前面介紹的三個神經網路都是“串聯”的,僅僅是卷積層的不斷堆疊,結構比較簡單,接下來兩篇博客要介紹的GoogLeNet和ResNet中開始出現“并聯”結構,這也是正式進入目標檢測演算法前最后要介紹的兩個神經網路啦!
文章目錄
- 一、引言
- 二、網路結構
- 1. Concatenation
- 2. Inception v1
- 3. 1×1卷積
- 4. 整體設計
- 三、實體演示
- 四、演變改進

一、引言
目標檢測整體的框架是由backbone、neck和head組成的,所以在學習具體的目標檢測演算法之前,有必要了解一下常見的卷積神經網路結構,這有利于后面學習目標檢測演算法的backbone部分,此前提到的AlexNet、VGGNet都是通過增大網路的層數來獲得更好的訓練效果,但是盲目增加網路層數會造成計算資源的浪費,增加網路復雜度不僅要考慮“深度”,也可以考慮“寬度”,GoogLeNet的做法給后面一系列網路結構帶來了啟發,因此有必要了解一下,
上一篇博客提到的VGGNet在2014年的ImageNet影像分類競賽中獲得了亞軍,而冠軍就是本文要介紹的GoogLeNet,GoogLeNet專注于加深網路結構,一共有22層,沒有全連接層,同時引入了新的基本結構——Inception模塊,以增加網路的寬度,這也是核心改進所在,GoogLeNet最初的想法很簡單,想要更好的預測效果,就要從網路深度和網路寬度兩個角度出發增加網路的復雜度,但這個思路有兩個較為明顯的問題:首先,更復雜的網路意味著更多的引數,即使是ILSVRC這種有1000類標簽的資料集也很容易過擬合;其次,更復雜的網路會消耗更多的計算資源,而且卷積核個數設計不合理會導致卷積核中引數沒有被完全利用(多種權重都趨近0),造成大量計算資源的浪費,GoogLeNet通過引入Inception模塊來解決上述問題,
二、網路結構
1. Concatenation
concatenation,也被簡稱為concat或者cat,其實就是一種特征融合方式,即整合特征圖的資訊,concat可以看成單獨一個層,實作對輸入資料的拼接,怎么拼接呢?下面來看一個例子:
import numpy as np
A = np.array([[1, 2], [3, 4]])
print("A.shape:", A.shape)
B = np.array([[5, 6]])
print("B.shape:", B.shape)
C = np.concatenate((A, B))
print("C:", C)
print("C.shape:", C.shape)
得到的輸出結果如下:
A.shape: (2, 2)
B.shape: (1, 2)
C: [[1 2]
[3 4]
[5 6]]
C.shape: (3, 2)
可以看出,其實就是完成矩陣之間的拼接,維度增加了,PyTorch中也有相應的cat()方法,可以指定按某個維度進行拼接,比如對一個矩陣來說,按行拼就是“豎著拼”,按列拼就是“橫著拼”,引數dim默認是0,而PyTorch中特征圖的第二維才是channels(batch_size×channels×height×width),所謂的特征融合concat就是把相同高和寬的特征圖按照通道疊加拼接在一起,所以寫代碼的時候要指定一下dim=1,如果要對兩個特征圖進行concat,一般需要通過上采樣或者下采樣,將他們的height和width調整成同樣大小,下面是PyTorch里的cat()方法使用示例,其實很好理解:
import torch
print("===========按維度0拼接===========")
A = torch.ones(2, 3) # 2x3的張量(矩陣)
print("A:", A, "\nA.shape:", A.shape)
B = 2 * torch.ones(4, 3) # 4x3的張量(矩陣)
print("B:", B, "\nB.shape:", B.shape,)
C = torch.cat((A, B), 0) # 按維數0(行)拼接
print("C:", C, "\nC.shape:", C.shape)
print("===========按維度1拼接===========")
A = torch.ones(2, 3) # 2x3的張量(矩陣)
print("A:", A, "\nA.shape:", A.shape)
B = 2 * torch.ones(2, 4) # 2x4的張量(矩陣)
print("B:", B, "\nB.shape:", B.shape)
C = torch.cat((A, B), 1) # 按維度1(列)拼接
print("C:", C, "\nC.shape:", C.shape)
得到的輸出結果如下:
===========按維度0拼接===========
A: tensor([[1., 1., 1.],
[1., 1., 1.]])
A.shape: torch.Size([2, 3])
B: tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
B.shape: torch.Size([4, 3])
C: tensor([[1., 1., 1.],
[1., 1., 1.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
C.shape: torch.Size([6, 3])
===========按維度1拼接===========
A: tensor([[1., 1., 1.],
[1., 1., 1.]])
A.shape: torch.Size([2, 3])
B: tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.]])
B.shape: torch.Size([2, 4])
C: tensor([[1., 1., 1., 2., 2., 2., 2.],
[1., 1., 1., 2., 2., 2., 2.]])
C.shape: torch.Size([2, 7])
2. Inception v1
GoogLeNet有很多版本,其區別主要體現在Inception的改進上,每個版本的Inception都在前一版的基礎上有所完善,先來看看最初的Inception v1,這也是GoogLeNet的核心模塊,
Inception的設計初衷是什么呢?首先,神經網路的權重矩陣是稀疏的,如果能將下面左邊的稀疏矩陣與2×2矩陣的卷積轉換成右邊2個子矩陣與2×2矩陣做卷積的方式,就能大大降低計算量,
[
5
2
0
0
0
0
1
2
0
0
0
0
0
0
3
7
4
0
0
0
6
4
0
0
0
0
0
0
5
0
0
0
0
0
0
0
]
?
[
3
4
2
2
]
?
[
5
2
1
2
]
?
[
3
4
2
2
]
[
3
7
4
6
4
0
0
0
5
]
?
[
3
4
2
2
]
\begin{bmatrix} 5 &2 &0 &0 &0 &0 \\ 1 &2 &0 &0 &0 &0 \\ 0 &0 &3 &7 &4 &0 \\ 0 &0 &6 &4 &0 &0 \\ 0 &0 &0 &0 &5 &0 \\ 0 &0 &0 &0 &0 &0 \end{bmatrix}\bigoplus \begin{bmatrix} 3 &4 \\ 2 &2 \end{bmatrix}\Leftrightarrow \frac{\begin{bmatrix} 5 &2 \\ 1 &2 \end{bmatrix}\bigoplus \begin{bmatrix} 3 &4 \\ 2 &2 \end{bmatrix}}{\begin{bmatrix} 3 &7 &4 \\ 6 &4 &0 \\ 0 &0 &5 \end{bmatrix}\bigoplus \begin{bmatrix} 3 &4 \\ 2 &2 \end{bmatrix}}
?????????510000?220000?003600?007400?004050?000000???????????[32?42?]????360?740?405?????[32?42?][51?22?]?[32?42?]?
同樣的道理,可以考慮將全連接變成稀疏連接,減少引數數量,但是這樣做在實作時卻不能很好地優化計算量,因為大部分硬體是針對密集矩陣的計算進行優化的,稀疏矩陣雖然資料量比較少,但是在計算上的耗時較長,不過,大量文獻表明,可以通過將稀疏矩陣聚類為較為密集的子矩陣來提高計算性能,從而在保持稀疏性的同時保持較高的計算性能,GoogLeNet就是通過構造“基礎神經元”來搭建一個稀疏的、具有高計算性能的網路結構,
于是就產生了下圖所示的結構,在這個結構中,將256個均勻分布在3×3尺度的特征轉換成多個不同尺度的聚類,這樣可以使計算更有效,收斂更快,下面是最原始的結構,利用了上一節說到的concatenation方法,使用不同大小的卷積核得到不同尺寸的特征并將其融合,卷積核的大小使用1、3、5的目的是方便對齊:設定步長為1,對三個尺寸的卷積核分別填充0、1、2,對池化操作填充1,通過concatenation方法即可實作相同尺寸特征圖的堆疊(尺寸相同,通道相加),
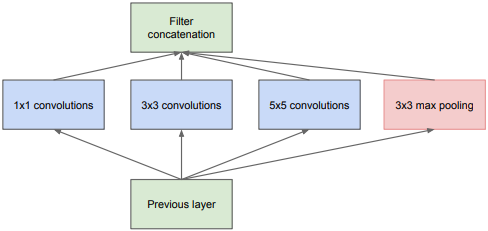
然而,這種結構仍然不理想,計算量的問題沒有得到很好的改善,對于5×5的卷積核來說,假設對100×100×128的輸入使用256個5×5的卷積核進行操作,那么引數個數將多達(128×5×5+1)×256=819456,如果在使用5×5的卷積核進行卷積之前,使用32個1×1的卷積操作,步長為1填充為0,那么就會得到100×100×32的特征圖,再與256個5×5的卷積核進行卷積的話,這兩步走的引數加起來也只有(128×1×1+1)×32+(32×5×5+1)×256=209184,引數量大大減少,整個程序如下圖所示,Inception v1就是以上述描述為基礎得到的,
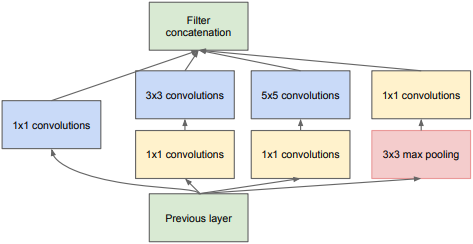
最后總結一下Inception v1的特點:
- 卷積層共有的一個功能,可以實作通道方向的降維和增維,至于是降還是增,取決于卷積層的通道數(卷積核個數);
- 由于1×1卷積只有一個引數,相當于對原始特征圖做了一個scale,并且這個scale還是通過訓練學習到的,對識別精度就會有提升;
- 增加了網路的深度和寬度;
- 同時使用了1×1,3×3,5×5的卷積,增加了網路對尺度的適應性,
3. 1×1卷積
Inception模塊里用到了1×1卷積,可能很多人在第一次看到這個東東時和我有著同樣的疑惑,和平常用的3×3、5×5卷積相比,這是個什么鬼?其實,1×1卷積的出現解決了很多問題,作用也很大,所以在這里單獨分析一波,
1×1卷積首先是出現在Network in Network(NIN)這篇論文當中,一般來講,其主要作用有以下四個:
- 進行通道數的降維和升維;
- 增加網路的非線性;
- 實作跨通道的互動和資訊整合;
- 實作與全連接層等價的效果,
對于作用1,降維主要是為了減少引數,上一節的討論就是最好的例子,GoogLeNet在利用1×1的卷積降維后,得到了更為緊湊的網路結構,雖然總共有22層,但是引數數量卻只是8層的AlexNet的十二分之一(當然也有很大一部分原因是去掉了全連接層),而升維主要是為了用最少的引數拓寬網路的通道數,比如256個3×3的卷積核引數量顯然要比256個1×1的卷積核大得多,
對于作用2,也很好理解,因為卷積層后面一般都會接一個非線性的激活函式,所以使用1×1卷積可以在保持特征圖尺度不變(即不損失解析度,不改變height和width)的前提下增加非線性特性,
對于作用3,其實就是通道之間的變換,這個作用可能會抽象一些,使用1×1卷積核,實作降維和升維的操作其實就是通道間資訊的線性組合變化,舉個栗子:在一個3×3×64的卷積核后面添加一個1×1×28的卷積核,這樣就得到了3×3×28卷積核,原來的64個通道就可以理解為跨通道線性組合變成了28個通道,這就是通道間的資訊互動,
對于作用4,通過上一篇博客里VGGNet測驗階段用卷積層替換全連接層的例子應該可以理解,
4. 整體設計
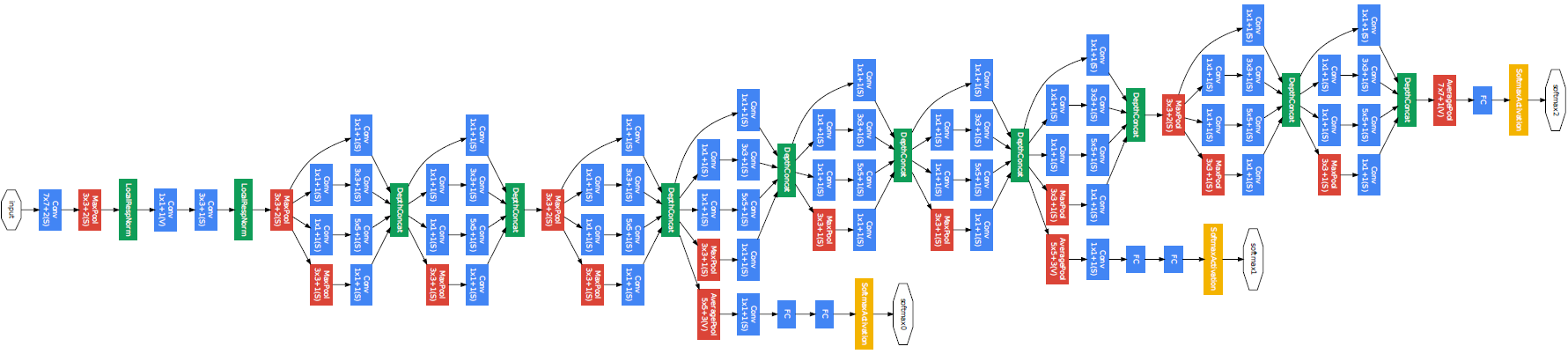
GoogLeNet的結構非常完整,原論文用了整整一面展示網路結構,下面是我把pdf橫過來后的截圖,
其實看下面這個表格也可以,同樣來自原論文,推薦大家去原論文Going deeper with convolutions
里看4K大圖:
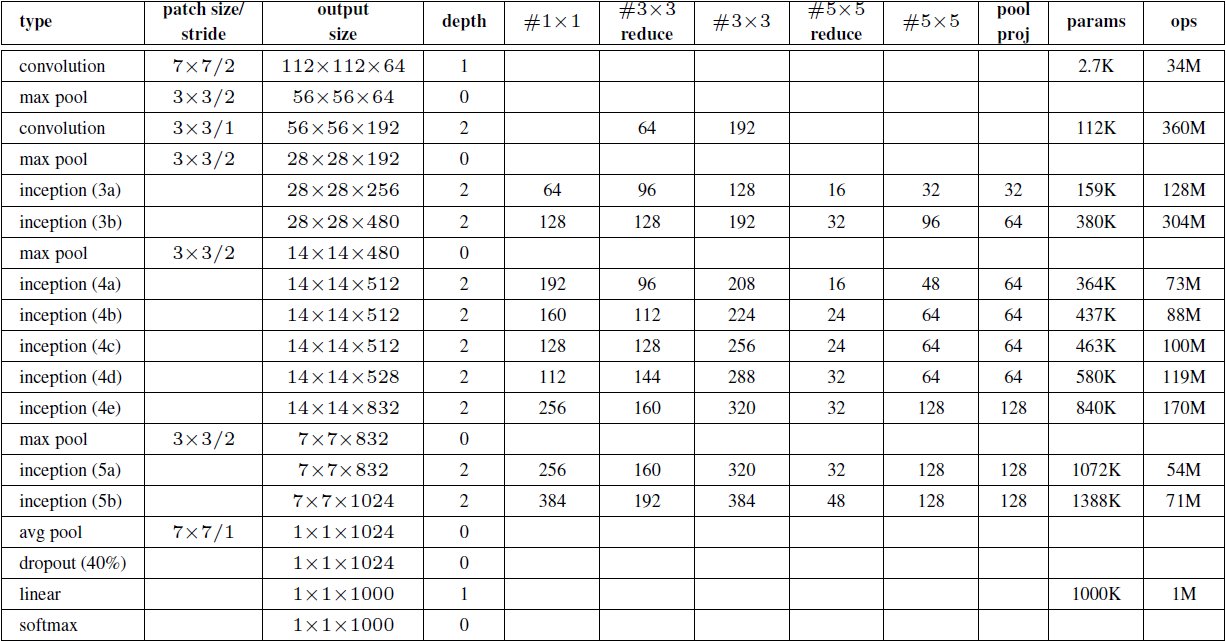
上表中#3×3reduce、#5×5reduce表示在3×3、5×5的卷積操作之前使用了1×1卷積操作,
除了前文討論,網路還有以下特性:
- 采用模塊化結構,組合拼接Inception結構,便于調整;
- 采用平均池化和全連接層的組合,實驗證明這樣做可以將準確率提高0.6%;
- 為了避免出現梯度消失的問題,網路額外增加了兩個輔助softmax函式,目的是增強反向傳播的速度,在訓練時,它們產生的損失會被加權到網路的總損失中;在測驗時,它們不參與分類作業,
三、實體演示
首先把Inception模塊實作出來,從前面的圖可以看出,Inception模塊有4條并行的線路,前3條線路分別使用1×1、3×3和5×5的卷積核提取不同空間尺寸下的資訊,中間2個線路會對輸入做1×1卷積運算,以減少輸入通道數,降低模型復雜度,第4條線路則會使用3×3最大池化層,然后接1×1卷積核改變通道數,4條線路都使用了合適的填充,使得輸入與輸出的特征圖高和寬一致,最后將每條線路的輸出在通道上合并,并輸入到接下來的層中,Inception v1模塊實作代碼如下:
import torch.nn as nn
import torch
def BasicConv2d(in_channels, out_channels, kernel_size):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=kernel_size // 2),
nn.BatchNorm2d(out_channels),
nn.ReLU(True)
)
class InceptionV1Module(nn.Module):
def __init__(self, in_channels, out_channels1, out_channels2reduce, out_channels2, out_channels3reduce,
out_channels3, out_channels4):
super.__init__()
# 線路1,單個1×1卷積層
self.branch1_conv = BasicConv2d(in_channels, out_channels1, kernel_size=1)
# 線路2,1×1卷積層后接3×3卷積層
self.branch2_conv1 = BasicConv2d(in_channels, out_channels2reduce, kernel_size=1)
self.branch2_conv2 = BasicConv2d(out_channels2reduce, out_channels2, kernel_size=3)
# 線路3,1×1卷積層后接5×5卷積層
self.branch3_conv1 = BasicConv2d(in_channels, out_channels3reduce, kernel_size=1)
self.branch3_conv2 = BasicConv2d(out_channels3reduce, out_channels3, kernel_size=5)
# 線路4,3×3最大池化層后接1×1卷積層
self.branch4_pool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.branch4_conv = BasicConv2d(in_channels, out_channels4, kernel_size=1)
def forward(self, x):
out1 = self.branch1_conv(x)
out2 = self.branch2_conv2(self.branch2_conv1(x))
out3 = self.branch3_conv2(self.branch3_conv1(x))
out4 = self.branch4_conv(self.branch4_pool(x))
out = torch.cat([out1, out2, out3, out4], dim=1)
return out
假設原始輸入影像尺寸為224×224×3,GoogLeNet的第一個模塊使用了一個64通道、卷積核尺寸為7×7的卷積層,stride=2,padding=3,輸出尺寸為112×112×64,卷積后進行ReLU操作,經過3×3的最大池化操作(stride=2)后,得到的輸出尺寸為56×56×64,
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
第二個模塊使用兩個卷積層,首先經過64通道的1×1卷積層,然后經過192通道的3×3卷積層,對應的是Inception模塊中從左到右的第二條線路,
nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
第三個模塊Inception(3a):①先經過1×1×64的卷積操作,得到28×28×64的輸出特征圖并送入ReLU激活函式;②接著經過1×1×96的卷積操作,得到28×28×96的輸出特征圖并送入ReLU激活函式,然后經過3×3×128的卷積操作(padding=1),得到28×28×128的輸出特征圖;③再經過1×1×16的卷積操作,得到28×28×16的輸出特征圖并送入ReLU激活函式,然后經過5×5×32的卷積操作(padding=2),得到28×28×32的輸出特征圖;④最后經過3×3的最大池化操作(padding=1)后接1×1×32的卷積操作,得到28×28×32的輸出特征圖,把4個分支合并為64+128+32+32=256個通道,就得到了尺寸為28×28×256的輸出特征圖,Inception(3b)和Inception(3a)計算程序類似,最后輸出480通道,
InceptionV1Module(192, 64, 96, 128, 16, 32, 32),
InceptionV1Module(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
第四個模塊更復雜了一些,但是理解起來很簡單,就是串聯了5個Inception模塊,
InceptionV1Module(480, 192, 96, 208, 16, 48, 64),
InceptionV1Module(512, 160, 112, 224, 24, 64, 64),
InceptionV1Module(512, 128, 128, 256, 24, 64, 64),
InceptionV1Module(512, 112, 144, 288, 32, 64, 64),
InceptionV1Module(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
第五個模塊和上述模塊類似,只是后面緊跟輸出層,該模塊需要使用平均池化層將每個通道的height和width都變成1,
InceptionV1Module(832, 256, 160, 320, 32, 128, 128),
InceptionV1Module(832, 384, 192, 384, 48, 128, 128),
nn.AvgPool2d(kernel_size=7, stride=1)
最后,將輸出變成二維陣列后,接一個輸出個數為標簽類別數的全連接層,
nn.Dropout(0.4),
nn.Linear(1024, num_classes)
完整的代碼如下:
class GoogLeNet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.inception3 = nn.Sequential(
InceptionV1Module(192, 64, 96, 128, 16, 32, 32),
InceptionV1Module(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.inception4 = nn.Sequential(
InceptionV1Module(480, 192, 96, 208, 16, 48, 64),
InceptionV1Module(512, 160, 112, 224, 24, 64, 64),
InceptionV1Module(512, 128, 128, 256, 24, 64, 64),
InceptionV1Module(512, 112, 144, 288, 32, 64, 64),
InceptionV1Module(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.inception5 = nn.Sequential(
InceptionV1Module(832, 256, 160, 320, 32, 128, 128),
InceptionV1Module(832, 384, 192, 384, 48, 128, 128),
nn.AvgPool2d(kernel_size=7, stride=1)
)
self.fc = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.inception3(x)
x = self.inception4(x)
x = self.inception5(x)
x = x.view(x.size(0), -1)
out = self.fc(x)
return out
可以把以下FlattenLayer加在全連接層容器最前面,來替換掉forward里的x.view,用下面的代碼查看各層輸出的尺寸:
class FlattenLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x.view(x.size(0), -1)
net = GoogLeNet(1000)
X = torch.rand(1, 3, 224, 224)
for block in net.children():
X = block(X)
print('output shape: ', X.shape)
得到的輸出結果如下:
output shape: torch.Size([1, 64, 56, 56])
output shape: torch.Size([1, 192, 28, 28])
output shape: torch.Size([1, 480, 14, 14])
output shape: torch.Size([1, 832, 7, 7])
output shape: torch.Size([1, 1024, 1, 1])
output shape: torch.Size([1, 1000])
四、演變改進
下面簡要介紹一下Inception v1改進:Inception v2,更多的諸如Xception這樣的變體就先不討論了,后面有時間再專門整理個Inception系列家族,之所以介紹v2不介紹后續的v3是因為v3里很多東西前面的博客還沒有涉及到,v2的核心思想在VGGNet里有提到一下,Inception v2和Inception v3是在同一篇論文Rethinking the Inception Architecture for Computer Vision中出現,提出Batch Normalization的論文Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift并不是Inception v2,兩者的區別在于論文里提到了多種設計和改進技術,使用其中一部分結構和改進技術的是Inception v2,全部使用了的是Inception v3,
GoogLeNet團隊在Inception v1的基礎上,提出了卷積核分解和特征圖尺寸縮減兩種優化方法,由于較大的卷積核尺寸可以帶來較大的感受野,但同時會帶來更多的引數和計算量,所以GoogLeNet團隊提出了用兩個連續的3×3卷積核代替一個5×5卷積核,在保持感受野大小的同時減少引數個數,第一個3×3的卷積核通過卷積,得到一個3×3的特征圖,然后通過一個3×3的卷積核產生一個1×1的特征圖,輸出尺寸與通過一個5×5的卷積核得到的輸出尺存相同,且引數的個數有所減少,大量實驗證明,這種替換不會造成表達缺失,這也是在上一篇博客中討論過的,
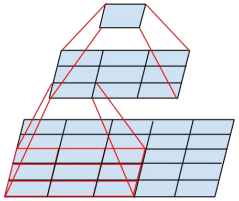
在此基礎上,GoogLeNet團隊考慮將卷積核進一步分解,例如,將3×3的卷積核分解,如下圖所示:先采用1×3的卷積核進行卷積,再通過3×1的卷積核進行二次卷積,最終的輸出尺寸與使用一個3×3的卷積核進行卷積后的輸出尺寸相同,且引數的數量又有所減少,所以,一個n×n的卷積核能夠由1×n和n×1的卷積核的組合代替,GoogLeNet團隊發現,在網路低層使用這種方法的效果并不好,而在中等大小的特征圖上使用這種方法的效果比較好(建議在第12層到第20層使用),
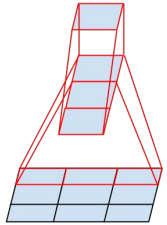
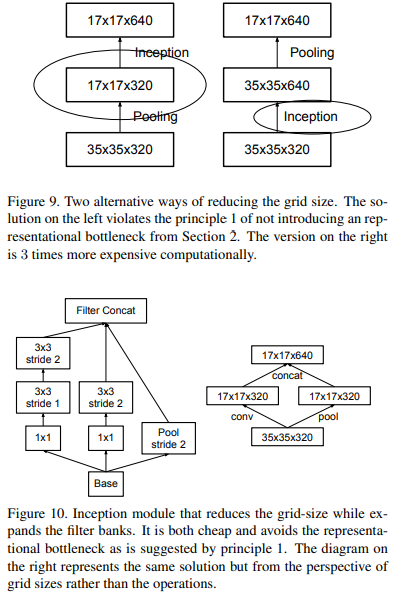
縮減特征圖尺寸的兩種方式,如下圖上面的兩個結構所示:一是先進行池化操作,再做Inception卷積;二是先做Inception卷積,再進行池化操作,然而,這兩種方式都有弊端:采用先池化、再卷積的方式,很可能會丟失部分特征;采用先卷積、再池化的方式,計算量會很大,為了在保持特征的同時降低計算量,GoogLeNet團隊讓卷積操作與池化操作并行,即先分開計算、再合并,
不知不覺1w多字了orz,Batch Normalization等有時間了再單獨記錄吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386580.html
標籤:其他