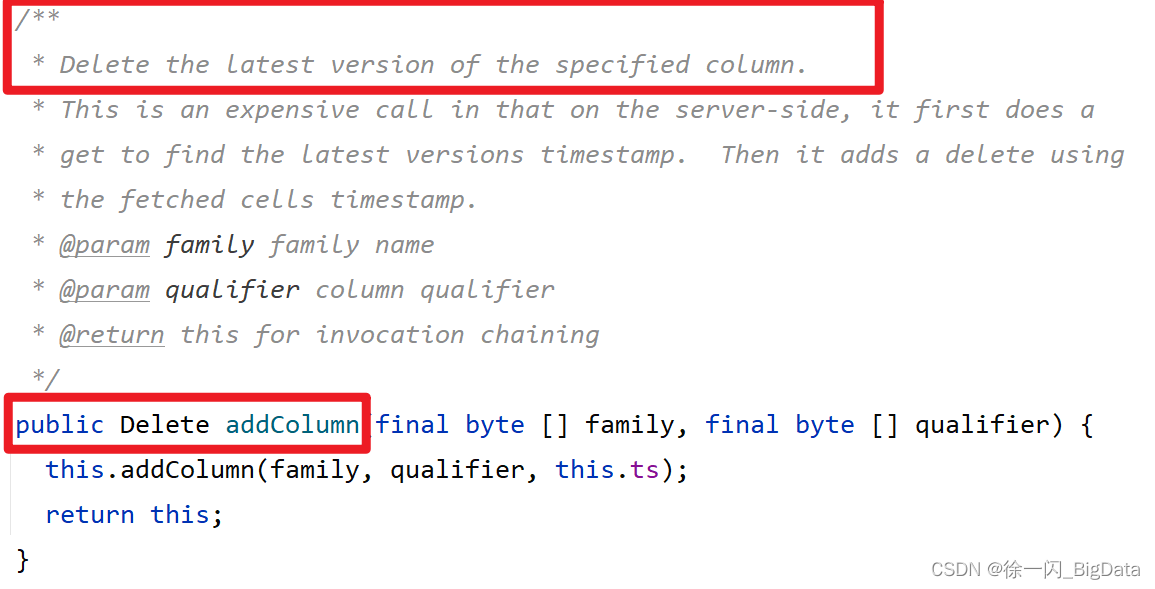
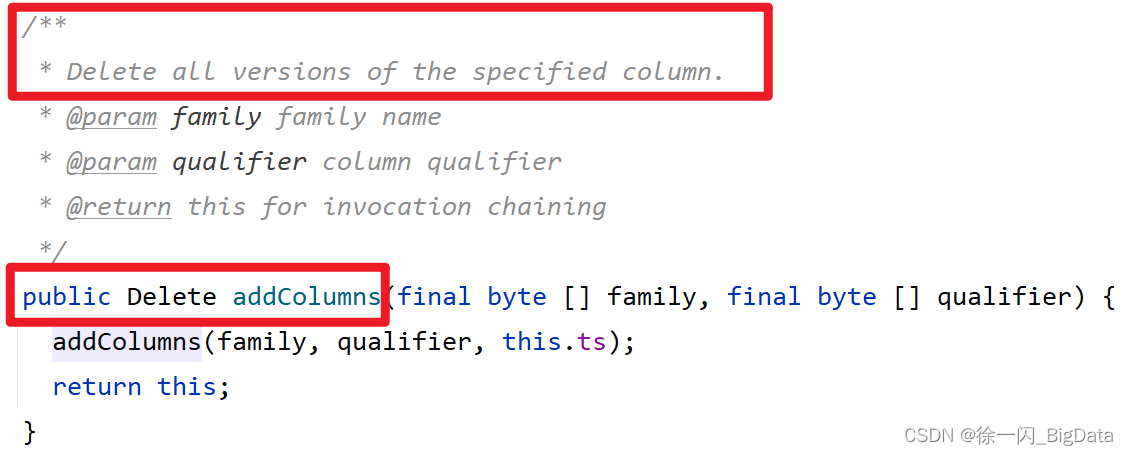
我:IDEA用API寫了個代碼,就搞定了,應該是addDelete類的Column()和addColumns().這兩個方法的區別就是一個是洗掉當前列的最大版本,一個是正兒八經的洗掉整列的資料.
其實最終的問題就是洗掉標記,客戶端里雖然我的語法是洗掉某一列的資料,但是客戶端用的卻是Delete這個標記,在API中的addColumns()是DeleteColumn標記,很明顯客戶端的是有bug的
 老程式員:好的,回答的不錯,先回去等通知吧.
老程式員:好的,回答的不錯,先回去等通知吧.
我:好的好的,謝謝(好像哪里不對)
![]()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379155.html
標籤:其他
上一篇:學習IT夢的開始
下一篇:Flume1.9.0配置