背景
剛學習Flink沒多久,之前用Spark做WordCount實作排序很簡單,因為Spark做的WC是簡單的批處理,直接排序就完事了,但是Flink的流處理需要考慮到狀態(Stateful),并且時間語意我選擇的是ProcessingTime,走了幾次坑之后終于實作,
需求
使用Flink統計Kafka的資料,需要按斬訓動視窗統計最近視窗5min的資料,每1min輸出一次結果,
技術選型:Java,Kafka,Flink
實作
首先需要新建一個Maven專案,pom檔案如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>fule</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
</dependencies>
</project>
Java代碼
package com.jd.wordcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @author 牌牌_琪
* @date 2021/12/16 17:05
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 創建環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
env.enableCheckpointing(60000);
// kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStream<String> dataStream = env.addSource(new FlinkKafkaConsumer011<String>("test", new SimpleStringSchema(), properties));
// 使用flatmap將生資料轉成元組型,如(spark,1),(kafka,1)
DataStream<Tuple2<String, Integer>> flatMap = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
// 水位線,因為使用processingTime,所以watermark沒用到
// flatMap.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple2<String, Integer>>(Time.seconds(2)) {
// @Override
// public long extractTimestamp(Tuple2<String, Integer> element) {
// return getCurrentWatermark().getTimestamp();
// }
// });
// 按單詞就行分組
KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = flatMap.keyBy(0);
// 建立滑動視窗,視窗大小5min,每1min滑動一次
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window = keyBy.window(SlidingProcessingTimeWindows.of(Time.minutes(5), Time.minutes(1)));
// 統計單詞的詞頻,并轉成Word物件(考慮到后邊要用視窗時間觸發onTimer,所以將資料轉成了物件)
DataStream<Word> apply = window.apply(new WindowFunction<Tuple2<String, Integer>, Word, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Word> out) throws Exception {
long end = window.getEnd();
int count = 0;
String word = input.iterator().next().f0;
for (Tuple2<String, Integer> tuple2 : input) {
count += tuple2.f1;
}
out.collect(Word.of(word, end, count));
}
});
// 按照windowEnd屬性分組
KeyedStream<Word, Tuple> windowEnd = apply.keyBy("windowEnd");
// 注意此步使用 KeyedProcessFunction 而不是 ProcessFunction ,因為 State 和 Timers 只能 keyedStream 觸發
SingleOutputStreamOperator<List<Word>> process = windowEnd.process(new KeyedProcessFunction<Tuple, Word, List<Word>>() {
private transient ValueState<List<Word>> valueState;
// 設定State
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<List<Word>> VSDescriptor = new ValueStateDescriptor<>("list-state1",
TypeInformation.of(new TypeHint<List<Word>>() {
})
);
valueState = getRuntimeContext().getState(VSDescriptor);
}
// 處理State,按條件觸發ontimer
@Override
public void processElement(Word value, Context ctx, Collector<List<Word>> out) throws Exception {
List<Word> buffer = valueState.value();
if (buffer == null) {
buffer = new ArrayList<>();
}
buffer.add(value);
valueState.update(buffer);
// 觸發條件:滑動視窗的視窗結束時間+1
// 比如,視窗時間是1000-2000,資料的windowEnd是2000,
// 如果下一條進來的windowEnd是3000,就會觸發1000-2000視窗的onTimer
ctx.timerService().registerProcessingTimeTimer(value.getWindowEnd() + 1);
}
// 觸發,對valueState中的資料按詞頻從大到小排序且輸出
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<List<Word>> out) throws Exception {
List<Word> value = valueState.value();
value.sort((a, b) -> (int) (b.getCount() - a.getCount()));
valueState.clear();
out.collect(value);
}
});
// 列印出來
process.print();
// 執行任務,不執行不會做任何操作
env.execute("WordCount");
}
}
package com.jd.wordcount;
/**
* @author 牌牌_琪
* @date 2021/12/16 17:28
*/
public class Word {
private String word;
private long windowEnd;
private int count;
public static Word of(String word, long windowEnd,int count) {
Word word1 = new Word();
word1.word = word;
word1.windowEnd = windowEnd;
word1.count = count;
return word1;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public long getWindowEnd() {
return windowEnd;
}
public void setWindowEnd(long windowEnd) {
this.windowEnd = windowEnd;
}
@Override
public String toString() {
return "Word{" +
"word='" + word + '\'' +
", windowEnd=" + windowEnd +
", count=" + count +
'}';
}
}
執行結果
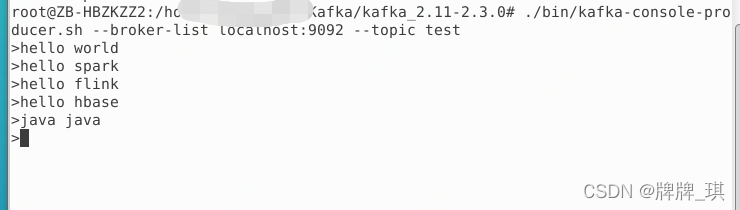
①前三條是0-1min發送的
②第四條是2-3min發送的
③第五條是5-6min發送的
flink任務每一分鐘執行一次統計前五分鐘的資料結果如下

說明:
第一條輸出統計的①
第二條輸出統計的①
第三四五輸出統計的①②
第六條輸出統計的②③
希望可以幫助你
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384180.html
標籤:其他
上一篇:大資料理論與實踐 考試索引