IMDB電影資料分析實踐
根據IMDB5000部電影資料集進行下列資料分析:
- 資料準備:讀取資料并查看資料的基本資訊
- 資料清洗:缺失值處理,重復值處理,處理后“干凈”資料的基本資訊,
- 資料分析及可視化展示:
電影出品國及地區和演員票房的情況分析:
繪制電影出品數量排名前10位的國家及地區的條形圖;繪制票房前十的電影中喜愛男 1 號,男 2 號,男 3 號的人數的分組條形圖,電影數量的分析:
按年份統計每年電影總數量、彩色影片數量和黑白影片數量并繪制折線圖(在同一個坐標系中繪制),電影型別的分析:
繪制不同型別的電影數量條形圖和餅圖,電影評分統計及電影評分相關因素分析:
找出評分排名前 20 位電影的片名和評分;繪制所有影片評分與受歡迎程度的關系散點圖,
文章目錄
- 一、資料準備:
- 1. 匯入numpy 包和 pandas 包,使用 read_csv 方法讀取本地 csv 資料;
- 2. 查看資料的基本內容、結構
- 二、資料清洗
- 1. 缺失資料處理
- 2. 重復值處理
- 3. 處理后的資料
- 三、資料分析及可視化展示
- 1. 電影出品國及地區和演員票房的情況分析:
- 1.1 繪制電影出品數量排名前10位的國家及地區的條形圖;
- 1.2 繪制票房前十的電影中喜愛男1號,男2號,男3號的人數的分組條形圖,
- 2. 電影數量的分析:
- 3. 電影型別的分析:
- 4. 電影評分統計及電影評分相關因素分析:
- 4.1 找出評分排名前20位電影的片名和評分;
- 4.2 繪制所有影片評分與受歡迎程度的關系散點圖,
一、資料準備:
讀取資料并查看資料的基本資訊
1. 匯入numpy 包和 pandas 包,使用 read_csv 方法讀取本地 csv 資料;
import pandas as pd
import numpy as np
movies = pd.read_csv('D:\\gaojie\\movie_metadata.csv',encoding='utf—8')
2. 查看資料的基本內容、結構
-
列印前五行觀察
movies.head (5)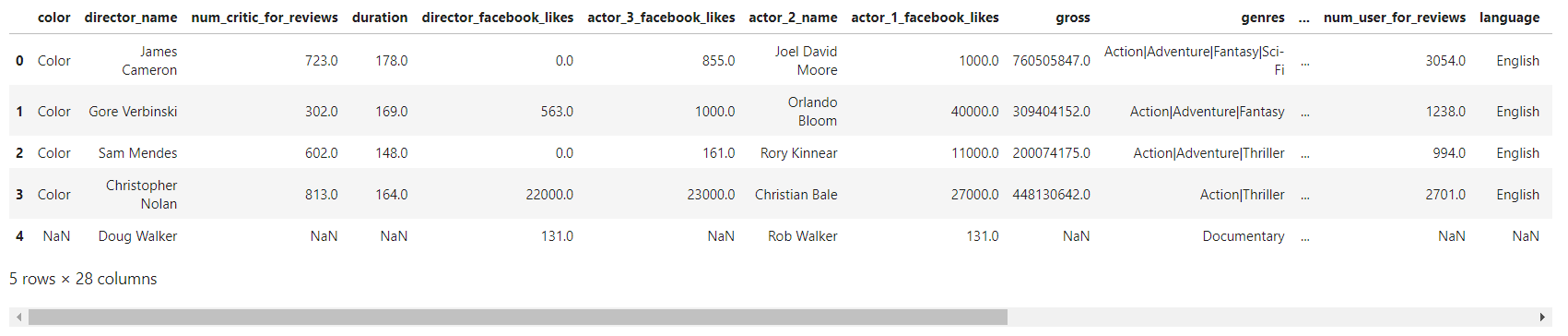
通過前五行,可以看出資料集有28列,以及具體的列名,同時也可以發現,前五行里就有空值較多的行,說明我們需要對資料作處理,
-
輸入 .shape 看看有多少行多少列
movies.shape
可以看到,資料集的維度是5043行,28列,
-
查看列的資料型別
movies.dtypes
可以看出,資料集中涉及資料的列默認為 float64 和 int64,無需對資料做型別轉換,而其他列均為 object 型別,后面需要考慮是否做型別轉換,
二、資料清洗
資料清洗也叫資料預處理,因為大多時候獲取的資料并不符合我們的資料分析的標準這時候我們就需要對資料進行預處理,使之資料更加規整有序方便我們下一步的分析,資料清洗通常需要資料分析大部分時間,但是我覺得也是有一定的步驟的,我將它大致分為六部曲: 選擇子集→列名重命名→缺失資料處理→資料型別轉換→資料排序→例外值處理
1. 缺失資料處理
-
先通過isnull函式看一下是否有空值,結果是有空值的地方顯示為True,沒有的顯示為False
print(movies.isnull())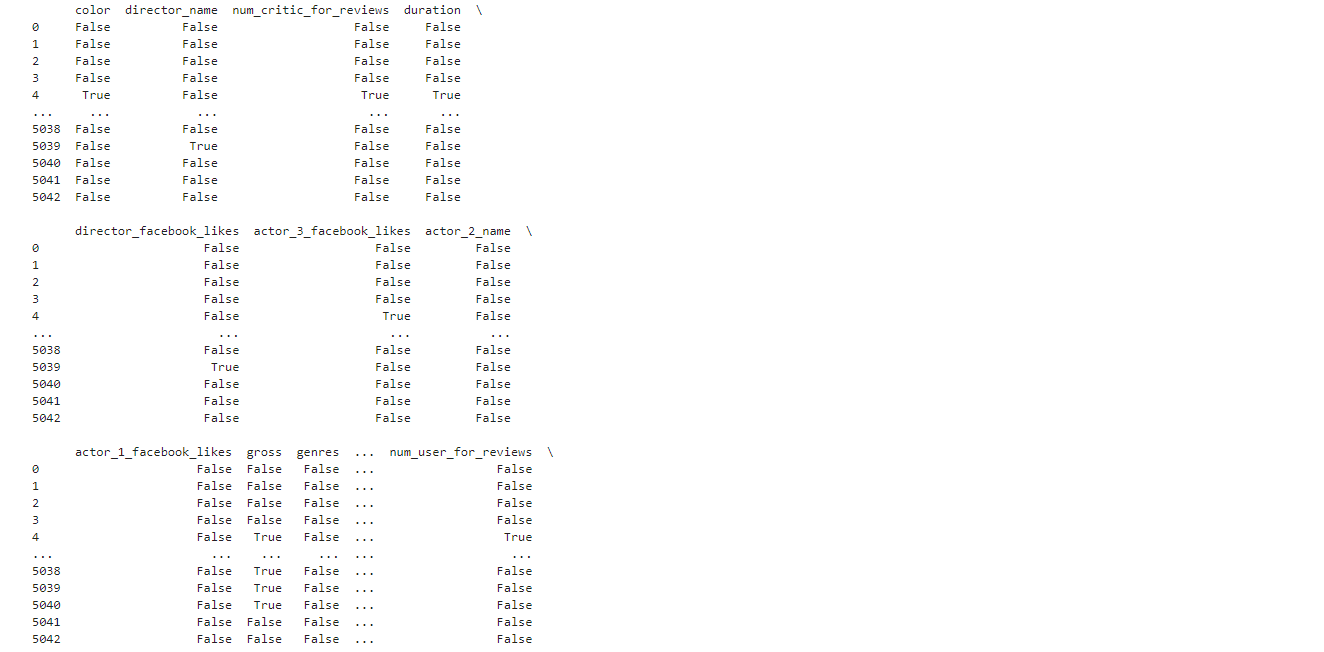
可以看到有空值的行非常之多,在分析之前我們需要處理對行進行取舍,
-
再通 過 isnull().sum() 直接看每一列有多少空值
print(movies.isnull().sum())
可以看到,只有極少列沒有空值,有的列空值例外之多,因此我們處理的時候只能選擇讓重點的列沒有空值,洗掉行而不要洗掉列,
-
為了方便我們這里選擇直接洗掉有缺失值的行
print ('洗掉缺失值前資料集大小 ',movies.shape ) # how=‘any’ 在給定的任何一列中有缺失值就洗掉 movies = movies.dropna(how ='any' ) print ('洗掉缺失值后大小 ',movies.shape )
可以看到一千多行有缺失值的資料被洗掉掉了,對資料的損耗還是非常大的,最好是只洗掉重要列有缺失值的行,或者按缺失值的比例洗掉,規定n行有多少個缺失值時再洗掉,
-
這里我們選擇洗掉電影名重復的行:
movies.drop_duplicates(subset=["movie_title"],keep='first',inplace=True) print(movies.duplicated().value_counts())
2. 重復值處理
-
先用 duplicated() 方法進行邏輯判斷,確定是否有重復值,統計重復值的數量
print(movies.duplicated().value_counts())
可以看到,雖然有眾多重復值,但我們應該考慮哪些列的重復值是不允許出現應該洗掉的,因為很多重復值可能只是資料相同,或者演員、國家這樣的重復值是允許出現的,
-
再用 duplicates(subset,keep,inplace) 方法對某幾列下面的重復行洗掉
- subset: 以哪幾列作為基準列,判斷是否重復,如果不寫則默認所有列都要重復才算
- keep: 保留哪一個,fist-保留首次出現的,last-保留最后出現的,False-重復的一個都不保留,默認為first
- inplace: 是否進行替換,最好選擇 False,保留原始資料,默認也是 False
這里我們選擇洗掉所有電影名重復的行
movies.drop_duplicates(subset=[‘director_name’],keep='first',inplace=True) print(movies.duplicated().value_counts())
可以看到重復值并沒有變化,因為重復值均為 int64 型別,也就是說沒有電影名重復的行,因此沒有資料被洗掉掉 ,
3. 處理后的資料
使用 info 查看處理后“干凈”資料的基本資訊:
movies.info

可以看到,處理后資料為3655行,保留了所有的列,我們將在此資料集上做資料分析及可視化展示,
三、資料分析及可視化展示
1. 電影出品國及地區和演員票房的情況分析:
1.1 繪制電影出品數量排名前10位的國家及地區的條形圖;
-
按country分組,統計所有國家的電影數量
country_group = movies.groupby('country').size() country_group
-
電影出品數量排名前10位的國家
group_head_10=country_group.sort_values(ascending=False).head(10) group_head_10
得到了電影數量前十的國家及對應的電影數量,因為電影數量為 int64,因此可以直接作為縱軸數值繪圖
-
繪制電影出品數量排名前 10 位的柱形圖的國家及地區的條形圖
group_head_10.plot(kind = 'bar')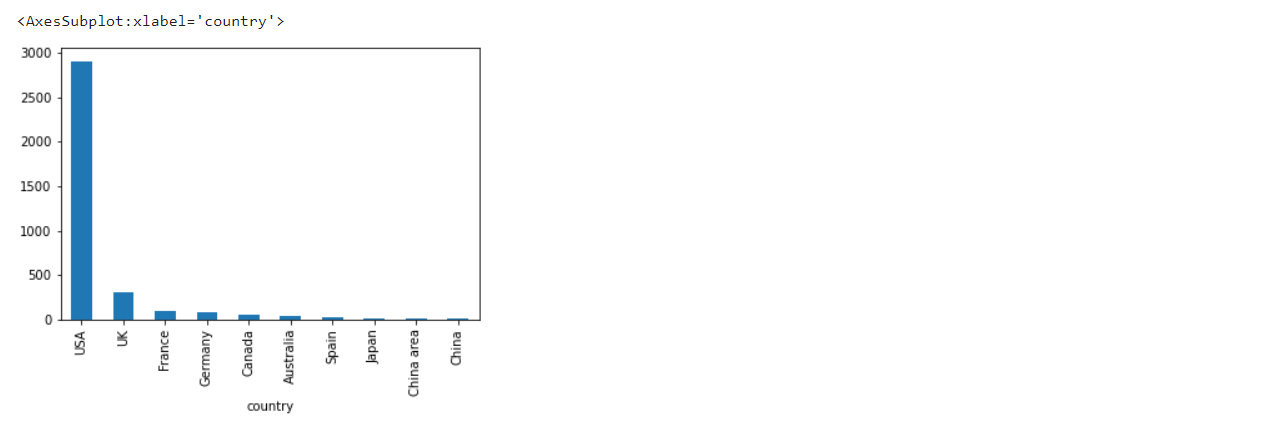
1.2 繪制票房前十的電影中喜愛男1號,男2號,男3號的人數的分組條形圖,
-
將電影按票房數降序排序,切取前10的電影資訊
movie_max=movies['gross'].sort_values(ascending=False).head(10) movie_max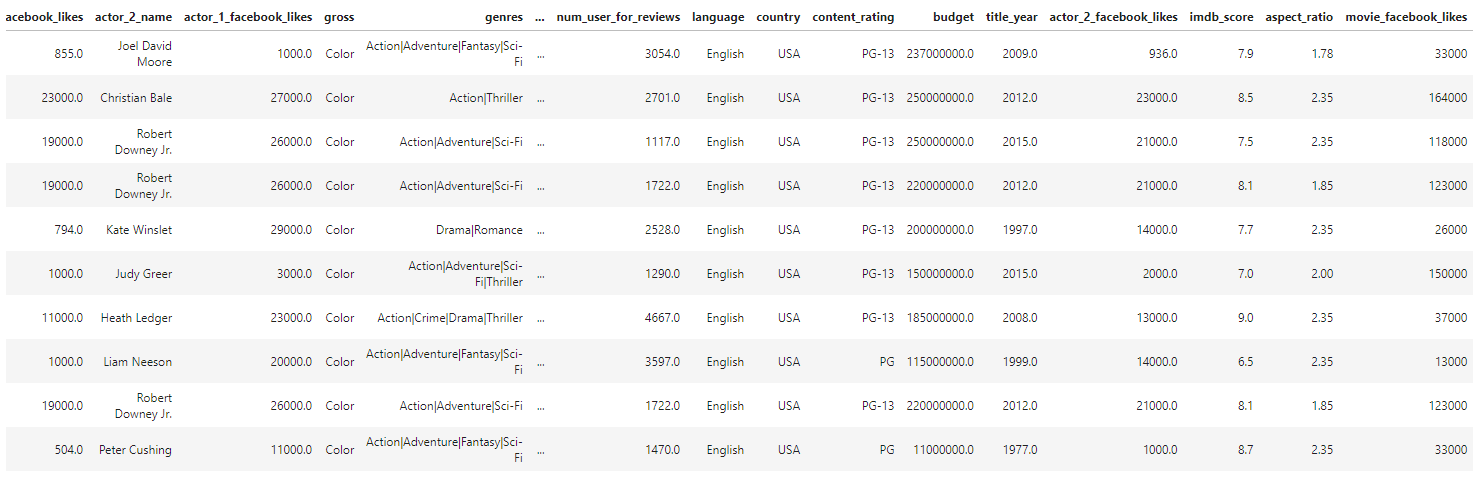
-
創建 DataFrame,作為分組條形圖的資料集
df = pd.DataFrame({'喜愛男1號':movie_max1['actor_1_facebook_likes'].values,'喜愛男2號':movie_max1['actor_2_facebook_likes'].values,'喜愛男3號':movie_max1['actor_3_facebook_likes'].values}, index=movie_max1['movie_title']) df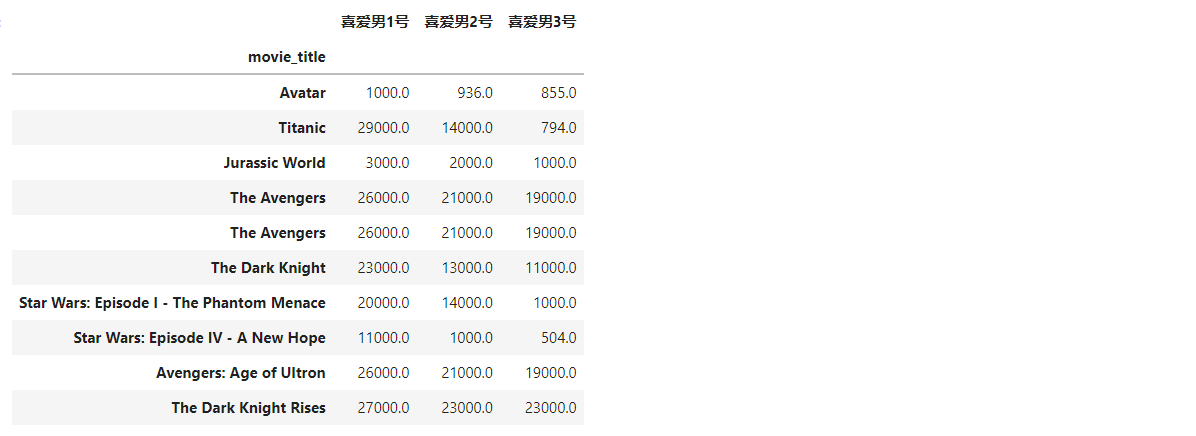
-
繪制分組條形圖
import pandas as pd import matplotlib.pyplot as plt import numpy as np import matplotlibplt.figure() df.plot.bar() plt.legend(ncol=3,loc=(0,1.1)) plt.show`` 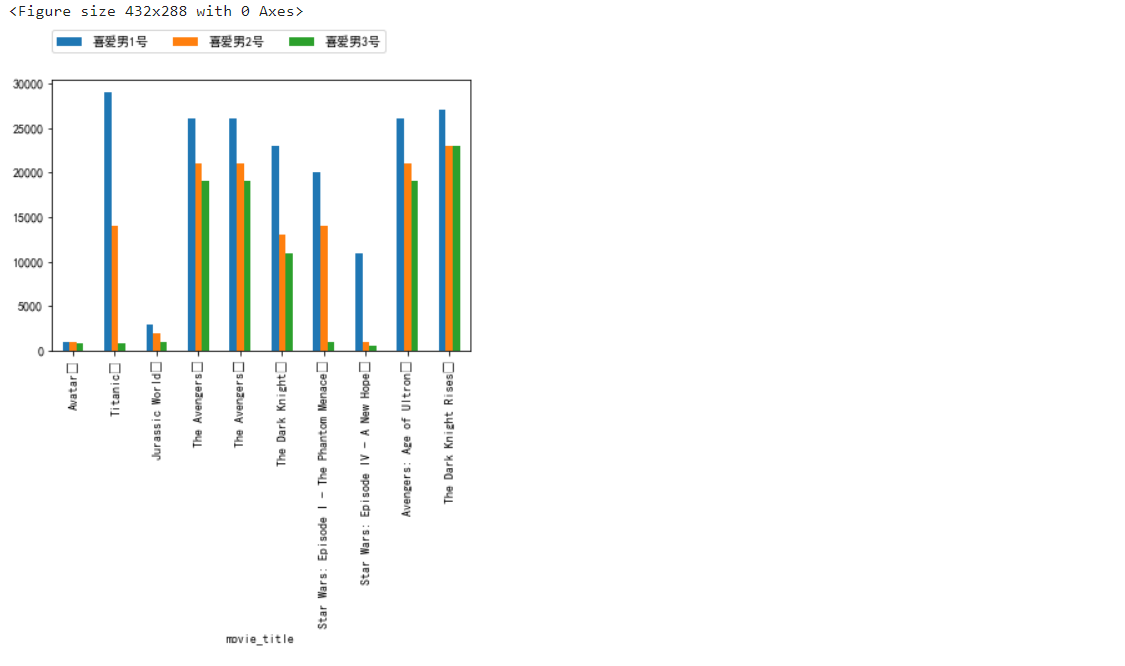
2. 電影數量的分析:
-
按年份統計每年電影總數量、彩色影片數量和黑白影片數量并繪制折線圖(在同一個坐標系中繪制),
# 每年電影總數量折線圖 movies['title_year'].value_counts().sort_index().plot(kind='line',label='total number') # 彩色影片數量折線圖 movies[movies['color']=='Color']['title_year'].value_counts().sort_index().plot(kind='line',c='red',label='color number') # 黑白影片數量折線圖 movies[movies['color']!='Color'] ['title_year'].value_counts().sort_index().plot(kind='line',c='black',label='Black White number') plt.legend(loc='upper left')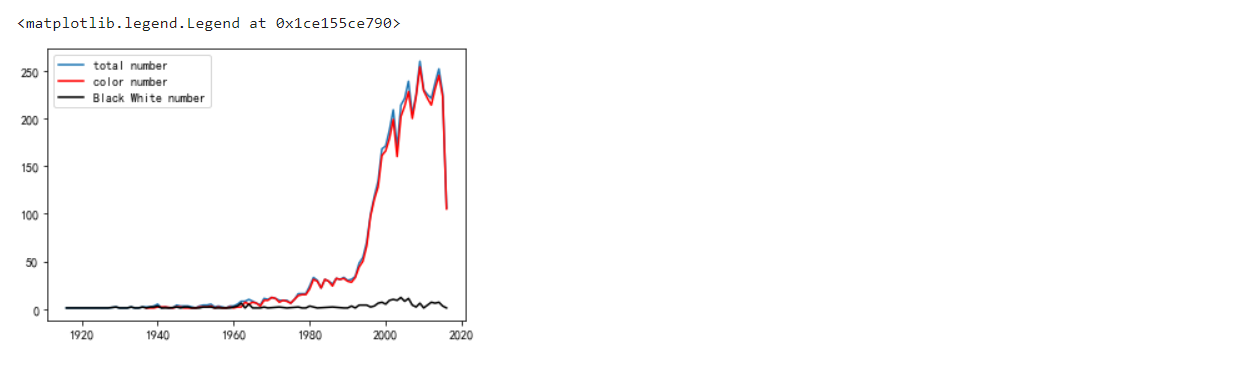
3. 電影型別的分析:
繪制不同型別的電影數量條形圖和餅圖,
-
提取 genres 列所有的電影型別,放入一個陣列中;
# 創建字典用于存盤電影型別 types = [] for tp in movies['genres']: sp = tp.split('|') for x in sp: types.append(x) # 格式化 types_df = pd.DataFrame({'genres':types})
可以看到,字典中共有14504個電影型別(包含重復值),
-
統計字典中各種型別的數量
types_df_counts = types_df['genres'].value_counts() types_df_counts
-
繪制不同型別的電影數量條形圖
types_df_counts.plot(kind='bar') plt.xlabel('genres') plt.ylabel('number') plt.title('genres&number')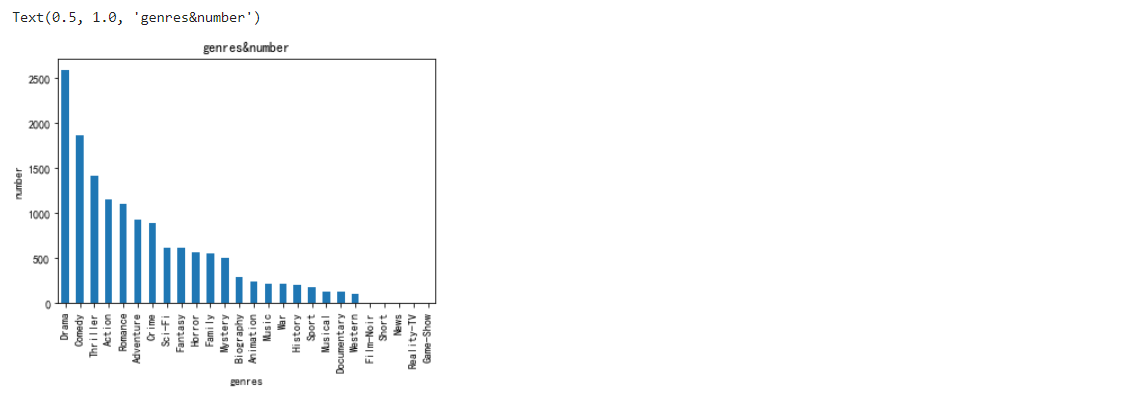
-
繪制不同型別的電影數量餅圖
b1 = types_df_counts/types_df_counts.sum() explode = (b1>=0.06)/20+0.02 types_df_counts.plot.pie(autopct='%1.1f%%',figsize=(8,8),\ label='',explode=explode) plt.title('Movie Type Proportional Distribution Map')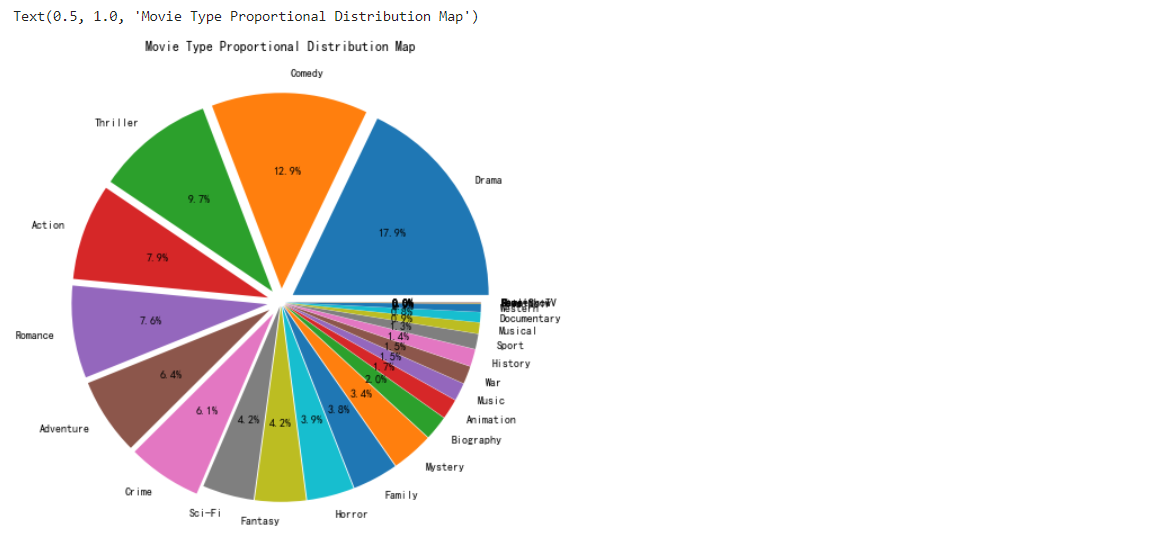
4. 電影評分統計及電影評分相關因素分析:
4.1 找出評分排名前20位電影的片名和評分;
movie_score_20 = movies.sort_values(['imdb_score'],ascending=False).head(20)
movie_score_20[['movie_title','imdb_score']]
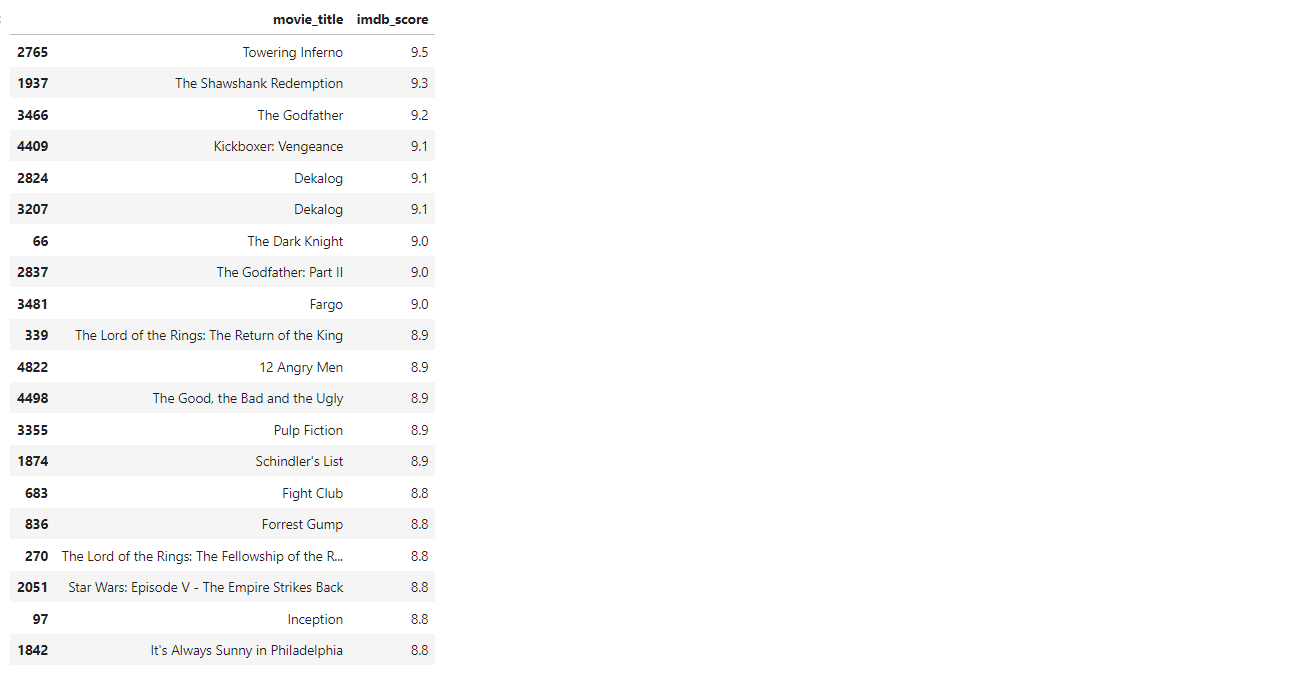
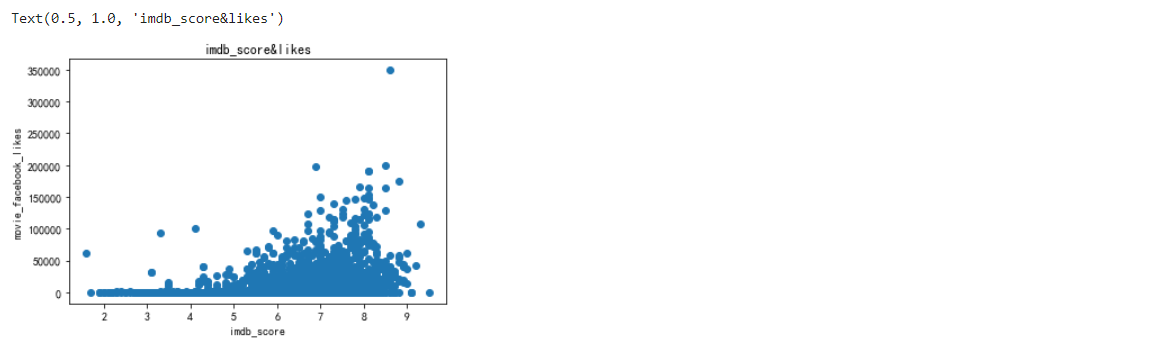
4.2 繪制所有影片評分與受歡迎程度的關系散點圖,
plt.scatter(x= movies.imdb_score,y= movies.movie_facebook_likes)
plt.xlabel('imdb_score')
plt.ylabel('movie_facebook_likes')
plt.title('imdb_score&likes')
Over
😃分享不易,點贊關注不迷路!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379228.html
標籤:AI
上一篇:python實作雙人版坦克大戰游戲,我敢打賭現在00后都沒玩過
下一篇:從tf1到tf2的幾個函式轉換