這是我的課程論文,寫的時候發現針對性的內容很少,因此寫完后放出來供大家參考,水平欠佳,勞煩賜教,
公式原來是用 latex 敲的,因為有些語法是擴展的,懶得再和 markdown 折騰了
面向深度學習的快取替換演算法
摘要:本文針對深度學習的落地痛點進行了分析并提出通過改善高速快取替換演算法的方式來提升深度學習的落地能力,具體而言,我們從降低能耗、存盤介質材料、降低演算法實作難度、綜合考慮各級存盤、結合機器(深度)學習等方面都進行了詳細的分析并給出了幾種可行的改進思路,
關鍵字:快取;替換演算法;深度學習;機器學習
1. 引言
今天的人工智能可以取得如此輝煌的進步,很大程度上要歸功于深度學習的蓬勃發展,雖然近幾年來深度學習在影像識別、語音處理、機器翻譯、智慧城市等領域都取得了一些落地成果,但無比龐大的計算量仍然是深度學習難以得到廣泛推廣應用的痛點之一,
在高性能計算機系統中,記憶體性能往往是最為關鍵的問題之一,其中對高速快取的改進更是提升記憶體性能最簡單、最經濟有效的方法[1],幸運的是,訓練深度學習模型的程序體現了非常強的空間區域性和時間區域性(如對計算機視覺領域的卷積神經網路而言,當核遍歷到某個位置時,核周圍的資料緊接著就會被訪問;自然語言處理領域廣泛使用的自注意力機制、長短期網路等都會綜合考慮以往訪問過的資料),這使得我們可以針對性地對現有的快取替換演算法進行改進,從而有效提高深度學習的落地能力,
2. 降低能耗
2.1 背景
20 年前,一個僅提供資料存盤和內容分發的資料中心的電力需求就能以每年 100W/ft2 的速度增長,對應的能源成本幾乎以每年 25% 的速率增長[2],對現代存盤體系結構(圖 2.1.1)的資料中心而言,存盤器幾乎是最大的能源消耗,各種開銷大約占據了總能源消耗量的 27%[3],
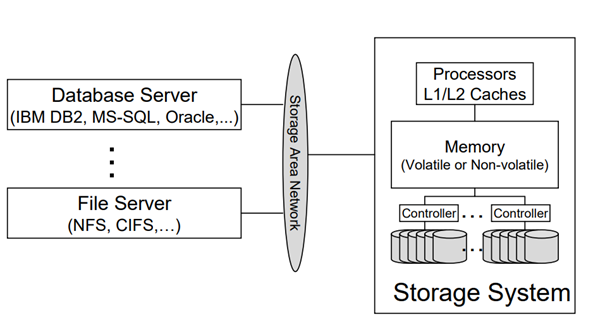
圖 2.1.1 現代存盤體系結構
20 年后深度學習蓬勃發展,各類大資料應用層出不窮的今天,存盤器市場的需求每年還保持著不低于 60% 的攀升比例[4],近幾年 Google、Microsoft、Nvidia、阿里巴巴、騰訊等互聯網公司在深度學習、大資料等領域掀起了一股超巨大模型的風氣,僅 2017 年 Google 提出 Transformer 模型到 2021 年短短的 4 年間,深度學習模型的引數大小已經斷崖式上漲到了 10 萬億(2021 年 11 月阿里巴巴達摩院以分布式的方式使用 512 張 Nvidia Tesla 訓練 10 天得到的超大規模通用性人工智能模型 M6-10T),
Nvidia 在 2021 年 5 月曾經公布過一個 2.5T 引數大小的模型訓練成本,其中僅電力需求就相當于一個小型核電廠的全年發電量,更糟糕的是,存盤器性能的提高會導致更高的功率和更多的通信耗費,一個用于信號處理的嵌入式應用程式僅記憶體通信就耗費了總功率的 50~80%[5],因此,降低能耗是深度學習發展必須直面的一個關鍵問題,
2.2 傳統方法存在的問題
針對快取和存盤器存在的高能耗問題,傳統方法主要有兩種解決方式,一種是根據運行情況讓存盤器在休眠和運行兩種狀態間切換,另一種是以高計算量為代價對存盤器進行動態管理,
采用休眠-運行策略的存盤器只能作業在全功率模式下的運行狀態,雖然休眠狀態下的能耗遠低于運行狀態,但存盤器從休眠狀態轉變為運行狀態時會產生非常大的延遲和能耗[6],此外,受到傳統功率模型的限制,采用休眠-運行策略的存盤器訪問空閑時間過短,不適應其昂貴的開機、休眠成本[7–10],
以高計算量為代價的演算法通常比較復雜,還需要對每個作業負載進行繁瑣的引數調優,難以應用于實際系統,PA-LRU[11]是這類演算法中的一個典型例子,它至少有四個引數,每個引數都需要根據當前作業負載、運行情況等進行動態調整,因此很難找到一組適用范圍較廣的引數,此外,PA-LRU 演算法的許多引數與存盤器能耗、回應時間等沒有直接關系,很難通過對原有演算法的擴展來實作自適應引數調優,
2.3 演算法方面的改進
對于休眠-運行策略,當下主流的方法是通過引入多級中間態進行動態管理[9,10],與休眠-運行策略下的全功率模型相比,多級中間態模型能耗更低,不同轉速間切換所需的延遲和能耗也遠低于全功率模型,遺憾的是,多級中間態模型在硬體實作上還存在一些難題,難以緩解當下的高計算量問題,
對現實存盤系統運行情況的大量統計結果表明,性能最優(命中率最高)的快取替換演算法并非是能耗最優的,存盤系統運行程序中各級子系統、各磁區的負載也并不服從均勻分布[11],因此在不影響快取性能的前提下,可以通過犧牲部分快取命中率的方式來降低存盤器能耗,PB-LRU[6]給出了一種可行的改進思路,它提出針對各級子系統、各級磁區設計快取替換演算法來降低整個系統的失效率,進而能量最優問題[11]轉換為多重背包問題采用動態規劃求解,
假設整個存盤系統的大小為 S,首先將整個存盤系統劃分為 n 個子系統 {1…n},再將每個子系統劃分為 m 個磁區,對應大小 0 < p1 < p2 < …< pm <= S,令 xij 表示子系統 i 是否存在大小為 j 的磁區,E(i, s) 為 s 大小的存盤器所對應的能耗,整個問題轉換為:
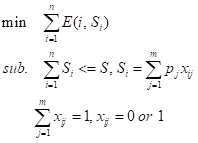
由于多重背包是一個 NP-Hard 問題,因此當前還無法在多項式時間復雜度內完成求解,PB-LRU[6]使用動態規劃完成了求解,對應狀態轉移公式如下所示:
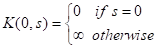
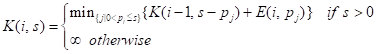
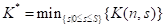
演算法中各磁區的大小是影響最后結果的一個重要因素,對此 PB-LRU 做了大量仿真實驗,得到的最優劃分如圖 2.3.1 所示
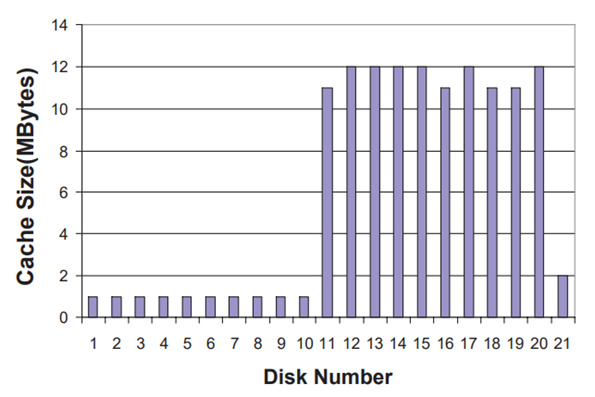
圖 2.3.1 PB-LRU 最優磁區劃分
動態存盤器管理的另一個難點在于如何綜合功耗、失效率、命中率等各個指標來合理、實時地評估現在的效益,馬特森堆疊演算法以跟蹤檔案的方式來實時確定所有不同大小的快取的命中率曲線[12,13],但并不能給出不同磁區大小下的能耗曲線[6],PB-LRU 在馬特森演算法的基礎上進行了改進,較好地解決了這一問題,估計值較真實值的誤差僅有 1.8%(圖 2.3.2),具體步驟如下所示:
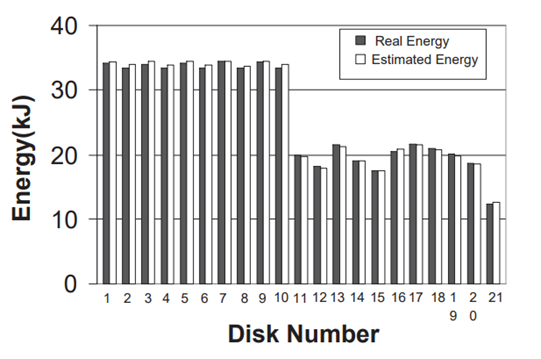
圖 2.3.2 PB-LRU 改進馬特森堆疊演算法的能耗估計結果對比
首先使用馬特森堆疊演算法確定不同磁區大小的請求是否會導致快取命中或錯過,如果一個請求在大小為 p 及其所有更小的磁區中未命中,那么該請求將會訪問相應的存盤器,當我們知道了對這個存盤器的最后訪問時間,我們就可以根據底層電源管理方案估計出從最后一次操作到當前操作的能源消耗,如果確定了實際的的功耗管理方案,我們就可以計算空閑期間消耗了多少能量,包括從休眠狀態切換到全速狀態所需的能量,
在每次更新堆疊的時候完成下列操作
① 在適當存盤器的堆疊中搜索請求的塊編號,如果它是堆疊頂部的第 i 個元素,即把它的深度設定為 i;如果沒有找到,那么將其深度設定為 ∞,
② 對于所有小于當前深度的磁區大小都增加他們的能源消耗估計,并且將之前累計的失效時間合并到當前的訪問時間中,
③ 使用與真實快取相同的替換策略更新堆疊并將請求的塊編號帶到堆疊的頂部,
PB-LRU 在不同的基準程式上的實驗結果如圖 2.3.3 ~ 圖 2.3.8 所示
圖 2.3.3 能耗對比 (OLTP)
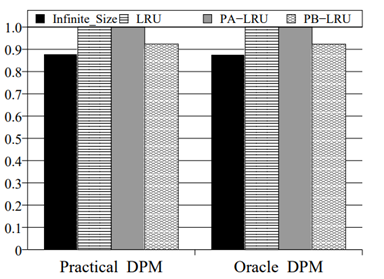
圖 2.3.4 能耗對比 (Cello96)
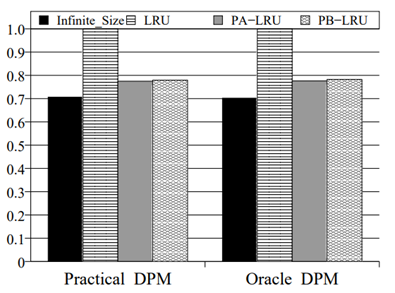
圖 2.3.5 能耗對比 (Exponential)
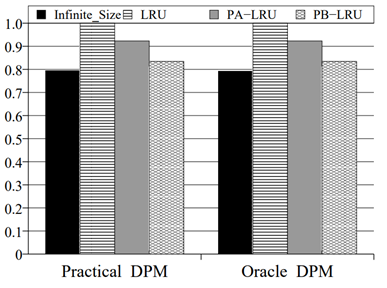
圖 2.3.6 能耗對比 (Pareto)
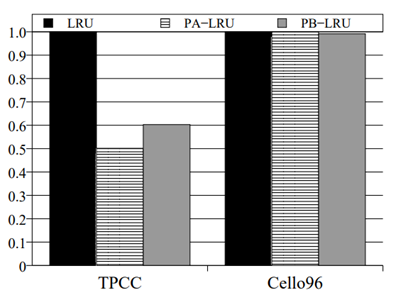
圖 2.3.7 平均回應時間 (OLTP and Cello96)
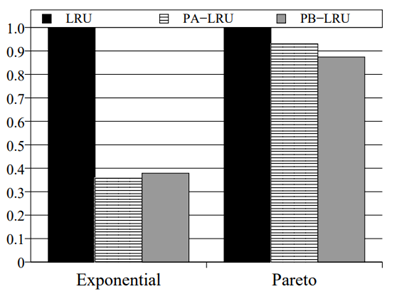
圖 2.3.8 平均回應時間 (Synthetic Traces)
2.4 硬體方面的改進
這部分主要針對嵌入式系統、移動終端等微型計算機,它們的能耗模型[14]和資料中心這類資料密集型有所不同,具體如下所示
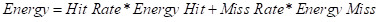
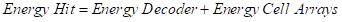
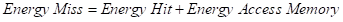
針對這一能耗模型,SF-LRU[15]給出了一個可行的改進思路,SF-LRU 通過引入第二次機會的想法來簡化了演算法的復雜度并使其易于在硬體上實作,較 LRU 而言,幾乎在能耗不變的情況下顯著提升了快取的命中率,圖 2.4.1 是 SF-LRU 的一個硬體實作,
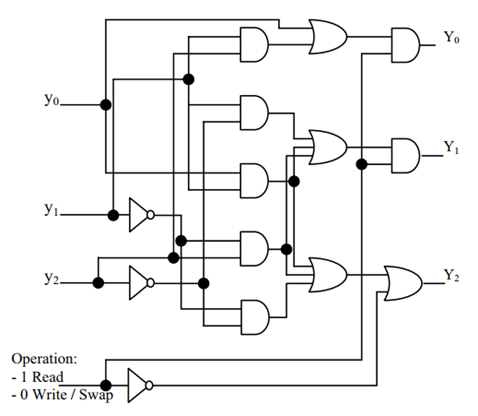
圖 2.4.1 SF-LRU 演算法的一個硬體實作
具體而言,SF-LRU 演算法的偽代碼如下所示
if (產生訪問請求) {
if (訪問命中)
執行 LRU 演算法
更新 RFCV
else
呼叫失效處理函式
比較 RFCV 的最后兩塊
if (最后一塊 > 倒數第 2 塊)
更新 RFCV 的最后一塊
交換倒數兩塊
執行 LRU
}
SF-LRU 在不同基準程式下的仿真結果如圖 2.4.2 ~圖 2.4.7 所示
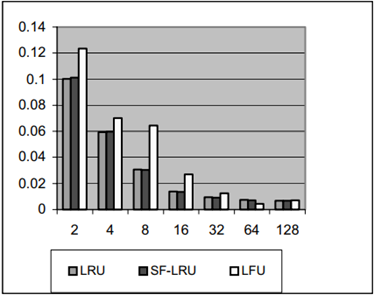
圖 2.4.2 32 block size D-cache (CC1)
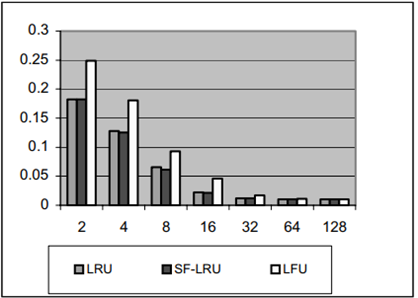
圖 2.4.3 32 block size D-cache for (Pasc)
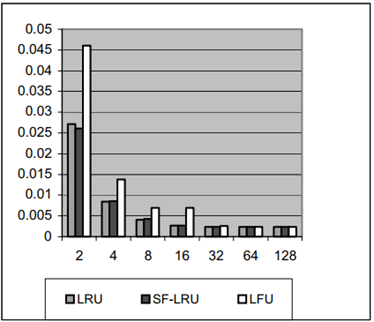
圖 2.4.4 32 block size D-cache for (Spice)
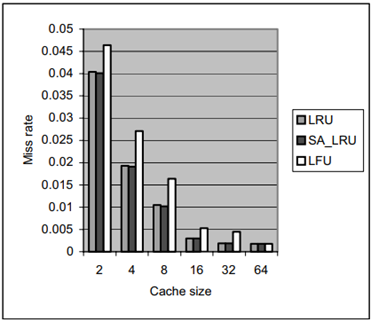
圖 2.4.5 8 block size I-cache for (Spice)
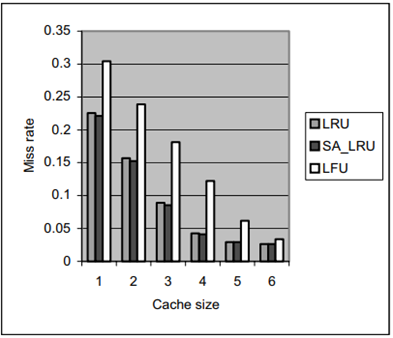
圖 2.4.6 8 block size I-cache for (CC1)
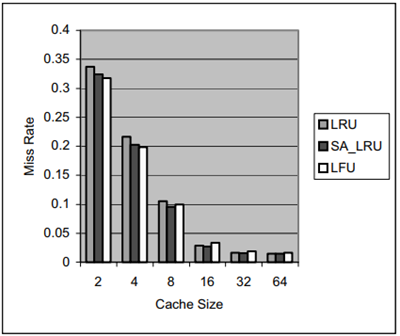
圖 2.4.7 8 block size I-cache for (Pasc)
3. 不同存盤介質分別考慮
3.1 閃存
近幾十年來快取替換演算法的研究都建立在二級存盤由磁盤組成的假設上,但移動終端、嵌入式設備等微型計算機的二級存盤主要由閃存構成,多數傳統快取替換演算法(LRU 等)是為磁盤存盤系統定制的,沒有綜合考慮到閃存這種材料的特殊性,不利于深度學習的推廣落地,
較磁盤而言,閃存在延遲和能耗上有著非對稱的讀寫代價[16](圖 3.1.1),在設計替換演算法是不僅要考慮命中率,還要考慮“臟”頁替換的代價且“臟”頁訪問時間和能耗均顯著高于“干凈”頁[17],
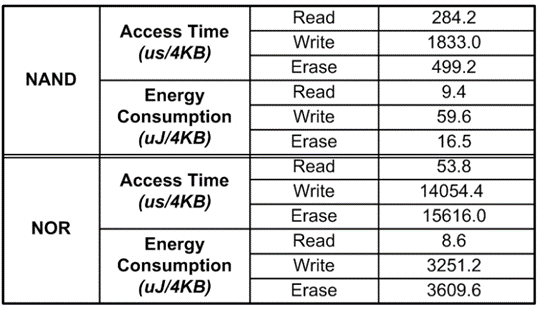
圖 3.1.1 閃存的讀寫時間
閃存較磁盤最為特別的一點在于閃存沒有尋道時間且資料在被擦除之前不能被覆寫,考慮到閃存的非對稱性讀寫耗費,基于閃存的快取替換演算法應該盡可能減少對閃存的寫和擦除操作,同時避免記憶體缺失導致的大量讀操作,
由于閃存不支持就地更新,頁被擦除之前不能對同一頁進行寫入操作,寫操作的增加隨即會導致擦除操作增加,進而加劇成本不平衡情況,如果考慮閃存寫操作伴隨的潛在擦除成本,那么寫操作的成本可以達到讀操作的 8 倍以上,此外,閃存塊會在執行指定數量的寫/擦除操作后耗盡,因此基于閃存的快取替換演算法還需要精心設計垃圾收集策略來均勻地消耗閃存區域,
綜合考慮這些因素,CFLRU 提出在頁面快取中刻意保留一定數量的“臟”頁來減少閃存的寫操作次數,同時犧牲部分快取命中率來提升系統整體性能[17],具體而言,CFLRU 在傳統 LRU 演算法的基礎上進行改進,首先將 LRU 串列劃分為兩個區域以尋找一個最小成本點,然后將最近使用的頁面組合起來,構成一個作業區域,之后大部分的快取命中都會發生在這個區域,之后再創建另一個首先清空區域來存放那些可能被驅逐的區域,當發生寫操作時,CFLRU 在首先清空區域選擇一個“干凈”頁進行驅逐,從而節省閃存的寫開銷,如果該區域沒有“干凈”頁,那么就驅逐 LRU 串列末尾的臟頁,對應示例如下:
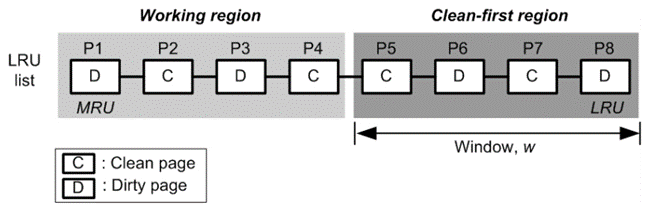
圖 3.1.2 CFLRU 演算法示例
清除區域(視窗)大小是影響演算法實際運行結果的一個重要引數,視窗過大會導致命中率急劇下降,CFLRU 通過大量仿真實驗得到了一組適合于各基準程式的引數(圖 3.1.3),未來我們可以結合深度學習來降低引數調優的難度,
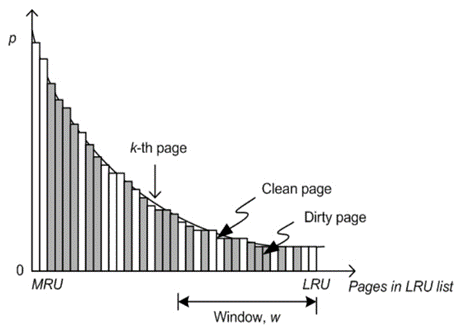
圖 3.1.3 CFLRU 演算法視窗大小曲線
CFLRU 在不同基準程式下的實驗結果如圖 3.1.4 ~ 圖 3.1.8 所示
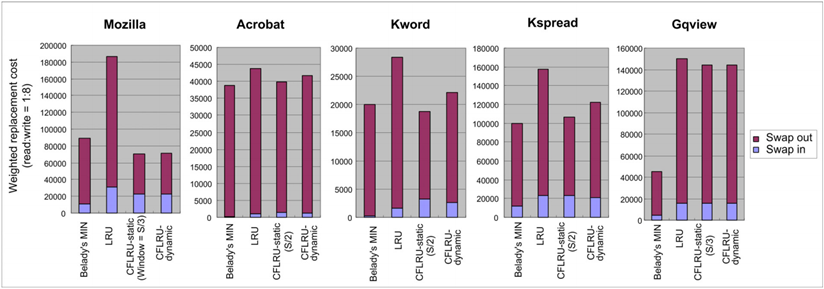
圖 3.1.4 CFLRU 在交換系統下的替換成本
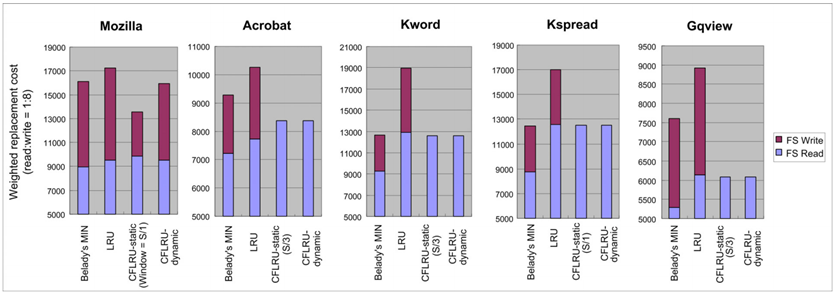
圖 3.1.5 CFLRU 在檔案系統下的替換成本
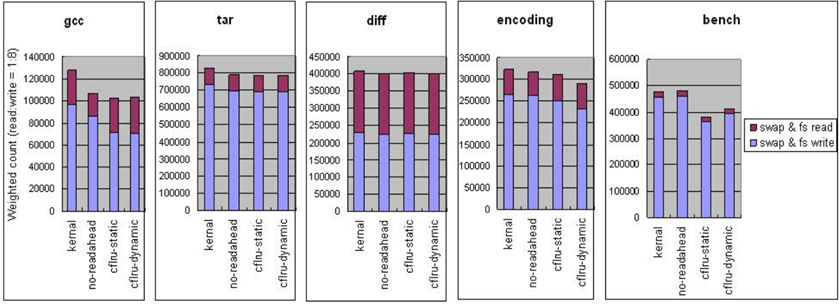
圖 3.1.6 CFLRU 在交換檔案系統下的替換成本
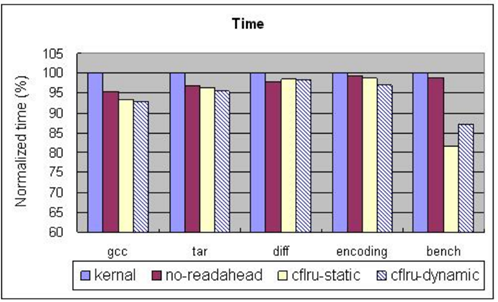
圖 3.1.7 CFLRU 在各個基準程式下的時間延遲
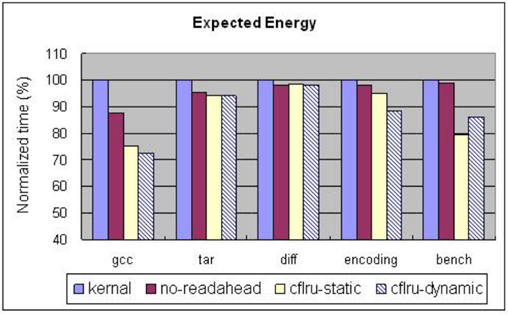
圖 3.1.8 CFLRU 在各個基準程式下的期望能耗
3.2 固態硬碟
隨著固態存盤技術的飛速發展,基于閃存的固態硬碟在存盤系統中所占的比例也在逐年上漲,較傳統硬碟而言,固態硬碟性能更高、能耗更低、噪音更小,但由于閃存材料的特殊性,也存在一些缺陷,
RPAC[18]針對固態硬碟快取替換演算法給出了一個可行的改進思路,現實存盤系統存盤軌跡[19](圖 3.4.1)的分析結果快取替換演算法應該記錄由相鄰塊構成區域的總體受歡迎程度,而不是僅用一個單獨的塊來考慮是否替換,
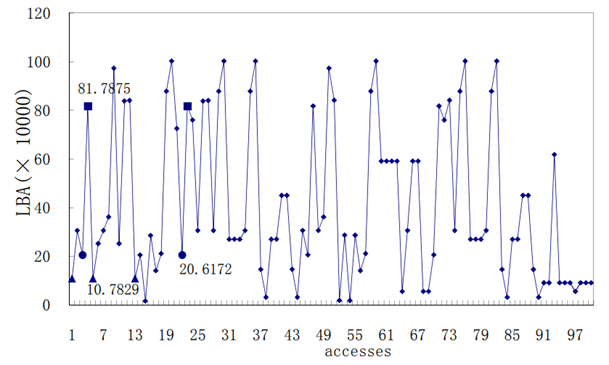
圖 3.4.1 現實存盤系統存盤軌跡
基于上述思想,RPAC 提出了一種基于哈希表和二叉樹的混合資料結構(圖 3.4.2)來維護區域級別的資訊,子區域的大小取決于二叉樹深度,哈希表用于記錄每個統計周期中各區域的訪問次數,用于后續區域受歡迎程度的計算,
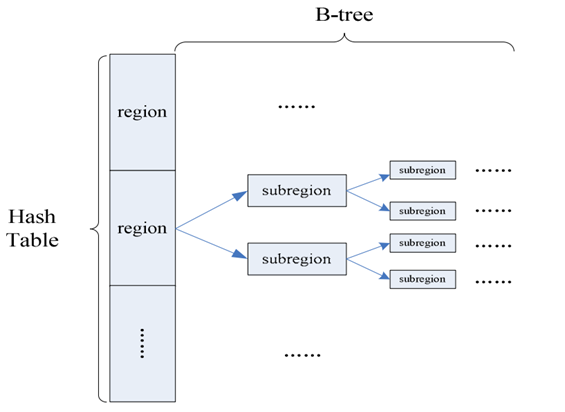
圖 3.4.2 RPAC 用于保持區域資訊的資料結構
RPAC 演算法在不同基準程式上的實驗結果如圖 3.4.3 ~圖 3.4.6 所示:
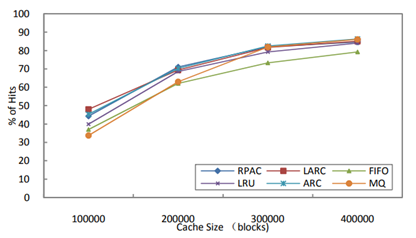
圖 3.4.3 RPAC 在 Mail 上的命中率
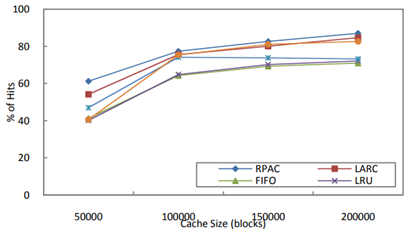
圖 3.4.4 RPAC 在 Webvm 上的命中率
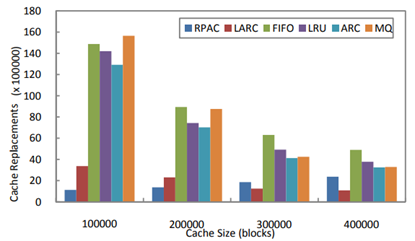
圖 3.4.5 RPAC 在 Mail 上的替換次數
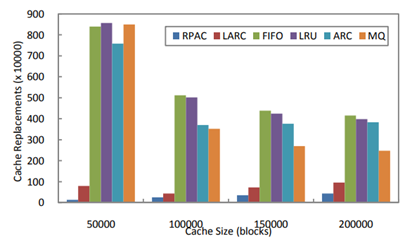
圖 3.4.6 RPAC 在 Webvm 上的替換次數
4. 降低演算法實作難度
雖然 LRU 類快取替換演算法在性能和能耗方面均有不錯的表現,但它需要大量硬體來實時跟蹤高速快取的訪問歷史,過高的硬體復雜度反過來又會直接影響記憶體訪問時間,進而導致使用 LRU 類演算法的高速快取只能采取相對簡單的寫策略[1],
針對這一問題,BPLRU[1]和 MPLRU[1]分別給出了一種降低硬體的可行思路, BPLRU 使用二叉樹(圖 4.1)的結構來近似模擬 LRU,訪問塊 A 或塊 B 時, AB/CD 位置為 1;訪問塊 C 或塊 D 時,AB/CD 置為 0,同理,A/B 位用于區分訪問物件 A、B 確定訪問的物件時塊 A 還是塊 B,具體替換策略如圖 4.2 所示:
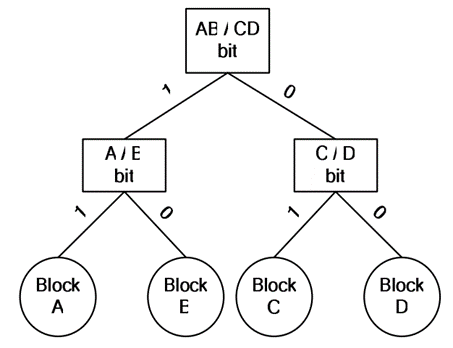
圖 4.1 BPLRU 使用的二叉樹結構
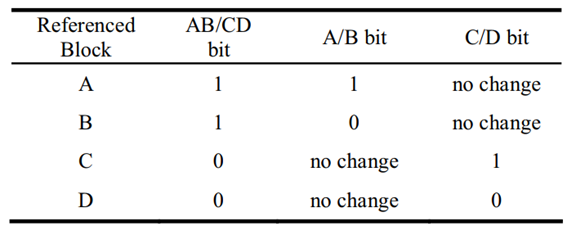
圖 4.2 BPLRU 替換策略
然而對 BPLRU 來說,如果待訪問的塊不在快取中,那么就會引發失效但歷史位并不會改變情況(圖 4.3)這意味著 BPLRU 因為缺少足夠的遲滯而不能對 LRU 進行很好的模擬,上層二叉樹的根節點也忽略了許多下層節點的資訊,
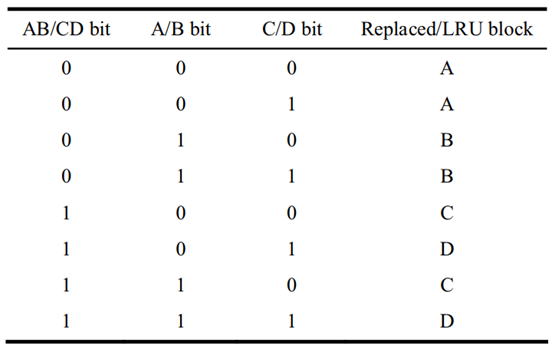
圖 4.3 BPLRU 的一種性能較差的情況
針對這一問題,MPLRU[1]提出保留節點的前一狀態并綜合前一狀態和當前狀態作出替換決定,當發生失效且需要進行替換時,MPLRU 將會使用前面保存的位來作出替換決定,讀命中則當前位的值被復制到前一位,當前位則根據當前參考的塊進行更新,MPLRU 的運行實體和具體替換策略分別如圖 4.4、圖 4.5 所示:
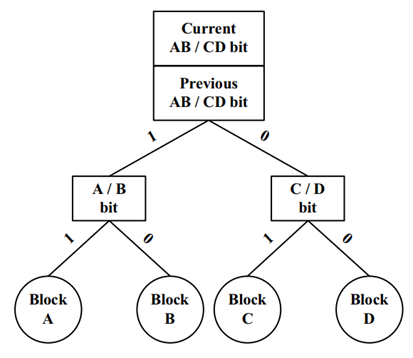
圖 4.4 MPLRU 運行實體
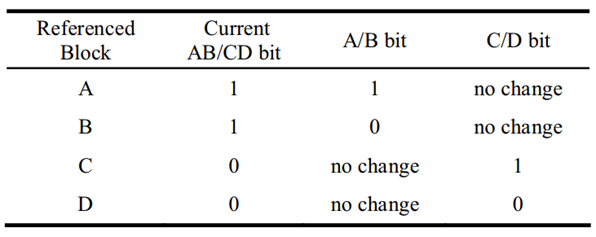
圖 4.5 MPLRU 替換策略
MPLRU 在不同基準程式下的實驗結果分別如圖 4.6 ~圖 4.9 所示:
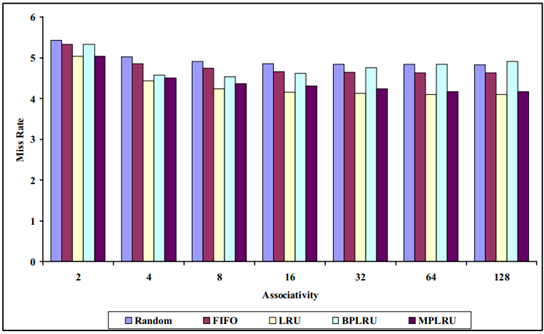
圖 4.6 8KB 下各種演算法的失效率對比
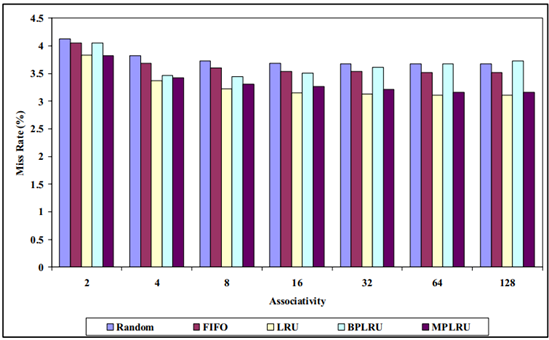
圖 4.7 16KB 下各種演算法的失效率對比
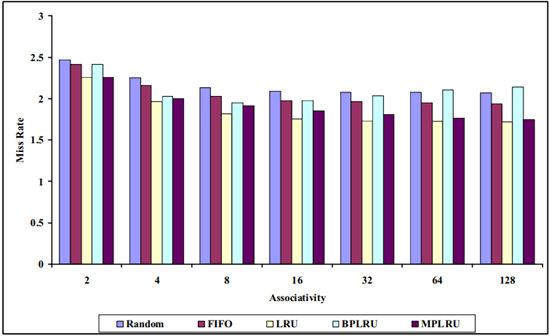
圖 4.8 32KB 下各種演算法的失效率對比
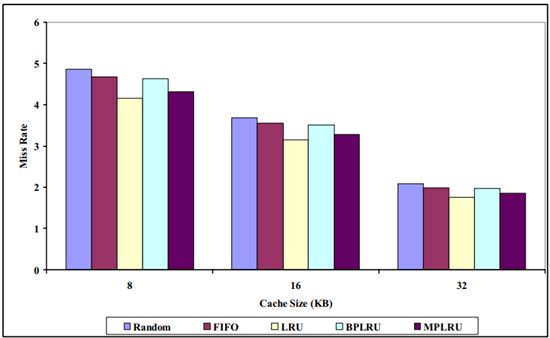
圖 4.9 使用 16 路組相聯,不同快取大小各種演算法的失效率對比
考慮 BPLRU 和 MPLRU 用于跟蹤訪問歷史的資料結構過于簡單,未來我們可以結合線索二叉樹、B+ 樹、平衡二叉樹、MVCC 等來實作對 LRU 類演算法更好的模擬,
5. 綜合考慮各級存盤
傳統快取替換演算法大多建立在一級存盤的基礎上,沒有充分考慮現在的多級快取情況,現在的高速快取普遍由 L1 快取、L2 快取和 L3 快取構成,其中 L1 快取過小,難以體現替換演算法的性能優勢;L3 快取較 L2 快取則過于靠近主存而具有較長延遲中[20],因此考慮多級高速快取的替換演算法應該針對 L2 快取進行改進,RDP[20]針對 L2 快取通過引入預測器(圖 5.1)和采樣器(圖 5.2)的硬體部件給出了一種可行的改進思路,
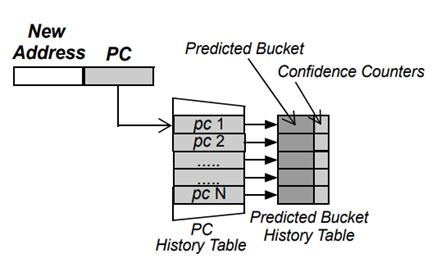
圖 5.1 預測器結構
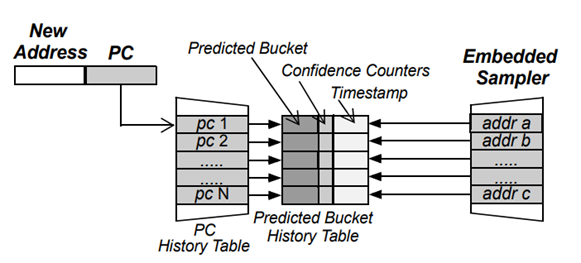
圖 5.2 嵌入了采樣器的預測器結構示意圖
實際部署推廣的程序中 RDP 類演算法主要會遇到以下 3 點問題:
① 預測器的大小問題,如果考慮 512 個表項,部署物件為 32 位,那么預測器可以僅使用 5 位的桶預測資訊和 2 位的飽和計數器,因此預測器的大小為 512*39*(32 + 5 + 2) = 2.5KB,
② 采樣問題,按照傳統方式,必須通過跟蹤許多未驗證的預測,等待下一次訪問來判斷是否匹配才能得到它們的重用距離并將其與 PC 關聯起來,這導致我們需要非常大的表來存盤地址并需要額外的哈希表來加速預測器的更新操作,對現實存盤系統的其他研究表明沒有必要收集所有地址的重用距離,隨機選擇一些地址進行跟蹤就有較大規律捕獲到可執行程式的記憶體行為[21,22],
③ 量化問題,量化方式的好壞會直接影響到最后演算法的效果,RDP 在前人[22]的基礎上,選擇性地選取磁區來量化重用距離,這樣每個 Cache 行只需要幾個額外的位就可以達到較高的量化準確率,
為避免估計訪問時間帶來的延遲和誤差,RDP 綜合考慮預測訪問時間最大和衰敗訪問時間最大的兩個候選物件,采取完全相同的度量標準來量化訪問時間并選擇其中最大的進行替換,從而保證了 RDP 演算法具有大量關于重用距離的可靠資訊,具體實體如圖 5.3 所示:
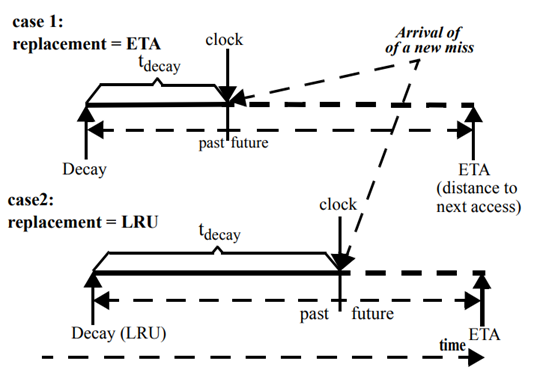
圖 5.3 RDP 運行實體示意
RDP 演算法在不同基準程式下的實驗結果如圖 5.4、圖 5.5 所示:
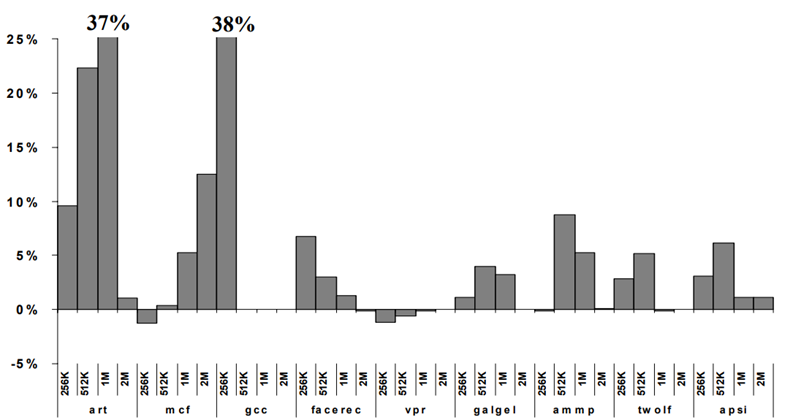
圖 5.4 RDP 在不同基準程式下降低的失效率
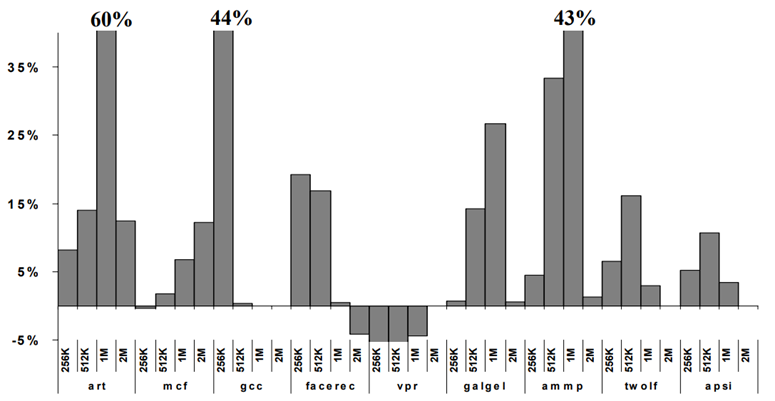
圖 5.5 RDP 在不同基準程式下對 IPC 的提升
6. 與機器(深度)學習結合
多數傳統快取替換演算法都存在很多問題,FIFO 實作難度低,但當物理記憶體比較大時就會陷入性能問題;LRU 對于稍大的回圈計算會出現嚴重的性能問題;LFU 和 MFU 等基于頻率的演算法在記憶體的不同部分存在不同的頻率模式時命中率會急劇下降;LFU 幾乎不關注最近訪問歷史,也不能很好地適應變化的訪問模式;MFU 沒有考慮最近訪問歷史,無法區分曾經很熱但現在變冷的塊和現在很熱的塊……
在深度學習爆發之前,許多研究已經針對傳統快取替換演算法的各種問題做出了相關改進并在特定的情況下取得了不錯的結果,LRFU[23]首次綜合考慮時近因素和頻率實作了 LFU 和 LRU 的結合;ARC[24]結合了 LFU 和 LRU 兩者,并在兩者間進行動態調整;WRP[25]引入了更多的評價指標來建立基于快取的頁面排名,如出現失效則選擇一個排名最低的頁面進行替換;LDF[26]在重用距離的基礎上,結合范數給出了一種新的評價方式,進而針對快取替換演算法的頁面替換進行了改進,降低了頁面替換的開銷和頁面故障率;LRU-K[27]通過監聽最近一次使用的位元數來簡化硬體實作難度……
傳統快取替換演算法大多的高計算量大多源于引數調優問題,因此考慮和深度學習結合進行改進是一個不錯的方向,AWRP[28]首次結合樸素貝葉斯和自適應權重的快取替換模型,通過動態老化因子與自適應權重排序策略相結合來提高快取性能,但是并沒有取得較傳統改進方式讓人滿意的結果;FPRA[29]通過引入模糊聚類方法中的中心聚類法并結合資料升唯、范數等給出了一種結果較好的改進思路,FRPA 能顯著提升記憶體性能主要源于聚類方法能讓同一集合中的頁面彼此更加相似,并使得最近、更頻繁和更小的參考率頁面具有更高的優先級[29],對應實驗結果如圖 6.1~圖 6.4 所示
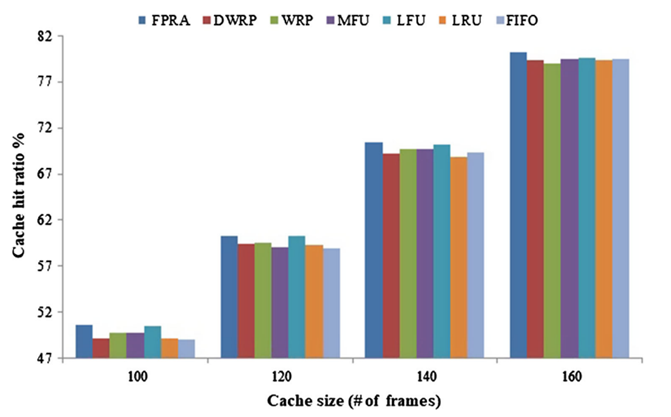
圖 6.1 FRPA 演算法命中率對比 (CC1)
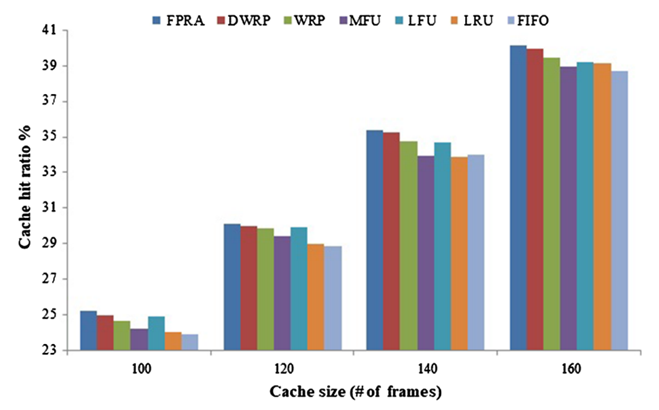
圖 6.2 FPRA 演算法命中率對比 (Spice)
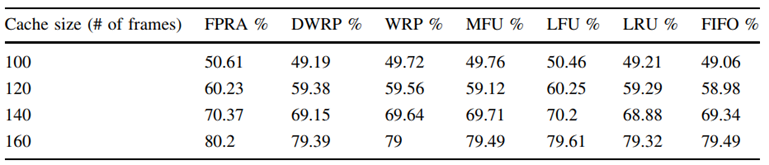
圖 6.3 FRPA 演算法命中率對比 (CC1)
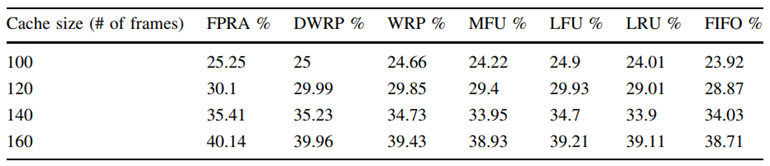
圖 6.4 FPRA 演算法命中率對比 (Spice)
7. 結語
在大資料時代下的今天,不只是深度學習,物流、軍事、醫療、教育等各行各業都在不斷涌現出龐大的計算需求,改進高速快取替換演算法無疑是緩解高計算量問題的有效方式之一,雖然本文針對降低能耗、存盤介質材料、降低演算法實作難度、綜合考慮各級存盤、結合機器(深度)學習等很多方面進行了詳細的分析探討并給出了一些可行的思路,但仍然還有很多本文沒有考慮到的一些改進方向,
隨著總線、體系結構等硬體的發展,應該綜合失效率、帶寬消耗、命中率等指標來共同評判快取替換演算法的優劣[15];基于閃存的存盤器雖然較傳統硬碟存盤器存在著沒有尋道時間、定位時間等諸多優勢,但其自身的各種缺陷也導致它只能作為一種過渡階段的存盤介質存在[19];針對特定應用領域改進的快取替換演算法(如 LR-LRU[30]就是一種適用于影像存盤和通信的智能快取替換策略)較通用的快取替換演算法一般能取得更好的應用結果……
8. 參考文獻
[1] GHASEMZADEH H, MAZROUEE S, KAKOEE M R. Modified pseudo LRU replacement algorithm[C/OL]//13th Annual IEEE International Symposium and Workshop on Engineering of Computer-Based Systems (ECBS’06). Potsdam, Germany: IEEE, 2006: 6 pp. – 376[2021–10–05]. http://ieeexplore.ieee.org/document/1607387/. DOI:10.1109/ECBS.2006.52.
[2] B M. Taking the data center power and cooling challenge[J]. Energy User News, 2002, 4.
[3] F M. More power needed[J]. Energy User News, 2002.
[4] Power, heat, and sledgehammer[R/OL]. Maximum Institution Inc., 2002. http://www.max-t.com/ downloads/ whitepapers/ SledgehammerPowerHeat20411.pdf.
[5] CHAKRABARTI C. Cache design and exploration for low power embedded systems[C/OL]//Conference Proceedings of the 2001 IEEE International Performance, Computing, and Communications Conference (Cat. No.01CH37210). Phoenix, AZ, USA: IEEE, 2001: 135–139[2021–11–12]. http://ieeexplore.ieee.org/document/918645/. DOI:10.1109/IPCCC.2001.918645.
[6] ZHU Q, SHANKAR A, ZHOU Y. PB-LRU: A Self-Tuning Power Aware Storage Cache Replacement Algorithm for Conserving Disk Energy[C/OL]//Proceedings of the 18th Annual International Conference on Supercomputing - ICS ’04. Malo, France: ACM Press, 2004: 79[2021–10–05]. http://portal.acm.org/citation.cfm?doid=1006209.1006221. DOI:10.1145/1006209.1006221.
[7] GURUMURTHI S, JIANYONG ZHANG, SIVASUBRAMANIAM A, 等. Interplay of energy and performance for disk arrays running transaction processing workloads[C/OL]//2003 IEEE International Symposium on Performance Analysis of Systems and Software. ISPASS 2003. Austin, TX, USA: IEEE, 2003: 123–132[2021–11–13]. http://ieeexplore.ieee.org/document/1190239/. DOI:10.1109/ISPASS.2003.1190239.
[8] PINHEIRO E, BIANCHINI R. Energy Conservation Techniques for Disk Array-Based Servers[C/OL]//Proceedings of the 18th Annual International Conference on Supercomputing - ICS ’04. Malo, France: ACM Press, 2004: 68[2021–11–13]. http://portal.acm.org/citation.cfm?doid=1006209.1006220. DOI:10.1145/1006209.1006220.
[9] GURUMURTHI S, SIVASUBRAMANIAM A, KANDEMIR M, 等. DRPM: Dynamic Speed Control for Power Management in Server Class Disks[C/OL]//Proceedings of the 30th Annual International Symposium on Computer Architecture - ISCA ’03. San Diego, California: ACM Press, 2003: 169[2021–11–13]. http://portal.acm.org/citation.cfm?doid=859618.859638. DOI:10.1145/859618.859638.
[10] CARRERA E V, PINHEIRO E, BIANCHINI R. Conserving Disk Energy in Network Servers[C/OL]//Proceedings of the 17th Annual International Conference on Supercomputing - ICS ’03. San Francisco, CA, USA: ACM Press, 2003: 86[2021–11–13]. http://portal.acm.org/citation.cfm?doid=782814.782829. DOI:10.1145/782814.782829.
[11] QINGBO ZHU, DAVID F M, DEVARAJ C F, 等. Reducing Energy Consumption of Disk Storage Using Power-Aware Cache Management[C/OL]//10th International Symposium on High Performance Computer Architecture (HPCA’04). Madrid, Spain: IEEE, 2004: 118–118[2021–11–13]. http://ieeexplore.ieee.org/document/1410070/. DOI:10.1109/HPCA.2004.10022.
[12] PATTERSON R H, GIBSON G A, GINTING E, 等. Informed Prefetching and Caching[C/OL]//Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles - SOSP ’95. Copper Mountain, Colorado, United States: ACM Press, 1995: 79–95[2021–11–13]. http://portal.acm.org/citation.cfm?doid=224056.224064. DOI:10.1145/224056.224064.
[13] MATTSON R L, GECSEI J, SLUTZ D R, 等. Evaluation techniques for storage hierarchies[J]. IBM Systems Journal, 1970, 9(2): 78–117. DOI:10.1147/sj.92.0078.
[14] SHIUE W-T, CHAKRABARTI C. Memory Exploration for Low Power, Embedded Systems[C/OL]//Proceedings of the 36th ACM/IEEE Conference on Design Automation Conference - DAC ’99. New Orleans, Louisiana, United States: ACM Press, 1999: 140–145[2021–11–12]. http://portal.acm.org/citation.cfm?doid=309847.309902. DOI:10.1145/309847.309902.
[15] ALGHAZO J, AKAABOUNE A, BOTROS N. SF-LRU cache replacement algorithm[C/OL]//Records of the 2004 International Workshop on Memory Technology, Design and Testing, 2004. San Jose, CA, USA: IEEE, 2004: 19–24[2021–10–05]. http://ieeexplore.ieee.org/document/1327979/. DOI:10.1109/MTDT.2004.1327979.
[16] LEE H G, CHANG N. Low-Energy Heterogeneous Non-Volatile Memory Systems for Mobile Systems[J]. Journal of Low Power Electronics, 2005, 1(1): 52–62. DOI:10.1166/jolpe.2005.001.
[17] PARK S, JUNG D, KANG J, 等. CFLRU: A Replacement Algorithm for Flash Memory[C/OL]//Proceedings of the 2006 International Conference on Compilers, Architecture and Synthesis for Embedded Systems - CASES ’06. Seoul, Korea: ACM Press, 2006: 234[2021–10–05]. http://portal.acm.org/citation.cfm?doid=1176760.1176789. DOI:10.1145/1176760.1176789.
[18] FENG YE, CHEN J, XUEJIAO FANG, 等. A Regional Popularity-Aware Cache replacement algorithm to improve the performance and lifetime of SSD-based disk cache[C/OL]//2015 IEEE International Conference on Networking, Architecture and Storage (NAS). Boston, MA, USA: IEEE, 2015: 45–53[2021–10–05]. http://ieeexplore.ieee.org/document/7255203/. DOI:10.1109/NAS.2015.7255203.
[19] HUANG S, WEI Q, CHEN J, 等. Improving flash-based disk cache with Lazy Adaptive Replacement[C/OL]//2013 IEEE 29th Symposium on Mass Storage Systems and Technologies (MSST). Long Beach, CA, USA: IEEE, 2013: 1–10[2021–11–13]. http://ieeexplore.ieee.org/document/6558447/. DOI:10.1109/MSST.2013.6558447.
[20] KERAMIDAS G, PETOUMENOS P, KAXIRAS S. Cache replacement based on reuse-distance prediction[C/OL]//2007 25th International Conference on Computer Design. Lake Tahoe, CA, USA: IEEE, 2007: 245–250[2021–10–05]. http://ieeexplore.ieee.org/document/4601909/. DOI:10.1109/ICCD.2007.4601909.
[21] BERG E, HAGERSTEN E. Fast Data-Locality Profiling of Native Execution[C/OL]//Proceedings of the 2005 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems - SIGMETRICS ’05. Banff, Alberta, Canada: ACM Press, 2005: 169[2021–11–13]. http://portal.acm.org/citation.cfm?doid=1064212.1064232. DOI:10.1145/1064212.1064232.
[22] PETOUMENOS P, KERAMIDAS G, ZEFFER H, 等. Modeling Cache Sharing on Chip Multiprocessor Architectures[C/OL]//2006 IEEE International Symposium on Workload Characterization. San Jose, CA, USA: IEEE, 2006: 160–171[2021–11–13]. http://ieeexplore.ieee.org/document/4086144/. DOI:10.1109/IISWC.2006.302740.
[23] CHO S, MOAKAR L A. AUGMENTED FIFO CACHE REPLACEMENT POLICIES FOR LOW-POWER EMBEDDED PROCESSORS[J]. Journal of Circuits, Systems and Computers, 2009, 18(06): 1081–1092. DOI:10.1142/S0218126609005551.
[24] WEI-CHE TSENG, CHUN JASON XUE, QINGFENG ZHUGE, 等. PRR: A low-overhead cache replacement algorithm for embedded processors[C/OL]//17th Asia and South Pacific Design Automation Conference. Sydney, Australia: IEEE, 2012: 35–40[2021–11–13]. http://ieeexplore.ieee.org/document/6164972/. DOI:10.1109/ASPDAC.2012.6164972.
[25] MA T, HAO Y, SHEN W, 等. An Improved Web Cache Replacement Algorithm Based on Weighting and Cost[J]. IEEE Access, 2018, 6: 27010–27017. DOI:10.1109/ACCESS.2018.2829142.
[26] KUMAR G, DEPARTMENT OF INFORMATION TECHNOLOGY, RAJ KUMAR GOEL INSTITUTE OF TECHNOLOGY AND MANAGEMENT, GHAZIABAD – 201001, UTTAR PRADESH, INDIA, TOMAR P, 等. A Novel Longest Distance First Page Replacement Algorithm[J]. Indian Journal of Science and Technology, 2017, 10(30): 1–6. DOI:10.17485/ijst/2017/v10i30/115500.
[27] O’NEIL E J, O’NEIL P E, WEIKUM G. An Optimality Proof of the LRU- K Page Replacement Algorithm[J]. Journal of the ACM, 1999, 46(1): 92–112. DOI:10.1145/300515.300518.
[28] FUNKE OLANREWAJU R, MAHMOUD MOHAMMAD AL-QUDAH D, WONG AZMAN A, 等. Intelligent Web Proxy Cache Replacement Algorithm Based on Adaptive Weight Ranking Policy via Dynamic Aging[J/OL]. Indian Journal of Science and Technology, 2016, 9(36)[2021–11–13]. https://indjst.org/articles/intelligent-web-proxy-cache-replacement-algorithm-based-on-adaptive-weight-ranking-policy-via-dynamic-aging. DOI:10.17485/ijst/2016/v9i36/102159.
[29] AKBARI BENGAR D, EBRAHIMNEJAD A, MOTAMENI H, 等. A Page Replacement Algorithm Based on a Fuzzy Approach to Improve Cache Memory Performance[J]. Soft Computing, 2020, 24(2): 955–963. DOI:10.1007/s00500-019-04624-w.
[30] WANG Y, YANG Y, HAN C, 等. LR-LRU: A PACS-Oriented Intelligent Cache Replacement Policy[J]. IEEE Access, 2019, 7: 58073–58084. DOI:10.1109/ACCESS.2019.2913961.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384054.html
標籤:其他
上一篇:【論文筆記】Recommendations as Treatments: Debiasing Learning and Evaluation
下一篇:【論文筆記】SamWalker: Social Recommendation with Informative Sampling Strategy