我們在《Word Embedding(三):Skip-Gram模型》中簡單介紹了Skip-Gram的原理及架構,至于Skip-Gram如何把輸入轉換為詞嵌入、其間有哪些關鍵點、面對大語料庫可能出現哪些瓶頸等,并沒有展開說明,而了解Skip-Gram的具體實作程序,有助于更好地了解word2vec以及其他預訓練模型,如BLMo、BERT、ALBERT等,所以,本文將詳細介紹Skip-Gram的實作程序,加深讀者對其原理與實作的理解,對于CBOW模型,其實作機制與Skip-Gram模型類似,后續文章將不再贅述,
預處理語料庫
text = "natural language processing and machine learning is fun
and exciting"
corpus = [[word.lower() for word in text.split()]]
這個語料庫就是一句話,共10個單詞,其中and出現兩次,共有9個不同單詞,因單詞較少,這里暫不設定停用詞,而是根據空格對語料庫進行分詞,分詞結果如下:
["natural", "language", "processing", "and", "machine","learning", "is", "fun","and", "exciting"]
Skip-Gram模型架構圖
使用Skip-Gram模型,設定window-size=2,以目標詞確定其背景關系,即根據目標詞預測其左邊2個和右邊2個單詞,具體模型如下圖所示:
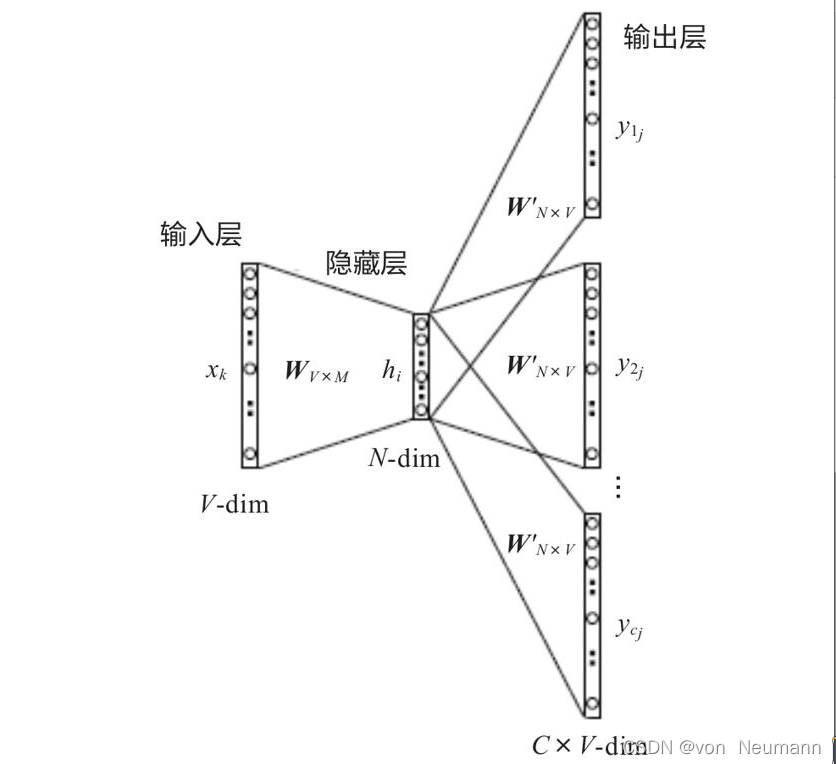
在上圖中,這里語料庫只有9個單詞V-dim=9,詞嵌入維度為10N-dim=10,C=4(該值為2*window-size),
如果用矩陣來表示上圖,可寫成如下圖所示的形式:
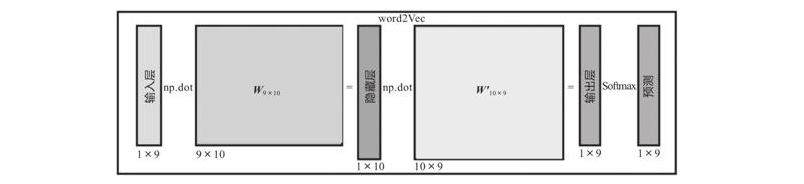
實際嵌入程序中,涉及的單詞量較大,本文為便于說明,僅使用一句話作為語料,在一些文章中,又將矩陣
W
V
×
N
W_{V\times N}
WV×N?稱為查找表(Lookup Table),
生成中心詞及其背景關系的資料集
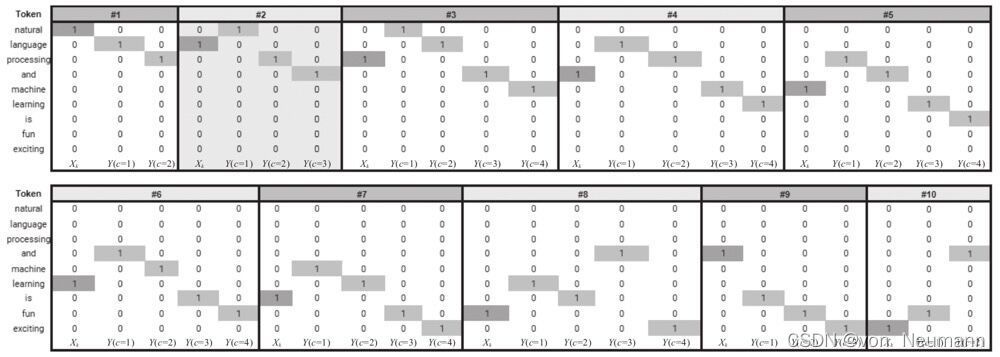
根據語料庫及window-size,生成中心詞與預測背景關系的資料集,如下圖所示:

圖中共有10對資料, X k X_k Xk?對應的詞為中心詞,其左邊或右邊的詞為背景關系,
生成訓練資料
為便于訓練word2vec模型,首先需要把各單詞數值化,這里把每個單詞轉換為獨熱編碼,在前面提到的語料庫中,上圖顯示了10對資料,每個視窗都由中心詞及其背景關系單詞組成,把上圖中的每個詞轉換為獨熱編碼后,可以得到如下圖所示的訓練資料集:
Skip-Gram模型的正向傳播
上述步驟完成了對資料的預處理,接下來開始資料的正向傳播,包括輸入層到隱藏層、隱藏層到輸出層,
從輸入層到隱藏層,用圖來表示就是輸入向量與權重矩陣
W
1
W_1
W1?的內積,如下圖所示:
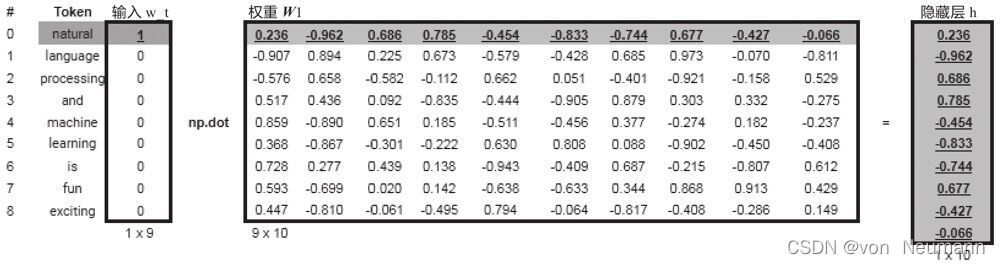
我們一般將矩陣 W 9 × 10 W_{9\times 10} W9×10?先隨機初始化為-1到1之間的數,
從隱藏層到輸出層,其實就是求隱含向量與權重矩陣
W
2
W_2
W2?的內積,然后使用Softmax激活函式、得到預測值,如下圖所示:
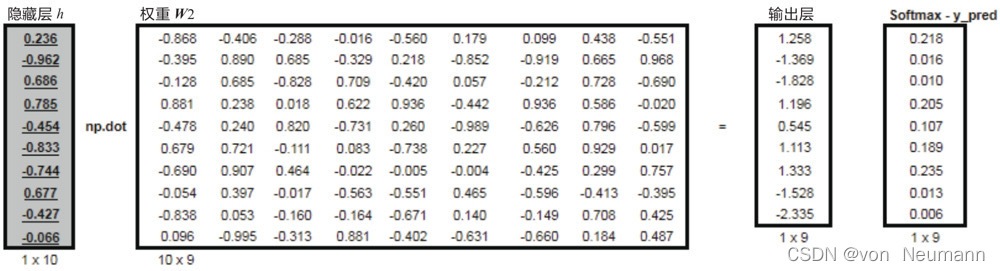
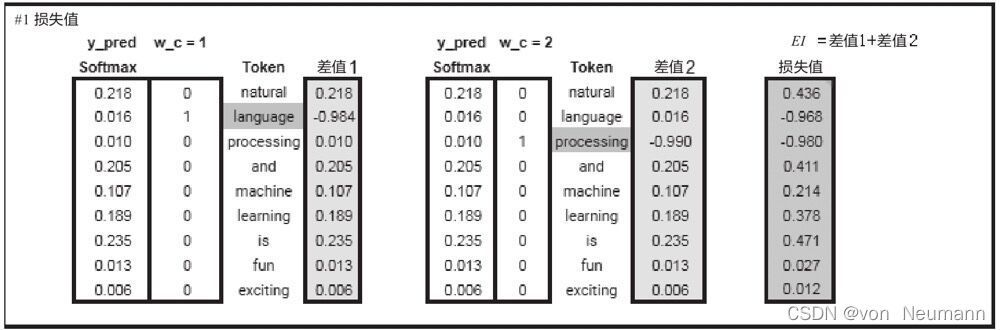
損失值是預測值與實際值的差,這里以選擇資料集#1為例,即中心詞為natural,然后計算對應該中心詞的輸出,即預測值,再計算預測值與實際值的差,得到損失值
E
l
El
El,中心詞natural的背景關系(這里只有下文)為language和processing,它們對應的獨熱編碼為w_c=1,w_c=2,具體計算程序如下圖所示,
Skip-Gram模型的目標函式
我們使用反向傳播函式,根據目標詞計算的損失值
E
I
EI
EI,反向更新
W
1
W_1
W1?和
W
2
W_2
W2?,假設輸出值為
u
u
u,即
h
W
=
u
hW=u
hW=u,則預測值為:
y
j
=
Softmax
(
u
j
)
=
e
u
j
∑
k
=
1
V
e
u
k
y_j=\text{Softmax}(u_j)=\frac{e^{u_j}}{\sum_{k=1}^Ve^{u_k}}
yj?=Softmax(uj?)=∑k=1V?euk?euj??
對于長度為
N
N
N的訓練文本且詞庫詞數為
V
V
V,在window-size指定為
w
w
w后,第
i
i
i個字符的前后window-size個字符組成第
i
i
i個字符的背景關系文本
context
(
i
)
\text{context}(i)
context(i),則目標函式為:
E
=
arg?max
?
W
,
W
′
∏
i
=
1
N
∏
j
=
i
?
w
i
+
w
P
(
y
j
∣
y
i
)
=
arg?max
?
W
,
W
′
log
?
∏
i
=
1
N
∏
j
=
i
?
w
i
+
w
P
(
y
j
∣
y
i
)
=
arg?max
?
W
,
W
′
∑
i
=
1
N
∑
j
=
i
?
w
i
+
w
log
?
P
(
y
j
∣
y
i
)
=
arg?max
?
W
,
W
′
∑
i
=
1
N
∑
j
=
i
?
w
i
+
w
log
?
e
u
i
∑
k
=
1
V
e
u
i
=
arg?max
?
W
,
W
′
∑
i
=
1
N
∑
j
=
i
?
w
i
+
w
(
e
u
i
?
log
?
∑
k
=
1
V
e
u
i
)
\begin{aligned} E&=\argmax_{W, W'}\prod_{i=1}^N\prod_{j=i-w}^{i+w}P(y_j|y_i)\\ &=\argmax_{W, W'}\log\prod_{i=1}^N\prod_{j=i-w}^{i+w}P(y_j|y_i)\\ &=\argmax_{W, W'}\sum_{i=1}^N\sum_{j=i-w}^{i+w}\log P(y_j|y_i)\\ &=\argmax_{W, W'}\sum_{i=1}^N\sum_{j=i-w}^{i+w}\log \frac{e^{u_i}}{\sum_{k=1}^Ve^{u_i}}\\ &=\argmax_{W, W'}\sum_{i=1}^N\sum_{j=i-w}^{i+w}(e^{u_i}-\log \sum_{k=1}^Ve^{u_i}) \end{aligned}
E?=W,W′argmax?i=1∏N?j=i?w∏i+w?P(yj?∣yi?)=W,W′argmax?logi=1∏N?j=i?w∏i+w?P(yj?∣yi?)=W,W′argmax?i=1∑N?j=i?w∑i+w?logP(yj?∣yi?)=W,W′argmax?i=1∑N?j=i?w∑i+w?log∑k=1V?eui?eui??=W,W′argmax?i=1∑N?j=i?w∑i+w?(eui??logk=1∑V?eui?)?
目標函式表示最大化已知中心詞 y i y_i yi?時背景關系單詞 y j y_j yj?的概率,伺候再通過深度學習中的反向傳播演算法優惠目標函式即可實作Skip-Gram模型,得到各個單詞的詞向量,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/386779.html
標籤:AI
上一篇:從零實作深度學習框架【收藏】
下一篇:什么是深度學習?kears簡介,深度學習常用的三大模型,MLP(多層感知機),CNN(卷積神經網路),RNN(回圈神經網路)