- 1 基本概念
- 2 糾刪碼操作
- 2.1 糾刪碼策略查看
- 2.2 糾刪碼策略設定
- 2.3 糾刪碼策略測驗
1 基本概念
??
HDFS為擦除編碼(EC)提供了支持,以更有效地存盤資料,與默認三個副本機制相比,EC策略可以節省約50%的存盤空間
??但不可忽略的是編解碼的運算會消耗CPU資源,糾刪碼的編解碼性能對其在HDFS中的應用起著至關重要的作用,如果不利用硬體方面的優化就很難得到理想的性能,英特爾的智能存盤加速庫(ISA-L)提供了對糾刪碼編解碼的優化,極大的提升了其性能
??糾刪碼是hadoop3.x新加入的功能,之前的hdfs都是采用副本方式容錯,默認情況下,一個檔案有3個副本,可以容忍任意2個副本(datanode)不可用,這樣提高了資料的可用性,但也帶來了2倍的冗余開銷,例如3TB的空間,只能存盤1TB的有效資料,而糾刪碼則可以在同等可用性的情況下,節省更多的空間,以RS-6-3-1024K這種糾刪碼策略為例子,6份原始資料,編碼后生成3份校驗資料,一共9份資料,只要最終有6份資料存在,就可以得到原始資料,它可以容忍任意3份資料不可用.
2 糾刪碼操作
2.1 糾刪碼策略查看
hdfs ec -listPolicies

上述策略中有多種,如上述策略箭頭指向,這里介紹其中一種,其他
以此類推
RS-6-3-1024k:使用RS編碼,每6個資料單元,生成3個校驗單元,共9個單元,也就是說:這9個單元中,只要有任意的6個單元存在(不管是資料單元還是校驗單元,只要總數=6),就可以得到原始資料,例如上傳一個40MB的資料,那么就會將40MB的資料按1024KB為一塊進行完全劃分(1024KB也是最小的資料單元),而策略中的6表示分割6個原始資料部分,對于40MB的資料,劃分為6個部分,那么每個部分是7MB,7MB的資料可以看做由多個1024KB的組成,同時它也是使用1024KB進行計算的(因為并不能做到每個資料內容都能進行一個6的整倍數)原始資料部分存盤是6*7MB=42MB,而使用原來副本數存盤(我這里設定的是3個),那么占用的記憶體就是120MB,雖然糾刪碼策略的校驗單元也占用記憶體,但是理論上糾刪碼策略節省的空間高達50%,
State:表示策略的狀態,上圖中RS-6-3-1024K表示開啟狀態
理論狀態下RS-6-3-1024k需要9臺DataNode,RS-3-2-1024k需要5臺DataNode支持,其他以此類推
2.2 糾刪碼策略設定
糾刪碼策略是與具體的路徑(
path)相關聯的,也就是說,如果我們要使用糾刪碼,則要給一個具體的路徑設定糾刪碼策略,后續,所有往此目錄下存盤的檔案,都會執行此策略
默認只開啟對RS-6-3-1024k策略的支持,如要使用別的策略需要先啟用
以下以為input目錄設定RS-3-2-1024K為例,開啟糾刪碼策略,就不會以原來的副本策略去存盤檔案
1、 開啟對RS-3-2-1024k策略的支持(開啟以后才能使用該策略)
#開啟
hdfs ec -enablePolicy -policy RS-3-2-1024k
#禁用
hdfs ec -disablePolicy -policy RS-3-2-1024k

2、在HDFS創建目錄,并設定擦除策略
#目錄創建
hdfs dfs -mkdir /input
#為input目錄設定策略
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
#獲取目錄的糾刪碼策略
hdfs ec -getPolicy -path /input

3、上傳檔案,并查看檔案編碼后的存盤情況
將任意檔案上傳到HDFS上,并查看副本數(當前集群中設定副本數是3,并且創建了5臺DataNode,理論上RS-3-2-1024K需要5臺DataNode支持)
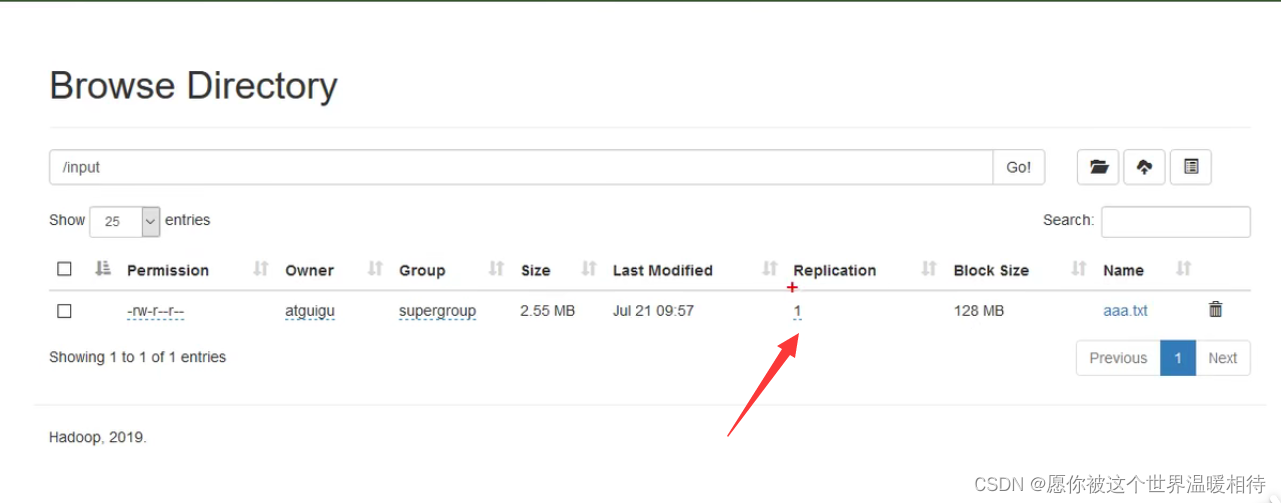
可以看到副本數為1,跟設定的不相同,點擊檔案可以產看資料的存盤情況,可以看到在5臺機器上都有資料,5個機器上的資料也就是我們的3個資料單元以及2個檢驗單元,每個單元在一個機器上,而不是5個單元在一個機器上,每個單元只會存一份
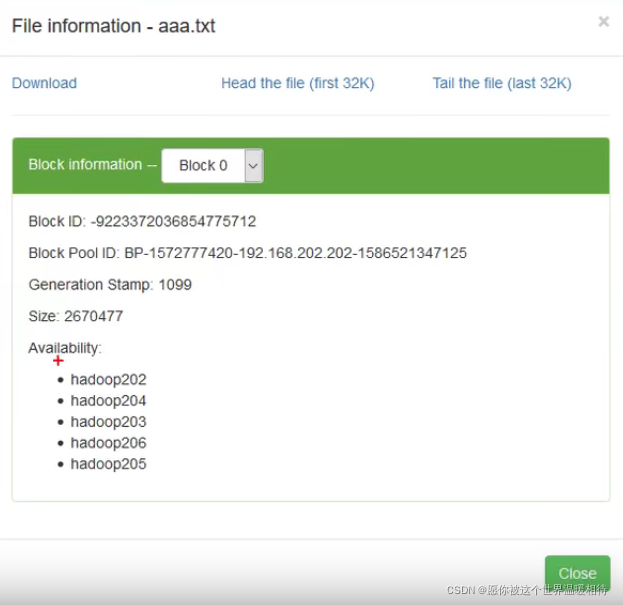
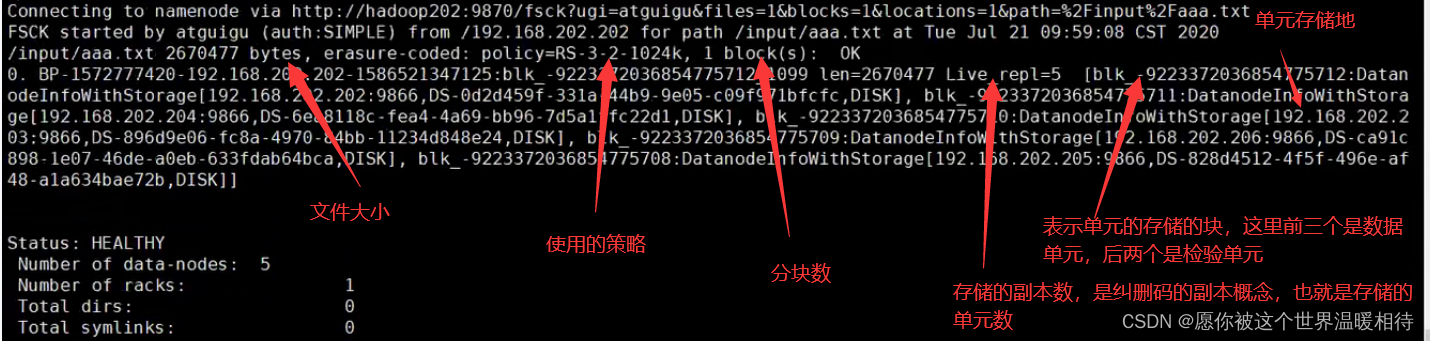
通過以下檔案查看檔案的存盤情況
hdfs fsck /input/aaa.txt -files -blocks -locations
2.3 糾刪碼策略測驗
根據糾刪碼策略的特性,這里關閉其中一個DataNode,那么存盤的5個單元中,就會缺失一個,嘗試是否能正常獲取檔案,使用一下命令獲取檔案到本地
hadoop fs -get input/aaa.txt ./ec
正常而言是會報一下的錯誤,但是該存盤是正常的,打開ec檔案會看到檔案被完整復制到了本地中

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384171.html
標籤:其他