🌟 前言
大家好,我是Edison😎
本篇文章將繼續介紹常見八大排序中的 交換排序;
不廢話,直接干!😎
Let’s get it!
🛫送給所有正在努力的大家一句話:你不一定逆風翻盤,但一定要向陽而生🌅

文章目錄
- 🌟 前言
- 1. 交換排序分類
- 2. 冒泡排序
- 🍑 基本思想
- 🍑 圖解冒泡
- 🍑 動圖演示
- 📃 代碼實作
- 📝 代碼優化
- 🍑 特性總結
- 3. 快速排序
- 🍑 基本思想
- 🍑 基準元素的選擇
- 🍑 挖坑法
- 📃 代碼實作
- 🍑 前后指標法
- 🎥 動圖演示
- 📃 代碼實作
- 🍑 非遞回實作
- 📃 挖坑法
- 📃 前后指標法
- 🍑 特性總結
- 總結
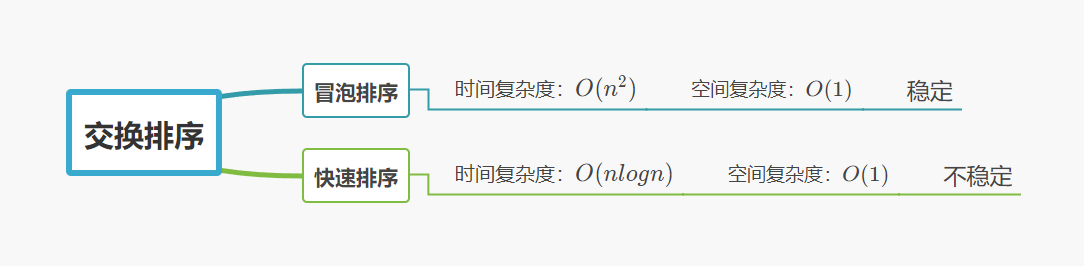
1. 交換排序分類
所謂交換,就是根據序列中兩個記錄鍵值的比較結果來對換這兩個記錄在序列中的位置,
交換排序的特點是:將鍵值較大的記錄向序列的尾部移動,鍵值較小的記錄向序列的前部移動,
交換排序 可以分為: 冒泡 和 快速排序
2. 冒泡排序
🍑 基本思想
冒泡排序的英文Bubble Sort,是一種最基礎的交換排序,
大家一定都喝過汽水,汽水中常常有許多小小的氣泡,嘩啦嘩啦飄到上面來,這是因為組成小氣泡的二訊訓碳比水要輕,所以小氣泡可以一點一點向上浮動,
而我們的冒泡排序之所以叫做冒泡排序,正是因為這種排序演算法的每一個元素都可以像小氣泡一樣,根據自身大小,一點一點向著陣列的一側移動,

具體如何來移動呢?讓我們來看一個栗子🌰
🍑 圖解冒泡
假設有下面一組無序陣列,我們要對它進行升序排序,具體實作程序如下

①第一趟冒泡排序👇
按照冒泡排序的思想,我們要把相鄰的元素兩兩比較,根據大小來交換元素的位置,程序如下:
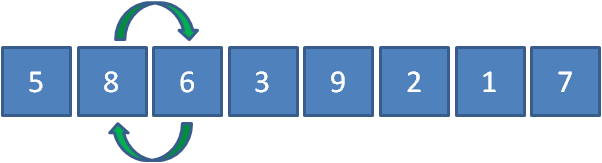
首先讓5和8比較,發現5比8要小,因此元素位置不變,
接下來讓8和6比較,發現8比6要大,所以8和6交換位置,
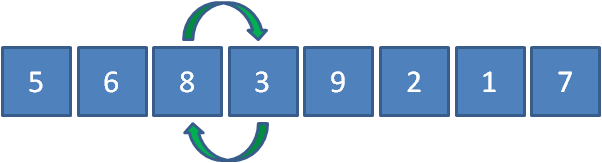
繼續讓8和3比較,發現8比3要大,所以8和3交換位置,
繼續讓8和9比較,發現8比9要小,所以元素位置不變,
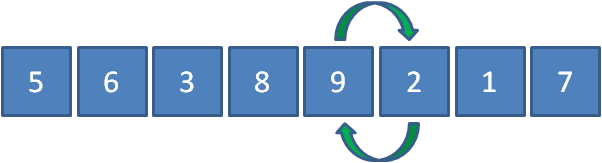
接下來讓9和2比較,發現9比2要大,所以9和2交換位置,
接下來讓9和1比較,發現9比1要大,所以9和1交換位置,
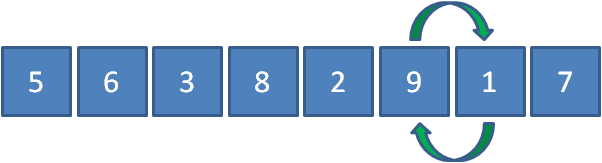
最后讓9和7比較,發現9比7要大,所以9和7交換位置,
這樣一來,元素9作為數列的最大元素,就像是汽水里的小氣泡一樣漂啊漂,漂到了最右側,
這時候,我們的冒泡排序的第一輪結束了,數列最右側的元素9可以認為是一個有序區域,有序區域目前只有一個元素,






②第二趟冒泡排序👇
下面,讓我們來進行第二輪排序:
首先讓5和6比較,發現5比6要小,因此元素位置不變,
接下來讓6和3比較,發現6比3要大,所以6和3交換位置,
繼續讓6和8比較,發現6比8要小,因此元素位置不變,
接下來讓8和2比較,發現8比2要大,所以8和2交換位置,
接下來讓8和1比較,發現8比1要大,所以8和1交換位置,
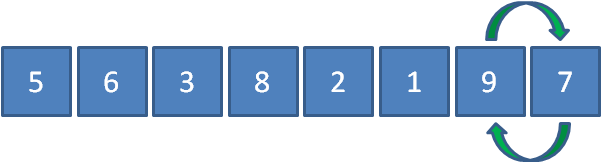
繼續讓8和7比較,發現8比7要大,所以8和7交換位置,
第二輪排序結束后,我們數列右側的有序區有了兩個元素,順序如下:


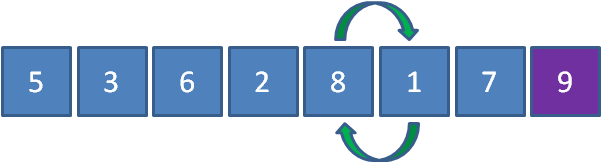

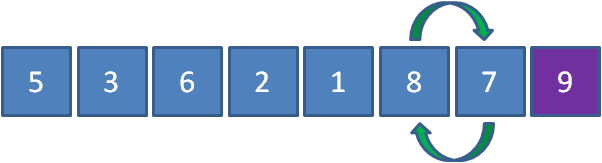


③第三趟冒泡排序👇
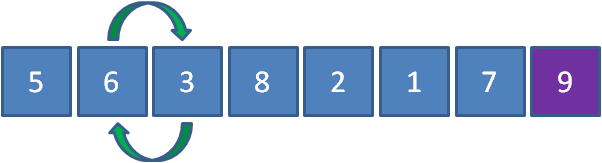
按照以上步驟,第三輪過后的狀態如下:

④第四趟冒泡排序👇
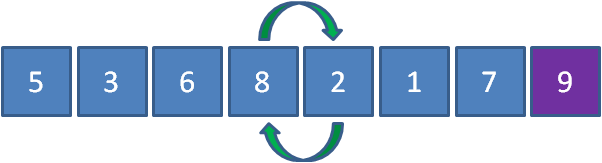
第四輪過后狀態如下:

⑤第五趟冒泡排序👇
第五輪過后狀態如下:

⑥第六趟冒泡排序👇
第六輪過后狀態如下:

⑦第七趟冒泡排序👇
第七輪過后狀態如下(已經是有序了,所以沒有改變):

⑧第八趟冒泡排序👇
第八輪過后狀態如下(同樣沒有改變):

到此為止,所有元素都是有序的了,這就是冒泡排序的整體思路,
🍑 動圖演示
清楚了冒泡排序的程序,我們再來看一個動態圖
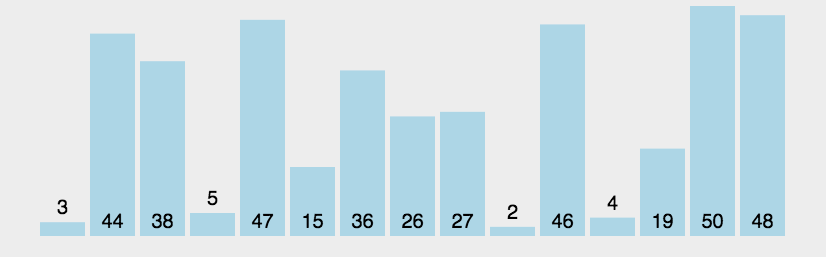
📃 代碼實作
代碼程序如下:
void bubble_sort(int* arr, int sz)
{
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[8] = { 5, 8, 6, 3, 9, 2, 1, 7 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
這個代碼很簡單,使用雙回圈的方式進行排序,
外部的回圈控制所有回合,內部回圈代表每一輪的冒泡處理,先進行元素比較,再進行元素交換,
來看下運行結果:
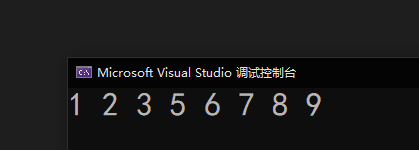
📝 代碼優化
讓我們回顧一下剛才描述的排序細節,仍然以
5,8,6,3,9,2,1,7這個數列為例;
當排序演算法分別執行到第六、第七、第八輪的時候,數列狀態如下:
很明顯可以看出,自從經過第六輪排序,整個數列已然是有序的了,
可是我們的排序演算法仍然 “兢兢業業” 地繼續執行第七輪、第八輪,
這種情況下,如果我們能判斷出數列已經有序,并且做出標記,剩下的幾輪排序就可以不必執行,提早結束作業,
優化的思路是:如果能判斷出數列已經是有序的了,并且做出標記,那么就不會執行多余的排序,

因此,我們進行一個優化的方法:就是設定一個flags;
如果在本輪排序中有元素進行交換,則說明數列無序,如果已經排序了那么設定為0;
如果在本輪排序中,沒有元素進行交換,則說明數列有序,那么設定為1,
優化后的代碼👇
void bubble_sort(int* arr, int sz)
{
int flags = 0;
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flags = 1;//不是有序的,flags設定為1
}
}
if (flags == 0)
return;
}
}
我們再來看一下運行結果:
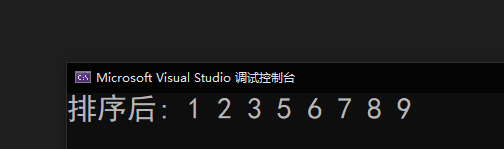
🍑 特性總結
1、冒泡排序是一種非常容易理解的排序;
2、時間復雜度: O ( N 2 ) O(N^2) O(N2)
3、空間復雜度: O ( 1 ) O(1) O(1)
4、穩定性:穩定
3. 快速排序
🍑 基本思想
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法;
其基本思想為:
任取待排序元素序列中的某元素作為基準值,按照該排序碼將待排序集合分割成兩子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值;
然后最左右子序列重復該程序,直到所有元素都排列在相應位置上為止,
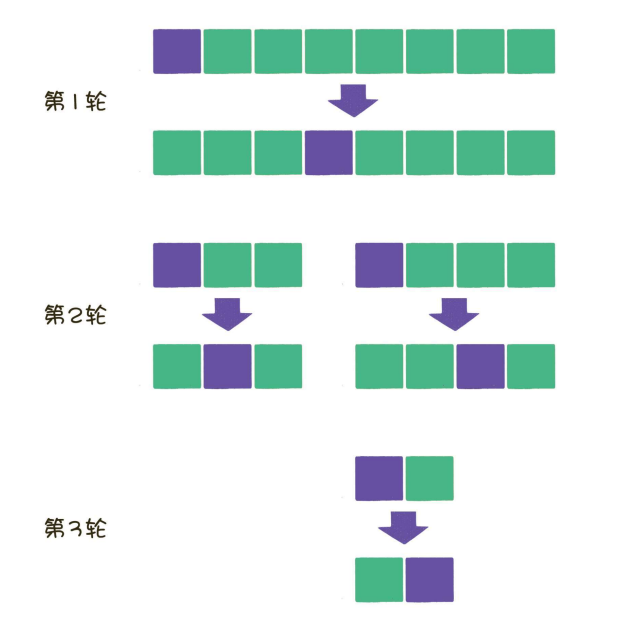
每次把數列分成兩部分,究竟有什么好處呢?
假如給出?個8個元素的數列,?般情況下,使?冒泡排序需要?較7 輪,每?輪把1個元素移動到數列的?端,
快速排序的流程是什么樣?呢?
原數列在每?輪都被拆分成兩部分, 每?部分在下?輪?分別被拆分成兩部分,直到不可再分為?,
基準元素的選擇,以及元素的交換,都是快速排序的核?問題,
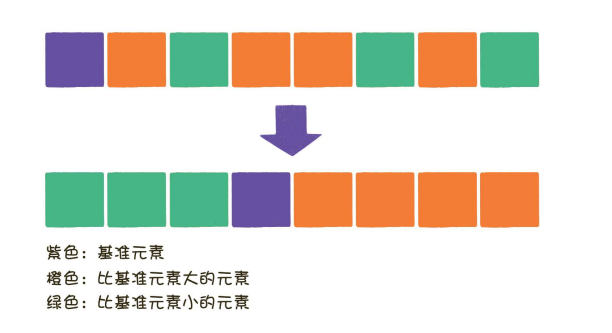
🍑 基準元素的選擇
隨機選擇一個元素作為基準元素,并且讓基準元素和數列?元素交換位置
這樣?來,即使在數列完全逆序的情況下,也可以有效地將數列分成兩部分,
即使是隨機選擇基準元素,也會有極?的?率選到數列的最? 值或最?值,同樣會影響分分割的效果,
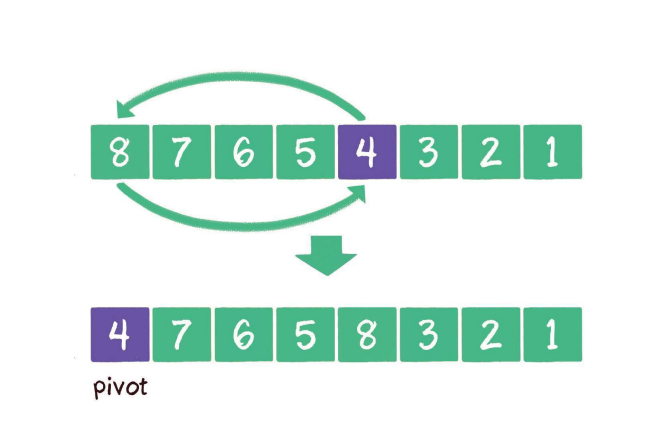
選定了基準元素以后,我們要做的就是把其他元素中?于基準元素的都交換到基準元素?邊,?于基準元素的都交換到基準元素另?邊,
常見的方式有:
1、挖坑法
2、前后指標法
🍑 挖坑法
什么是挖坑法呢?我們來看一看詳細程序👇
給定原始數列如下,要求從小到大排序:
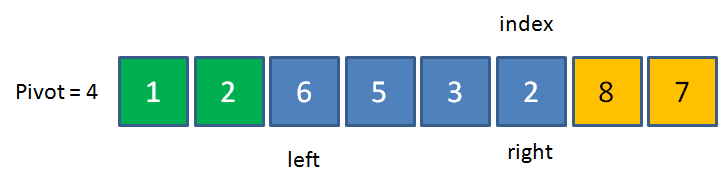
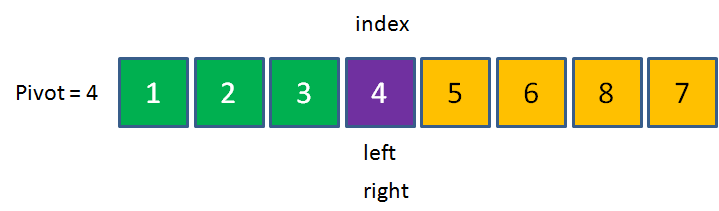
首先,我們選定基準元素Pivot,并記住這個位置index,這個位置相當于一個“坑”,并且設定兩個指標left和right,指向數列的最左和最右兩個元素:
接下來,從right指標開始,把指標所指向的元素和基準元素做比較,
如果比pivot大,則right指標向左移動;如果比pivot小,則把right所指向的元素填入坑中,
在當前數列中,1 < 4,所以把1填入基準元素所在位置,也就是坑的位置,這時候,元素1本來所在的位置成為了新的坑,同時,left向右移動一位,
此時,left左邊綠色的區域代表著小于基準元素的區域,
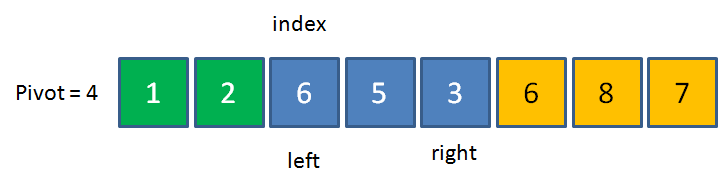
接下來,我們切換到left指標進行比較,如果left指向的元素小于pivot,則left指標向右移動;如果元素大于pivot,則把left指向的元素填入坑中,
在當前數列中,7>4,所以把7填入index的位置,這時候元素7本來的位置成為了新的坑,同時,right向左移動一位,
此時,right右邊橙色的區域代表著大于基準元素的區域,




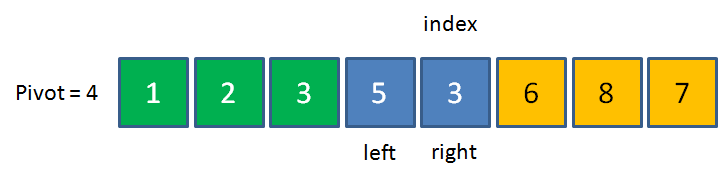
下面按照剛才的思路繼續排序👇
8>4,元素位置不變,right左移
2<4,用2來填坑,left右移,切換到left,
6>4,用6來填坑,right左移,切換到right,
3<4,用3來填坑,left右移,切換到left,
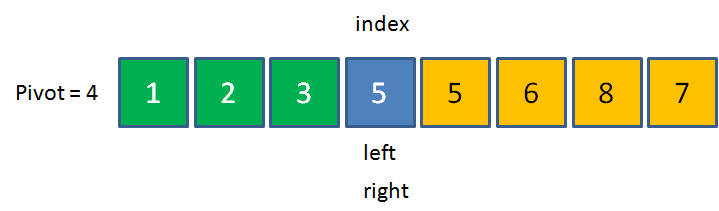
5>4,用5來填坑,right右移,這時候left和right重合在了同一位置,
這時候,把之前的pivot元素,也就是4放到index的位置,此時數列左邊的元素都小于4,數列右邊的元素都大于4,這一輪交換終告結束,

📃 代碼實作
//快速排序(挖坑法)
void QuickSort1(int* a, int begin, int end)
{
if (begin >= end)//當只有一個資料或是序列不存在時,不需要進行操作
return;
int left = begin;//L
int right = end;//R
int key = a[left];//在最左邊形成一個坑位
while (left < right)
{
//right向左,找小
while (left < right&&a[right] >= key)
{
right--;
}
//填坑
a[left] = a[right];
//left向右,找大
while (left < right&&a[left] <= key)
{
left++;
}
//填坑
a[right] = a[left];
}
int meeti = left;//L和R的相遇點
a[meeti] = key;//將key拋入坑位
QuickSort1(a, begin, meeti - 1);//key的左序列進行此操作
QuickSort1(a, meeti + 1, end);//key的右序列進行此操作
}
代碼中,QuickSort方法通過遞回的方式,實作了分割的思想,
時間復雜度: O ( N l o g N ) O(NlogN) O(NlogN)
🍑 前后指標法
什么是指標交換法?我們來看一看詳細程序👇
給定原始數列如下,要求從小到大排序:
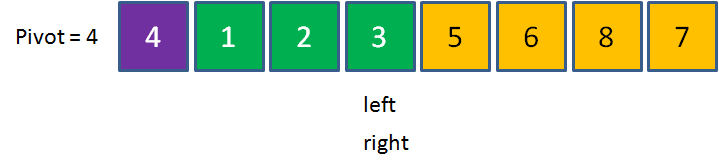
開局和挖坑法相似,我們首先選定基準元素Pivot,并且設定兩個指標left和right,指向數列的最左和最右兩個元素:
接下來是第一次回圈,從right指標開始,把指標所指向的元素和基準元素做比較,
如果大于等于pivot,則指標向左移動;如果小于pivot,則right指標停止移動,切換到left指標,
在當前數列中,1<4,所以right直接停止移動,換到left指標,進行下一步行動,
輪到left指標行動,把指標所指向的元素和基準元素做比較,如果小于等于pivot,則指標向右移動;如果大于pivot,則left指標停止移動,
由于left一開始指向的是基準元素,判斷肯定相等,所以left右移一位,
由于7 > 4,left指標在元素7的位置停下,這時候,我們讓left和right指向的元素進行交換,
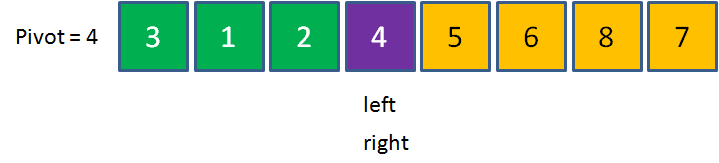
接下來,我們進入第二次回圈,重新切換到right向左移動,right先移動到8,8>4,繼續左移,由于2<4,停止在2的位置,
切換到left,6>4,停止在6的位置,
元素6和2交換,
進入第三次回圈,right移動到元素3停止,left移動到元素5停止,
元素5和3交換,
進入第四次回圈,right移動到元素3停止,這時候請注意,left和right指標已經重合在了一起,
當left和right指標重合之時,我們讓pivot元素和left與right重合點的元素進行交換,此時數列左邊的元素都小于4,數列右邊的元素都大于4,這一輪交換終告結束,









🎥 動圖演示
我們再來看一個動態圖👇
📃 代碼實作
//快速排序(前后指標法)
void QuickSort2(int* a, int begin, int end)
{
if (begin >= end)//當只有一個資料或是序列不存在時,不需要進行操作
return;
//三數取中
int midIndex = GetMidIndex(a, begin, end);
Swap(&a[begin], &a[midIndex]);
int prev = begin;
int cur = begin + 1;
int keyi = begin;
while (cur <= end)//當cur未越界時繼續
{
if (a[cur] < a[keyi] && ++prev != cur)//cur指向的內容小于key
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
int meeti = prev;//cur越界時,prev的位置
Swap(&a[keyi], &a[meeti]);//交換key和prev指標指向的內容
QuickSort2(a, begin, meeti - 1);//key的左序列進行此操作
QuickSort2(a, meeti + 1, end);//key的右序列進行此操作
}
時間復雜度: O ( N l o g N ) O(NlogN) O(NlogN)
🍑 非遞回實作
我們前面實作快排是采用遞回的方式,但是有些場景遞回解決不了的問題
1、當遞回深度過大的時候,遞回程式本身可能沒用錯誤,但是編譯之后會報錯——堆疊溢位(stack overflow),
2、性能問題,
于是就需要非遞回登場了
當我們需要將一個用遞回實作的演算法改為非遞回時,一般需要借用一個資料結構,那就是堆疊,
介紹空間復雜度時我們曾經提到過,代碼中?層?層的?法調?,本?就使?了?個?法調?堆疊,每次進??個新?法,就相當于?堆疊;每次有?法回傳,就相當于出堆疊,
所以,可以把原本的遞回實作轉化成?個堆疊的實作,在堆疊中存盤每? 次?法調?的引數,
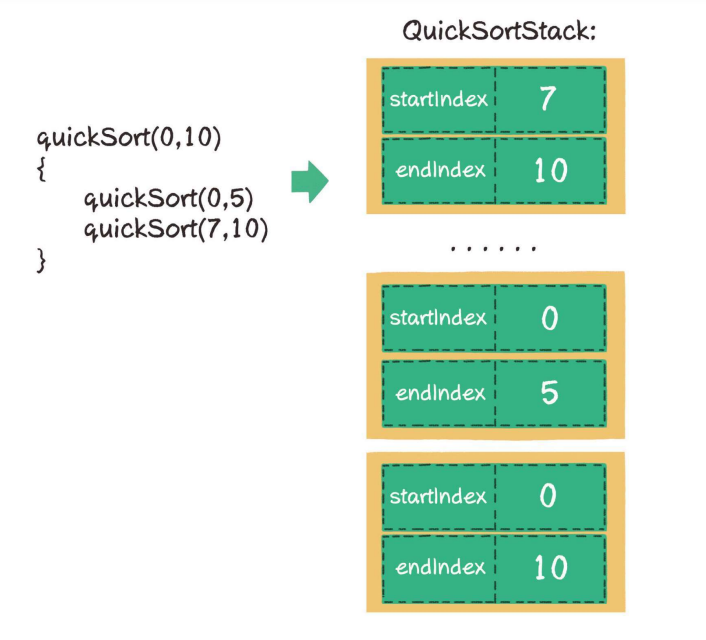
📃 挖坑法
//挖坑法(單趟排序)
int PartSort2(int* a, int left, int right)
{
int key = a[left];//在最左邊形成一個坑位
while (left < right)
{
//right向左,找小
while (left < right&&a[right] >= key)
{
right--;
}
//填坑
a[left] = a[right];
//left向右,找大
while (left < right&&a[left] <= key)
{
left++;
}
//填坑
a[right] = a[left];
}
int meeti = left;//L和R的相遇點
a[meeti] = key;//將key拋入坑位
return meeti;//回傳key的當前位置
}
📃 前后指標法
//前后指標法(單趟排序)
int PartSort3(int* a, int left, int right)
{
int prev = left;
int cur = left + 1;
int keyi = left;
while (cur <= right)//當cur未越界時繼續
{
if (a[cur] < a[keyi] && ++prev != cur)//cur指向的內容小于key
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
int meeti = prev;//cur越界時,prev的位置
Swap(&a[keyi], &a[meeti]);//交換key和prev指標指向的內容
return meeti;//回傳key的當前位置
}
🍑 特性總結
1、 快速排序整體的綜合性能和使用場景都是比較好的,所以才敢叫快速排序
2、時間復雜度: O ( N ? l o g N ) O(N*logN) O(N?logN)
3、 空間復雜度: O ( l o g N ) O(logN) O(logN)
4、穩定性:不穩定
總結
在 交換排序中,快速排序是不太容易理解的,這里我推薦大家可以多看下視頻,或者閱讀一些書籍;
🤗作者水平有限,如有總結不對的地方,歡迎留言或者私信!
💕如果你覺得這篇文章還不錯的話,那么點贊👍、評論💬、收藏🤞就是對我最大的支持!
🌟你知道的越多,你不知道越多,我們下期見!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385602.html
標籤:其他
上一篇:Linux中的31個普通信號