本文已加入 🚀 Python AI 計劃,從一個Python小白到一個AI大神,你所需要的所有知識都在 這里 了,
- 作者:K同學啊
- 資料:公眾號(K同學啊)內回復
DL+35可以獲取資料 - 代碼:全部代碼已放入文中,也可以去我的 GitHub 上下載
大家好,我是『K同學啊』!
今天我將帶大家探索一下深度學習在醫學領域的應用–腦腫瘤識別,腦腫瘤也稱為顱內腫瘤,是顱內占位性病變的主要疾病,在兒童易患的惡性病變中僅次于白血病,位于第二位,有資料表明,我國每年新增兒童腦瘤患者7000~8000名,其中70%~80%的患兒腫瘤呈惡性,由于腦腫瘤患者年齡越小,發病速度越快,腫瘤惡性程度越高,所以早期發現,治療成為降低疾病危害的重要方式之一,
這次我們一共用到了253張腦部掃描圖片資料,其中患有腦腫瘤的患者腦部掃描圖片155張,正常人的腦部掃描圖片98張,使用的演算法為MobileNetV2,最后的識別準確率是90.0%,AUC值為0.869,
本次的重點: 相對于《深度學習100例》以往的案例,本次我們將加入AUC評價指標來評估腦腫瘤識別的識別效果,AUC(Area under the Curve of ROC)是ROC曲線下方的面積,是判斷二分類預測模型優劣的標準,
我的環境:
- 語言環境:Python3.8
- 編譯器:Jupyter lab
- 深度學習環境:TensorFlow2.4.1
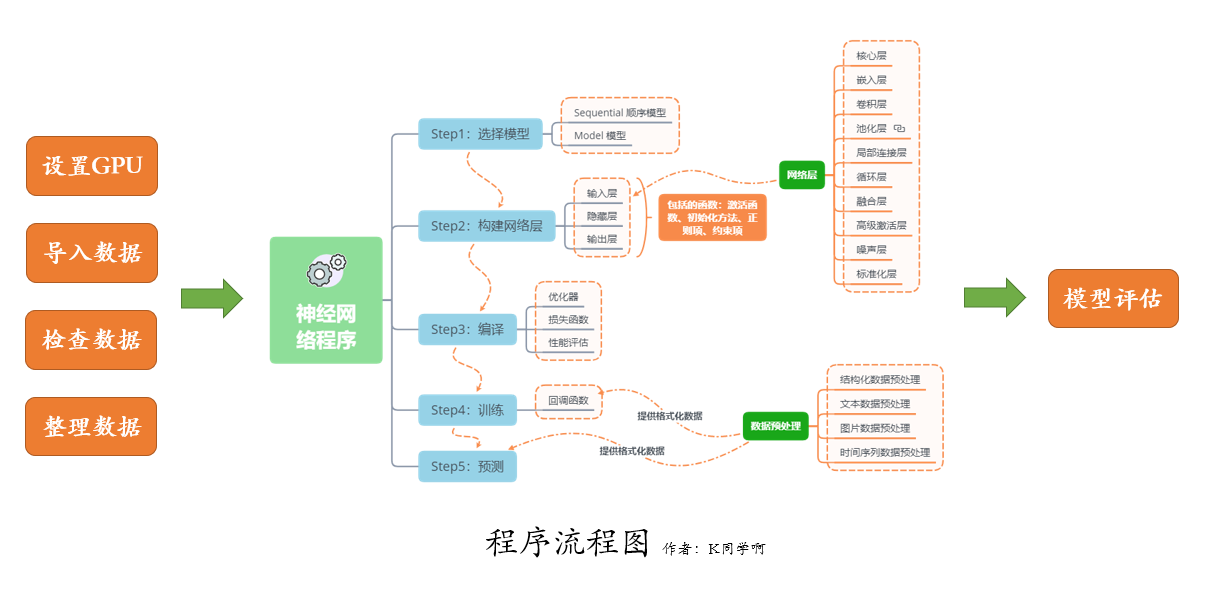
我們的代碼流程圖如下所示:
文章目錄
- 一、設定GPU
- 二、匯入資料
- 1. 匯入資料
- 2. 檢查資料
- 3. 配置資料集
- 4. 資料可視化
- 三、構建模型
- 四、編譯
- 五、訓練模型
- 六、模型評估
- 1. 混淆矩陣
- 2. 各項指標評估
- 3. AUC 評價
一、設定GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多個GPU,僅使用第0個GPU
tf.config.experimental.set_memory_growth(gpu0, True) #設定GPU顯存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import pandas as pd
import warnings
from tensorflow import keras
warnings.filterwarnings("ignore") #忽略警告資訊
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
二、匯入資料
1. 匯入資料
import pathlib
data_dir = "./35-day-brain_tumor_dataset"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("圖片總數為:",image_count)
圖片總數為: 253
batch_size = 16
img_height = 224
img_width = 224
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 253 files belonging to 2 classes.
Using 203 files for training.
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 253 files belonging to 2 classes.
Using 50 files for validation.
class_names = train_ds.class_names
print(class_names)
['no', 'yes']
2. 檢查資料
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(16, 224, 224, 3)
(16,)
3. 配置資料集
- shuffle() : 打亂資料,關于此函式的詳細介紹可以參考:https://zhuanlan.zhihu.com/p/42417456
- prefetch() : 預取資料,加速運行,其詳細介紹可以參考我前兩篇文章,里面都有講解,
- cache() : 將資料集快取到記憶體當中,加速運行
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 這里可以設定預處理函式
# .batch(batch_size) # 在image_dataset_from_directory處已經設定了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing) # 這里可以設定預處理函式
# .batch(batch_size) # 在image_dataset_from_directory處已經設定了batch_size
.prefetch(buffer_size=AUTOTUNE)
)
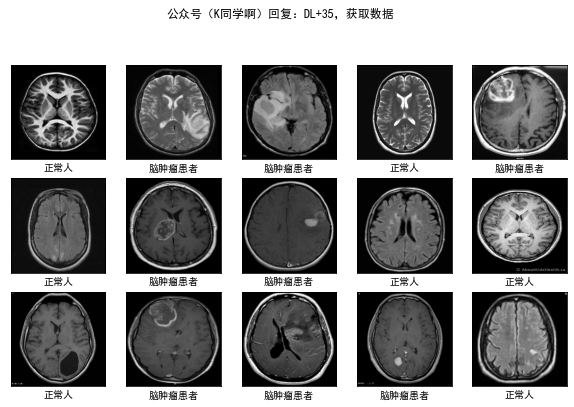
4. 資料可視化
plt.figure(figsize=(10, 8)) # 圖形的寬為10高為5
plt.suptitle("公眾號(K同學啊)回復:DL+35,獲取資料")
class_names = ["腦腫瘤患者","正常人"]
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 顯示圖片
plt.imshow(images[i])
# 顯示標簽
plt.xlabel(class_names[labels[i]-1])
plt.show()
三、構建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
# 加載預訓練模型
base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet',
include_top=False,
input_shape=(img_width,img_height,3),
pooling='max')
for layer in base_model.layers:
layer.trainable = True
X = base_model.output
"""
注意到原模型(MobileNetV2)會發生過擬合現象,這里加上一個Dropout層
加上后,過擬合現象得到了明顯的改善,
大家可以試著通過調整代碼,觀察一下注釋Dropout層與不注釋之間的差別
"""
X = Dropout(0.4)(X)
output = Dense(len(class_names), activation='softmax')(X)
model = Model(inputs=base_model.input, outputs=output)
# model.summary()
四、編譯
model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
五、訓練模型
from tensorflow.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
NO_EPOCHS = 50
PATIENCE = 10
VERBOSE = 1
# 設定動態學習率
annealer = LearningRateScheduler(lambda x: 1e-3 * 0.99 ** (x+NO_EPOCHS))
# 設定早停
earlystopper = EarlyStopping(monitor='val_acc', patience=PATIENCE, verbose=VERBOSE)
#
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=VERBOSE
save_best_only=True,
save_weights_only=True)
train_model = model.fit(train_ds,
epochs=NO_EPOCHS,
verbose=1,
validation_data=val_ds,
callbacks=[earlystopper, checkpointer, annealer])
Epoch 1/50
13/13 [==============================] - 7s 145ms/step - loss: 3.1000 - accuracy: 0.6700 - val_loss: 1.7745 - val_accuracy: 0.6400
WARNING:tensorflow:Early stopping conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy
......
Epoch 49/50
13/13 [==============================] - 1s 60ms/step - loss: 3.0536e-08 - accuracy: 1.0000 - val_loss: 2.6647 - val_accuracy: 0.8800
WARNING:tensorflow:Early stopping conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy
Epoch 00049: val_accuracy did not improve from 0.90000
Epoch 50/50
13/13 [==============================] - 1s 60ms/step - loss: 1.4094e-08 - accuracy: 1.0000 - val_loss: 2.6689 - val_accuracy: 0.8800
WARNING:tensorflow:Early stopping conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy
Epoch 00050: val_accuracy did not improve from 0.90000
六、模型評估
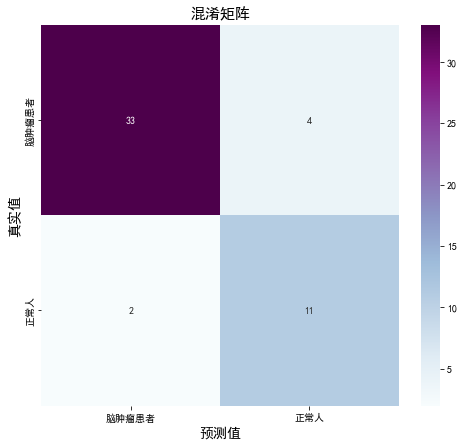
1. 混淆矩陣
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
# 定義一個繪制混淆矩陣圖的函式
def plot_cm(labels, predictions):
# 生成混淆矩陣
conf_numpy = confusion_matrix(labels, predictions)
# 將矩陣轉化為 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('混淆矩陣',fontsize=15)
plt.ylabel('真實值',fontsize=14)
plt.xlabel('預測值',fontsize=14)
val_pre = []
val_label = []
for images, labels in val_ds:#這里可以取部分驗證資料(.take(1))生成混淆矩陣
for image, label in zip(images, labels):
# 需要給圖片增加一個維度
img_array = tf.expand_dims(image, 0)
# 使用模型預測圖片中的人物
prediction = model.predict(img_array)
val_pre.append(class_names[np.argmax(prediction)])
val_label.append(class_names[label])
plot_cm(val_label, val_pre)
2. 各項指標評估
from sklearn import metrics
def test_accuracy_report(model):
print(metrics.classification_report(val_label, val_pre, target_names=class_names))
score = model.evaluate(val_ds, verbose=0)
print('Loss function: %s, accuracy:' % score[0], score[1])
test_accuracy_report(model)
precision recall f1-score support
腦腫瘤患者 0.94 0.89 0.92 37
正常人 0.73 0.85 0.79 13
accuracy 0.88 50
macro avg 0.84 0.87 0.85 50
weighted avg 0.89 0.88 0.88 50
Loss function: 2.668877601623535, accuracy: 0.8799999952316284
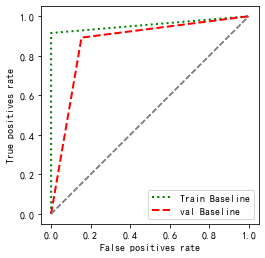
3. AUC 評價
一句話介紹:AUC(Area under the Curve of ROC)是ROC曲線下方的面積,是判斷二分類預測模型優劣的標準,
- AUC = 1:是完美分類器,絕大多數預測的場合,不存在完美分類器,
- 0.5 < AUC < 1:優于隨機猜測,
- AUC = 0.5:跟隨機猜測一樣(例:丟硬幣),模型沒有預測價值,
- AUC < 0.5:比隨機猜測還差,
ROC曲線的橫坐標是偽陽性率(也叫假正類率,False Positive Rate),縱坐標是真陽性率(真正類率,True Positive Rate),相應的還有真陰性率(真負類率,True Negative Rate)和偽陰性率(假負類率,False Negative Rate),這四類的計算方法如下:
- 偽陽性率(FPR):在所有實際為陰性的樣本中,被錯誤地判斷為陽性的比率,
- 真陽性率(TPR):在所有實際為陽性的樣本中,被正確地判斷為陽性的比率,
- 偽陰性率(FNR):在所有實際為陽性的樣本中,被錯誤的預測為陰性的比率,
- 真陰性率(TNR):在所有實際為陰性的樣本中,被正確的預測為陰性的比率,
val_pre = []
val_label = []
for images, labels in val_ds:#這里可以取部分驗證資料(.take(1))生成混淆矩陣
for image, label in zip(images, labels):
# 需要給圖片增加一個維度
img_array = tf.expand_dims(image, 0)
# 使用模型預測圖片中的人物
prediction = model.predict(img_array)
val_pre.append(np.argmax(prediction))
val_label.append(label)
train_pre = []
train_label = []
for images, labels in train_ds:#這里可以取部分驗證資料(.take(1))生成混淆矩陣
for image, label in zip(images, labels):
# 需要給圖片增加一個維度
img_array = tf.expand_dims(image, 0)
# 使用模型預測圖片中的人物
prediction = model.predict(img_array)
train_pre.append(np.argmax(prediction))
train_label.append(label)
sklearn.metrics.roc_curve():用于繪制ROC曲線
主要引數:
y_true:真實的樣本標簽,默認為{0,1}或者{-1,1},如果要設定為其它值,則 pos_label 引數要設定為特定值,例如要令樣本標簽為{1,2},其中2表示正樣本,則pos_label=2,y_score:對每個樣本的預測結果,pos_label:正樣本的標簽,
回傳值:
fpr:False positive rate,tpr:True positive rate,thresholds
def plot_roc(name, labels, predictions, **kwargs):
fp, tp, _ = metrics.roc_curve(labels, predictions)
plt.plot(fp, tp, label=name, linewidth=2, **kwargs)
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False positives rate')
plt.ylabel('True positives rate')
ax = plt.gca()
ax.set_aspect('equal')
plot_roc("Train Baseline", train_label, train_pre, color="green", linestyle=':')
plot_roc("val Baseline", val_label, val_pre, color="red", linestyle='--')
plt.legend(loc='lower right')
auc_score = metrics.roc_auc_score(val_label, val_pre)
print("AUC值為:",auc_score)
AUC值為: 0.869022869022869
🥇 需要 專案定制、畢設輔導 的同學可以加我V.信:mtyjkh_
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/389051.html
標籤:AI