一. 面試題及剖析
1. 今日面試題
請說一下HashMap及其底層實作原理
HashMap默認的初始容量是多大?
HashMap的容量為什么必須是2的N次方?如何保證這一點?
HashMap是怎么添加資料的?
HashMap中put()方法的實作程序是什么樣的?
你有沒有看過HashMap的put()方法原始碼?
......
2. 題目剖析
在前2篇文章中,壹哥 給大家介紹了HashMap的基本特點,介紹了HashMap的底層資料結構,并且 壹哥 給大家重點講解了HashMap中的重要屬性,分析了HashMap的默認初始容量、負載因子等重要屬性,但HashMap中還有很多其他的核心方法,那么在這篇文章中,壹哥 會重點帶大家來閱讀HashMap中的一些核心方法的原始碼,
前2篇文章地址如下:
高薪程式員&面試題精講系列39之說說HashMap的特點及其底層資料結構
高薪程式員&面試題精講系列40之HashMap默認初始容量、最大容量、負載因子是多少?鏈表轉紅黑樹閾值是多少?HashMap什么時候進行擴容?
二. HashMap的初始化方法
HashMap中的方法有很多,我們從哪里開始看呢?在使用HashMap時,我們一般都要先創建一個物件出來,所以構造方法無疑就是我們閱讀核心方法的入口點,
1. HashMap的構造方法
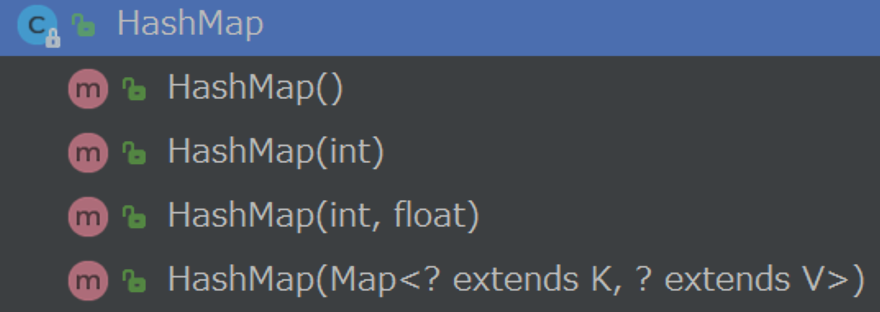
HashMap提供了4個構造方法來進行物件的初始化,
- HashMap(): 創建一個默認初始容量為16 和 默認負載因子為0.75 的空HashMap;
- HashMap(int initialCapacity): 創建一個 帶有指定初始容量和默認負載因子為0.75 的空HashMap;
- HashMap(int initialCapacity, float loadFactor): 創建一個 帶有指定初始容量和負載因子的 空HashMap;
- HashMap(Map<? extends K, ? extends V> m):根據某個已有的Map創建一個HashMap物件,
這4個構造方法如下圖所示:
構造方法的作用,一般就是進行物件創建,還有就是進行必要的初始化操作,在HashMap中,除了可以在構造方法中進行初始化之外,還會在put()方法中對HashMap進行一定的初始化操作,當我們呼叫put(k,v)方法添加添加時,其內部會先檢查 table陣列 是否為空,如果為空就先進行初始化,對table陣列進行擴容,
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;首次初始化分為無參初始化和有參初始化兩種情況,無參時默認容量是16,也就是table陣列的初始長度為16,有參初始化的時候,會使用tableSizeFor()方法來確保實際的容量是2的N次方,最后在resize()方法中new一個Node陣列出來,
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
......
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
......
return newTab;
}其中 newCap就是容量,默認是16或者是自定義的值,至于HashMap的擴容機制,我在后面再給大家細說,
2. HashMap的初始容量設定
本節相關面試題:
為什么HashMap的容量必須是2的整數倍?
怎么保證這一點?
前面我們已經知道,在構建HashMap物件時應該設定一個初始容量,并且該初始容量的大小必須是 2的n次方,否則默認會采用 16 作為初始容量,但真正開發的時候,我們又很難保證每個開發人員都會按要求來設定初始容量,總有些不守規則的呆逼用7、15、39等數字來做初始容量,那假如就有人采用了這樣的數值作為初始容量會發生什么呢?
其實對這個問題,我們大可不必擔心,默認情況下,當我們設定HashMap的初始容量時,如果該值不是2的n次方,HashMap會把 第一個大于等于該數值的2的n次方 來作為初始容量,
比如某個呆逼就把初始容量設定成3,你以為這個呆逼不成熟的想法就會實作嗎?不會的!!!HashMap的作者早就預料到會有這種菜鳥存在了!這個3根本就不會成為初始容量的!
真正的初始容量會被HashMap自動設定為4(以此類推,1->1、3->4、7->8、9->16...),也就是說HashMap并不一定會直接采用我們傳入的數值來作為初始容量,而是會經過計算,得到一個新值,這個新值必須是2的整數倍!這樣做可以提高hash的效率,后面到hash()方法時我再細說,
另外在JDK 1.7和JDK 1.8中,HashMap設定這個初始容量的時機是不同的,JDK 1.8中,當我們呼叫HashMap建構式時,就會進行初始容量的設定;而在JDK 1.7中,要等到第一次put操作時才會進行這一設定,
這時有些小伙伴可能很好奇,到底是在哪里進行的自動轉換,可以把初始容量自動變成2的整數倍?這個功能是由HashMap中的tableSizeFor()方法來實作的,我們繼續往下看,
3. tableSizeFor初始化容量轉換
本節相關面試題:
為什么HashMap中的容量必須為2的整數冪?
上面 壹哥 給大家說過,即使我們在進行HashMap初始化時,設定的初始容量不是2的整數倍,我們也不用擔心,因為HashMap內部會自動把這個初始容量設定為2的整數倍,這個功能是由tableSizeFor(initialCapacity)方法來實作的,其原始碼如下:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}這是一個非常巧妙,也非常有意思的演算法,比如你給定的初始大小是63,經過該方法計算后,最后得到的結果是64;如果給定的初始大小是65,那得到的最后結果是128;如果給定的初始大小是64,最后得到的結果還是64,總是能得到一個不小于給定初始大小,并且是2的n次方的結果!
那么tableSizeFor()這個方法具體是怎么進行計算的呢?結合著原始碼,壹哥 給大家細講一下,
該方法首先會 把初始引數減 1,然后 連續地執行 或等于 和 無符號右移 操作,最后計算出一個 2的N次方的結果,下圖演示了初始引數為 18 時的一系列計算程序,最后得出的初始大小為 32,
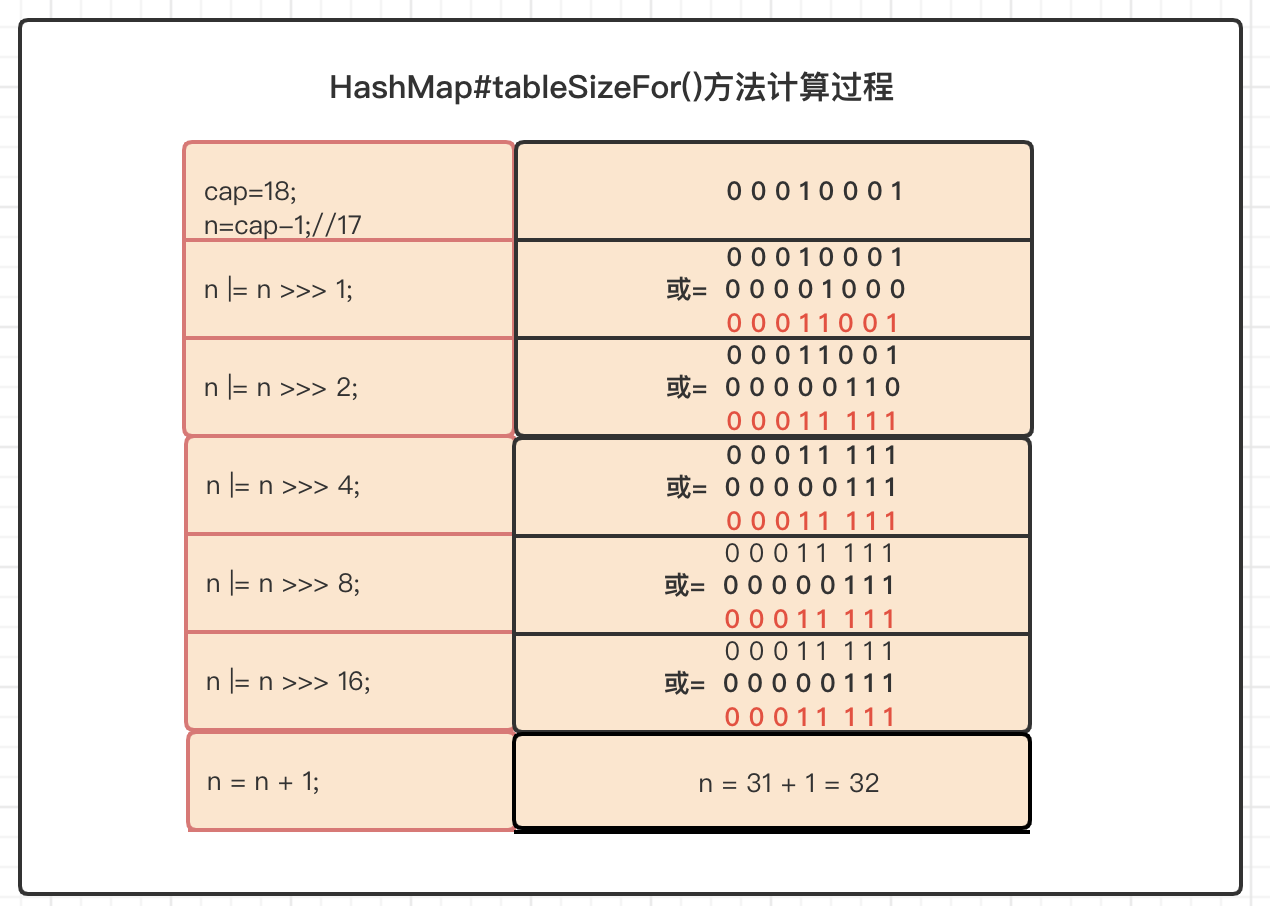
tableSizeFor()方法具體的執行程序是:
先把18減去1得到17;
將17轉為對應的8位二進制,把該資料進行無符號右移1位,再把17和位移后的資料執行 或運算,然后把或運算的結果再賦值給n變數;
然后依次重復上面的步驟執行下去......
經過該方法的計算,不管我們給定的初始值是不是2的整數倍,最后一定會得到一個大于或等于給定值的2的整數倍!
三. HashMap的put()方法【重點】
接下來我們進入到HashMap的put()方法中來,了解一下HashMap是如何添加資料的,以及HashMap的存盤機制到底是怎么回事,
本節相關面試題:
HashMap中put()方法的實作機制是什么樣的?
1. HashMap插入資料步驟
首先我們來了解一下HashMap#put()方法插入資料的具體步驟,這里我借用網上的一張圖,給大家展示put()方法是如何插入一個資料節點的,

根據上圖,我們可以總結出向HashMap中插入資料的具體步驟,其實可以簡單總結為如下幾步:
- 根據待插入資料的key,計算出其對應的hash值,并根據該hash值確定元素的插入位置(即在動態陣列中的位置);
- 將元素放入到陣列的指定位置,如果該位置上之前沒有元素,則直接放入;
- 放入該位置后,如果陣列元素超過了擴容閾值,則對陣列進行擴容;
- 放入該位置后,如果陣列元素沒超過擴容閾值,則寫入結束;
- 如果該位置上之前已有元素,則直接覆寫掉舊元素;
- 如果元素之前組成了紅黑樹,則掛入到樹的指定位置;
- 如果之前元素組成了鏈表,則先進行判斷,看看鏈表長度是否超過了樹化的閾值;
- 如果加入該元素后,鏈表長度超過8,則將鏈表轉化為紅黑樹后插入;
- 如果加入該元素后,鏈表長度不超過8,則直接插入,
2. put(key,value)方法原始碼
上面簡單梳理了插入元素的步驟,但為了弄清楚HashMap的存盤機制及原理,我們還是要來看看put(k,v)方法的原始碼,如下:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}猛看一眼,這個put()方法很簡單哎,里面一句話就完事了!但事實真的如此嗎?作為HashMap中非常重要的方法,怎么可能就這么簡單呢?所以我們需要繼續往下追蹤,看看putVal()方法,這才是HashMap存值的關鍵所在!
3. putVal()方法原始碼
接下來我們看看實作存值的關鍵所在吧,putVal()方法原始碼如下所示:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果table陣列沒有初始化,或者初始化的大小為0,則對table進行resize擴容操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果陣列的當前位置上沒有存盤資料節點,則直接生成一個資料節點并放入到陣列的當前位置上
//注意:陣列的索引位置i,是由陣列長度n-1,和key的hash值進行&與運算得到
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//如果當前位置上已經有了資料節點,則先解決沖突,再放入到該位置上,
//沖突的解決有3種情況:①.直接覆寫;②.使用鏈表;③.使用紅黑樹,
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//判斷要添加的元素和已經存在的元素是否相同(hash一致,并且equals回傳true)
//如果相同,則進行元素替換,新元素直接覆寫舊元素
e = p;
else if (p instanceof TreeNode)
//如果要添加的元素和已經存在的元素不相同(hash一致,并且equals回傳true)
//且桶內元素的型別是TreeNode,也就是解決hash沖突用的是樹型結構,則把元素放入到樹中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果桶內元素的型別不是TreeNode,而是鏈表型別,則把元素放入到鏈表的最后一個元素上
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果鏈表的長度大于等于轉換為樹的閾值8(TREEIFY_THRESHOLD),則將存盤元素的資料結構變更為樹,進行樹化操作
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果是已存在的key,則直接跳出
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//已經存在元素時
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//記錄每次add/remove等操作次數
++modCount;
// 如果K-V數量大于閾值,進行resize操作
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}這個putVal()方法的原始碼明顯就復雜了很多,好在 壹哥 對該方法中的核心代碼,都給大家做了詳細注釋,對于該方法的代碼功能,請仔細閱讀代碼中的注釋,
4. HashMap的put()方法執行流程
雖然上面的putVal()方法原始碼中,壹哥 對核心代碼都做了中文注釋,但可能還是有些難以理解,所以我們再結合下圖,來重點分析put()方法的內部實作,
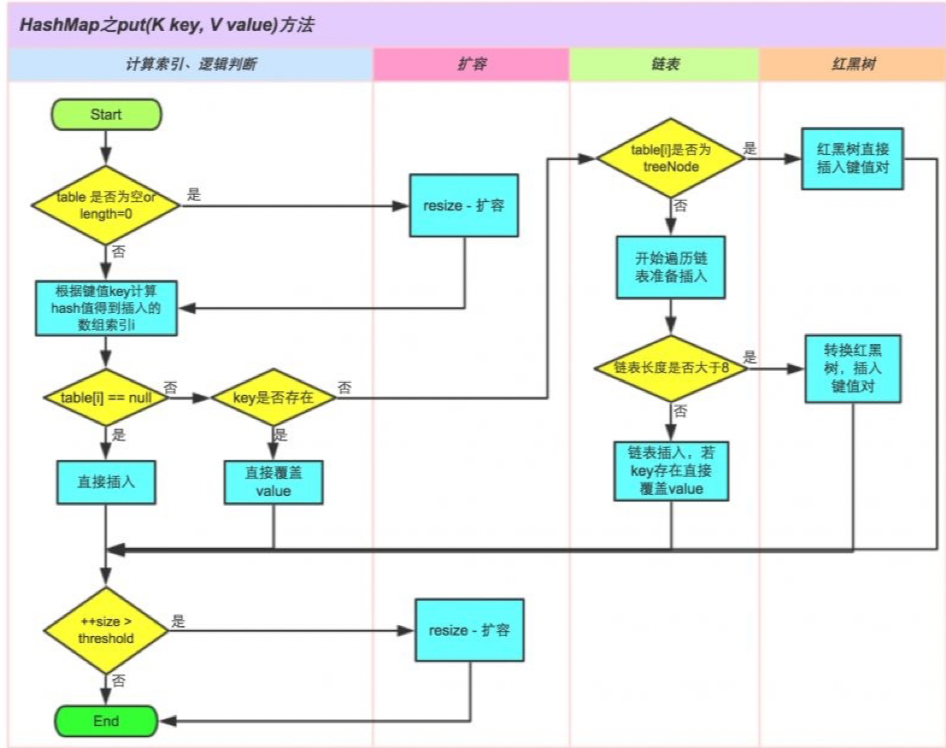
我結合上面的原始碼和圖片,最終給大家總結出put()方法的代碼執行流程如下:
- ①. 判斷鍵值對陣列table[i]是否為慷訓leng=0,如果是,則執行resize()擴容;
- ②. 根據鍵key計算出hash值,然后得到插入的陣列索引i,如果table[i]==null,則直接新建一個節點進行插入,并轉向⑥;如果table[i]不為空,則轉向③;
- ③. 判斷table[i]中首個元素的key是否和當前key一樣,如果相同直接覆寫value,否則轉向④,這里的相同依據的是hashCode以及equals();
- ④. 判斷table[i]是否為TreeNode型別,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對,否則轉向⑤;
- ⑤. 遍歷table[i],判斷鏈表長度是否大于8,大于8的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操作,否則進行鏈表的插入操作;如果在遍歷程序中發現key已經存在,則直接覆寫value即可;
- ⑥. 插入成功后,判斷實際存在的鍵值對數量size是否超過了最大容量threshold,如果超過,則進行擴容,
以上這些內容就是HashMap的存盤機制及其實作原理,掌握這些內容就可以回答出如下面試題:
HashMap中put()方法的實作程序是什么樣的?
五. 結語
至此,壹哥 就把今天的內容給大家講解完畢,我們要重點掌握HashMap對容量的設定、put()方法的執行流程,這也是面試時的重點,接下來,壹哥 會繼續分析HashMap的底層原理,比如HashMap中的擴容機制、索引定位、沖突解決、鏈表與紅黑樹的轉換、get()取值流程等,請各位繼續關注 壹哥 吧,送給你的肯定都是滿滿的干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387808.html
標籤:其他
上一篇:圣誕節,程式員應該怎么浪漫?