前言
今天小松由于作業需要,研究了一下思必馳的一個語音識別模型,這塊之前沒有接觸過,主要看了語音喚醒這一塊內容,
本地語音喚醒,在做完配置后,只需要實作喚醒回呼介面,實體化喚醒引擎,這個喚醒引擎我理解為啟動喚醒功能的容器,你可以實作很多介面,比如喚醒引擎檢測到說話聲,會有對應的回呼方法,開發人員可以實作這些回呼方法,自定義自己的app的效果
部分回呼方法會帶來約定好的回傳值,比如檢測到聲音變化或者錯誤碼等等,下圖表示整個流程,藍框外面為應用開發來做,框里面除了實作介面回呼,其他的都是sdk的作業

話說這個專案檔案真的拉胯,在sdk檔案里面,本地語音識別,實時短語音識別和本地語音喚醒都是同樣的內容,改了點邊邊角角都當三個item了,甚至介面檔案直接拿jdk的來當……

當然做為開發工程師,我們不能滿足于調包,調參,上圖中藍色框內的部分就是sdk做的事情,我們希望能深入理解,語音是一個比較大的模塊,本文僅討論其中的喚醒識別,由于小松水平有限,若有錯誤,懇請指正
喚醒識別
大家都知道,語音識別現在已經普遍采用了深度學習中的神經網路,而喚醒識別,是語音識別的第一步,類似于tcp鏈接的第一次握手,相比普通的語音識別,需要做更多的作業,主要是語音活動端點檢測(VAD)和喚醒詞識別技術
VAD
現在你手上有一個iphone,你只需要說:“嘿 siri”,siri就會回答你,類似的,小度,小愛,小冰都是一樣的,那么,就這一句話,你是否想過,發生了什么事情呢?
- 特征提取,從原始音頻中提取時域或者頻域特征,類似于你不管在微信給別人發什么訊息,在計算機看來,都會被轉成2進制,聲音的特征很豐富,有能量,熵,基頻等
- 初步決策:這里是分析中心,每一個輸入的音頻片段會被切分為語音片段和非語音片段,我們常用的降噪耳機,就是在這里去區別人聲與環境噪聲,進行降,這里的演算法非常復雜:可以設立規則,比如均勻分貝的聲音大概率是環境噪音等,但是不準確;也可以進行大資料統計深度學習,較準確但是可解釋性差一點
- 后處理:主要是對初步決策的結果進行平滑,每一個音頻片段都是以幀的形式傳入,在處理1,2,3幀時,可能初步決策認為1,3,是人聲,2是環境聲,這個理論上不太可能,因為人說話應該是連續的,不大可能中間突然沒了一幀,然后瞬間有了,所以后處理就是將這些可能的誤差進行修正,避免頻繁切換語音狀態
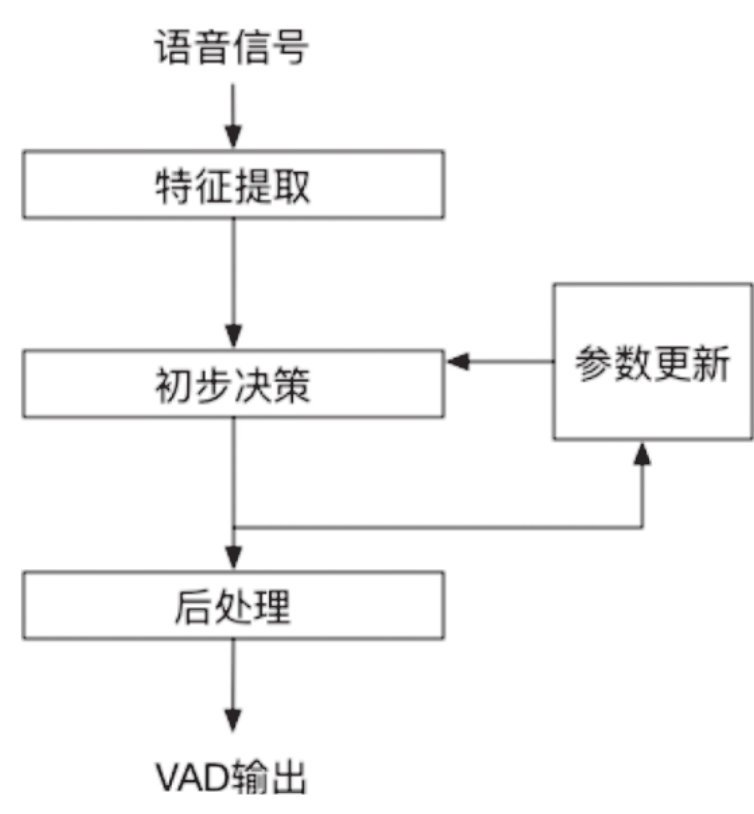
從上面可以知道,最關鍵的部分是初步決策中選擇何種VAD演算法區分人聲與環境聲,我們希望這個VAD演算法能在嘈雜環境,也就是高信噪比下能區分人聲,同時有較好的魯棒性
關鍵在于,**人聲和噪聲的區別是什么?**肯定是有區別的,不然人耳為什么能區分?基于這個角度,出現了下面這些演算法
-
短時能量檢測
這種方法認為,能量是語音與噪聲最大的區別,語音的能量更大,同時由于語音本質是非線性的(再嘮叨的人也不會連續不斷的說話),我們只需要統計這些非線性聲音的能量,求一個平均值,然后未來再出現類似能量的聲音,我們就認為是人聲,公式如下
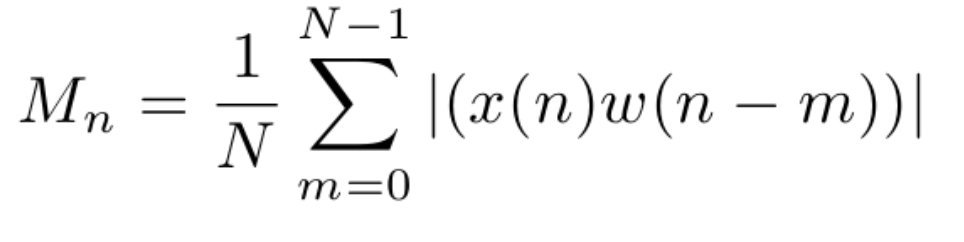
開發同學不必深究公式,簡單說就是x(n)為原生聲音,w(n - m)為窗函式,表示取樣長度,然后最后求平均值即可
? 這個方法在環境聲比較固定,且比較小,比如持有intel 版本的mac程式員,使用這種方法,能比較好的過濾這種mac的風扇聲(intel給爺爬,m1 yyds)
? 局限性也比較明顯,那就是適用范圍窄,在較為復雜的環境下,比如,公司,馬路,菜市場這些地方,就幾乎沒有什么作用
-
基于DNN
影像,語音,除了我們能看到,能聽到的內容,其實還隱藏著大量的特征資訊,只是我們的器官沒有能力去決議,而深層神經網路,可以在多次卷積-激活-池化下提取出特征,進行聲學特征向量建模,這種方法,某種程度上來說,是萬能的,只要兩個東西有區別,神經網路就幾乎可以提取到他們的不同之處
一般針對語音,提取的是短時頻譜特征,如MFCC梅爾倒譜系數,PLP(感知線性預測),FBANK相關性濾波器組特征,至于為什么選他們三,很簡單,因為測驗發現神經網路提取他們三更容易……,
提取程序如下

語音通常是一段連續的波形語音,所以首先會將其轉換為離散的序列向量,稱為特征向量,每隔大概10ms做一個切分,這些長度10毫秒的每一個向量稱為”幀“,
然后進行加窗,因為聲音前后是有關系的,被生硬的切分為很多幀后需要一些平滑窗進行平滑處理,減少邊界效應
FFT就是大家熟知的快速傅里葉變換,是一種數學變換,將時域特征轉換為頻域特征
最后進行濾波器組分析,這里分析出來的特征主要就是 FBANK, MFCC,PLP
將這些特征取出后,自然就是進行訓練了,建立多層神經網路,不斷的訓練,最后將輸出結果進行后處理
從結果上看,DNN的語音斷點檢測的準確率提高了很多,但是在嘈雜環境下效果仍然不佳
關鍵在于,我們其實什么都沒做,全交給DNN去自己發現,而面對紛繁復雜的聲音世界,他是沒有辦法完全窮盡的,所以有一些特征,他是學不會的,或者很難學的,我們需要自己發現,并告知他,這樣才能更大程度提高他的準確性和魯棒性
下圖可以簡單總結一下
| 演算法 | 原理 | 優點 | 缺點 |
|---|---|---|---|
| 短時能量檢測 | 計算人聲能量的平均值 | 簡單,噪聲小且穩定時效果較好 | 適用范圍窄,功能弱 |
| DNN | 深度學習提取特征 | 效果更好,適用性更好 | 可解釋性差,優化較為困難 |
| DNN+ 輸入特征 | DNN+人工輸入特征 | 應該是目前最好的解決方案 | 很難實作 |
喚醒詞識別
上面說了針對語音端點檢測的演算法原理和兩種現有的演算法,我們回到siri,現在iphone已經在嘈雜環境下用DNN識別出了你的語音,那么接下來就是解碼的程序,將你的語音轉為系統能識別的指令
當我們說:“你好,siri”的時候,siri并不會理我們,所以,我們可以推測,siri的啟動指令,一定是通過“嘿,siri”轉換而來,那么,這就是使用了關鍵詞檢測
所以,iphone在用DNN訓練時,一定是針對這句話進行了多種語言,多種聲音模式的大資料訓練,并構建了一個關鍵詞聲學模型,這種針對于關鍵詞的檢測演算法有很多種,其中一種常用的是基于隱馬爾科夫模型的關鍵詞檢測
隱馬爾科夫模型
聽著很懸,但是思想不難,只需要為關鍵詞構造一組HMM模型,稱為keyword 模型,為非關鍵詞構造另一組HMM模型,稱為Filler模型,當接受到一個關鍵詞的時候,如果發現他屬于Filler模型,那么就cut掉
我們都說,幸福的家庭都是一樣的幸福,而不幸的家庭各有各的不幸,在這里,也一樣,keyword模型只有一個,而Filler模型是一個統稱,他的HMM模型,可以有很多個
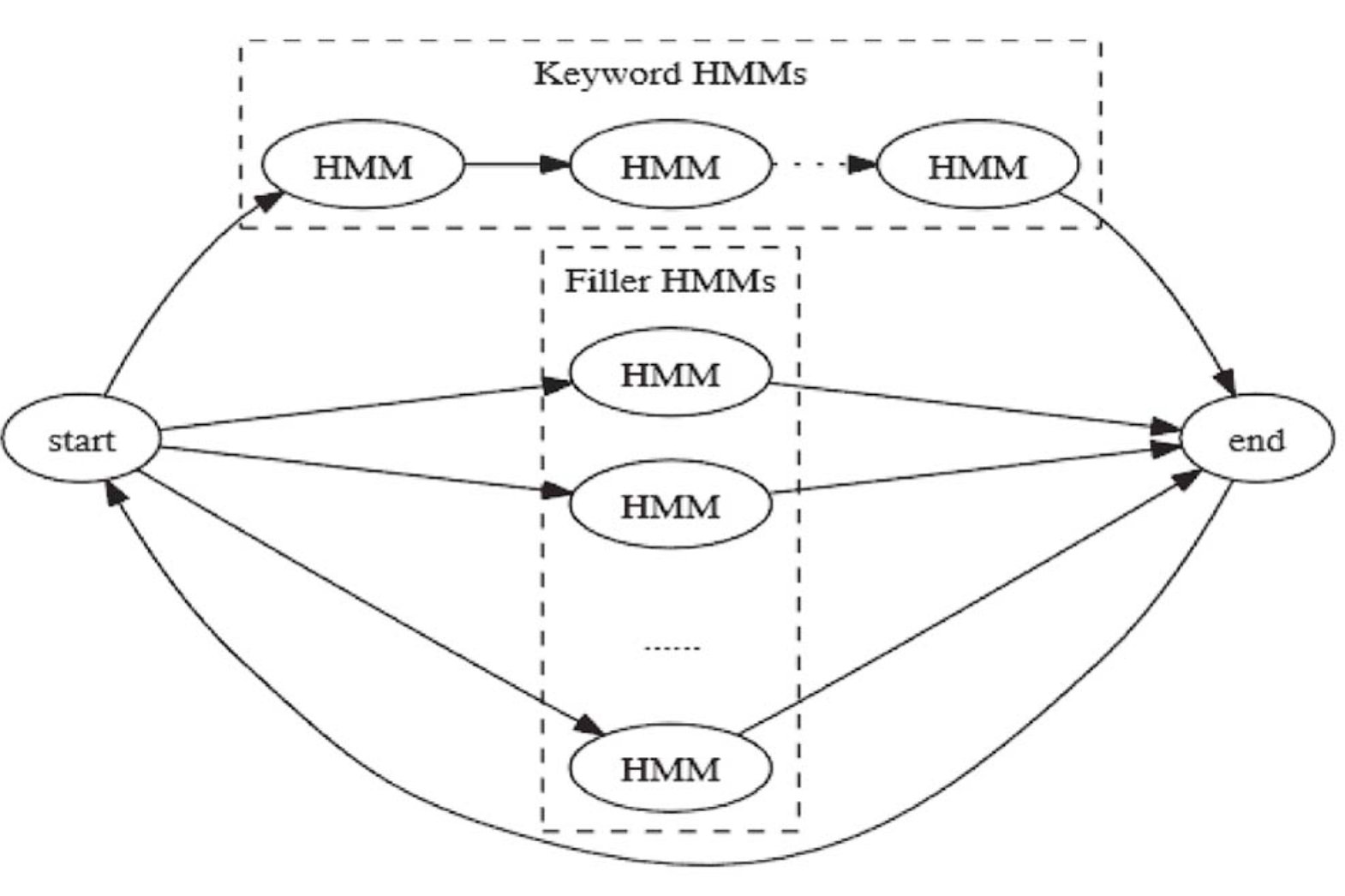
這個模型的核心作用就是過濾出關鍵詞,并將他通過HMM模型轉換為系統可識別的信號,這一程序就是解碼的程序,將聲學型號進行轉換
解碼
你可能會說,這還不簡單,我們直接硬編碼就行了,反正喚醒識別只用說“嘿,siri"
當然不是!喚醒識別雖然只有這么一句,但是后續用戶還會說很多不一樣的話,而解碼器是需要在整個語音互動的程序起作用的,而不僅僅是喚醒這一塊
但是,世界上的不同的話何止千萬?難道讓服務器去窮盡這宛若繁星的句子嗎?肯定不是,本質上還是檢測句子中的關鍵詞,進而推斷這一句話想表達的意思
所以解碼程序,本質上還是關鍵詞檢測
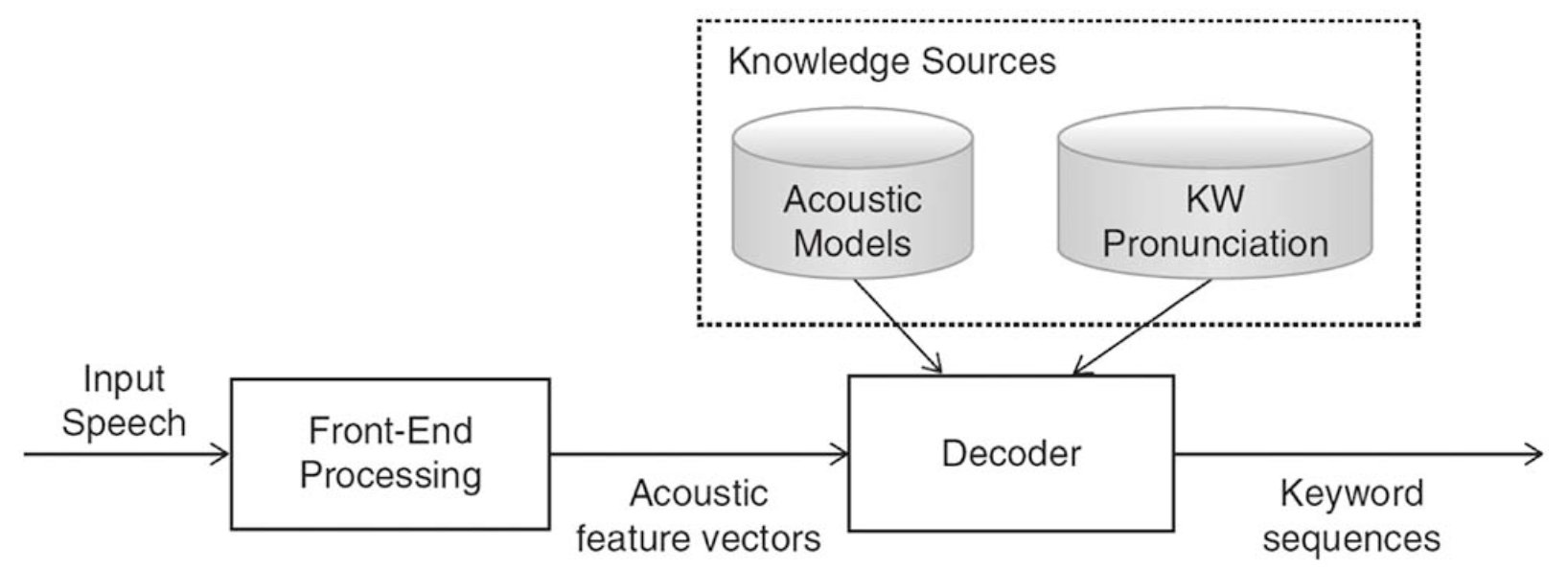
上圖就是解碼器所處的位置,既然要做關鍵詞檢測,就必須有一個詞庫KW進行配對,同時需要一個Acoustic Models模型,區分出每一句話中的關鍵詞,當然這里已經不屬于喚醒識別的范疇了,本文僅討論喚醒識別,有興趣的同學可以去研究哦,我后續也會繼續研究的~
后記
這還是小松第一次較為系統的總結語言識別相關知識,總結下來就是兩步
- 語音檢測VAD DNN演算法過濾噪聲
- 喚醒詞識別 隱馬爾科夫模型識別關鍵詞,解碼器匹配詞庫解碼
我本科時接過百度的apollo,百度的語音模型算是國內比較領先的了,具體使用也很簡單,就是將關鍵詞填進去,然后當一句話包含那個關鍵詞時,就可以被模型檢測出來,回傳相應的結果,
比如在后臺,填入一個”吃飯“,然后在app中實作回呼函式:呼叫地圖,搜索飯店
這樣,你對著集成了apollo模型的app說:吃飯,app就會自動打開地圖搜索飯點
還挺好玩,有興趣的同學可以嘗試一下,
小松很開心生活在這個知識爆炸的時代,有太多我曾經好奇的問題都有科學的答案,即使沒有現成的答案,也有科學的方法幫助我們去尋求答案,終生學習,一起進步!
參考書籍《人工智能:語音識別理解與實踐》
個人簡介
>我是小松,20屆,末流985本科,曾參與開發手機QQ,現在不斷在b站更新題解視頻,手繪圖解和代碼實戰,專注android與演算法,文章首發與公眾號小松漫步
>另外建有學習群,已經有上百位愛學習的小伙伴,每周與群友進行模擬面試,互相鼓勵學習,有意參與可以加我微信 cs183071301,加了后,請主動說自己的技術堆疊和稱呼,然后我拉你進群(務必備注自己哦)
>每周周六晚9點大家可以一起線上參與模擬遠程面試,b站【小松不漫步】直播,大家快來參與吧
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384431.html
標籤:其他