一、ssh免密登錄
1、在每個節點生成公鑰和私鑰,并拷貝
Hadoop100:
生成公鑰和私鑰
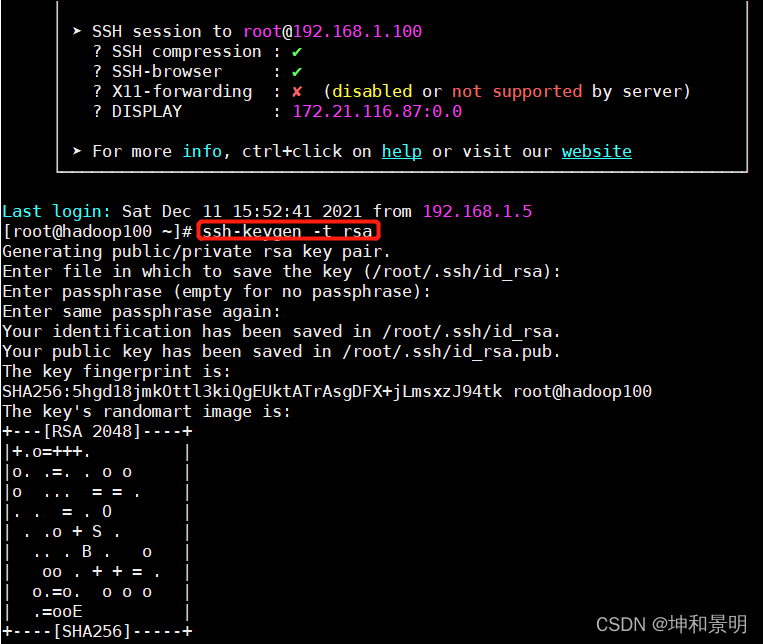
[root@hadoop100] ssh-keygen -t rsa然后敲(三個回車)出現如下圖所示:
2、 將公鑰拷貝到要免密登錄的目標機器上
[root@hadoop100] ssh-copy-id hadoop100
[root@hadoop100] ssh-copy-id hadoop101
[root@hadoop100] ssh-copy-id hadoop102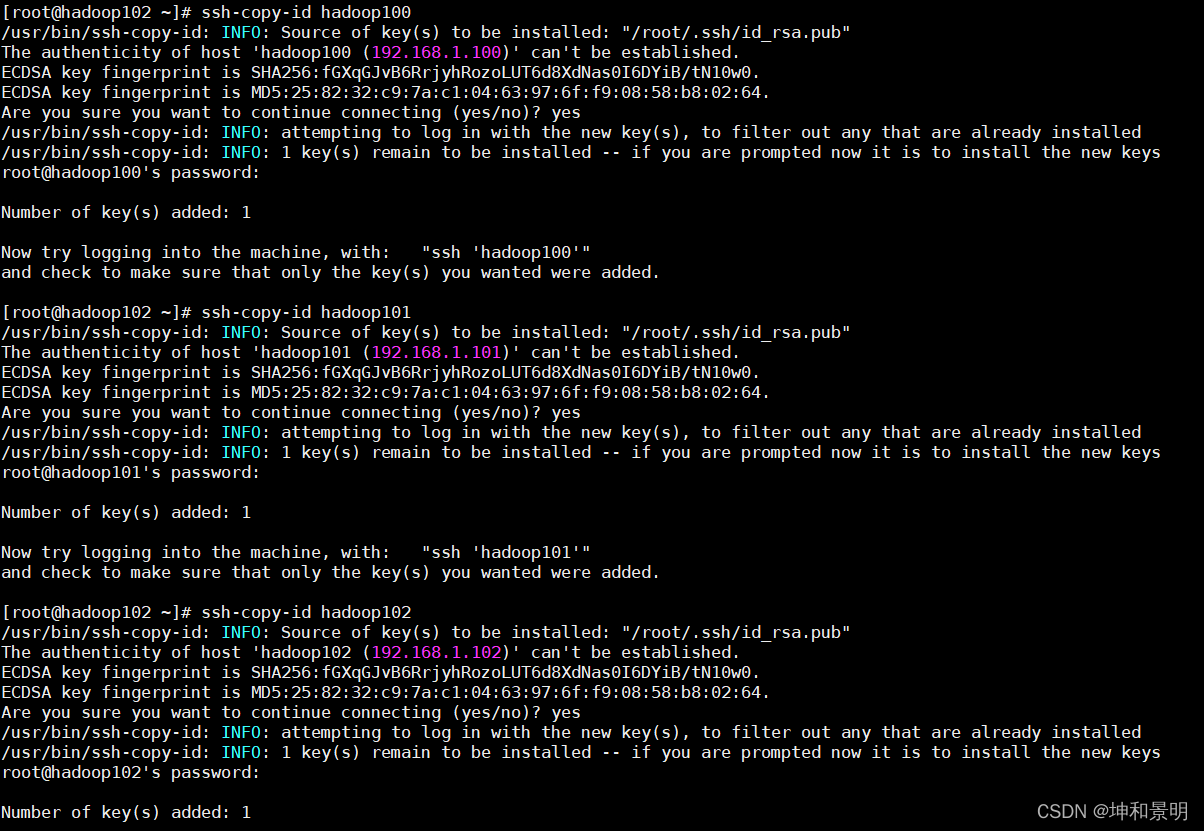
三臺虛擬機都要配置免密登錄,這樣更加快捷,hadoop100,hadoop101,hadoop102的免密配置操作是一樣的
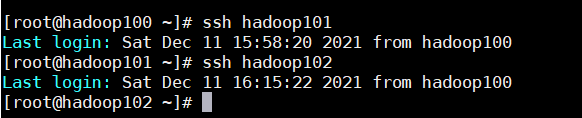
3、虛擬機的跳轉命令
ssh 主機名正常情況下跳轉很麻煩,需要輸入yes,密碼之類的,配過免密就很方便
二、分布式集群格式化
(1)分布式集群第一次啟動之前要格式化
格式化之前,要把三個服務器上的hadoop安裝目錄下的 data目錄和logs目錄都刪掉
[root@hadoop101 opt]# cd /opt/module/hadoop-3.1.3
切換到hadoop-3.1.3目錄下刪掉data和logs檔案
[root@hadoop101 opt]# rm -rf data
[root@hadoop101 opt]# rm -rf logs(2)在指定namenode運行的服務器上執行格式化:
(namenode指定在hadoop100上運行的)
[root@hadoop100 hadoop-3.1.3]# hdfs namenode -format(3)啟動集群(單起)
| hadoop100 | hadoop101 | hadoop102 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
Hadoop100:
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start nodemanagerhadoop101:
yarn --daemon start resourcemanager
hdfs --daemon start datanode
yarn --daemon start nodemanagerhadoop102:
hdfs --daemon start secondarynamenode
hdfs --daemon start datanode
yarn --daemon start nodemanager1)啟動hdfs相關
hdfs --daemon start namenode
hdfs --daemon start datanode2)啟動yarn相關
yarn --daemon start resourcemanager
yarn --daemon start nodemanager三、修改hadoop組態檔
(1)在hadoop100上的start-dfs.sh 和stop-dfs.sh 檔案最上邊添加幾行資料
cd /opt/module/hadoop-3.1.3/sbin[root@hadoop100] vi start-dfs.sh
添加下面的內容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root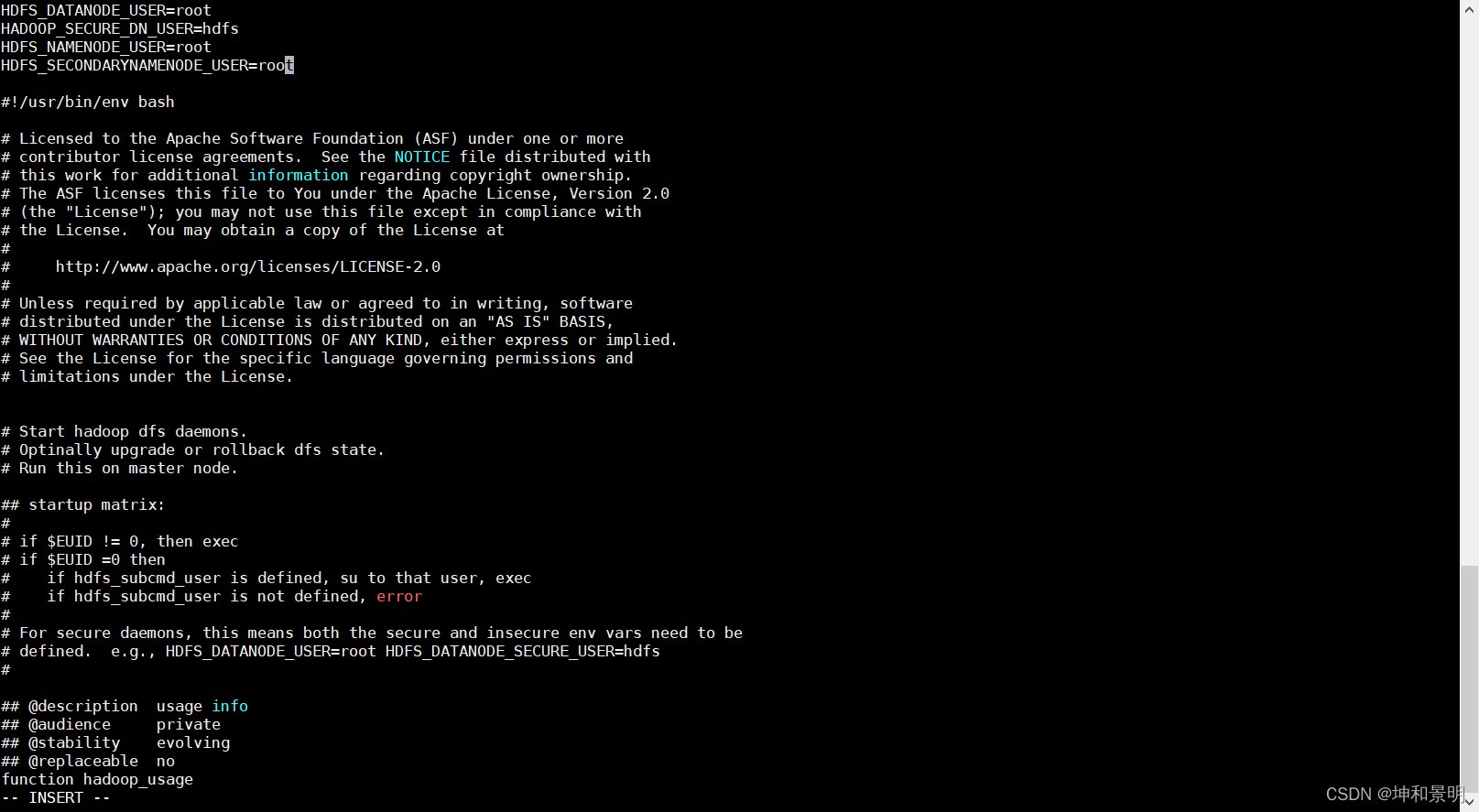
[root@hadoop100] vi stop-dfs.sh
添加下面的內容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root 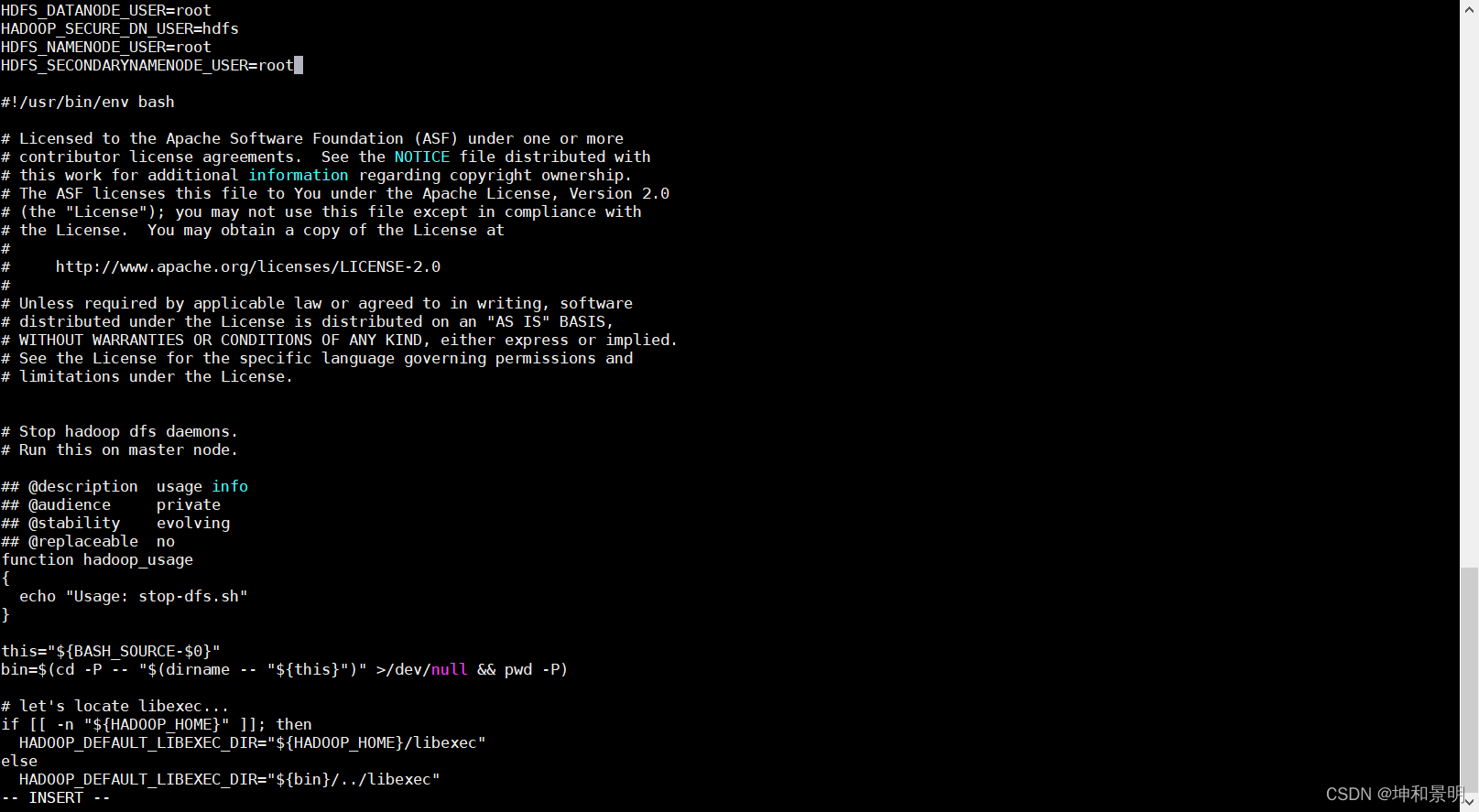
在 start-yarn.sh 和 stop-yarn.sh檔案最上方添加幾行資料
[root@hadoop100] vi start-yarn.sh
添加下面的內容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root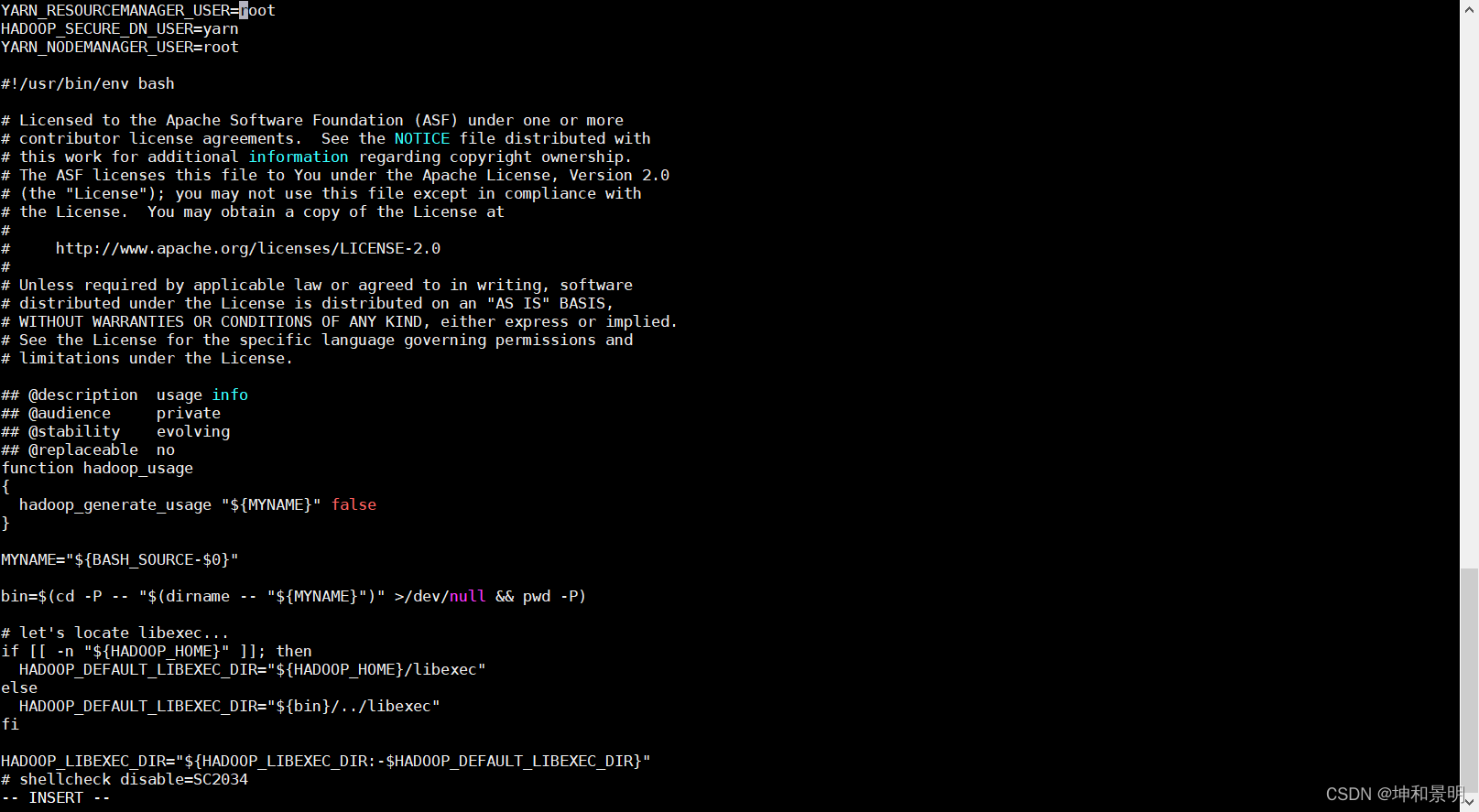
vi stop-yarn.sh
添加下面的代碼
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root 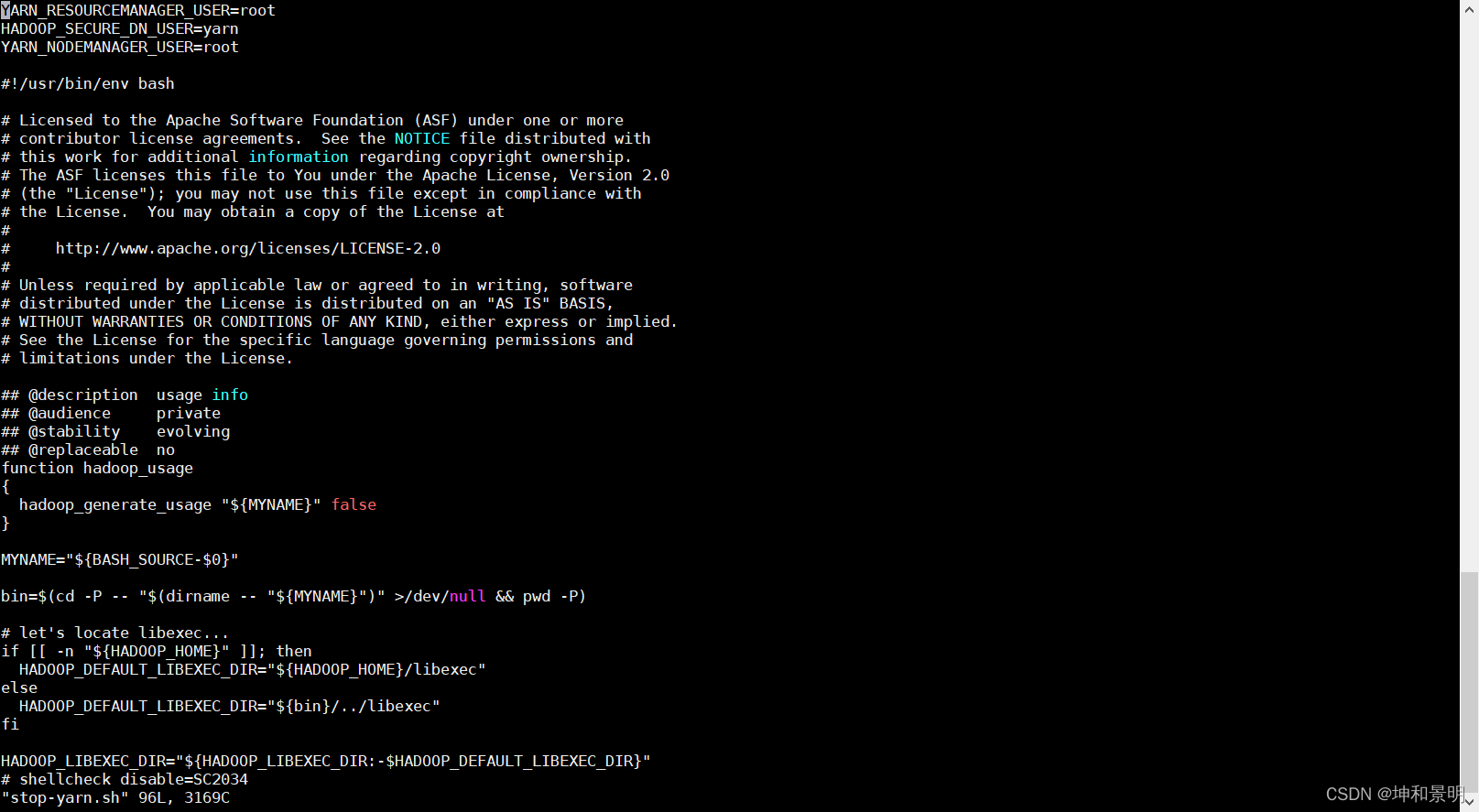
(2)在hadoop100上修改workers:
[root@hadoop100] cd /opt/module/hadoop-3.1.3/etc/hadoop
[root@hadoop100] vi workers
修改下面的
hadoop100
hadoop101
hadoop102
(3)把上面的修改同步到hadoop101、hadoop102上:
[root@hadoop100] scp - r /opt/module/hadoop-3.1.3/sbin/ hadoop101:/opt/module/hadoop-3.1.3/
[root@hadoop100] scp - r /opt/module/hadoop-3.1.3/sbin/ hadoop102:/opt/module/hadoop-3.1.3/
[root@hadoop100] scp - r /opt/module/hadoop-3.1.3/etc/hadoop/ hadoop101:/opt/module/hadoop-3.1.3/etc/
[root@hadoop100] scp - r /opt/module/hadoop-3.1.3/etc/hadoop/ hadoop102:/opt/module/hadoop-3.1.3/etc/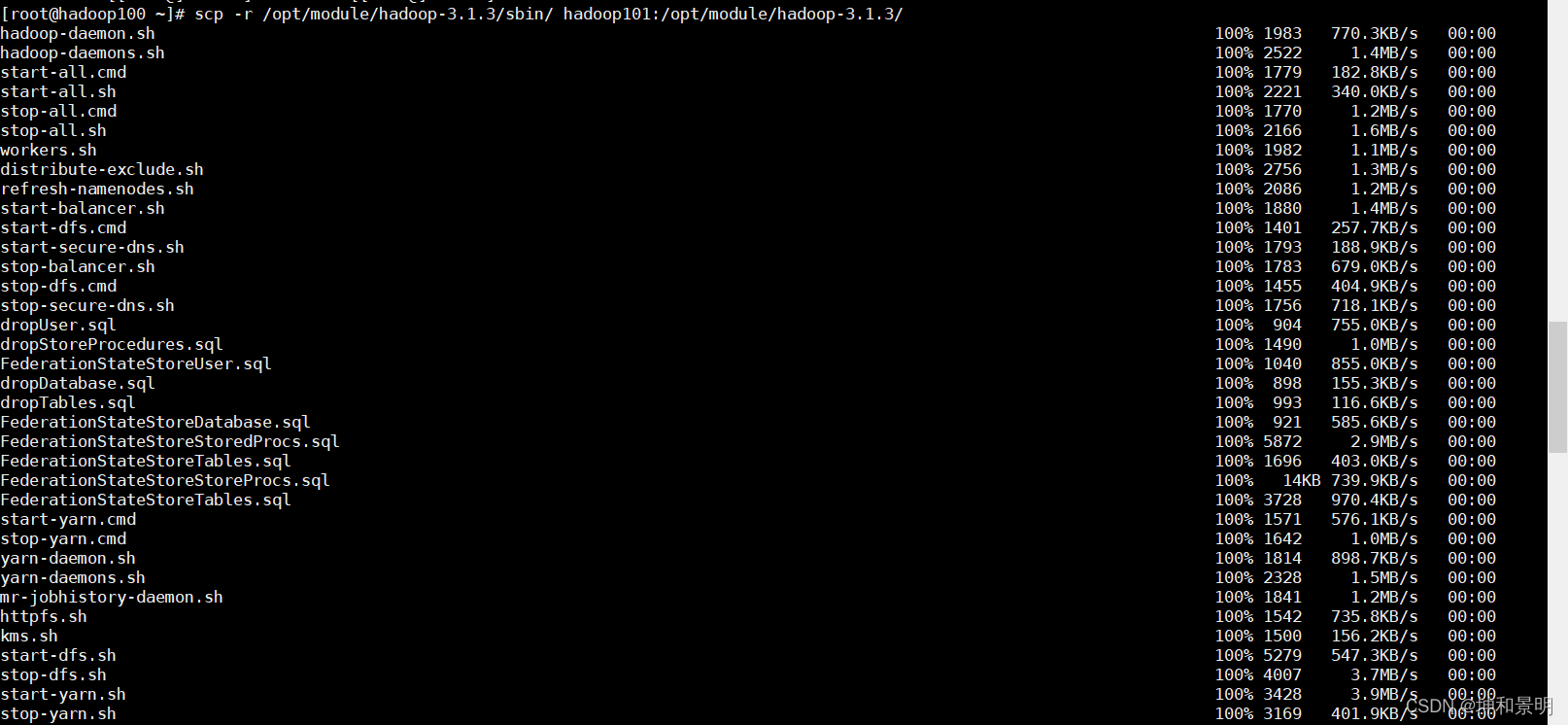
如上圖所示,輸入完代碼會進行拷貝覆寫
四、啟動停止集群
如果集群上已經啟動hadoop相關程式,可以先執行停止,
群起命令
hadoop100:
start-all.shhadoop101:
start-yarn.sh用jps查看一下
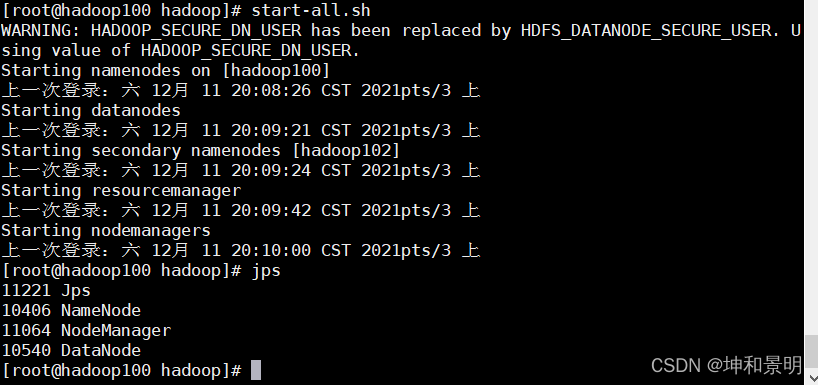
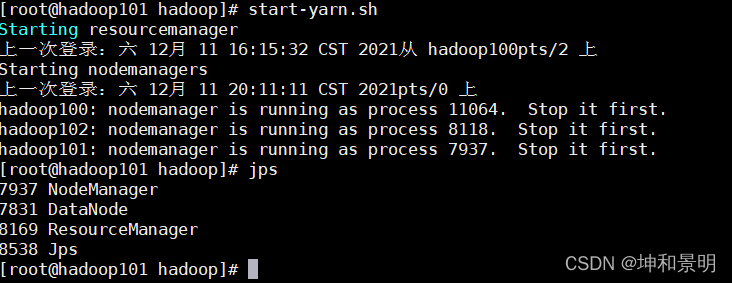
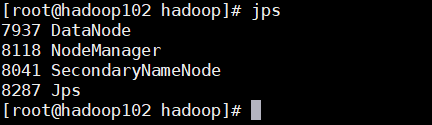
群停命令:
hadoop100:
stop-all.shhadoop101:
stop-yarn.sh轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379496.html
標籤:其他
上一篇:大資料之分布式資料庫HBase