文章目錄
- 一、摘要
- 二、介紹
- 三、初步作業
- 3.1 ifdnamf框架的概述
- 3.2 基于特征交叉的資訊融合
- 3.3 基于注意機制的交叉特征融合
- 3.4 基于多隱層的GMF結構
- 四、實驗
- References
論文名稱:Information Fusion-Based Deep Neural Attentive Matrix Factorization Recommendation
原文地址:IFDNAMF
?本系列歷史文章?
【推薦系統論文精讀系列】(一)–Amazon.com Recommendations
【推薦系統論文精讀系列】(二)–Factorization Machines
【推薦系統論文精讀系列】(三)–Matrix Factorization Techniques For Recommender Systems
【推薦系統論文精讀系列】(四)–Practical Lessons from Predicting Clicks on Ads at Facebook
【推薦系統論文精讀系列】(五)–Neural Collaborative Filtering
【推薦系統論文精讀系列】(六)–Field-aware Factorization Machines for CTR Prediction
【推薦系統論文精讀系列】(七)–AutoRec Autoencoders Meet Collaborative Filtering
【推薦系統論文精讀系列】(八)–Deep Crossing:Web-Scale Modeling without Manually Crafted Combinatorial Features
【推薦系統論文精讀系列】(九)–Product-based Neural Networks for User Response Prediction
【推薦系統論文精讀系列】(十)–Wide&Deep Learning for Recommender Systems
【推薦系統論文精讀系列】(十一)–DeepFM A Factorization-Machine based Neural Network for CTR Prediction
一、摘要
推薦系統的出現,有效地緩解了資訊過載的問題,而傳統的推薦系統,要么忽略用戶和物品的豐富屬性資訊,如用戶的人口統計特征、物品的內容特征等,面對稀疏性問題,要么采用全連接網路連接特征資訊,忽略不同屬性資訊之間的互動,本文提出了基于資訊融合的深度神經注意矩陣分解(ifdnamf)推薦模型,該模型引入了用戶和物品的特征資訊,并采用不同資訊域之間的交叉積來學習交叉特征,此外,還利用注意機制來區分不同交叉特征對預測結果的重要性,此外,ifdnamf采用深度神經網路來學習用戶與專案之間的高階互動,同時,作者在電影和圖書這兩個資料集上進行了廣泛的實驗,并證明了該模型的可行性和有效性,
二、介紹
近年來,互聯網用戶和應用程式等資料源的數量和型別迅速增加,導致互聯網資訊呈指數級增長,創建大量資料、收集和處理,這導致了大量的資料供應和用戶的個性化需求之間的巨大矛盾,這個龐大的資料集使用戶難以快速獲得滿足其個性化需求的資訊,這被稱為資訊過載,如何平衡海量資料與用戶的個性化需求,快速準確地為用戶提供海量資料的個性化資訊已成為亟待解決的問題,
推薦系統被認為是緩解這一問題的有效解決方案,通過分析用戶的偏好,推薦系統可以主動向符合興趣的用戶推薦資訊,而傳統的推薦系統通常采用單一形式的資料,例如基于矩陣分解的推薦系統往往是基于顯式反饋資料的評級矩陣或隱式反饋資料的互動矩陣的分解來完成推薦任務,
采用單一形式的輸入資料資訊不足,容易受到噪聲資料的影響,因此難以準確、全面地對用戶和專案進行建模,難以滿足用戶對專案的新穎性的需求,這限制了推薦系統的性能,事實上,除了評級資訊外,還有其他輔助資訊,如用戶的社會人口統計學特征(年齡、性別、職業等),該專案的內容功能(類別、介紹等)等等,推薦系統采用資訊融合技術,可以將輔助資訊集成到推薦系統的建模程序中,使推薦系統能夠更全面地對用戶偏好和專案表示進行建模,提高模型的表達能力,提高推薦的性能,提高推薦結果的新穎性,
本文提出了基于資訊融合的深度神經注意矩陣因子分解(ifdnamf)推薦模型,基于深度神經網路可以融合任意連續特征和類別特征的特征,我們將輔助資訊引入到模型中,在進行資訊融合時,為了完成不同資訊域特征之間的互動式融合,并以有針對性的方式獲得不同的交叉特征,我們采用了element-product,同時,為了區分不同交叉特征對推薦結果的重要性,我們還引入了注意機制來學習不同交叉特征的權重,
此外,基于矩陣分解的推薦系統還受到了簡單線性內積的局限性,另外,在傳統矩陣分解的內積程序中,所有維數的結果以相同的權值累積,可以看作是連接權值均為1,從而得到最終的標量結果,這兩種方法都使得建模用戶和專案之間復雜的非線性關系是無效的,為了解決這些問題,He等人提出了廣義矩陣分解(GMF),該方法利用神經網路通過激活函式賦予MF非線性學習能力,并通過引入權重矩陣將不同維度的值與不同的權值相結合,
GMF有能力模擬用戶和專案之間的二階非線性互動,該模型的表達能力得到了顯著的提高,盡管有這些優點,但由于網路結構較淺,GMF無法有效捕獲用戶與資訊更豐富的專案之間的高階互動,這可能會限制推薦系統的性能,因此,在ifdnamf中由非線性元素乘積得到的二階互動上引入了隱層,通過深度神經網路,我們可以模擬用戶與專案之間復雜的非線性高階互動,
我們所提出的方法的主要貢獻可以總結如下,
-
首先提出了一種新的推薦模型,即基于資訊融合的深度神經注意矩陣分解(ifdnamf)推薦模型,其中引入輔助資訊,幫助模型更全面、具體地描述用戶特征和專案特征;
-
然后,我們提出了一種新的資訊融合方法,即采用不同資訊域之間的內積來學習交叉特征,這樣ifdnamf就可以獲得包含輔助資訊之間的高值資訊的“和”關系,同時,為了區分不同交叉特征對推薦結果的重要性,我們還引入了注意機制來學習不同交叉特征的權重;
-
最后,我們在兩個資料集上進行了廣泛的實驗:電影鏡頭和圖書,實驗結果表明,該方法具有優異的應用性能,
三、初步作業
在本節中,我們首先介紹ifdnamf推薦模型的框架,并描述它如何作業,然后,我們闡述了我們提出的ifdnamf如何解決現有方法的局限性,即完成特征在不同輔助資訊特征域之間的交叉,更全面地建模用戶偏好和專案表示,采用注意機制學習資訊融合時不同交叉特征的重要性,并利用深度神經網路對二階和非線性高階互動進行建模,
3.1 ifdnamf框架的概述
為了充分利用輔助資訊更全面、準確地建立用戶偏好和專案表示模型,同時學習用戶與專案之間復雜的非線性高階互動,進一步提高推薦性能,提出了基于資訊融合的深度神經注意矩陣分解推薦模型,其中在融合資訊時,采用元素級產品操作,有針對性地完成不同資訊域特征間的互動,
此外,ifdnamf采用注意機制來區分融合程序中不同交叉特征對最終潛在特征表示的重要性,此外,利用深度神經網路建模用戶與專案之間復雜的非線性高階互動,圖1顯示了模型框架,該框架主要由輸入層、互動層、池化層、GMF層、隱藏層、輸出層6個部分組成,
輸入層獲取用戶和專案的連續特征和類別特征,包括用戶ID、專案ID等屬性特征,通過嵌入技識訓取用戶和專案的嵌入向量,然后通過這些嵌入向量之間的成對元素乘積運算捕獲交叉特征,然后,根據從注意中學習到的不同權重的注意融合機制,將交叉特征進入池化層獲取用戶和專案的潛在特征的機制,然后ifdnamf通過對這些潛在特征執行元素級操作,對用戶和GMF層中的專案之間的二階互動進行建模,通過隱藏層的深度神經網路對GMF層的結果進行迭代訓練,以模擬用戶與專案之間的高階互動,最后,在輸出層中生成用戶對專案的預測評級,并向用戶推薦一個基于預測評級的Top_N推薦串列,
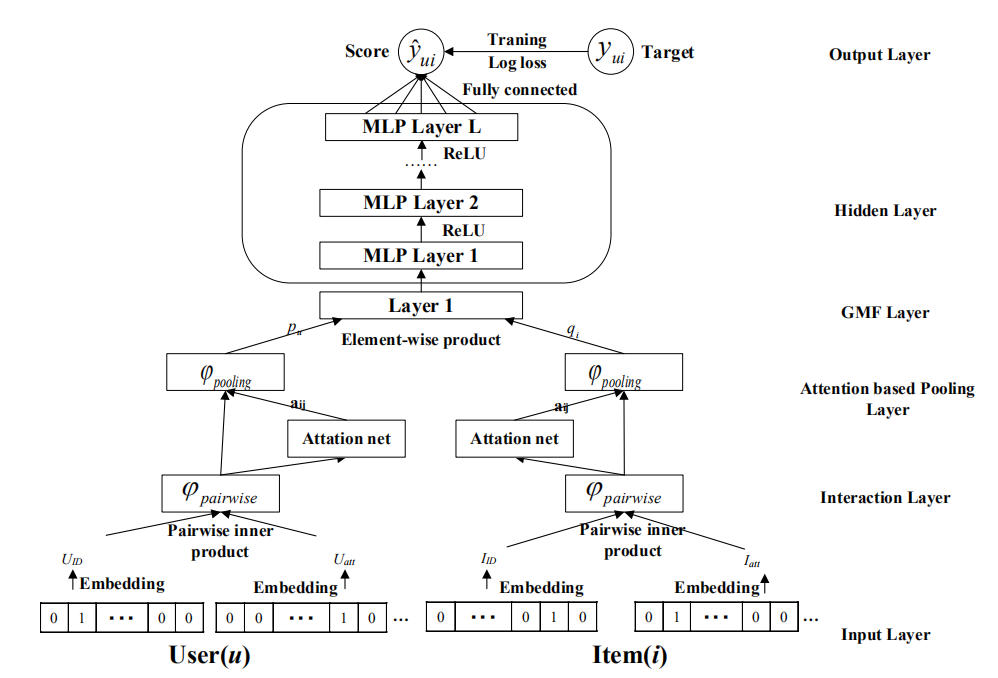
3.2 基于特征交叉的資訊融合
為了引入特征間“和”關系中所包含的資訊,我們提出了一種在ifdnamf推薦模型中基于特征交叉的資訊融合方法,具體的實作如圖1中的互動層所示,在融合輔助資訊時,采用不同特征之間的元素級乘積,有針對性地完成不同資訊域特征之間的互動,得到不同的交叉特征,即,在用戶ID與每個用戶屬性特性之間執行元素級產品,在用戶屬性特性之間執行成對元素級產品,采用元素級產品建模專案ID與每個專案屬性特性之間的互動以及專案屬性特性之間的互動,圖1中的成對元素級乘積是上述嵌入向量之間的元素級乘積的操作,通過嵌入向量之間的成對元素乘積,我們可以得到用戶和項的多個交叉特征,定義為:
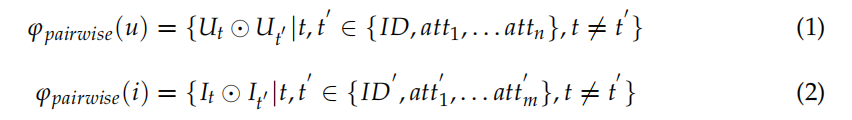
同時,我們比較了ifdnamf模型與采用全連通網路的傳統推薦模型的性能,并證明了我們提出的ifdnamf的有效性,該模型在4.2節中進行資訊融合時不同資訊域特征之間的互動作用,
3.3 基于注意機制的交叉特征融合
在這里,我們采用注意機制來學習不同的交叉特征對預測結果的重要性,從而融合不同的交叉特征,具體來說,通過將基于注意機制的池化層注意網應用于不同的交叉特征,分別學習了用戶的不同交叉特征和專案aij和a0ij的注意得分,這代表了不同的交叉特征對預測的貢獻,計算公式表述如下:

然后,通過和池操作,根據不同的貢獻層次,對用戶和專案的多個交叉特征進行組合,得到包含用戶和專案屬性特征的潛在特征向量,即pu和qi,計算程序表述如下:
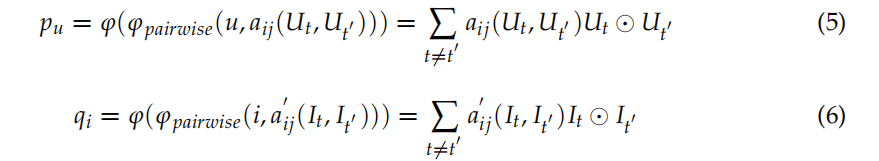
3.4 基于多隱層的GMF結構
傳統的基于矩陣分解的推薦模型由于采用了線性內積,無法捕捉用戶與專案之間復雜的非線性互動作用,針對這個問題,人們已經做了許多相關的作業,其中GMF模型尤為明顯,通過對用戶與專案之間的二階互動引入單層神經網路,利用激活函式和偏差項賦予模型建模用戶與專案之間的非線性互動的能力,但是GMF是一個淺層模型,它可以很好地模擬用戶和專案的低階互動特征,它不能有效地捕獲包含更豐富資訊的更抽象的特征,即高階互動資訊,
例如,如果我們用單層神經網路將用戶和音樂之間的互動資訊輸入到推薦模型中,我們就可以捕捉到用戶更喜歡的古典音樂,然后,如果我們將得到的結果輸入下一層神經網路進行學習,我們可以得到用戶傾向于在古典音樂中聽莫扎特的音樂,因此,我們在ifdnamf模型中引入了基于多個隱藏層的GMF結構,使該模型不僅可以建模用戶與專案之間的非線性二階互動,還可以捕獲用戶與專案之間的高階互動,該公式可以定義如下:
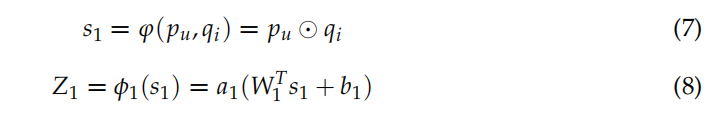
四、實驗
在本節中,我們通過對性能指標與基線的比較分析,來驗證我們提出的ifdnamf推薦模型的可行性和有效性,實驗分析主要集中在以下三個方面:
- ifdnamf模型推薦系統的性能;
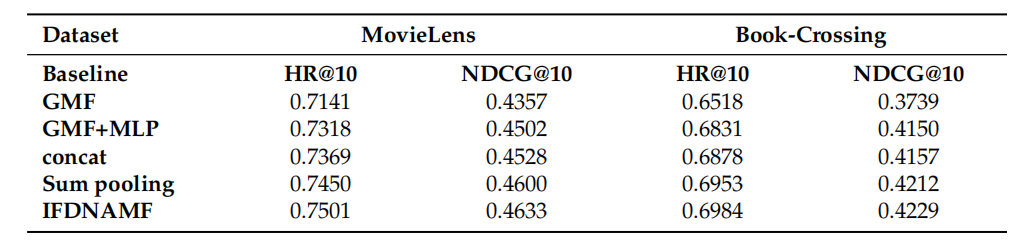
- 潛在向量維數對模型性能的影響;
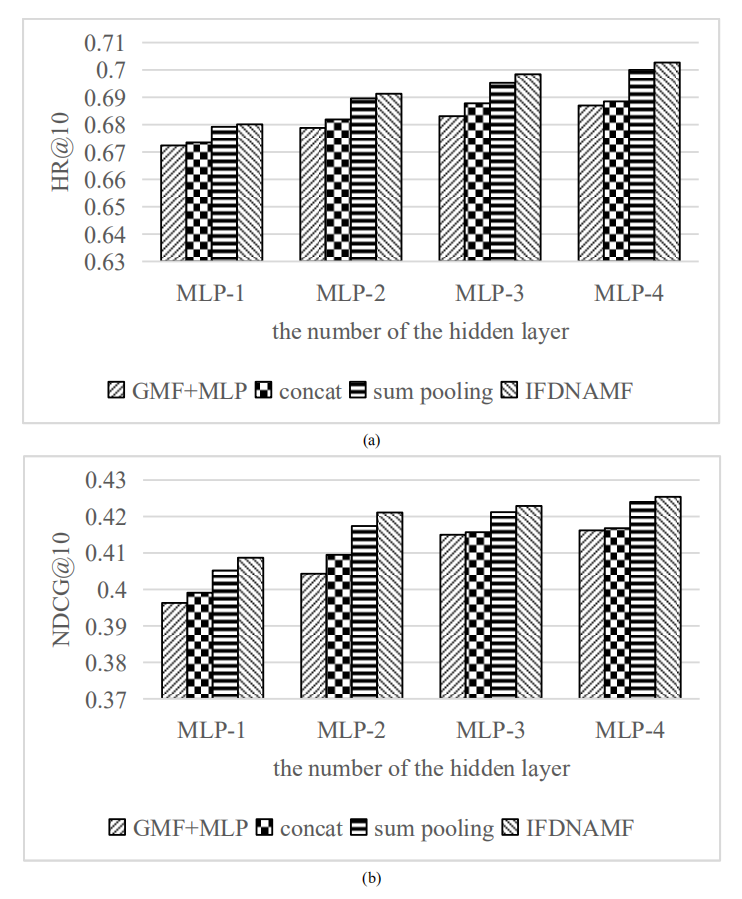
- 隱層數對模型性能的影響,
References
1.Meng, T.; Jing, X.; Yan, Z.; Pedrycz, W. A survey on machine learning for data fusion. Inf. Fusion 2020, 57, 115–129.
2.Chen, J.; Wu, Y.; Fan, L.; Lin, X.; Zheng, H.; Yu, S.; Xuan, Q. N2vscdnnr: A local recommender system based on node2vec and rich
information network. IEEE Trans. Comput. Soc. Syst. 2019, 6, 456–466.
3.Guia, M.; Silva, R.R.; Bernardino, J. A hybrid ontology-based recommendation system in e-commerce. Algorithms 2019, 12, 11.
4.Li, Y.; Wu, F.-X.; Ngom, A. A review on machine learning principles for multi-view biological data integration. Briefifings Bioinform.
2018, 19, 325–340.
5.Zitnik, M.; Nguyen, F.; Wang, B.; Leskovec, J.; Goldenberg, A.; Hoffman, M.M. Machine learning for integrating data in biology
and medicine: Principles, practice, and opportunities. Inf. Fusion 2019, 50, 71–91.
6.Ding, W.; Jing, X.; Yan, Z.; Yang, L.T. A survey on data fusion in internet of things: Towards secure and privacy-preserving fusion.
Inf. Fusion 2019, 51, 129–144.
7.He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative fifiltering. In Proceedings of the 26th International
Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182.
8.Rosa, R.L.; Rodriguez, D.Z.; Bressan, G. Music recommendation system based on user’s sentiments extracted from social networks.
9.Liu, H.; Kong, X.; Bai, X.; Wang, W.; Bekele, T.M.; Xia, F. Context-based collaborative fifiltering for citation recommendation. IEEE
Access 2017, 3, 1695–1703.
10.Wang, H.; Wang, N.; Yeung, D.-Y. Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’15, Sydney, Australia, 10–13 August 2015;
Association for Computing Machinery: New York, NY, USA, 2015; pp. 1235–1244.Algorithms 2021, 14, 281
11.Zhang, S.; Yao, L.; Wu, B.; Xu, X.; Zhang, X.; Zhu, L. Unraveling metric vector spaces with factorization for recommendation.
IEEE Trans. Ind. Inform. 2020, 16, 732–742.
12.He, X.; Zhang, H.; Kan, M.-Y.; Chua, T.-S. Fast matrix factorization for online recommendation with implicit feedback. In Pro
ceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy,
11–15 July 2016; pp. 549–558.
13Margaris, D.; Spiliotopoulos, D.; Karagiorgos, G.; Vassilakis, C. An algorithm for density enrichment of sparse collaborative
fifiltering datasets using robust predictions as derived ratings. Algorithms 2020, 13, 7.
14.Chen, C.; Zeng, J.; Zheng, X.; Chen, D. Recommender system based on social trust relationships. In Proceedings of the 2013 IEEE
gorithms* 2020, 13, 7.
14.Chen, C.; Zeng, J.; Zheng, X.; Chen, D. Recommender system based on social trust relationships. In Proceedings of the 2013 IEEE
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385488.html
標籤:AI