Intro
本文是筆者對DeepSORT演算法學習的階段性總結,基于筆者接觸到的所有開源學習資料,輔以個人理解進行重新編排而成,力求清晰,使非專業的讀者也能迅速對該演算法原理有較為透徹的理解,便于后續代碼學習,
筆者本人為非cs相關專業,論述不當之處歡迎指出,文中參考的博客均已在第0章中列出,在此致謝,如涉侵權敬請作者聯系筆者洗掉,
0、參考博客
0.1 整體演算法
博客1,MOT綜述、演算法流程,強烈推薦:https://zhuanlan.zhihu.com/p/97449724
博客2,帶使用的函式的演算法流程:https://zhuanlan.zhihu.com/p/80764724
博客3,原始碼講解:https://zhuanlan.zhihu.com/p/90835266
博客4,流程圖:人臉跟蹤:deepsort代碼解讀_BigCowPeking-CSDN博客_deepsort原始碼
0.2 卡爾曼濾波
博客1:推薦您從一個小故事開始:如何通俗并盡可能詳細地解釋卡爾曼濾波? - 知乎
博客2:幾個視頻值得一看:如何通俗并盡可能詳細地解釋卡爾曼濾波? - 知乎
博客3:某位活菩薩翻譯的外網博文:如何通俗并盡可能詳細地解釋卡爾曼濾波? - 知乎
1、多目標跟蹤(MOT)綜述
1.1 目標跟蹤的任務分類
目標跟蹤(Object Tracking)是計算機視覺領域的重要問題,按任務型別劃分有如下幾類,對于做交叉學科研究接觸到這一領域的外行而言,最重要的是先搞明白自己的課題需求歸屬哪種任務場景,筆者的課題任務為MOT任務,
單目標跟蹤(VOT/SOT):給定一個目標,追蹤這個目標的位置,
多目標跟蹤(Multiple Object Tracking,MOT):追蹤多個目標的位置,
行人重識別(Person Re-ID):行人重識別是利用計算機視覺技術判斷影像或者視頻序列中是否存在特定行人的技術,廣泛被認為是一個影像檢索的子問題,即給定一個監控行人影像,檢索跨設備下的該行人影像,旨在彌補固定的攝像頭的視覺局限,并可與行人檢測/行人跟蹤技術相結合,
MTMCT:多目標多攝像頭跟蹤(Multi-target Multi-camera Tracking),跟蹤多個攝像頭拍攝的多個人,
姿態跟蹤:追蹤人的姿態,
以下是MOT任務與其他相關任務的區分:
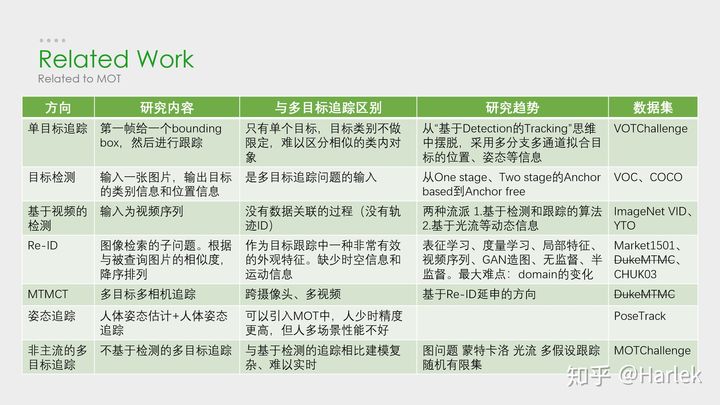
1.2 MOT任務的解決方案及實作
MOT任務常見的解決方案主要有兩種,即MFT 和 TBD,簡介如下:
MFT:需要手動在初始幀中選擇感興趣區域,然后演算法在第二幀開始的其余幀追蹤這個目標,
TBD:基于檢測的目標跟蹤,是目標檢測的后續任務,由于目標跟蹤近幾年的發展,成為常用方法,我們的DeepSORT也屬于這類方法,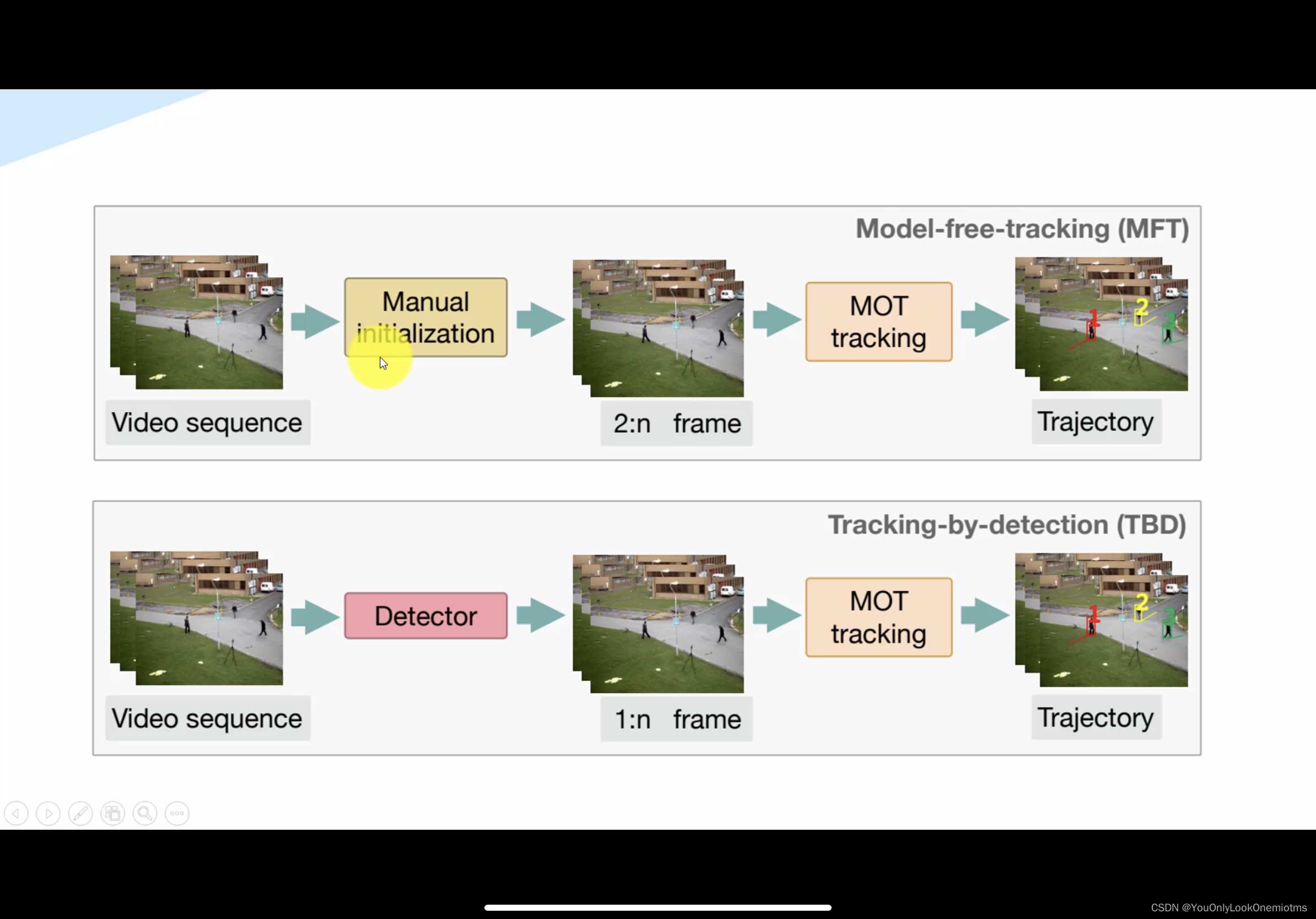
一般Tracking by Detection的實作主要分為如下步驟:
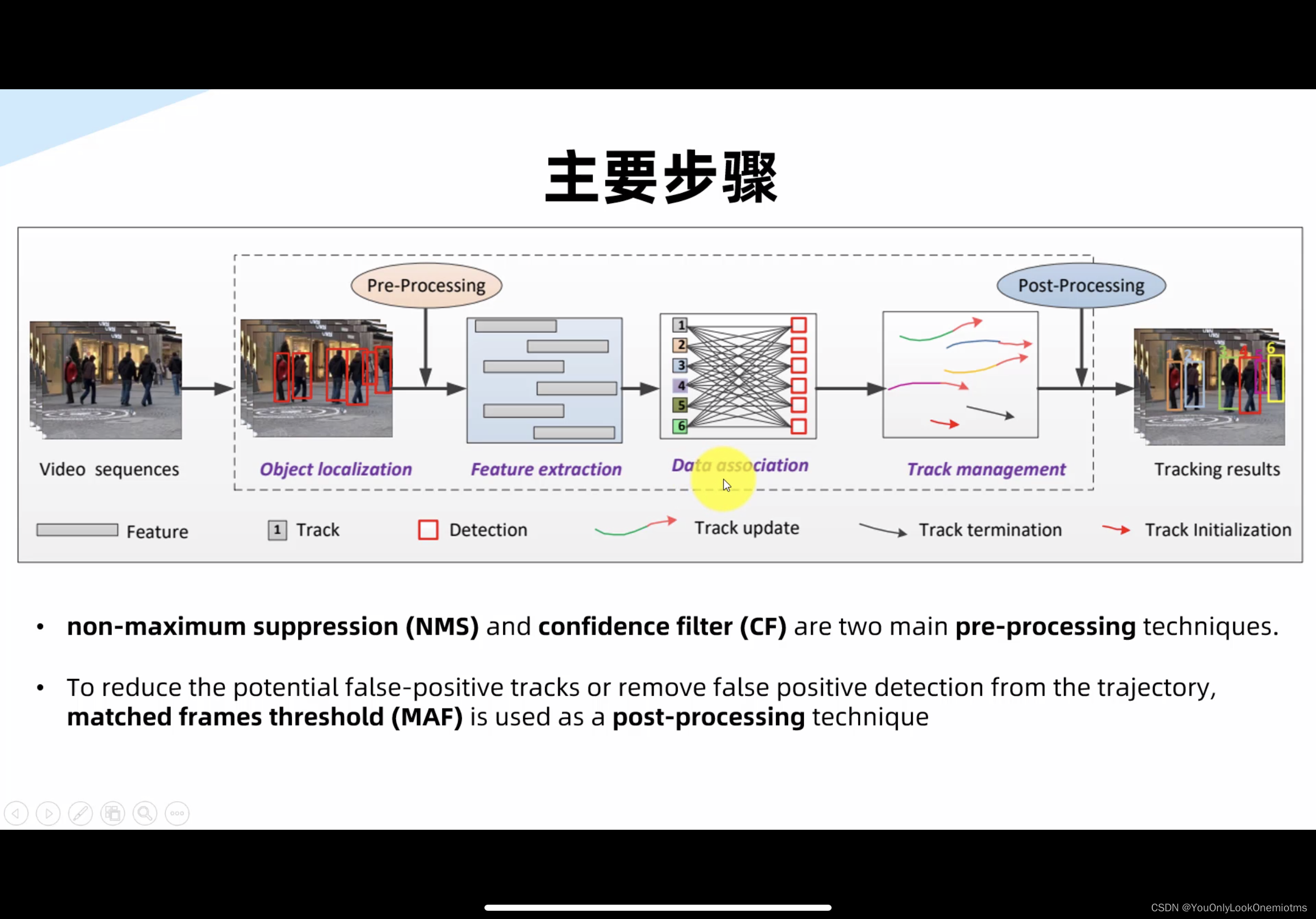
Object Localization:即Detection,在DeepSORT語境下,這一步相當于卡爾曼濾波的傳感器,
Preprocessing:前處理,有NMS和置信度閾值兩種(即拋棄confidence小于閾值的detection)
Feature Extraction:特征提取,在DeepSORT語境下,這部分是Re-ID模型對外觀特征的提取,
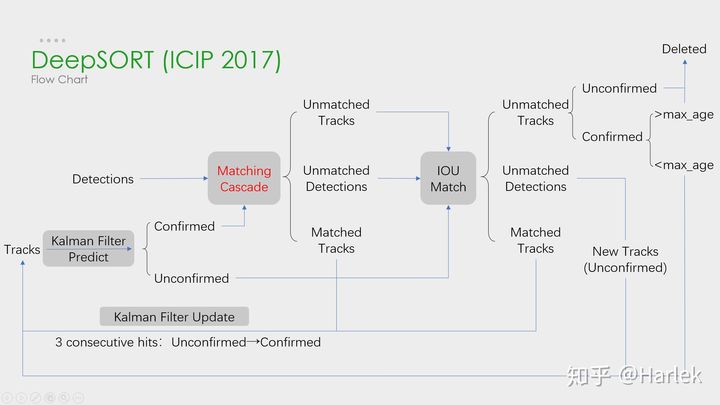
Data Association:這一步是資料關聯,在DeepSORT語境下,即對當前第k幀的detection和卡爾曼濾波中predict階段根據前一幀k-1幀生成的track prediction匹配,在DeepSORT中是級聯匹配和IOU匹配,
Track Management:包括卡爾曼濾波中的 track update,和對track的初始化、洗掉
Postprocessing: 后處理,
1、SORT 與DeepSORT
這一步建議讀者先找到這兩個演算法的論文看,對這兩個演算法有個大概了解,一個簡單的目標:讀完至少知道這兩篇論文各哪有幾個小節(精確到二級標題),主要部件是哪些,
SORT和DeepSORT的優點特征是實作速度和準確性的tradeoff,因而倍受工業界青睞,本節接下來會給出這兩個演算法的關鍵流程圖,讀者看不懂也沒有關系,看看關鍵部件如何組織即可,
1.1 SORT(Simple Online Realtime Tracking)
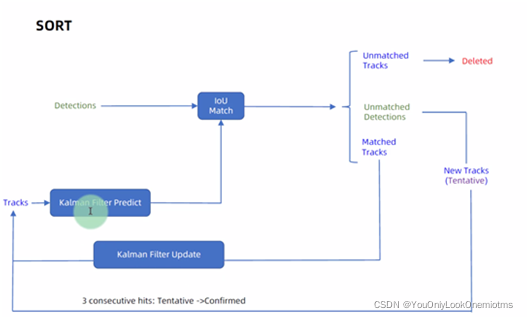
SORT是一個粗略的框架,核心就是兩個演算法:卡爾曼濾波和匈牙利匹配,
卡爾曼濾波:在圖中被分為兩個程序:預測和更新,預測程序:當一個小車經過移動后,且其初始定位和移動程序都是高斯分布時,則最終估計位置分布會更分散,即更不準確;更新程序:當一個小車經過傳感器(也就是我們的Detections)觀測定位,且其初始定位和觀測都是高斯分布時,則觀測后的位置分布會更集中,即更準確,但是由于我們得到的是一堆Track和一堆Detection,因此只有在用匈牙利演算法進行分配后,才能把Track按照對應的Detection結果更新,
匈牙利演算法:解決的是一個二分圖分配問題(Assignment Problem),即如何分配使成本最小,在上圖中是IOU Match那里,即基于IOU距離構造的成本矩陣對Detection和Track作匹配,SK-learn庫的linear_assignment_和scipy庫的linear_sum_assignment都實作了這一演算法,只需要輸入cost_matrix即代價矩陣就能得到最優匹配,不過要注意的是這兩個庫函式雖然演算法一樣,但給的輸出格式不同,具體演算法步驟也很簡單,是一個復雜度 的演算法,
SORT的問題:ID-switch很高,即同一個人的ID會變化,這主要是由于該演算法論文3.4節中的一幀不匹配洗掉機制及IOU 成本矩陣的問題,
1.2 DeepSORT
主要特點:
1、加入外觀資訊,借用了ReID領域模型來提取外觀特征(即標題中的Deep Association Metric),減少了ID switch的次數,
2、匹配機制從原來的基于IOU成本矩陣的匹配變成了級聯匹配+IOU匹配(技術細節將在后續章節中講解),
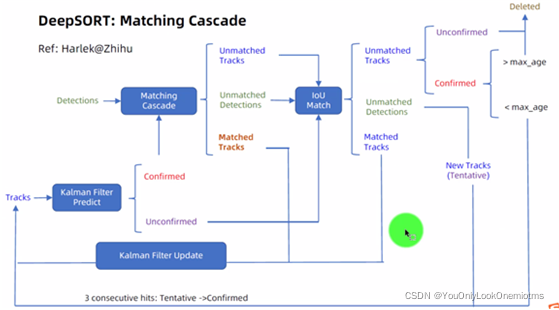
2、卡爾曼濾波
2.1 Genreal Glimpse:
定義:利用線性系統狀態方程,通過系統輸入輸出觀測資料,對系統狀態進行最優估計的演算法,由于觀測資料中包括系統中的噪聲和干擾的影響,所以這一最優估計也可看作是濾波程序,
輸入->程序->輸出:
輸入:為k-1時刻的狀態向量(nx1)和協方差矩陣(nxn);
程序:分predict和update兩部分,predict基于先驗的model(狀態轉移資訊),如小車運動方程等,從k-1時刻根據model predict k時刻的狀態和協方差;update是基于當下k時刻傳感器(觀測資訊),對prediction進行更新,
輸出:為k時刻的狀態向量(nx1)和協方差矩陣(nxn)
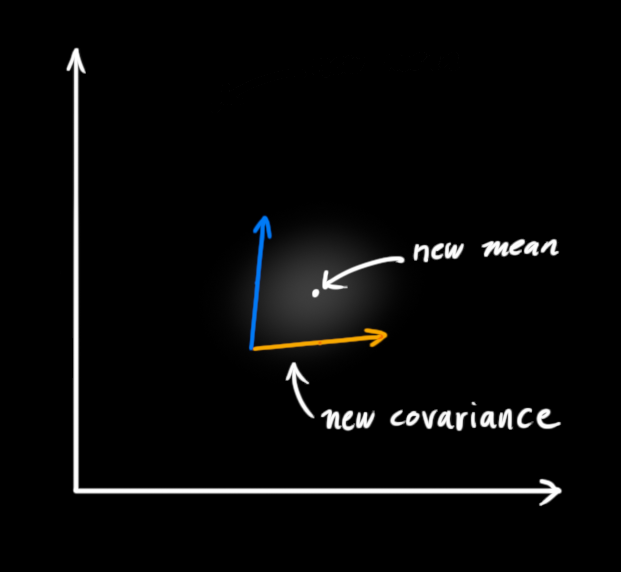
本質:Predict得到k時刻狀態的一個高斯分布(一個高斯斑),觀測得到k時刻狀態的另一個高斯分布(另一個高斯斑),因為無論傳感器的觀測還是模型的預測都會存在噪聲,因此卡爾曼濾波器就是融合這兩種資訊,方法是將兩個分布相乘,得到一個新的高斯斑,如下所示:
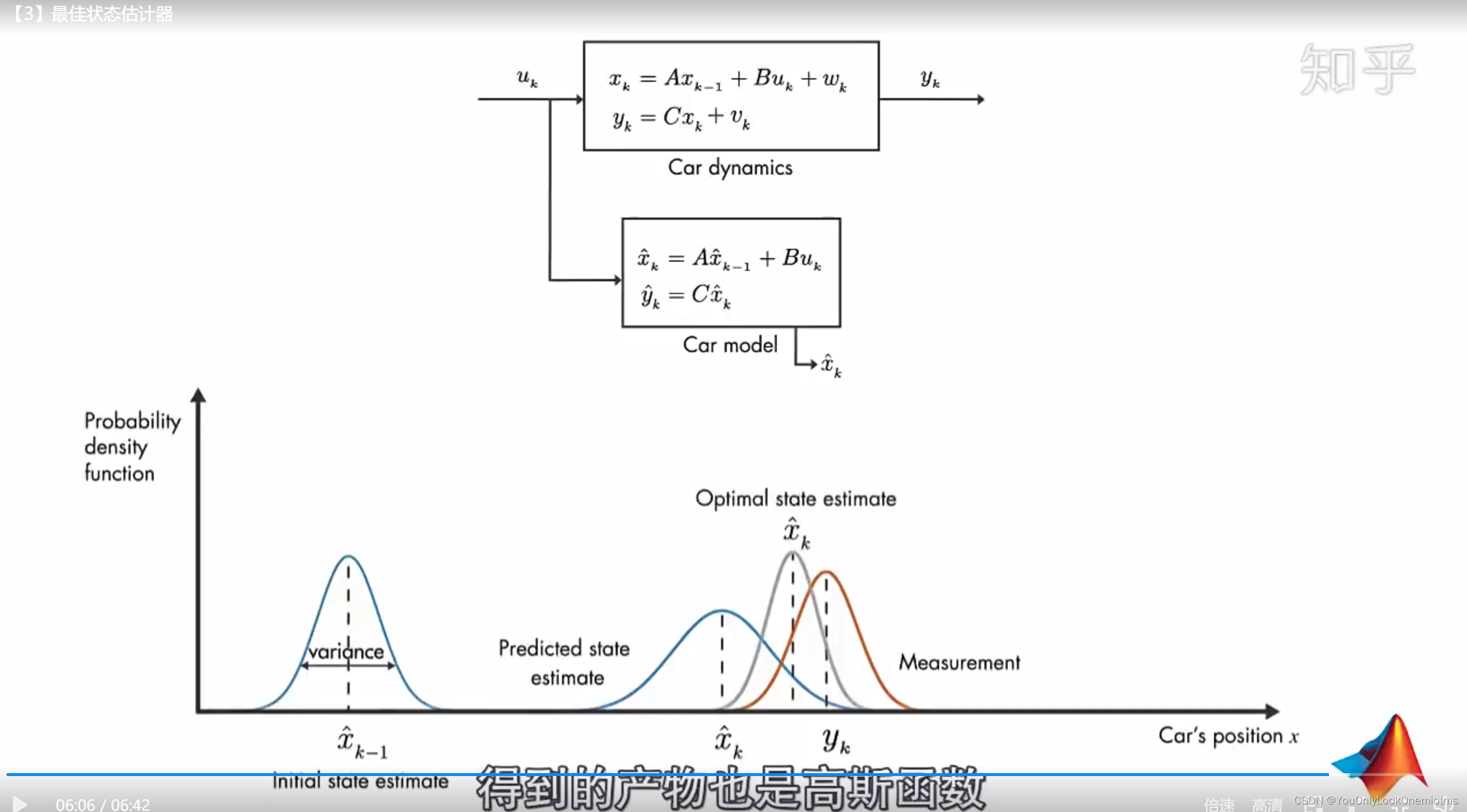
2.2 定性不定量地,illustration by an example
2.2.1 初始狀態分布(高斯斑)
如下所示,以一輛小車的二維狀態【位置,速度】為例,其某一時刻的狀態分布(高斯斑)也許會長下圖這樣,
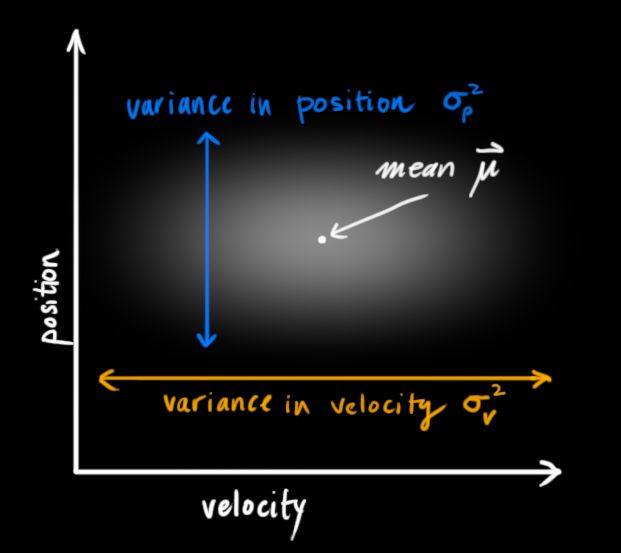
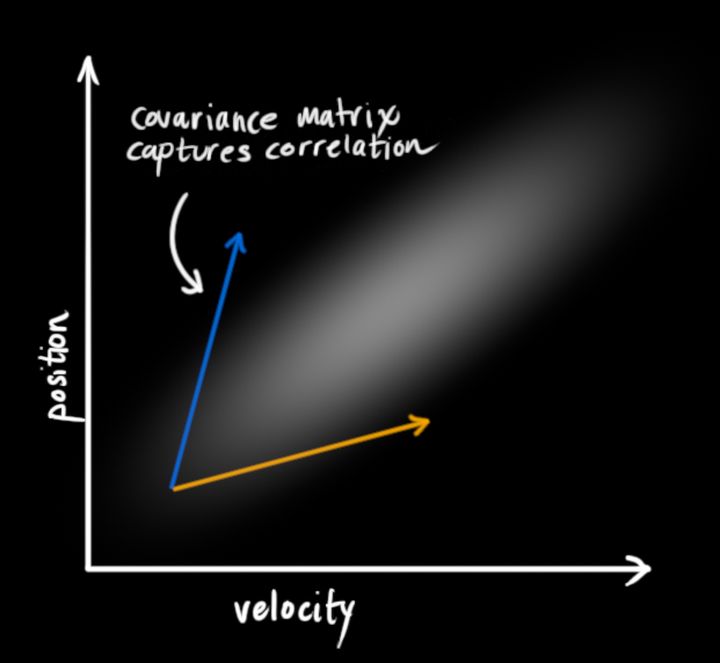
協方差描述了離散性,當狀態量之間有所關聯(如速度和位置分布其實是有關聯的),高斯斑會長這樣:
2.2.12 預測(Predict)
在知道了k-1時刻的狀態分布(狀態分布自然包含狀態和協方差,即“分布”)之后,基于model給出的狀態轉移我們可以預測k時刻的
:
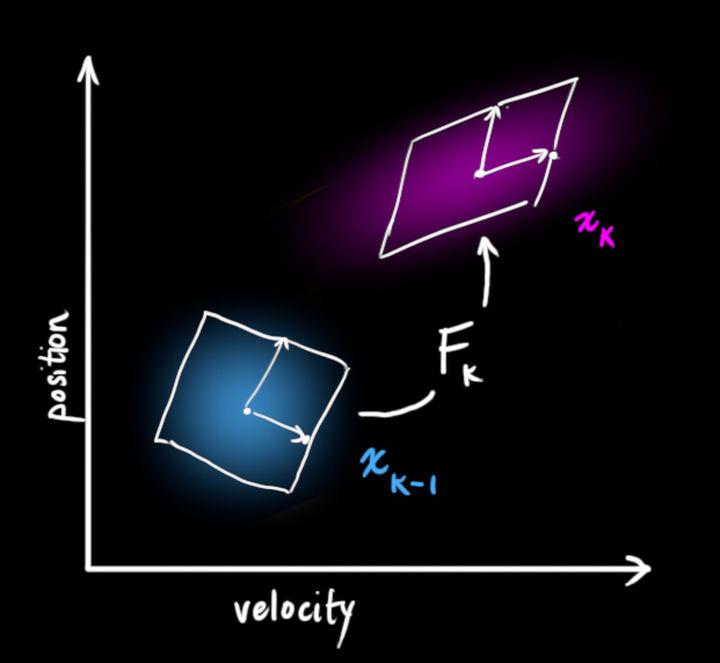
考慮外力作用下,基于牛頓力學(model)我們就可以得到如下的狀態轉移:
寫成矩陣形式即:
以上為狀態轉移矩陣,
為控制矩陣,
為控制向量,特別注意的是我們這里狀態向量只有兩維,因此控制矩陣
退化為向量,控制向量
退化為標量,
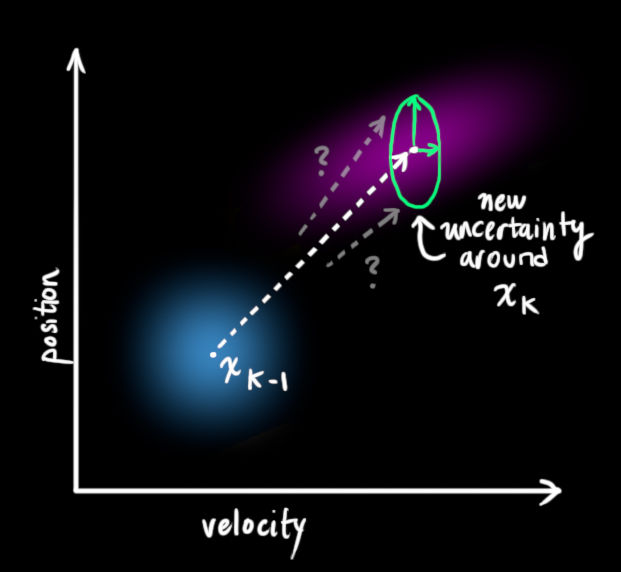
以上即基于model的predict的確定性部分,很多時候這種predict是有噪聲的,如一陣風吹過,小車經過下坡……都沒用在model里考慮,如下圖所示,原始狀態中的每一個點可以都會預測轉換到一個范圍,而不是某個確定的點,所有的點經過轉移后,構成的新分布協方差是放大的,假設分布里的每個點移動到一個符合方差
的新非高斯分布中:
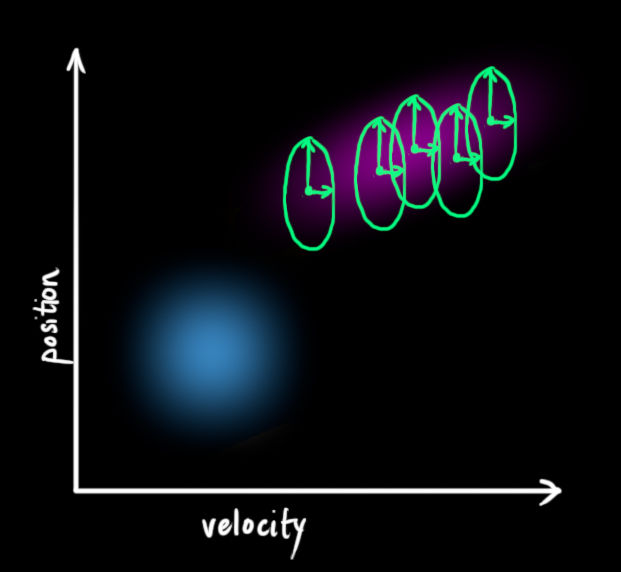
所有點:
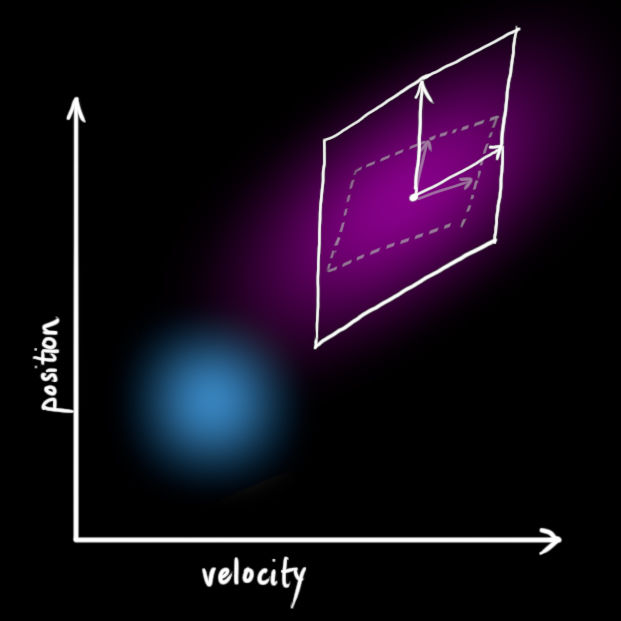
因此考慮噪聲之后,發散了:
因此,把predict中的不確定性假設為符合高斯分布的噪聲,我們得到predict的最終結果即prediction:
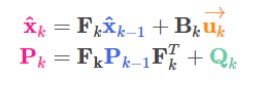
2.2.3 Update by Sensor
引入傳感器,我們有k時刻的讀數,有以下兩個問題:
1、傳感器測量的可能并非我們要的那幾個狀態量,
2、傳感器有一定誤差,
針對第一點,例如,在DeepSORT中,Detection無法回傳速度相關量,因此引入測量矩陣Hk,將觀測向量映射到狀態向量,這樣我們就可以從傳感器觀測值得到對應的狀態值,
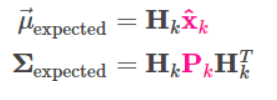
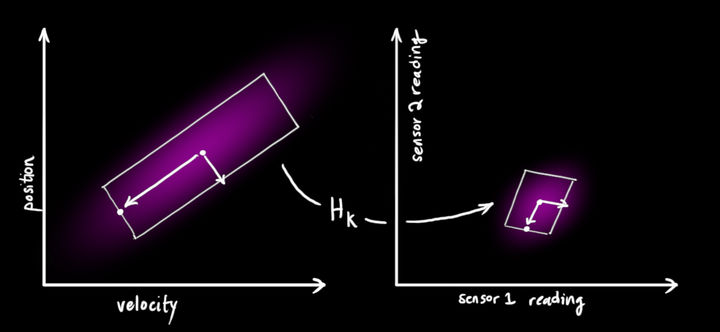
針對第二點引入傳感器的讀數方差和讀數均值
,傳感器的讀數分布如下所示
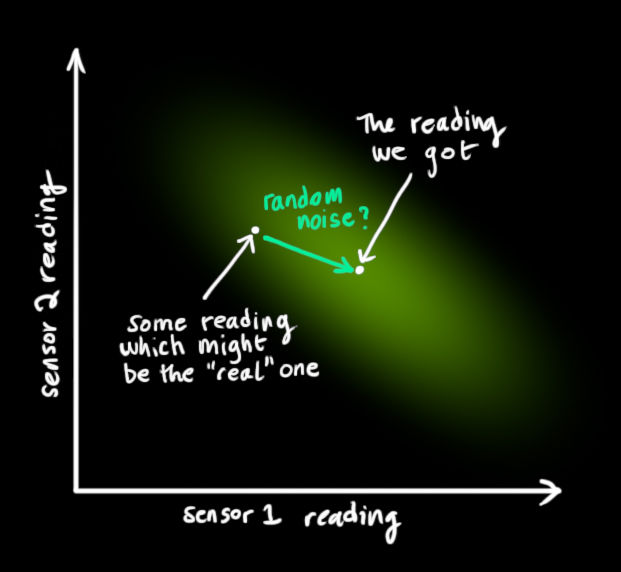
所以現在我們有了兩個高斯斑,一個來自于我們預測值,另一個來自于我們測量值,我們必須嘗試去把兩者的資料預測值(粉色)與觀測值(綠色)融合起來,所以我們得到的新的資料會長什么樣子呢?對于任何狀態我們有兩個可能性:
(1)傳感器讀數更接近系統真實狀態
(2)預測值更接近系統真實狀態,
如果我們有兩個相互獨立的獲取系統狀態的方式,并且我們想知道兩者都準確的概率值,我們只需要將兩者相乘,所以我們將兩個高斯斑相乘,得到新的高斯斑:
2.3 計算公式
一般的卡爾曼濾波分為predict和update
predict
這一步給出的是預測值,也稱先驗狀態估計值(a prior state estimate);
update
這一步給出的是狀態的最優估計值,也稱后驗狀態估計值(a posteriori state estimate)
以上K稱為卡爾曼增益,是預測噪聲和測量噪聲的比較,詳細見下面鏈接給出的推導,
kalman filter的詳細推導程序參考:卡爾曼濾波(Kalman Filter)原理與公式推導 - 知乎,但其中有一些小錯誤,
在deepsort代碼實作中也可以把上面三條公式寫成下面的五條:
- 在上面的(1)中,z為detection的均值向量,不包含速度變化值,即z =[𝒄𝒚,𝒄𝒛,𝒓,𝒉],𝑯稱為測量矩陣,它將track的均值向量
映射到測量空間,該公式計算detection和track的均值誤差,y稱為innovation (新息),
- 在(2)中,R為檢測器的噪聲矩陣,它是一個4x4的對角矩陣,對角線上的值分別為中心點兩個坐標以及寬高的噪聲,以任意值初始化,該公式先將協方差矩陣P映射到測量空間,然后再加上噪聲矩陣R,
- (3) 計算卡爾曼增益𝑲,卡爾曼增益用于估計誤差的重要程度,
- (4)和(5)得到更新后的均值向量
和協方差矩陣P',
3、 匈牙利演算法
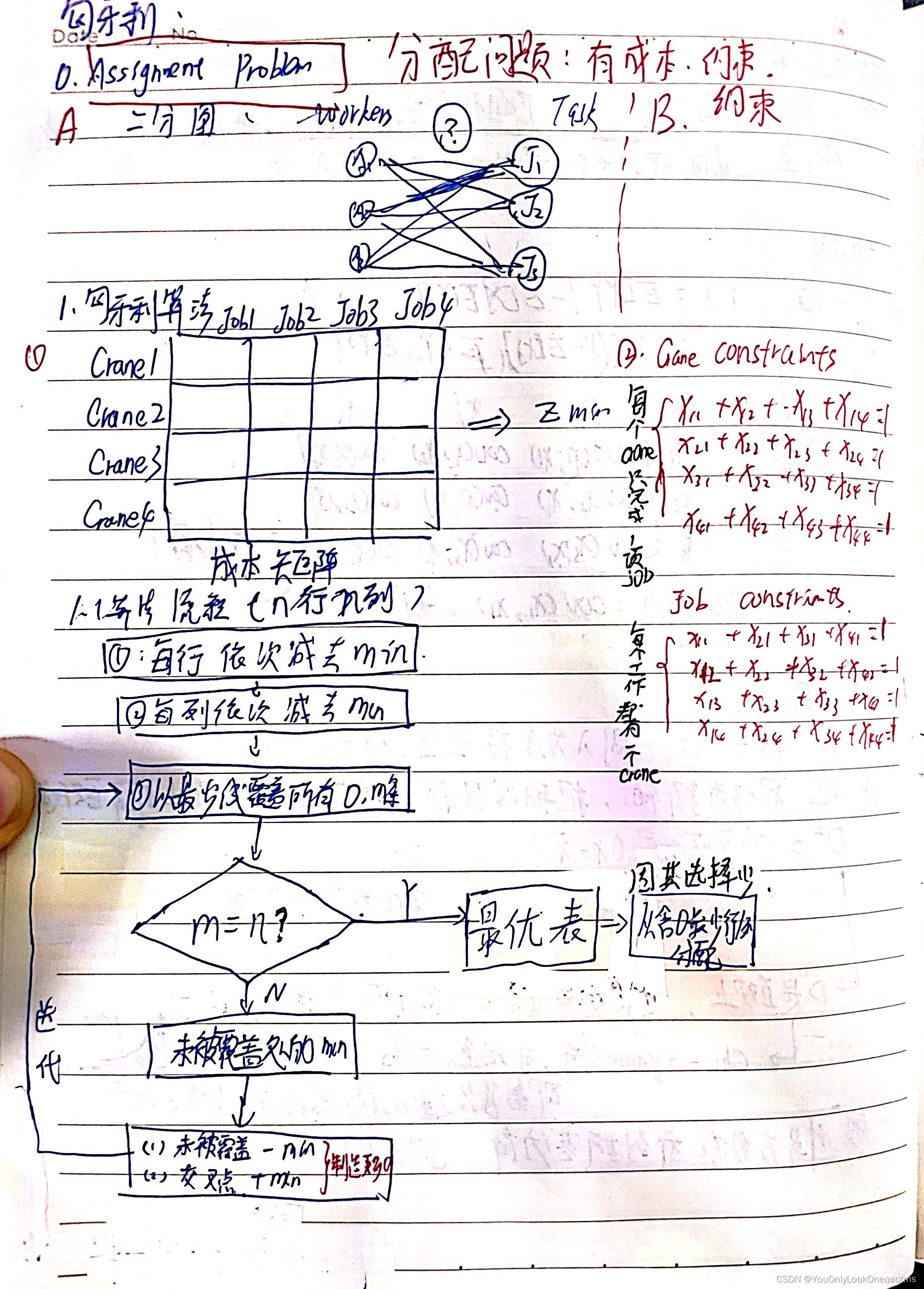
匈牙利演算法是用來解決二分圖中的最優分配問題(Assignment Problem)的,像下圖所示的給四個起重機分配四個任務就是典型的分配問題,有兩類要素:
1、左邊的表格是成本矩陣;
2、右邊是約束,如圖中所示,一個起重機只能做一個job,一個job只能一個起重機來做,

匈牙利演算法在代碼中很容易通過呼叫函式實作,這里不加解釋地給出主要流程圖,SK-learn庫的linear_assignment_和scipy庫的linear_sum_assignment都實作了這一演算法,只需要輸入cost_matrix即代價矩陣就能得到最優匹配,不過要注意的是這兩個庫函式雖然演算法一樣,但給的輸出格式不同,
4、DeepSORT演算法流程及其關鍵組件
再次給出DeepSORT的演算法流程
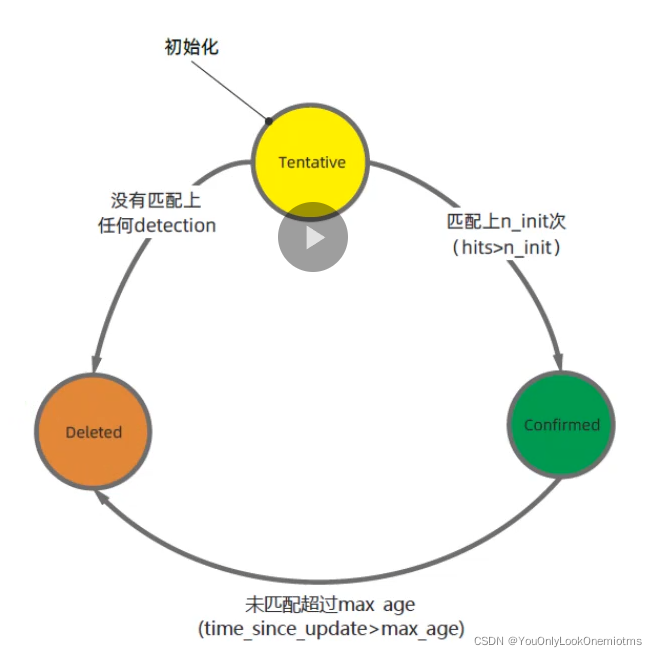
4.1 Track的不同狀態
如下所示,是track的三個狀態,文中兩個閾值取的是n_init=3,Amax=30.
4.2 級聯匹配
目的:長時間遮擋中,卡爾曼濾波的prediction會發散,不確定性增加,而這樣不確定性強的track的馬氏距離反而更容易競爭到detection匹配,因此,需要按照遮擋時間n從小到大給track分配匹配的優先級,基于匈牙利演算法,
輸入為:
1、基于第k-1幀由卡爾曼濾波predict到的當前第k幀所有confirmed狀態的track;
2、當前第k幀的所有detection
輸出為:
1、match上的detection、track;
2、沒有match上的track;
3、沒有match上的detection,
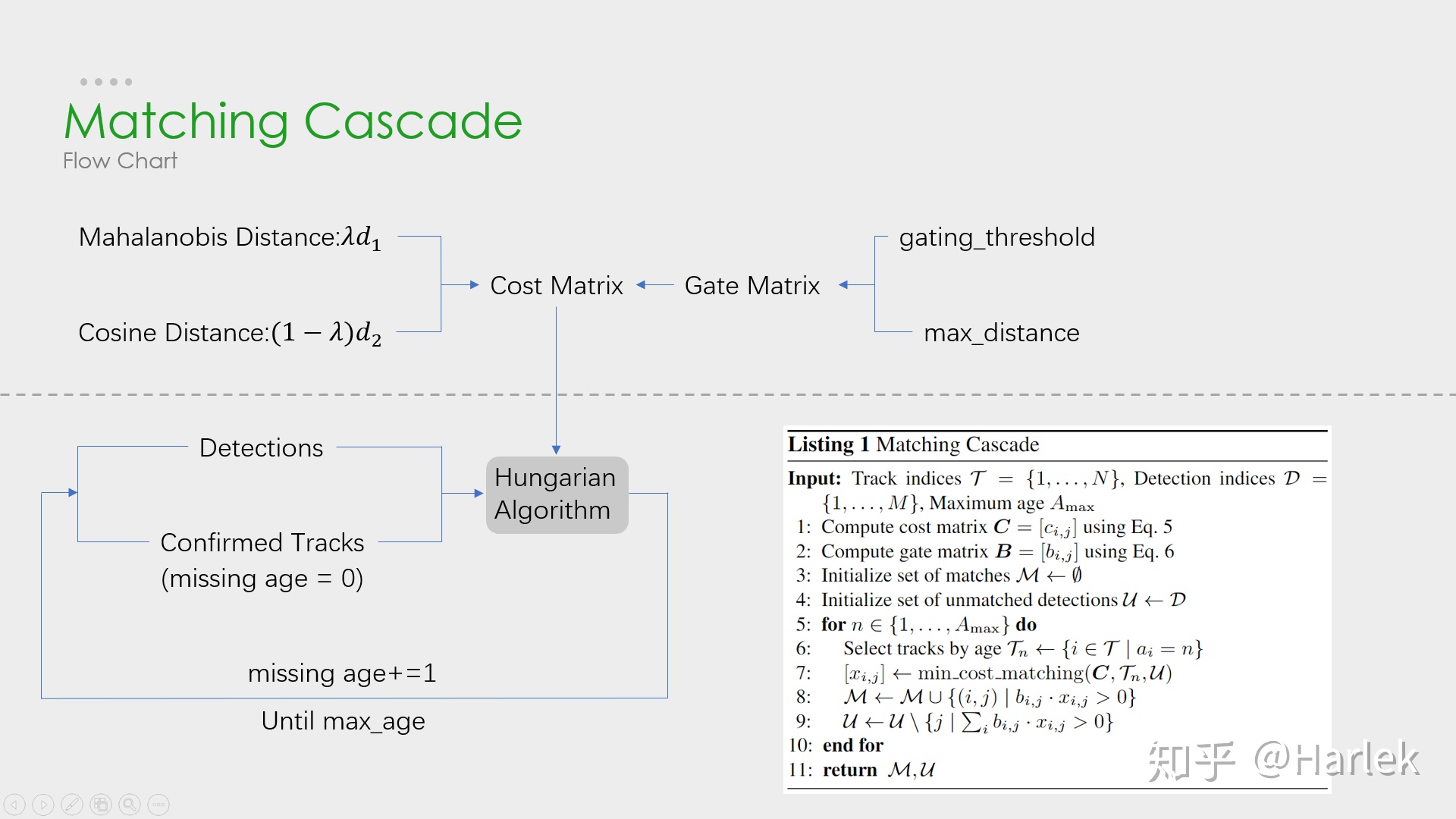
Listing 1講解:
#input:基于第k-1幀由卡爾曼濾波predict到的當前第k幀所有confirmed狀態的track索引T={1,...,N},當前第k幀所有detections D={1,...,M},最大未匹配幀數Amax=30
1.用外觀最小余弦距離和馬氏距離計算成本矩陣C(實操中lambda=0,只會用到外觀最小余弦距離)
2.用外觀最小余弦距離和馬氏距離計算閾值矩陣B,用來濾掉不可能的匹配
3.用空集初始化match上的集合M
4.用D來初始化unmatch集合U
5. for n 屬于 {1,...,Amax} : #n是每個track未匹配幀數
6. 從T中挑出一個子集Tn,即那些未匹配幀數=n的track的索引
7. 用匈牙利演算法 對上一步選出的子集Tn和D進行匹配
8. 向M中添加匹配的序列號對(i,j),確保這個匹配滿足閾值矩陣B(即bij=1)
9. 從未匹配索引集合U中刪去匹配的序列號對(i,j)的j,確保這個匹配滿足閾值矩陣B(即bij=1)
10. end
11. return M,U級聯匹配流程圖里上半部分就是特征提取和相似度估計,也就是算這個分配問題的代價函式,主要由兩部分組成:代表運動模型的馬氏距離和代表外觀模型的Re-ID特征,
級聯匹配流程圖里下半部分匈牙利演算法資料關聯作為流程的主體,為什么叫級聯匹配,主要是它的匹配程序是一個回圈,從missing age=0的軌跡(即每一幀都匹配上,沒有丟失過的)到missing age=30的軌跡(即丟失軌跡的最大時間30幀)挨個的和檢測結果進行匹配,也就是說,對于沒有丟失過的軌跡賦予優先匹配的權利,而丟失的最久的軌跡最后匹配,
論文關于引數λ(運動模型的代價占比)的取值是這么說的:
在我們的實驗中,我們發現當相機運動明顯時,將λ= 0設定是一個合理的選擇,
因為相機抖動明顯,卡爾曼預測所基于的勻速運動模型并不work,所以馬氏距離其實并沒有什么作用,但注意也不是完全沒用了,主要是通過閾值矩陣(Gate Matrix)對代價矩陣(Cost Matrix)做了一次閾值限制,
4.3 IOU匹配
IOU匹配是在級聯匹配之后做的東西,從SORT中繼承而來,用來解決突然的外觀變換導致級聯匹配難以match的情況,如部分遮擋等,也是基于匈牙利演算法做的,
輸入:
1、candidate track,包括:
1.1 級聯匹配中剩下的unmatched,n=1的track;
1.2 基于第k-1幀由卡爾曼濾波predict到的當前第k幀所有unconfirmed狀態(即tenative)的track;
2、級聯匹配中剩下的unmatched detection
輸出:
1、match上的detection、track;
2、沒有match上的track;
3、沒有match上的detection,
然后進行更新處理,包括:
1、卡爾曼濾波 update track在第k幀狀態的均值和方差
2、是否有track需要轉為confirmed(到本幀match上且已連續命中3幀)
3、是否有要洗掉的track,即n>Amax
4、對unmatched detections分配新的track ID,為unconfirmed態即tenative態,
三者關系如下:
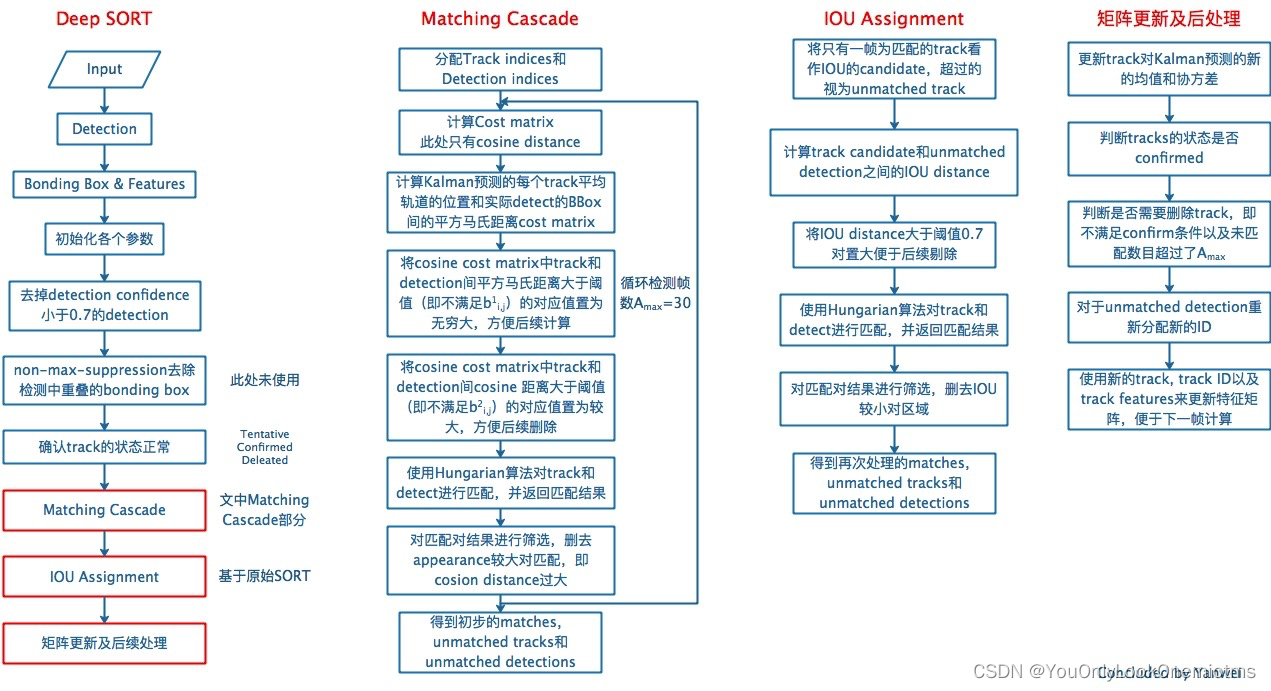
至此,關于DeepSORT的講解基本結束,還有馬氏距離、Re-ID模型等概念未加介紹,將后續更新附上,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/382132.html
標籤:其他
上一篇:繼電器命令命令引數