?作者 |小欣
今天和大家分享一篇關于“Vision Transformer的自監督學習”的文章,文章來源是BEiT(BERT Pre-Training of Image Transformers),文章的出品方是微軟,感興趣的小伙伴可以自行去下載閱讀哦!好的,接下來,我們就簡單地“解剖”一下這篇文章吧!
Transformer 在計算機視覺領域已經獲得巨大的成功,然而,大量的實驗研究表明,訓練Vision Transformer 需要比訓練卷積神經網路(CNN)更多的資料,
為了解決這個問題,自監督預訓練這種方式,即可以利用大規模的無標注資料,近期研究,比如對比學習或者自蒸餾,都揭示了在vision Transformer上進行預訓練的可行性,
這篇文章引入了一種自監督的視覺表示模型 BEIT,它代表Vision Transformer的雙向編碼表示,這是繼在自然語言處理領域開發的 BERT (Devlin等人在2019年提出) 之后,通過影像掩碼建模任務來預訓練視覺轉換器的模型,

文章的主要貢獻
● 提出了一個影像掩碼建模任務,以自我監督的方式預訓練視覺轉換器,還從變分自編碼器的角度提供了理論解釋,
● 預訓練 BEIT 模型,并對下游任務進行廣泛的微調實驗,例如影像分類和語意分割,
● 展示自監督 BEIT 的自注意力機制可以區分語意區域和物體邊界,并且不需要使用任何人工注釋,

文章的研究方法(Methods)
文章借鑒了自然語言處理中BERT的訓練方法,首次提出了影像掩碼建模對vision transformer進行預訓練的方法,首先將原始影像“標記”為視覺標記,
然后隨機掩蓋一些影像塊并將它們輸入到主干Transformer 中,預訓練的目標是恢復原始基于損壞的影像補丁的視覺標記,
文章中提出的BEIT如下圖所示,給定輸入影像 ,BEIT 將其編碼為背景關系向量表示,BEIT 通過遮掩影像建模(MIM)任務以自監督學習的方式進行預訓練,
MIM 旨在基于編碼向量恢復被屏蔽的影像塊,對于下游任務(例如影像分類和語意分割),則在預訓練的 BEIT 上附加任務層并微調特定資料集上的引數,
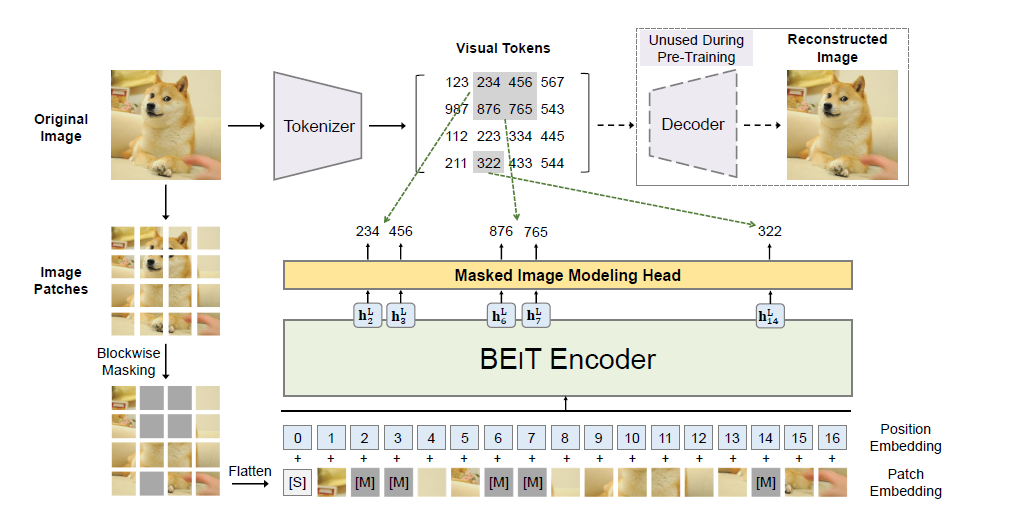
對于一個二維的影像,先將其分割成個patch,然后將每個patch經過線性映射,得到patch的向量表示,接下來,需要對每個patch的向量表示進行標記,
先將patch的向量表示為一個tokenizer(也可以認為是一個encoder),從而得到影像標記(visual token),然后把visual token 送到相應的解碼器中(decoder),得到一個生成的影像,用重構損失來學習tokenizer和decoder的引數,
擁有了經過學習而得到的visual token之后,可以進一步來預訓練Vision Transformer,該預訓練方法依賴于此前提出的MIM,
對于輸入圖中的影像內容,先分割成個patch,然后隨機掩蓋40%的patch,這些掩蓋的patch進一步設定成可學習的向量,接著,將所有patch再一起送到Vision Transformer,由此可見,該預訓練是去預測被掩蓋的patch的標記(token),
預訓練的目標為:
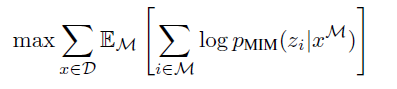
為被掩蓋的patch,為預測被掩蓋patch的標記,
下圖描述了輸入影像被掩蓋的演算法:

具體來說,每個影像在預訓練中有兩個視圖,即影像塊(例如 16×16 像素)和視覺標記(即離散標記),首先將原始影像“標記”為視覺標記,然后隨機屏蔽一些影像塊并將它們輸入到主干 Transformer 中,
預訓練的目標是恢復原始基于損壞的影像補丁的視覺標記,在預訓練 BEIT 之后,可以通過在預訓練的編碼器上,附加任務層來直接微調下游任務的模型引數,

文章的研究結果(Result)
文章將BEiT預訓練得到的模型應用在“影像分類”和“語意分割”等下游視覺任務進行測評,與現有的預訓練模型對比,得到了具有競爭力的結果,
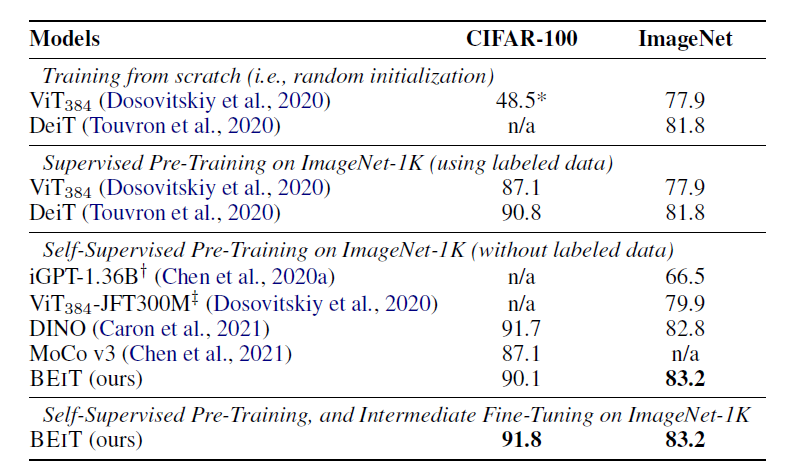
例如,基本大小的 BEIT 在 ImageNet-1K 上實作了 83:2% 的 top-1 準確率,明顯優于使用相同設定的從頭開始的 DeiT 訓練 (81:8%; Touvron et al., 2020),此外,大尺寸 BEIT 僅使用 ImageNet-1K 獲得 86:3%,甚至在 ImageNet-22K 上進行監督預訓練時的性能甚至優于 ViT-L(85:2%;Dosovitskiy 等人,2020),
下面的表格比較了文章提出的BEiT和現有的預訓練模型在“影像分類”上的精度,我們能夠發現文章提出的模型,可以達到最高的精度,
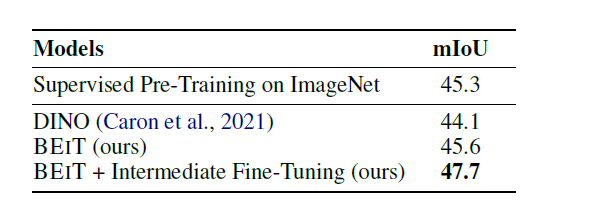
與此同時,繼續比較“影像語意”在分割上的精度,可以發現文章提出的BEiT,同樣比現有模型的精度要高,
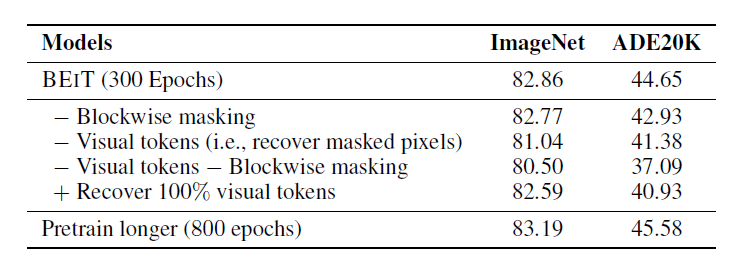
文章進一步研究各種模型變體的結果,也有了新的發現,
首先,通過隨機采樣掩蓋位置來消融塊狀掩碼,能發現分塊掩蓋對這兩個任務都有好處,尤其是在“語意分割”方面,
其次,可以通過預測掩蓋patch的原始像素來消除視覺標記的使用,即預訓練任務成為恢復掩蓋patch的像素回歸問題,文章中提出的掩碼影像建模任務明顯優于一般的像素級自動編碼,
第三,將視覺標記和塊狀掩碼的使用結合在一起,可以發現塊狀掩碼對像素級自動編碼更有幫助,減輕了短距離依賴的缺陷,
第四,將 BEIT 與不同的訓練步驟進行比較,進一步發現對模型進行更長時間的預訓練可以提高下游任務的性能,

文章的研究結論(Conlcusion)
這篇文章描述了一種用于vision Transformer的自監督預訓練框架,在下游任務(例如影像分類和語意分割)上實作了強大的微調結果,
文章中提出的方法,能夠幫助大多數 BERT 的預訓練(即使用掩碼輸入進行自動編碼)進一步開展影像轉換器作業,
文章還展示了一些有趣的特性,如自動獲取有關語意區域的知識,而無需使用任何人工注釋的資料,
代碼和預訓練模型可從https://aka.ms/beit獲得,
私信我領取目標檢測與R-CNN/資料分析的應用/電商資料分析/資料分析在醫療領域的應用/NLP學員專案展示/中文NLP的介紹與實際應用/NLP系列直播課/NLP前沿模型訓練營等干貨學習資源,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387131.html
標籤:其他