目錄
廢話
1.環境配置(jupyter notebook python 3.6.5)
2.訓練集準備
3.代碼思路(艸圖)
4.人臉識別原始碼
5.參考文章
6.可能遇到的問題
廢話
嗯,開局說點廢話,之前用stm32和esp8266改裝了下宿舍門,但終究覺得沒人臉識別來得舒服,所以就有了這篇文章
1.環境配置(jupyter notebook python 3.6.5)
我這里用的是python3.6,如果你想搭建一個3.6的環境又不想影響原有的,可以用小黑窗(Anaconda Prompt)搭建一個虛擬環境(虛擬環境是一個獨立的空間不會影響外界,也不會受外界影響,適合應對不同版本python的需求)
如何搭建虛擬環境可以看看這篇文,簡單粗暴
當你搭建好虛擬環境后,第三方庫的安裝也要安在虛擬環境里,那么如何切換到虛擬環境里呢
打開小黑窗
activate 虛擬環境名字
就可以激活了效果如下:

看到小括號就說明已經切換到虛擬環境里了
然后就可以安裝所需的第三方庫了,eg.Opencv,scipy,request,dlib,安裝方法如下:
1)OpenCV
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python==3.4.2.16pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python==3.4.2.162)scipy
pip install scipy
3) request
pip install request4) dlib
dlib庫的安裝比較麻煩,你得先找到對應版本,因為不同python版本對應不同dlib
如果你跟我一樣是3.6,那裝19.7就行
缺版本或找不到對應版本可以留言
2.訓練集準備
這個訓練集捏,是借助recognizer.train得到的.yml檔案,所以精度沒特別高,但是拿來玩玩門鎖 還是夠用,追求精度可以走深度學習
代碼如下:
1)第一步準備照片(即你的人臉像),以“序號.名稱”命名,例如“1.xx"這是為了方便切片和保存(即我們可以通過切片將每張照片的臉部特征,序號,名稱一一對應)記得你照片的存放路徑
2)第二步準備人臉資料集haarcascade_frontalface_alt2.xml,這個是opencv自帶的用于檢測人臉(注意是檢測人臉不是識別人臉)這種做法我覺得有點像RIO ,就是我們在一張圖片中匹配人像特征不是從角落開始,而是定位人臉,然后規劃一個區域,在區域內進行匹配,這樣節省很多時間
3)第三步,跑代碼就完事了,然后你會在你指定的檔案夾里面找到yml檔案,這就是你的訓練集
import os
import sys
from PIL import Image
import numpy as np
import cv2
def getImageAndLabels(path):
#建兩個空串列后續存盤資料
facesSamples=[]
ids=[]
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#檢測人臉
face_detector = cv2.CascadeClassifier('E:\jupyter_notebook\practice\haarcascades\haarcascade_frontalface_alt2.xml')
#列印陣列imagePaths
print('路徑:',imagePaths)
#遍歷串列中的圖片
for imagePath in imagePaths:
#打開圖片,灰度
PIL_img=Image.open(imagePath).convert('L')
#此時獲取的是整張圖片的陣列
img_numpy=np.array(PIL_img,'uint8')
#獲取圖片人臉特征,相當于rio
faces = face_detector.detectMultiScale(img_numpy)
#將檔案名前的名字轉化為ID并記錄下來
str_id = os.path.split(imagePath)[1].split('.')[0]
id = int(str_id)
#id = os.path.split(imagePath)[1].split('.')[0]
#預防檢測到無面容照片
for x,y,w,h in faces:
#把ID寫進ids串列中
ids.append(id)
#把所畫的方框寫進facesSamples串列中
facesSamples.append(img_numpy[y:y+h,x:x+w])
#列印臉部特征和id
print('id:', id)
print('fs:', facesSamples)
return facesSamples,idsif __name__ == '__main__':
#圖片路徑
path='E:/face_dormitory/train'
#獲取影像陣列和id標簽陣列和姓名
faces,ids=getImageAndLabels(path)
#獲取訓練物件
recognizer=cv2.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids))
#保存檔案
recognizer.write('E:/face_dormitory/opencv/trainer/trainer_xx.yml')3.代碼思路(艸圖)
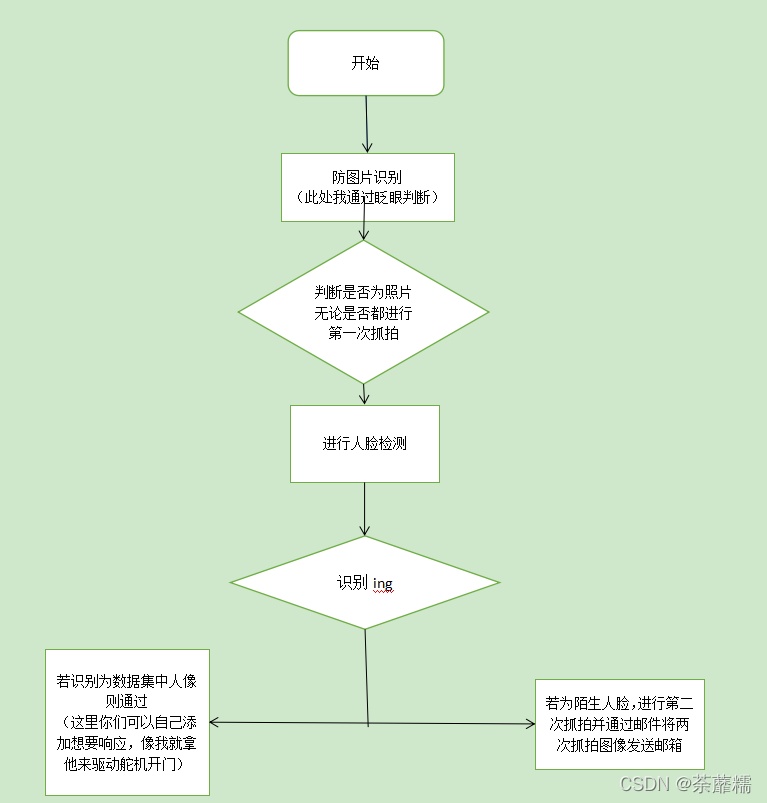
4.人臉識別原始碼
1)引入庫
import cv2
import numpy as np
import os
import urllib
import urllib.request
import hashlib
from scipy.spatial import distance as dist
from collections import OrderedDict
import argparse
import time
import dlib2)加載訓練集(這里shape_predictor_68_face_landmarks是用于眨眼檢測的)
#加載訓練資料集檔案
recogizer=cv2.face.LBPHFaceRecognizer_create()
recogizer.read('E:/face_dormitory/opencv/trainer/trainer_xx.yml')
names=[] #建個空id串列
warningtime = 0
predictor = dlib.shape_predictor('E:/face_dormitory/opencv/shape_predictor_68_face_landmarks.dat')3)郵件函式(即識別出陌生人或可疑人用于發送抓拍照片的)
import smtplib
from PIL import Image
import email # 檔案名不可以和引入的庫同名
from email.mime.image import MIMEImage # 圖片型別郵件
from email.mime.text import MIMEText # MIME 多用于郵件擴充協議
from email.mime.multipart import MIMEMultipart # 創建附件型別
HOST = 'smtp.qq.com' # 呼叫的郵箱借借口
SUBJECT = 'Warning!!!' # 設定郵件標題
FROM = '1xxxxxxxxx@qq.com' # 發件人的郵箱需先設定開啟smtp協議
#TO = '1xxxxxxxxxxx@qq.com' # 設定收件人的郵箱(可以一次發給多個人,用逗號分隔)
TO = 'xxxxxxxxxx@qq.com' # 設定收件人的郵箱(可以一次發給多個人,用逗號分隔)
message = MIMEMultipart('related') # 郵件資訊,內容為空 #相當于信封##related表示使用內嵌資源的形式,將郵件發送給對方
def sendmail(HOST, SUBJECT,FROM,TO,message):
# ===========發送資訊內容=============
message_html = MIMEText('<h1 style="color:red;font-size:100px">Warning!!!</h1><img src="cid:small">', 'html', 'utf-8')
message.attach(message_html)
# ===========發送圖片-=============
message_image0 = MIMEText(open('E:/face_dormitory/unidentified/0.jpg', 'rb').read(), 'base64', 'utf-8')
message_image0['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 設定圖片在附件當中的名字
message_image1 = MIMEText(open('E:/face_dormitory/unidentified/1.jpg', 'rb').read(), 'base64', 'utf-8')
message_image1['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 設定圖片在附件當中的名字
message.attach(message_image0)# 添加圖片檔案到郵件-附件中去
message.attach(message_image1)# 添加圖片檔案到郵件-附件中去
'''
path='E:/face_dormitory/unidentified'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
PIL_img=Image.open(imagePath,'utf-8')
PIL_img['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'
message.attach(PIL_img)
'''
# ===========洗掉緩沖圖片-=============
#os.remove('E:/face_dormitory/unidentified/0.jpg')
#os.remove('E:/face_dormitory/unidentified/1.jpg')
# ===========發送excel-附件=============
#message_xlsx = MIMEText(open('email_demo.xlsx', 'rb').read(), 'base64', 'utf-8')# 將xlsx檔案作為內容發送到對方的郵箱讀取excel,rb形式讀取,對于MIMEText()來說默認的編碼形式是base64 對于二進制檔案來說沒有設定base64,會出現亂碼
#message_xlsx['Content-Disposition'] = 'attachment;filename="email_demo_change.xlsx"'# 設定檔案在附件當中的名字
#message.attach(message_xlsx)# 添加excel檔案到郵件-附件中去
# ===========配置相關-=============
message['From'] = FROM # 設定郵件發件人
message['TO'] = TO # 設定郵件收件人
message['Subject'] = SUBJECT # 設定郵件標題
email_client = smtplib.SMTP_SSL()# 獲取傳輸協議
email_client.connect(HOST, '465')# 設定發送域名,埠465
result = email_client.login(FROM, 'xxxxxxx') # qq授權碼
print('登錄結果', result)
# ===========操作=============
email_client.sendmail(from_addr=FROM, to_addrs=TO.split(','), msg=message.as_string()) #發送郵件指令
email_client.close()# 關閉郵件發送客戶端寫郵件函式我是借鑒這個大佬的,站在巨人肩膀上嘛,總不能什么都靠自己來
4)防照片檢測(即眨眼檢測)這個也可以用于疲勞檢測
詳見:i·bug - resources - Facial point annotations
FACIAL_LANDMARKS_68_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 36)),
("jaw", (0, 17))
])def eye_aspect_ratio(eye):
# 計算距離,豎直的
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# 計算距離,水平的
C = dist.euclidean(eye[0], eye[3])
# ear值
ear = (A + B) / (2.0 * C)
return eardef shape_to_np(shape, dtype="int"):
# 創建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍歷每一個關鍵點
# 得到坐標
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coordsdef pervent_to_photo():
# 設定判斷引數
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
# 初始化計數器
COUNTER = 0
TOTAL = 0
# 檢測與定位工具
print("loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
#predictor = dlib.shape_predictor('E:/face_dormitory/opencv/shape_predictor_68_face_landmarks.dat')
# 分別取兩個眼睛區域
(lStart, lEnd) = FACIAL_LANDMARKS_68_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_68_IDXS["right_eye"]
# 讀取視頻
print("starting video stream thread...")
vs = cv2.VideoCapture(0)
time.sleep(1.0)
# 遍歷每一幀
while True:
# 預處理
frame = vs.read()[1]
if frame is None:
break
(h, w) = frame.shape[:2]
width=1200
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 檢測人臉
rects = detector(gray, 0)
# 遍歷每一個檢測到的人臉
for rect in rects:
# 獲取坐標
shape = predictor(gray, rect)
shape = shape_to_np(shape)
# 分別計算ear值
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# 算一個平均的
ear = (leftEAR + rightEAR) / 2.0
# 繪制眼睛區域
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
# 檢查是否滿足閾值
if ear < EYE_AR_THRESH:
COUNTER += 1
else:
# 如果連續幾幀都是閉眼的,總數算一次
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# 重置
COUNTER = 0
# 顯示
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Frame", frame)
#眨眼兩次則判斷不是照片
if TOTAL >= 2:
cv2.imwrite(r"E:/face_dormitory/unidentified/"+"1.jpg",frame) #抓拍
break
#空格退出
if ord(' ') == cv2.waitKey(10):
break
#vs.release()
cv2.destroyAllWindows()5)人臉檢測函式
#準備識別的圖片
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#轉換為灰度
face_detector=cv2.CascadeClassifier('E:\jupyter_notebook\practice\haarcascades\haarcascade_frontalface_alt2.xml') #加入資料集
face=face_detector.detectMultiScale(gray,1.1,5,cv2.CASCADE_SCALE_IMAGE,(100,100),(300,300)) #范圍在100*100~300*300判斷為臉
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人臉識別
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
#置信評分 confidence 越大越不可信
if confidence > 50:
global warningtime
global num
warningtime += 1
if warningtime > 100:
#cv2.imwrite(r"E:/face_dormitory/unidentified/"+str(num)+".jpg",frame) #抓拍
cv2.imwrite(r"E:/face_dormitory/unidentified/"+"0.jpg",frame) #抓拍
time.sleep(0.1)
sendmail(HOST=HOST, SUBJECT=SUBJECT,FROM=FROM,TO=TO,message=message)
print('ddddddddddd')
#num += 1
warningtime = 0
cv2.putText(img, 'unidentified', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv2.imshow('result',img)#取名函式,切片取名,即照片名為1.cj.jpg,取名后就為cj
def name():
#相冊路徑
path = 'E:/face_dormitory/train'
#回圈讀圖
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
#切名字
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)6)主函式
?
#防照片識別
pervent_to_photo()
#打開攝像頭,0是本地默認,1是外用,我把本地關了把外用開著所以直接0
cap=cv2.VideoCapture(0)
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
#空格退出
if ord(' ') == cv2.waitKey(10):
break
cv2.destroyAllWindows()
cap.release()
?5.參考文章
感謝大佬1
感謝大佬2
感謝大佬3
6.可能遇到的問題
1.如果你搭建了虛擬環境且里面安裝了opencv,但是再參考的時候報錯沒裝庫,看看有沒有將虛擬環境匯入kernel
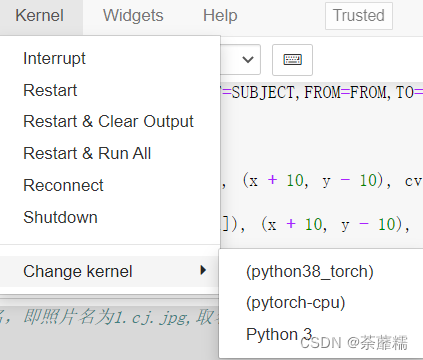
2.如果你發現我的邏輯有問題,相信你自己,錯的肯定是我,請務必懟我,畢竟有探討才有完善,我也是個小菜雞
3.如果出現”No module named XXX“,說明安裝差庫了,請跑到虛擬環境里去安裝,虛擬環境是獨立的,你之前安裝了什么都跟虛擬環境無關
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386587.html
標籤:其他