前言
在kubernets集群的每個節點上都運行著kube-proxy行程,負責實作Kubernetes中service組件的虛擬IP服務,目前kube-proxy有如下三種作業模式:
- User space 模式
- iptables 模式
- IPVS 模式
-
User space模式
在這種模式下,kube-proxy通過觀察Kubernetes中service和endpoint物件的變化,當有新的service創建時,所有節點的kube-proxy在node節點上隨機選擇一個埠,在iptables中追加一條把訪問service的請求重定向到這個埠的記錄,并開始監聽這個埠的連接請求,
比如說創建一個service,對應的IP:1.2.3.4,port:8888,kube-proxy隨機選擇的埠是32890,則會在iptables中追加
-A PREROUTING -j KUBE-PORTALS-CONTAINER -A KUBE-PORTALS-CONTAINER -d 1.2.3.4/32 -p tcp --dport 8888 -j REDIRECT --to-ports 32890KUBE-PORTALS-CONTAINER 是kube-proxy在iptable中創建的規則鏈,在PREROUTING階段執行
執行程序:
- 當有請求訪問service時,在PREROUTING階段,將請求jumpKUBE-PORTALS-CONTAINER
- KUBE-PORTALS-CONTAINER中的這條記錄起作用,把請求重定向到kube-proxy剛監聽的埠32890上,資料包進入kube-proxy行程內,
- 然后kube-proxy會從這個service對應的endpoint中根據SessionAffinity來選擇一個作為真實服務回應請求,
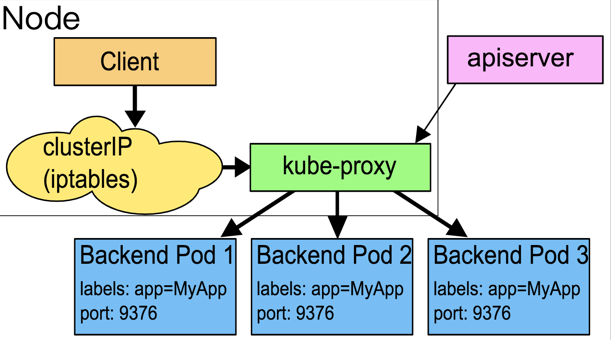
這種模式的缺點就是,請求資料需要到kube-proxy中,就是用戶空間中,才能決定真正要轉發的實際服務地址,性能會有損耗,并且在應用執行程序中,kube-proxy的可用性也會影響系統的穩定
-
iptables 模式(目前kube-proxy默認的作業模式)
在這種模式下,kube-proxy通過觀察Kubernetes中service和endpoint物件的變化,當有servcie創建時,kube-proxy在iptables中追加新的規則,對于service的每一個endpoint,會在iptables中追加一條規則,設定動作為DNAT,將目的地址設定成真正提供服務的pod地址;再為servcie追加規則,設定動作為跳轉到對應的endpoint的規則上,
默認情況下,kube-proxy隨機選擇一個后端的服務,可以通過iptables中的 -m recent 模塊實作session affinity功能,通過 -m statistic 模塊實作負載均衡時的權重功能
比如說創建了一個service,對應的IP:1.2.3.4,port:8888,對應一個后端地址:10.1.0.8:8080,則會在iptables中追加(主要規則):
-A PREROUTING -j KUBE-SERVICES -A KUBE-SERVICES -d 1.2.3.4/32 -p tcp –dport 8888 -j KUBE-SVC-XXXXXXXXXXXXXXXX -A KUBE-SVC-XXXXXXXXXXXXXXXX -j KUBE-SEP-XXXXXXXXXXXXXXXX -A KUBE-SEP-XXXXXXXXXXXXXXXX -p tcp -j DNAT –to-destination 10.1.0.8:8080KUBE-SERVICES 是kube-proxy在iptable中創建的規則鏈,在PREROUTING階段執行
執行程序:
- 當請求訪問service時,iptables在prerouting階段,將講求jump到KUBE-SERVICES,
- 在KUBE-SERVICES 中匹配到上面的第一條準則,繼續jump到KUBE-SVC-XXXXXXXXXXXXXXXX,
- 根據這條準則jump到KUBE-SEP-XXXXXXXXXXXXXXXX,
- 在KUBE-SEP-XXXXXXXXXXXXXXXX規則中經過DNAT動做,訪問真正的pod地址10.1.0.8:8080,
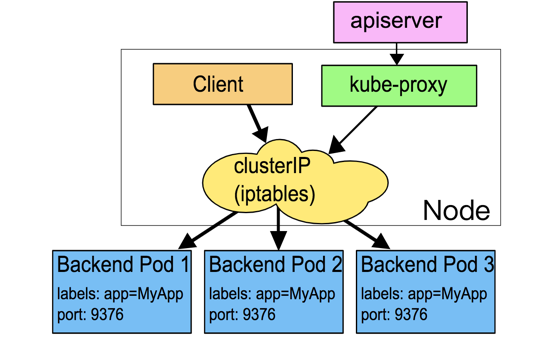
在這種邏輯下,資料轉發都在系統內核層面做,提升了性能,并且即便kube-proxy不作業了,已經創建好的服務還能正常作業 ,但是在這種模式下,如果選中的第一個pod不能回應,請求就會失敗,不能像userspace模式,請求失敗后kube-proxy還能對其他endpoint進行重試,
這就要求我們的應用(pod)要提供readiness probes功能,來驗證后端服務是否能正常提供服務,kube-proxy只會將readiness probes測驗通過的pod寫入到iptables規則中,以此來避免將請求轉發到不正常的后端服務中,
-
IPVS 模式
-
介紹
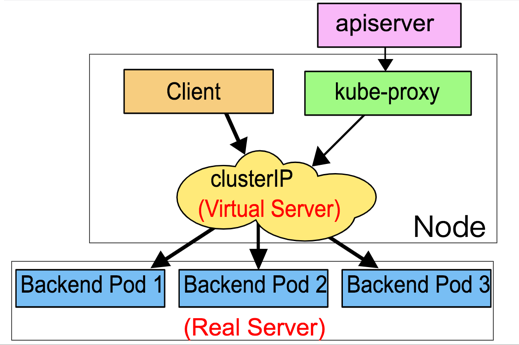
由于在iptables模式中,kube-proxy需要為每一個服務,每一個endpoint都生成相應的iptables規則,當服務規模很大時,性能也將顯著下降,因此kubernetes在1.8引入了IPVS模式,1.9版本中變成beta,在1.11版本中成為GA,在IPVS模式下,kube-proxy觀察Kubernetes中service和endpoint物件的變化,通過呼叫netlink介面創建相應的IPVS規則,并周期性的對Kubernetes的service、endpoint和IPVS規則進行同步,當訪問一個service時,IPVS負責選擇一個真實的后端提供服務,
IPVS模式也是基于netfilter的hook功能(INPUT階段),這點和iptables模式是一樣的,但是用的是內核作業空間的hash表作為存盤的資料結構,在這種模式下,iptables可通過ipset來驗證具體請求是否滿足某條規則,在service變成時,只用更新ipset中的記錄,不用改變iptables的規則鏈,因此可以保證iptables中的規則不會隨著服務的增加變多,在超大規模服務集群的情況下提供一致的性能效果,
在對規則進行同步時的性能也要高于iptables(只用對特定的一個hash表進行更新,而不是像iptables模式下對整個規則表進行操作),所以能提供更高的網路流量,
IPVS在對后端服務的選擇上也提供了更多靈活的演算法:
- rr: round-robin
- lc: least connection (最少連接數演算法)
- dh: destination hashing(目的hash演算法)
- sh: source hashing(原地址hash演算法)
- sed: shortest expected delay(最短延遲演算法)
- nq: never queue
-
kube-proxy啟用IPVS
由于IPVS的優勢,所以盡可能的采用IPVS作為kube-proxy的作業模式,通過以下步驟在創建集群時啟用IPVS
-
安裝依賴工具包
apt install -y ipvsadm ipset- ipset是IPVS作業時會用刀的工具包
- ipvsadm 是一個客戶端工具,可以讓我們和ipvs表的資料進行互動
-
kube-proxy啟用IPVS時依賴模塊:
ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack可通過如下命令檢查系統是否啟用了這些模塊
$ lsmod | grep -e ip_vs -e nf_conntrack如果沒有啟用,通過如下命令啟用
$ modprobe -- ip_vs $ modprobe -- ip_vs_rr $ modprobe -- ip_vs_wrr $ modprobe -- ip_vs_sh $ modprobe -- nf_conntrack -
kube-proxy組態檔中追加IPVS相關配置
proxy-mode: "ipvs" ipvs-min-sync-period: ipvs 規則重繪的最小時間間隔 ipvs-scheduler: ipvs的負載演算法(rr、lc等) ipvs-sync-period: ipvs規則重繪的最大時間間隔(30s)
采用用IPVS模式時,在啟動kube-proxy前必須要確保IPVS模塊在服務上存在,如果kube-proxy啟動時,經過驗證發現IPVS模塊不可用,kube-proxy自動采用iptables模式作業,參考代碼:server_others.go
在介紹kube-proxy如何使用IPVS實作對service的請求前,先看下IPVS的簡單介紹及作業原理
IPVS
-
介紹
IPVS是Linux服務器中用來實作LVS(Linux virtual service)的一個模塊,作業在內核空間是一種基于虛擬IP的負載均衡技術,通過用戶空間的ipvsadm來執行規則制定,常見術語稱 解釋 Real Server 后端請求處理服務器 P Client IP,客戶端IP P Director Virtual IP,負載均衡器虛擬IP P Director IP,負載均衡器IP P Real Server IP,后端處理請求的真實服務器IP -
作業原理
-
因為IPVS是hook到netfilter的input鏈中執行的,所以需要先了解下資料在netfilter中的流轉程序
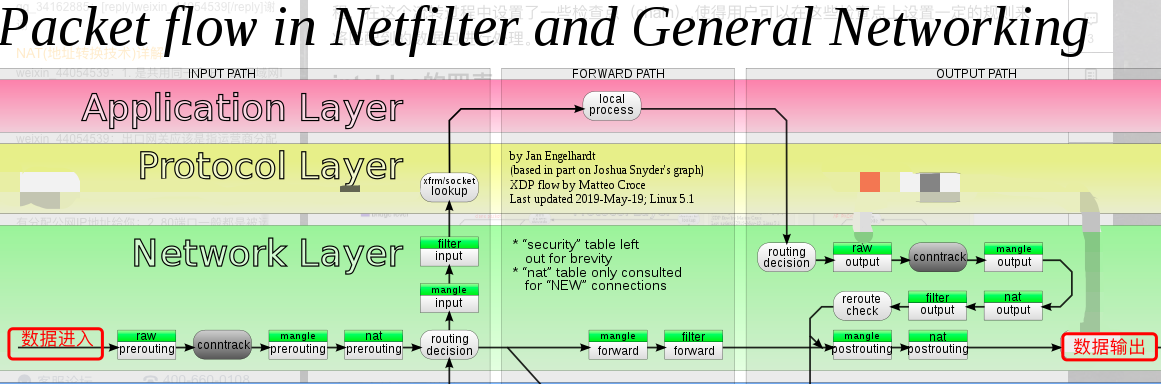
正常流程:
- 資料進入內核空間,到達PreRouting
- 進行路由決策
- 請求是發往本機的進入input
- 進入用戶空間處理
- 處理完進入output
- 進入postrouting
- 發送出去
- 請求不是本機的,進入forward
- 進入postrouting
- 發送出去
-
加入IPVS后的簡化邏輯圖
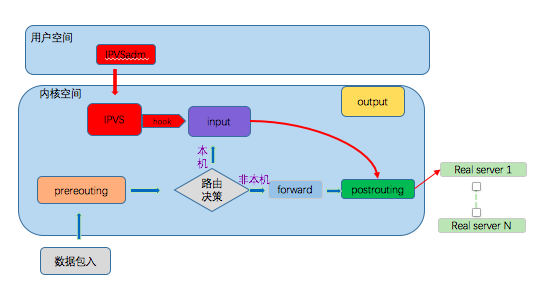
- 請求到達負載均衡器的內核空間時,到達PREROUTING鏈
- 當內核根據路由決策發現地址是本機時,將資料包送往INPUT鏈
- 資料包到達INPUT鏈時,首先會被IPVS檢查,如果請求的目的地址、埠資訊不在自己的hash表中時,資料正常發往用戶空間處理
- 如果hash表中的規則匹配到請求記錄,依據IPVS的作業模式,對請求頭中的資訊進行修改,之后直接交由POSTROUTING鏈執行
- POSTROUTING根據IPVS修改后的請求頭資訊(此時目的地址是真實的服務地址),通過路由表,用正確的設備將請求轉發出去
可以看到,當IPVS模塊作業后,在input鏈上會再次對請求做匹配,匹配到的直接做postrouting,不再進入用戶空間處理,而是把請求發送到IPVS選中的提供真實服務的服務器
-
IPVS有三種作業模式NAT(Masq)、DR、TUN,因為kube-proxy采用的是NAT模式,所以下面只對NAT模式進行分析
NAT:Network Address Transition(網路地址轉換),作業在此模式下的IPVS,首先根據scheduler策略選擇一個真實的后端服務,接著將請求頭中的目的地址IP、埠轉換成真實服務的IP和埠,之后進入POSTROUTING,向真實的服務器發起請求,當回應資料回傳時,再通過masqreade,將回傳資料的源地址修改成虛擬服務器的地址,具有有如下特性:
-
Real Server應該使用私有ip地址,和client IP不在一個網段中(如果在一個網段中,real Server可以將資料直接回傳客戶端,不會再經過Director Server回傳)
-
一般Real Server的網關應該指向DIP,不然的話無法保證回應報文經過Director Server(IP 協議,資料發送給不在同一個網段的服務器時,會把資料發送給網關)
-
RIP要和DIP應該在同一網段內
-
進出的報文,無論請求還是回應都要經過Directory server(滿足上面三點,這個是自然而然的)
-
支持埠映射
-
Real Server可以使用任意系統,只要埠對應即可
其流程如下:
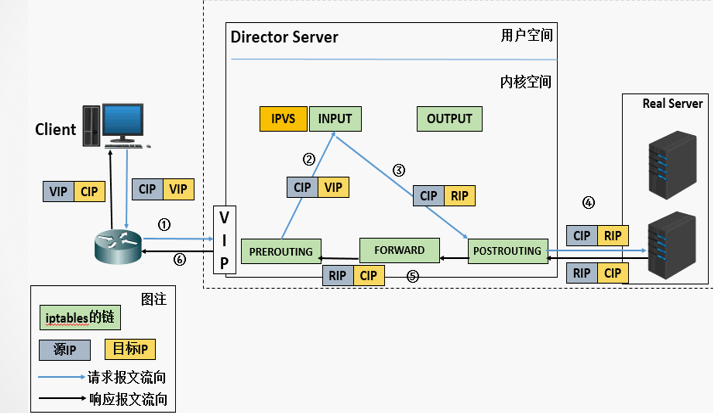
-
當用戶請求到達DirectorServer,此時請求的資料報文會先到內核空間的PREROUTING鏈, 此時報文的源IP為CIP,目標IP為VIP ,
-
PREROUTING檢查發現資料包的目標IP是本機,將資料包送至INPUT鏈,
-
IPVS比對資料包請求的服務是否為集群服務,若是,修改資料包的目標IP地址為后端服務器IP,然后將資料包發至POSTROUTING鏈, 此時報文的源IP為CIP,目標IP為RIP ,在這個程序完成了目標IP的轉換,
-
POSTROUTING鏈通過選路,將資料包發送給Real Server,
-
Real Server比對發現目標為自己的IP,開始構建回應報文, 此時報文的源IP為RIP,目標IP為CIP ,
-
因為Real Server的網關指向DIP,并且通常情況下CIP和RIP不在同一個網段內,在這種情況下,Real Server會先將資料發送給Director Server(網關),這樣資料就可以沿原路回傳,
-
Director Server在回應客戶端前,此時會將源IP地址修改為自己的VIP地址,然后回應給客戶端, 此時報文的源IP為VIP,目標IP為CIP,
-
在此程序中CIP一直是不發生變化的
-
-
kube-proxy如何使用IPVS
-
從IPVS的作業原理上可以知道,kube-proxy想使用IPVS,需要完成以下幾個作業
- 需要路由決策判斷要訪問的service的VIP屬于本機,否則,資料不經過input,直接forward出去,IPVS就沒有機會作業了
- iptables中的規則需要允許對service請求通過,否則資料被過濾掉也不會經過IPVS
- IPVS要能夠判斷出訪問的service服務是屬于集群服務
- IPVS要能夠根據service服務對應的VIP,找到真實的服務,之后修改請求頭,向真實的服務發送請求
- 由于在kubernetes下作業的IPVS,不一定滿足經典的NAT模式的特性,所以資料回傳路徑不一定和請求路徑一致,會出現Real Server直接回傳資料給客戶端的情況
-
為了讓node節點識別對應的VIP,kube-proxy啟動時創建了一個虛擬網路設備kube-ipvs0,型別是dummy,并把service的VIP都設定到這個設備下面,創建這個設備,以及向設備中追加VIP的邏輯都在代碼proxier.go中
$ ip addr 27: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether ba:6b:cb:b9:61:89 brd ff:ff:ff:ff:ff:ff inet 10.254.0.1/32 brd 10.254.0.1 scope global kube-ipvs0 valid_lft forever preferred_lft forever inet 10.254.0.2/32 brd 10.254.0.2 scope global kube-ipvs0 valid_lft forever preferred_lft forever inet 10.254.199.160/32 brd 10.254.199.160 scope global kube-ipvs0 valid_lft forever preferred_lft forever對應的service
$ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default clientip ClusterIP 10.254.199.160 <none> 8080/TCP 23h default kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 25d kube-system kube-dns ClusterIP 10.254.0.2 <none> 53/UDP,53/TCP,9153/TCP 23d kube-system kubelet ClusterIP None <none> 10250/TCP 18d可以看到所有的VIP都在kube-ipvs0這個設備下面
-
為了讓iptables中的規則允許對Servcie的請求通過,kube-proxy在iptables中追加了如下幾條主要規則(iptables.masqueradeAll=false;clusterCIDR=172.30.0.0/16,clusterCIDR就是集群中的pod能分配的IP地址段):
-
NAT表中:
$ iptables -t nat -nL Chain PREROUTING (policy ACCEPT) target prot opt source destination KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */ Chain OUTPUT (policy ACCEPT) target prot opt source destination KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */ Chain POSTROUTING (policy ACCEPT) target prot opt source destination KUBE-POSTROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */ Chain KUBE-MARK-MASQ (3 references) target prot opt source destination MARK all -- 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000 Chain KUBE-POSTROUTING (1 references) target prot opt source destination MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ mark match 0x4000/0x4000 MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 match-set KUBE-LOOP-BACK dst,dst,src Chain KUBE-SERVICES (2 references) target prot opt source destination KUBE-MARK-MASQ all -- !172.30.0.0/16 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst有兩點需要解釋下
-
關于規則
KUBE-MARK-MASQ all -- !172.30.0.0/16 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst意思是對于非集群內的pod訪問集群的cluster IP時會執行masquerade,這是因為在kube-proxy的啟動條件設定成了iptables.masqueradeAll=false;clusterCIDR=172.30.0.0/16才這樣
如果設定成iptables.masqueradeAll=false;clusterCIDR=,即不設定CIDR規則會變成
KUBE-MARK-MASQ all -- 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP src,dst效果應該是對自己訪問自己的請求做masquerade,其他請求都不做
如果iptables.masqueradeAll=true,規則變成
KUBE-MARK-MASQ all -- 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst效果對所有請求都做masquerade
-
關于匹配語法 -m set --match-set ,,, 代表用set模塊的對請求進行匹配
語法如下:
-m set --match-set name flags具體傳入的flags要依據 name指定的set的型別來傳入,具體ipset的用法可通過如下命令查看
ipset --help這里以KUBE-CLUSTER-IP為例
$ ipset --list KUBE-CLUSTER-IP Name: KUBE-CLUSTER-IP Type: hash:ip,port Revision: 5 Header: family inet hashsize 1024 maxelem 65536 Size in memory: 408 References: 2 Number of entries: 5 Members: 10.254.0.2,udp:53 10.254.0.1,tcp:443 10.254.0.2,tcp:9153 10.254.199.160,tcp:8080 10.254.0.2,tcp:53-
對應的型別資訊:Type: hash:ip,port
-
結合前面的規則
ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst表述的意思是請求的目的地址IP、目的埠和KUBE-CLUSTER-IP中的Members有匹配時,就接收請求
-
-
-
filter表中
$ iptables -nL -t filter Chain FORWARD (policy ACCEPT) target prot opt source destination KUBE-FORWARD all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes forwarding rules */ Chain OUTPUT (policy ACCEPT) target prot opt source destination KUBE-FIREWALL all -- 0.0.0.0/0 0.0.0.0/0 Chain KUBE-FIREWALL (2 references) target prot opt source destination DROP all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes firewall for dropping marked packets */ mark match 0x8000/0x8000 Chain KUBE-FORWARD (1 references) target prot opt source destination ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes forwarding rules */ mark match 0x4000/0x4000 ACCEPT all -- 172.30.0.0/16 0.0.0.0/0 /* kubernetes forwarding conntrack pod source rule */ ctstate RELATED,ESTABLISHED ACCEPT all -- 0.0.0.0/0 172.30.0.0/16 /* kubernetes forwarding conntrack pod destination rule */ ctstate RELATED,ESTABLISHED
通過分析kube-proxy追加的這些規則,可以看到訪問service提供的服務時,iptables中的規則最終都會允許請求通過,并且通過 -m set --match-set 的規則匹配機制,kube-proxy不用隨著servcie的創建和銷毀來修改iptables中的規則,只用修改對應的ipset中相應的Members就能夠達到效果,保證iptables的規則表固定大小,實作大規模服務集群中保持性能的穩定
-
-
請求通過了iptables中的規則后,在INPUT階段,需要IPVS來對請求進行判斷,看請求的服務是否屬于集群服務,是的話還要能找出正確的真實服務地址,這個kube-proxy如何實作呢
kube-proxy通過監聽API server,當有service創建時,通過呼叫系統的netlink 介面,將service和對應的endpoint插入到IPVS對應的hash表中,對應代碼在proxier.go中,用戶可以通過ipvsadm工具查看ipvs hash表中的資料
$ ipvsadm --list IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP promote.cache-dns.local:http rr -> master:6443 Masq 1 1 0 TCP promote.cache-dns.local:doma rr -> 172.30.78.2:domain Masq 1 0 0 TCP promote.cache-dns.local:9153 rr -> 172.30.78.2:9153 Masq 1 0 0 TCP promote.cache-dns.local:http rr -> 172.30.22.4:http-alt Masq 1 0 0 -> 172.30.78.4:http-alt Masq 1 0 0 UDP promote.cache-dns.local:doma rr -> 172.30.78.2:domain Masq 1 0 0因為啟用了DNS的cache功能,所以這個地方看到的service資訊是DNS快取資訊
通過上述幾個步驟后,kube-proxy就把需要使用IPVS的依賴條件都實作,就可以在請求到來時利用IPVS機制對請求進行轉發了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/38922.html
標籤:其他