訊息佇列面試題
題目來自于中華石杉,解決方案根據自己的思路來總結而得,
題目主要如下:
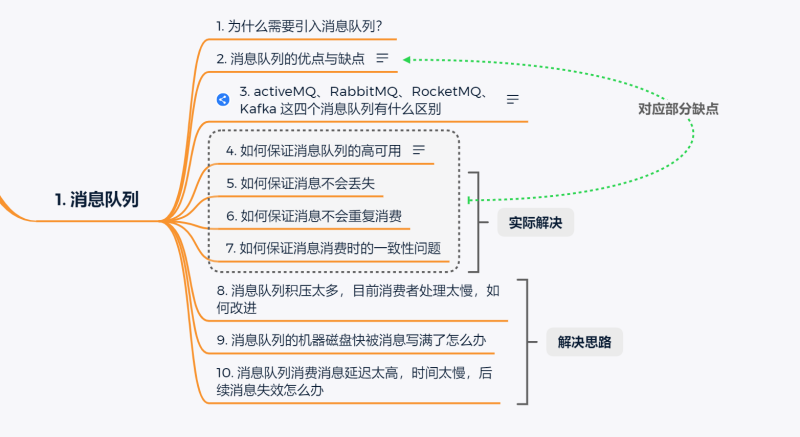
1. 為什么要引入訊息佇列?
訊息佇列的引入可以解決3個核心問題:
- 解耦
- 異步
- 削峰
- 解耦
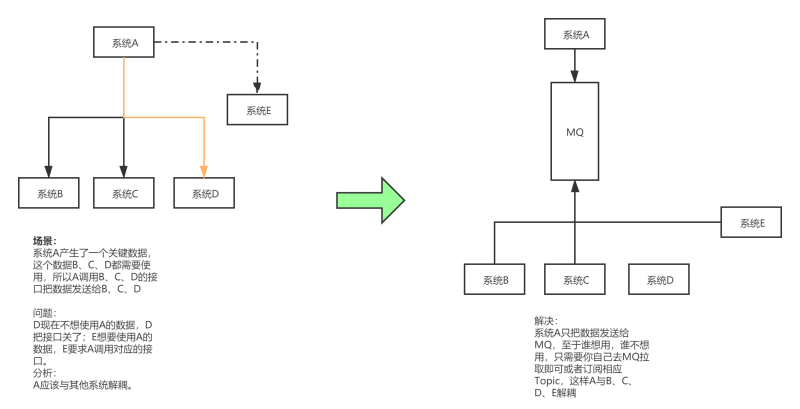
在一個專案中,如果一個模塊A產生的一個關鍵資料,需要呼叫其他模塊介面服務;而需要呼叫的介面很多,又不確定之后是否還需要將資料傳給其他模塊的介面時,這時可以使用訊息佇列,使用了訊息佇列之后,模塊A不需要在對接各個模塊,而是直接對接訊息佇列,這樣一來,當其他的模塊需要這個資料時,也不用再修改A資料,而是去到MQ中訂閱這個Topic,使得模塊A與其他模塊之間耦合度降低,
- 異步
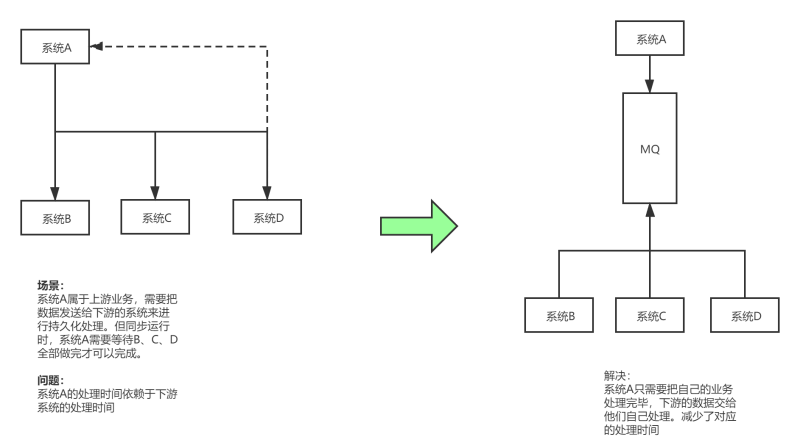
在一個專案中,如果模塊A的請求處理需要20ms,而模塊A又依賴了模塊B,模塊C ,模塊D ,在A請求處理結束后,A需要呼叫
模塊B,C,D的對應請求處理,這時B請求處理需要100ms,C 需要200ms,D 需要400ms,這樣一來,總體一個請求的總時長為
20 + 100 + 200 + 400 = 720 ms 遠遠大于模塊A的請求處理時間,另一方面,模塊B 模塊C 模塊D之間 并沒有順序關系,
這時可以引入訊息佇列 ,模塊A在請求處理結束后,將自己的資料發送給訊息佇列MQ,由B,C ,D去訊息佇列獲取資料,自行處理
模塊A在處理完成后直接回傳給客戶端處理結果,而不需要等待B,C,D處理結束,如此一來,一個請求處理的就只需要計算
模塊A的處理時間=20ms,大大提高了用戶體驗,
- 削峰
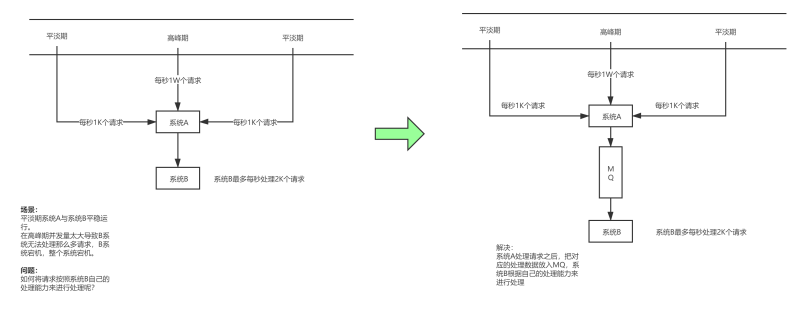
如果一個系統只能一秒鐘處理5000個請求(MySQL一般只能2000QPS),而在特殊時期就只要1個小時的時間段內,請求量暴漲,一秒鐘來了1W個請求,從而系統會之間宕機,但這種情況可能在平時不會發生,不需要升級相應的服務器配置,
問題在于在1小時的時間段,如何把請求從10000QPS 下降到5000QPS 使得系統能夠正常運轉而不發生宕機,
這時候可以引入訊息佇列,假設模塊A負責處理請求,模塊B負責將資料持久化到資料庫,模塊A在接受到請求時,把請求交給訊息佇列,由訊息佇列來緩解對應的請求壓力,類似于Buffer建立一個緩沖區,模塊B根據自己的請求處理速度去到訊息佇列中去消費資料,這樣一來就解決了對應特定時間段的削峰問題,
- 要結合實際專案來說明:
體現上述的三個點,
2. MQ有什么缺點?
任何技術都是一把雙刃劍,在引入訊息佇列的同時必定也會伴隨著相應的問題,正如《人月神話》中所說,沒有銀彈,
訊息佇列的引入會帶來3個核心的問題:
- 系統可靠性降低
在引入MQ時,MQ作為了中間層,這就使得模塊與對應的MQ是緊耦合的關系,一旦MQ宕機,下游服務即使正常運行,但整個系統卻無法使用,這個問題的解決方式是 MQ的高可用,使得MQ高可用,不會那么容易宕機達到5個9,
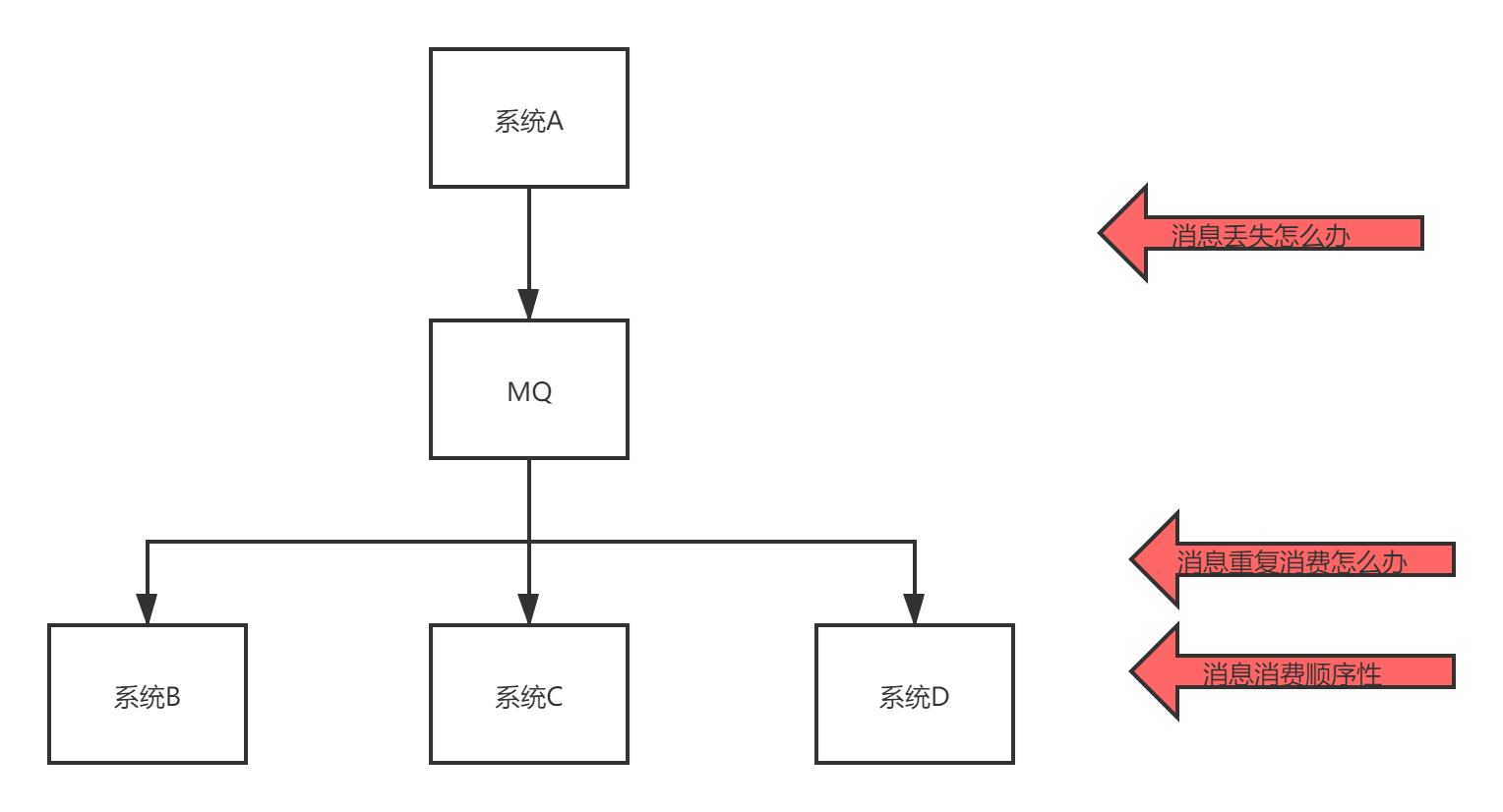
- 系統復雜度提高
引入MQ,需要考慮的問題變復雜,隨之而來的問題是- 訊息丟了怎么辦
- 重復消費訊息問題
- 訊息的順序問題
這幾個問題都有對應的解決方案,
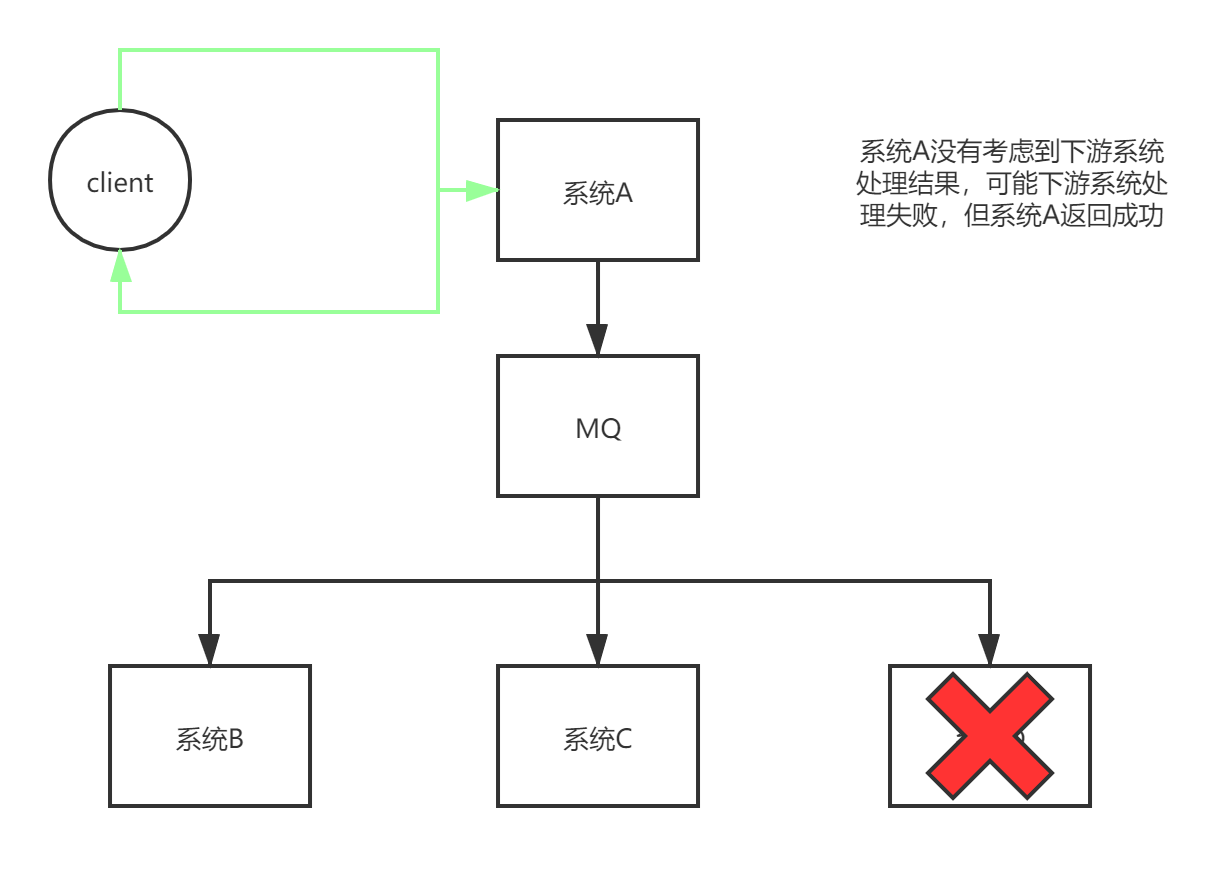
- 處理結果的最終一致性問題
引入MQ會導致處理結果的最終一致性問題,因為模塊A與其他模塊之間解耦,從而模塊A不知道其他模塊的處理結果
這就導致模塊A以為處理結果OK,但實際上可能模塊B處理結果失敗,這也是異步化所帶來的最終一致性問題,
3. 你都了解過哪些MQ? 他們之間有什么區別嗎?
這個問題可以延伸為技術選型問題,關于這個問題可以認為憑什么你選擇了這個MQ,而沒有選擇其他MQ,對應可以擴展為spring-security 與shiro 都是安全框架都實作了Oauth2協議,而且shiro是輕量級的,為什么你選擇了Spring-Security這個安全框架這個問題比較考察技術廣度,
首先我了解過的MQ有:activeMQ,RabbitMQ,RocketMQ,Kafka
| activeMQ | RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 并發量 | 萬級 | 萬級 | 十萬級 | 萬級 |
| 處理時長 | 毫秒 | 微妙 | 毫秒 | 毫秒 |
| 開發語言 | Java | ErLang | Java | Java Scala |
| 功能完備 | 完備 | 完備 且提供了插件與管理界面 | 完備 | 完備 |
| 常用場景 | 小型專案demo | * | * | 大資料領域日志處理、實時計算 |
| 社區活躍度 | 較低 | 高 | 高 | 高 |
activeMQ社區活躍度較低,不建議使用,
RabbitMQ社區活躍度高,更新版本頻繁,但使用開發語言為ErLang , 當有定制化需求無法進行擴展
RocketMQ 阿里出品,但存在著后續專案不更新情況,這就使得企業自行維護相應的功能或者定制化功能
Kafka 大資料領域 主要用來進行實時計算,日志采集的訊息佇列,功能相比于其他MQ少,但是kafka是大資料領域公認的訊息佇列
如果對功能有要求,小公司可以選擇RabbitMQ, 有技術團隊的大公司可以使用RocketMQ,大資料生態為了與其他組件配合所以使用Kafka
4. 如何保證MQ的高可用
- RabbitMQ的HA
RabbitMQ的解決方式為=>集群模式 + 鏡像
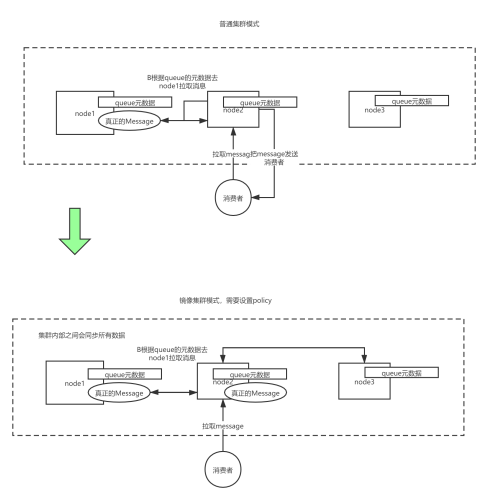
普通集群模式:
queue創建之后,如果沒有其它policy(策略),則queue就會按照普通模式集群,對于Queue來說,訊息物體只存在于其中一個節點,A、B兩個節點僅有相同的元資料,即佇列結構,但佇列的元資料僅保存有一份,即創建該佇列的rabbitmq節點(A節點),當A節點宕機,你可以去其B節點查看,./rabbitmqctl list_queues發現該佇列已經丟失,但宣告的exchange還存在,
當訊息進入A節點的Queue中后,consumer從B節點拉取時,RabbitMQ會臨時在A、B間進行訊息傳輸,把A中的訊息物體取出并經過B發送給consumer,所以consumer應平均連接每一個節點,從中取訊息,
該模式存在一個問題就是當A節點故障后,B節點無法取到A節點中還未消費的訊息物體,如果做了佇列持久化或訊息持久化,那么得等A節點恢復,然后才可被消費,并且在A節點恢復之前其它節點不能再創建A節點已經創建過的持久佇列;如果沒有持久化的話,訊息就會失丟,這種模式更適合非持久化佇列,
只有該佇列是非持久的,客戶端才能重新連接到集群里的其他節點,并重新創建佇列,
假如該佇列是持久化的,那么唯一辦法是將故障節點恢復起來,
鏡像集群模式:
核心在于:鏡像集群會同步訊息
該模式解決了上述問題,其實質和普通模式不同之處在于,訊息物體會主動在鏡像節點間同步,而不是在consumer取資料時臨時拉取,該模式帶來的副作用也很明顯,除了降低系統性能外,如果鏡像佇列數量過多,加之大量的訊息進入,集群內部的網路帶寬將會被這種同步通訊大大消耗掉,所以在對可靠性要求較高的場合中適用,
一個佇列想做成鏡像佇列,需要先設定policy,然后客戶端創建佇列的時候,rabbitmq集群根據“佇列名稱”自動設定是普通集群模式或鏡像佇列,但這不是分布式存盤,而是多節點主備存盤,相比于Kafka的分布式架構會多消耗資源, - Kafka實作高可用
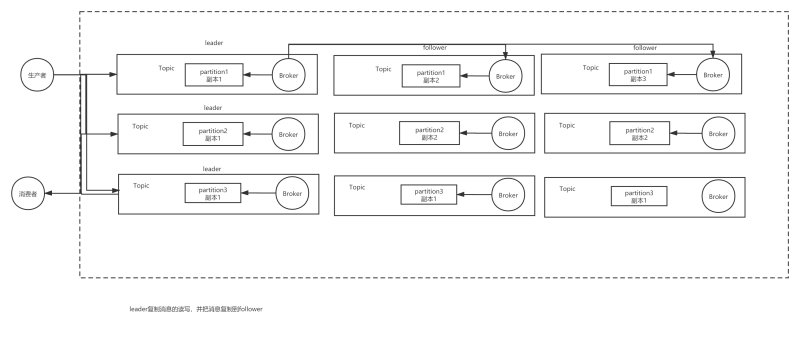
Kafka的高可用主要是通過Kafka通過把每個Topic中的訊息分成多個Partition,每個Partition做一個集群,而每一個Partition內部集群通過選舉得到一個leader,其他是follower,leader復制訊息的讀寫,并把訊息復制到follower,Kafka在發送訊息時,只有當每個partition的follower復制到了訊息才確認訊息已經被存盤,
5. 如何保證訊息不會丟失?
- RabbitMQ方式
1.1 生產者方面- 開啟RabbitMQ的事務方式txSelect(),當生產者寫入訊息失敗時,采取重試機制,但這個寫入是同步的,
- 使用confirm方式: 其中confirm也可以使用三種方式:
- 普通confirm
- 批量confirm
- 異步confirm 設定監聽器
channel.confirmSelect();
//普通confirm
if (channel.waitForConfirms()) {
System.out.println("訊息發送成功" );
}
//批量confirm 失敗會報錯
channel.waitForConfirmsOrDie();
//異步監聽confirm
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("未確認訊息,標識:" + deliveryTag);
}
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println(String.format("已確認訊息,標識:%d,多個訊息:%b", deliveryTag, multiple));
}
});
1.2 RabbitMQ方面
RabbitMQ在記憶體快取訊息,當MQ宕機時,會發生訊息丟失現象,這一點需要RabbitMQ將訊息持久化到硬碟上,減小訊息丟失的可能
1.3 消費者方面
RabbitMQ默認是autoAck=true,這樣就使得消費者在接受到訊息時,立馬告知MQ我消費了資料,但還沒有來得及處理,所以需要把autoAck=false,之后當訊息處理完成之后手動提交,
2 kafka方面
- 生產端
資料丟失發送在leader向follower同步訊息的時候,leader宕機使得訊息丟失,
解決方案是設定4個引數:- replication.factor = n > 1 設定partition有多少個副本數
- kafka咋服務端設定mini.sync.replicas=1 即一個leader至少保證有一個follower存活
- producer在發送訊息時,設定acks=all 設定所有訊息必須全部寫入replication后回傳成功,
- retries=Integer.MAX 把重試次數調制最大
- 消費端
在消費者端關閉自動確認訊息,這樣需要手動確認 保證訊息不會丟失,
6. 如何保證訊息不會重復消費?
- 在消費者消費訊息時,把對應的唯一值放入HashSet 或者Redis來避免同一條訊息消費多次
- 使用資料庫的唯一鍵約束來報錯處理
7. 如何保證消費者消費訊息時訊息的順序性?
訊息佇列本身就是為了把多個任務解耦并行化處理,如果要保證訊息的順序訊息,實際上就是取消并行處理,改成串行處理,
- RabbitMQ
將一組訊息放入同一個queue,這樣就只會有一個consumer來消費這個queue中的資料,在consumer內部采用佇列的方式來處理順序訊息 - Kafka
生產者寫訊息時,每次寫入一個topic,將partition對應key值修改同一key,這樣訊息只會進入一個partition,也只有一個消費者在進行消費,之后也采用記憶體佇列的方式順序處理訊息,
8. 訊息佇列積壓太多,目前消費者處理太慢,如何改進?
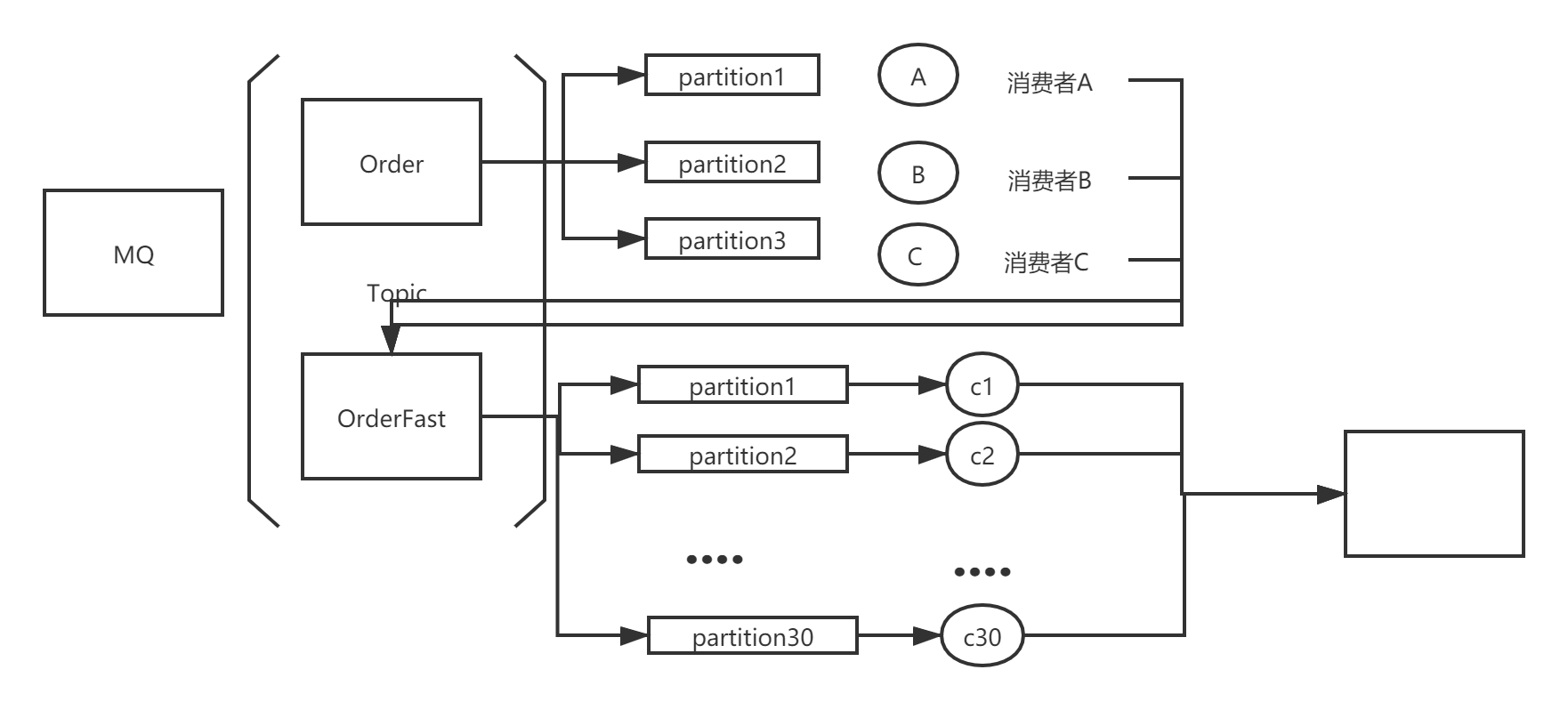
目前的消費者難以在短時間內處理這么多條訊息,考慮引入多個消費者,但引入這多個消費者只用于消費當前訊息,并不是長期使用,假定長期使用的消費者為A、B、C 訂閱的Topic是Order,新申請3 * 10~20 = 30~60個機器 作為新的消費者組GroupNew, GroupNew 訂閱新的Topic - OrderFast,從這個topic中獲取訊息并消費,將原有長期使用的消費者組修改代碼,不處理訊息 直接將訊息寫入到新的Topic - OrderFast
9. 訊息佇列的機器磁盤快被訊息寫滿了怎么辦?
- 可以采取上述方案,不同的是寫入到另外一臺MQ中,而不是在本機的Topic
- 下一個訊息直接丟棄不處理,到訊息佇列機器恢復之后,將生產者與消費者之間通過代碼查詢出對應的缺失部分,再進行補償式操作,
10. 訊息佇列消費訊息太慢,訊息過期失效怎么辦?
- 生產環境設定訊息不過期
- 如果已經過期失效,那么需要查出過期失效的訊息,重新進行補償式操作
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/3851.html
標籤:其他
下一篇:自制正則運算式測驗工具