前提:
以下的一些資料結構大家需提前知道,否則看起來會比較有困難,大家也可以按照本文所提到的知識點去主動查閱學習,
1.Hash表?No
因考慮到在資料檢索的程序中經常會有范圍的查詢(如下),而hash表不能提供這種功能,
SELECT * FROM hero WHERE age>5 AND age<20;
使用哈希演算法實作的索引雖然可以做到快速檢索資料,但是沒辦法做資料高效范圍查找,因此哈希索引是不適合作為 Mysql 的底層索引的資料結構,
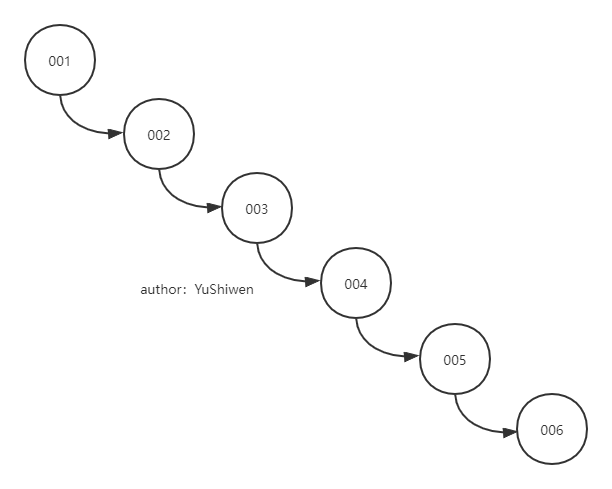
2.二叉查找樹(BST)?No
二叉查找樹(Binary Search Tree)雖然可以達到范圍搜索,但是在樹的插入程序中,如果插入的資料本來就是有順序的,那么就會形成一條鏈(如下),它的最壞情況是O(n),
3.紅黑樹?No
紅黑樹雖然看似達到了平衡狀態,但是也會有極端情況存在,和上述BST樹一樣,雖然不會成為鏈狀,但是紅黑樹會存在右傾的現象,
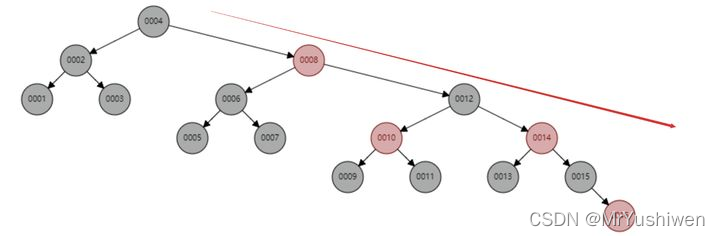
圖片來自網路
在資料庫中的基本主鍵自增操作,主鍵一般都是數百萬數千萬的,如果紅黑樹存在這種問題,對于查找性能而言也是巨大的消耗,我們資料庫不可能忍受這種無意義的等待的,
4.平衡二叉樹(AVL)?差那么二點意思
平衡二叉樹,英文翻譯為Balanced Binary Tree,為啥叫AVL呢?
AVL 是大學教授 G.M. Adelson-Velsky 和 E.M. Landis 名稱的縮寫,他們提出的平衡二叉樹的概念,為了紀念他們,將平衡二叉樹稱為 AVL樹,
AVL樹本質上是一顆二叉查找樹,但是它又具有以下特點:
- 它是一棵空樹或它的左右兩個子樹的高度差的絕對值不超過1,
- 左右兩個子樹也都是一棵平衡二叉樹,
它不存在紅黑樹這種右傾的現象,也具備資料高效范圍查找的能力,但是資料庫查詢資料的瓶頸在于磁盤的IO,樹節點在磁盤空間中存盤可能是不連續的,假設我們一次IO讀取一個樹的節點,此次讀入記憶體的這頁中沒有其他樹的節點,那么每讀取一個樹的節點,就要進行一次IO,這是多么消耗時間啊,所以我們設計資料庫索引時需要首先考慮怎么盡可能減少磁盤 IO 的次數,
磁盤讀取依靠的是機械運動,分為尋道時間、旋轉延遲、傳輸時間三個部分,這三個部分耗時相加就是一次磁盤IO的時間;這個花費的時間成本是記憶體訪問的十幾萬倍左右,
正是由于磁盤IO是非常昂貴的操作,所以計算機作業系統對此做了優化:預讀;每一次IO時,不僅僅把當前磁盤地址的資料加載到記憶體,同時也把相鄰資料也加載到記憶體緩沖區中,因為區域預讀原理說明:當訪問一個地址資料的時候,與其相鄰的資料很快也會被訪問到,每次磁盤IO讀取的資料我們稱之為一頁(page),一頁的大小與作業系統有關,一般為4k或者8k,這也就意味著讀取一頁內資料的時候,實際上發生了一次磁盤IO,
相關術語解釋:
- 扇區(sector):
- 磁盤上的每個磁道被等分成多個弧段,這個弧段便稱作扇區(sector),
扇區是磁盤物理層面的名稱,它是實際發生讀寫的最底層,
- 磁盤塊(IO Block):
- 作業系統不與扇區直接進行互動,因為一般情況下一個扇區是512byte,如果1T去用512byte進行劃分,那劃分的地址空間太多了,為了讓作業系統能夠尋址到更大的地址空間,作業系統將相鄰的扇區組合在一起,形成一個塊,對塊進行管理,每個磁盤塊可以包括 2、4、8、16、32 或 64 個扇區,這便是磁盤塊(IO Block),
磁盤塊是作業系統中出現的名稱,檔案系統讀寫資料的最小單位,它同時也被叫做磁盤簇,
- 頁(page):
頁是記憶體中出現的名稱,它是記憶體的最小存盤單位,頁的大小通常為磁盤塊大小的 2^n 倍,
4.B-tree(B-樹也稱B樹)?差那么一點意思
B樹是一種平衡的多叉樹,B樹相比于平衡二叉樹(AVL),它能夠在單個節點中存盤大量鍵,也降低了樹的高度,從而減少了IO的次數,
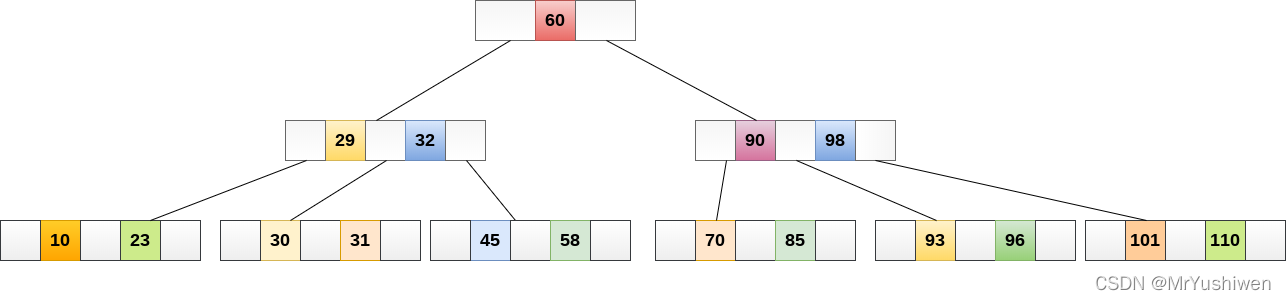
圖片來自網路
B樹的節點中存盤的是資料,單個節點存盤的內容還是太少了,如何讓一個節點存盤的內容更多呢?B+樹它來了,
5.B+樹
在節點中存盤某段資料的首地址,并且B+樹的葉子節點用了一個鏈表串聯起來,便于范圍查找,

B+樹高度降低,減少了磁盤 IO,其次,B+樹的葉子節點是真正資料存盤的地方,葉子節點用了鏈表連接起來,這個鏈表本身就是有序的,在資料范圍查找時,更具備效率,因此 Mysql 的索參考的就是 B+樹,B+樹在查找效率、范圍查找中都有著非常不錯的性能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/387905.html
標籤:其他