Apriori原理:如果某個項集是頻繁的,那么它的所有子集都是頻繁的,
Apriori演算法:


1 輸入支持度閾值t和資料集 2 生成含有K個元素的項集的候選集(K初始為1) 3 對候選集每個項集,判斷是否為資料集中某條記錄的子集 4 如果是:增加候選集的計數 5 保留頻繁集(計數>t) 6 根據頻繁集生成含有K+1個元素的項集候選集 7 回圈2-5,直至候選集為空View Code
Apriori演算法是有缺點的
缺點是:1.需要多長掃描 2.產生大量的候選頻繁集 3.時間和空間復雜度高,
FP樹增長演算法是一種挖掘頻繁項集的演算法,Apriori演算法雖然簡單易實作,效果也不錯,但是需要頻繁地掃描資料集,IO費用很大,FP樹增長演算法有效地解決了這一問題,其通過兩次掃描資料集構建FP樹,然后通過FP樹挖掘頻繁項集,
背景知識
1.什么是項和項集?
比如我們在購物的時候,購物車內的每一件商品成為一項,若干個項的集合成為項集,例如{啤酒,尿布}成為一個二元項集,
2.什么是支持度?
支持度是在所有的項集中{X,Y}出現的可能性,
例如:購買商品的資料是(表示4條購物資訊):
①{啤酒,尿布,娃哈哈}
②{啤酒,方便面}
③{尿布,奶粉}
④{啤酒,尿布,洗發水}
在這組資料中,{啤酒,尿布}出現的可能性就是這里面資料的概率,{啤酒,尿布}的支持度是2/4=50%.
{尿布,奶粉}的支持度是1/4=25%
3.什么是頻繁項集?
我們首先設定一個最小閾值A,支持度大于A的項集就是頻繁項集,小于A的項集被剔除,
比如 我們設定閾值為30%,在上面的例子中{啤酒,尿布}就是頻繁項集,{尿布,奶粉}就要被剔除,
問題:如何求出頻繁項集?
首先構造FP樹
然后通過FP樹可以求出頻繁項集
FP演算法
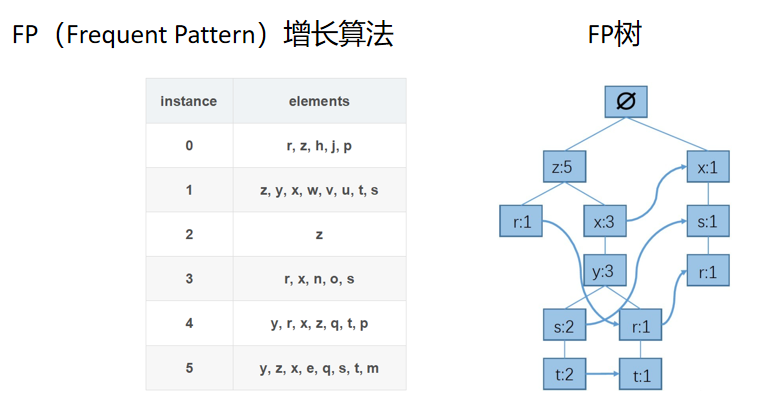
其中istance表示購買次數,elements表示每次一次性購買的商品,每個字母表示商品,
步驟一:統計每個元素出現次數,保留頻繁元素(假設次數>3),按照元素出 現次數降序排序,
其中h,j,p,w,v,u,n,o,q,p,e,m的次數是小于等于3的.因此把它們去掉,然后把其他的字母按照次數從大到小排列,
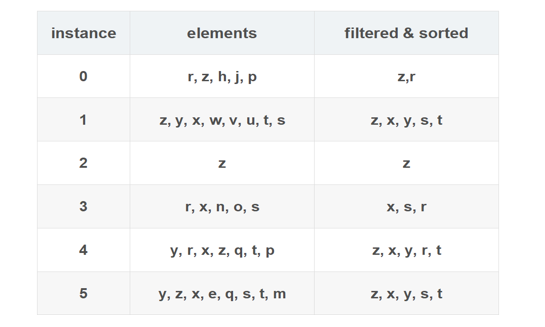
步驟二:構建FP樹
通過上面的序列按照每一行進入樹根初始化樹葉,如果沒有相同的字母就重新創建葉子節點,每個葉子節點有字母其次數,
如圖所示
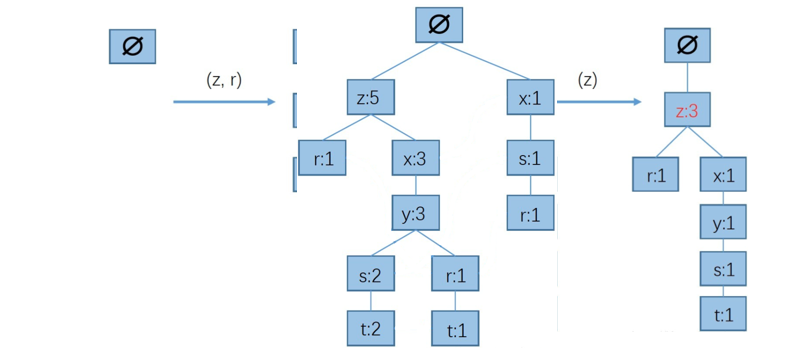
步驟三:FP樹中找到元素的前綴路徑(以元素結尾的路徑)
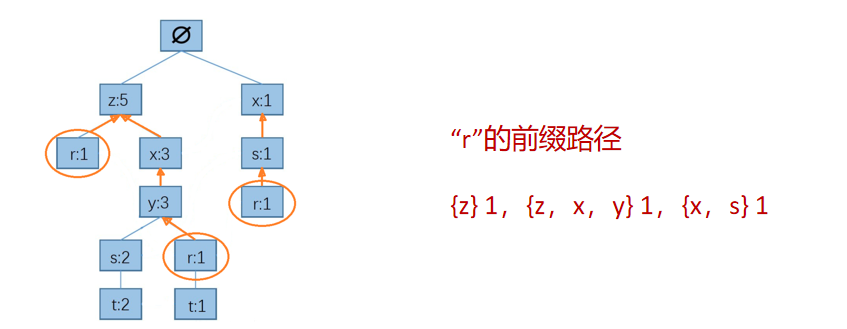
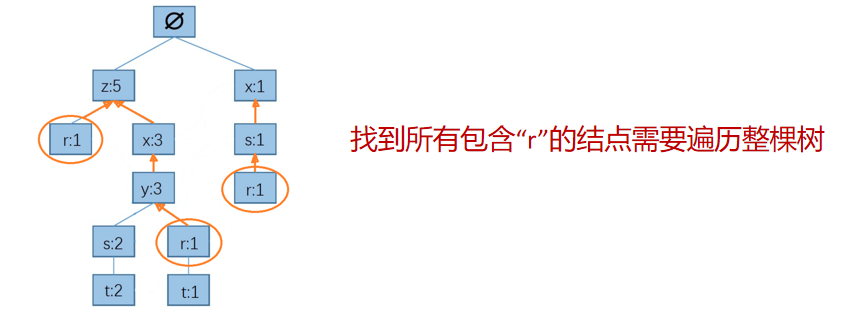
為了方便查找,用的鏈表來加快尋找的前綴路徑,
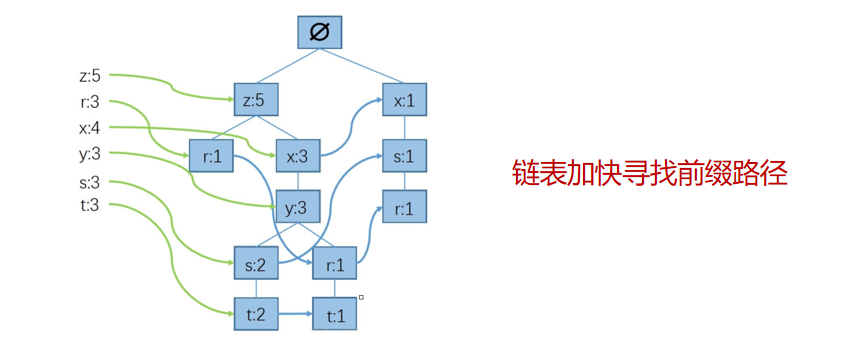
通過上面的操作就得到了如下所示的資訊,
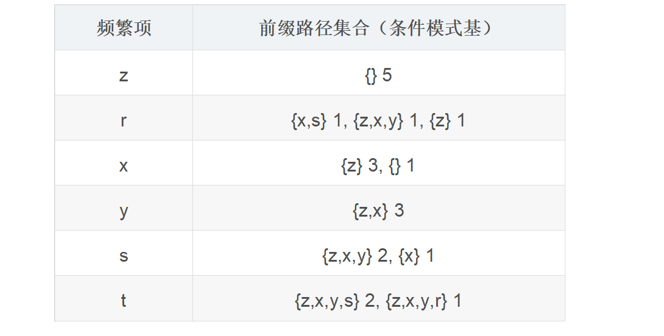
步驟四:根據前綴路徑構造條件FP樹
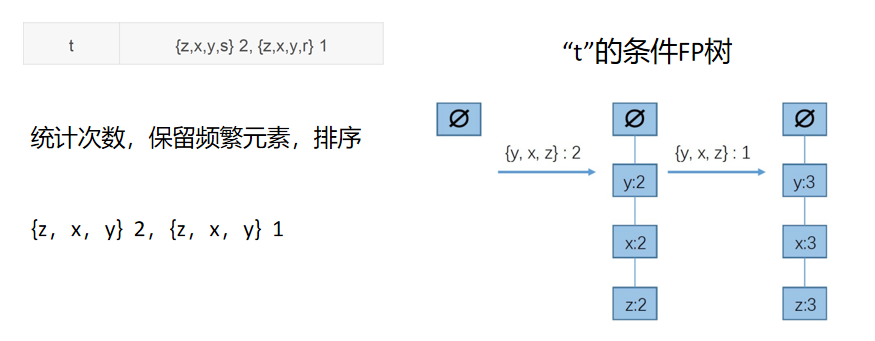
因此我們可以得到以t為結尾的頻繁項集:{y,t}{x,t},{z,t}....一直到{x,y,z,t},
步驟5:遞回構造下一層條件FP樹,直至條件FP樹為空.
總結:
有一個誤區:不是在FP樹上找頻繁項,而是在條件FP樹上找頻繁項,
掃描資料,得到所有頻繁一項集的計數,然后洗掉支持度低于閾值的項,將一項頻繁集放入項頭表,并按照支持度降序排列,
掃描資料,將讀到的原始資料剔除非頻繁1項集,并按照支持度降序排列,
讀入排序后的資料集,插入FP樹,插入時按照排序后的順序,插入FP樹中,排序靠前的節點是祖先節點,而靠后的是子孫節點,如果有共用的祖先,則對應的公用祖先節點計數加1,插入后,如果有新節點出現,則項頭表對應的節點會通過節點鏈表鏈接上新節點,直到所有的資料都插入到FP樹后,FP樹的建立完成,
從項頭表的底部項依次向上找到項頭表項對應的條件模式基,從條件模式基遞回挖掘得到項頭表項項的頻繁項集,
如果不限制頻繁項集的項數,則回傳步驟4所有的頻繁項集,否則只回傳滿足項數要求的頻繁項集,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/388946.html
標籤:其他