這是一個有點奇怪的問題,但我一直在以python中的json檔案格式從api匯入屬性資料。然后我使用 Pandas 將 json 轉換為資料幀。
我在操作資料框中的資料時遇到問題。我當前的資料設定為像這張表一樣格式化。
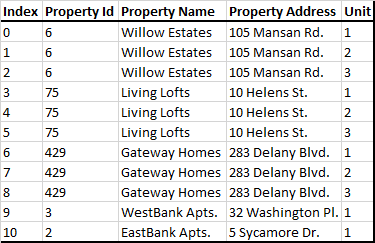
每個屬性都被分配了一個名稱、一個屬性 ID 和地址,并且一個屬性中的每個單元都有一個記錄。理想情況下,我想創建多個由屬性 id 分隔的資料框,使其看起來像這樣。
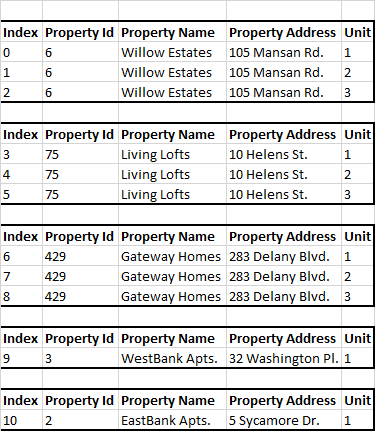
我唯一的問題是,由于它們是一些組織問題,大約有 100 個不同的屬性 ID,而且沒有一個 ID 是有序的。它們都有一個從 1 到 1000 的亂數。
有沒有辦法通過結合使用某種唯一識別符號和 for 回圈來根據屬性 id 自動分離資料幀?
我真的不知道如何處理這個場景。謝謝!
uj5u.com熱心網友回復:
試試這個:
list_of_dataframes = [x for _, x in df.groupby(df['Property Id'].ne(df['Property Id'].shift(1)).cumsum())]
現在list_of_dataframes是一個listdataframes,其中每個資料幀中包含行,其中Property Id是連續相同。所以Property Ids1 1 1 9 9 9 1 1 1將回傳3 個資料幀,一個包含前三個 1,第二個包含接下來的三個 9,最后一個包含最后三個 1。
如果不希望組基于連續順序(即,您想要1 1 1 9 9 9 1 1 1兩個資料幀,第一個包含所有六個 1,第二個包含三個 9),您可以這樣做:
list_of_dataframes = [x for _, x in df.groupby(df['Property Id'])]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390092.html