引言
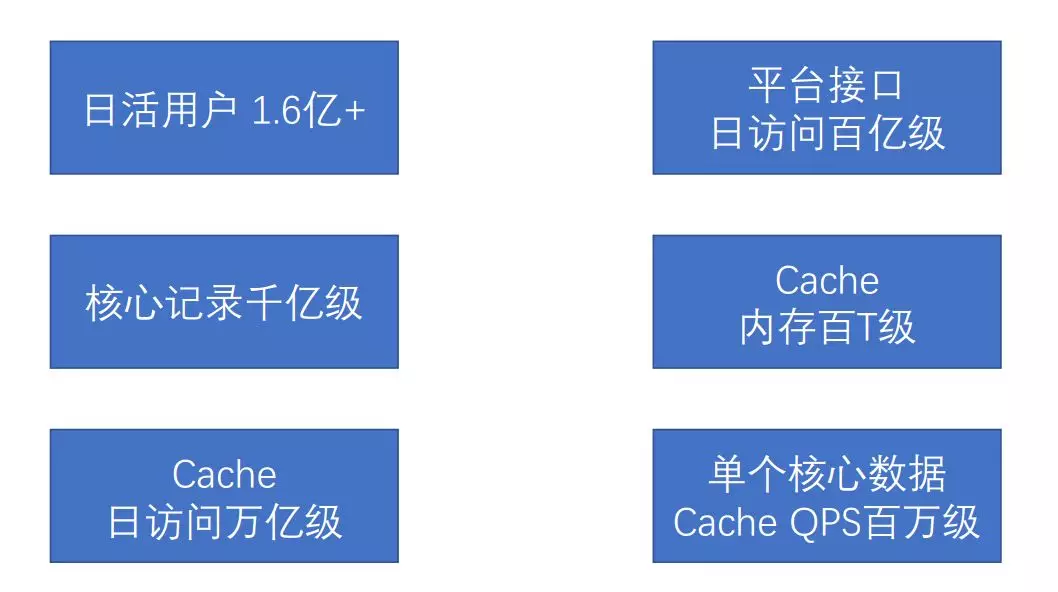
“ 微博榷訓躍用戶 1.6 億+,每日訪問量達百億級,面對龐大用戶群的海量訪問,良好的架構且不斷改進的快取體系具有非常重要的支撐作用,
本文由新浪微博技術專家陳波老師,分為如下四個部分跟大家詳細講解那些龐大的資料都是如何呈現的:
- 微博在運行程序中的資料挑戰
- Feed 平臺系統架構
- Cache 架構及演進
- 總結與展望
微博在運行程序中的資料挑戰
Feed 平臺系統架構
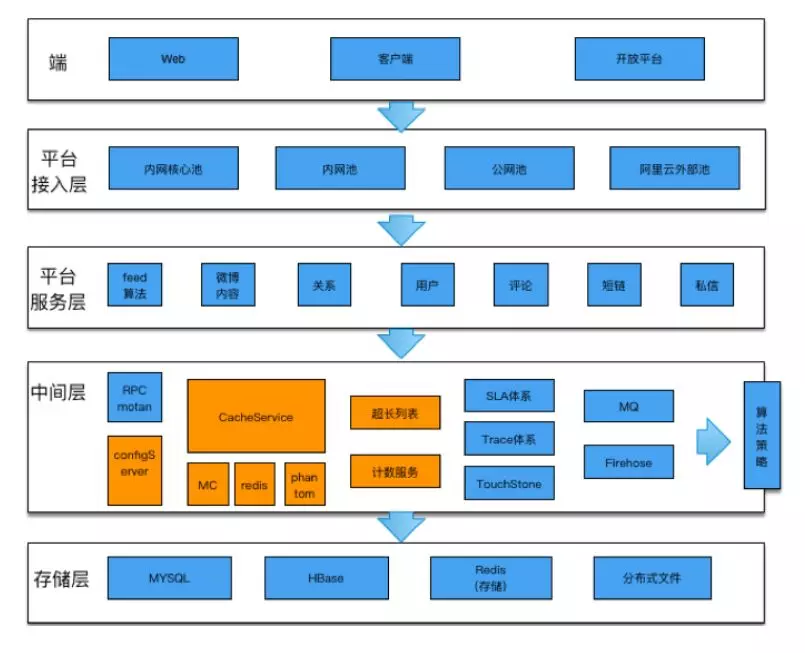
Feed 平臺系統架構總共分為五層:
- 最上面是端層,比如 Web 端、客戶端、大家用的 iOS 或安卓的一些客戶端,還有一些開放平臺、第三方接入的一些介面,
- 下一層是平臺接入層,不同的池子,主要是為了把好的資源集中調配給重要的核心介面,這樣遇到突發流量的時候,就有更好的彈性來服務,提高服務穩定性,
- 再下面是平臺服務層,主要是 Feed 演算法、關系等等,
- 接下來是中間層,通過各種中間介質提供一些服務,
- 最下面一層就是存盤層,
Feed Timeline
大家日常刷微博的時候,比如在主站或客戶端點一下重繪,最新獲得了十到十五條微博,這是怎么構建出來的呢?
重繪之后,首先會獲得用戶的關注關系,比如他有一千個關注,會把這一千個 ID 拿到,再根據這一千個 UID,拿到每個用戶發表的一些微博,
同時會獲取這個用戶的 Inbox,就是他收到的特殊的一些訊息,比如分組的一些微博、群的微博、下面的關注關系、關注人的微博串列,
拿到這一系列微博串列之后進行集合、排序,拿到所需要的那些 ID,再對這些 ID 去取每一條微博 ID 對應的微博內容,
如果這些微博是轉發過來的,它還有一個原微博,會進一步取原微博內容,通過原微博取用戶資訊,進一步根據用戶的過濾詞對這些微博進行過濾,過濾掉用戶不想看到的微博,
根據以上步驟留下的微博,會再進一步來看,用戶對這些微博有沒有收藏、點贊,做一些 Flag 設定,還會對這些微博各種計數,轉發、評論、贊數進行組裝,最后才把這十幾條微博回傳給用戶的各種端,
這樣看來,用戶一次請求得到的十幾條記錄,后端服務器大概要對幾百甚至幾千條資料進行實時組裝,再回傳給用戶,
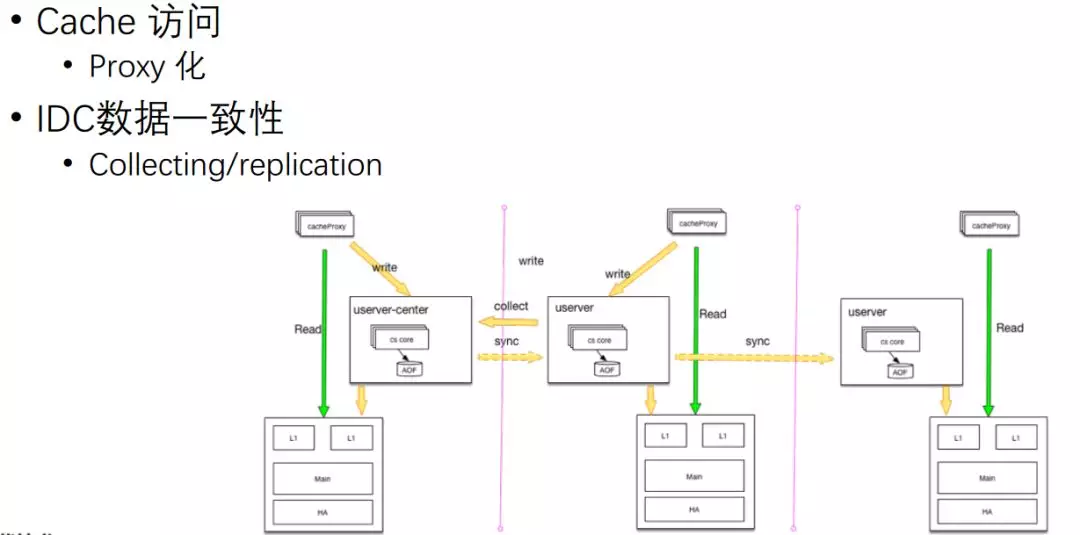
整個程序對 Cache 體系強度依賴,所以 Cache 架構設計優劣會直接影響到微博體系表現的好壞,
Feed Cache 架構
接下來我們看一下 Cache 架構,它主要分為六層:
- 第一層是 Inbox,主要是分組的一些微博,然后直接對群主的一些微博,Inbox 比較少,主要是推的方式,
- 第二層是 Outbox,每個用戶都會發常規的微博,都會到它的 Outbox 里面去,根據存的 ID 數量,實際上分成多個 Cache,普通的大概是 200 多條,如果長的大概是 2000 條,
- 第三層是一些關系,它的關注、粉絲、用戶,
- 第四層是內容,每一條微博一些內容存在這里,
- 第五層就是一些存在性判斷,比如某條微博我有沒有贊過,之前有一些明星就說我沒有點贊這條微博怎么顯示我點贊了,引發了一些新聞,而這種就是記錄,實際上她有在某個時候點贊過但可能忘記了,
- 最下面還有比較大的一層——計數,每條微博的評論、轉發等計數,還有用戶的關注數、粉絲數這些資料,
Cache 架構及演進
簡單 KV 資料型別
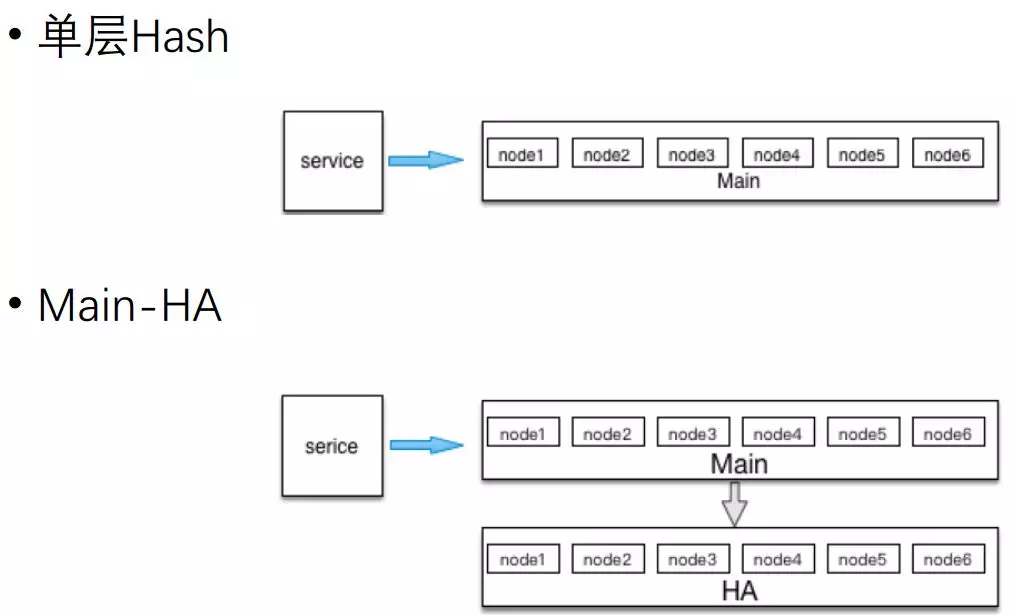
接下來我們著重講一下微博的 Cache 架構演程序序,最開始微博上線時,我們是把它作為一個簡單的 KV 資料型別來存盤,
我們主要采取哈希分片存盤在 MC 池子里,上線幾個月之后發現一些問題:有一些節點機器宕機或是其他原因,大量的請求會穿透 Cache 層達到 DB 上去,導致整個請求變慢,甚至 DB 僵死,
于是我們很快進行了改造,增加了一個 HA 層,這樣即便 Main 層出現某些節點宕機情況或者掛掉之后,這些請求會進一步穿透到 HA 層,不會穿透到 DB 層,
這樣可以保證在任何情況下,整個系統命中率不會降低,系統服務穩定性有了比較大的提升,
對于這種做法,現在業界用得比較多,然后很多人說我直接用哈希,但這里面也有一些坑,
比如我有一個節點,節點 3 宕機了,Main 把它給摘掉,節點 3 的一些 QA 分給其他幾個節點,這個業務量還不是很大,穿透 DB,DB 還可以抗住,
但如果這個節點 3 恢復了,它又加進來之后,節點 3 的訪問就會回來,稍后節點 3 因為網路原因或者機器本身的原因,它又宕機了,一些節點 3 的請求又會分給其他節點,
這個時候就會出現問題,之前分散給其他節點寫回來的資料已經沒有人更新了,如果它沒有被剔除掉就會出現混插資料,
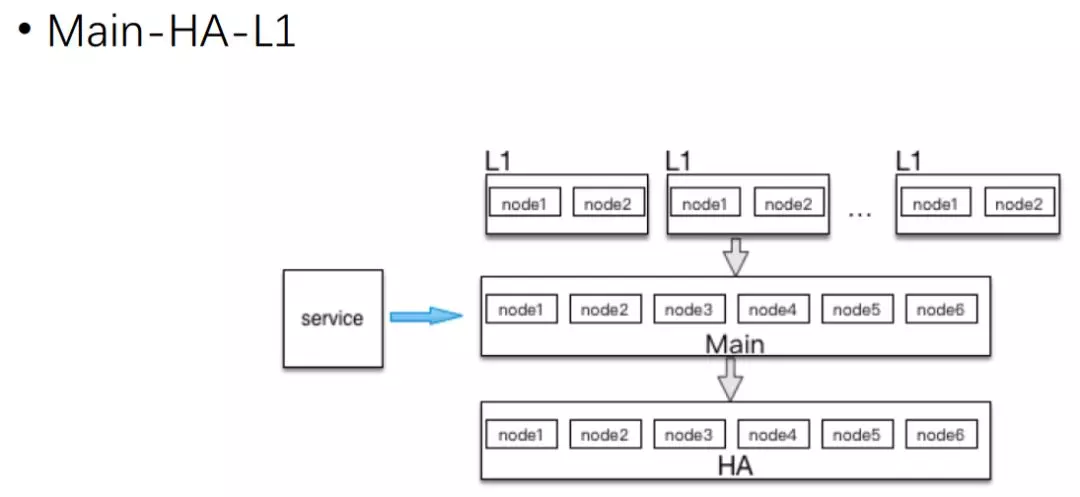
實際上微博是一個廣場型的業務,比如突發事件,某明星找個女朋友,瞬間流量就 30% 了,
突發事件后,大量的請求會出現在某一些節點,會導致這些節點非常熱,即便是 MC 也沒辦法滿足這么大的請求量,這時 MC 就會變成瓶頸,導致整個系統變慢,
基于這個原因,我們引入了 L1 層,還是一個 Main 關系池,每一個 L1 大概是 Main 層的 N 分之一,六分之一、八分之一、十分之一這樣一個記憶體量,根據請求量我會增加 4 到 8 個 L1,這樣所有請求來了之后首先會訪問 L1,
L1 命中的話就會直接訪問,如果沒有命中再來訪問 Main-HA 層,這樣在一些突發流量的時候,可以由 L1 來抗住大部分熱的請求,
對微博本身來說,新的資料就會越熱,只要增加很少一部分記憶體就會抗住更大的量,

簡單總結一下:通過簡單 KV 資料型別的存盤,我們實際上是以 MC 為主的,層內 Hash 節點不漂移,Miss 穿透到下一層去讀取,
通過多組 L1 讀取性能提升,能夠抗住峰值、突發流量,而且成本會大大降低,
對讀寫策略,采取多寫,讀的話采用逐層穿透,如果 Miss 的話就進行回寫,對存在里面的資料,我們最初采用 Json/xml,2012 年之后就直接采用 Protocol Buffer 格式,對一些比較大的用 QuickL 進行壓縮,
集合類資料

剛才講到簡單的 QA 資料,那對于復雜的集合類資料怎么來處理?
比如我關注了 2000 人,新增 1 個人,就涉及到部分修改,有一種方式是把 2000 個 ID 全部拿下來進行修改,但這種對帶寬、機器壓力會很大,
還有一些分頁獲取,我存了 2000 個,只需要取其中的第幾頁,比如第二頁,也就是第十到第二十個,能不能不要全量把所有資料取回去,
還有一些資源的聯動計算,會計算到我關注的某些人里面 ABC 也關注了用戶 D,這種涉及到部分資料的修改、獲取,包括計算,對 MC 來說實際上是不太擅長的,
各種關注關系都存在 Redis 里面取,通過 Hash 分布、儲存,一主多從的方式來進行讀寫分離,現在 Redis 的記憶體大概有 30 個 T,每天都有 2-3 萬億的請求,
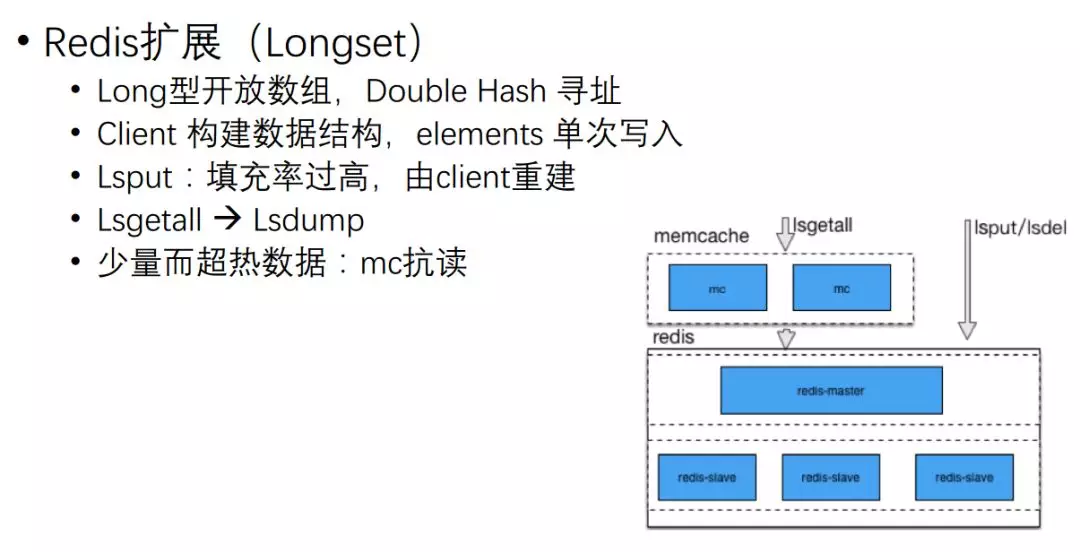
在使用 Redis 的程序中,實際上還是遇到其他一些問題,比如從關注關系,我關注了 2000 個 UID,有一種方式是全量存盤,
但微博有大量的用戶,有些用戶登錄得比較少,有些用戶特別活躍,這樣全部放在記憶體里成本開銷是比較大的,
所以我們就把 Redis 使用改成 Cache,比如只存活躍的用戶,如果你最近一段時間沒有活躍,會把你從 Redis 里踢掉,再次有訪問的時候再把你加進來,
這時存在一個問題,因為 Redis 作業機制是單執行緒模式,如果它加某一個 UV,關注 2000 個用戶,可能擴展到兩萬個 UID,兩萬個 UID 塞回去基本上 Redis 就卡住了,沒辦法提供其他服務,
所以我們擴展一種新的資料結構,兩萬個 UID 直接開了端,寫的時候直接依次把它寫到 Redis 里面去,讀寫的整個效率就會非常高,
它的實作是一個 long 型的開放陣列,通過 Double Hash 進行尋址,

我們對 Redis 進行了一些其他的擴展,大家可能也在網上看到過我們之前的一些分享,把資料放到公共變數里面,
整個升級程序,我們測驗 1G 的話加載要 10 分鐘,10G 大概要 10 分鐘以上,現在是毫秒級升級,
對于 AOF,我們采用滾動的 AOF,每個 AOF 是帶一個 ID 的,達到一定的量再滾動到下一個 AOF 里去,
對 RDB 落地的時候,我們會記錄構建這個 RDB 時,AOF 檔案以及它所在的位置,通過新的 RDB、AOF 擴展模式,實作全增量復制,
其他資料型別:計數
接下來還有一些其他的資料型別,比如一個計數,實際上計數在每個互聯網公司都可能會遇到,對一些中小型的業務來說,實際上 MC 和 Redis 足夠用的,
但在微博里計數出現了一些特點:單條 Key 有多條計數,比如一條微博,有轉發數、評論數,還有點贊;一個用戶有粉絲數、關注數等各種各樣的數字,
因為是計數,它的 Value size 是比較小的,根據它的各種業務場景,大概就是 2-8 個位元組,一般 4 個位元組為多,
然后每日新增的微博大概十億條記錄,總記錄就更可觀了,然后一次請求,可能幾百條計數要回傳去,

計數器 Counter Service
最初是可以采取 Memcached,但它有個問題,如果計數超過它內容容量時,會導致一些計數的剔除,宕機或重啟后計數就沒有了,
另外可能有很多計數它為零,那這個時候怎么存,要不要存,存的話就占很多記憶體,
微博每天上十億的計數,光存 0 都要占大量的記憶體,如果不存又會導致穿透到 DB 里去,對服務的可溶性會存在影響,
2010 年之后我們又采用 Redis 訪問,隨著資料量越來越大之后,發現 Redis 記憶體有效負荷還是比較低的,它一條 KV 大概需要至少 65 個位元組,
但實際上我們一個計數需要 8 個位元組,然后 Value 大概 4 個位元組,所以有效只有 12 個位元組,還有四十多個位元組都是被浪費掉的,
這還只是單個 KV,如果在一條 Key 有多個計數的情況下,它就浪費得更多了,
比如說四個計數,一個 Key 8 個位元組,四個計數每個計數是 4 個位元組,16 個位元組大概需要 26 個位元組就行了,但是用 Redis 存大概需要 200 多個位元組,
后來我們通過自己研發的 Counter Service,記憶體降至 Redis 的五分之一到十五分之一以下,而且進行冷熱分離,熱資料存在記憶體里,冷資料如果重新變熱,就把它放到 LRU 里去,
落地 RDB、AOF,實作全增量復制,通過這種方式,熱資料單機可以存百億級,冷資料可以存千億級,
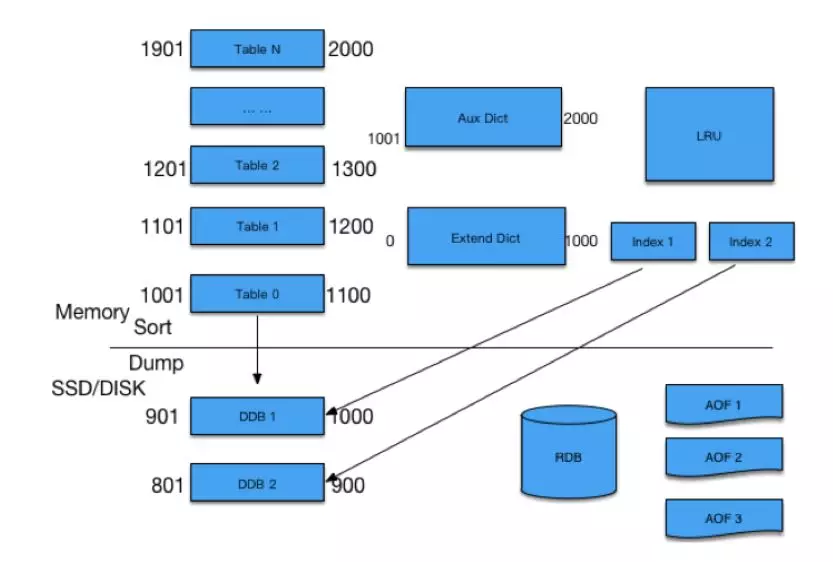
整個存盤架構大概是上圖這樣,上面是記憶體,下面是 SSD,在記憶體里是預先把它分成 N 個 Table,每個 Table 根據 ID 的指標序列,劃出一定范圍,
任何一個 ID 過來先找到它所在的 Table,如果有直接對它增增減減,有新的計數過來,發現記憶體不夠的時候,就會把一個小的 Table Dump((記憶體資訊)轉儲,轉存 ) 到 SSD 里去,留著新的位置放在最上面供新的 ID 來使用,
有些人疑問說,如果在某個范圍內,我的 ID 本來設的計數是 4 個位元組,但是微博特別熱,超過了 4 個位元組,變成很大的一個計數怎么處理?
對于超過限制的,我們把它放在 Aux dict 進行存放,對于落在 SSD 里的 Table,我們有專門的 IndAux 進行訪問,通過 RDB 方式進行復制,
其他資料型別:存在性判斷

除了計數,微博還有一些業務,一些存在性判斷,比如一條微博展現的,有沒有點贊、閱讀、推薦,如果這個用戶已經讀過這個微博了,就不要再顯示給他,
這種有一個很大的特點,它檢查是否存在,每條記錄非常小,比如 Value 1 個 bit 就可以了,但總資料量巨大,
比如微博每天新發表微博 1 億左右,讀的可能有上百億、上千億這種總的資料需要判斷,
怎么來存盤是個很大的問題,而且這里面很多存在性就是 0,還是前面說的,0 要不要存?
如果存了,每天就存上千億的記錄;如果不存,那大量的請求最侄訓穿透 Cache 層到 DB 層,任何 DB 都沒辦法抗住那么大的流量,

我們也進行了一些選型:首先直接考慮能不能用 Redis,單條 KV 65 個位元組,一個 KV 可以 8 個位元組的話,Value 只有 1 個 bit,這樣算下來每日新增記憶體有效率是非常低的,
第二種我們新開發的 Counter Service,單條 KV Value 1 個 bit,我就存 1 個 byt,總共 9 個 byt 就可以了,
這樣每日新增記憶體 900G,存的話可能就只能存最新若干天的,存個三天差不多快 3 個 T 了,壓力也挺大,但比 Redis 已經好很多,
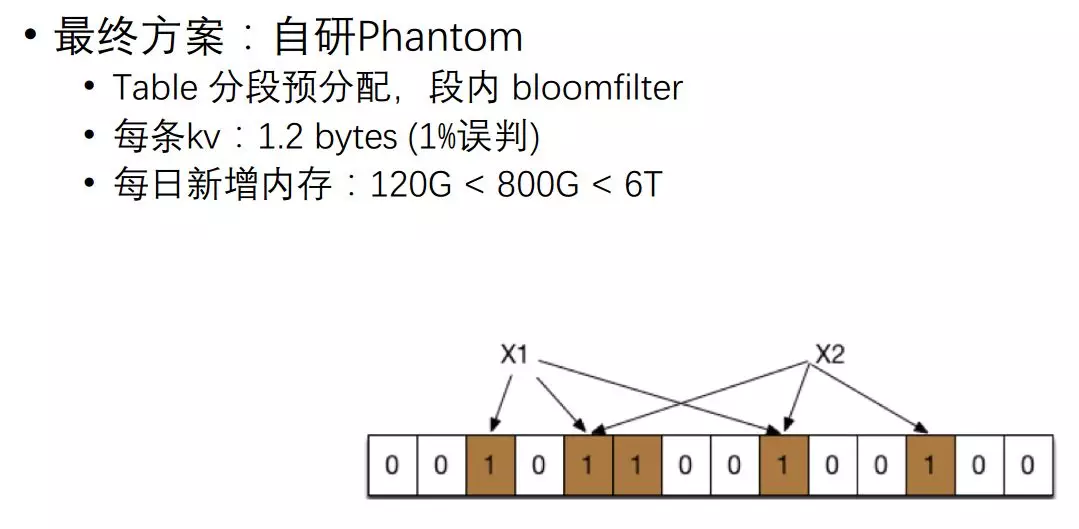
我們最終方案是自己開發 Phantom,先采用把共享記憶體分段分配,最終使用的記憶體只用 120G 就可以,
演算法很簡單,對每個 Key 可以進行 N 次哈希,如果哈希的某一個位它是 1,那么進行 3 次哈希,三個數字把它設為 1,
把 X2 也進行三次哈希,后面來判斷 X1 是否存在的時候,從進行三次哈希來看,如果都為 1 就認為它是存在的;如果某一個哈希 X3,它的位算出來是 0,那就百分百肯定是不存在的,
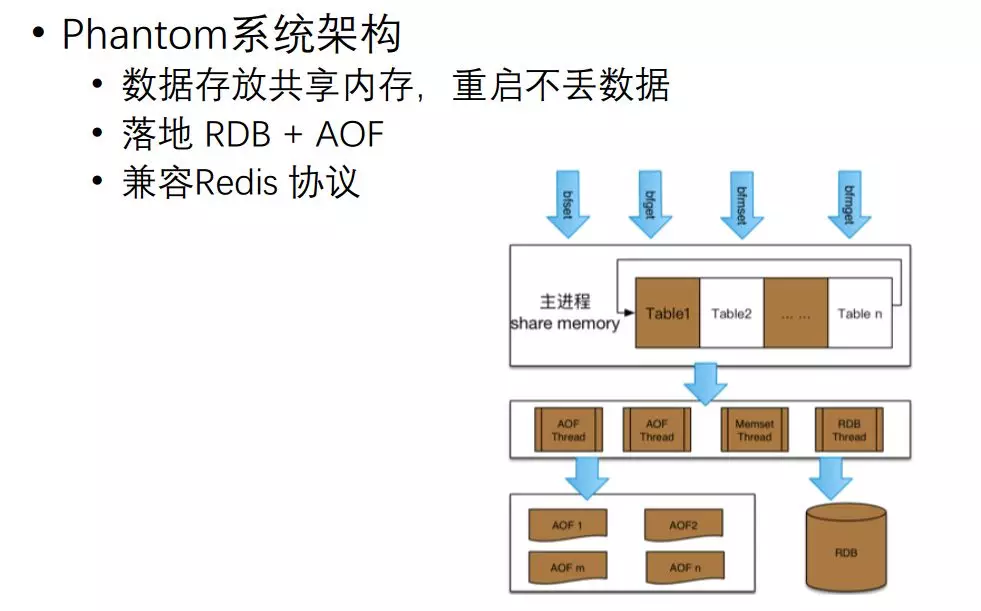
它的實作架構比較簡單,把共享記憶體預先拆分到不同 Table 里,在里面進行開方式計算,然后讀寫,落地的話采用 AOF+RDB 的方式進行處理,
整個程序因為放在共享記憶體里面,行程要升級重啟資料也不會丟失,對外訪問的時候,建 Redis 協議,它直接擴展新的協議就可以訪問我們這個服務了,

小結一下:到目前為止,我們關注了 Cache 集群內的高可用、擴展性、組件高性能,還有一個特別重要就是存盤成本,還有一些我們沒有關注到的,比如運維性如何,微博現在已經有幾千差不多上萬臺服務器等,
進一步優化

服務化

采取的方案首先就是對整個 Cache 進行服務化管理,對配置進行服務化管理,避免頻繁重啟,另外如果配置發生變更,直接用一個腳本修改一下,
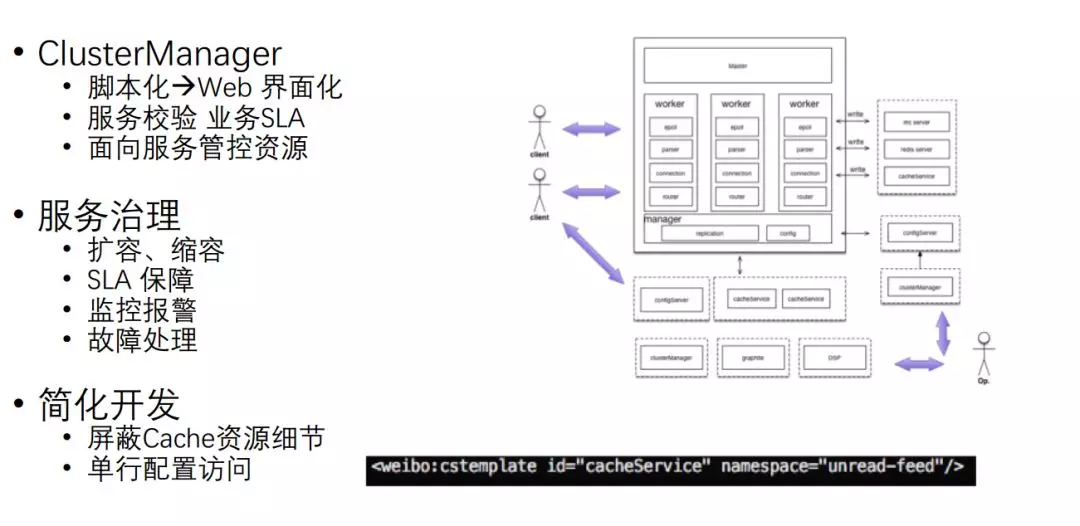
服務化還引入 Cluster Manager,實作對外部的管理,通過一個界面來進行管理,可以進行服務校驗,
服務治理方面,可以做到擴容、縮容,SLA 也可以得到很好的保障,另外,對于開發來說,現在就可以屏蔽 Cache 資源,
總結與展望
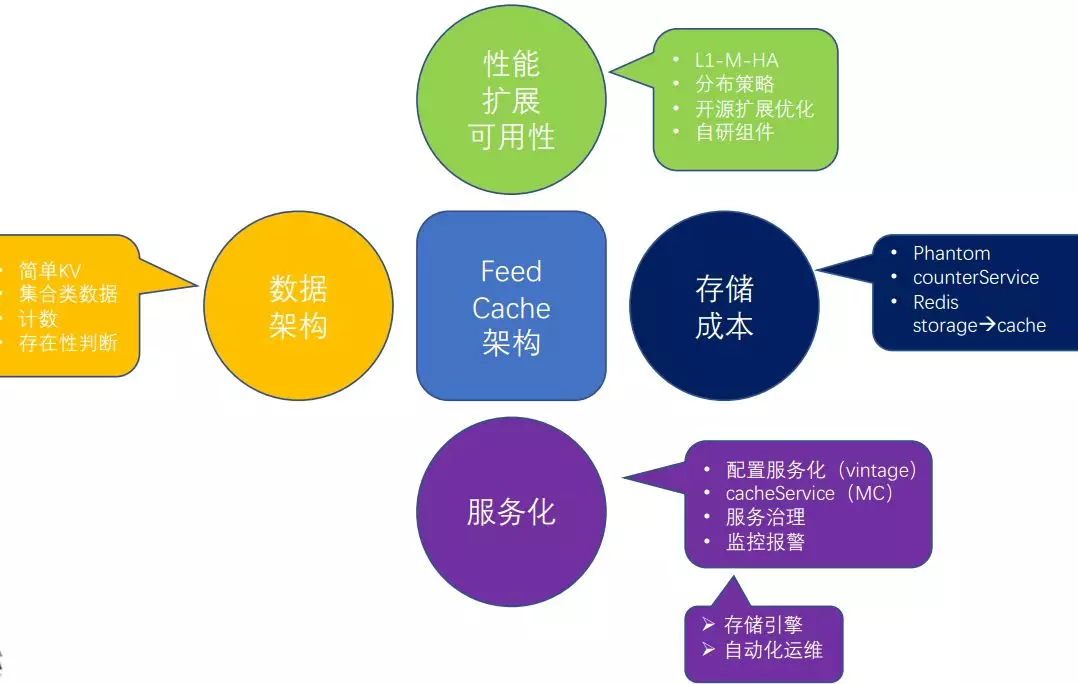
最后簡單總結一下,對于微博 Cache 架構來說,我們從它的資料架構、性能、儲存成本、服務化等不同方面進行了優化增強,
如果有需要領取免費資料的小伙伴們,可以點擊此處領取資料哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385509.html
標籤:其他
上一篇:opvx4: 資料結構