RNN(Recurrent Neural Network)是怎么來的?
一些應用場景,比如說寫論文,寫詩,翻譯等等,
既然已經學習過神經網路,深度神經網路,卷積神經網路,為什么還要學習RNN?
首先我們必須要知道DNN,CNN的輸入是相互獨立的,比如說我們有一張照片,最終輸入是貓還是狗,我輸入的每張照片之間是不是沒什么關系,也就是說相互獨立,但是現實生活當中,有好多都是相互連接的,比如說股票隨著時間的變化,再比如說:我是中國人,因此我的母語是______.我們知道這個空格要填的是漢語對吧,我們是怎么知道到,是不是通過上文進行簡單的推斷,知道這個地方要填漢語的呀,假如說:我們現在還是三歲小孩,讀一個字忘一個字,那么我讀到空格這個地方時候知道是漢語嗎?不知道吧,所以RNN的本質是啥啊,是不是就是讓它,“像人一樣具有記憶啊”,
網路結構是什么樣子的呢?
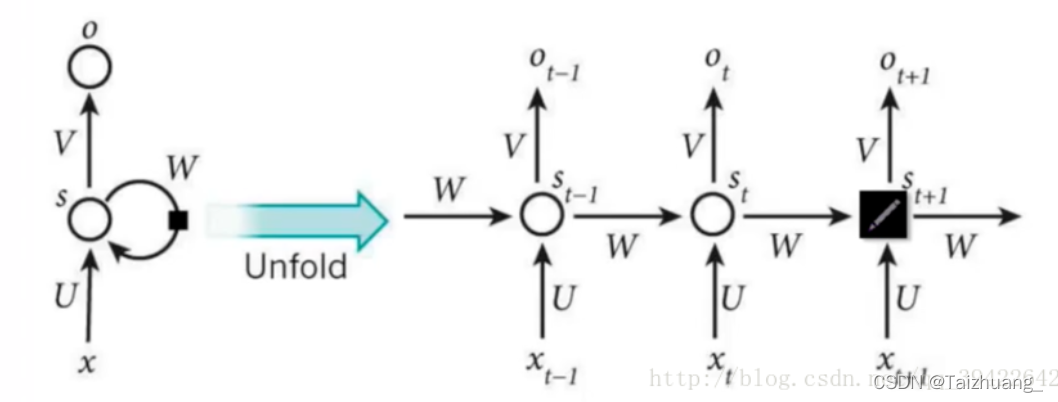
每個神經單元做的事情都是一樣的,因此呢我們要是把他給折疊起來呢就是左邊圖的樣子,要是張開的話就是有點圖的樣子,一句話概括RNN,就是一個結構重復的使用,
然后在這里我們引入一下時間步:什么是時間步,我要說一句話:我對人工智能很感興趣,
我是怎么說的,是不是一個字一個字說出來的,那么同理,如果是我們機器處理的話,是不是同樣也是一個字一個字輸入并且處理的呀,因此呢,我這輸入每個字,處理每個字的時候,就叫做一個時間步,
因此呢,我們上邊的結構圖可不可以這樣去理解:xt代表的就是t時刻的輸入,ot代表的就是t時刻的輸出,st-1就是t時刻的記憶,
就好像我們現在是演算法一的階段,我們的知識是由,演算法一這個學到的東西(輸入)加上我們深度二以及深度二以前的東西(記憶),
因此我們的公式能寫成什么呀:
St = f(U*xt + w*st-1)
那么就有同學問啦,里邊的公式我理解沒那么加一個f()是什么呀,這個呀就是激活函式,什么作用呢,就是過濾資訊的,比如說我現在在給大家講RNN,大家在深度的時候也學了RNN對吧,我呢,比你們之前那個老師講的更容易理解更清楚供透徹,因此,大家是不可以吧他們講的給忘啦,記住我講了就行啦,對不對,RNN也是一樣啊,我既然可以記憶啦,我肯定只記住有用的更重要的資訊啊,那么神經網路中什么最適合過濾資訊啊,激活函式吧,
做一個非線性的變換,來過濾資訊,
大家已經學完了這個月的知識啦,那么是不是馬上要月考了呀,那么月考的時候,大家是不是帶著這個月的記憶就行啦,這個月的記憶是怎么構成的?是不是就是這個月學到的東西,加上上個月以及之前學的東西啊,
也就是告訴大家,我在計算ot的時候,是不是通過st算得的啊,
公式:ot = f(v * st)這是不是我t時刻的輸出啊,也就是說我月考的成績,
總結:
Xt:就是本月學的東西,也就是輸入對吧
St:就是本月的記憶,剛才也講啦,本月的記憶是不是由我當月學的,加上我之前學的記憶,就好像大家馬上要月考啦,大家腦子里邊是不是除了這個月學的東西,也有之前學的東西啊,
Ot:就是大家的月考了,是不是大家都是憑著記憶去考的試,而不是通過作弊去考的試吧,
但是很多情況下的Ot是不存在的,因為很多的NLP任務只關注最后一個輸出,例如情感分析,在給大家類比一下:大家要去找作業的時候,人家是不是只看大家的技術怎么樣啊,而不是看你,機器一考了100,機器二考了100,深度100,然后就要你啦對不對,我只看你學完實訓之后出來掌握了多少技術,對不對,
BPTT:RNN的反向傳播
實質是和BP演算法一致的,只不過因為RNN是處理的序列資料,是不是隨著時間步去處理的呀,我正向傳播的時候是不是一個時間步一個時間步的去計算,同時時間步之間試試又是相互關聯的呀,我正想傳播如此,那么我反向傳播的時候,是不是也應該隨著時間步去反向傳播啊,這就是BPTT(back propagetion through time),通過時間步反向傳播,那么我們知道BP演算法的核心是反向的鏈式求導,也就是說,尋找各個引數的梯度,然后沿著各個引數梯度的方向,不斷的尋找最優的引數,直到收斂,
那么接下來我們就去看一看BPTT
首先對V求導是最簡單的:
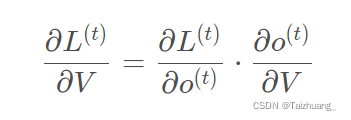
但是我們知道:RNN的代價是怎么產生的呀,是不是我在每一個時刻都會產生一個代價啊,
比如說我輸出了一個樣本,我這一個樣本呢的序列長度是5,那么我的時間步是不是就是5,
每個時間步是不是都有一個輸出啊,因此,我算代價的時候,我不能只算第五個時間步的輸出和真實值的交叉熵啊,我要把每個時間步的輸出都會有代價,那么我是不是要做一個所有時間步的加和是我的總代價啊,因此我對V的求偏導是不是就是這樣啦:
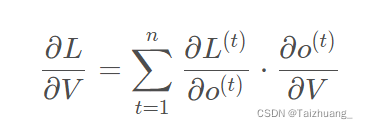
但是對U和W進行求導的時候就比較復雜啦:
如圖:
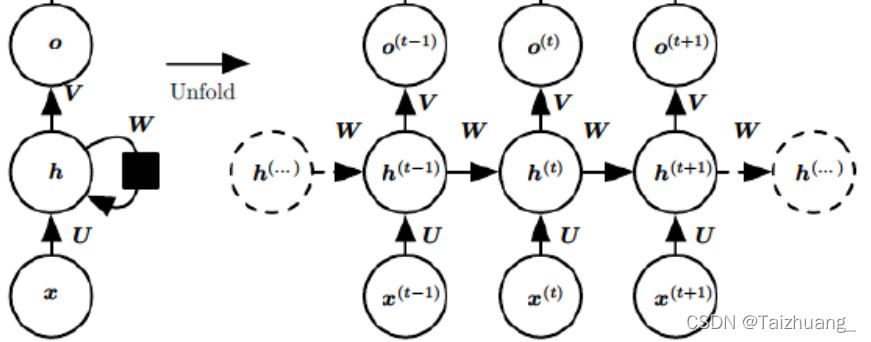
是不是我們對W和U進行求偏導的時候是不是要涉及到歷史的資料啊,我們拿三個時刻舉例:
對W求偏導公式:
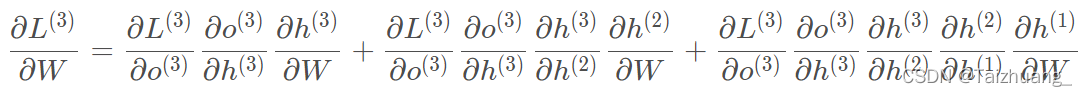
對U求偏導:
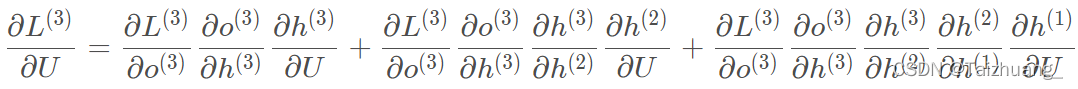
但是好在我們是不是能發現一定的規律:
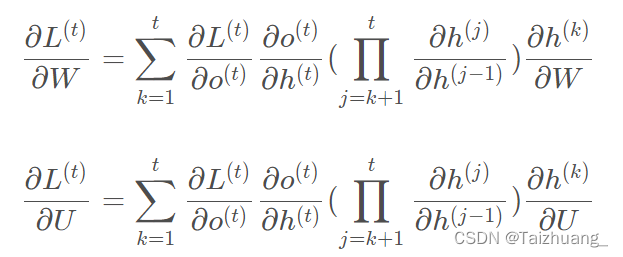
那么我們知道這里邊是不是h這個隱藏單元中是不是又激活函式在里邊的呀:
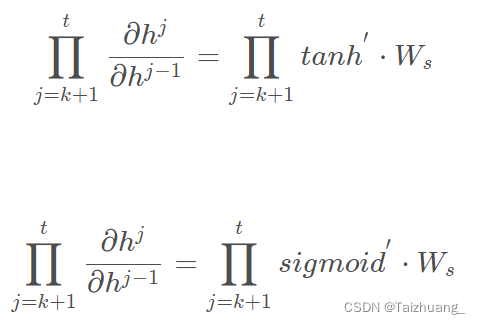
那么我們這么做累乘的話會出現什么問題啊,梯度消失!!!
RNN中共享引數的問題:
首先我們知道在深度神經網路里邊是不是引數都特別的多啊,然后呢,像在CNN,RNN這樣的網路里邊呢,我們讓他們去共享引數,那么是不是就大大的減少了引數量啊,這樣引數量一減少,那么速度上是不是就會有很大很大的提升!!!
我想讓這么多隱藏神經單元的作用是一樣的!!!
舉個例子:我愛我的祖國
在輸入第一個‘我’的時候,得到的輸出和輸入第三個‘我’的時候的到的輸出是一樣的
因為什么呀,相同的輸入,相同的引數所以我會得到相同的結果,那么輸入第一個‘我’和
第二個‘愛’的時候得到的輸出肯定是不一樣的,為什么呀?相同的引數(U,W,V)不同的輸入,所以得到的輸出是不一樣的,
RNN的優缺點:
優點呢就是可以解決處理序列資料,使神經網路具有記憶的功能啊,
缺點就是,如果序列太長會導致梯度消失或者梯度爆炸,梯度消失呢也就導致了RNN不能長期的記憶,如果我一個序列很長的話,后邊層的梯度根本就傳不到前邊層,后邊層的誤差,不能影響到前邊層的計算,因此就不能去調整前層的引數了,所以他們就是失去了關系,因此RNN的梯度消失導致了RNN不能長期記憶,

梯度消失的話可以使用LSTM中的門解決,
梯度爆炸可以設定一個最大閾值,
圖片來源于知乎
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384125.html
標籤:AI