我的目標是具有兩個能夠再現二次函式的神經元的順序神經網路。要做到這一點,我選擇了第一個神經元被激活功能lambda x: x**2,第二個神經元是None。
每個神經元輸出A(ax b)其中A是激活函式,a是給定神經元的權重,b是偏置項。第一個神經元的輸出傳遞給第二個神經元,該神經元的輸出就是結果。
我的網路輸出的形式是:
訓練模型意味著調整每個神經元的權重和偏差。選擇一組非常簡單的引數,即:
將我們引向一個拋物線,它應該可以通過上面描述的 2 神經元神經網路完全學習:
為了實作神經網路,我這樣做:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
定義要學習的函式:
f = lambda x: x**2 2*x 2
使用上述函式生成訓練輸入和輸出:
np.random.seed(42)
questions = np.random.rand(999)
solutions = f(questions)
定義神經網路架構:
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1],activation=lambda x: x**2),
tf.keras.layers.Dense(units=1, input_shape=[1],activation=None)
])
編譯網:
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.1))
訓練模型:
history = model.fit(questions, solutions, epochs=999, batch_size = 1, verbose=1)
生成f(x)使用新訓練模型的預測:
np.random.seed(43)
test_questions = np.random.rand(100)
test_solutions = f(test_questions)
test_answers = model.predict(test_questions)
可視化結果:
plt.figure(figsize=(10,6))
plt.scatter(test_questions, test_solutions, c='r', label='solutions')
plt.scatter(test_questions, test_answers, c='b', label='answers')
plt.legend()
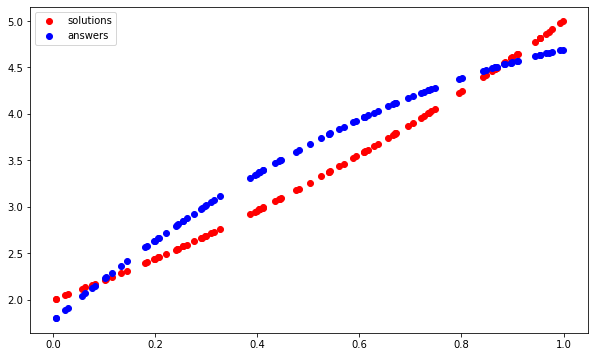
紅點形成我們的模型應該學習的拋物線曲線,藍點形成它已經學習的曲線。這種方法顯然行不通。
上面的方法有什么問題,如何讓神經網路真正學習拋物線?
uj5u.com熱心網友回復:
使用建議的架構進行修復
降低學習率來達到目的0.001,編譯如下:
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.001))
可視化新結果:
plt.figure(figsize=(10,6))
plt.scatter(test_questions, test_solutions, c='r',marker=' ', s=500, label='solutions')
plt.scatter(test_questions, test_answers, c='b', marker='o', label='answers')
plt.legend()
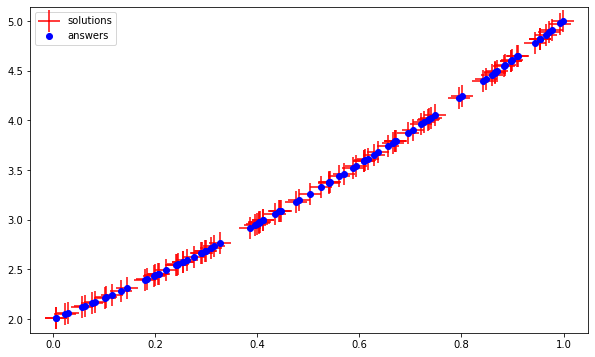
很合身。要檢查實際權重以了解究竟學到了什么拋物線,我們可以這樣做:
[np.array(layer.weights) for layer in model.layers]
輸出:
[array([-1.3284513, -1.328055 ], dtype=float32),
array([0.5667597, 1.0003909], dtype=float32)]
預期1, 1, 1, 1,但將這些值代入方程
項系數x^2:
0.5667597*(-1.3284513)**2 # result: 1.0002078022990382
項系數x:
2*0.5667597*-1.3284513*-1.328055 # result: 1.9998188460235597
常數項:
0.5667597*(-1.328055)**2 1.0003909 # result: 2.000002032736224
即學習到的拋物線是:
1.0002078022990382 * x**2 1.9998188460235597 * x 2.000002032736224
這非常接近f,即x**2 2*x 2。
令人欣慰的是,學習到的拋物線和真實拋物線的系數之間的差異小于學習率。
請注意,我們可以使用更簡單的架構
IE:
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1],activation=lambda x: x**2),
])
即我們有一個輸出為 (a*x b)**2 的神經元,并且通過訓練a和b調整 -> 我們也可以像這樣描述任何拋物線。(實際上也嘗試過這個,它奏效了。)
uj5u.com熱心網友回復:
添加到@Zabob 的答案中。您使用了對初始學習率敏感的 Adam 優化器,雖然它被認為非常健壯,但我發現它對初始學習率敏感 - 并且可能導致意外結果(就像在您學習的情況下一樣)反曲線)。如果將優化器更改為 SGD:
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.SGD(0.01))
然后在不到 100 個 epoch 中,您可以獲得一個優化的網路:
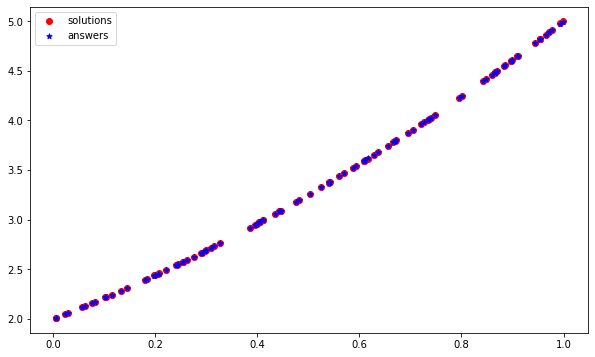
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387547.html
上一篇:Python上的導數