目錄
專案解決方案
一、核心業務流程
1、快遞單
2、運單
3、干線運輸
二、邏輯架構
三、資料流轉
四、專案的技術選型
1、流式處理平臺
2、分布式計算平臺
3、海量資料存盤
五、框架軟體版本
六、技術亮點
七、服務器資源規劃
專案解決方案
一、核心業務流程
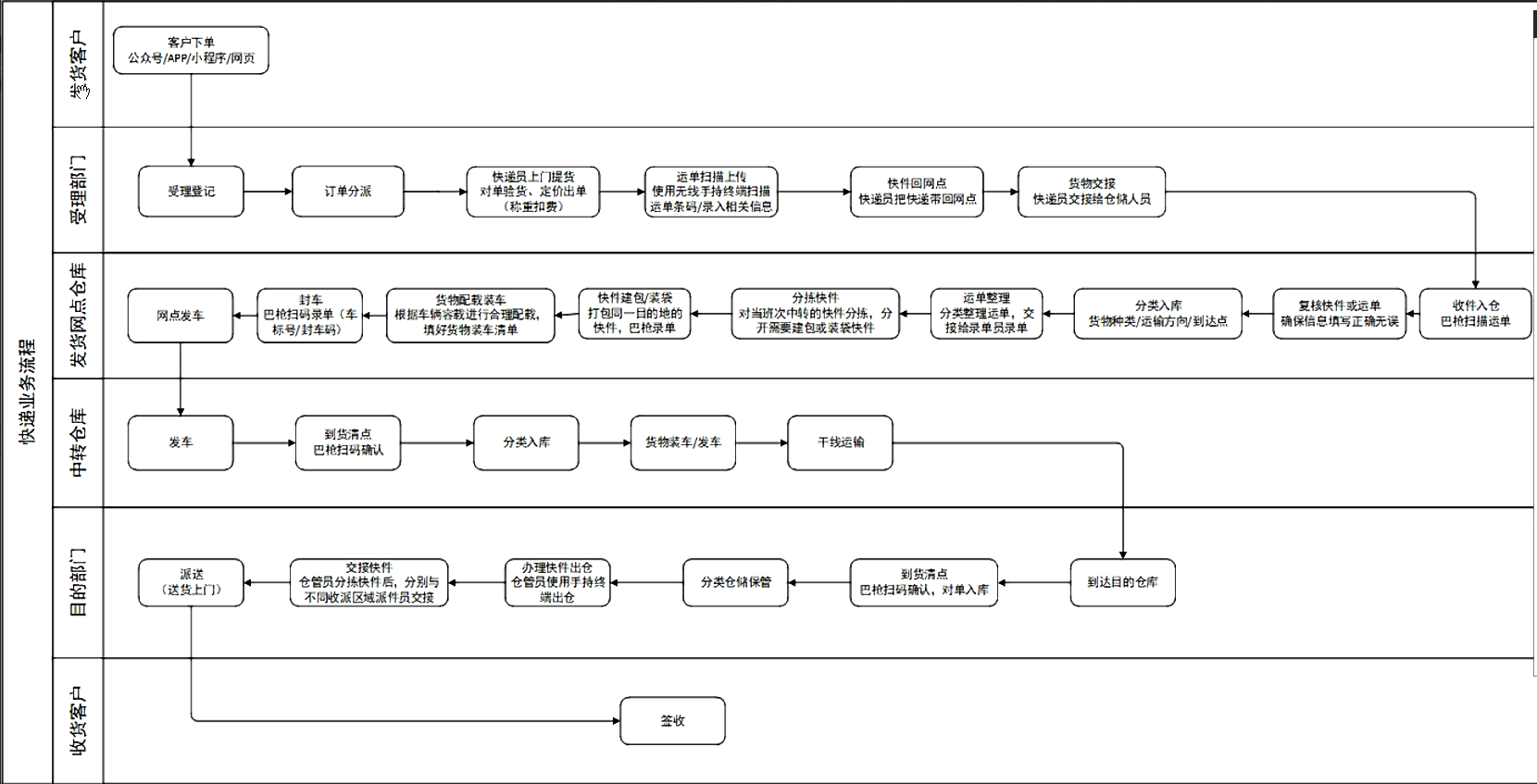
| 操作步驟 | 說明 |
| 1 | 客戶下單 |
| 客戶通過微信公眾號、微信小程式、App端、官網填寫訂單,并提交到物流公司的訂單管理系統OMS系統,如果通過電話方式下單,將對接到物流公司的呼叫中心,呼叫中心接線員根據客戶的描述,在OMS系統中填寫訂單資訊, | |
| 2 | 受理登記、訂單分派 |
| 快遞員收到通知后,聯系客戶,與客戶確認時間、確認要郵寄的貨物,快遞員上門取件,根據公司的規定,對客戶要郵件的貨物進行檢查、確認 | |
| 3 | 快遞員上門提貨 |
| 快遞員收到通知后,聯系客戶,與客戶確認時間、確認要郵寄的貨物,快遞員上門取件,根據公司的規定,對客戶要郵件的貨物進行檢查、確認 | |
| 4 | 運單掃描上傳 |
| 快遞員收到客戶要郵寄的物件后,進行稱重,根據要發往的目的地,進行計劃,并現場收費(預付款),列印運單憑證,并掃描運單上傳到物流公司OMS,運單會自動與訂單建立關聯, | |
| 5 | 快件回發貨網點 |
| 快遞員根據收派范圍收取快件后,統一將貨物運回發貨網點 | |
| 6 | 發貨網點貨物交接 |
| 快遞員將收到的貨物統一移交給倉庫管理員,倉庫管理員根據該快遞員收取的貨物逐一清點,確認貨物準確無誤,并依次錄單, | |
| 7 | 發貨網點收件入倉 |
| 倉庫管理員將快件進行檢查確認,放入到倉庫臨時存放區, | |
| 8 | 發貨網點運單復核 |
| 發貨物流網點倉庫管理員再次清點運單,確保運單與實物匹配, | |
| 9 | 發貨網點分類入庫 |
| 發貨物流網點倉庫管理員根據貨物的種類、運輸方向、到達點進行分類入庫, | |
| 10 | 發貨網點運單整理(電話下單、網點下單) |
| 發貨物流網點分類整理運單,并交接給錄單員錄單, | |
| 11 | 發貨網點分揀快件 |
| 對當班次中轉的快件分揀,分開需要建包或裝袋的快件 | |
| 12 | 發貨網點快件包裝 |
| 將統一目的地的快件,進行打包裝袋 | |
| 13 | 發貨網點配載裝車 |
| 倉庫管理員根據車輛容載進行合理配載,填好貨物裝車清單 | |
| 14 | 發貨網點封車 |
| 倉庫管理員進行掃碼錄單,需要將車牌號錄入到系統,并列印封車碼,貼上封條 | |
| 15 | 發貨網點發車,開始進入干線運輸 |
| 16 | 中轉物流網點清點 |
| 快遞車輛到達中轉物流網點后,中轉物流網點需要對車輛貨物進行清單,確保與運單對應的裝車清單貨物一致,給回單給發貨網點, | |
| 17 | 中轉物流網點分類入庫 |
| 18 | 貨物裝車/發車 |
| 19 | 干線運輸 |
| 20 | 到達目的倉庫 |
| 21 | 目的地網點到貨清點 |
| 目的地倉庫管理員通過巴槍掃碼確認,并回單給上一個中轉物流網點, | |
| 22 | 目的地網點分類倉庫保存 |
| 按照類似發貨方式分類入庫保存, | |
| 23 | 目的地網點辦理快件出倉、交接快件 |
| 在OMS系統中,系統根據派送區域分配快遞員,目的地倉庫管理員使用手持中轉辦理出倉,根據不同收派區域派送員交接, | |
| 24 | 目的地網點快遞員派送 |
| 目的地網點派送員送貨上門, | |
| 25 | 識訓客戶簽收 |
| 客戶簽識訓物 |
1、快遞單
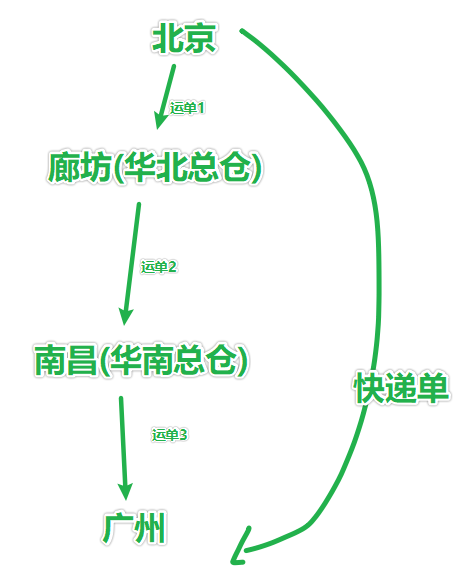
快遞單指的是 對貨物在從發貨到簽收的全生命流程中, 針對消費者端的一個唯一標記
2、運單
貨物在運輸的程序中 每一個環節所對應的 具體標記
因為快遞企業內部分了許多的小部門,分公司, 有管運輸 有管倉儲
不同部門和不同部門 或不同公司和公司之間 進行貨物傳輸的一個唯一標記
一個快遞單,從產生到結束, 中間會經過許多的運單
一個運單 會包含多個快遞單
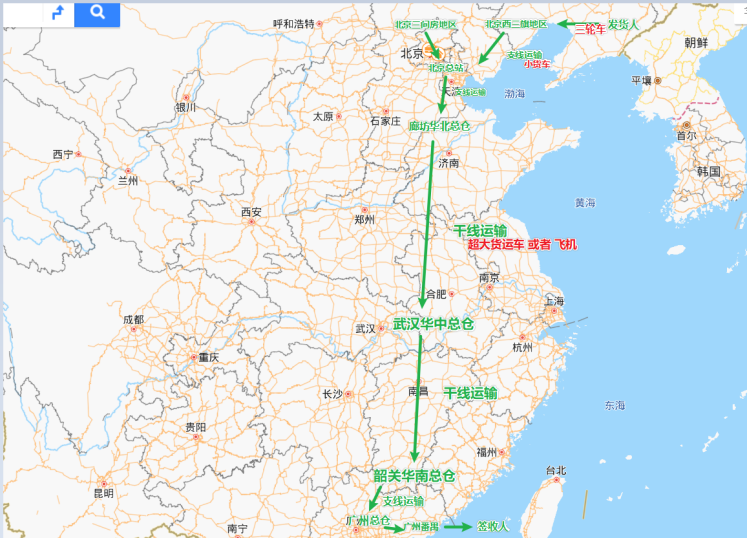
3、干線運輸
干線運輸指的是運輸的主干線, 在主干線上有最大的運力,一般快件的運行都是由支線去向主干線去匯集, 由主干線運輸過去
好處就是 經由 支線 和干線的運輸, 成本最低
二、邏輯架構
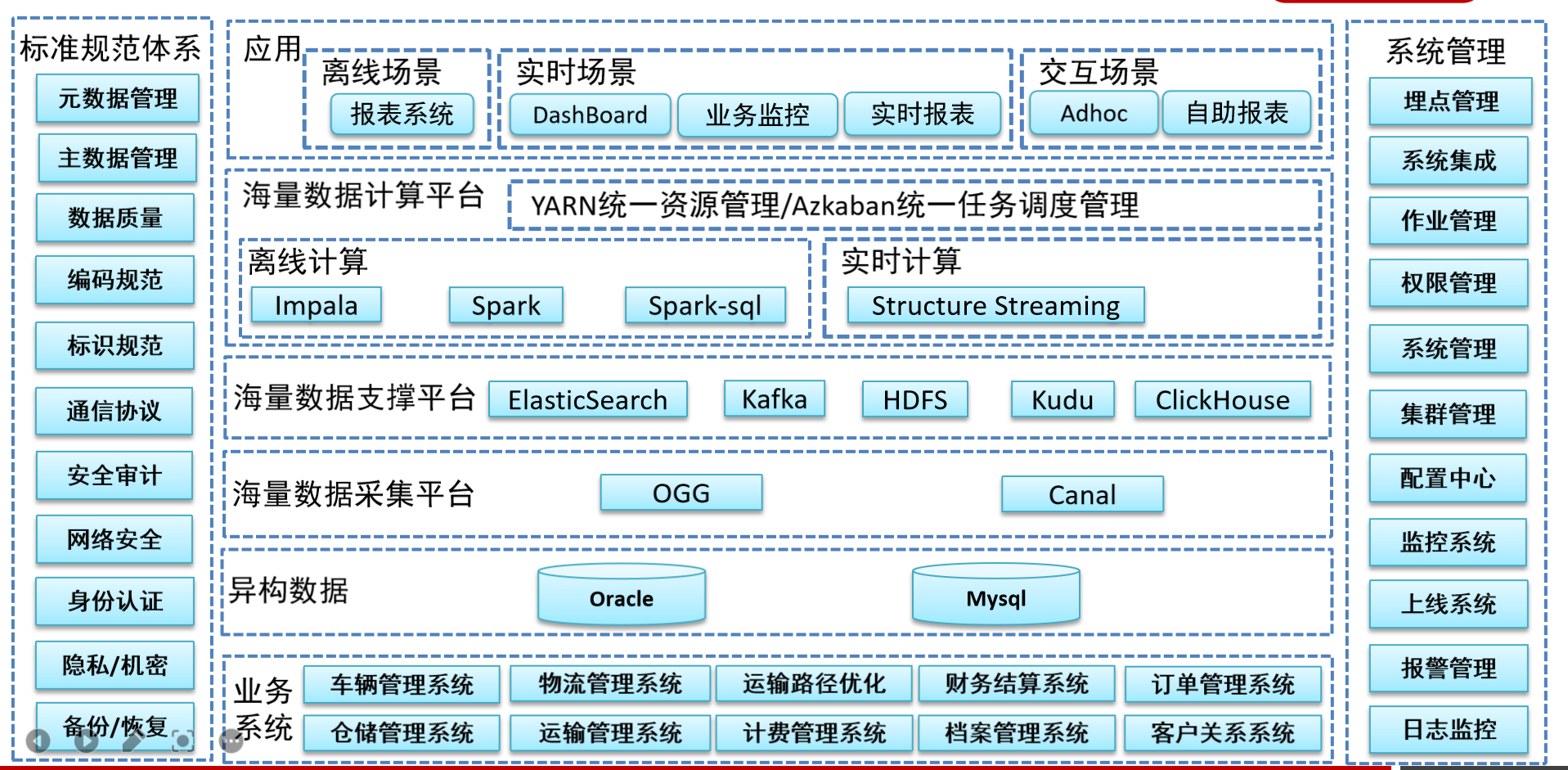
說明:
- 異構資料源
資料源主要有兩種方式:Oracle資料庫、MySQL資料庫
- 資料采集平臺
資料采集平臺負責將異構資料源采集到資料存盤平臺,分為批量匯入以及實時采集兩個部分:
| 實時采集 | Oracle資料庫采用ogg進行實時采集,MySQL資料庫采用Canal進行實時采集,采集到的資料會存放到訊息佇列臨時存盤中, |
- 資料存盤平臺
本次建設的物流大資料平臺存盤平臺較為豐富,因為不同的業務需要,存盤分為以下幾個部分:
| Kafka | 作為實時資料的臨時存盤區,方便進行實時ETL處理 |
| Kudu | 與Impala mpp計算引擎對接,支持更新,也支持大規模資料的存盤 |
| HDFS | 存盤溫資料、冷資料,大規模的分析將基于HDFS存盤進行計算, |
| ElasticSearch | 所有業務資料的查詢都將基于ElasticSearch來實作 |
| ClickHouse | 實時OLAP分析 |
- 資料計算平臺
資料計算平臺主要分為離線計算和實時計算,
| 離線計算 | Impala:提供準實時的高效率OLAP計算、以及快速的資料查詢 |
| Spark/ Spark-SQL:大批量資料的作業將以Spark方式運行 | |
| 實時計算 | 采用StructuredStreaming開發實時ETL業務 |
- 大資料平臺應用
| 離線場景 | 報表系統 |
| 小區畫像 | |
| 實時場景 | DashBoard |
| 業務監控 | |
| 實時報表 | |
| 互動查詢 | AdHoc(即席查詢) |
| 自助報表 |
三、資料流轉
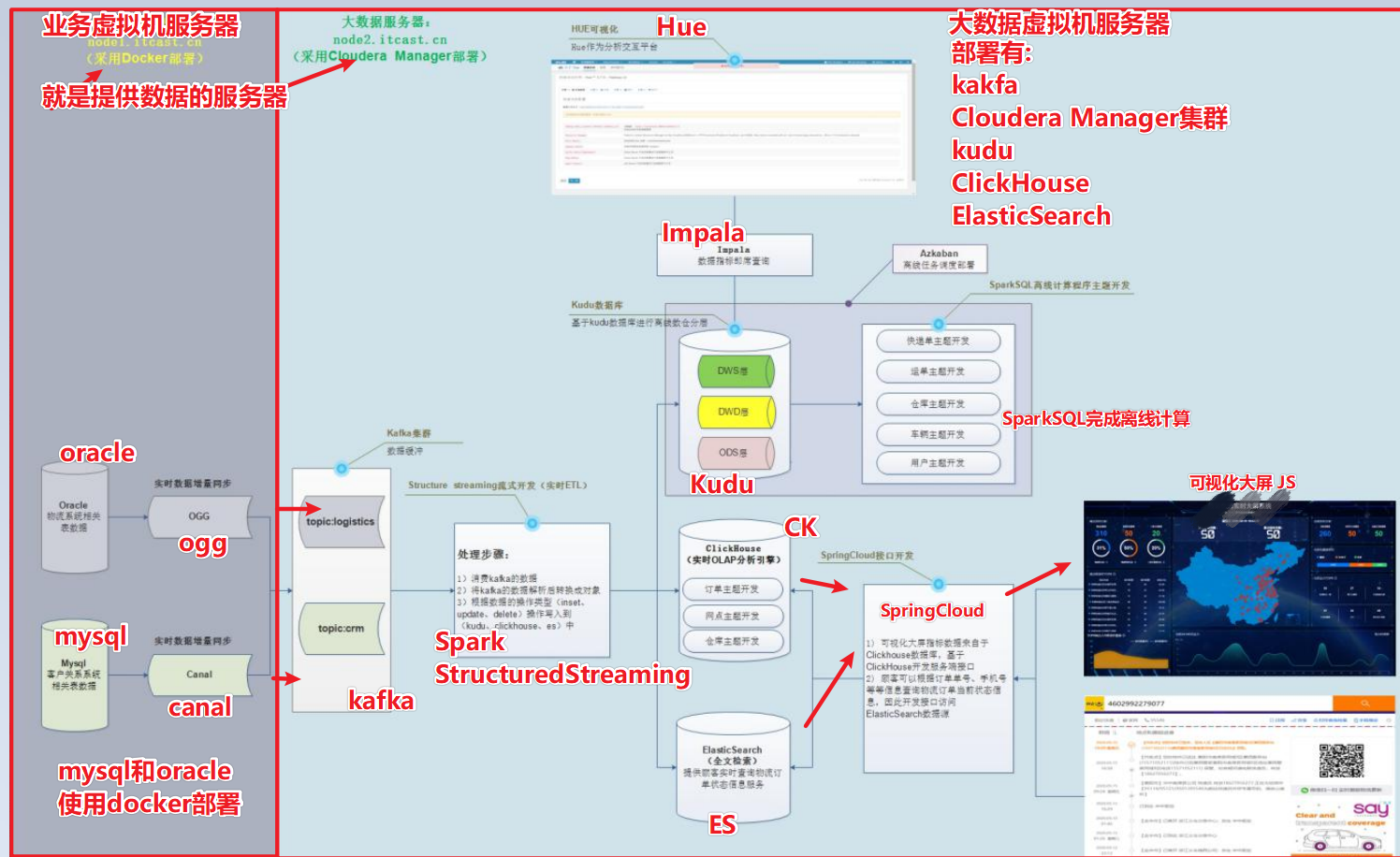
- 業務資料主要存放到Oracle和Mysql資料庫中
- OGG和Canal分別將Oracle和Mysql的增量資料同步到kafka集群,然后通過Structure Streaming程式進行實時ETL處理,將處理的結果寫入到Kudu資料庫中,供應用平臺進行分析處理
- 使用Spark與Kudu整合,進行一些ETL處理后,將資料匯入到Kudu中,方便進行資料的準實時分析、查詢,
- 為了將一些要求監控的業務實時展示,Structure Streaming流處理會將資料寫入到ClickHouse,Java Web后端直接將資料查詢出來進行展示,
- 為了方便業務部門對各類單據的查詢,Structure Streaming流式處理系統同時也將資料經過JOIN處理后,將資料寫入到Elastic Search中,然后基于Spring Cloud開發能夠支撐高并發訪問的資料服務,方便運營人員、客戶的查詢,
四、專案的技術選型
1、流式處理平臺
采用Kafka作為訊息傳輸中間介質(事件總線\訊息總線)
- kafka對比其他MQ的優點
| 可擴展 | Kafka集群可以透明的擴展,增加新的服務器進集群, |
| 高性能 | Kafka性能遠超過傳統的ActiveMQ、RabbitMQ等,Kafka支持Batch操作, |
| 容錯性 | Kafka每個Partition資料會復制到幾臺服務器,當某個Broker失效時,Zookeeper將通知生產者和消費者從而使用其他的Broker, |
- kafka對比其他MQ的缺點
| 重復訊息 | Kafka保證每條訊息至少送達一次,雖然幾率很小,但一條訊息可能被送達多次, |
| 訊息亂序 | Kafka某一個固定的Partition內部的訊息是保證有序的,如果一個Topic有多個Partition,partition之間的訊息送達不保證有序, |
| 復雜性 | Kafka需要Zookeeper的支持,Topic一般需要人工創建,部署和維護比一般MQ成本更高, |
- kafka對比其他MQ的使用場景
| Kafka | 主要用于處理活躍的流式資料,大資料量的資料處理上 |
| 其他MQ | 用在對資料一致性、穩定性和可靠性要求很高的場景,對性能和吞吐量還在其次,更適合于企業級的開發 |
- 總結
| 資料可靠性 | 延遲 | 單機吞吐 | 社區 | 客戶端 | |
| ActiveMQ | 中 | / | 萬級 | 不太活躍 | 支持全面 |
| RabbitMQ | 高 | 微秒級 | 萬級 | 活躍 | 支持全面 |
| Kafka | 高 | 毫秒級 | 十萬級 | 活躍 | 支持全面 |
| RocketMQ | 高 | 毫秒級 | 十萬級 | 有待加強 | 有待加強 |
2、???????分布式計算平臺
分布式計算采用Spark生態
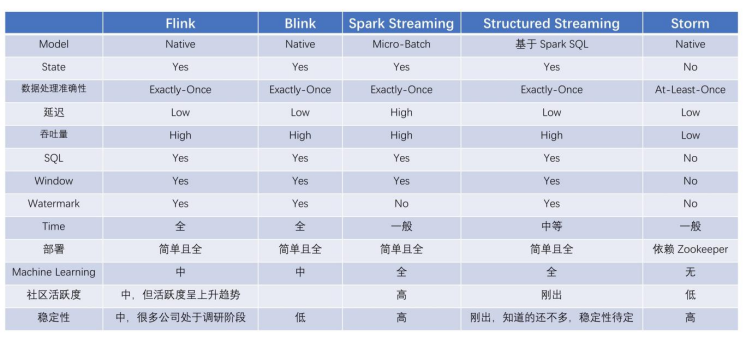
- 如果對延遲要求不高的情況下,可以使用 Spark Streaming,它擁有豐富的高級 API,使用簡單,并且 Spark 生態也比較成熟,吞吐量大,部署簡單,社區活躍度較高,從 GitHub 的 star 數量也可以看得出來現在公司用 Spark 還是居多的,并且在新版本還引入了 Structured Streaming,這也會讓 Spark 的體系更加完善,
- 如果對延遲性要求非常高的話,可以使用當下最火的流處理框架 Flink,采用原生的流處理系統,保證了低延遲性,在 API 和容錯性方面做的也比較完善,使用和部署相對來說也是比較簡單的,加上國內阿里貢獻的 Blink,相信接下來 Flink 的功能將會更加完善,發展也會更加好,社區問題的回應速度也是非常快的,另外還有專門的釘釘大群和中文串列供大家提問,每周還會有專家進行直播講解和答疑,
結論:
| 本專案使用Structured Streaming開發實時部分,同時離線計算使用到SparkSQL,而Spark的生態相對于Flink更加成熟,因此采用Spark開發 |
3、海量資料存盤
ETL后的資料存盤到Kudu中,供離線、準實時查詢、分析
Kudu是一個與hbase類似的列式存盤分布式資料庫
官方給kudu的定位是:在更新更及時的基礎上實作更快的資料分析
- Kudu對比其他列式存盤(Hbase、HDFS)
| HDFS | 使用列式存盤格式Apache Parquet,Apache ORC,適合離線分析,不支持單條紀錄級別的update操作,隨機讀寫性能差 |
| HBASE | 可以進行高效隨機讀寫,卻并不適用于基于SQL的資料分析方向,大批量資料獲取時的性能較差, |
| KUDU | KUDU較好的解決了HDFS與HBASE的這些缺點,它不及HDFS批處理快,也不及HBase隨機讀寫能力強,但是反過來它比HBase批處理快(適用于OLAP的分析場景),而且比HDFS隨機讀寫能力強(適用于實時寫入或者更新的場景),這就是它能解決的問題, |
HBase和Kudu這一類的資料庫, 不是用來做計算的, 而是做`高吞吐存取`的作用
比如:有一個非常復雜的業務查詢
- 用SQL寫
- SELECT * 后 用代碼處理
不管是OLAP還是OLTP 都是2最好
Elastic Search作為單據資料的存盤介質,供顧客查詢訂單資訊
- Elastic Search的使用場景
ES是一個檔案型的NoSQL資料庫, 特點是: 全文檢索
| 記錄和日志分析 | 圍繞Elasticsearch構建的生態系統使其成為最容易實施和擴展日志記錄解決方案之一,利用這一點來將日志記錄添加到他們的主要用例中,或者將我們純粹用于日志記錄, |
| 采集和組合公共資料 | Elasticsearch可以靈活地接收多個不同的資料源,并能使得這些資料可以管理和搜索 |
| 全文搜索 | 非常強大的全文檢索功能,方便顧客查詢訂單相關的資料 |
| 事件資料和指標 | Elasticsearch還可以很好地處理時間序列資料,如指標(metrics )和應用程式事件 |
| 資料可視化 | 憑借大量的圖表選項,地理資料的平鋪服務和時間序列資料的TimeLion,Kibana是一款功能強大且易于使用的可視化工具,對于上面的每個用例,Kibana都會處理一些可視化組件, |
ClickHouse作為實時資料的指標計算存盤資料庫
- ClickHouse與其他的OLAP框架的比較
| 商業OLAP資料庫 | 例如:HP Vertica, Actian the Vector, |
| 云解決方案 | 例如:亞馬遜RedShift和谷歌的BigQuery |
| Hadoop生態軟體 | 例如:Cloudera Impala, Spark SQL, Facebook Presto , Apache Drill ClickHouse支持實時的高并發系統 ClickHouse不依賴于Hadoop生態軟體和基礎 ClickHouse支持分布式機房的部署 |
| 開源OLAP資料庫 | 例如:InfiniDB, MonetDB, LucidDB |
| 開源分析 | 例如:Druid , Apache Kylin |
五、???????框架軟體版本
| Centos | 7.5 |
| Cloudera Manager | 6.2.1 |
| Hadoop | 3.0.0+cdh6.2.1 |
| ZooKeeper | 3.4.5+cdh6.2.1 |
| Kafka | 2.1.0+cdh6.2.1 |
| Scala | 2.11 |
| Spark | 2.4.0-cdh6.2.1 |
| Clickhouse | 0.22 |
| Oracle | 11g |
| Mysql | 5.7 |
| Canal | 1.1.2 |
| Kudu | 1.9.0+cdh6.2.1 |
| Azkaban | 3.71.0 |
| ElasticSearch | 7.6.1 |
| Impala | 3.2.0+cdh6.2.1 |
| HUE | 4.3.0+cdh6.2.1 |
| Spring Cloud | Hoxton.SR6 |
| NodeJS | 12.18.2 |
| VUE | 2.13.3 |
注意:
| 在專案實施中,框架版本選型盡可能不要選擇最新的版本,選擇最新框架半年前左右的穩定版本, |
六、???????技術亮點
- 完整Lambda架構系統,有離線業務、也有實時業務
- ClickHouse實時存盤、計算引擎
- Kudu + Impala準實時分析系統
- 基于Docker搭建異構資料源,還原企業真實應用場景
- 以企業主流的Spark生態圈為核心技術,例如:Spark、Spark SQL、structured Streaming
- ELK全文檢索
- Spring Cloud搭建資料服務
- 存盤、計算性能調優
七、服務器資源規劃
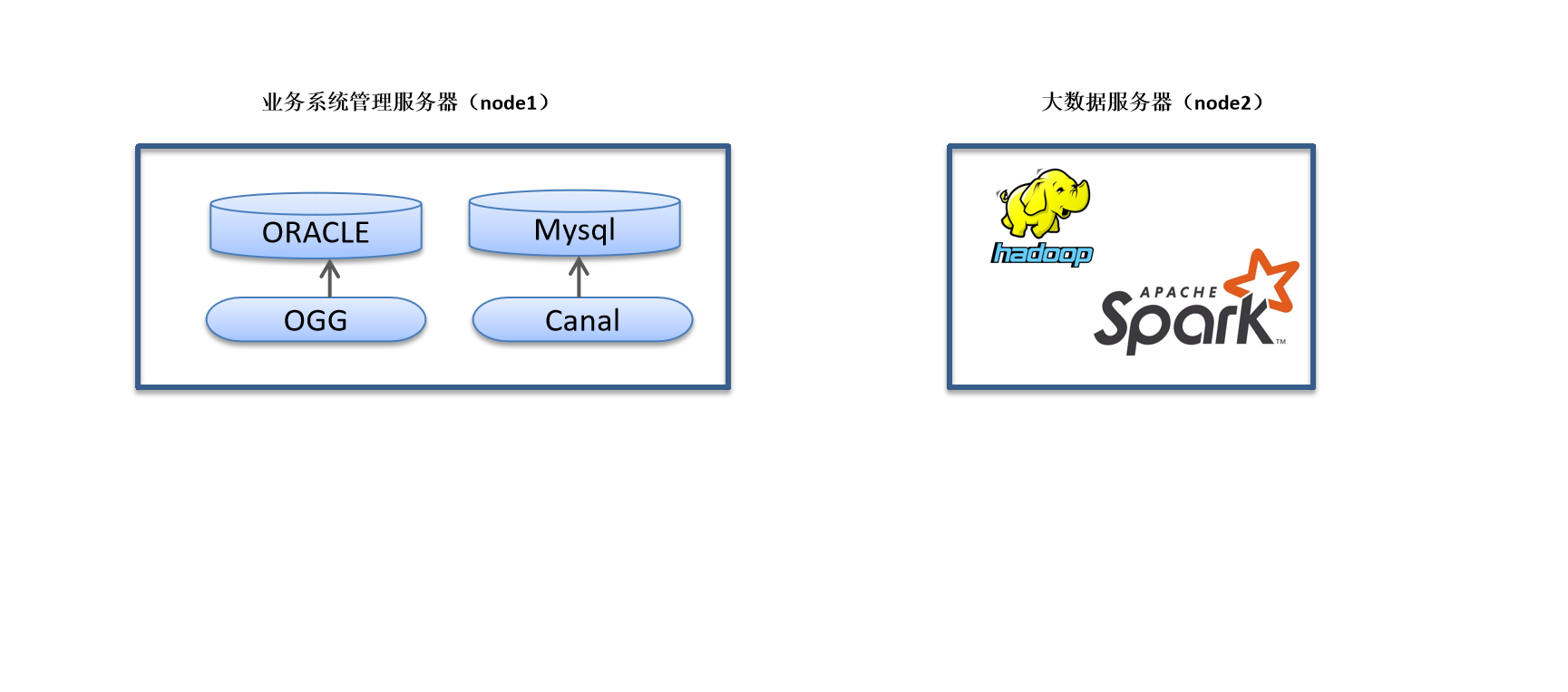
因服務器資源有限,該專案采用兩臺服務器進行演示,每臺服務器配置如下:
| 用途 | 主機名 | 作業系統/版本 | IP | 記憶體 | 硬碟 |
| 業務系統服務器 | node1 | Centos/7.5.1804 | 192.168.88.10 | 3GB | 40G |
| 大資料服務器 | node2 | Centos/7.5.1804 | 192.168.88.20 | 12GB | 60G |
使用到的軟體資訊:
| 服務器 | node1 | node2 |
| Docker | √ | |
| Oracle(11g) | √ | |
| OGG | √ | |
| MySql 5.7 | √ | |
| Canal | √ | |
| Hadoop | √ | |
| Spark | √ | |
| Kafka | √ | |
| ClickHouse | √ | |
| ElasticSearch | √ | |
| Kudu | √ | |
| Azkaban | √ | |
| Impala | √ | |
| HUE | √ |
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢大資料系列文章會每天更新,停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/389105.html
標籤:其他