某不愿意透露姓名的神州實習生:一閃,聽說你最近一直在摸魚?
我:開發人的事,能叫摸魚嗎,一個需求給我3天,我1天就做完了,要是直接交上去,那不得被壓榨嗎?
神州實習生:原來是這樣,那你抽個時間幫我寫資料介面,晚上我把SQL發你

Spark與Flink的區別
老程式員:明天咱們要招實習生了,快給我出點面試題
我:(???)那之前面我的時候題目誰出的
老程式員:(= =)那肯定是我親自出的,因為我很欣賞你
我:……那開局第一個問題:Spark和Flink的區別
老程式員:這問題人人都問,他們估計都背熟了
我:可以問深一點嘛,比如他們會說”Spark只支持處理時間,但是Flink還支持事件時間”,然后就告訴他們”StructStreaming是支持事件時間的,有了解嗎?”
老程式員:真筍啊(我喜歡)

我:如果他們沒提到CK的話,就讓補充一下,比如Flink只存盤狀態資料,SparkStreaming還存盤計算邏輯,因為底層呼叫的是ssc的getActiveOrCreate()方法巴拉巴拉
深究
老程式員:不錯不錯.再說兩個
我:Emmmm,那就再問個共享組,這東西據我所知不是經常問,出其不意(必自bi),Map在G1組中,因為FlatMap被指定為G1組后,與前面的Filter無法組成任務鏈,但是與后面的Map仍有可能組成任務鏈,從這一點出發,Map是屬于G1組的(你可別問我原始碼怎么寫的,我可不會啊)
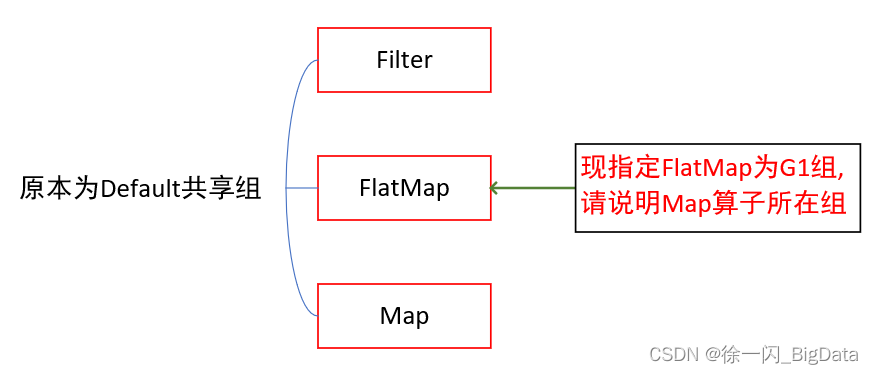
老程式員:原始碼里怎么體現的?
![]()
我:...我又想到一個問題(趕緊扯開話題),對于事件時間,當一條流中的資料有時稀疏有時密集時,我們選用間歇型生成WaterMark還是周期型?
老程式員:周期型,因為對于在面對資料密集的流時,使用間歇型會導致我們的每一條資料都帶有WaterMark,如果再考慮WaterMark的廣播,資料量會急劇增長,所以只要有資料密集的可能性,就應該避免間歇型.對于資料稀疏的情況,雖然周期型也會生成多余的WaterMark,但是當資料量少時,程式壓力也較小,這是完全可以接受的.
我:那你再說說看,FlinkCDC、MaxWell、Canal的區別
老程式員: ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
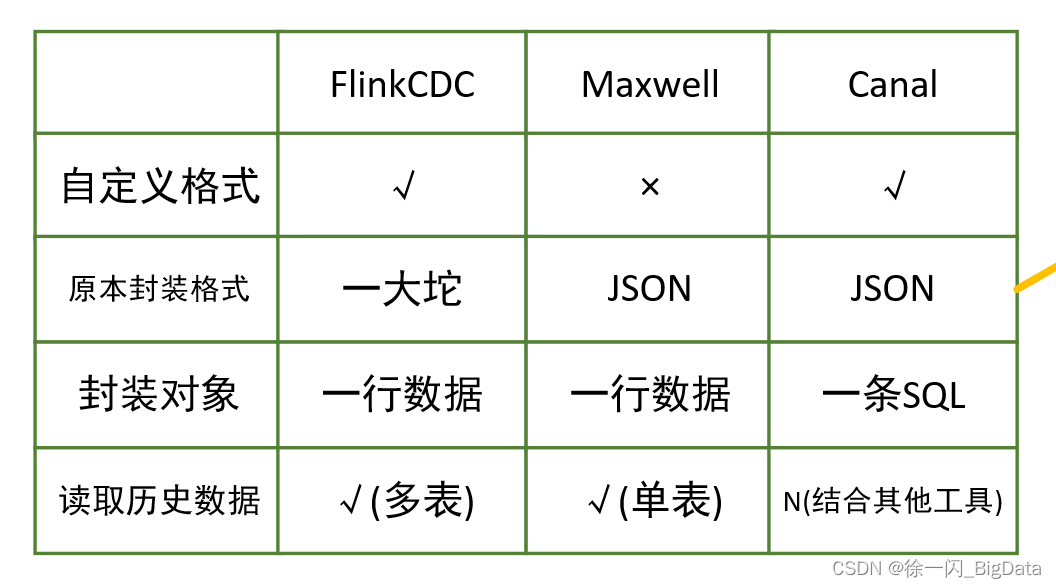
我:你這一套我都聽爛了,有沒有其他新鮮點的?
老程式員: 在FlinkCDC1.0中初始化程序中會鎖表,并且是單執行緒的,所以沒人用,直到2.0版本之后,我才開始在構建時把它考慮進去
![]()
我:我們公司在離線架構上對于hive表多半都是Parquet存盤,唯獨Ads層沒有指定Parquet.你知道是為什么嗎?
老程式員:可能是貴司用的是Hive On Spark吧,Spark對Parquet是有優化的,對于Ads層的資料可能要匯出到Mysql,所以沒有使用列存
我:最后一個問題吧,談談你了解的Kafka
老程式員:Kafka是一個高吞吐的分布式訊息佇列(省略2000字架構介紹),常常是用來做實時數倉的分層和起到一個聚合的作用,在19年的時候,有個叫Pulsar的玩意頂替Kafka成為了Apache的頂級專案,但是好像也沒有什么后文了.
我:不錯,你有什么問題要問我的嗎.
老程式員:明天你和我一起去面新人.你負責提問題,記得多出幾個啊.

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379426.html
標籤:其他
上一篇:多執行緒實作檔案決議避免大資料量檔案一次性加載到記憶體引起OOM
下一篇:亂七八糟講比賽