目錄
物流專案介紹和內容大綱
一、專案簡介
二、功能介紹
三、內容大綱
四、技術亮點及價值有離線業務、也有實時業務
物流專案介紹和內容大綱
一、專案簡介
本專案基于大型物流公司研發的智慧物流大資料平臺,該物流公司是國內綜合性快遞、物流服務商,并在全國各地都有覆寫的網點,經過多年的積累、經營以及布局,擁有大規模的客戶群,日訂單達上千萬,如此規模的業務資料量,傳統的資料處理技術已經不能滿足企業的經營分析需求,該公司需要基于大資料技術構建資料中心,從而挖掘出隱藏在資料背后的資訊價值,為企業提供有益的幫助,帶來更大的利潤和商機
該大資料專案主要圍繞訂單、運輸、倉儲、搬運裝卸、包裝以及流通加工等物流環節中涉及的資料、資訊等,通過大資料分析可以提高運輸以及配送效率、減少物流成本、更有效地滿足客戶服務要求,實作快速、高效、經濟的物流,并針對資料分析結果,提出具有中觀指導意義的解決方案
物流大資料可以根據市場進行資料分析,提高運營管理效率,合理規劃分配資源,調整業務結構,確保每個業務均可盈利,根據資料分析結果,規劃、預計運輸路線和配送路線,緩解運輸高峰期的物流行為,提高客戶的滿意度,提高客戶粘度
二、功能介紹
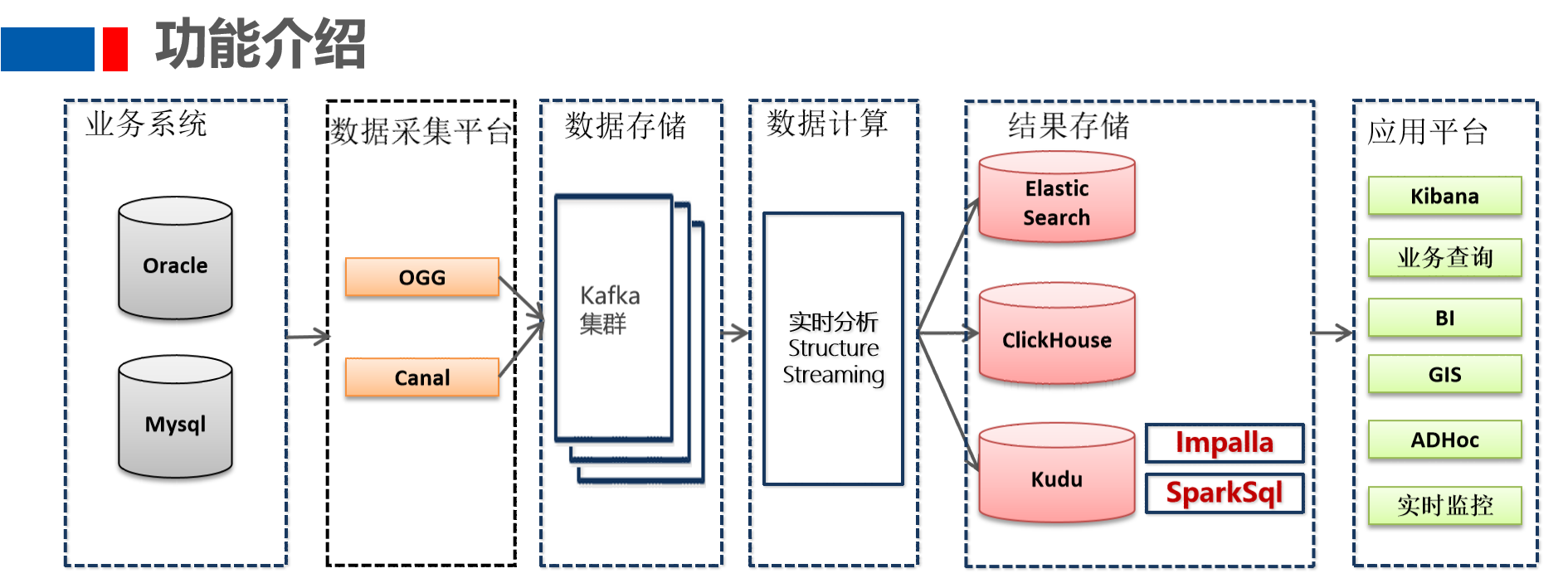
1、 業務系統資料主要存放到Oracle和Mysql資料庫中,比如CRM系統資料在Mysql,OMS系統資料存放在Oracle中
2、OGG增量同步Oracle資料庫的資料,Canal增量同步Mysql資料庫的資料
3、OGG及Canal增量抽取的資料會寫入到Kafka集群,供實時分析計算程式消費
4、實時分析計算程式消費kafka的資料,將消費出來的資料進行ETL操作
5、為了方便業務部門對各類單據的查詢,StructureStreaming流式處理系統將資料經過JOIN處理后,將資料寫入到Elastic Search中
6、StructureStreaming流處理會將資料寫入到ClickHouse,Java Web后端直接將資料查詢出來進行展示
7、StructureStreaming將實時ETL處理后的資料同步更新到Kudu中,方便進行資料的準實時分析、查詢,Impala對kudu資料進行分析查詢
8、前端應用對資料進行可視化展示
三、內容大綱
- 第1章:客快物流大資料之專案介紹及解決方案
- 第2章:客快物流大資料之docker使用
- 第3章:客快物流大資料之業務服務器環境配置
- 第4章:客快物流大資料之大資料服務器環境配置
- 第5章:客快物流大資料之實時ETL開發
- 第6章:客快物流大資料之主題及指標開發
- 第7章:客快物流大資料之實時OLAP分析
- 第8章:客快物流大資料之ES全文檢索
- 第9章:客快物流大資料之資料服務開發
四、技術亮點及價值有離線業務、也有實時業務
- 基于Docker搭建異構資料源,還原企業真實應用場景
- 以企業主流的Spark生態圈為核心技術,例如:Structure Streaming
- Azkaban定時調度主題及指標統計作業
- Kudu + Impala準實時分析系統
- 使用HUE集成Impala進行資料即席查詢
- ClickHouse實時存盤、計算引擎
- 自定義資料源實作Spark與Clickhouse的整合
- ELK全文檢索
- Spring Cloud搭建資料服務
- 存盤、計算性能調優
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢大資料系列文章會每天更新,停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386518.html
標籤:其他