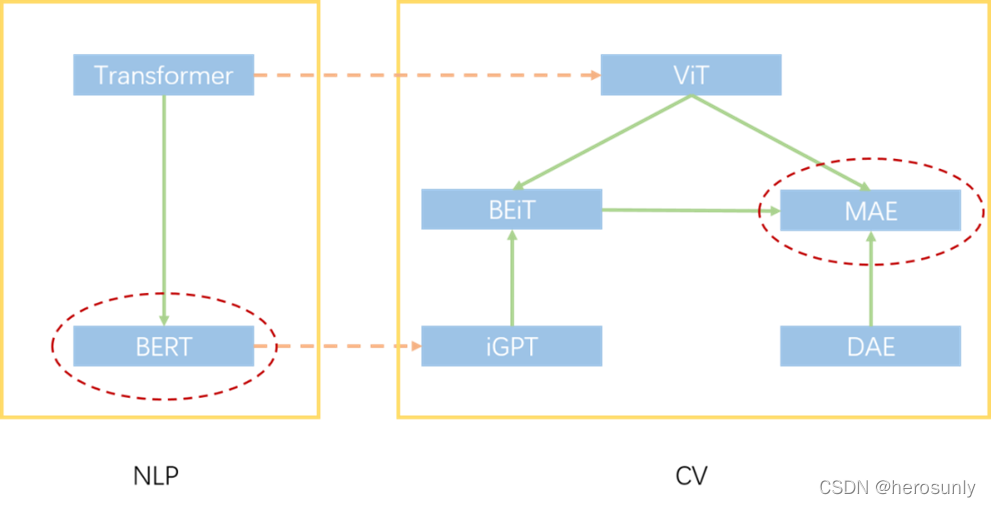
| NLP | CV |
|---|---|
| Transformer | ViT |
| BERT | MAE |
文章目錄
- 1. 標題
- 2. 摘要
- 3. 模型架構
- 4. 結論
1. 標題
??Masked Autoencoders Are Scalable Vision Learners指的是帶掩碼的自編碼器是可擴展的視覺學習器,其中這里的Autoencoders指的是模型的輸入和輸出都是相同的,簡單來說Autoencoder=encoder+decoder,
??作者其中包括了ResNet的第一作者何愷明大神,
2. 摘要
??MAE的方法比較簡單:對輸入圖片進行隨機塊的mask,然后對mask塊中的像素進行重構,核心設計主要是源于兩點,
??第一,設計了非對稱的編碼器和解碼器架構,其中編碼器僅對沒有進行mask的區域進行編碼,解碼器是輕量級的,能夠重構原始的圖片,
??第二,如果對圖片中絕大多數的區域進行mask,比如75%,就會得到一個很有意義的自監督任務,
??通過上述兩個設計,就能夠更加有效地訓練大模型,如訓練速度提升3倍,并且提高訓練的精度,
??在ViT-Huge的模型中僅僅使用100W的資料就能得到(87.8%)的準確率,在下游任務進行遷移學習的效果優于有監督的預訓練,
3. 模型架構
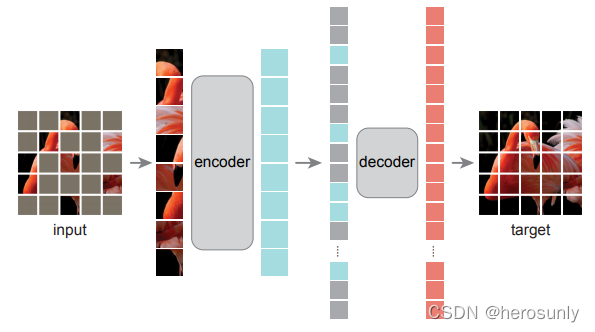
??其中masked的塊被涂成灰色(絕大部分),將沒有masked的區域作為encoder(ViT)的輸入,將其輸出填入到新構建的長向量中,灰色部分只包含了位置向量填入到新構建的長向量中,然后將長向量輸入到decoder中,最侄訓原出整個原來的圖片,encoder的模型復雜度大于decoder,
4. 結論
??簡單的演算法具有一定的擴展性,是深度學習的核心,在NLP中,簡單的自監督學習方法得到了成功的應用,但在計算機視覺中,預訓練范式絕大多數還是有監督的方法,在本研究中,使用了autoencoder進行類似于NLP的自監督學習,
??在另一方面,由于影像和語言資料的本質并不相同,所以必須謹慎進行處理,在NLP中,一個詞是一個語意的單元,包含的語意資訊是比較多的,在影像中,雖然每個patch包含一定的語意資訊,但它并不是一個語意的segment,MAE能夠學習到比較好的語意表達,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379390.html
標籤:AI