目錄
1.背景介紹
2.壓縮方法概述
3.壓縮方法詳述
3.1引數剪枝
3.2引數量化
3.3低秩分解(張量分解)
3.4引數共享
3.5緊湊網路
3.6知識蒸餾
3.7混合模型
3.8不同壓縮模型比較

1.背景介紹
深度學習模型的壓縮和加速是指利用神經網路引數的冗余性和網路結構的冗余性精簡模型,在不影響任務完成度的情況下,得到引數量更少、結構更精簡的模型.被壓縮后的模型計算資源需求和記憶體需求更小,相比 原始模型能夠滿足更加廣泛的應用需求. 接下來系統介紹模型壓縮與加速方面的進展,通過從引數剪枝、引數量化、緊湊網路、知識蒸餾、低秩分解、引數共享、混合方式這 7 個方面探究相關技術的發展歷程, 并分析其特點,
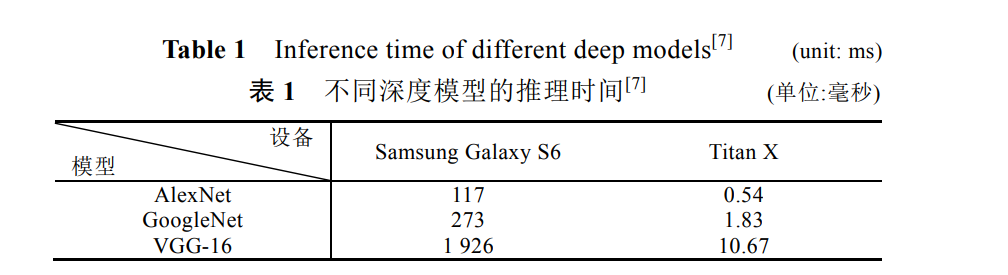
上圖是不同深度模型的推理平均時間統計,通過這個可以看出整體的時間成本還是比較嚴重的:在深度學習技術日益火爆的背景下,對深度學習模型強烈的應用需求使得人們對記憶體占用少、計算資源要求低、同時依舊保證相當高的正確率的“小模型”格外關注,利用神經網路的冗余性進行深度學習的模型壓縮和加速引起了學術界和工業界的廣泛興趣,各種作業層出不窮!
2.壓縮方法概述

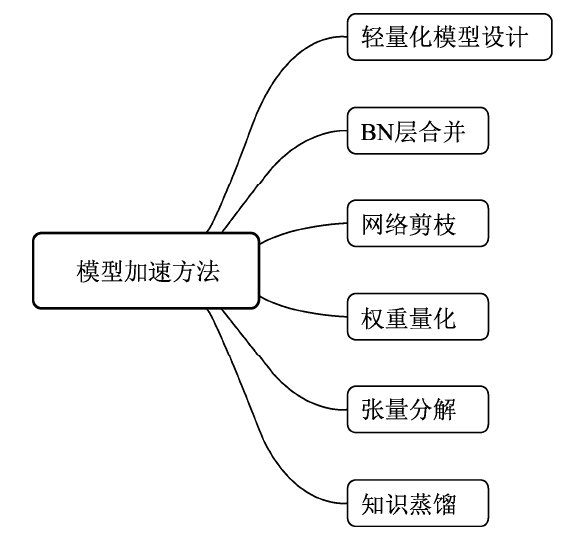
當前的經典物體檢測結構大都依賴使用卷積網路進行特征提取,即Backbone,在前面的章節中我們也詳細介紹過如VGGNet、ResNet等優秀的基礎網路,但很遺憾,這些網路往往計算量巨大,當前依靠這些基礎網路的檢測演算法很難達到實時運行的要求,尤其是在ARM、FPGA及ASIC等計算力有限的移動端硬體平臺,因此如何將物體檢測演算法加速到滿足工業應用的要求,是一個亟待解決的問題, 當前,實作模型加速的方法很多,如輕量化設計、BN層合并、剪枝與量化、張量分解、蒸餾與遷移學習等,這些方法相互之間并不獨立,可以靈活地結合使用,如圖所示:
-
輕量化設計:從模型設計時就采用一些輕量化的思想,例如采用深度可分離卷積、分組卷積等輕量卷積方式,減少卷積程序的計算量,此外,利用全域池化來取代全連接層,利用1×1卷積實作特征的通道降維,也可以降低模型的計算量,這兩點在眾多網路中已經得到了應用,
-
BN層合并:在訓練檢測模型時,BN層可以有效加速收斂,并在一定程度上防止模型的過擬合,但在前向測驗時,BN層的存在也增加了多余的計算量,由于測驗時BN層的引數已經固定,因此可以在測驗時將BN層的計算合并到卷積層,從而減少計算量,實作模型加速,
-
網路剪枝:在卷積網路成千上萬的權重中,存在著大量接近于0的引數,這些屬于冗余引數,去掉后模型也可以基本達到相同的表達能力,因此有眾多學者以此為出發點,搜索網路中的冗余卷積核,將網路稀疏化,稱之為網路剪枝,具體來講,網路剪枝有訓練中稀疏與訓練后剪枝兩種方法,
-
權重量化:是指將網路中高精度的引數量化為低精度的引數,從而加速計算的方法,高精度的模型引數擁有更大的動態變化范圍,能夠表達更豐富的引數空間,因此在訓練中通常使用32位浮點數(單精度)作為網路引數的模型,訓練完成后為了減小模型大小,通常可以將32位浮點數量化為16位浮點數的半精度,甚至是int8的整型、0與1的二值型別,典型方法如DeepCompression,
-
張量分解(低秩分解):由于原始網路引數中存在大量的冗余,除了剪枝的方法以外,我們還可以利用SVD分解和PQ分解等方法,將原始張量分解為低秩的若干張量,以減少卷積的計算量,提升前向速度,
-
知識蒸餾:通常來講,大的模型擁有更強的擬合與泛化能力,而小模型的擬合能力較弱,并且容易出現過擬合,因此,我們可以使用大的模型指導小模型的訓練,保留大模型的有效資訊,實作知識的蒸餾,
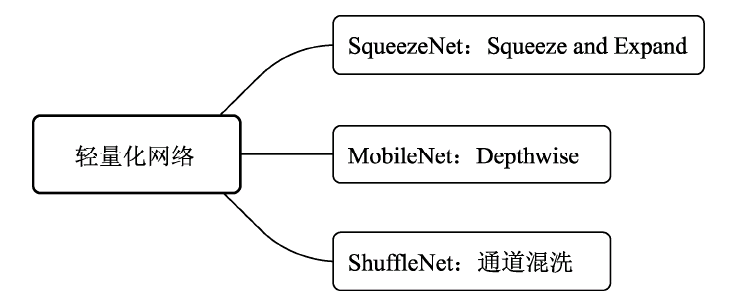
對于輕量化的網路設計,目前較為流行的有SqueezeNet、MobileNet及ShuffleNet等結構,如上圖所示,其中,SqueezeNet采用了精心設計的壓縮再擴展的結構,MobileNet使用了效率更高的深度可分離卷積,而ShuffleNet提出了通道混洗的操作,進一步降低了模型的計算量,
3.壓縮方法詳述
3.1引數剪枝
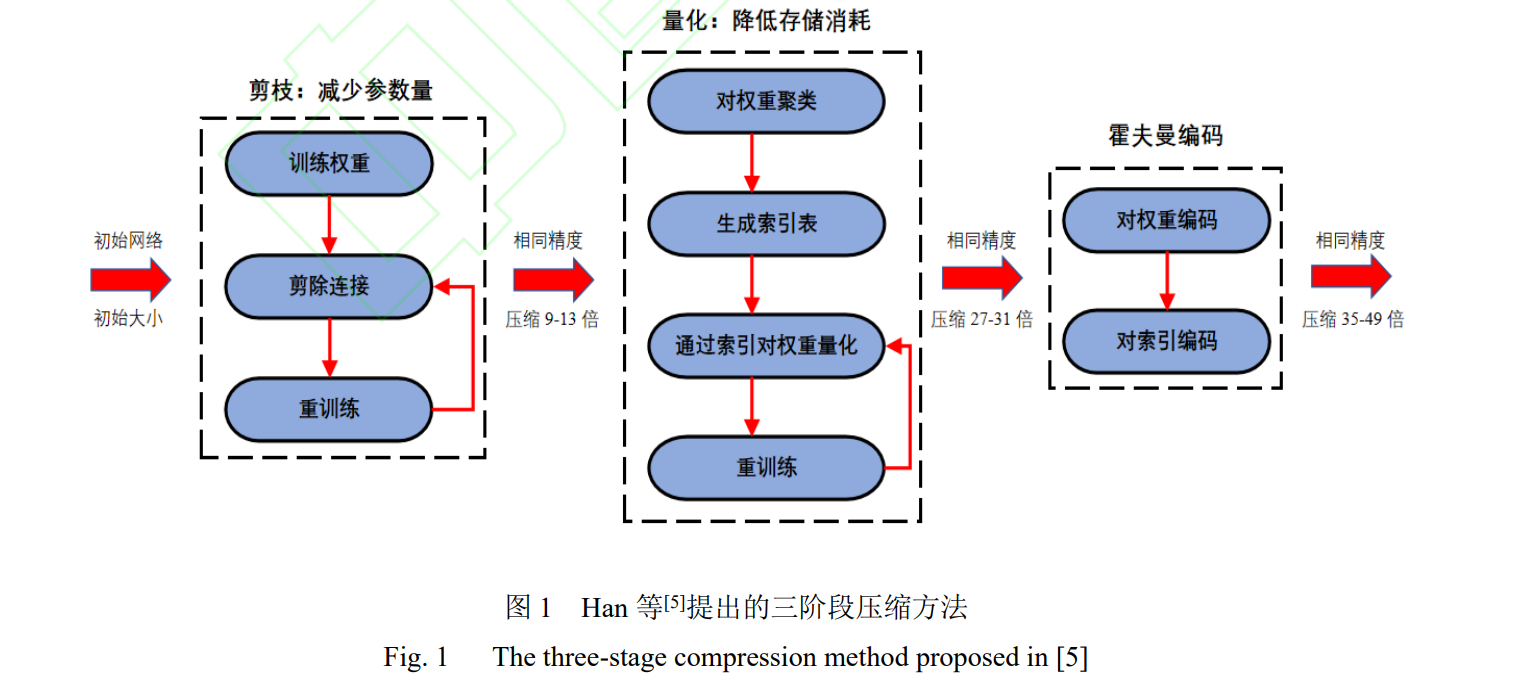
引數剪枝是指在預訓練好的大型模型的基礎上,設計對網路引數的評價準則,以此為根據洗掉“冗余”引數,根據剪枝粒度粗細,引數剪枝可分為非結構化剪枝和結構化剪枝、自動化剪枝,非結構化剪枝的粒度比較細,可以無限制地去掉網路中期望比例的任何“冗余”引數,但這樣會帶來裁剪后網路結構不規整、難以有效加速的問題,結構化剪枝的粒度比較粗,剪枝的最小單位是 filter 內引數的組合,通過對 filter 或者 feature map 設定評價因子,甚至可以刪 除整個 filter 或者某幾個 channel,使網路“變窄”,從而可以直接在現有軟/硬體上獲得有效加速,但可能會帶來預測精度(accuracy)的下降,需要通過對模型微調(fine-tuning)以恢復性能,
實體:
3.2引數量化
引數量化是指用較低位寬表示典型的 32 位浮點網路引數,網路引數包括權重、激活值、梯度和誤差等等,可以使用統一的位寬(如 16-bit、8-bit、2-bit 和 1-bit 等),也可以根據經驗或一定策略自由組合不同的位寬,
引數量化的優點是:
-
能夠顯著減少引數存盤空間與記憶體占用空間,將引數從 32 位浮點型量化到 8 位整型,從而縮 小 75%的存盤空間,這對于計算資源有限的邊緣設備和嵌入式設備進行深度學習模型的部署和使用都有很大的幫助;
-
能夠加快運算速度,設備能耗,讀取 32 位浮點數所需的帶寬可以同時讀入 4 個 8 位整數,并且整 型運算相比浮點型運算更快,自然能夠降低設備功耗,
但其仍存在一定的局限性:
-
網路引數的位寬減少損失了一 部分資訊量,會造成推理精度的下降,雖然能夠通過微調恢復部分精確度,但也帶來時間成本的增加;
-
量化到特 殊位寬時,很多現有的訓練方法和硬體平臺不再適用,需要設計專用的系統架構,靈活性不高,
分類:二值化、三值化、聚類量化、混合位寬
3.3低秩分解(張量分解)
神經網路的 filter 可以看作是四維張量:寬度 w高度 h通道數 c卷積核數 n,由于 c 和 n 對網路結構的整 體影響較大,所以基于卷積核(w*h)矩陣資訊冗余的特點及其低秩特性,可以利用低秩分解方法進行網路壓縮,低秩分解是指通過合并維數和施加低秩約束的方式稀疏化卷積核矩陣,由于權值向量大多分布在低秩子空間,所以可以用少數的基向量來重構卷積核矩陣,達到縮小存盤空間的目的,
低秩分解方法在大卷積核和中小型網路上有不錯的壓縮和加速效果,過去的研究已經比較成熟,但近兩年已不再流行,原因在于:除了矩陣分解操作成本高、逐層分解不利于全域引數壓縮,需要大量的重新訓練才能達到收斂等問題之外,近兩年提出的新網路越來越多地采用 1*1 卷積,這種小卷積核不利于低秩分解方法的使用,很難實作網路壓縮與加速!
分類:二元分解、多元分解
3.4引數共享
引數共享是指利用結構化矩陣或聚類等方法映射網路引數,減少引數數量,引數共享方法的原理與引數剪枝類似,都是利用引數存在大量冗余的特點,目的都是為了減少引數數量,但與引數剪枝直接裁剪不重要的引數不同,引數共享設計一種映射形式,將全部引數映射到少量資料上,減少對存盤空間的需求,由于全連接層引數數量較多,引數存盤占據整個網路模型的大部分,所以引數共享對于去除全連接層冗余性能夠發揮較好的效果; 也由于其操作簡便,適合與其他方法組合使用,但其缺點在于不易泛化,如何應用于去除卷積層的冗余性仍是一個挑戰,同時,對于結構化矩陣這一常用映射形式,很難為權值矩陣找到合適的結構化矩陣,并且其理論依據不 夠充足,
分類:回圈矩陣、聚類共享
3.5緊湊網路
以上 4 種利用引數冗余性減少引數數量或者降低引數精度的方法雖然能夠精簡網路結構,但往往需要龐大的預訓練模型,在此基礎上進行引數壓縮,并且這些方法大都存在精確度下降的問題,需要微調來提升網路性能,設計更緊湊的新型網路結構,是一種新興的網路壓縮與加速理念,構造特殊結構的 filter、網路層甚至網路, 從頭訓練,獲得適宜部署到移動平臺等資源有限設備的網路性能,不再需要像引數壓縮類方法那樣專門存盤預訓練模型,也不需要通過微調來提升性能,降低了時間成本,具有存盤量小、計算量低和網路性能好的特點,但其缺點在于:由于其特殊結構很難與其他的壓縮與加速方法組合使用,并且泛化性較差,不適合作為預訓練模型幫助其他模型訓練,
3.6知識蒸餾
知識蒸餾最早由 Buciluǎ 等人提出,用以訓練帶有偽資料標記的強分類器的壓縮模型和復制原始分類器的輸出,與其他壓縮與加速方法只使用需要被壓縮的目標網路不同,知識蒸餾法需要兩種型別的網路:教師模型和學生模型,
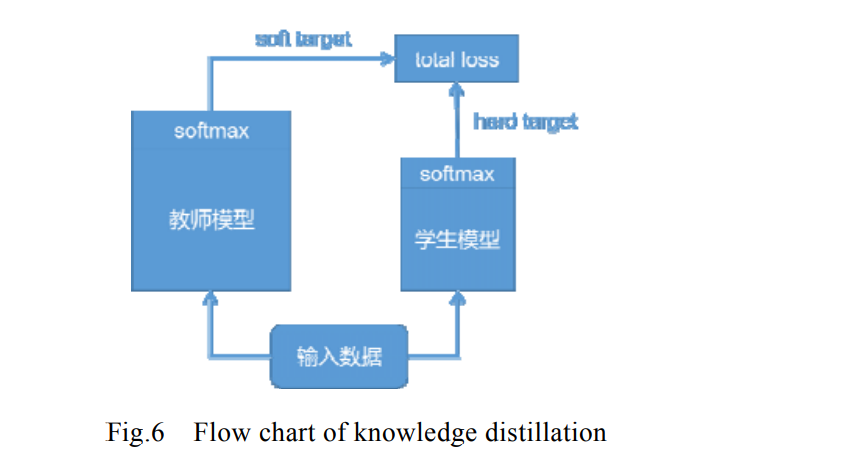
預先訓練好的教師模型通常是一個大型的神經網路模型,具有很好的性能,如上圖所示,將教師模 型的 softmax 層輸出作為 soft target 與學生模型的 softmax 層輸出作為 hard target 一同送入 total loss 計算,指導學生模型訓練,將教師模型的知識遷移到學生模型中,使學生模型達到與教師模型相當的性能.學生模型更加緊 湊高效,起到模型壓縮的目的.知識蒸餾法可使深層網路變淺,極大地降低了計算成本,但也存在其局限性.由于 使用 softmax 層輸出作為知識,所以一般多用于具有 softmax 損失函式的分類任務,在其他任務的泛化性不好; 并且就目前來看,其壓縮比與蒸餾后的模型性能還存在較大的進步空間.
3.7混合模型
以上這些壓縮與加速方法單獨使用時能夠獲得很好的效果,但也都存在各自的局限性,組合使用可使它們 互為補充,研究人員通過組合使用不同的壓縮與加速方法或者針對不同網路層選取不同的壓縮與加速方法,設計了一體化的壓縮與加速框架,能夠獲得更好的壓縮比與加速效果,引數剪枝、引數量化、低秩分解和引數共享經常組合使用,極大地降低了模型的記憶體需求和存盤需求,方便模型部署到計算資源有限的移動平臺,知識蒸餾可以與緊湊網路組合使用,為學生模型選擇緊湊的網路結構,在保證壓縮比的同時,可提升學生模型的性能,混合方式能夠綜合各類壓縮與加速方法的優勢,進一步加強了壓縮與加速效果,將會是未來在深度學習模型壓縮與加速領域的重要研究方向,
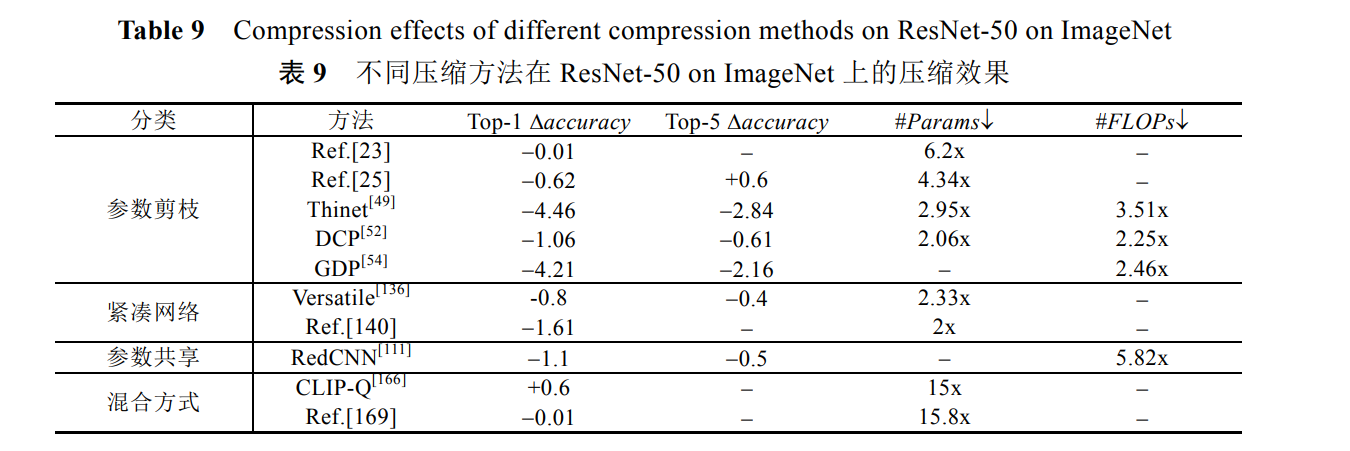
3.8不同壓縮模型比較
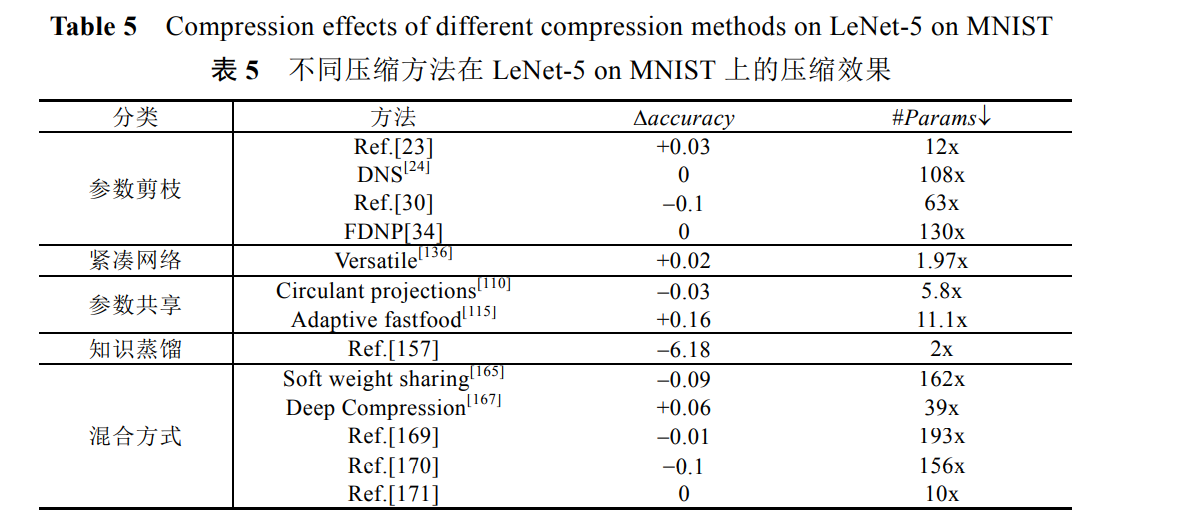
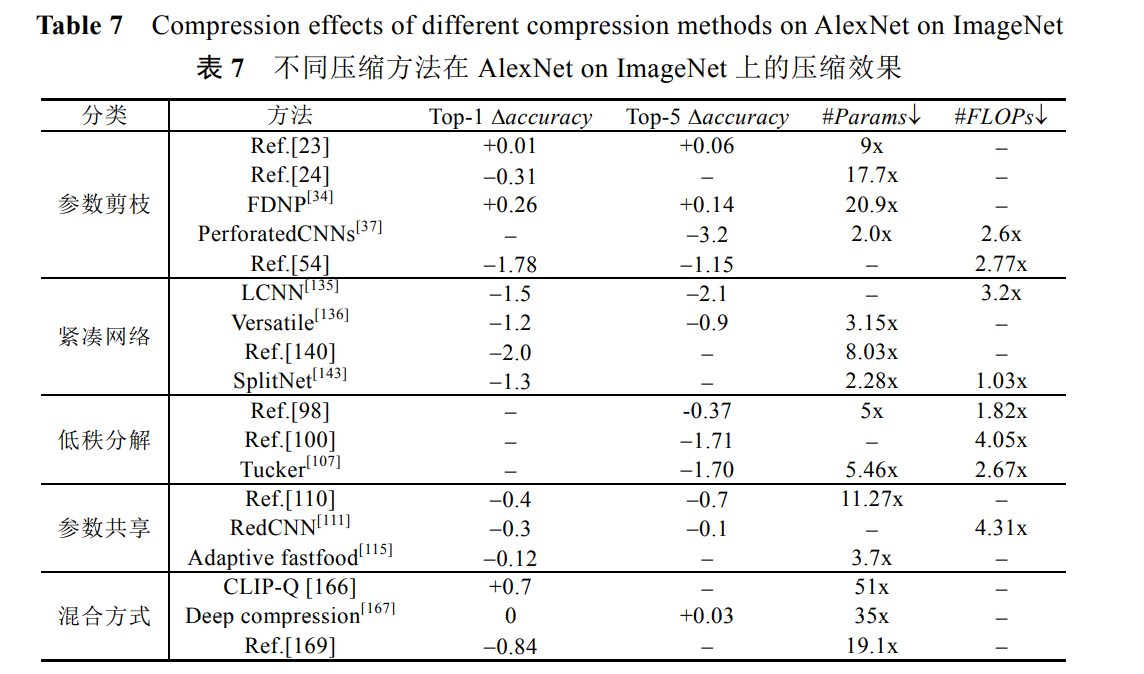
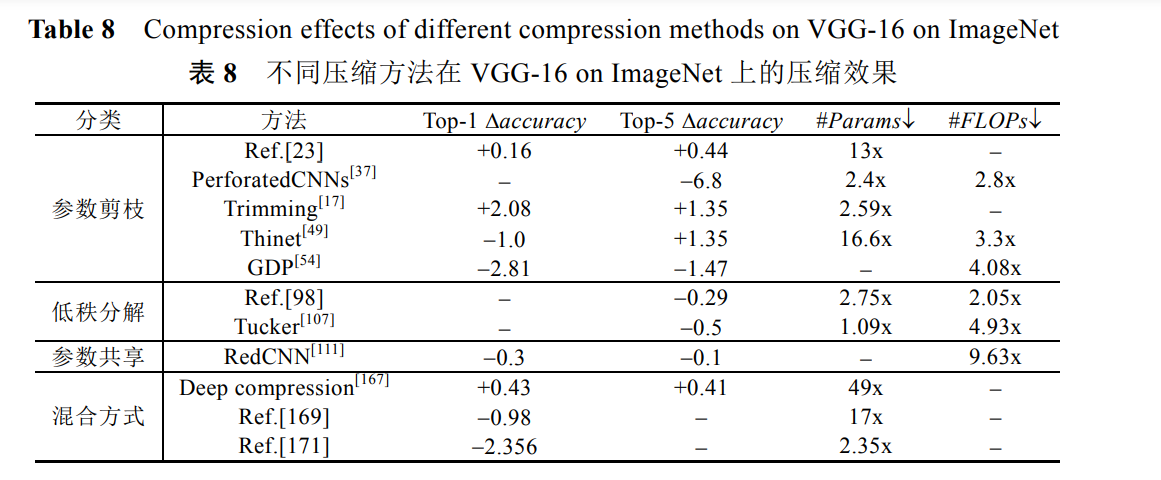
圖展示了引數剪枝、緊湊網路、引數共享和混合方式這 4 類壓縮技術的一些代表性方法使用 CIFAR-10 資料集在 VGG-16 上的壓縮效果,可以看出,這 4 類方法的壓縮效果差別比較大,整體來看,結構化剪枝效果更好, 同時起到了網路壓縮和加速的效果,accuracy 甚至有些提升, 權值隨機編碼方法能夠實作高達 159x 的引數壓縮比,accuracy 略有下降!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384120.html
標籤:AI