Hadoop期末復習城科專用
根據老師給出的知識點范圍整理,有的知識點太長了,就標了一部分黑色字體,把黑色字體記住答上也應該能得分,其余的方便記憶理清思路,列出來的全是給的知識點范圍,如果覺得長了,可以自行省略背,
有需要.md檔案的同學可以加Q2660593526
論述題最后一個就不寫了
目錄
- Hadoop期末復習城科專用
- 一、Hadoop集群
- 概念解釋:
- 1.Yarn
- 簡答題
- 1.Hadoop集群6個核心組態檔以及它的作用
- 2.Hadoop集群部署方式以及各方式使用場景
- 3.Hadoop版本的區別
- 4.大資料的意義(圍繞這個寫就行)
- 二、HDFS
- 概念解釋:
- 1.NameNode
- 2.Secondary NameNode
- 3.DataNode
- 4.元資料
- 5.Block(資料塊)
- 簡答題:
- 1.HDFS檔案上傳流程(HDFS寫資料原理,詳細看書53頁,感覺沒必要)
- 2.NameNode管理分布式檔案系統的命名空間
- 3.HDFS Block與MapReduce split之間的聯系
- 三、MapReduce
- 1.核心思想及概念
- 2.MapReduce作業程序(可以只背這部分黑色的)
- 3.Shuffle作業流程(可以只背這部分黑色的)
- 1.Map階段
- 2.Reduce階段
- 組件
- 4.InputFormat組件
- 5.Mapper組件
- 6.Reducer組件
- 7.Partitoner組件
- 8.Combiner組件
- 9.JobTracker
- 10.TaskTracker:
- 四、Zookeeper
- 概念解釋:
- 1.zookeeper
- 2.Znode
- 簡答題:
- 3.Zookeeper集群選舉機制(書上107,如果能理清就可以看,建議不看)
- 全新集群選舉:
- 非全新集群選舉:
- 4.Watch機制
- 五、Hive
- 概念解釋:
- 1.Hive
- 2.HQL
- 3.星狀模型
- 4.雪花模型
- 5.桶表
- 簡答題
- 6.Hive的特點是什么
- 六、Flume
- 概念解釋
- 1.Source
- 2.Channel
- 3.Sink
- 4.Flume攔截器
- 簡答題
- 5.Flume的作業原理
- 七、Azkaban
- 概念解釋:
- Azkaban
- 八、Sqoop
- 概念解釋:
- Sqoop
- 論述題
- 1.HDFS不適合應用的場景有哪些
- Sqoop匯入匯出資料的作業原理是什么
- 2.基于Hadoop的大資料分析程序與傳統資料分析相位元點有哪些,有何不同
- 3.大資料研究的意義是什么,理由,
- 4.Hadoop的組件有哪些,結構分別是什么,特點是什么
- 四大組件:
- MapReduce
- HDFS
- Yarn
- Others(其他工具類)
- 5.Hadoop集群的特點是什么,分布式系統給Hadoop帶來什么特性
- 集群特點
- 分布式系統特性
- 優點:
- 缺點:
- 6.總結Hadoop集群部署的程序,分為哪些步驟
- 7.與普通集群相比,Hadoop高可用集群有哪些特殊之處,兩者有何不同
- 普通集群
- Hadoop集群(詳情見書第7頁,具體內容可以背點)
一、Hadoop集群
概念解釋:
1.Yarn
Yarn是Hadoop2.0中的資源管理器,它可為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和資料共享等方面帶來巨大好處,
簡答題
1.Hadoop集群6個核心組態檔以及它的作用
| 組態檔 | 功能描述 |
|---|---|
| hadoop-env.sh | 配置Hadoop運行所需的環境變數 |
| yarn-env.sh | 配置Yarn運行所需環境變數 |
| core-site.xml | Hadoop核心全域組態檔,可在其他組態檔中參考該檔案 |
| hdfs-site.xml | HDFS組態檔,繼承core-site.xml組態檔 |
| mapred-site.xml | MapReduce組態檔,繼承core-site.xml組態檔 |
| yarn-site.xml | YARN組態檔,繼承core-site.xml檔案 |
2.Hadoop集群部署方式以及各方式使用場景
(1)獨立模式:又稱單例模式,在該模式下,無須運行任何守護行程,所有的程式都在單個JVM上執行,
(2)偽分布模式:Hadoop程式的守護行程運行在一臺主機節點上,通常使用偽分布式模式來除錯Hadoop分布式程式的代碼,以及程式執行是否正確,偽分布式模式是完全分布式模式的一個特例,
(3)完全分布式模式:Hadoop的守護行程分別運行在由多個主機搭建的集群上,不同節點擔任不同的角色,在實際作業應用開發中,通常使用該模式構建企業級Hadoop系統,
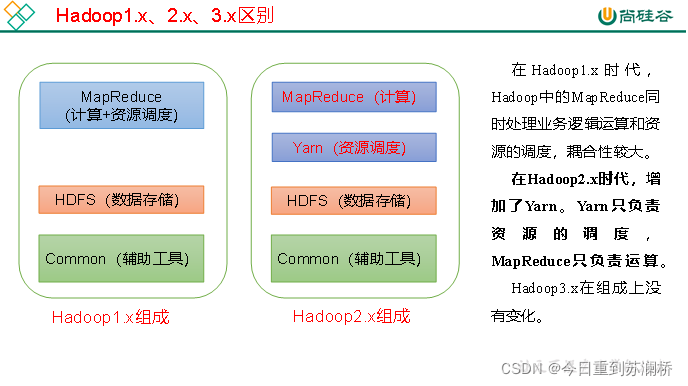
3.Hadoop版本的區別
借用尚硅谷一張圖
4.大資料的意義(圍繞這個寫就行)
研究大資料,最重要的意義在于預測,因為資料從根本上來講,是對過去和現在的歸納和總結,其本身不具備趨勢和方向性的特征,但是可以應用大資料去了解事物發展的客觀規律、了解人類行為,并且能夠幫助我們改變過去的思維方式,建立新的資料思維模式,從而對未來進行預測和推測,
二、HDFS
概念解釋:
1.NameNode
NameNode是HDFS集群的主服務器,通常稱為名稱節點或主節點,一旦NameNode關閉,就無法訪問Hadoop集群,NameNode主要以元資料的形式進行管理和存盤,用于維護檔案系統名稱并管理客戶端對檔案的訪問;NameNode記錄對檔案系統名稱的空間或其屬性的任何更改操作;HDFS負責整個資料集群的管理,并且在組態檔中,可以設定備份數量,這些資訊都由NameNode存盤,
2.Secondary NameNode
HDFS中提供了Secondary NameNode(輔助名稱節點),它并不是要取代NameNode也不是NameNode的備份,它的職責是周期性地把NameNode中地EditLog日志檔案合并到FsImage鏡像檔案中,從而減小EditLog日志檔案大小,縮短集群重啟時間,保證了HDFS系統地完整性,
3.DataNode
DataNode是HDFS集群中的從服務器,通常稱為資料節點,檔案系統存盤檔案的方式是將檔案切分成多個資料塊,這些資料塊實際上是存在DataNode節點上的,因此DataNode機器需要配置大量磁盤空間,它與NameNode不斷地保持通信,DataNode在客戶端或者NameNode地調度下,存盤并檢索資料塊,對資料塊進行創建、洗掉等操作,并且定期向NameNode發送所存盤地資料塊串列,每當DataNode啟動時,它將負責把持有地資料塊串列發送到NameNode集群中,
4.元資料
元資料從型別上可分為三種資訊形式,一是維護HDFS中檔案和目錄的資訊,如檔案名、目錄名、父目錄資訊、檔案大小、創建時間、修改時間等;二是記錄檔案內容,存盤相關資訊,如檔案分塊情況、副本個數、每個副本所在的DataNode資訊等;三是用來記錄HDFS中所有DataNode的資訊,用于DataNode管理,
5.Block(資料塊)
每個磁盤都有默認的資料塊大小,這是磁盤進行資料讀/寫的最小單位,HDFS同樣也有塊的概念,它是抽象的塊,而非整個檔案作為存盤單元,默認大小為128M,且備份3份,每個塊盡可能的存盤于不同的DataNode中,按塊存盤的好處主要是屏蔽了檔案大小,提供資料的容錯性和可用性,
簡答題:
1.HDFS檔案上傳流程(HDFS寫資料原理,詳細看書53頁,感覺沒必要)
配個尚硅谷的流程圖,理解一下
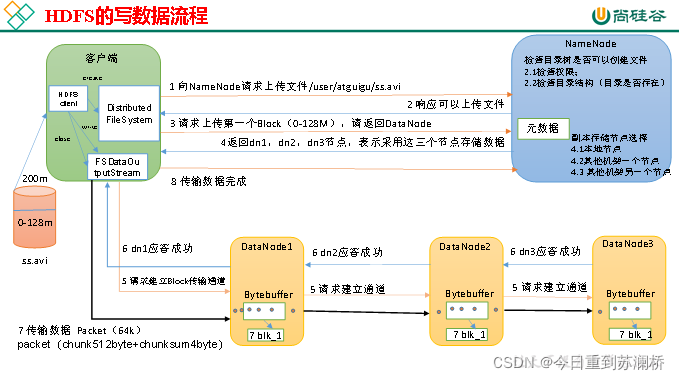
(1)客戶端向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
(2)NameNode回傳是否可以上傳,
(3)客戶端請求第一個 Block上傳到哪幾個DataNode服務器上,
(4)NameNode回傳3個DataNode節點,分別為dn1、dn2、dn3,
(5)客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
(6)dn1、dn2、dn3逐級應答客戶端,
(7)客戶端開始往dn1上傳第一個Block(先從磁盤讀取資料放到一個本地記憶體快取),以Packet為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答,
(8)當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器,(重復執行3-7步),
2.NameNode管理分布式檔案系統的命名空間
NameNode內部以元資料的形式,維護著兩個檔案,分別是FsImage鏡像檔案和EditLog日志文件,其中,FsImage鏡像檔案用于存盤整個檔案系統命名空間的資訊,EditLog日志檔案用于持久化記錄檔案系統元資料發生的變化,當NameNode啟動的時候,FsImage鏡像檔案就會被加載到記憶體中,然后對記憶體里的資料執行記錄的操作,以確保記憶體所保留的資料處于最新狀態,這樣就加快了元資料的讀取和更新操作,
3.HDFS Block與MapReduce split之間的聯系
- split是MapReduce里的概念,是切片的概念,split是邏輯切片 ;而block是hdfs中切塊的大小,block是物理切塊;
- split的大小在默認的情況下和HDFS的block切塊大小一致,為了是MapReduce處理的時候減少由于split和block之間大小不一致,可能會完成多余的網路之間的傳輸,
如果blockSize小于maxSize && blockSize 大于 minSize之間,那么split就是blockSize;
如果blockSize小于maxSize && blockSize 小于 minSize之間,那么split就是minSize;
如果blockSize大于maxSize && blockSize 大于 minSize之間,那么split就是maxSize;
三、MapReduce
1.核心思想及概念
”分而治之“:把一個復雜的問題,按照一定的“分解”方法分為等價的規模較小的若干部分,然后逐個解決
MapReduce作為一種分布式計算模型,它主要解決海量資料的計算問題,使用MapReduce分析海量資料時,每個MapReduce程式被初始化為一個作業任務,每個作業任務可以分為Map和Reduce兩個階段,具體介紹如下:
-
Map階段:負責將任務分解,即把復雜的任務分解成若干個“簡單的任務”來并行處理,但前提是這些任務沒有必然的依賴關系,可以單獨執行任務
-
Reduce階段:負責將任務合并,即把Map階段的結果進行全域匯總
2.MapReduce作業程序(可以只背這部分黑色的)
-
分片、格式化資料源
(對資料進行分片和格式化)輸入Map階段的資料源,必須經過分片和格式化操作,
分片操作:指的是將源檔案劃分為大小相等的小資料塊(Hadoop 2. x中默認128MB) ,也就是分片(split),Hadoop會為每一個分片構建一個Map任務,并由該任務運行自定義的map()函式,從而處理分片里的每一-條記錄,格式化操作:將劃分好的分片(split)格式化為鍵值對<key,value>形式的資料其中,key代表偏移量,value代表每一-行內容,
-
執行MapTask
(處理任務,并將任務處理結果寫入記憶體緩沖區,若緩沖區將滿則寫入磁盤)每個Map任務都有一個記憶體緩沖區(緩沖區大小100MB),輸入的分片(split)資料經過Map任務處理后的中間結果會寫入記憶體緩沖區中,如果寫入的資料達到記憶體緩沖的閾值(80MB),會啟動一個執行緒將記憶體中的溢位資料寫入磁盤,同時不影響map中間結果繼續寫入緩沖區,
在溢寫程序中,MapReduce框架會對key進行排序,如果中間結果比較大,會形成多個溢寫檔案,最后的緩沖區資料也會全部溢寫入磁盤形成一個溢寫檔案,如果是多個溢寫檔案,則最后合并所有的溢寫檔案為-一個檔案, -
執行Shuffle程序
(將MapTask處理結果發給ReduceTask,并對資料進行磁區和排序)MapReduce作業程序中,Map階段處理的資料如何傳遞給Reduce 階段,這是MapReduce框架中關鍵的一個程序,這個程序叫作Shuffle. Shuffle 會將MapTask輸出的處理結果資料分發給ReduceTask,并在分發的程序中,對資料按key進行磁區和排序,
-
執行ReduceTask
(邏輯處理并輸出)輸入ReduceTask的資料流是<key, {value list}>形式,用戶可以自定義reduce()方法進行邏輯處理,最終以<key,value>的形式輸出,
-
寫入檔案
(將結果寫入檔案)MapReduce框架會自動把ReduceTask生成的< key, value>傳入OutputFormat的write方法,實作檔案的寫入操作,
3.Shuffle作業流程(可以只背這部分黑色的)
1.Map階段
(1)MapTask處理的結果會暫且放入一個記憶體緩沖區(默認大小100MB)內,當緩沖區快要溢位時(達到80%),會在本地檔案系統創建一個溢位檔案,將該緩沖區的資料寫入這個檔案,(若MapTask緩沖區將要溢位,則把緩沖區資料寫入本地溢位檔案)
(2)寫入磁盤前,執行緒會根據ReduceTask的數量將資料磁區,一個Reduce任務對應一個磁區的資料,這樣做目的是為了避免有些ruduce任務分配大量資料,而有些reduce任務分到很少的資料,甚至沒有分到資料的尷尬局面(將資料進行磁區)
(3)分完資料后,會對每個磁區的資料進行排序,如果此時設定了Combiner,將排序后的結果進行Combine操作,這樣做目的時盡可能少地執行資料寫入磁盤的操作,(對磁區資料進行排序,進行Combine操作)
(4)當Map任務輸出最后一個記錄時,可能有很多溢位檔案,這時需要將這些檔案合并,合并程序中不斷地進行排序和Combine操作,其目的有兩個:一是盡量減少每次寫入磁盤的資料量;二是盡量減少下一復制階段網路傳輸的資料量,最后合并成一個已磁區且排序的檔案(對溢位檔案進行合并,合并時進行排序和Combine操作)
(5)將磁區資料復制給對應的Reduce任務,
2.Reduce階段
(1)Reduce會接受到不同map任務傳來的資料,并且每個map傳來的資料都是有序的,如果Reduce階段接受到的資料量相當小,則直接存盤在記憶體中,如果資料量超過了該緩沖區大小的一定比例,則對資料合并后溢寫到磁盤中,(Reduce接受到的資料量小,存在記憶體中,否則將資料合并后存在磁盤)
(2)隨著溢寫檔案的增多,后臺執行緒會將它們合并成一個更大的有序的檔案,這樣做是為了給后面的合并節省時間,(后臺執行緒會將溢位檔案合并成一個大的有序的檔案)
(3)合并的程序中產生了許多中間檔案(寫入磁盤了),但MapReduce會讓寫入磁盤的資料盡可能地少,并且最后一次合并地結果沒有寫入磁盤,而是直接輸入到reduce函式,
組件
4.InputFormat組件
InputFormat組件主要用于描述輸入資料的格式,它提供一下兩個功能,
- 資料切分:按照某個策略將輸入資料切分成若干個分片,以便確定MapTask個數以及對應的分片,
- 為Mapper提供輸入資料:給定某個分片,將其決議成一個一個的key/value鍵值對,
5.Mapper組件
MapReduce程式會根據輸入檔案產生多個map任務,Hadoop提供的Mapper類是實作Map任務的一個抽象類,該基類提供了一個map()方法,默認情況下,Mapper類中的map方法是沒有做任何處理的,如果想自定義map()方法,只需要繼承Mapper類并重寫map()方法即可,
6.Reducer組件
Map程序輸出的鍵值對,將由Reducer組件進行合并處理,Hadoop提供了一個抽象類Reducer,當用戶呼叫Reducer類時,會直接呼叫Reducer類里的run()方法,該方法中定義了setup(),reduce(),cleanup()三個方法的執行順序:setup->reduce->cleanup,默認情況下,setup()和cleanup()方法內部不做任何處理,reduce()方法是處理資料的核心方法,該方法接受Map階段輸出的鍵值對資料,對傳入的鍵值對資料進行處理,并產生最終某種形式的結果并輸出,
7.Partitoner組件
Partitioner組件可以讓Map對Key進行磁區,從而根據不同的key分發到不同的Reduce中去處理,其目的是將key均勻分布在ReduceTask上,Hadoop自帶一個默認的磁區類HashPartitioner,它繼承了Partitioner類,并提供了一個getPartition方法,如果想自定義一個Partitioner組件,需要繼承Partitioner類并重寫getPartition()方法,重寫getPartitioner方法時,通常做法是使用hash函式對檔案數量進行磁區,即通過hash操作,獲得一個非負整數的hash碼,然后用當前作業的reduce節點數進行驅魔運算,從而實作資料均勻分布在ReduceTask的目的,
8.Combiner組件
在Map階段輸出可能會產生大量相同的資料,勢必會降低Reduce聚合階段的執行效率,Combiner組件的作用就是對Map階段的輸出的重復資料先做一次合并計算,然后把新的(key,value)作為Reduce階段的輸入,如果想自定義Combiner,需要繼承Reducer類,并且重寫reduce()方法,
9.JobTracker
- 概述:JobTracker是一個后臺服務行程,啟動之后,會一直監聽并接收來自各個TaskTracker發送的心跳資訊,包括資源使用情況和任務運行情況等資訊,
- JobTracker的主要功能:
1.作業控制:在hadoop中每個應用程式被表示成一個作業,每個作業又被分成多個任務,JobTracker的作業控制模塊則負責作業的分解和狀態監控,
*最重要的是狀態監控:主要包括TaskTracker狀態監控、作業狀態監控和任務狀態監控,主要作用:容錯和為任務調度提供決策依據,
2.資源管理,
10.TaskTracker:
- TaskTracker概述:TaskTracker是JobTracker和Task之間的橋梁:一方面,從JobTracker接收并執行各種命令:運行任務、提交任務、殺死任務等;另一方面,將本地節點上各個任務的狀態通過心跳周期性匯報給JobTracker,TaskTracker與JobTracker和Task之間采用了RPC協議進行通信,
- TaskTracker的功能:
1.匯報心跳:Tracker周期性將所有節點上各種資訊通過心跳機制匯報給JobTracker,這些資訊包括兩部分:
機器級別資訊:節點健康情況、資源使用情況等,
任務級別資訊:任務執行進度、任務運行狀態等,
2.執行命令:JobTracker會給TaskTracker下達各種命令,主要包括:啟動任務(LaunchTaskAction)、提交任務(CommitTaskAction)、殺死任務(KillTaskAction)、
殺死作業(KillJobAction)和重新初始化(TaskTrackerReinitAction),
四、Zookeeper
概念解釋:
1.zookeeper
zookeeper是一個分布式協調服務的開源框架,本質上是一個分布式的小檔案存盤系統,提供基于類似檔案系統的目錄樹方式的資料存盤,并且可以對樹中的節點進行有效管理,從而用來維護和監控存盤的資料的狀態變化,通過監控這些資料狀態的變化,從而達到基于資料的集群管理,如同一命名服務、分布式配置管理、分布式訊息佇列、分布式鎖、分布式協調等功能,
2.Znode
**Zookeeper是由節點組成的樹,樹中的每個節點被稱為Znode樹中每個節點被稱為都可以擁有子節點,每一個Znode默認能夠存盤1MB的資料,每個Znode都可以通過其路徑唯一標識,**Zookeeper資料模型中的每個Znode都是由3部分組成,分別是stat(狀態資訊,描述Znode的版本,權限資訊等組成)、data(與該Znode關聯的資料)和Children(該Znode下的子節點),
簡答題:
3.Zookeeper集群選舉機制(書上107,如果能理清就可以看,建議不看)
這個很多,實在背不下來就寫這個黑體,黑體下面就別看了
Zookeeper選舉機制有兩種型別,分別為全新集群選舉和非全新集群選舉,全新集群選舉是新搭建起來的,沒有資料ID和邏輯時鐘的資料影響集群的選舉;非全新集群選舉時是優中選優,保證Leader是Zookeeper集群中資料最完整、最可靠的一臺服務器,
首先明白幾個概念:
服務器ID:每個服務器都有不同的ID,假設我們有服務器1,服務器2,服務器3,數字編號越大當選leader的權重越大,
選舉狀態:每個Zookerper服務器都有4種狀態,分別為競選狀態(LOOKING)、隨從狀態(FOLLOWING,同步leader狀態,參與投票),觀察狀態(OBSERVING,同步leader狀態,不參與投票)和領導者狀態(LEADING),
資料ID:代表服務器中存放的最新資料版本號,值越大說明資料越新,
邏輯時鐘:投票次數,起始值為0,每投完一次票,這個資料就會增加,然后與接收到其他服務器回傳的投票資訊中的數值相比較,根據不同的值做出不同判斷,
全新集群選舉:
假設現在有5臺服務器均沒有資料,它們的編號分別是1,2,3,4,5,按編號依次啟動,程序如下:
- 服務器 1 啟動,給自己投票,然后發投票資訊給其他服務器,由于其他服務器沒有啟動,所以它收不到反饋資訊,但是由于投票還沒有到達半數(服務器 1 怎么知道一共有多少臺服務器參與選舉呢, 那是因為在zk組態檔中配置了集群資訊,所有配置了3888埠的服務器均會參與投票,假設這5臺都參與投票,則超過半數應為至少3臺服務器參與投票,),所以服務器 1 的狀態一直處于 LOOKING,
- 服務器 2 啟動, 給自己投票,然后與其他服務投票資訊交換結果, 由于服務器 2 的編號大于服務器 1, 所以服務器 2 勝出,但是由于投票仍未到達半數,所以服務器 2 同樣處于 LOOKING 狀態,
- 服務器 3 啟動, 給自己投票,然后與其他服務投票資訊交換結果, 由于服務器 3 的編號大于服務器 2,1,所以服務器 3勝出, 并且此時投票數正好大于半數, 所以選舉結束,服務器 3 處于LEADING 狀態, 服務器 1, 服務器 2 處于 FOLLOWING 狀態,
- 服務器 4 啟動, 給自己投票, 同時與之前的服務器 1 ,2,3交換資訊,盡管服務器 4 的編號最大,但之前服務器 3 已經勝出,所以服務器 4 只能處于 FOLLOWING 狀態,
- 服務器 5 啟動, 同上,FOLLOWING狀態,
- 整個zookeeper集群啟動以后,領導者就使用2888埠向從屬機開始通信,
非全新集群選舉:
對于運行正常的zookeeper集群,中途有機器down掉,需要重新選舉時,選舉程序就需要加入資料ID、服務器ID、和邏輯時鐘,
這樣選舉就變成:
- 邏輯時鐘小的選舉結果被忽略,重新投票;(除去選舉次數不完整的服務器)
- 統一邏輯時鐘后,資料id大的勝出;(選出資料最新的服務器)
- 資料id相同的情況下,服務器id大的勝出,(資料相同的情況下, 選擇服務器id最大,即權重最大的服務器)
4.Watch機制
在ZooKeeper中,引入了Watch機制來實作這種分布式的通知功能,ZooKeeper允許客戶端向服務端注冊一個Watch監聽,當服務端的一些事件觸發了這個Watch,那么就會向指定客戶端發送一個事件通知,來實作分布式的通知功能,
特點:
- 一次性觸發
- 事件封裝
- 異步發送
- 先注冊再觸發
五、Hive
概念解釋:
1.Hive
Hive是建立在Hadoop檔案系統上的資料倉庫,它提供了一系列工具,能夠對存盤再HDFS中的資料進行資料提取、轉換和加載,這是一種可以存盤、查詢和分析存盤再Hadoop中的大規模資料的工具
2.HQL
Hive定義了簡單的類SQL查詢語言,稱為HQL,它可以將結構化的資料檔案映射為一張資料表,允許熟悉SQL的用戶查詢資料,也允許熟悉MapReduce的開發者開發自定義的mapper和reducer來處理復雜的分析作業,相對于Java代碼撰寫的MapReduce來說,Hive的優勢更明顯,
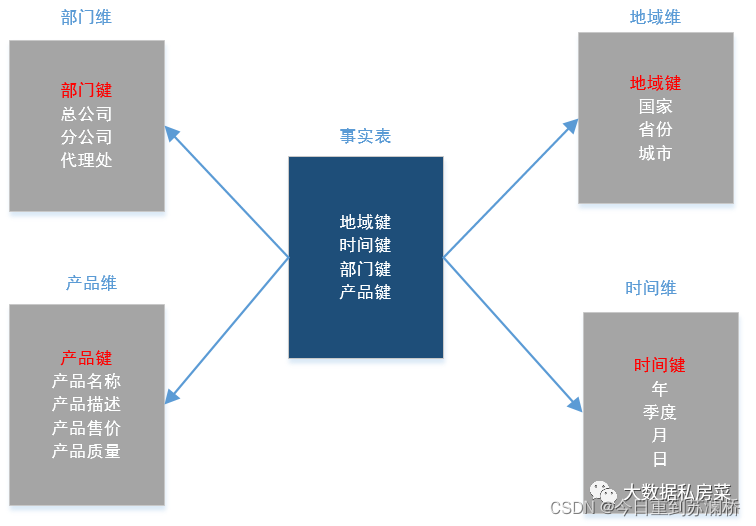
3.星狀模型
在資料倉庫建模中,形狀模型是維度建模中的一種選擇方式,星狀模型是由一個事實表和維度表組合而成,并且以事實表為中心,所有的維度表直接與事實表相連,如下圖所示,所有的維度表都直接連接到事實表中,作為事實表與維度表連接的外鍵,因此維度表和事實表是有關聯的,然而,維度表與維度表并沒有直接相連,因此,維度表之間是并沒有關聯的,
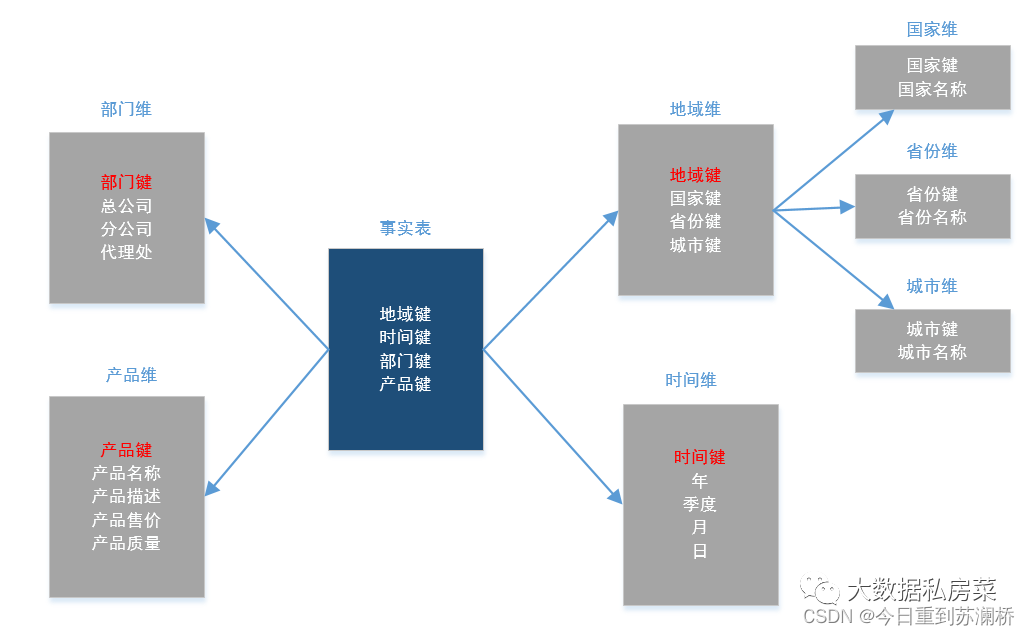
4.雪花模型
雪花模型也是維度建模的另一種選擇,它是對星狀模型的拓展,如下圖所示,雪花模型的維度表可以擁有其他的維度表,并且維度表與維度表之間相互關聯的,因此,雪花模型相比星狀模型更規范一些,但是,由于雪花模型需要關聯多層的維度表,因此,性能也比星狀模型要低,所以一般不是很常用,
5.桶表
簡單來說,桶表就是把“大表”分成了“小表”,把表或者磁區組織成桶表的目的主要是為了獲得更高的查詢效率,尤其是抽象查詢更為便捷,桶表是Hive資料模型的最小單元,資料加載到桶表時,會對欄位的值進行Hash取值,然后除以桶個數得到余數進行分桶,保證每個桶中都有資料,在物理上,每個桶表就是表或磁區的一個檔案,
簡答題
6.Hive的特點是什么
- 可擴展:Hive可以自由的擴展集群的規模,一般情況下不需要重啟服務,
- 延展性:Hive支持用戶自定義函式,用戶可以根據自己的需求來實作自己的函式,
- 容錯:良好的容錯性,節點出現問題SQL仍可完成執行,
六、Flume
概念解釋
1.Source
Source(資料采集器):用于源資料的采集,然后將采集到的資料寫入到Channel并流向Sink,
2.Channel
Channel(緩沖通道):底層是一個緩沖佇列,對Source中的資料進行快取,將資料高效,準確地寫入Sink,待資料全部到達Sink后,Flume就會洗掉該快取通道中的資料
3.Sink
Sink(接收器):接受并匯集向Sink的所有資料,根據需求,可以直接進行集中式存盤,也可以繼續作為資料源傳入其他遠程服務器或者Source中,
4.Flume攔截器
主要用于實作對Flume系統資料流中event的修改操作,常用的Flume攔截器有 時間攔截器、靜態攔截器和查詢和替換攔截器
簡答題
5.Flume的作業原理
Flume的核心是把資料源(如 Web Server)通過資料采集器(Source)收集過來,再將收集的資料通過緩沖通道(Channel)匯集到指定的接收器(Sink),
七、Azkaban
概念解釋:
Azkaban
開源的一個批量作業流任務調度器,用于在一個作業流內以一個特定的順序運行運行一組作業和流程,定義了一種KV檔案格式來建立任務之間的依賴關系,并提供一個易于使用的UI維護和跟蹤作業流
八、Sqoop
概念解釋:
Sqoop
–是一款開源工具,主要用于在Hadoop和關系型資料庫或大型機器之間傳輸資料,可以使用Sqoop工具將資料從關系資料庫系統匯入Hadoop分布式檔案系統中,或者將Hadoop中的資料轉換匯出到關系資料庫管理系統
論述題
1.HDFS不適合應用的場景有哪些
- 不能做到低延遲資料訪問:由于hadoop針對高資料吞吐量做了優化,犧牲了獲取資料的延遲,所以對于低延遲訪問資料的業務需求不適合HDFS,
- 不適合大量的小檔案存盤 :對于Hadoop系統,小檔案通常定義為遠小于HDFS的資料塊大小(128MB)的檔案,由于每個檔案都會產生各自的元資料,Hadoop通過NameNode來存盤這些資訊,若小檔案過多,容易導致NameNode存盤出現瓶頸,
- 不支持用戶的并行寫:HDFS目前不支持并發多用戶的寫操作,寫操作只能在檔案末尾追加資料,
Sqoop匯入匯出資料的作業原理是什么
- 匯入原理:Sqoop使用JDBC檢查打入的資料表,檢索出表中的所有列及列的SQL資料型別,并將這些SQL型別映射為JAVA資料型別,在轉換后的MapReduce應用中使用這些對應的Java型別來保存欄位的值,Sqoop的代碼生成器使用這些資訊來創建物件表的類,用于保存從表中抽取的記錄,
- 匯出原理:在匯出資料之前Sqoop會根據資料庫連接字串來選擇一個匯出方法,對于大部分系統來說,Sqoop會選擇JDBC,Sqoop會根據目標表的定義生成一個Java類,這個生成的類能夠從文本中決議出記錄資料,并能夠向表中插入型別合適的值,然后啟動一個MapReduce作業,從HDFS中讀取源資料檔案,使用生成的類決議出記錄,并且執行選定的匯出方法
2.基于Hadoop的大資料分析程序與傳統資料分析相位元點有哪些,有何不同
- 成本降低,能用PC機,就不用大型機和高端存盤
- 軟體容錯硬體故障視為常態,通過軟體保證可靠性
- 簡化并行分布式計算,無須控制節點同步和資料交換
3.大資料研究的意義是什么,理由,
研究大資料,最重要的意義在于預測,因為資料從根本上來講,是對過去和現在的歸納和總結,其本身不具備趨勢和方向性的特征,但是可以應用大資料去了解事物發展的客觀規律、了解人類行為,并且能夠幫助我們改變過去的思維方式,建立新的資料思維模式,從而對未來進行預測和推測,
4.Hadoop的組件有哪些,結構分別是什么,特點是什么
四大組件:
MapReduce
結構:由一個JobTracker和多個DateNode組成,
特點:“分而治之”,將海量資料分解成多個任務進行處理,
HDFS
結構:由一個NameNode和多個DataNode組成
特點:高容錯性的資料備份機制
Yarn
結構:由ResourceManager和ApplicationMaster實作
特點:通用
Others(其他工具類)
特點:提供服務,提供API
5.Hadoop集群的特點是什么,分布式系統給Hadoop帶來什么特性
集群特點
- 擴容能力強
- 成本低
- 高效率
- 可靠性
- 高容錯性
分布式系統特性
優點:
- 高容錯
- 流式資料訪問
- 支持超大檔案
- 高資料吞吐量
- 可構建在廉價機器上
缺點:
- 高延遲
- 不適合小檔案存取場景
- 不適合并發寫入
6.總結Hadoop集群部署的程序,分為哪些步驟
- JDK安裝
- Hadoop安裝
- Hadoop集群配置
? (1) 在hadoop-env.sh檔案中配置JAVA_HOME引數
? (2) 在core-site.xml檔案中配置HDFS地址、埠號以及臨時檔案目錄
? (3) 在hdfs-site.xml檔案中設定NameNode和DataNode兩大行程
? (4) 在mapred-site.xml檔案中指定MapReduce運行時框架
? (5) 在yarn-site.xml檔案中指定YARN集群管理者
? (6) 修改slaves檔案記錄從節點主機名
? (7) 將組態檔分發到子節點
7.與普通集群相比,Hadoop高可用集群有哪些特殊之處,兩者有何不同
普通集群
- 并發量差
- 容錯性差(不具有高可用性)
注:不具有高可用性的意思是,比如當用戶訪問時,服務器后臺因為一些原因導致服務器崩潰,用戶就能直接看到錯誤頁面,服務器也因為錯誤從而停止運行(宕機),這就叫做不具有高可用性,
Hadoop集群(詳情見書第7頁,具體內容可以背點)
- 擴容能力強
- 成本低
- 高效率
- 可靠性
- 高容錯性
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379157.html
標籤:其他
上一篇:Flume1.9.0配置
下一篇:hadoop偽分布式搭建筆記