JAVASE學習筆記(十三.1)
- Java7新特性 - `AutoCloseable`
- 1. 概述
- 2. 應用場景
- 示例
- 如何解決
- 改進
- 注意
- Java8新特性 - `Stream流`
- 1. 概述
- 2. Stream的API
- 3. Stream的認識
- (1)Stream-流的常用創建方法
- 面試題
- stream流使用步驟
- 準備作業
- (2)中間操作
- 1. 過濾:filter
- 2. 映射改造:peek / map
- peek和map的區別是什么?
- 3. 排序:sorted
- 4. ==distanct==
- 5. 集合分頁:skip / limit
- 匿名內部類作用
- (3)終止操作
- findFirst& findAny
- 總結
- 4. 使用場景
Java7新特性 - AutoCloseable
1. 概述
JDK在1.7之后出現了自動關閉類的功能,該功能的出現為各種關閉資源提供了相當大的幫助,這里我們談一談自動關閉類,
JDK1.7之后出現了一個重要的介面,以及改造了一個重要的方法結構:
- AutoCloseable自動關閉介面
- try(){}–catch{}–finally{}
相應的 一些資源也實作了該介面,如PreparedStatement、Connection、InputStream、OutputStream等等資源介面,
2. 應用場景
示例
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class MyLockDemo {
static Lock lock = new ReentrantLock();
public static void main(String[] args) {
try {
lock.lock();
System.out.println("1-----加鎖成功!!!");
System.out.println("2-----開始執行業務邏輯");
Thread.sleep(3000);
System.out.println("3-----業務執行完畢");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
System.out.println("4----釋放鎖資源");
}
}
}
如上,在開發中鎖是釋放必須要做得事情,所以就把放在finally中來執行,但是在開發中往往很多的開發中,都會忘記釋放鎖或者忘記把鎖的釋放放入finally中,就造成死鎖現象,這個很危險的操作和行為,
如何解決
- 使用
AutoCloseable介面覆寫close方法
實作
AutoCloseable介面,
覆寫close方法,
把原來要寫finally中釋放資源的動作,放入到close方法中去執行,
而這個執行是jvm自己去執行.
在有try(){}–catch{}–finally{}的時候去實作
- 介面的實作類要重寫close()方法,
- 將要關閉的資源定義在try()中,這樣當程式執行完畢之后,資源將會自動關閉,
- 自定義類如果要進行自動關閉,只需要實作AutoCloseable介面重寫close()方法即可,
同時也只有實作了AutoCloseable介面才能將自定義類放入到try()塊中,否則編譯不能通過
改進
- 定義類MyLock類
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class MyLock implements AutoCloseable{
Lock lock = new ReentrantLock();
// 加鎖
public void lock() {
lock.lock();
}
// 釋放鎖
public void unlock() {
lock.unlock();
}
@Override
public void close() throws Exception {
unlock();
System.out.println("4----釋放鎖資源");
}
}
改進
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class MyLockDemo {
public static void main(String[] args) {
try (MyLock lock = new MyLock();){
lock.lock();
System.out.println("1-----加鎖成功!!!");
System.out.println("2-----開始執行業務邏輯");
Thread.sleep(3000);
System.out.println("3-----業務執行完畢");
} catch (Exception e) {
e.printStackTrace();
}// finally {
// // 不需要定義了.因為會自動去釋放資源
// lock.unlock();
// }
}
}
1-----加鎖成功!!!
2-----開始執行業務邏輯
3-----業務執行完畢
4----釋放鎖資源 -- 這里的執行就是AutoCloseable中的close方法自動執行的
注意
若是有多個類需要上鎖釋放鎖
在try{}中用“;”隔開
釋放鎖有順序,先上鎖的最后放
Java8新特性 - Stream流
1. 概述
概念:Stream 是Java8 提出的一個新概念,不是輸入輸出的 Stream
流,而是一種用函式式編程方式在集合類上進行復雜操作的工具,簡而言之,是以內部迭代的方式處理集合資料的操作,內部迭代可以將更多的控制權交給集合類,Stream和 Iterator 的功能類似,只是 Iterator 是以外部迭代的形式處理集合資料的操作,
總結:Stream 是Java8 的新特性,它是基于Lambda運算式在集合陣列等進行一系列的優化和操作的工具集,解決集合中一些像過濾,排序,分組,聚合,改造等一系列的問題,
在Java8以前,對集合的操作需要寫出處理的程序,如在集合中篩選出滿足條件的資料,需要一 一遍歷集合中的每個元素,再把每個元素逐一判斷是否滿足條件,最后將滿足條件的元素保存回傳,而Stream 對集合篩選的操作提供了一種更為便捷的操作,只需將實作函式介面的篩選條件作為引數傳遞進來,Stream會自行操作并將合適的元素同樣以Stream 的方式回傳,最后進行接收即可,
- 集合和陣列在遍歷元素的時候十分冗余,受到函式式編程以及流水線思想的啟發,我們可以將常見的操作封裝成比較簡單的方法,比如遍歷的時候直接呼叫一個方法即可,而不用寫冗余的回圈程式,這就是Stream流物件的由來,
- Stream是一個介面,有兩種方式來進行創建流物件,
一是呼叫 Stream.介面中的of方法,
二是呼叫集合或者陣列中的strain方法來獲取 Stream.流物件 - Stream物件中常用的方法有:遍歷元素,篩選元素,跳過元素,截取元素,計數,把流物件拼接,對流物件中的資料元素進行轉換,
2. Stream的API
流是javaAPI中的新的成員,它可以讓你用宣告式的方式處理集合,簡單點說,可以看成遍歷資料的一個高級點的迭代器,也可以看做一個工廠,資料處理的工廠,當然,流還天然的支持并行操作;也就不用去寫復雜的多執行緒的代碼,下面是Stream的接口定義
在jdk1.8的java.util.stream.Stream介面,里面定義流的API的方法,jdk集合Collection.java頂級集合,利用默認方法進行了實作,具體的實作是通過:StreamSupport.java實作的,
Stream是處理集合的一套高級的API的解決方案
public interface Stream<T> extends BaseStream<T, Stream<T>> {
Stream<T> filter(Predicate<? super T> predicate);
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper);
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper);
Stream<T> distinct();
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> peek(Consumer<? super T> action);
Stream<T> limit(long maxSize);
Stream<T> skip(long n);
void forEach(Consumer<? super T> action);
void forEachOrdered(Consumer<? super T> action);
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
long count();
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
Optional<T> findFirst();
Optional<T> findAny();
public static <T> Builder<T> builder() {
return new Streams.streamBuilderImpl<>();
}
public static <T> Stream<T> empty() {
return StreamSupport.stream(Spliterators.<T> emptySpliterator(), false);
}
public static <T> Stream<T> of(T t) {
return StreamSupport.stream(new Streams.streamBuilderImpl<>(t), false);
}
@SafeVarargs
@SuppressWarnings("varargs") // Creating a Stream from an array is safe
public static <T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
public static <T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {
Objects.requireNonNull(f);
final Iterator<T> iterator = new Iterator<T>() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(iterator, Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
}
public static <T> Stream<T> generate(Supplier<T> s) {
Objects.requireNonNull(s);
return StreamSupport.stream(new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s),
false);
}
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>((Spliterator<T>) a.spliterator(),
(Spliterator<T>) b.spliterator());
Stream<T> Stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return Stream.onClose(Streams.composedClose(a, b));
}
public interface Builder<T> extends Consumer<T> {
@Override
void accept(T t);
default Builder<T> add(T t) {
accept(t);
return this;
}
Stream<T> build();
}
}
3. Stream的認識
通過上述介面定義,可以看到,抽象方法,有30多個方法,里面還有一些其他的介面;
上述方法可分為三類:
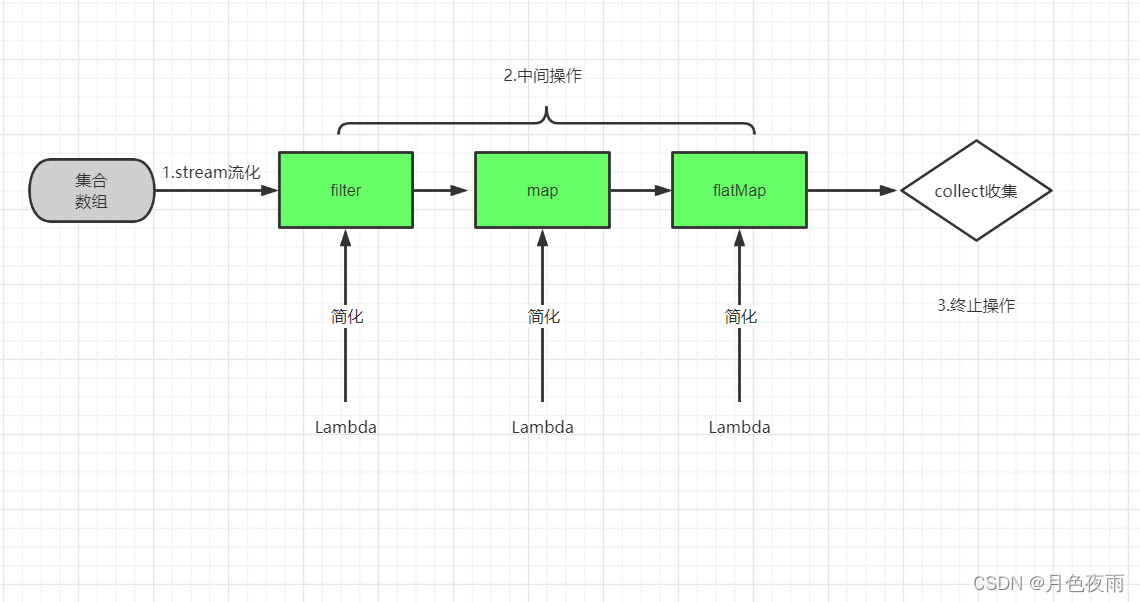
(1)Stream-流的常用創建方法
面試題
stream()和parallelStream()兩種流化方法的區別
stream流使用步驟
- 流化
- 中間操作
- 終端操作
準備作業
//1.創建集合
List<User> users = new ArrayList<>();
users.add(new User("月色",18,0));
users.add(new User("夜雨",16,1));
users.add(new User("搖光",18,0));
users.add(new User("流蘇",19,1));
//2.流化
Stream<User> stream = users.stream();
Stream<User> userStream = users.parallelStream();
List<User> collect = Stream.of(new User("月色", 18, 0), new User("夜雨", 16, 1)).collect(Collectors.toList());
1.1 集合轉流:使用Collection下的 stream() 和 parallelStream() 方法
List<String> list = new ArrayList<>();
Stream<String> Stream = list.stream(); //獲取一個順序流
Stream<String> parallelStream = list.parallelStream(); //獲取一個并行流
1.2 陣列轉流:使用Arrays 中的 stream() 方法
Integer[] nums = new Integer[10];
Stream<Integer> Stream = Arrays.stream(nums);
1.3 使用Stream中的靜態方法:of()、iterate()、generate()
List<User> collect = Stream.of(new User("月色", 18, 0), new User("夜雨", 16, 1)).collect(Collectors.toList());
Stream.of:把多個物件進行流化處理
Stream<Integer> Stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
Stream2.forEach(System.out::println); // 0 2 4 6 8 10
Stream<Double> Stream3 = Stream.generate(Math::random).limit(2);
Stream3.forEach(System.out::println);
1.4 使用 BufferedReader.lines() 方法,將每行內容轉成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_Stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
1.5 使用 Pattern.splitAsStream() 方法,將字串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
(2)中間操作
intermediate operation 中間操作:中間操作的結果是刻畫、描述了一個Stream,并沒有產生一個新集合,這種操作也叫做惰性求值方法,
對應的方法如下:
這是所有Stream中間操作的串列:
過濾()==>filter()//將滿足條件的過濾出來
地圖==>map()//映射結果,改造資料,有回傳值
轉換()==>flatMap()
不同()==>distinct()
排序()==>sorted()
窺視()==>peek()//映射結果,改造資料,無回傳值
限制()==>limit()
跳躍()==>skip()
疊加()==>reduce()
1. 過濾:filter
語法:
Stream<T> filter(Predicate<? super T> predicate);
寫法
userList1.stream().filter(new Predicate<User>() {
@Override
public boolean test(User user) {
System.out.println("11111");
return false;
}
});
userList1.stream().filter(u-> {
return u.getAge() > 16;
});
userList1.filter(u -> u.getAge() > 16)
是過濾,把條件滿足的過濾匹配處理,如下
public class StreamDemo01 {
public static void main(String[] args) {
// 1:創建一個集合
List<User> userList1 = new ArrayList<>();
userList1 .add(new User("月色",18,0));
userList1 .add(new User("夜雨",16,1));
userList1 .add(new User("搖光",18,0));
userList1 .add(new User("流蘇",19,1));
// 3: 結束操作
List<User> collect = userList1.stream()
.filter(u -> u.getAge() > 16) // 把滿足條件的篩選出來
.collect(Collectors.toList());
for (User user : collect) {
System.out.println(user);
}
}
}
2. 映射改造:peek / map
屬于:映射 ,它可以改變集合中的物件的屬性值
Stream<T> peek(Consumer<? super T> action);
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
- peek操作案例:
把集合中年齡大于16歲的用戶的年齡+1歲,如下
List<User> collect = userList1.stream() // 1: stream流化操作
.filter(u -> u.getAge() > 16) // // 2:中間操作 filter 把滿足條件的篩選出來
.peek(u->u.setAge(u.getAge() + 1))// 3:中間操作 peek 把每個用戶的年齡加1歲
.collect(Collectors.toList()); // 4: 結束操作
for (User user : collect) {
System.out.println(user);
}
- map操作案例:
List<User> collect = userList1.stream() // 1: stream流化操作
.filter(u -> u.getAge() > 16) // // 2:中間操作 filter 把滿足條件的篩選出來
.map(u -> {
u.setAge(u.getAge() + 1);
return u;
})// 3:中間操作 peek 把每個用戶的年齡加1歲
.collect(Collectors.toList()); // 4: 結束操作
peek和map的區別是什么?
- peek和map區別:peek無回傳值,map有回傳值(可以改變回傳值)
- peek你前面集合流化物件回傳的是什么就是什么?
map可以把stream回傳值進行改變,我可以把集合中的物件改成map在回傳,或者我只需要集合中某個一列的值,
public class StreamDemo02 {
public static void main(String[] args) {
// 1:創建一個集合
List<User> userList1 = new ArrayList<>();
userList1 .add(new User("月色",18,0));
userList1 .add(new User("夜雨",16,1));
userList1 .add(new User("搖光",18,0));
userList1 .add(new User("流蘇",19,1));
// user--nickname
List<String> nicknames = userList1.stream().map(u -> {
return u.getUsername();
}).collect(Collectors.toList());
for (String nickname : nicknames) {
System.out.println(nickname);
}
// user---map
List<Map<String, Object>> collect = userList1.stream().map(u -> {
Map<String, Object> map = new HashMap<>();
map.put("id", u.getId());
map.put("username", u.getUsername());
map.put("sex", u.getSex());
return map;
}).collect(Collectors.toList());
for (Map<String, Object> stringObjectMap : collect) {
System.out.println(stringObjectMap);
}
// user--->uservo
List<UserVo> collect1 = userList1.stream().map(u -> {
UserVo userVo = new UserVo();
userVo.setId(u.getId());
userVo.setUsername(u.getUsername());
userVo.setSex(u.getSex() == 1 ? "男" : "女");
return userVo;
}).collect(Collectors.toList());
for (UserVo userVo : collect1) {
System.out.println(userVo);
}
}
}
3. 排序:sorted
public class StreamDemo03 {
public static void main(String[] args) {
// 1:創建一個集合
List<User> userList1 = new ArrayList<>();
userList1 .add(new User("月色",18,0));
userList1 .add(new User("夜雨",16,1));
userList1 .add(new User("搖光",18,0));
userList1 .add(new User("流蘇",19,1));
// List<User> sortUserList = userList1.stream().sorted(new Comparator<User>() {
// @Override
// public int compare(User o1, User o2) {
// return o2.getAge() - o1.getAge();
// }
// }).collect(Collectors.toList());
// List<User> sortUserList = userList1.stream().sorted((User o1, User o2) ->{
// return o2.getAge() - o1.getAge();
// }).collect(Collectors.toList());
List<User> sortUserList = userList1.stream().sorted((o1, o2) -> o2.getAge() - o1.getAge()).collect(Collectors.toList());
for (User user : sortUserList) {
System.out.println(user);
}
}
}
4. distanct
去重這里有個坑:去重是通過equal來比較兩者值是否相等來實作去重,但是問題來了:
類似
Integer這種型別原始碼已經重寫了equal方法,但是像我們自定義的一些型別,物件,它并沒有重寫equal方法,所以它依舊在比較地址以至于不能完成去重功能,所以我們要使用distabct的時候注意是否需要重寫equal
- 如果是物件,必須滿足eqauls是true ,并且hashcode要相同
public class User {
// 身份id
private Integer id;
// 姓名
private String username;
// 密碼
private String password;
// 芳齡
private Integer age;
// 性別 0 女 1 男
private Integer sex;
// 身家
private Double money;
public User(){
}
public User(Integer id, String username, String password, Integer age, Integer sex, Double money) {
this.id = id;
this.username = username;
this.password = password;
this.age = age;
this.sex = sex;
this.money = money;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", age=" + age +
", sex=" + sex +
", money=" + money +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(id, user.id) && Objects.equals(username, user.username) && Objects.equals(password, user.password) && Objects.equals(age, user.age) && Objects.equals(sex, user.sex) && Objects.equals(money, user.money);
}
@Override
public int hashCode() {
return Objects.hash(id, username, password, age, sex, money);
}
}
public class StreamDemo04 {
public static void main(String[] args) {
// 1:創建一個集合
List<User> userList1 = new ArrayList<>();
User user1 = new User(1, "小文", "123456", 16, 1, 20000d);
User user2 = new User(1, "小文", "123456", 16, 1, 20000d);
userList1.add(user1);
userList1.add(user2);
userList1.add(new User(2, "老季", "123456", 22, 1, 100000d));
userList1.add(new User(3, "怪咖", "123456", 13, 1, 89557d));
userList1.add(new User(4, "小六", "123456", 26, 1, 78000d));
userList1.add(new User(5, "小劉", "123456", 46, 1, 58000d));
System.out.println(user1.equals(user2));
List<User> userList = userList1.stream().distinct().collect(Collectors.toList());
for (User user : userList) {
System.out.println(user);
}
// List<Integer> userList1 = new ArrayList<>();
// userList1.add(1);
// userList1.add(2);
// userList1.add(3);
// userList1.add(1);
//
// List<Integer> collect = userList1.stream().distinct().collect(Collectors.toList());
// System.out.println(collect);
}
}
轉換()==>flatMap()
疊加()==>reduce()
5. 集合分頁:skip / limit
public class StreamDemo03 {
public static void main(String[] args) {
// 1:創建一個集合
List<User> userList1 = new ArrayList<>();
userList1 .add(new User("月色",18,0));
userList1 .add(new User("夜雨",16,1));
userList1 .add(new User("搖光",18,0));
userList1 .add(new User("流蘇",19,1));
int pageSize =2;// 每頁顯示多少條
int pageno = 1; // 當前頁
List<User> userpage = pageUser(pageNo,pageSize);
}
public static List<User> pageUser(int pageNo,int pageSize){
int skip = (pageNo - 1) * pageSize;
return userList1.stream().sorted((o1, o2) -> o2.getAge() - o1.getAge())
.skip(skip) // (pageno-1) * pageSize
.limit(pageSize) // pageSize
.collect(Collectors.toList());
//類似分頁
for(User user : sortUserList){
system.out.println(user);
}
}
}
匿名內部類作用
中間操作經常用
Lambda運算式簡化代碼,使用lambda運算式會派生一個介面類,好處是:
把匿名內部類(介面,抽象類)當做方法的引數傳遞以后,它可以達到一個效果就是可以把方法中的一部分邏輯抽離到匿名內部類的方法中去處理,
userList1.stream().filter(new Predicate<User>() {
@Override
public boolean test(User user) {
System.out.println("11111");
return false;
}
});
userList1.stream().filter(u-> {
return u.getAge() > 16;
});
userList1.filter(u -> u.getAge() > 16)
(3)終止操作
terminal operation 終止操作:最侄訓從Stream中得到值,說白了:就是可以直接得到結果
回圈()==>foreach()
count():回傳流中元總個數素
收集()==>collect()---放
andMatch():接受一個`predicate`函式,只要流中有一個元素符合該斷言回傳true,否則回傳false
noneMatch():接受一個`predicate`函式,當流中每個元素都不符合該斷言回傳true,否則回傳false
allMatch():接受一個`predicate`函式,當流中每個元素都符合該斷言回傳true,否則回傳false
min():回傳流中元素最小值
max():回傳流中元素最大值
findFirst& findAny
- 兩者在stream(串行)的情況下,兩者其實都回傳的第一個元素
- 如果是parallelStream(并行)情況下findAny就造成隨機回傳
findAny()回傳的元素是不確定的,對于同一個串列多次呼叫findAny()有可能會回傳不同的值,使用findAny()是為了更高效的性能,
如果是資料較少,串行地情況下,一般會回傳第一個結果,
如果是并行的情況,那就不能確保是第一個,
總結
steram流一旦呼叫終止方法就代表流已經操作完畢,不能進行其他操作了
若要重新進行操作
將結果再次轉換為流即可
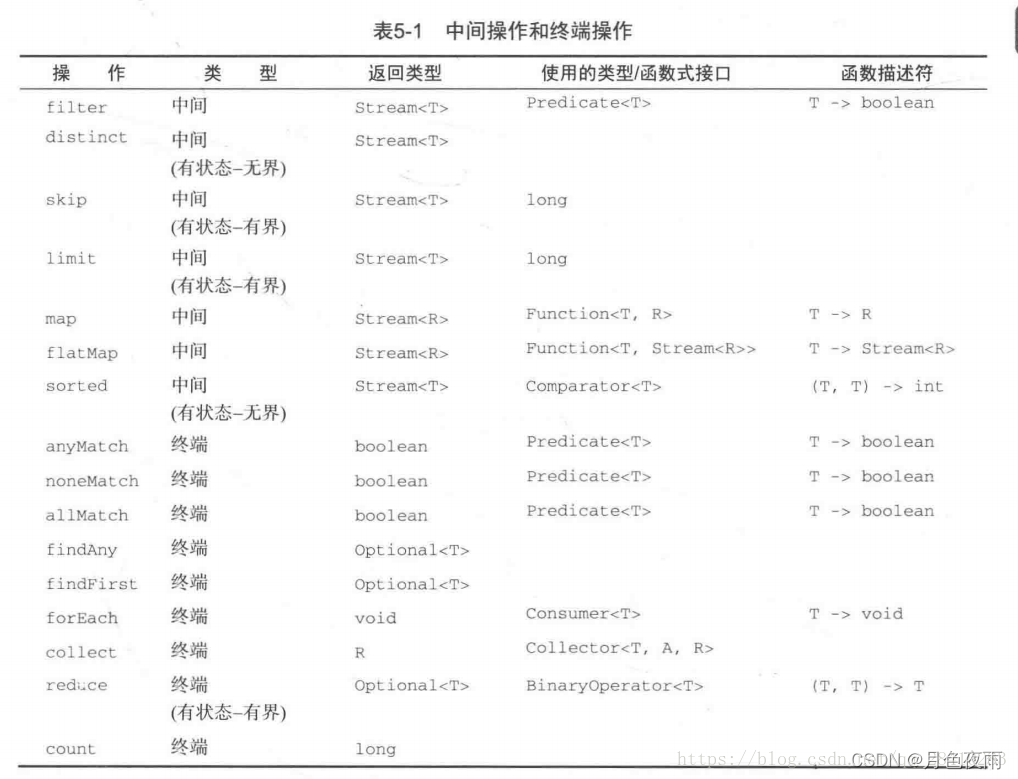
- 如何區分這2種操作
可以根據操作的回傳值型別判斷:
回傳值是Stream,則該操作是中間操作
回傳值是其他值或者為空,則該操作是終止操作,
如下圖的前2個操作是中間操作,只有最后一個操作是終止操作,
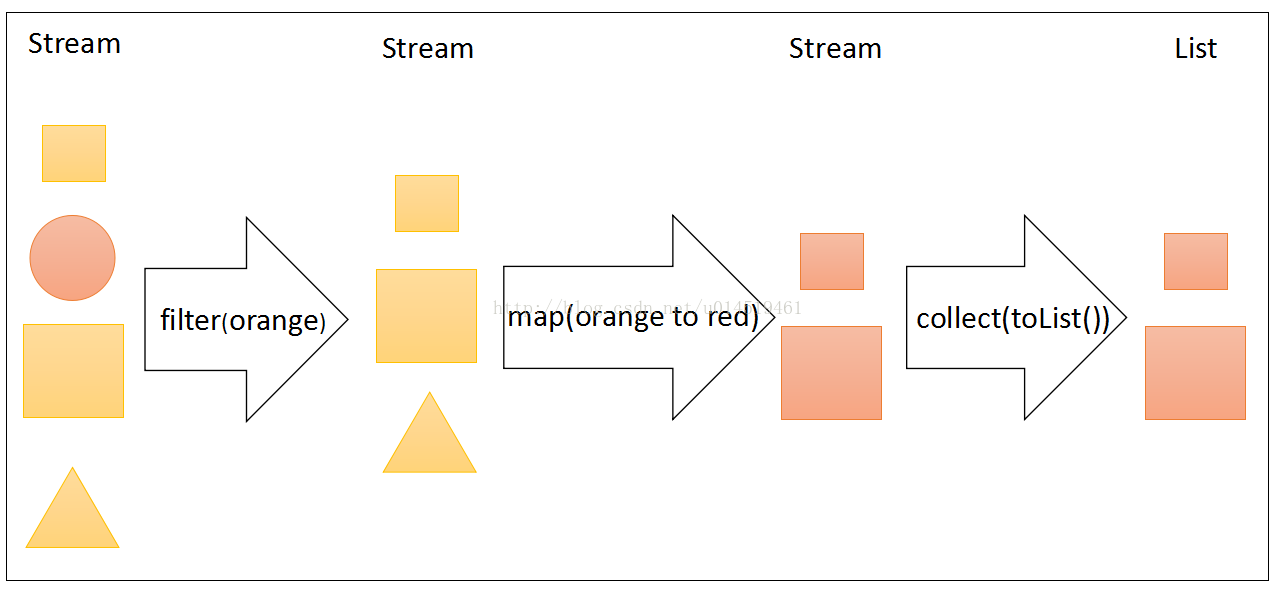
可以形象地理解Stream的操作是對一組粗糙的工藝品原型(即對應的 Stream
資料源)進行加工成顏色統一的工藝品(即最終得到的結果),第一步篩選出合適的原型(即對應Stream的 filter
的方法),第二步將這些篩選出來的原型工藝品上色(對應Stream的map方法),第三步取下這些上好色的工藝品(即對應Stream的
collect(toLis t())方法),在取下工藝品之前進行的操作都是中間操作,可以有多個或者0個中間操作,但每個Stream資料源只能有一次終止操作,否則程式會報錯
4. 使用場景
場景:查詢用戶資訊的時候為了安全起見,需要把集合中每個用戶物件的敏感資訊賦值null,在進行回傳,
- 版本8之前:新建list
List<User> userList = new ArrayList();
List<User> newList = new ArrayList();
for(User user : userList){
user.setPassword = null;
newList.add(user);
}
-
版本8之后:stream流化
-
peek解決:
List<User> userList = userList1.stream().peek(u -> u.setPassword("")).collect(Collectors.toList());
userList.forEach(System.out::println);
- map解決
List<User> userList2 = userList1.stream().map(u -> {
u.setPassword("");
return u;
}).collect(Collectors.toList());
userList2.forEach(System.out::println);
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/388251.html
標籤:其他
上一篇:JavaWeb(一)——JavaWeb介紹、Tomcat服務器、HTTP協議
下一篇:Log4j漏洞修復方案