機器學習有無監督學習和監督學習兩個型別,這兩者有何區別呢?
1.監督學習(supervised learning)
簡單來說監督學習就是既有條件值又有結果值,比如說判斷一張圖片是貓還是狗,你首先需要給機器模型一大批的資料,并在資料后面告訴計算機這是貓或者這是狗,然后計算機就根據這一大批資料進行經驗的總結,在后來使用的程序中你給計算機一張圖片資訊他可以回傳給你一個值告訴你這是什么動物,像這樣的就是一個很典型的監督學習的例子,
2.無監督學習(unsupervised learning)
輸入資料沒有被標記,也沒有確定的結果,樣本資料類別未知,需要根據樣本間的相似性對樣本集進行分類(聚類,clustering)試圖使類內差距最小化,類間差距最大化,通俗點講就是沒有結果值需要計算機根據樣板資料自行分類,例如給計算機一堆人的照片,計算機按照年齡大小對人們進行自動的分類就是無監督的學習,
今天我們就拿監督學習的一個叫決策樹的演算法實體來給大家講講機器學習的實作,帶大家入門機器學習,
具體題目是:現有一個excel表格其中記錄了一個音樂軟體的用戶資訊,包含年齡、性別(用1代表男、用2代表女,因為這個現有的演算法模型只能支持數字)以及喜歡音樂的型別三個欄位,通過我們的代碼我們得到一個可以通過年齡性別預測喜歡音樂型別的模型,
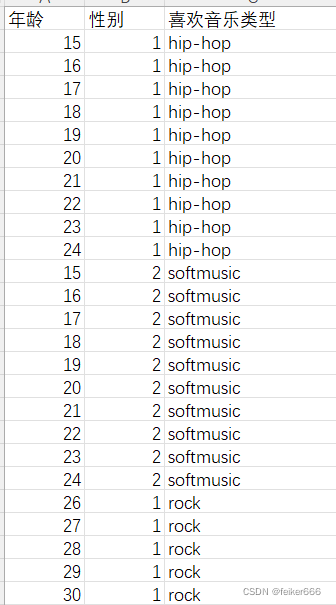
這里用的是較為理想的資料大家也可以自己建立個excel進行處理(最后用csv形式匯出)
1.庫準備
pandas,sklearn,joblib
可以通過命令列進行下載
pip install pandas
pip install sklearn
pip install joblib本文為了演示方便采用conda環境下的jupyter notebook進行示范,大家也可以自己在pycharm上執行,
2.決策樹演算法的了解
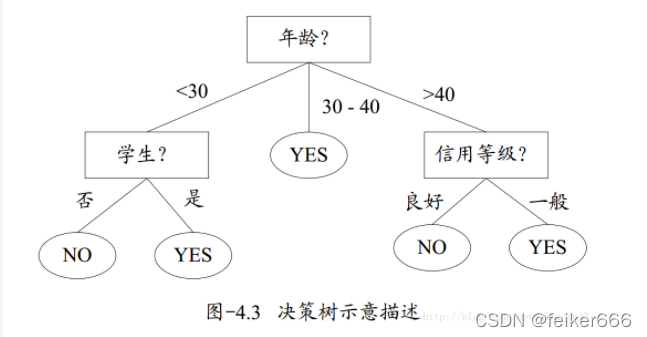
大家可以參考這張圖來對決策樹有一定的了解, 所謂決策樹,就是一個類似于流程圖的樹形結構,樹內部的每一個節點代表的是對一個特征的測驗,樹的分支代表該特征的每一個測驗結果,而樹的每一個葉子節點代表一個類別,
準備好之后發車
1.首先打開jupyter界面創建一個python3檔案,把準備好的csv檔案和jupyter檔案放在同一目錄下
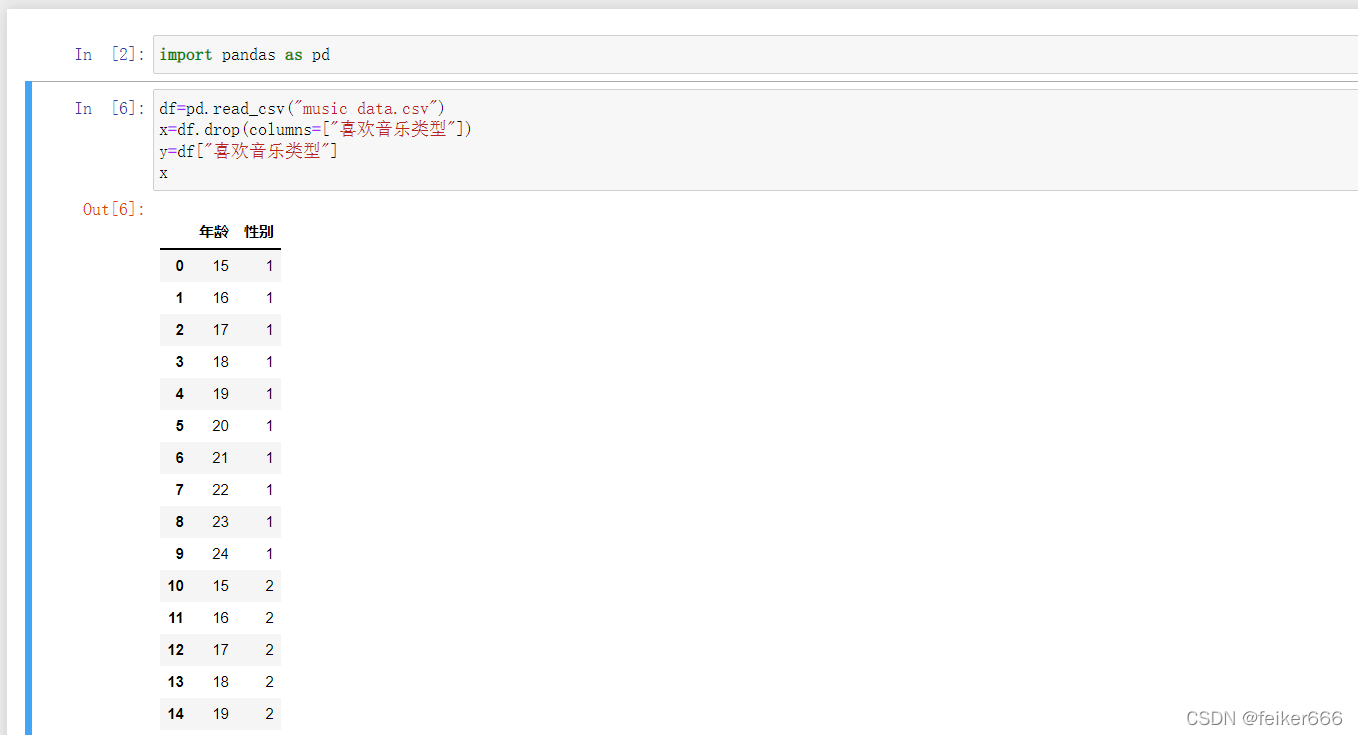
import pandas as pd
df=pd.read_csv("music data.csv")
x=df.drop(columns=["喜歡音樂型別"])
y=df["喜歡音樂型別"]
用pandas模塊打開csv 并得到條件項x和結果項y
2.匯入sklearn庫進行模型構造和訓練
在sklearn中有現成的決策樹模型可以采用
from sklearn.tree import DecisionTreeClassifier
model=model=DecisionTreeClassifier()#得到模型物件
model.fit(x,y)#用fit方法對其進行訓練這樣一個較為簡單的模型就大功告成了!
3.測驗資料

我們輸入14歲男性計算機便推測它喜歡hiphop ,
4.在實際的操作中我們肯定還需要有資料進行測驗
所以我們還可以用sklearn進行劃分資料和進行精確度計算,我們先把測驗資料x_test傳入得到predictions在將predictions和預設的結果值y_test對比
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
model=DecisionTreeClassifier()
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
model.fit(x_train,y_train)
predictions=model.predict(x_test)
score=accuracy_score(y_test,predictions)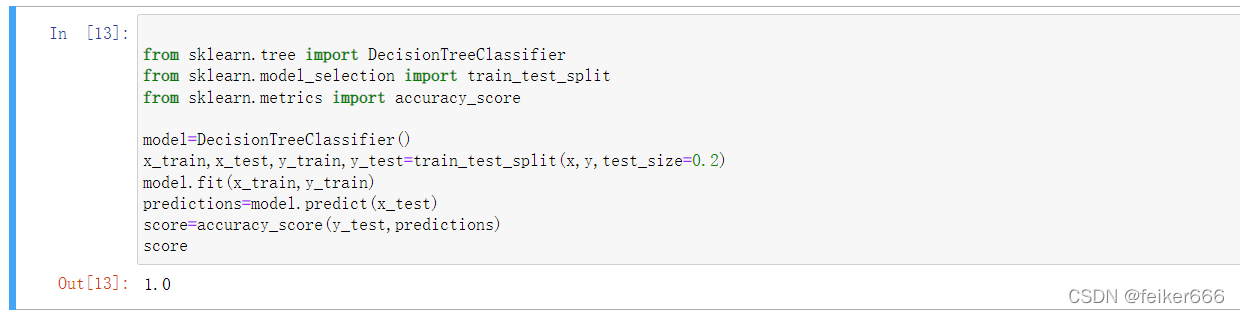
1代表完全正確,這是由于咱們的資料是高度理想化的,
最后我們在建立了模型之后怎么將他存盤起來呢,總不能我們用一次就需要訓練一次吧這就用到了我們的joblib模塊,
import joblib
joblib.dump(model,'music.joblib')#保存
#model = joblib.load('music.joblib') 讀取
這樣我們訓練好一個模型后就可以多處呼叫,
下期更新html,css,js網路前段三件套的入門
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385490.html
標籤:AI
下一篇:Linux入侵檢測