有一個表格,其中包含 3 名員工和他們應該分別參加的 3-4 門課程的串列。我想為該表中的每個員工創建單獨的 PDF。第一個 PDF 將包含 Emp1 將學習的 3 門課程的串列,第二個 PDF 將包含 Emp2 將學習的 3 個課程的串列,依此類推。
以下代碼僅創建 1 個 PDF,并包含所有員工的所有課程串列。
我的想法是最初根據 EmpNo 對資料進行拆分/分組,然后創建單獨的 PDF,為此我需要創建一個 For 回圈進行迭代。但是,我無法弄清楚這一點......
資料幀代碼
pip install fpdf #To generate PDF
import pandas as pd
data = {'EmpNo': ['123','123','123','456','456', '456','456','789','789','789'],
'First Name': ['John', 'John', 'John', 'Jane', 'Jane', 'Jane', 'Jane', 'Danny', 'Danny', 'Danny'],
'Last Name': ['Doe', 'Doe' ,'Doe', 'Doe' ,'Doe', 'Doe', 'Doe', 'Roberts', 'Roberts', 'Roberts'],
'Activity Code': ['HR-CONF-1', 'HR-Field-NH-ONB','COEATT-2021','HR-HBK-CA-1','HR-WD-EMP','HR-LIST-1','HS-Guide-3','HR-WD-EMP','HR-LIST-1','HS-Guide-3'],
'RegistrationDate': ['11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021','11/22/2021', '11/22/2021', '11/22/2021','11/22/2021']}
df = pd.DataFrame(data = data, columns = ['EmpNo','First Name', 'Last Name', 'Activity Code', 'RegistrationDate'])
employees = data['EmpNo']
employees = data.drop_duplicates(subset=['EmpNo'])
print(df)
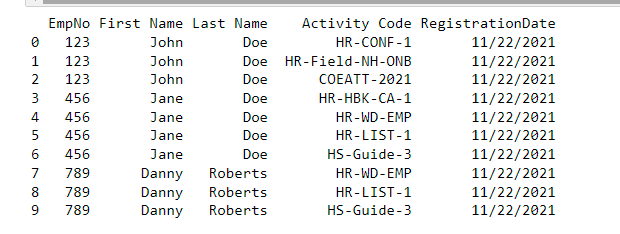
輸入看起來像這樣,
PDF生成代碼
from fpdf import FPDF
class PDF(FPDF):
def header(self):
# Arial bold 15
self.set_font('Helvetica', 'B', 15)
# Move to the right
self.cell(80)
# Title
self.cell(42, 2, 'Plan', 0, 0, 'C')
# Line break
self.ln(20)
# Page footer
def footer(self):
# Position at 1.5 cm from bottom
self.set_y(-15)
# Arial italic 8
self.set_font('Helvetica', 'I', 8)
# Page number
self.cell(0, 10, 'Page ' str(self.page_no()) '/{nb}', 0, 0, 'C')
# Footer image First is horizontal, second is vertical, third is size
for EmpNo in employees['EmpNo']:
print (EmpNo)
# Instantiation of inherited class
pdf = PDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Helvetica', '', 11)
pdf.cell(80, 6, 'Employee ID: ' str(data.loc[0]['EmpNo']), 0, 1, 'L')
pdf.ln(2.5)
pdf.multi_cell(160, 5, 'Dear ' str(data.loc[0]['First Name']) ' ' str(data.loc[0]['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', 'B', 13)
pdf.cell(80, 6, 'Name', 0, 0, 'L')
pdf.cell(40, 6, 'Date', 0, 0, 'L')
pdf.cell(40, 6, 'Link', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', '', 8)
for i in range (len(data)):
pdf.set_font('Helvetica', '', 8)
pdf.cell(80, 6, data.loc[0 i]['Activity Code'], 0, 0, 'L')
#pdf.cell(40, 6, data.loc[0 i]['Activity Link'], 0, 1, 'L')
pdf.cell(40, 6, data.loc[0 i]['RegistrationDate'], 0, 0, 'L')
pdf.set_font('Helvetica', 'U', 8)
pdf.cell(40, 6, 'Click Here', 0, 1, 'L', link = 'www.google.com')
pdf.set_font('Helvetica', 'B', 10)
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.cell(80, 6, 'IF YOU REQUIRE ANY HELP, PLEASE CONTACT US', 0, 0, 'L')
pdf.output(str(data.loc[0]['First Name']) ' ' str(data.loc[0]['Last Name']) '.pdf', 'F')
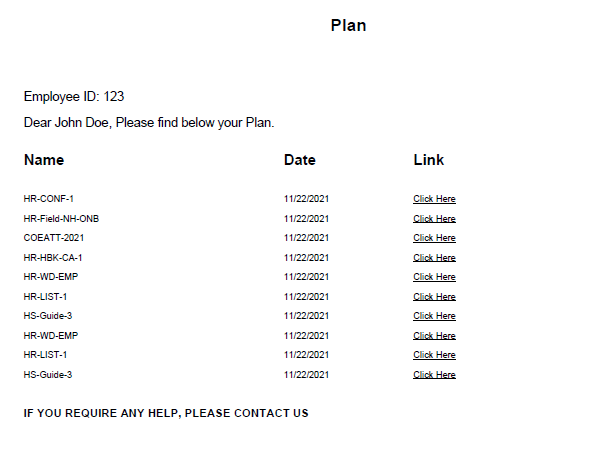
這是生成的 PDF 快照。
我可以使用下面的代碼拆分資料,但我堅持如何調出單獨的拆分,然后進一步創建多個 PDF
splits = list(data.groupby('EmpNo'))
任何幫助將不勝感激。謝謝。
uj5u.com熱心網友回復:
我會這樣寫 groupby:
for EmpNo, data in df.groupby("EmpNo"):
對于每個組,groupby 將回傳它分組的變數,以及與該變數匹配的資料幀。
接下來,我將提取該資料幀的第一行。這是為了更容易獲取名稱和類似屬性。
first_row = data.iloc[0]
(iloc 和 loc 有什么區別?)
由于我們已經有了員工 ID,我們可以跳過在資料框中查找它。對于其他屬性,我們可以像first_row['First Name'].
pdf.cell(80, 6, 'Employee ID: ' str(EmpNo), 0, 1, 'L')
# ...
pdf.multi_cell(160, 5, 'Dear ' str(first_row['First Name']) ' ' str(first_row['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
接下來,在這個回圈子集的回圈中,我將使用.iterrows()回圈而不是使用range()and .loc。如果您的資料幀的索引不是從零開始,這會更容易并且不會中斷。(分組后,第二組的索引將不再從零開始。)
這是更改后的最終源代碼:
import pandas as pd
data = {'EmpNo': ['123','123','123','456','456', '456','456','789','789','789'],
'First Name': ['John', 'John', 'John', 'Jane', 'Jane', 'Jane', 'Jane', 'Danny', 'Danny', 'Danny'],
'Last Name': ['Doe', 'Doe' ,'Doe', 'Doe' ,'Doe', 'Doe', 'Doe', 'Roberts', 'Roberts', 'Roberts'],
'Activity Code': ['HR-CONF-1', 'HR-Field-NH-ONB','COEATT-2021','HR-HBK-CA-1','HR-WD-EMP','HR-LIST-1','HS-Guide-3','HR-WD-EMP','HR-LIST-1','HS-Guide-3'],
'RegistrationDate': ['11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021', '11/22/2021','11/22/2021', '11/22/2021', '11/22/2021','11/22/2021']}
df = pd.DataFrame(data = data, columns = ['EmpNo','First Name', 'Last Name', 'Activity Code', 'RegistrationDate'])
from fpdf import FPDF
class PDF(FPDF):
def header(self):
# Arial bold 15
self.set_font('Helvetica', 'B', 15)
# Move to the right
self.cell(80)
# Title
self.cell(42, 2, 'Plan', 0, 0, 'C')
# Line break
self.ln(20)
# Page footer
def footer(self):
# Position at 1.5 cm from bottom
self.set_y(-15)
# Arial italic 8
self.set_font('Helvetica', 'I', 8)
# Page number
self.cell(0, 10, 'Page ' str(self.page_no()) '/{nb}', 0, 0, 'C')
# Footer image First is horizontal, second is vertical, third is size
for EmpNo, data in df.groupby("EmpNo"):
# Get first row of grouped dataframe
first_row = data.iloc[0]
# Instantiation of inherited class
pdf = PDF()
pdf.alias_nb_pages()
pdf.add_page()
pdf.set_font('Helvetica', '', 11)
pdf.cell(80, 6, 'Employee ID: ' str(EmpNo), 0, 1, 'L')
pdf.ln(2.5)
pdf.multi_cell(160, 5, 'Dear ' str(first_row['First Name']) ' ' str(first_row['Last Name']) ', Please find below your Plan.', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', 'B', 13)
pdf.cell(80, 6, 'Name', 0, 0, 'L')
pdf.cell(40, 6, 'Date', 0, 0, 'L')
pdf.cell(40, 6, 'Link', 0, 1, 'L')
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.set_font('Helvetica', '', 8)
for _, row in data.iterrows():
pdf.set_font('Helvetica', '', 8)
pdf.cell(80, 6, row['Activity Code'], 0, 0, 'L')
#pdf.cell(40, 6, row['Activity Link'], 0, 1, 'L')
pdf.cell(40, 6, row['RegistrationDate'], 0, 0, 'L')
pdf.set_font('Helvetica', 'U', 8)
pdf.cell(40, 6, 'Click Here', 0, 1, 'L', link = 'www.google.com')
pdf.set_font('Helvetica', 'B', 10)
pdf.cell(80, 6, '', 0, 1, 'C')
pdf.cell(80, 6, 'IF YOU REQUIRE ANY HELP, PLEASE CONTACT US', 0, 0, 'L')
pdf.output(str(first_row['First Name']) ' ' str(first_row['Last Name']) '.pdf', 'F')
經測驗,有效。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/381142.html