目錄
1. 前言
2. Scikit-learn內置資料集
3. 資料加載示例
例1:鳶尾花資料集
例2:糖尿病資料集
例3:手寫數字資料集
1. 前言
機器學習演算法是以資料為糧食的,所以機器學習開發的第一步就是資料的準備,資料預處理和特征工程是機器學習中不顯眼(沒有像演算法開發那樣亮麗)但是往往是涉及作業量最大的一部分,
對機器學習演算法的學習和開發人員的一個福音是互聯網上有很多開源的資料集,scikit-learn也內置了一部分簡單的規模較小的資料(toy datasets,玩具資料集),并且為其它規模較大的資料集準備了相應的獲取(下載)的API,這些資料集已經經過了適當的預處理,可以使得機器學習演算法的學習和開發人員可以回避掉資料采集和處理的“吃力不討好”的程序而聚焦于機器學習演算法本身,
此外,scikit-learn還有自動生成面向各種機器學習問題的隨機資料集的工具,這些隨機生成的資料集雖然不是來源于實際測量,但是由于可以很簡單地生成,而且其統計特征是受控的,所以對于機器學習的學習者或者機器學習演算法的早期開發驗證也是非常有用,
本系列簡要介紹這幾種資料集的生成、加載和/或獲取方式,以及相應的基于scikit-learn的處理方法,
本文作為本系列的第一篇,先介紹scikit-learn內置的一些玩具資料集,
2. Scikit-learn內置資料集
Scikit-learn中內置了一些非常經典的小規模的資料集(稱為toy datasets, 玩具資料集),這些資料集可以用sklearn.dataset模塊中load_xyz系列函式進行加載(其中'xyz'表示資料集的名稱),
詳細參見: 7.1. Toy datasets — scikit-learn 1.0.1 documentation
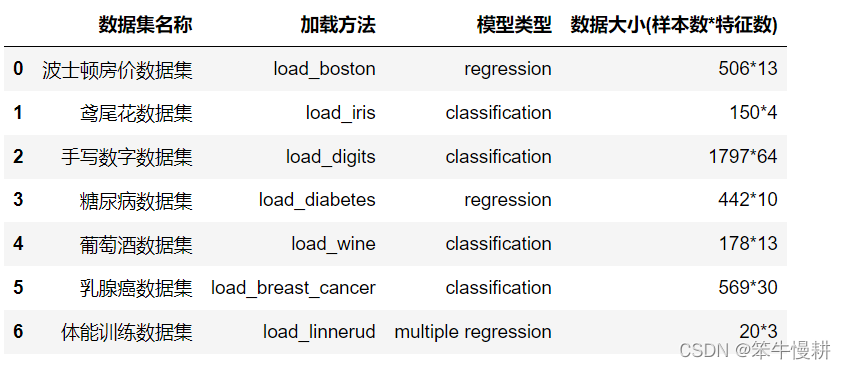
以上這個表格是用以下代碼在Jupyter Notebook中生成的, 這也算是對Pandas DataFrame的一種妖嬈的用法了^-^.
import pandas as pd
dataset = pd.DataFrame()
dataset['資料集名稱'] = ['波士頓房價資料集','鳶尾花資料集','手寫數字資料集','糖尿病資料集','葡萄酒資料集','乳腺癌資料集','體能訓練資料集']
dataset['加載方法'] = ['load_boston','load_iris','load_digits','load_diabetes','load_wine','load_breast_cancer','load_linnerud']
dataset['模型型別'] = ['regression','classification','classification','regression','classification','classification','multiple regression']
dataset['資料大小(樣本數*特征數)'] = ['506*13','150*4','1797*64','442*10','178*13','569*30','20*3']
dataset3. 資料加載示例
例1:鳶尾花資料集
from sklearn.datasets import load_iris, load_digits, load_diabetes
from sklearn.datasets import get_data_home
iris = sklearn.datasets.load_iris()
print(type(iris))
#print(iris.DESCR)
print(list(iris))
print(iris['data'].shape, iris['target'].shape)
print(iris['frame'])
print(iris['feature_names'])
print(iris['filename'])
print(iris['data_module'])<class 'sklearn.utils.Bunch'> ['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'] (150, 4) (150,) None ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] iris.csv sklearn.datasets.data
如以上例子所示,sklearn通過load_xyz()加載的資料集以Bunch的格式回傳,與Python中的dict很像,里面包含鍵值對(key-value pair),
首先我們可以通過list()呼叫觀察所加載的資料集有哪些鍵,
需要注意的是,并不是每個資料集都具有完全相同的鍵集,比如說iris資料集有8個鍵值,而波斯頓房價資料集則只有6個,但是'data','target','DESCR'大家都有,而且可能最常用的可能就是這3個,'DESCR'包含了該資料集的描述性資訊,'data','target'則顧名思義分別是指資料樣本及對應的標簽,
例2:糖尿病資料集
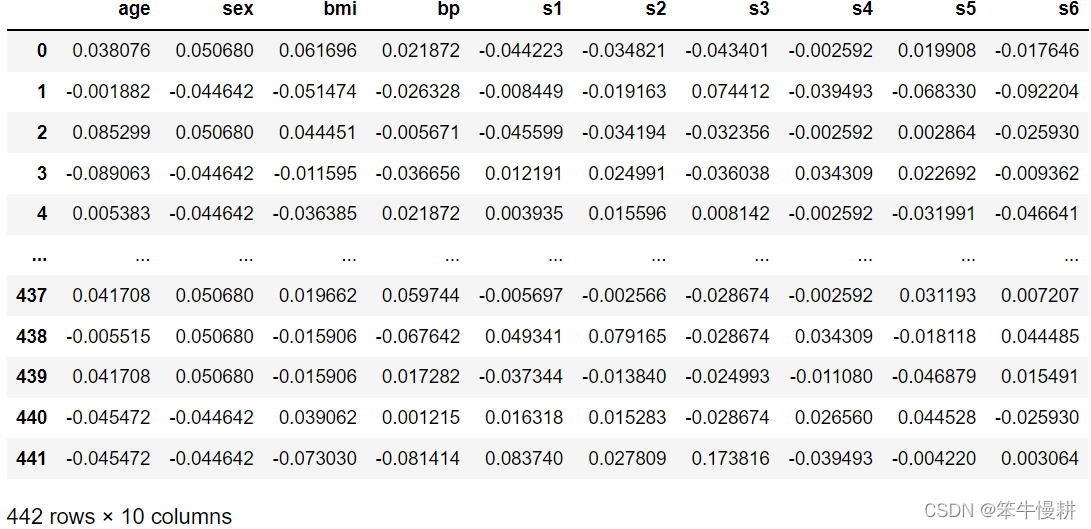
考慮到可能Pandas DataFrame可能更加為人熟知,也可以把Bunch資料轉換為Pandas Dataframe然后再做進一步的處理,如下所示,DataFrame的顯示更養眼一些,
當然,其實每個函式都有一個引數'as_frame',如果這個引數被設定為True的話,下載時就順便轉換成Pandas DataFrame,而不需要下載后再顯式地轉換了,
diabetes = sklearn.datasets.load_diabetes()
#print(df.DESCR)
print(list(diabetes))
print(diabetes['data'].shape, diabetes['target'].shape)
# 轉化為df
df = pd.DataFrame.from_records(data=diabetes.data, columns=data.feature_names)
df['data', 'target', 'frame', 'DESCR', 'feature_names', 'data_filename', 'target_filename', 'data_module'] (442, 10) (442,)
例3:手寫數字資料集
手寫數字資料集由于其原始資料其實是二維影像,所以其中還有'images'這一項,對應了資料樣本的二維表示,可以用imshow()作為影像顯示出來,
from matplotlib.pyplot import imshow
df = sklearn.datasets.load_digits()
#print(df.DESCR)
print(list(df))
imshow(df['images'][10])['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR']

如上圖可以看出,‘手寫數字資料集’中的數字只有8?8的大小(比之MNIST的28?28要小得多),所以人眼看上去很難辨認,但是機器演算法能夠做到!
下一篇:機器學習筆記:常用資料集之scikit-learn在線下載開源資料集
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385910.html
標籤:AI