本文章收錄于【Elasticsearch 系列】,將詳細的講解 Elasticsearch 整個大體系,包括但不限于ELK講解、ES調優、海量資料處理等
一、什么是mapping
自動或手動為index中的type建立的一種資料結構和相關配置,簡稱為mapping,我們以下面的例子來說明什么是mapping,
插入幾條資料,讓es自動為我們建立一個索引
PUT /article/_doc/1
{
"post_date": "2017-01-01",
"title": "my first article",
"content": "this is my fi rst article in this website",
"author_id": 11400
}我們可以通過 GET article/_mapping 命令來查看es自動建立的mapping,從下圖可以看出es會根據欄位值的不同會給欄位設定不同的值
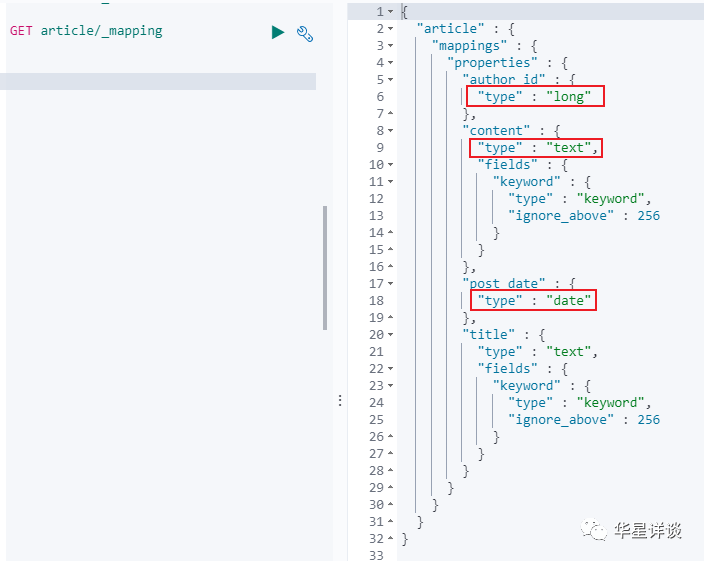
dynamic mapping,自動為我們建立index,以及對應的mapping,mapping中包含了每個field對應的資料型別,以及如何分詞等
當然我們也可以手動在創建資料之前,先創建index以及對應的mapping
二、精確匹配與全文搜索的對比分析
1、精確匹配(exact value)
Elasticsearch中的資料可以大致分為兩種型別:精準匹配及全文文本,
精準匹配是確定的,正如它的名字一樣,精準匹配“Foo”和“foo”就并不相同,2021 和2021-09-15也不相同,
比如有個欄位的值是2022-01-01,當通過精準匹配(exact value)搜索的時候,必須輸入2022-01-01,才能搜索出來,如果你輸入一個01,是搜索不出來的,
2、全文檢索(full text)
全文文本從另一個角度來說是文本化的資料(常常以人類的語言書寫),比如一篇推文(Twitter的文章)或郵件正文,
全文文本(full text)就不是說單純的只是匹配完整的一個值,而是可以對值進行拆分詞語后(分詞)進行匹配,也可以通過縮寫、時態、大小寫、同義詞等進行匹配,
比如:
(1)縮寫 vs. 全程:cn vs china
(2)格式轉化:like liked likes
(3)大小寫:Tom vs tom
(4)同義詞:like vs love
2017-01-01,2017 01 01,搜索2017,或者01,都可以搜索出來
china,搜索cn,也可以將china搜索出來
likes,搜索like,也可以將likes搜索出來
Tom,搜索tom,也可以將Tom搜索出來
like,搜索love,同義詞,也可以將like搜索出來
三、倒排索引原理理解
假如我們有兩個檔案,他們分別是
doc1:I really liked my small dogs, and I think my mom also liked them.
doc2:He never liked any dogs, so I hope that my mom will not expect me to liked him.我們來進行模擬分詞以及倒排索引的建立,建立倒排索引的時候,會執行一個操作(normalization),也就是說對拆分出的各個單詞進行相應的處理,以提升后面搜索的時候能夠搜索到相關聯的檔案的概率,
normalization簡單來說就是在建立倒排索引時進行時態的轉換,單復數的轉換,同義詞的轉換,大小寫的轉換,比如:mom —> mother,liked —> like,small —> little,dogs —> dog,
建立倒排索引,加入normalization

?
當使用mother liked little dog搜索時,會先進行分詞,然后進行normalization,就會把mother 轉成 mom、like-->like、little--> little、dog-->dog,
搜索結果:doc1和doc2都會搜索出來
四、分詞器的內部組成到底是什么,以及內置分詞器的介紹
1、什么是分詞器
分詞器是Elasticsearch中很重要的一個組件,用來將一段文本分析成一個一個的詞,Elasticsearch再根據這些詞去做倒排索引,主要功能是做切分詞語和normalization(提升recall召回率)
比如給你一段句子,然后將這段句子拆分成一個一個的單個的單詞,同時對每個單詞進行normalization(時態轉換,單復數轉換),分詞器
recall召回率:搜索的時候,增加能夠搜索到的結果的數量
2、分詞器內部主要組成部分
分詞器主要由三個部門組成:字符過濾器(character filter)、分詞器(tokenizer)、token filter
-
character filter:在一段文本進行分詞之前,先進行預處理,比如說最常見的就是,過濾html標簽(<span>hello<span> 轉換成 hello),& 轉換成 and(I&you 轉換成 I and you);
-
tokenizer:進行分詞處置,比如hello you and me 進行分詞之后 hello, you, and, me
-
token filter:進行normalization相關的一些操作,比如dogs轉換成dog、liked轉換成like、Tom轉換成tom、a/the/an這種無意義的停用詞直接干掉、mother轉換成mom、small轉換成little,
分詞器非常重要,它能夠將一段文本進行各種處理,最后處理好的結果才會拿去建立倒排索引,
2、elasticsearch內置分詞器介紹
-
standard analyzer:標準分詞器,是Elasticsearch中默認的分詞器,可以拆分英文單詞,大寫字母統一轉換成小寫,
-
simple analyzer:按非字母的字符分詞,例如:數字、標點符號、特殊字符等,會去掉非字母的詞,大寫字母統一轉換成小寫,
-
whitespace analyzer:簡單按照空格進行分詞,相當于按照空格split了一下,大寫字母不會轉換成小寫,
-
stop analyzer:會去掉無意義的詞,例如:the、a、an 等,大寫字母統一轉換成小寫,
-
keyword analyzer:不拆分,整個文本當作一個詞,
elasticsearch 中默認使用的分詞器為standard,
下面用一個例子來說明在各個分詞器中的表現
例子陳述句:Set the shape to semi-transparent by calling set_trans(5)
在各種分詞器中的表現為
standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5
simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
language analyzer(特定的語言的分詞器,比如說,英語分詞器):set, shape, semi, transpar, call, set_tran, 5
五、query string的分詞器
1、query string分詞
query string必須和index建立時相同的analyzer進行分詞,其對exact value和full text是區別對待的
比如我們有一個document,其中有一個field,包含的value是:hello you and me,建立倒排索引,我們要搜索這個document對應的index,搜索文本是hell me,這個搜索文本就是query string,
query string默認情況下es會使用它對應的field建立倒排索引時相同的分詞器去進行分詞,進行分詞和normalization,只有這樣才能實作正確的搜索
比如我們建立倒排索引的時候,將dogs --> dog,結果你搜索的時候,還是一個dogs,那不就搜索不到了嗎?所以搜索的時候,那個dogs也必須變成dog才行,才能搜索到,
不同型別的field,可能有的就是full text,有的就是exact value
六、mapping 元資料詳細講解
1、什么是mapping
mapping是定義檔案及其包含的欄位如何存盤和索引的程序,
mapping就是index的元資料,每個index都有一個自己的mapping,決定了資料型別,建立倒排索引的行為,還有進行搜索的行為例如等,
可以使用映射(mapping)來定義哪些字串欄位應被視為全文欄位,哪些欄位包含數字、日期或地理位置以及日期值的格式,還可以自定義規則來控制動態添加欄位的映射,
ES的mapping類似于靜態語言中的資料型別:宣告一個變數為int型別的變數,以后這個變數都只能存盤int型別的資料,一個number型別的mapping欄位只能存盤number型別的資料,
同語言的資料型別相比,mapping還有一些其他的含義,mapping不僅告訴ES一個field中是什么型別的值, 它還告訴ES如何索引資料以及資料是否能被搜索到,
當你的查詢沒有回傳相應的資料,你的mapping很有可能有問題,當你拿不準的時候,直接檢查你的mapping,
當我們向elasticsearch中插入一條資料時,es內部流程如下:
(1)往es里面直接插入資料,es會自動建立索引,同時建立type以及對應的mapping
(2)mapping中就自動定義了每個field的資料型別
(3)不同的資料型別(比如說text和date),可能有的是exact value,有的是full text
(4)exact value,在建立倒排索引的時候,分詞的時候,是將整個值一起作為一個關鍵詞建立到倒排索引中的;full text,會經歷各種各樣的處理,分詞,normaliztion(時態轉換,同義詞轉換,大小寫轉換),才會建立到倒排索引中
(5)同時呢,exact value和full text型別的field就決定了,在一個搜索過來的時候,對exact value field或者是full text field進行搜索的行為也是不一樣的,會跟建立倒排索引的行為保持一致;比如說exact value搜索的時候,就是直接按照整個值進行匹配,full text query string,也會進行分詞和normalization再去倒排索引中去搜索
(6)可以用es的dynamic mapping,讓其自動建立mapping,包括自動設定資料型別;也可以提前手動創建index和type的mapping,自己對各個field進行設定,包括資料型別,包括索引行為,包括分詞器,等等
2、mapping的核心資料型別以及dynamic mapping
(1)、核心的資料型別
mapping的核心資料型別分為:
簡單型別:string、byte、short、integer、long、float、double、boolean、date;
物件型別:一種支持 JSON 分層性質的型別,例如 object或nested,
特殊型別:如geo_point, geo_shape, 或completion
(2)動態映射(dynamic mapping)
當我們插入一條資料時,如果這個索引在es中存在,es則會根據相應的規則幫我們動態映射到對應的mapping資料型別,
比如true或false會映射成boolean型別,123會映射成long型別,123.45映射成double型別,2017-01-01映射成date型別,"hello world" 映射成string(text)型別
(3)查看索引的mapping結構
GET article/_mapping
3、手動建立和修改mapping以及定制string型別資料是否分詞
(1)如何建立索引
允許分詞:analyzed
不允許分詞:not_analyzed
不能被索引和分詞:no
只能創建index時手動建立mapping,或者新增field mapping,但是不能update field mapping
創建索引
PUT /article
{
"mappings": {
"properties": {
"author_id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "english"
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
}
}
}
}(2)對mapping的各種操作
但是不能夠修改mapping,修改mapping時會報錯:index [article/F4pFl4TdQASTSN2y-kkgEA] already exists
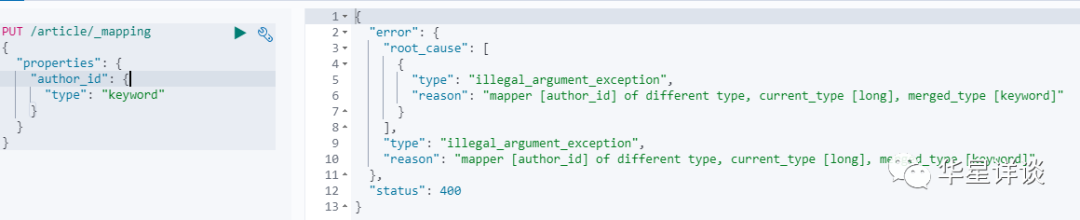
但是可以新增欄位,然后設定對應的資料型別
#新增mapping欄位映射
PUT /article/_mapping
{
"properties": {
"createName": {
"type": "keyword"
}
}
}查看索引中所有欄位的mapping映射
GET /article/_mapping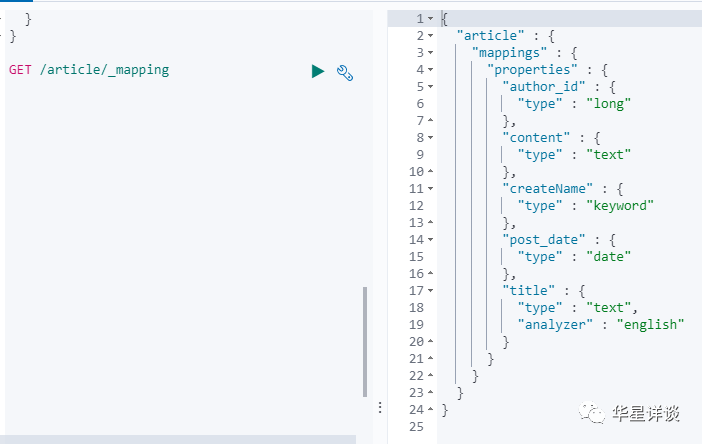
查看索引單個欄位的mapping映射
GET /article/_mapping/field/createName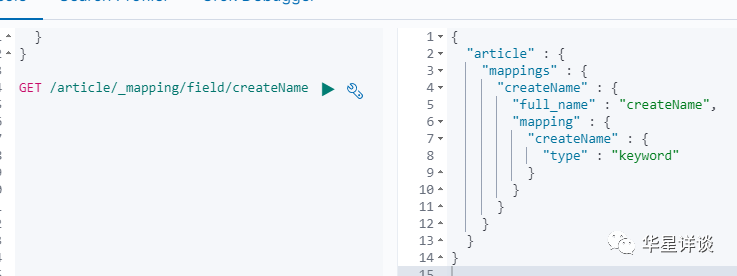
(3)mapping復雜資料型別以及object型別
a、多值欄位:multivalue field
{ "tags": [ "tag1", "tag2" ]}
建立索引時與string是一樣的,資料型別不能混
b、空欄位:empty field
null,[],[null]
c、物件欄位:object field
比如如下index中,address就是個物件欄位(object型別)
PUT /company/employee/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}< END >
本文章收錄于【Elasticsearch 系列】,將詳細的講解 Elasticsearch 整個大體系,包括但不限于ELK講解、ES調優、海量資料處理等
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386522.html
標籤:其他
下一篇:訊息佇列之RabbitMQ