前段時間因為店鋪不能開門,我花了一些空余時間看了很多機器學習相關的資料,我發現目前的機器學習入門大多要不門檻比較高,要不過于著重使用而忽視基礎原理,所以我決定開一個新的系列針對程式員講講機器學習,這個系列會從機器學習的基礎原理開始一直講到如何應用,看懂這個系列需要一定的編程知識(主要會使用 python 語言),但不需要過多的數學知識,并且對于涉及到的數學知識會作出簡單的介紹,因為我水平有限(不是專業的機器學習工程師),這個系列不會講的非常深入,看完可能也就只能做一個調參狗,各路大佬覺得哪些部分講錯的可以在評論中指出,
如果你沒有學過 python,但學過其他語言 (例如 Java 或 C#),推薦你看 Learn Python in Y Minutes,大約半天時間就能掌味訓礎語法(快的可能只需一個小時??),
- 英文版
- 中文版
機器學習的本質
在講解具體的例子與模型之前,我們先來了解一下什么是機器學習,在業務中我們有很多需要解決的問題,例如用戶提交訂單時如何根據商品串列計算訂單金額,用戶搜索商品時如何根據商品關鍵字得出商品搜索結果,用戶查看商品一覽時如何根據用戶已買商品計算商品推薦串列,這些問題都可以分為 輸入,操作,輸出,如下圖所示:
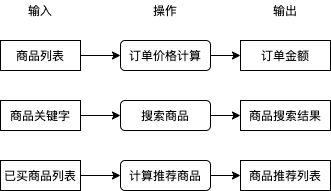
其中操作部分我們通常會直接撰寫程式代碼實作,程式代碼會查詢資料庫,使用某種演算法處理資料等,這些作業可能很枯燥,一些程式員受不了了就會自稱碼農,因為日復一日撰寫這些邏輯就像種田一樣艱苦和缺乏新意,你有沒有想過如果有一套系統,可以只給出一些輸入和輸出的例子就能自動實作操作中的邏輯?如果有這么一套系統,在處理很多問題的時候就可以不需要考慮使用什么邏輯從輸入轉換到輸出,我們只需提供一些例子這套系統就可以自動幫我們實作,
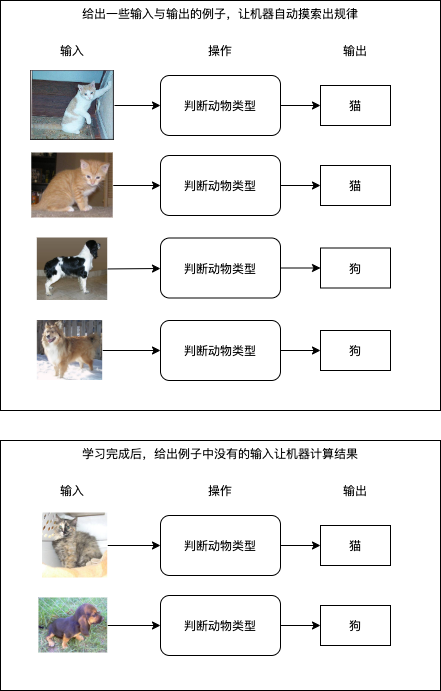
好訊息是這樣的系統是存在的,我們給出一些輸入與輸出的例子,讓機器自動摸索出它們之間的規律并且建立一套轉換它們的邏輯,就是所謂的機器學習,目前機器學習可以做到從圖片識別出物體類別,從圖片識別出文字,從文本識別出大概含義,也可以做到上圖中的從已買商品串列計算出推薦商品串列,這些操作都不需要撰寫具體邏輯,只需要準備一定的例子讓機器自己學習即可,如果成功摸索出規律,機器在遇到例子中沒有的輸入時也可以正確的計算出輸出結果,如下圖所示:
可惜的是機器學習不是萬能的,我們不能指望機器可以學習到所有規律從而實作所有操作,機器學習的界限主要有:
- 做不到 100% 的精度,例如前述的根據商品串列計算訂單價格要求非常準確,我們不能用機器學習來實作這個操作
- 需要一定的資料量,如果例子較少則無法成功學習到規律
- 無法實作復雜的判斷,機器學習與人腦之間仍然有相當大的差距,一些復雜的操作無法使用機器學習代替
到這里我們應該對機器學習是什么有了一個大概的印象,如何根據輸入與輸出摸索出規律就是機器學習最主要的命題,接下來我們會更詳細分析機器學習的流程與步驟,需要注意的是,不是所有場景都可以明確的給出輸入與輸出的例子,可以明確給出例子的學習稱為有監督學習 (supervised learning),而只給出輸入不給出輸出例子的學習稱為無監督學習 (unsupervised learning),無監督學習通常用于實作資料分類,雖然不給出輸出但是會按一定的規律控制學習的程序,因為無監督學習應用范圍不廣,這個系列講的基本上都是有監督學習,
機器學習的流程與步驟
我們先來了解一下機器學習的流程:
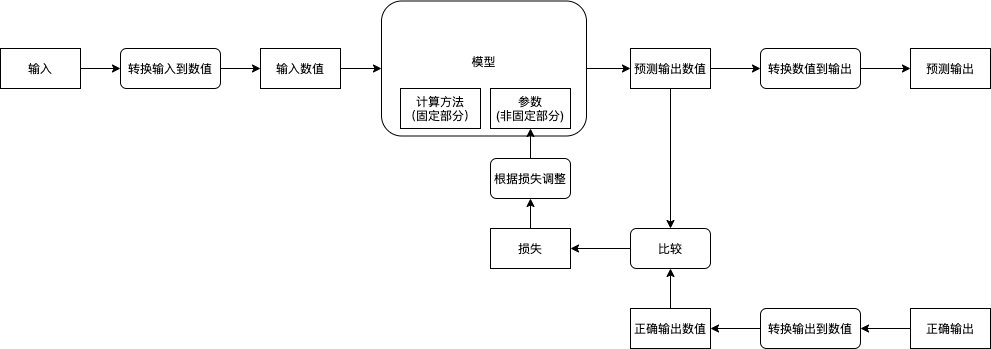
而實作機器學習需要以下的步驟:
- 收集輸入與輸出的例子
- 建立模型
- 確定輸入輸出與模型可接識訓傳的數值之間如何轉換
- 使用輸入與輸出的例子調整模型的引數
- 使用沒有參與訓練的輸入與輸出評價模型是否成功摸索出規律
收集輸入與輸出的例子
在開始機器學習之前我們需要先收集輸入與輸出的例子,收集到的例子又稱資料集 (Dataset),收集作業一般是個苦力活,例如學習從圖片判斷物體類別需要收集一堆圖片并手動對它們進行分類,學習從圖片識別文字需要收集一堆圖片并手動記錄圖片對應的文本,這樣的作業通常稱為打標簽 (Labeling),標簽 (Label) 就相當于這個資料對應的輸出結果,有些時候我們也可以偷懶,例如實作驗證碼識別的時候我們可以反過來根據文本生成圖片,然后把圖片當作輸入文本當作輸出,再例如實作商品推薦的時候我們可以把用戶購買過的商品分割成兩部分,一部分作為已購買商品 (輸入),另一部分作為推薦商品 (輸出),注意輸入與輸出可以有多個,例如視頻網站可以根據用戶的年齡,性別,所在地 (3 個輸入) 來判斷用戶喜歡看的視頻型別 (1 個輸出),再例如自動駕駛系統可以根據視頻輸入,雷達輸入與地圖路線 (3 個輸入) 計算汽車速度與方向盤角度 (2 個輸出),后面會介紹如何處理多個輸入與輸出,包括數量可變的輸入,
如果你只是想試試手而不是解決實際的業務問題,可以直接用別人收集好的資料集,以下是包含了各種公開資料集鏈接的 Github 倉庫:
https://github.com/awesomedata/awesome-public-datasets
建立模型
用于讓機器學習與實作操作的就是模型 (Model),模型可以分為兩部分,第一部分是計算方法,這部分需要我們來決定并且不會在學習程序中改變;第二部分是引數,這部分會隨著學習不斷調整,最終實作我們想要的操作,模型的計算方法需要根據業務(輸入與輸出的型別)來決定,例如分類可以使用多層線性模型,影像識別可以使用 CNN 模型,趨勢預測可以使用 RNN 模型,文本翻譯可以使用 Transformer 模型,物件識別可以使用 R-CNN 模型等 (這些模型會在后續的章節詳細介紹),通常我們可以直接用別人設計好的模型再加上一些細微調整(只會做這種作業的也叫調參狗??,我們的第一個小目標),而一些復雜的業務需要自己設計模型,這是真正難的地方,你可能會想是否有一種模型可以適用于所有型別的業務,遺憾的是目前并沒有,如果有那就是真正的人工智能了,
因為篇幅限制,現實使用的模型會在后面的文章中介紹,請參考本文末尾的預告,
確定輸入輸出與模型可接識訓傳的數值之間如何轉換
在機器學習中,模型只會接受和回傳數值 (通常使用多維陣列,即矩陣),所以我們還需要決定輸入輸出與數值之間如何轉換,例如輸入是圖片時,我們可以把每個像素的紅綠藍值與圖片大小一起組成一個三維陣列(紅綠藍 * 圖片寬度 * 圖片高度),再例如輸入是資料庫中的商品時,我們可以先根據總商品大小創建一個一維陣列,然后用陣列 1, 0, 0, ... 代表第一個商品,陣列 0, 1, 0, ... 代表第二個商品,陣列 0, 0, 1, ... 代表第三個商品,把數值轉換到輸出也一樣,將對應關系反過來就行了,注意轉換方式也是一個比較重要的部分,使用正確的轉換方式可以讓機器學習事半功倍,而使用錯誤的轉換方式可能導致學習緩慢或學習失敗,
為了提升學習速度,我們通常會一次性的給模型傳入多組輸入并讓模型回傳多組輸出,傳入的多組輸入也叫批次 (Batch),例如準備了 10000 組輸入與輸出,每次給模型傳入 50 組,那么批次大小就是 50,需要分 2000 個批次傳入,分批次會讓輸入與輸出的陣列維度加一,例如一次性傳 50 張寬 30 x 高 20 的圖片時,需要把這些圖片轉換為一個 50 x 3 x 30 x 20 的四維陣列,再例如傳 50 個商品時,需要把這些商品轉換為一個 50 x 商品數量的二維陣列,你可能會有疑問為什么不能一次性把所有輸入傳給模型,如果輸入輸出數量過大(有的資料集會有上百萬組資料),那么計算機不會有足夠的記憶體處理它們;另一個原因是分批次傳入可以防止過擬合 (Overfitting),但本篇不會詳細介紹這點,慣例上,我們通常會選擇 32 ~ 100 為批次大小,
此外,為了提升學習效果我們還可以選擇把數值正規化 (Normalization),例如一個輸入數值的取值范圍在 0 ~ 10 的時候,我們可以把數值全部除以 10,用 0 代表最小的值,用 1 代表最大的值,這個手法可以改善模型的學習速度與提升最終的效果,因為理解需要一定的數學知識,本篇不會詳細介紹為什么,
使用輸入與輸出的例子調整模型的引數
接下來我們就可以開始學習了,首先我們會給模型的引數 (非固定部分) 隨機賦值,然后給模型傳入預先準備好的輸入,然后模型回傳預測的輸出,第一次因為引數是隨機的,回傳的預測輸出與正確輸出可能會差很遠,例如傳一張狗的圖片給模型,模型可能會告訴你這是豬,接下來你需要糾正模型,把預測輸出的數值與正確輸出的數值通過某種方法得到它們的相差值 (也叫損失 - Loss),然后根據損失來調整模型的引數 (修改引數使得損失接近 0),讓下一次模型的預測輸出的數值更接近正確輸出的數值,如果把事先準備的所有輸入 (批次) 都傳給了模型,并且根據模型的預測輸出與正確輸出調整了模型的引數,那么就可以說經過了一輪訓練 (1 Epoch),通常我們需要經過好幾輪訓練才能達到理想的效果,
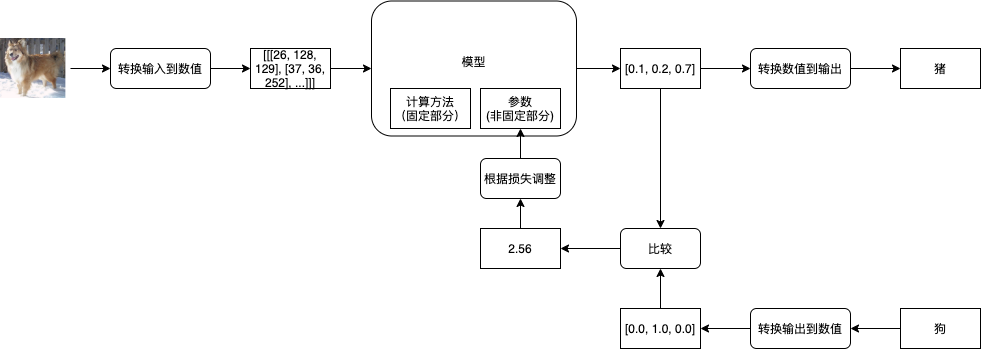
評價模型是否達到理想的效果通常會使用正確率 (Accuracy, 很多文章會縮寫成 Acc),例如傳入 100 個輸入給模型,模型回傳的 100 個預測輸出中有 99 個與正確輸出是一致的,那么正確率就是 99 %,如果模型足夠強大,我們可以讓模型針對參與訓練的輸入達到 100 % 的正確率,但這并不能說明模型訓練成功,我們還需要使用沒有參與訓練的輸入與輸出來評價模型是否成功摸索出規律,如果模型能力不足,或者用了與業務不匹配的模型,那么模型會給出很低的正確率,并且經過再多訓練都不會改善,這個時候我們就需要換一個模型了,模型通過訓練達到很高的正確率又稱收斂 (Converge),我們首先需要確定模型能收斂,再確定模型是否能成功摸索出規律,
使用沒有參與訓練的輸入與輸出評價模型是否成功摸索出規律
如果模型針對參與訓練的輸入達到了很高的正確率,那么就有兩種情況,第一種情況是模型成功的摸索出規律了,第二種情況是模型只是把所有參與訓練的輸入與輸出記住,第二種情況非常糟糕,就像我們把試卷的所有問題和答案記住了,但是沒有理解為什么,遇到另一張沒看過的試卷時就會得出很低的分數,這樣的情況又稱過擬合 (Overfitting),
為了判斷是否發生過擬合,我們通常會把事先準備好的輸入與輸出資料集打亂并分為三個集合,分別是訓練集 (Training Set),驗證集 (Validating Set) 與測驗集 (Testing Set),舉例來說我們可以把 70 % 的資料劃給訓練集,15 % 的資料劃給驗證集,剩余 15 % 的資料劃給測驗集,訓練集中的輸入與輸出用于傳給模型并且調整模型的引數;驗證集中的輸入與輸出不會參與訓練,用于在經過每一輪訓練后判斷模型在遇到未知的輸入時可以得出的正確率,如果模型針對訓練集可以得出 99 % 的正確率,但針對驗證集只能得出 50 % 的正確率,那么就可以判斷發生了過擬合;測驗集用于在最終訓練完成后判斷模型是否過度偏向于訓練集與驗證集中的資料,如果針對測驗集都可以得出比較高的正確率,那么就可以說這個模型訓練成功了,
因為實際的業務場景中收集到的輸入與輸出會夾雜一些不完全正確的資料,如果不停的去訓練模型,模型為了迎合這些不完全正確的資料會去破壞已經摸索出的規律,導致最終一定發生過擬合,為了防止這種情況我們可以使用提早停止 (Early Stopping) 的手法,在每一輪訓練后都計算模型針對訓練集與驗證集的正確率,然后在驗證集正確率最高的時候停止訓練,例如:
- 第一輪訓練后,訓練集正確率 60 %,驗證集正確率 58 %
- 第二輪訓練后,訓練集正確率 79 %,驗證集正確率 72 %
- 第三輪訓練后,訓練集正確率 88 %,驗證集正確率 86 %
- 第四輪訓練后,訓練集正確率 92 %,驗證集正確率 85 %
- 第五輪訓練后,訓練集正確率 99 %,驗證集正確率 78 %
我們可以看出應該在第三輪訓練后停止訓練,在實際操作中我們會記錄每一輪訓練的正確率與驗證集正確率最高時模型的狀態,如果驗證集正確率經過一定訓練次數都沒有超過之前的最高值,那么就使用之前記錄的模型狀態作為結果并停止訓練,在停止訓練后,我們需要判斷驗證集正確率的最高值是否達到我們滿意的水平,如果沒有達到則代表模型不適合或者沒有能力應付當前的業務,我們需要修改模型并重新開始訓練,
如果驗證集正確率的最高值達到我們滿意的水平,那么就可以做最后一步了,即用模型判斷測驗集的正確率,因為測驗集完全沒有參與過之前的步驟,如果測驗集的正確率也達到滿意的水平,那么就可以說這個模型訓練成功了,但如果測驗集的正確率沒有達到滿意的水平,則代表模型對訓練集與驗證集有偏向,因為我們在驗證集正確率不滿意的時候會修改模型,修改后的模型會更偏向于驗證集的資料,但這個偏向可能會不適合驗證集以外的資料,訓練集,驗證集與測驗集的意義可以總結如下:
- 訓練集 (Training Set): 用于訓練模型引數
- 驗證集 (Validating Set): 用于判斷模型是否支持處理沒有訓練過的輸入,并手動調整模型的計算方法
- 測驗集 (Testing Set): 用于最終判斷模型是否支持處理完全沒有參與訓練與手動調整模型的輸入
一個常見的人為錯誤是劃分這三個集合的時候沒有對資料進行打亂,例如有貓狗豬的圖片各 1000 張,如果劃分集合的時候這些圖片是排序好的,那么訓練集會只有貓和狗的圖片,測驗集會只有豬的圖片,這樣就很難確保訓練出來的模型可以正確識別豬了,
從劃分資料集到訓練成功的流程可以總結如下:
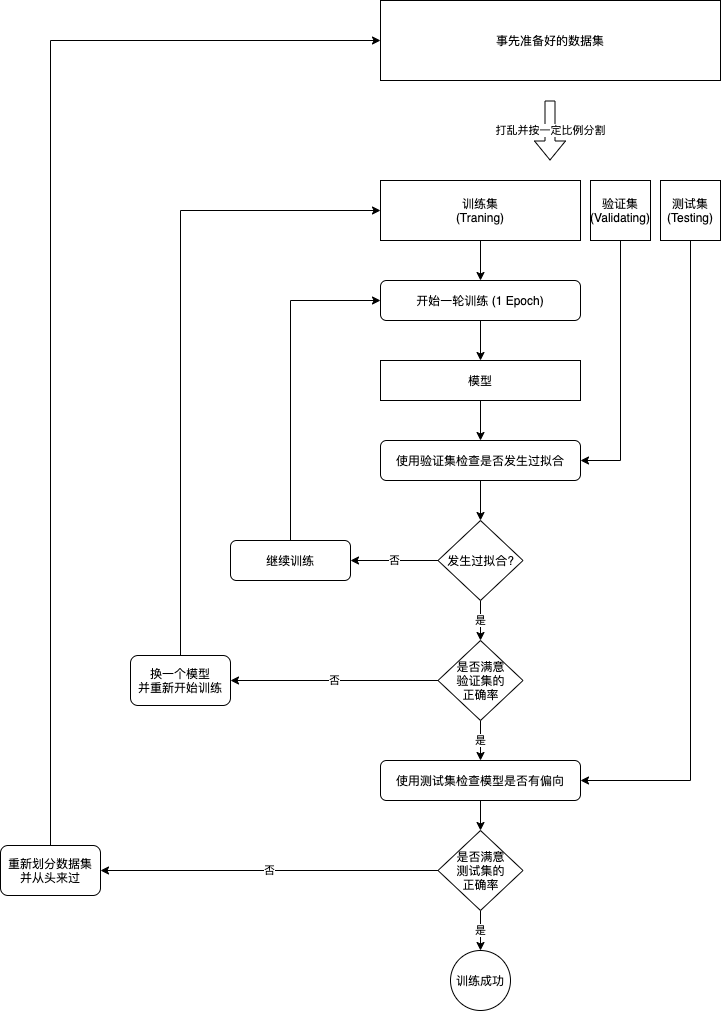
注1: 讓模型成功摸索出規律 (針對未知輸入得出正確輸出) 的作業一般稱為泛化 (Generalization),
注2: 防止過擬合還有另外一些手法,會在接下來的文章中介紹,
機器學習,深度學習與人工智能的區別
對初學者來說一個很常見的問題是,機器學習,深度學習與人工智能有什么區別?如果機器學習的模型非常復雜(經過多層次的計算),那么就可以說是深度學習,如果模型的效果非常好,在某個領域達到或者超過人類的水平,那就可以說是人工智能,但實際上它們都是 PPT 詞匯,給??投資人??看的時候寫人工智能比寫機器學習要搶眼多了,就算不滿足人工智能的水平很多公司都會宣傳為人工智能,這個系列是給在 IT 食物鏈最底層的程式員看的,所以還是謙虛點叫機器學習吧,
一個最簡單的例子
為了更好的理解前述的步驟,我準備了一個最簡單的例子:
假設有以下的輸入與輸出,怎樣才能自動找出從輸入轉換到輸出的方法呢?

你很可能一眼就已經看出了它們的規律,別急,讓我們使用機器學習來解決這個問題,
我們可以先假設輸入乘以某個值再加上某個值等于輸出,然后:
- 用 x 代表輸入
- 用 y 代表輸出
- 用 weight 代表輸入乘以的值 (公式中縮寫為 w)
- 用 bias 代表輸出加上的值 (公式中縮寫為 b)
用數學公式可以表達如下:
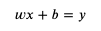
這個公式就是模型中的計算方法部分,而 weight 和 bias 則是這個模型的引數,我們把部分輸入與輸出代入 x 和 y:
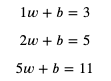
接下來要做的就是找出可以滿足這些等式的 weight 和 bias,
我們首先隨便給 weight 和 bias 分配值,例如給 weight 分配 1,給 bias 分配 0,然后試試計算結果:
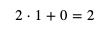
這個計算結果 2 就是預測輸出,而預測輸出和正確輸出之間的差距就是損失,
如果用 predicted (縮寫 p) 代表預測輸出,用 loss (縮寫 l) 代表損失,可以得出以下公式:
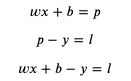
如果 loss 等于 0,那么預測輸出 predicted 就會等于正確輸出 y,我們的目標是盡量的讓 loss 接近 0,
想想如果 weight 增加 1 時 loss 會增加多少,而 bias 增加 1 時 loss 會增加多少:
- weight 增加 1 時,loss 會增加 x
- bias 增加 1 時,loss 會增加 1
可以看出 weight 和 bias 與 loss 是正相關的,并且 weight 和 bias 對 loss 的貢獻是 x 比 1,在前面的例子中,loss 等于 predicted - y 等于 2 - 5 等于 -3,我們需要增加 weight 和 bias 的值來讓 loss 更接近 0,增加 weight 和 bias 時的比例應該與貢獻比例一致,試著給 weight 加上 x,bias 加上 1,調整以后 weight 等于 3,bias 等于 1,計算結果如下:
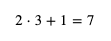
這下 loss 等于 7 - 5 等于 2 了,我們需要減少 weight 和 bias 來讓 loss 更接近 0,如果和之前一樣 weight 減去 x,bias 減去 1,那么 weight 和 bias 就會變回之前的值,不管調整多少次都無法減少 loss,噢??,解決這個問題可以控制每次 weight 和 bias 的修改量,例如每次只修改 0.01 倍 (這個倍數又稱學習比率 - Learning Rate - 簡稱 LR),總結規則如下:
如果 loss 小于 0:
- weight 增加 x 乘以 0.01
- bias 增加 0.01
如果 loss 大于 0:
- weight 減少 x 乘以 0.01
- bias 減少 0.01
模擬一下修改的程序:
第一輪:
x = 2, y = 5, weight = 1, bias = 0
predicted = 2 * 1 + 0 = 2
loss = 2 - 5 = -3
weight += 2 * 0.1
bias += 0.1
第二輪:
x = 2, y = 5, weight = 1.02, bias = 0.01
predicted = 2 * 1.02 + 0.01 = 2.05
loss = 2.05 - 5 = -2.95
weight += 2 * 0.1
bias += 0.1
第三輪:
x = 2, y = 5, weight = 1.04, bias = 0.02
predicted = 2 * 1.04 + 0.02 = 2.1
loss = 2.1 - 5 = -2.9
weight += 2 * 0.1
bias += 0.1
可以看到 loss 越來越接近 0,繼續修改下去 weight 會等于 2.2,bias 會等于 0.6,滿足 x 等于 2,y 等于 5 的情況,但滿足不了資料集中的其他資料,我們可以撰寫一個程式遍歷資料集中的資料來進行同樣的修改,來看看能不能找到滿足資料集中所有資料的 weight 和 bias:
# 定義引數
weight = 1
bias = 0
# 定義學習比率
learning_rate = 0.01
# 準備訓練集,驗證集和測驗集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
for x, y in traning_set:
# 計算預測值
predicted = x * weight + bias
# 計算損失
loss = predicted - y
# 列印除錯資訊
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 判斷需要如何修改 weight 和 bias 才能減少 loss
if loss < 0:
# 需要增加 weight 和 bias 來讓 predicted 更大
weight += x * learning_rate
bias += 1 * learning_rate
else:
# 需要減少 weight 和 bias 來讓 predicted 更小
weight -= x * learning_rate
bias -= 1 * learning_rate
# 檢查驗證集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
輸出結果如下:
epoch: 1
traning x: 2, y: 5, predicted: 2, loss: -3, weight: 1, bias: 0
traning x: 5, y: 11, predicted: 5.109999999999999, loss: -5.890000000000001, weight: 1.02, bias: 0.01
traning x: 6, y: 13, predicted: 6.4399999999999995, loss: -6.5600000000000005, weight: 1.07, bias: 0.02
traning x: 7, y: 15, predicted: 7.940000000000001, loss: -7.059999999999999, weight: 1.1300000000000001, bias: 0.03
traning x: 8, y: 17, predicted: 9.64, loss: -7.359999999999999, weight: 1.2000000000000002, bias: 0.04
validating x: 12, y: 25, predicted: 15.410000000000004
validating x: 1, y: 3, predicted: 1.3300000000000003
validating accuracy: 0.5298666666666668
epoch: 2
traning x: 2, y: 5, predicted: 2.6100000000000003, loss: -2.3899999999999997, weight: 1.2800000000000002, bias: 0.05
traning x: 5, y: 11, predicted: 6.560000000000001, loss: -4.439999999999999, weight: 1.3000000000000003, bias: 0.060000000000000005
traning x: 6, y: 13, predicted: 8.170000000000002, loss: -4.829999999999998, weight: 1.3500000000000003, bias: 0.07
traning x: 7, y: 15, predicted: 9.950000000000003, loss: -5.049999999999997, weight: 1.4100000000000004, bias: 0.08
traning x: 8, y: 17, predicted: 11.930000000000003, loss: -5.069999999999997, weight: 1.4800000000000004, bias: 0.09
validating x: 12, y: 25, predicted: 18.820000000000007
validating x: 1, y: 3, predicted: 1.6600000000000006
validating accuracy: 0.6530666666666669
epoch: 3
traning x: 2, y: 5, predicted: 3.220000000000001, loss: -1.779999999999999, weight: 1.5600000000000005, bias: 0.09999999999999999
traning x: 5, y: 11, predicted: 8.010000000000002, loss: -2.9899999999999984, weight: 1.5800000000000005, bias: 0.10999999999999999
traning x: 6, y: 13, predicted: 9.900000000000002, loss: -3.099999999999998, weight: 1.6300000000000006, bias: 0.11999999999999998
traning x: 7, y: 15, predicted: 11.960000000000004, loss: -3.0399999999999956, weight: 1.6900000000000006, bias: 0.12999999999999998
traning x: 8, y: 17, predicted: 14.220000000000006, loss: -2.779999999999994, weight: 1.7600000000000007, bias: 0.13999999999999999
validating x: 12, y: 25, predicted: 22.230000000000008
validating x: 1, y: 3, predicted: 1.9900000000000007
validating accuracy: 0.7762666666666669
省略途中的輸出
epoch: 90
traning x: 2, y: 5, predicted: 4.949999999999935, loss: -0.05000000000006466, weight: 1.9799999999999676, bias: 0.9900000000000007
traning x: 5, y: 11, predicted: 10.999999999999838, loss: -1.616484723854228e-13, weight: 1.9999999999999676, bias: 1.0000000000000007
traning x: 6, y: 13, predicted: 13.309999999999807, loss: 0.3099999999998069, weight: 2.0499999999999674, bias: 1.0100000000000007
traning x: 7, y: 15, predicted: 14.929999999999772, loss: -0.07000000000022766, weight: 1.9899999999999674, bias: 1.0000000000000007
traning x: 8, y: 17, predicted: 17.48999999999974, loss: 0.4899999999997391, weight: 2.059999999999967, bias: 1.0100000000000007
validating x: 12, y: 25, predicted: 24.759999999999607
validating x: 1, y: 3, predicted: 2.9799999999999676
validating accuracy: 0.9918666666666534
testing x: 9, y: 19, predicted: 18.819999999999705
testing x: 13, y: 27, predicted: 26.739999999999572
testing accuracy: 0.9904483430799063
最終 weight 等于 2.05,bias 等于 1.01,它針對沒有訓練過的檢查集和測驗集可以達到 99 % 的正確率 (預測輸出 99 % 接近正確輸出),如果 99 % 的正確率可以接受,那么就可以說這次訓練成功了,
如果你想看 weight 和 bias 的變化,可以記錄它們的值并且使用 matplotlib 來顯示圖表,
安裝 matplotlib 的命令:
pip3 install matplotlib
修改后的代碼:
# 定義引數
weight = 1
bias = 0
# 定義學習比率
learning_rate = 0.01
# 準備訓練集,驗證集和測驗集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
# 記錄 weight 與 bias 的歷史值
weight_history = [weight]
bias_history = [bias]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
for x, y in traning_set:
# 計算預測值
predicted = x * weight + bias
# 計算損失
loss = predicted - y
# 列印除錯資訊
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 判斷需要如何修改 weight 和 bias 才能減少 loss
if loss < 0:
# 需要增加 weight 和 bias 來讓 predicted 更大
weight += x * learning_rate
bias += 1 * learning_rate
else:
# 需要減少 weight 和 bias 來讓 predicted 更小
weight -= x * learning_rate
bias -= 1 * learning_rate
weight_history.append(weight)
bias_history.append(bias)
# 檢查驗證集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
輸出的圖表,可以看到 weight 接近 2 以后一直上下浮動,而 bias 逐漸接近 1:
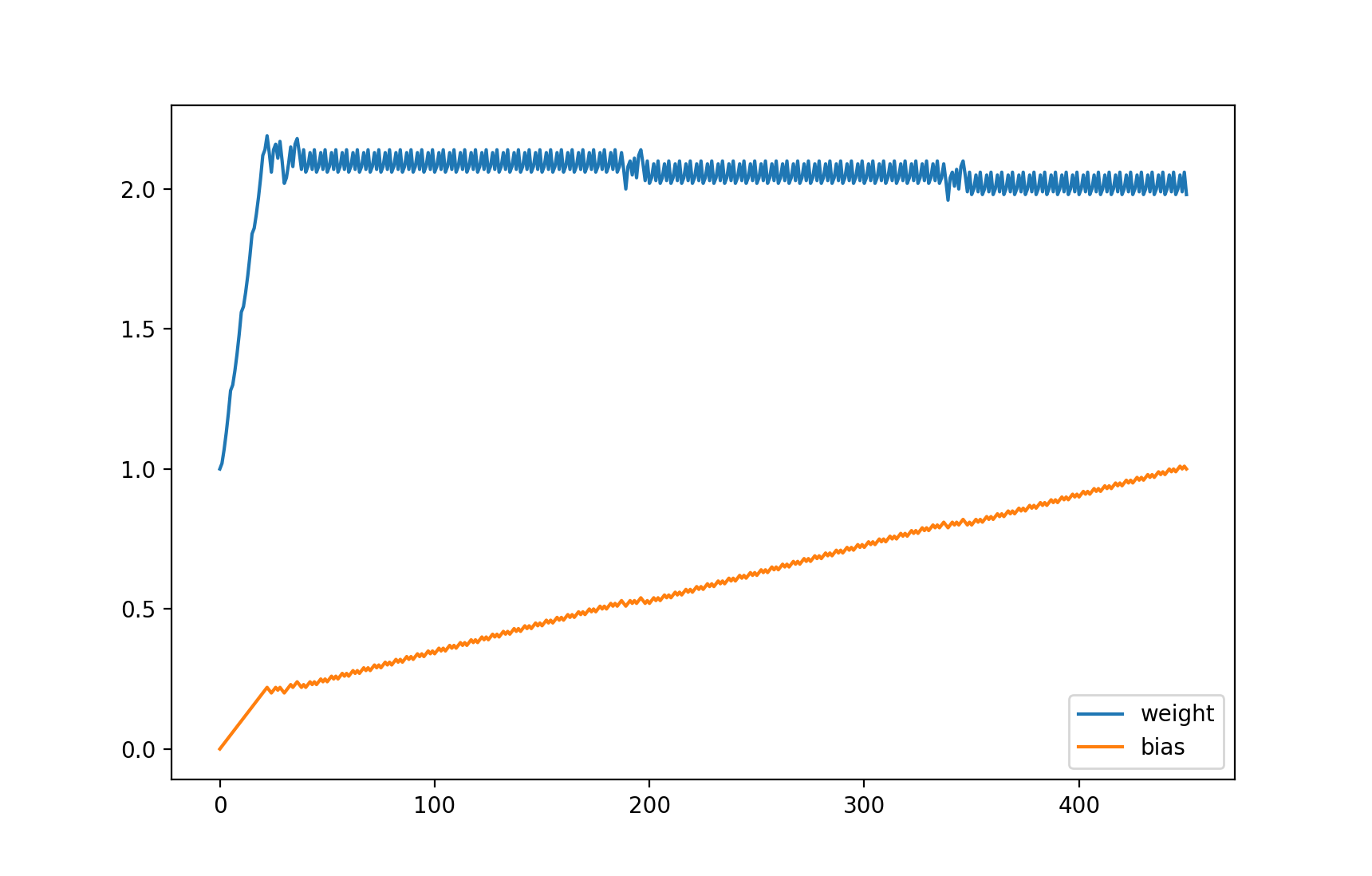
等等,你是不是覺得這個例子很蠢?這個例子的確很蠢,如果我們用其他方法 (例如聯立方程式) 可以馬上計算出 weight 應該等于 2,bias 應該等于 1,這時預測輸出 100 % 等于正確輸出,但這個例子代表了機器學習最基礎的原理 - 計算各個引數對損失的貢獻比例然后修改引數讓損失接近 0,如果模型的計算方法非常復雜,將沒有方法立刻計算出可以讓損失等于 0 的引數值,只能慢慢的調整引數去試,
好了,那為什么上面的例子不能調整 weight 到 2,bias 到 1 呢?主要有兩個原因,第一是學習比率為 0.01,如果出現 loss 很接近但小于 0,weight 和 bias 增加以后 loss 大于 0,然后減少 weight 和 bias 又讓 loss 變回原來的值,那么接下來無論學習多少次 loss 都不會等于 0,而是在小于 0 的某個值和大于 0 的某個值之間搖擺;第二是我們在正確率達到 99 % 的時候就中斷了訓練,你可以試試減少學習比率和增加中斷訓練需要的正確率,試試 weight 和 bias 會不會更接近 2 和 1,
此外在這個例子中,因為所有資料都是完美的,沒有雜質在里面,并且模型非常的簡單,所以不會出現過擬合 (Overfitting) 問題,也不需要使用提早停止 (Early Stopping) 的手法來防止過擬合,
機器學習與微分
很多機器學習的文章喜歡用拋物線和一個球來形容機器學習訓練的程序:
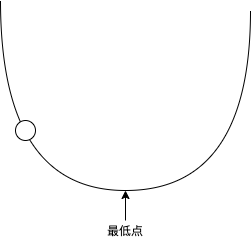
把球看作引數,拋物線看作 loss 的值,如果球在左半部分 loss 小于 0,如果球在右半部分 loss 大于 0,如果球落在最低點那么 loss 等于 0,機器學習的程序就是調整這個球的位置,球所在的位置的梯度 (Gradient) 決定了球的移動方向和每次的移動距離(移動速度),球在左半邊的時候會向右移,球在右半邊的時候會向左移,而梯度越大每次的移動距離就越長,如果每次的移動距離很長,球可能會一直左右搖擺而無法落在最低點,這個時候我們就需要使用學習比率 (Learning Rate) 來控制每次移動的距離,讓每次移動的距離等于 梯度 * 學習比率,
在前述的例子中,引數 weight 的梯度是 x,而引數 bias 的梯度是 1,這實際上就是它們的導函式 (Derivative Function):

如果你還記得高中學過的微積分,那么立刻就能看明白,但我問過但很多程式員都說已經忘光了還給數學老師了??,所以我在這里再簡單解釋一下微分的概念,還記得的就當復習叭,
所謂微分就是求某個函式的導函式,而導函式就是求某一個點上值的變化與結果的變化的關聯 (梯度),以前面的例子為例,weight 如果增加 1,那么 loss 就會增加 x,weight 如果增加 2,那么 loss 就會增加 2x,所以 weight 的導函式可以用 x 來表示;而 bias 如果增加 1,那么 loss 就會增加 1,bias 如果增加 2,那么 loss 就會增加 2,所以 bias 的導函式可以用 1 來表示,
求導函式的通用公式如下:
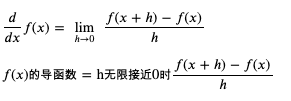
求 weight 和 bias 的導函式 (weight 和 bias 的變化與 loss 的變化的關聯) 的程序如下:

你可能會有疑問為什么要求 h 無限接近于 0,這是因為導函式求的是某個點上變化的關聯,而這個關聯可能會根據點的位置而不同,在上述例子中 weight 和 bias 不管在哪里,它們和 loss 的關聯都是相同的,不會依賴于 weight 和 bias 的值,我們可以看一個根據位置不同關聯發生變化的例子,例如 x 的平方:
當 x 等于 3 時,x 的平方等于 9
當 x 等于 5 時,x 當平方等于 25
求 x 的變化與 x 的平方的變化的關聯
當 x 等于 3 + 1 時,x 的平方等于 16,與原值相差 7
當 x 等于 5 + 1 時,x 當平方等于 36,與原值相差 11
可以看到當 x 增加 1 時,x 的平方增加多少不是固定的,會依賴于 x 的值
求 x 的平方的導函式的程序如下:
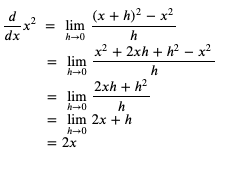
我們可以粗略檢查一下這個導函式是否正確 (以下的代碼運行在 python 的 REPL 中):
>>> ((3 + 1) ** 2 - 3 ** 2) / 1
7.0
>>> ((3 + 0.1) ** 2 - 3 ** 2) / 0.1
6.100000000000012
>>> ((3 + 0.01) ** 2 - 3 ** 2) / 0.01
6.009999999999849
>>> ((3 + 0.001) ** 2 - 3 ** 2) / 0.001
6.000999999999479
>>> ((5 + 1) ** 2 - 5 ** 2) / 1
11.0
>>> ((5 + 0.1) ** 2 - 5 ** 2) / 0.1
10.09999999999998
>>> ((5 + 0.01) ** 2 - 5 ** 2) / 0.01
10.009999999999764
>>> ((5 + 0.001) ** 2 - 5 ** 2) / 0.001
10.001000000002591
可以看到變化的值越接近 0,變化值與結果的關聯越接近 2x,
現在我們了解微分了,那積分是什么呢?積分分為不定積分和定積分,不定積分就是反過來從導函式求原始函式,定積分就是從導函式和引數的變化范圍求結果的變化范圍:

好了,復習就到此為止,我們來總結一下機器學習是怎么利用微分來調整引數的:
- 假設一個可以從輸入計算輸出的公式
- 定好計算損失的方法,并把公式變形為計算損失的公式
- 利用微分來計算公式的各個引數對損失的貢獻比例 (也就是偏導)
- 隨機分配引數的值
- 用預先收集好的輸入計算預測輸出,然后用預測輸出和正確輸出計算損失
- 根據各個引數對損失的貢獻比例調整引數,使得損失接近 0
- 損失非常接近 0 時,代表公式計算的預測輸出非常接近正確輸出,如果達到可接受的范圍就可以停止訓練
這種調整引數方式稱為梯度下降法 (Gradient Descent),因為引數的值是隨機分配的,通常又稱為隨機梯度下降法 (Stochastic Gradient Descent, 簡稱 SGD),
讓引數調整量依賴損失的大小
我們再來回頭看看前面的例子,會發現調整引數的時候,調整量只會依賴輸入與學習比率,不會依賴損失的大小,如果我們想在損失比較大的時候調整多一點,損失比較小的時候調整少一點,應該怎么辦呢?
我們可以改變損失的計算方法,把預測輸出和正確輸出相差的值的平方作為損失,這里我引入一個新的臨時變數 diff (縮寫 d) 來表示預測輸出和正確輸出相差的值:
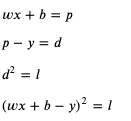
這個時候應該如何計算 weight 和 bias 的導函式呢?
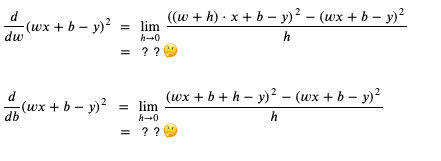
我們可以使用連鎖律 (Chain Rule),簡單的來說就是如果 x 的變化影響了 y 的變化,y 的變化影響了 z 的變化,那么 x 的變化 與 z 的變化之間的關系可以用前面兩個變化的關系組合計算出來 (注意下圖中的公式用的是 Lagrange's notation,只是記法不一樣):
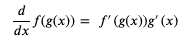
使用連鎖律計算 weight 和 bias 的導函式的程序如下 (如果你有興趣和時間可以試試不用連鎖律計算,看看結果是否一樣):

可以看到修改 loss 的計算方式后,weight 和 bias 對 loss 的貢獻比例是 2 * diff * x 比 2 * diff,會依賴于預測輸出與正確輸出相差的值,現在我們修改一下上面例子的代碼,看看是否仍然可以訓練成功:
# 定義引數
weight = 1
bias = 0
# 定義學習比率
learning_rate = 0.01
# 準備訓練集,驗證集和測驗集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
# 記錄 weight 與 bias 的歷史值
weight_history = [weight]
bias_history = [bias]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
for x, y in traning_set:
# 計算預測值
predicted = x * weight + bias
# 計算損失
diff = predicted - y
loss = diff ** 2
# 列印除錯資訊
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 計算導函式值
derivative_weight = 2 * diff * x
derivative_bias = 2 * diff
# 修改 weight 和 bias 以減少 loss
# diff 為正時代表預測輸出 > 正確輸出,會減少 weight 和 bias
# diff 為負時代表預測輸出 < 正確輸出,會增加 weight 和 bias
weight -= derivative_weight * learning_rate
bias -= derivative_bias * learning_rate
# 記錄 weight 和 bias 的歷史值
weight_history.append(weight)
bias_history.append(bias)
# 檢查驗證集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
輸出如下:
epoch: 1
traning x: 2, y: 5, predicted: 2, loss: 9, weight: 1, bias: 0
traning x: 5, y: 11, predicted: 5.66, loss: 28.5156, weight: 1.12, bias: 0.06
traning x: 6, y: 13, predicted: 10.090800000000002, loss: 8.463444639999992, weight: 1.6540000000000001, bias: 0.1668
traning x: 7, y: 15, predicted: 14.246711999999999, loss: 0.567442810944002, weight: 2.003104, bias: 0.22498399999999996
traning x: 8, y: 17, predicted: 17.108564320000003, loss: 0.011786211577063013, weight: 2.10856432, bias: 0.24004976
validating x: 12, y: 25, predicted: 25.332206819199993
validating x: 1, y: 3, predicted: 2.3290725023999994
validating accuracy: 0.8815346140160001
epoch: 2
traning x: 2, y: 5, predicted: 4.420266531199999, loss: 0.3360908948468813, weight: 2.0911940287999995, bias: 0.23787847359999995
traning x: 5, y: 11, predicted: 10.821389980735997, loss: 0.03190153898148744, weight: 2.1143833675519996, bias: 0.24947314297599996
traning x: 6, y: 13, predicted: 13.046511560231679, loss: 0.0021633252351850635, weight: 2.1322443694784, bias: 0.25304534336128004
traning x: 7, y: 15, predicted: 15.138755987910837, loss: 0.019253224181112433, weight: 2.1266629822505987, bias: 0.25211511215664645
traning x: 8, y: 17, predicted: 17.10723714394308, loss: 0.011499805041069082, weight: 2.1072371439430815, bias: 0.2493399923984297
validating x: 12, y: 25, predicted: 25.32814566046583
validating x: 1, y: 3, predicted: 2.3372744504317566
validating accuracy: 0.8829828285293095
epoch: 3
traning x: 2, y: 5, predicted: 4.427353651343945, loss: 0.327923840629112, weight: 2.0900792009121885, bias: 0.24719524951956806
traning x: 5, y: 11, predicted: 10.823573450784844, loss: 0.03112632726796794, weight: 2.112985054858431, bias: 0.2586481764926892
traning x: 6, y: 13, predicted: 13.045942966156671, loss: 0.0021107561392730407, weight: 2.1306277097799464, bias: 0.2621767074769923
traning x: 7, y: 15, predicted: 15.13705972504188, loss: 0.01878536822855566, weight: 2.125114553841146, bias: 0.2612578481538589
traning x: 8, y: 17, predicted: 17.105926192335282, loss: 0.011220358222651178, weight: 2.1059261923352826, bias: 0.2585166536530213
validating x: 12, y: 25, predicted: 25.324134148545966
validating x: 1, y: 3, predicted: 2.3453761313679533
validating accuracy: 0.8844133389237396
省略途中的輸出
epoch: 202
traning x: 2, y: 5, predicted: 4.950471765167672, loss: 0.002453046045606255, weight: 2.0077909582882314, bias: 0.9348898485912089
traning x: 5, y: 11, predicted: 10.984740851695477, loss: 0.00023284160697942092, weight: 2.0097720876815246, bias: 0.9358804132878555
traning x: 6, y: 13, predicted: 13.003973611325808, loss: 1.578958696858945e-05, weight: 2.011298002511977, bias: 0.936185596253946
traning x: 7, y: 15, predicted: 15.011854308097591, loss: 0.00014052462047262272, weight: 2.01082116915288, bias: 0.9361061240274299
traning x: 8, y: 17, predicted: 17.009161566019216, loss: 8.393429192445584e-05, weight: 2.0091615660192175, bias: 0.935869037865478
validating x: 12, y: 25, predicted: 25.02803439201881
validating x: 1, y: 3, predicted: 2.9433815220012365
validating accuracy: 0.9900028991598299
testing x: 9, y: 19, predicted: 19.00494724565038
testing x: 13, y: 27, predicted: 27.03573010747495
testing accuracy: 0.9992081406680464
weight 與 bias 的變化如下:
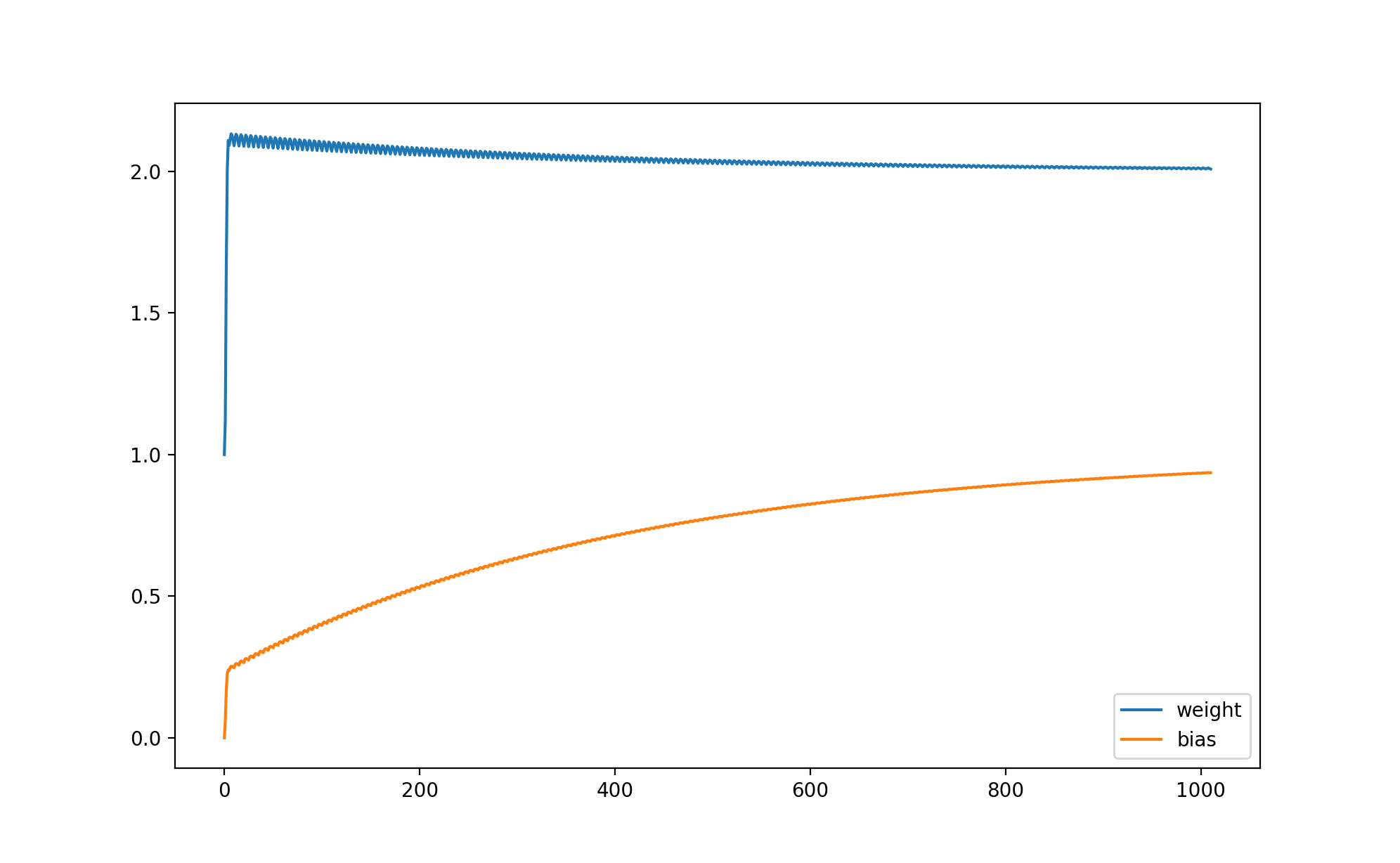
你可能會發現訓練速度比前面的例子慢很多,這是因為這個例子實在太簡單了,所以無法顯示出讓引數調整量依賴損失的優勢,在復雜的場景下它可以讓訓練速度更快并且讓預測輸出更接近正確輸出,此外,還有另外一些計算損失的方法,例如 Cross Entropy 等,它們將在后面的文章中提到,
最后補充一個知識點,通過輸入計算預測輸出的程序在機器學習中稱作 Forward,而通過損失調整引數的程序則稱作 Backward,如果引數經過多層計算,那么可以把調整多層引數的程序稱為反向傳播 (Backpropagation),多層計算的模型將在后面的文章中提到,
寫在最后
看到這里你可能會有點失望,因為這篇太基礎了,也沒有涉及到實用的例子??,但這個系列的閱讀目標是程式員,主要是那些人到中年,天天只做增刪查改,并且開始掉頭發的程式員們,他們很多都抱怨其他高級的教程看不懂,所以這個系列會把容易理解放在首位,看完可能只能做個調參狗,但如主席所說的,不管黑狗白狗,能解決問題的就是好狗??,希望這個系列可以讓你踏入機器學習的大門,并且可以利用機器學習解決業務上的問題,
接下來的文章內容預計如下:
- pytorch 與矩陣計算入門
- 線性模型,激活函式與多層線性模型
- 遞回神經網路 RNN, LSTM 與 GRU
- 卷積神經網路 CNN
- (之后如果還有時間可能會介紹 R-CNN, Transformer, GAN 等更復雜的模型)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/38960.html
標籤:其他