🍂Hadoop入門
🍂🍂
- 🍂Hadoop入門
- 一、🍁環境準備
- 二、🍁Hadoop?HDFS
- 1、 分布式檔案系統架構
- 2、HDFS資料分類
- ①、DataNode
- ②、NameNode
- ③、SencondaryNameNode
- 三、🍁搭建Hadoop集群
- ① 環境準備
- ② 修改配置
- ③ 拷貝至node02、node03
- ④ 配置環境變數
- ⑤ 格式化NameNode?測驗
一、🍁環境準備
提前準備三臺虛擬機,構建三臺虛擬機免登錄(前提三臺虛擬機網路配置與本機名都已經配置,可翻看之前文章)
虛擬機相互免秘鑰
##右【123】意味著要三臺虛擬機同時操作
##三臺主機分別生成秘鑰
【123】ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
##host驗證
【123】vim /etc/ssh/ssh_config 在最后添加
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
##將秘鑰分別拷貝給自己和別人
【123】ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01
【123】ssh-copy-id -i ~/.ssh/id_rsa.pub root@node02
【123】ssh-copy-id -i ~/.ssh/id_rsa.pub root@node03
##免密中要輸入密碼
##關閉主機拍攝快照
power off
驗證:測驗免密登錄
二、🍁Hadoop?HDFS
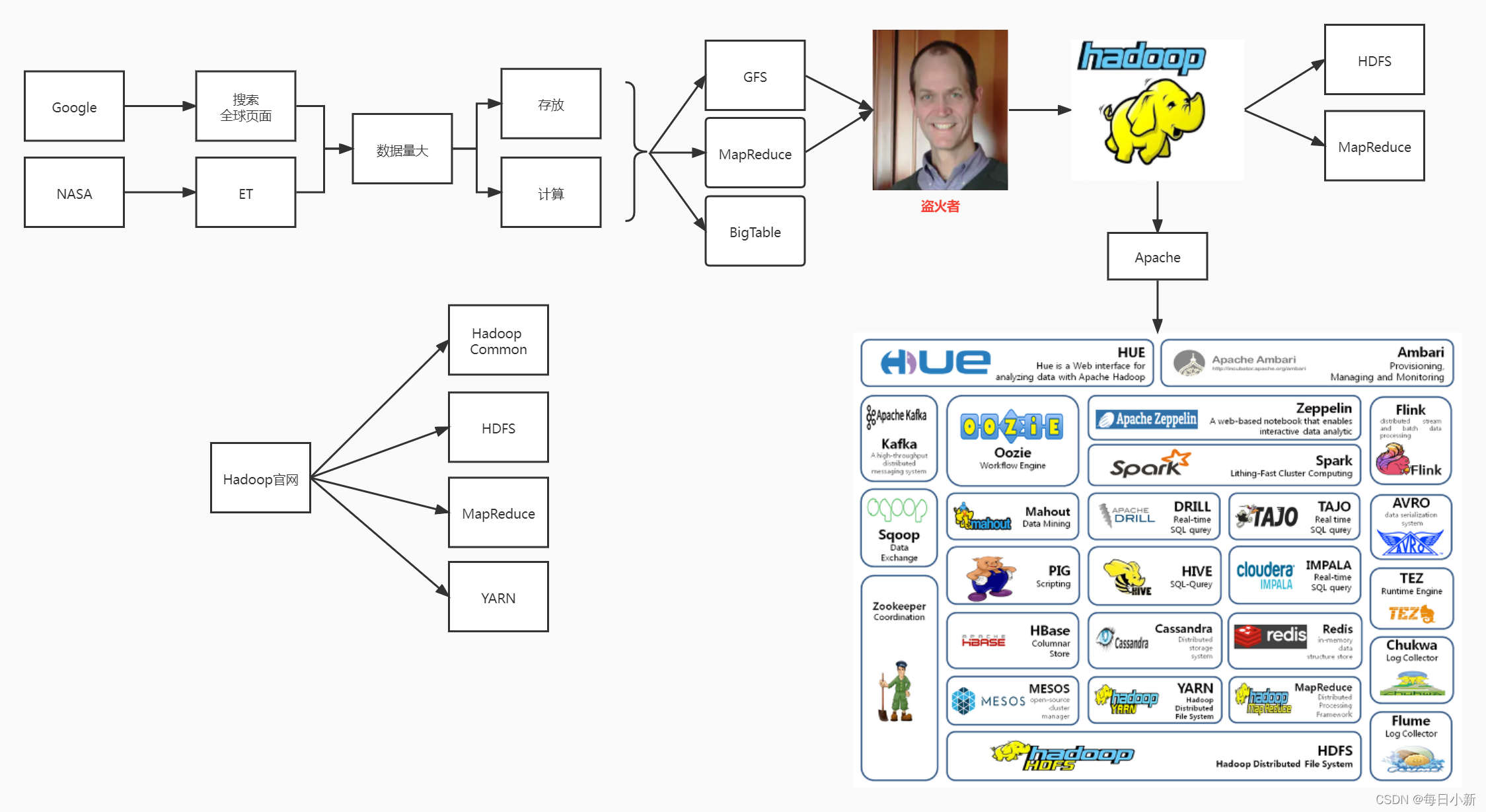
Nutch,Hadoop最早起源于Nutch,Nutch的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存盤和索引問題,Doug cutting花費了自己的兩年業余時間,將論文實作了出來,2008年1月,HADOOP成為Apache頂級專案,狹義上來說,hadoop就是單獨指代hadoop這個軟體,廣義上來說,hadoop指代大資料的一個生態圈,包括很多其他的軟體,
1、 分布式檔案系統架構
重要思想,就是檔案切分思想,通過對檔案的切分,劃分除等同的存盤塊Block,塊的大小不可改變,但內容的可以跟塊的大小不一樣,
DFS:分布式檔案系統:效率,安全,檔案依二進制存盤,拆分多個小資料存放,需要時再合并,根據偏移量進行合并,如果檔案存盤到單塊硬碟肯定慢,超出磁盤存盤空間等,二進制是一個位元組陣列,切分為塊,切分塊時,塊大小不一,只有找到全部的檔案才進行拼接,如果資料塊大小不一致,需要為單獨快設計演算法,讀取時間和程式計算時間,我們的檔案應該切分為等大的塊首選確定一個塊的大小,然后將檔案從頭至尾開始切分,從第一個塊至第二個快大小都是相同的,除了最后一個塊,45M 16M16M13M在HDFS中,資料的等大是計算的前提(最后一個可能不是等大)
- 名詞:access.log 檔案
- 切分之后每個部分被稱為Block
- 每個檔案可以切分成ceil(File/Block)
- HPV1 Block 64M(默認)
- HPV2 3 Block 128M(默認)
- 是否能夠修改HDF上的資料?
- 遷移資料量不可控
- 破壞等大特性,故此不被修改,但可以被追加,默認是關閉追加
- 是否額能修改已經上傳塊的大小?
- 不能,只能上傳新的,每個block可以不是128,可以自定義切分,但要等大,最后一個可以不扽大
- 遺留問題
- 有可能一個單詞,一個資料被切成兩分
- 安全
- 檔案切分一旦一個塊丟失則檔案損壞,—資料備份
- 塊的管理
- DataNode 1, DataNode 2,…資料存盤節點
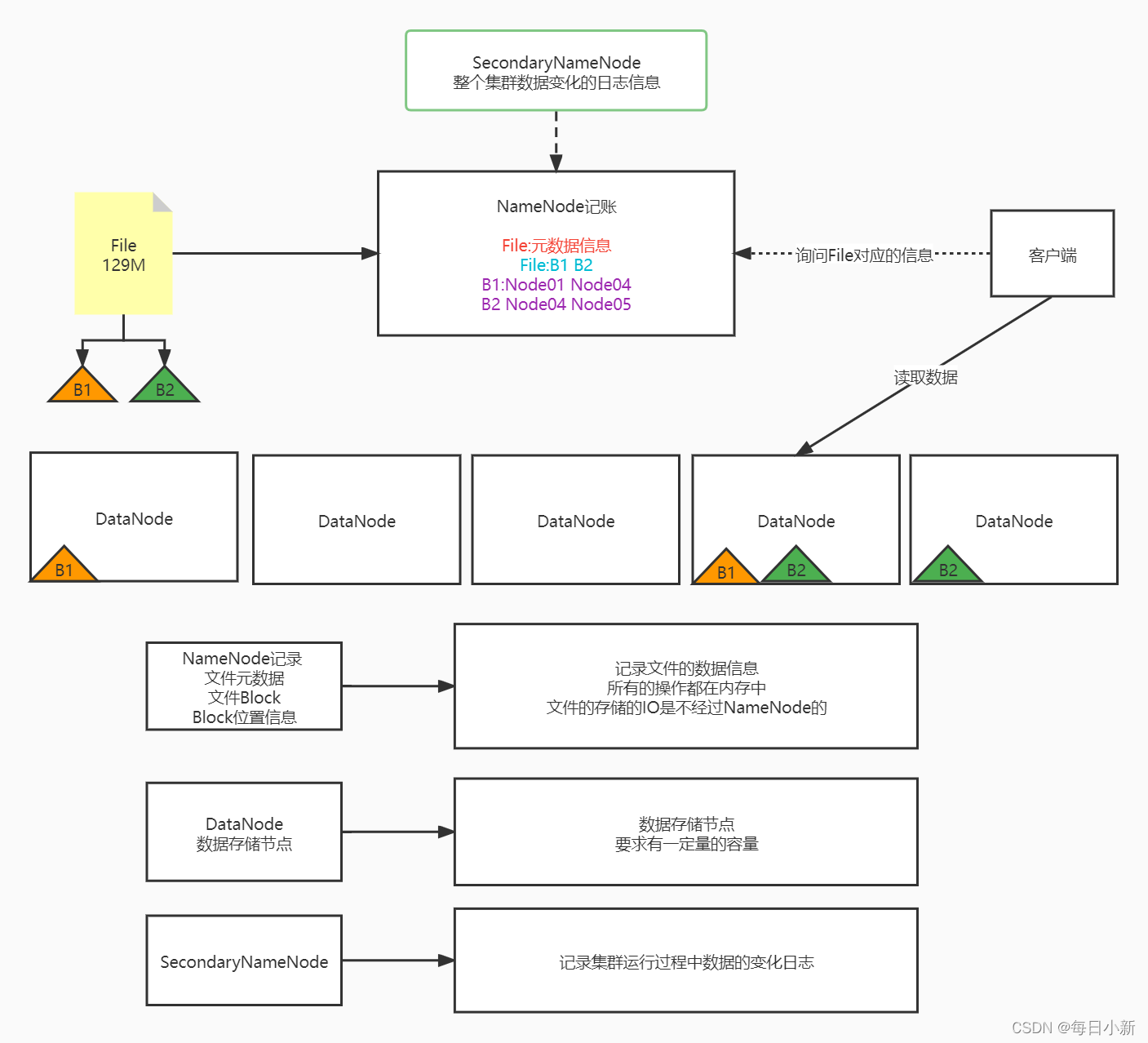
- NameNode 6 記賬,記錄元資料資訊,以及每個塊位置資訊(映射資訊),所有操作都在記憶體中,NameNode不負責IO操作,只提供地址
- NameNode安全問題:一但損壞則找不到block,故SencondaryNameNode記錄整個集群資料變化的日志資訊
塊的管理方式
2、HDFS資料分類
- 檔案
- 元資料:描述檔案大小,權限,時間,所有者,副本數,快的大小,檔案與檔案快可以不同,
- 真實資料:即檔案存放二進制在計算機上
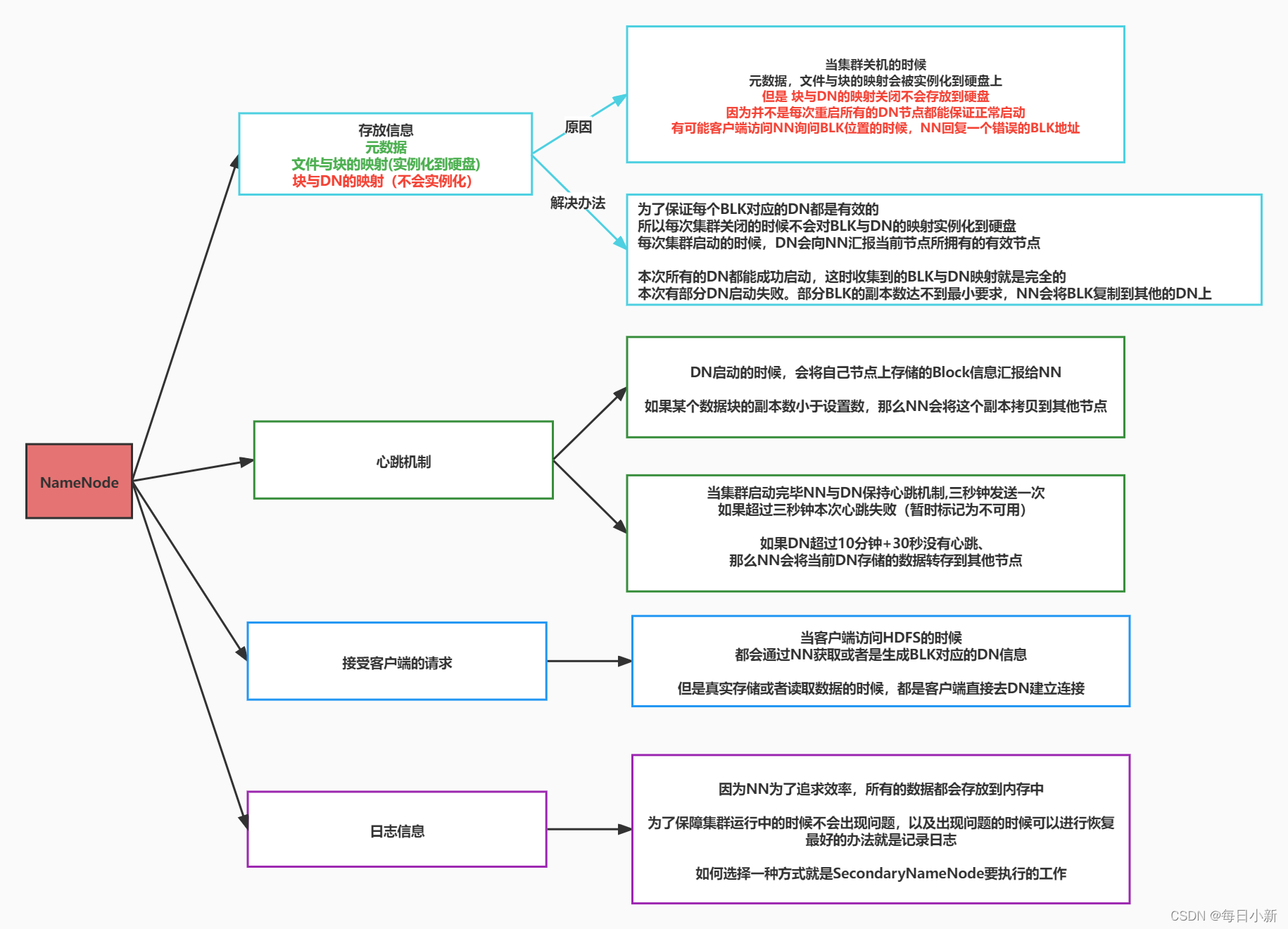
- 節點:
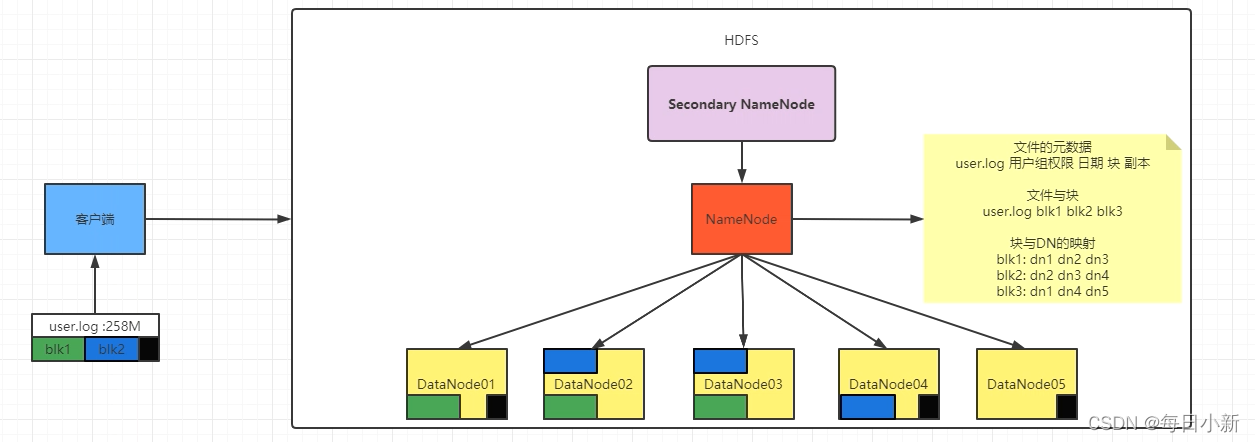
- NameNode:元素據,檔案與塊的映射,特殊點:集群關機時,源資料檔案和塊的映射會被實體化到硬碟上,但塊與資料映射關閉不會存放到硬碟
- 導致節點丟失(防止:啟動進入安全模式,不允許客戶端對服務查詢)
- 為了保證每個BLK都是有效的,所以每次關閉步進行實體化到硬碟
- NamNode:心跳機制–DN,每三秒發送一次,當集群啟動完畢后保持心跳,超過3秒則失敗(暫時標記不可用)10分鐘+30秒后則轉移資料
- 接受客戶請求:先去NN訪問獲取地址,再去DN獲取資料
- 日志資訊:保證集群中的時候不會出現問題以及問題出現的時候,存日志方式解決(Secondary NameNode)
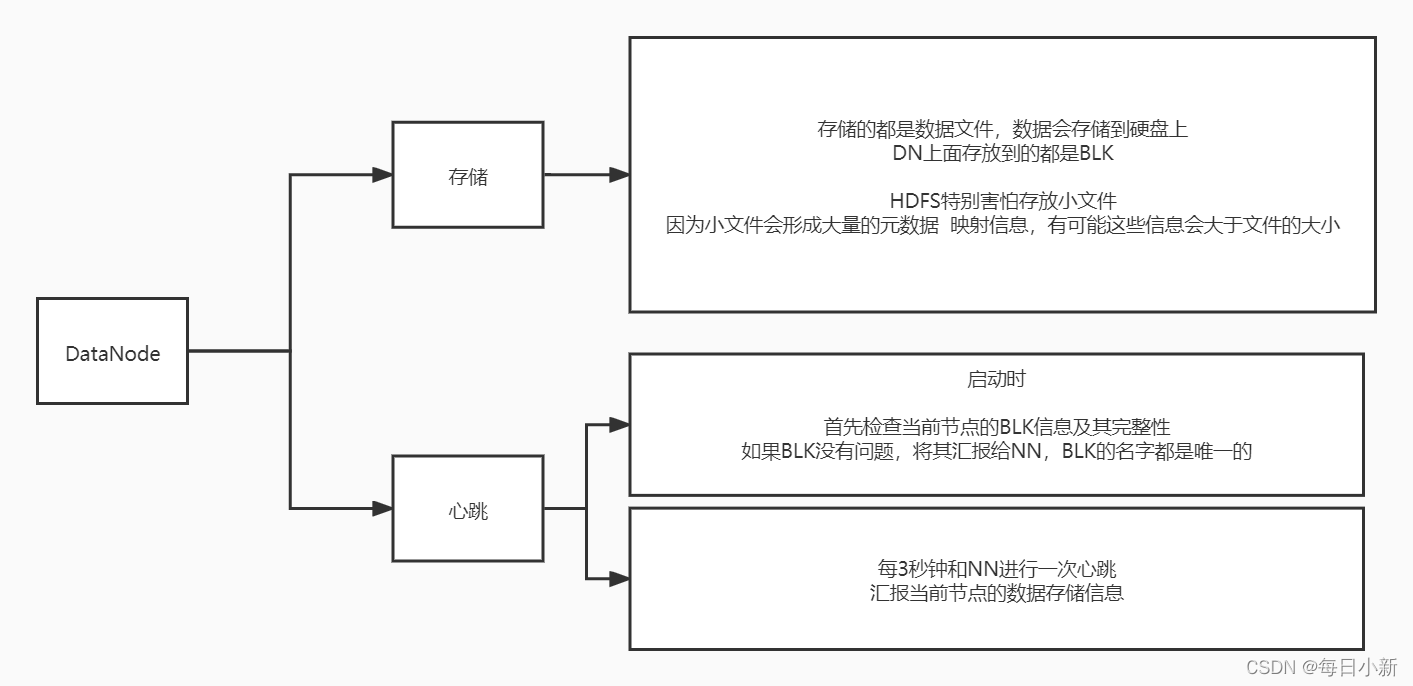
①、DataNode
- 存盤
- DN存的時BLK,害怕存放小檔案,因為小檔案會形成大量的元資料,映射資訊,有可能這些資訊會大于檔案的大小
- 心跳
- 啟動時,首先檢查當前節點的完整性,如果BLK沒問題,將其匯報給NN,BLK的名字都是唯一的
- 每3秒一次心跳匯報當前節點存盤資訊
②、NameNode
- 為了提高效率
- 所有的資料都會在記憶體中處理,安全問題掉電擦除,有可能資料丟>失,當正常關閉,序列化到硬碟,開啟則進行反序列化
- 所有的操作都存放日志(硬碟)當讀取資料的時候需要硬碟讀取,有可能速度不夠,關閉直接關閉即可,開啟需要從以往資料中尋找對應的請求
- 方案
- 同時兼顧效率和安全,放記憶體速度快,但怕斷電,所以每次依然會記錄日志,每次操作先記錄日志,在將資料修改到記憶體中,但用戶查詢的>時候優先使用記憶體
③、SencondaryNameNode
作用就是為了合并,fsimage:當前記憶體中檔案系統的快照(序列化)edits日志,合并Fsimage與Edits,
三、🍁搭建Hadoop集群
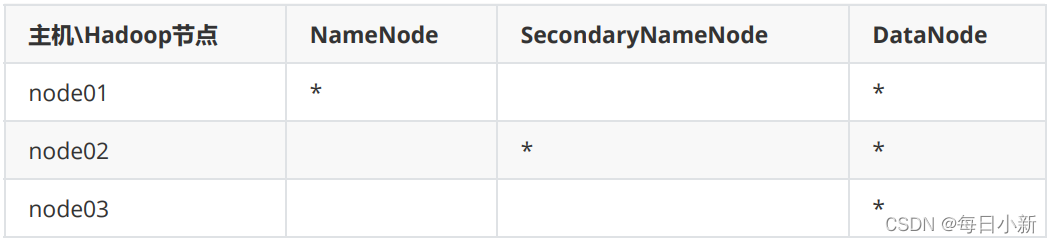
① 環境準備
#直接上傳安裝包
[root@node01 ~]# tar -zxvf hadoop-3.1.2.tar.gz
[root@node01 ~]# mv hadoop-3.1.2 /opt/yjx/
[root@node01 ~]# cd /opt/yjx/hadoop-3.1.2/etc/hadoop/
② 修改配置
[root@node01 hadoop]# vim hadoop-env.sh
##直接在檔案的最后添加
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
[root@node01 hadoop]# vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/yjx/hadoop/full</value>
</property>
[root@node01 hadoop]# vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node02:50091</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
[root@node01 hadoop]# vim workers
node01
node02
node03
③ 拷貝至node02、node03
[root@node02 ~]# scp -r root@node01:/opt/yjx/hadoop-3.1.2 /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/hadoop-3.1.2 /opt/yjx/
④ 配置環境變數
[root@node01 hadoop]# vim /etc/profile
# 添加 ,三個虛擬機都要配置
export HADOOP_HOME=/opt/yjx/hadoop-3.1.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 記得重繪配置組態檔
source /etc/profile
⑤ 格式化NameNode?測驗
# 先格式化,不要重復此操作
[root@node01 yjx]# hdfs namenode -format
# 啟動集群
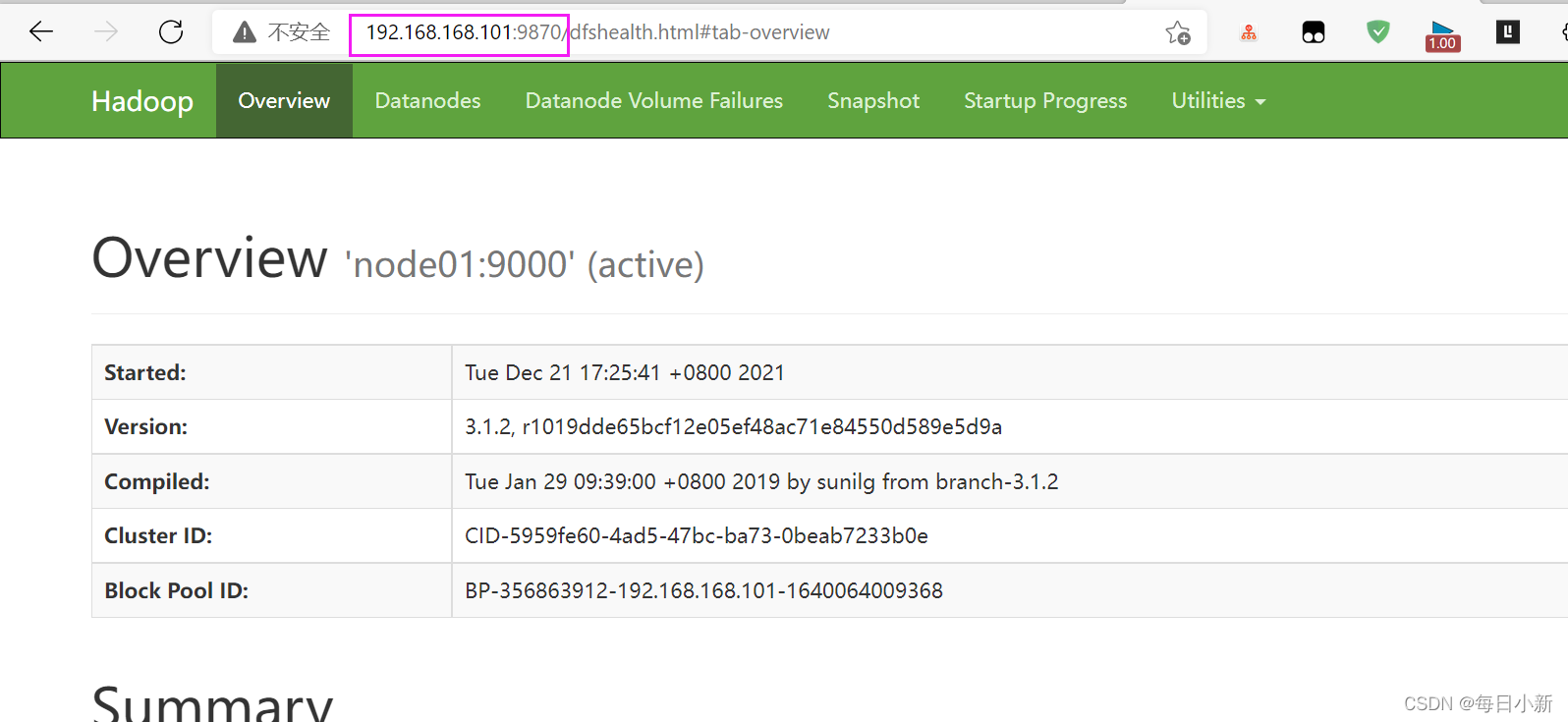
[root@node01 yjx]# start-dfs.sh
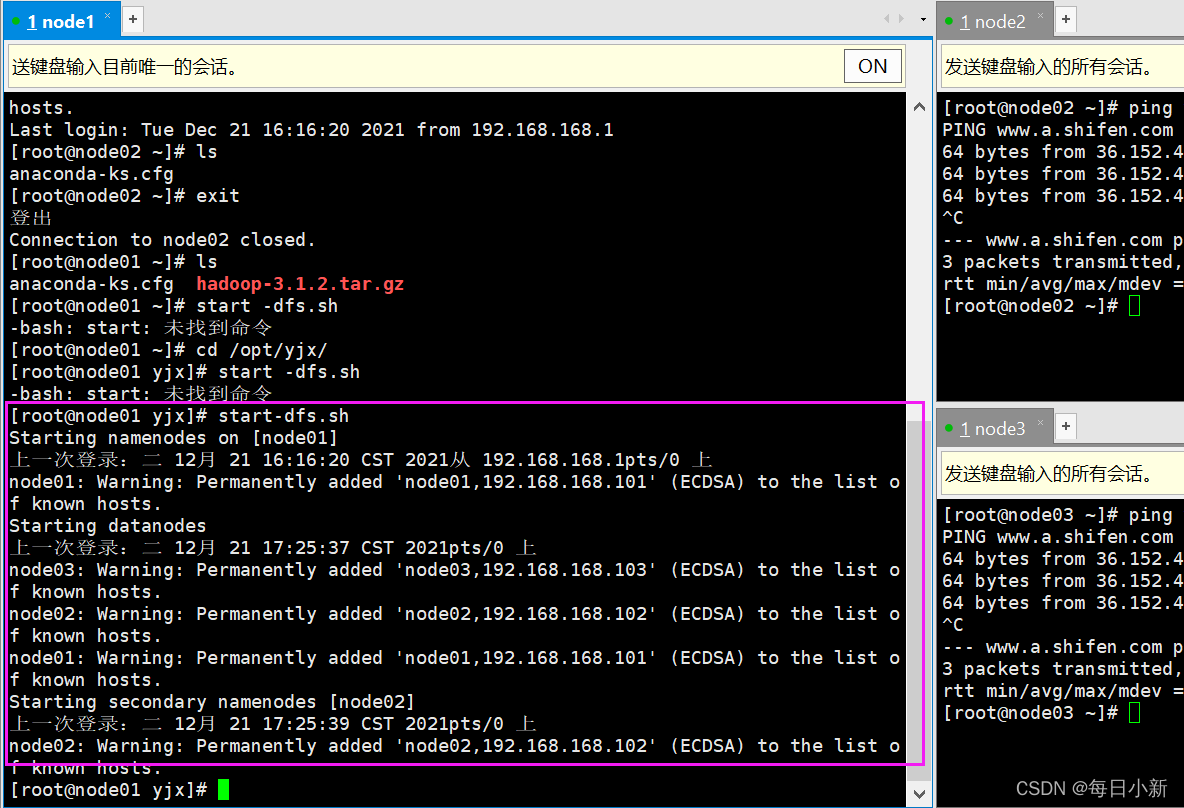
測驗:192.168.168.101:9870
常用命令:
# 創建檔案夾
[root@node01 ~]# hdfs dfs -mkdir -p /yjx
# 上傳檔案
[root@node01 ~]# hdfs dfs -put zookeeper-3.4.5.tar.gz /yjx/
# 下載檔案
[root@node01 ~]# hdfs dfs -D dfs.blocksize=1048576 -put zookeeper-3.4.5.tar.gz /yjx/
Hadoop的Shell命令
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
https://www.cnblogs.com/duanxz/p/3799467.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/389097.html
標籤:其他