系列文章目錄
- 跑通代碼—CVPR2020–StegaStamp: Invisible Hyperlinks in Physical Photographs
- 跑通代碼—WACV2020-Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
- 跑通代碼-ICCV2021-HiNet: Deep Image Hiding by Invertible Network
文章目錄
- 系列文章目錄
- 前言
- 一、實驗的具體細節
- 1.1 SETR代碼的選擇
- 1.2 “剪裁”的細節
- 二、訓練結果
- 2.1 單層SETR邊緣檢測結果
- 2.2 多層SETR邊緣檢測結果
- 總結
前言
跑通代碼是第一步,接下來的作業是做個合格的 ”模型小裁縫“,將現有的優秀網路通過縫縫補補的操作應用到新的任務上,今天準備使用2021年CVPR論文(Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6881-6890.)中的Transformers模型,實驗中沒有對模型進行任何的修改,直接遷移到邊緣提取的任務上,原始論文使用的24層,本次實驗使用了1層和16層兩種引數,論文提供多種Decode的方式,實驗選擇的是Naive upsampling,下圖1中的b,將特征還原到原始影像的尺寸,SETR主要為多層ViT的堆疊,然后設計了幾種Decode的結構,很多blog多說論文的創新性不夠,我個人覺得,論文的題目就是Rethinking……說明是一篇探索性的論文,而不是精度提升的論文,宗旨是告訴我們ViT在實體分割、影像分類上能work,并且存在很大的優勢,至于提升到SOTA是后面的作業,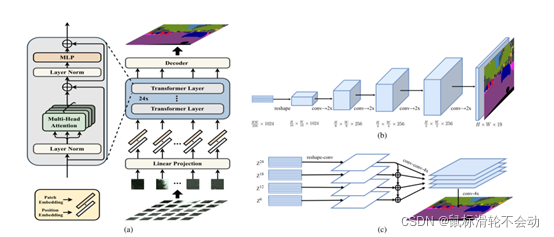
使用的訓練構架為2020年CVPR論文(Poma, X. S., Riba, E., & Sappa, A. (2020). Dense extreme inception network: Towards a robust cnn model for edge detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 1923-1932).)原始代碼的跑通結果可以參考博客跑通代碼—WACV2020-Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
一、實驗的具體細節
1.1 SETR代碼的選擇
由于SETR的官方代碼是基于 MMsegmentation實作的,很難快速上手,所以選擇了較為簡單的開源代碼實作專案920232796/SETR-pytorch
from SETR.transformer_seg import SETRModel
import torch
if __name__ == "__main__":
net = SETRModel(patch_size=(32, 32),
in_channels=3,
out_channels=1,
hidden_size=1024,
num_hidden_layers=8,
num_attention_heads=16,
decode_features=[512, 256, 128, 64])
t1 = torch.rand(1, 3, 256, 256)
print("input: " + str(t1.shape))
# print(net)
print("output: " + str(net(t1).shape))
給出的代碼能很好的實作輸入與輸出影像尺寸的不變,相當于整個SETR的塊代碼都寫好了,只需要設定相應的引數即可直接使用,將Dense Extreme Inception Network中的模型部分整個替換掉,換成上面的SETR模型,其他的引數可以保持不變,依然是Dense Extreme Inception Network的訓練設定,
1.2 “剪裁”的細節
首先需要注意的是,Dense Extreme Inception Network中的模型輸出具有多尺度融合的設定,所以對應的Loss位置,設定不同尺度損失函式的權重,由于SETR改之后,沒有多尺度的輸出,所以Loss權重地方需要修改為無權重,并且Loss加和取平均的地方也需要修改為單層輸出的Loss,對應main.py中修改的位置在第42行上下,
原始Loss代碼
loss = sum([criterion(preds, labels, l_w)/args.batch_size for preds, l_w in zip(preds_list,l_weight)])
修改之后的
loss = criterion(preds_list, labels, l_weight[0])/args.batch_size
接著是模型的部分,只需要將原始的模型替換成SETR的模型,其他的都不需要修改,由于沒有預訓練的引數,所以不需要匯入引數,從頭開始訓練,
原始的代碼
# Instantiate model and move it to the computing device
model = DexiNedVit().to(device)
修改之后的
model = SETRModel(patch_size=(32, 32),
in_channels=3,
out_channels=1,
hidden_size=1024,
sample_rate=5,
num_hidden_layers=1,
num_attention_heads=16,
decode_features=[512, 256, 128, 64, 32]).to(device)
二、訓練結果
2.1 單層SETR邊緣檢測結果


上述訓練使用BIPED資料集進行訓練,batchsize是16,上圖為訓練8156個epoch的結果,Loss在0.023左右,每三列是一組,第一列是原始影像,第二列是邊緣的真值(groundtruth),第三列為模型提取的邊緣,從圖中的結果可以看出,邊緣的提取結果能看出來是影像的邊緣,簡單一點的紋理還可以提取出來,但是對于較為豐富的紋理提取的效果不是很好,主要有幾個原因,第一、使用單層的SETR對紋理細節的表征能力還不夠,引數欠缺,無法表達更加豐富的紋理特征,第二、沒有多尺度的融合,相當于只做了一個回歸任務,強行套用了SETR的模型,第三、沒有使用SETR的預備訓練引數,整個模型是從頭開始訓練的,沒有預訓練的引數,模型很難達到好的效果,
2.2 多層SETR邊緣檢測結果
多層SETR模型使用了16層(圖1(a)中的塊重復16次),訓練程序中的輸出結果下圖,


由上圖可以看出,增加SETR的層數能在一定程度上提升效果,只訓練4000個epoch的結果已經與單層8000多個epoch的差不多,沒有多尺度的融合,效果應該也無法超越現有的最好結果,
總結
結合兩篇頂會論文的相關模型結構,使用Transformer實驗了邊緣提取的相關模型,相比目前性能最好的邊緣提取模型,實驗的結果還差很遠,魔改第一步完成,接下來就是分析魔改效果不好的原因,怎么進一步提升,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/388031.html
標籤:其他