我們在大學里肯定有過、周末不想待在寢室以及吃完飯后下午第四大節有課而又不想回到遙遠的寢室,這時候你就需要空教室,但一個一個的去找的話就太費時間了,所以就有了我們這次的專案,我們的專案只要輸入星期幾的第幾大節就可以查詢到那個時間的空教室,以及在這個基礎上我們添加了查詢班級課表的功能,可以查詢到其他班級的課表,主要運用到的技術就是scrapy加上selenium
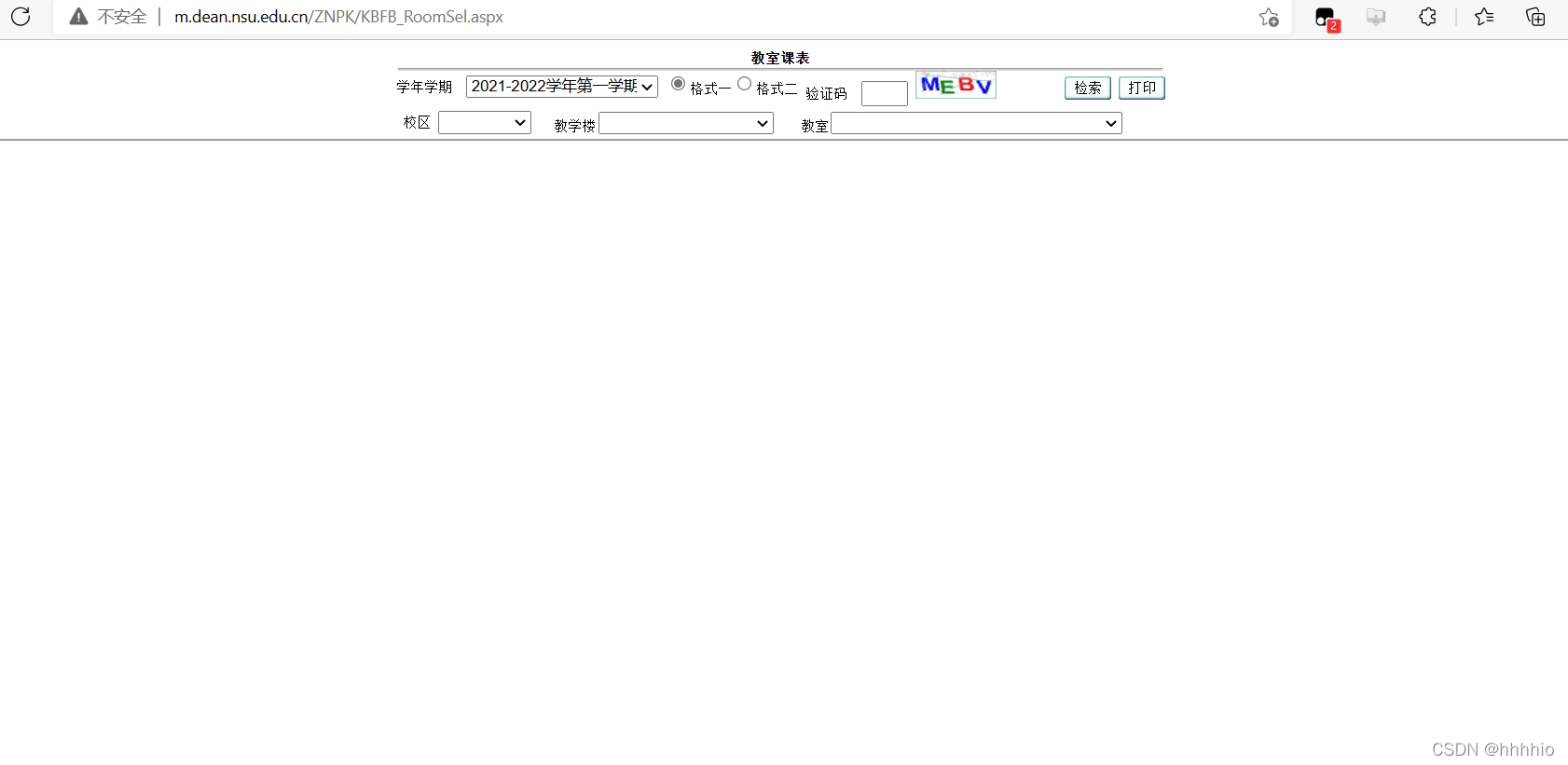
首先這是我們學校的課表
這是對于scrapy的爬蟲部件
import scrapy
from selenium import webdriver
from Class.items import ClassItem
import re
import time
class ClassplanSpider(scrapy.Spider):
name = 'ClassPlan'
#allowed_domains = ['www.xxx.com']
//校園網的地址
start_urls = ['http://m.dean.nsu.edu.cn/ZNPK/KBFB_RoomSel.aspx']
//對爬取資料進行決議
def parse(self, response):
//一天有著六節課,存盤資料時開始將其設為1
classNumber=1
//同理一周有七天
ClassWeek=1
base0=response.xpath('//*[@id="pageRpt"]/table[3]/tbody/tr[position()>1 and position()<8]')
Text=response.xpath('//*[@id="pageRpt"]/table[2]/tbody/tr/td/text()').extract()
if(Text!=[]):
text=Text[0]
index1 =text.find("房:")
index2=text.find("教")
JXL=text[index1 + 2:index2 - 2]
Room=text[index2+3:]
for j in base0:
base=j.xpath('./td[@ valign="top"]')
for i in base:
text=i.xpath('./text()').extract()
item=ClassItem()
item['classInfo']=text
classTime='星期'+str(ClassWeek)+'第'+str(classNumber)+'節課'
item['classTime']= classTime
item['classJXL']=JXL
item['classRoom']=Room
ClassWeek=ClassWeek+1
yield item
classNumber=classNumber+1
ClassWeek=1
yield scrapy.Request(url='http://m.dean.nsu.edu.cn/ZNPK/KBFB_RoomSel.aspx',dont_filter = True)
這是定義的item檔案
import scrapy
class ClassItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
classInfo=scrapy.Field()
classTime=scrapy.Field()
classJXL=scrapy.Field()
classRoom=scrapy.Field()
pass這是對于中間鍵的一些重定義
class SeleniumMiddleware(object):
def __init__(self):
self.chaojiying = Chaojiying_Client('hhhhio', 'sabercon110', '922661')
self.timeout = 50
# 2.Firefox---------------------------------
# 實體化引數物件
options = webdriver.FirefoxOptions()
self.JxlCount=12
self.RoomCount=1
# 無界面
options.add_argument('--headless')
# 關閉瀏覽器彈窗
options.set_preference('dom.webnotifications.enabled', False)
options.set_preference('dom.push.enabled', False)
# 打開瀏覽器
self.browser = webdriver.Firefox(firefox_options=options)
# 指定瀏覽器視窗大小
self.browser.set_window_size(1400, 700)
# 設定頁面加載超時時間
self.browser.set_page_load_timeout(self.timeout)
self.wait = WebDriverWait(self.browser, self.timeout)
def process_request(self, request, spider):
# 當請求的頁面不是當前頁面時
if self.browser.current_url != request.url:
# 獲取頁面
self.browser.get(request.url)
time.sleep(5)
else:
pass
self.browser.switch_to_default_content()
//對下拉選框,進行選擇
s1 = Select(self.browser.find_element_by_name("Sel_XQ"))
s1.select_by_visible_text("本校區")
s2 = Select(self.browser.find_element_by_name("Sel_JXL"))
s2.select_by_index(self.JxlCount)
s3 = Select(self.browser.find_element_by_name("Sel_ROOM"))
roomNum = len(s3.options)
print(roomNum)
if(roomNum==1):
s2.select_by_index(self.JxlCount+1)
s3 = Select(self.browser.find_element_by_name("Sel_ROOM"))
s3.select_by_index(self.RoomCount)
else:
s3.select_by_index(self.RoomCount)
input=self.browser.find_element_by_id('txt_yzm')
text=self.browser.find_element_by_id('txt_yzm').get_attribute('value')
while(text==''):
image_element = self.browser.find_element_by_id('imgCode')
image_element.screenshot("image_element.png")
with open("image_element.png", 'rb') as f:
content = f.read()
# 測驗識別驗證碼
resp = requests.post("http://127.0.0.1:7788", data=content)
code = resp.json()["code"]
print(code)
input.send_keys(code)
text = self.browser.find_element_by_id('txt_yzm').get_attribute('value')
time.sleep(5)
search = self.browser.find_element_by_name("btnSearch")
time.sleep(5)
search.click()
//切換iframe
self.browser.switch_to_frame('frmRpt')
if(self.RoomCount<roomNum):
self.RoomCount=self.RoomCount+1
if(self.RoomCount==roomNum):
self.RoomCount=1
self.JxlCount=self.JxlCount+1
with open('ip.html','w',encoding="utf-8")as fp:
fp.write(self.browser.page_source)
# 回傳頁面的response
return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source,
encoding="utf-8", request=request)
def spider_closed(self):
# 爬蟲結束 關閉視窗
self.browser.close()
pass
@classmethod
def from_crawler(cls, crawler):
# 設定爬蟲結束的回呼監聽
s = cls()
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s重定義了init方法,在開始的時候運用selenium打開瀏覽器,在爬取前利用selenium選取校區,教學樓,教室等資料,將驗證碼放入三方網站,進行識別,當驗證碼為空時,填入驗證碼然后模擬點擊檢索

注意,獲得到的資料存在另一個iframe里面,要回傳html需要selenium先切換到這個iframe,在回傳結果后爬蟲檔案中定義的parse2進行決議
對于資料存盤方面的代碼
class mysqlPileLine(object):
conn = None
cursor= None
def open_spider(self,spider):
self.conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',password='123456',db='class',charset='utf8')
self.index=0
def process_item(self, item, spider):
self.cursor=self.conn.cursor()
self.index=self.index+1
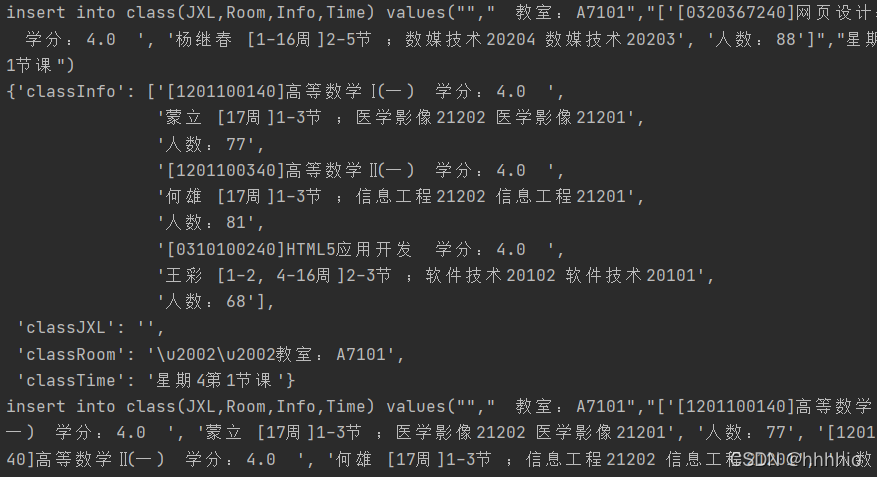
text=('insert into class(JXL,Room,Info,Time) values("%s","%s","%s","%s")'%(item["classJXL"],item["classRoom"],item["classInfo"],item["classTime"]))
print(text)
try:
self.cursor.execute(text)
self.cursor.connection.commit()
except Exception as e:
print(e)
self.conn.rollback()
def close_spider(self):
self.cursor.close()
self.conn.close()
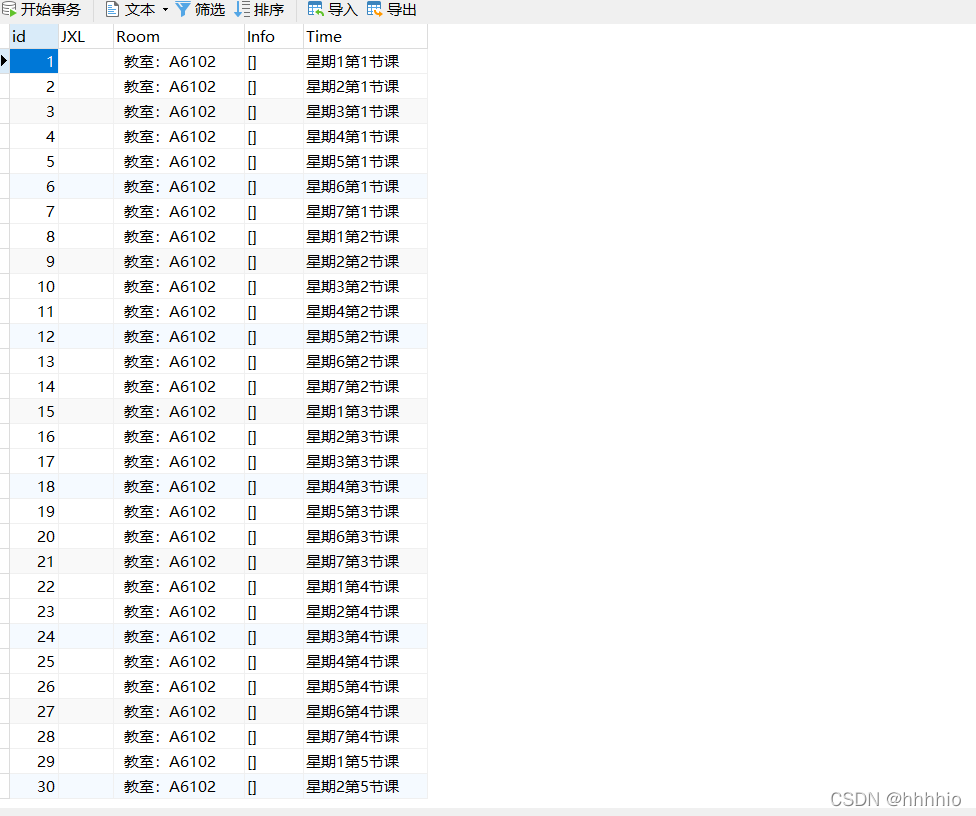
結果展示
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/389127.html
標籤:其他
上一篇:idea開發工具遠程鏈接Linux服務器進行檔案操作
下一篇:幾款好用的子域名收集工具