pytorch 簡介
pytorch 是目前世界上最流行的兩個機器學習框架的其中之一,與 tensoflow 并峙雙雄,它提供了很多方便的功能,例如根據損失自動微分計算應該怎樣調整引數,提供了一系列的數學函式封裝,還提供了一系列現成的模型,以及把模型組合起來進行訓練的框架,pytorch 的前身是 torch,基于 lua,而 pytorch 基于 python,雖然它基于 python 但底層完全由 c++ 撰寫,支持自動并列化計算和使用 GPU 加速運算,所以它的性能非常好,
傳統的機器學習有的會像前一節的例子中全部手寫,或者利用 numpy 類別庫減少一部分作業量,也有人會利用 scikit-learn (基于 numpy) 類別庫封裝好的各種經典演算法,pytorch 與 tensorflow 和傳統機器學習不一樣的是,它們把重點放在了組建類似人腦的神經元網路 (Neural Network),所以能實作傳統機器學習無法做到的非常復雜的判斷,例如判斷圖片中的物體型別,自動駕駛等,不過,它們組建的神經元網路作業方式是不是真的和人腦類似仍然有很多爭議,目前已經有人開始著手組建原理上更接近人腦的 GNN (Graph Neural Network) 網路,但仍未實用化,所以我們這個系列還是會著重講解當前已經實用化并廣泛應用在各個行業的網路模型,
學 pytorch 還是學 tensorflow 好?
對初學者來說一個很常見的問題是,學 pytorch 還是學 tensorflow 好?按目前的統計資料來說,公司更多使用 tensorflow,而研究人員更多使用 pytorch,pytorch 的增長速度非常快,有超越 tensorflow 的趨勢,我的意見是學哪個都無所謂,如果你熟悉 pytorch,學 tensorflow 也就一兩天的事情,反過來也一樣,并且 pytorch 和 tensorflow 的專案可以互相移植,選一個覺得好學的就可以了,因為我覺得 pytorch 更好學 (封裝非常直觀,使用 Dynamic Graph 使得除錯非常容易),所以這個系列會基于 pytorch 來講,
Dynamic Graph 與 Static Graph
機器學習框架按運算的流程是否需要預先固定可以分為 Dynamic Graph 和 Static Graph,Dynamic Graph 不需要預先固定運算流程,而 Static Graph 需要,舉例來說,對同一個公式 wx + b = y,Dynamic Graph 型的框架可以把 wx,+b 分開寫并且逐步計算,計算的程序中隨時都可以用 print 等指令輸出途中的結果,或者把途中的結果發送到其他地方記錄起來;而 Static Graph 型的框架必須預先定好整個計算流程,你只能傳入 w, x, b 給計算器,然后讓計算器輸出 y,中途計算的結果只能使用專門的除錯器來查看,
一般的來說 Static Graph 性能會比 Dynamic Graph 好,Tensorflow (老版本) 使用的是 Static Graph,而 pytorch 使用的是 Dynamic Graph,但兩者實際性能相差很小,因為消耗資源的大部分都是矩陣運算,使用批次訓練可以很大程度減少它們的差距,順帶一提,Tensorflow 1.7 開始支持了 Dynamic Graph,并且在 2.0 默認開啟,但大部分人在使用 Tensorflow 的時候還是會用 Static Graph,
# Dynamic Graph 的印象,運算的每一步都可以插入自定義代碼
def forward(w, x, b):
wx = w * x
print(wx)
y = wx + b
print(y)
return y
forward(w, x, b)
# Static Graph 的印象,需要預先編譯整個計算流程
forward = compile("wx+b")
forward(w, x, b)
安裝 pytorch
假設你已經安裝了 python3,執行以下命令即可安裝 pytorch:
pip3 install pytorch
之后在 python 代碼中使用 import torch 即可參考 pytorch 類別庫,
pytorch 的基本操作
接下來我們熟悉一下 pytorch 里面最基本的操作,pytorch 會用 torch.Tensor 型別來統一表現數值,向量 (一維陣列) 或矩陣 (多維陣列),模型的引數也會使用這個型別,(tensorflow 會根據用途分為好幾個型別,這點 pytorch 更簡潔明了)
torch.Tensor 型別可以使用 torch.tensor 函式構建,以下是一些簡單的例子(運行在 python 的 REPL 中):
# 參考 pytorch
>>> import torch
# 創建一個整數 tensor
>>> torch.tensor(1)
tensor(1)
# 創建一個小數 tensor
>>> torch.tensor(1.0)
tensor(1.)
# 單值 tensor 中的值可以用 item 函式取出
>>> torch.tensor(1.0).item()
1.0
# 使用一維陣列創建一個向量 tensor
>>> torch.tensor([1.0, 2.0, 3.0])
tensor([1., 2., 3.])
# 使用二維陣列創建一個矩陣 tensor
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]])
tensor([[ 1., 2., 3.],
[-1., -2., -3.]])
tensor 物件的數值型別可以看它的 dtype 成員:
>>> torch.tensor(1).dtype
torch.int64
>>> torch.tensor(1.0).dtype
torch.float32
>>> torch.tensor([1.0, 2.0, 3.0]).dtype
torch.float32
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]]).dtype
torch.float32
pytorch 支持整數型別 torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64 ,浮點數型別 torch.float16, torch.float32, torch.float64,還有布林值型別 torch.bool,型別后的數字代表它的位數 (bit 數),而 uint8 前面的 u 代表它是無符號數 (unsigned),實際絕大部分場景都只會使用 torch.float32,雖然精度沒有 torch.float64 高但它占用記憶體小并且運算速度快,注意一個 tensor 物件里面只能保存一種型別的數值,不能混合存放,
創建 tensor 物件時可以通過 dtype 引數強制指定型別:
>>> torch.tensor(1, dtype=torch.int32)
tensor(1, dtype=torch.int32)
>>> torch.tensor([1.1, 2.9, 3.5], dtype=torch.int32)
tensor([1, 2, 3], dtype=torch.int32)
>>> torch.tensor(1, dtype=torch.int64)
tensor(1)
>>> torch.tensor(1, dtype=torch.float32)
tensor(1.)
>>> torch.tensor(1, dtype=torch.float64)
tensor(1., dtype=torch.float64)
>>> torch.tensor([1, 2, 3], dtype=torch.float64)
tensor([1., 2., 3.], dtype=torch.float64)
>>> torch.tensor([1, 2, 0], dtype=torch.bool)
tensor([ True, True, False])
tensor 物件的形狀可以看它的 shape 成員:
# 整數 tensor 的 shape 為空
>>> torch.tensor(1).shape
torch.Size([])
>>> torch.tensor(1.0).shape
torch.Size([])
# 陣列 tensor 的 shape 只有一個值,代表陣列的長度
>>> torch.tensor([1.0]).shape
torch.Size([1])
>>> torch.tensor([1.0, 2.0, 3.0]).shape
torch.Size([3])
# 矩陣 tensor 的 shape 根據它的維度而定,每個值代表各個維度的大小,這個例子代表矩陣有 2 行 3 列
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]]).shape
torch.Size([2, 3])
tensor 物件與數值,tensor 物件與 tensor 物件之間可以進行運算:
>>> torch.tensor(1.0) * 2
tensor(2.)
>>> torch.tensor(1.0) * torch.tensor(2.0)
tensor(2.)
>>> torch.tensor(3.0) * torch.tensor(2.0)
tensor(6.)
向量和矩陣還可以批量進行運算(內部會并列化運算):
# 向量和數值之間的運算
>>> torch.tensor([1.0, 2.0, 3.0])
tensor([1., 2., 3.])
>>> torch.tensor([1.0, 2.0, 3.0]) * 3
tensor([3., 6., 9.])
>>> torch.tensor([1.0, 2.0, 3.0]) * 3 - 1
tensor([2., 5., 8.])
# 矩陣和單值 tensor 物件之間的運算
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]])
tensor([[ 1., 2., 3.],
[-1., -2., -3.]])
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]]) / torch.tensor(2)
tensor([[ 0.5000, 1.0000, 1.5000],
[-0.5000, -1.0000, -1.5000]])
# 矩陣和與矩陣最后一個維度相同長度向量之間的運算
>>> torch.tensor([[1.0, 2.0, 3.0], [-1.0, -2.0, -3.0]]) * torch.tensor([1.0, 1.5, 2.0])
tensor([[ 1., 3., 6.],
[-1., -3., -6.]])
tensor 物件之間的運算一般都會生成一個新的 tensor 物件,如果你想避免生成新物件 (提高性能),可以使用 _ 結尾的函式,它們會修改原有的物件:
# 生成新物件,原有物件不變,add 和 + 意義相同
>>> a = torch.tensor([1,2,3])
>>> b = torch.tensor([7,8,9])
>>> a.add(b)
tensor([ 8, 10, 12])
>>> a
tensor([1, 2, 3])
# 在原有物件上執行操作,避免生成新物件
>>> a.add_(b)
tensor([ 8, 10, 12])
>>> a
tensor([ 8, 10, 12])
pytorch 還提供了一系列方便的函式求最大值,最小值,平均值,標準差等:
>>> torch.tensor([1.0, 2.0, 3.0])
tensor([1., 2., 3.])
>>> torch.tensor([1.0, 2.0, 3.0]).min()
tensor(1.)
>>> torch.tensor([1.0, 2.0, 3.0]).max()
tensor(3.)
>>> torch.tensor([1.0, 2.0, 3.0]).mean()
tensor(2.)
>>> torch.tensor([1.0, 2.0, 3.0]).std()
tensor(1.)
pytorch 還支持比較 tensor 物件來生成布林值型別的 tensor:
# tensor 物件與數值比較
>>> torch.tensor([1.0, 2.0, 3.0]) > 1.0
tensor([False, True, True])
>>> torch.tensor([1.0, 2.0, 3.0]) <= 2.0
tensor([ True, True, False])
# tensor 物件與 tensor 物件比較
>>> torch.tensor([1.0, 2.0, 3.0]) > torch.tensor([1.1, 1.9, 3.0])
tensor([False, True, False])
>>> torch.tensor([1.0, 2.0, 3.0]) <= torch.tensor([1.1, 1.9, 3.0])
tensor([ True, False, True])
pytorch 還支持生成指定形狀的 tensor 物件:
# 生成 2 行 3 列的矩陣 tensor,值全部為 0
>>> torch.zeros(2, 3)
tensor([[0., 0., 0.],
[0., 0., 0.]])
# 生成 3 行 2 列的矩陣 tensor,值全部為 1
torch.ones(3, 2)
>>> torch.ones(2, 3)
tensor([[1., 1., 1.],
[1., 1., 1.]])
# 生成 3 行 2 列的矩陣 tensor,值全部為 100
>>> torch.full((3, 2), 100)
tensor([[100., 100.],
[100., 100.],
[100., 100.]])
# 生成 3 行 3 列的矩陣 tensor,值為范圍 [0, 1) 的隨機浮點數
>>> torch.rand(3, 3)
tensor([[0.4012, 0.2412, 0.1532],
[0.1178, 0.2319, 0.4056],
[0.7879, 0.8318, 0.7452]])
# 生成 3 行 3 列的矩陣 tensor,值為范圍 [1, 10] 的隨機整數
>>> (torch.rand(3, 3) * 10 + 1).long()
tensor([[ 8, 1, 5],
[ 8, 6, 5],
[ 1, 6, 10]])
# 和上面的寫法效果一樣
>>> torch.randint(1, 11, (3, 3))
tensor([[7, 1, 3],
[7, 9, 8],
[4, 7, 3]])
這里提到的操作只是常用的一部分,如果你想了解更多 tensor 物件支持的操作,可以參考以下檔案:
- https://pytorch.org/docs/stable/tensors.html
pytorch 保存 tensor 使用的資料結構
為了減少記憶體占用與提升訪問速度,pytorch 會使用一塊連續的儲存空間 (不管是在系統記憶體還是在 GPU 記憶體中) 保存 tensor,不管 tensor 是數值,向量還是矩陣,
我們可以使用 storage 查看 tensor 物件使用的儲存空間:
# 數值的儲存空間長度是 1
>>> torch.tensor(1).storage()
1
[torch.LongStorage of size 1]
# 向量的儲存空間長度等于向量的長度
>>> torch.tensor([1, 2, 3], dtype=torch.float32).storage()
1.0
2.0
3.0
[torch.FloatStorage of size 3]
# 矩陣的儲存空間長度等于所有維度相乘的結果,這里是 2 行 3 列總共 6 個元素
>>> torch.tensor([[1, 2, 3], [-1, -2, -3]], dtype=torch.float64).storage()
1.0
2.0
3.0
-1.0
-2.0
-3.0
[torch.DoubleStorage of size 6]
pytorch 會使用 stride 來確定一個 tensor 物件的維度:
# 儲存空間有 6 個元素
>>> torch.tensor([[1, 2, 3], [-1, -2, -3]]).storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
# 第一個維度是 2,第二個維度是 3 (2 行 3 列)
>>> torch.tensor([[1, 2, 3], [-1, -2, -3]]).shape
torch.Size([2, 3])
# stride 的意義是表示每個維度之間元素的距離
# 第一個維度會按 3 個元素來切分 (6 個元素可以切分成 2 組),第二個維度會按 1 個元素來切分 (3 個元素)
>>> torch.tensor([[1, 2, 3], [-1, -2, -3]])
tensor([[ 1, 2, 3],
[-1, -2, -3]])
>>> torch.tensor([[1, 2, 3], [-1, -2, -3]]).stride()
(3, 1)
pytorch 的一個很強大的地方是,通過 view 函式可以修改 tensor 物件的維度 (內部改變了 stride),但是不需要創建新的儲存空間并復制元素:
# 創建一個 2 行 3 列的矩陣
>>> a = torch.tensor([[1, 2, 3], [-1, -2, -3]])
>>> a
tensor([[ 1, 2, 3],
[-1, -2, -3]])
>>> a.shape
torch.Size([2, 3])
>>> a.stride()
(3, 1)
# 把維度改為 3 行 2 列
>>> b = a.view(3, 2)
>>> b
tensor([[ 1, 2],
[ 3, -1],
[-2, -3]])
>>> b.shape
torch.Size([3, 2])
>>> b.stride()
(2, 1)
# 轉換為向量
>>> c = b.view(6)
>>> c
tensor([ 1, 2, 3, -1, -2, -3])
>>> c.shape
torch.Size([6])
>>> c.stride()
(1,)
# 它們的儲存空間是一樣的
>>> a.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
>>> b.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
>>> c.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
使用 stride 確定維度的另一個意義是它可以支持共用同一個空間實作轉置 (Transpose) 操作:
# 創建一個 2 行 3 列的矩陣
>>> a = torch.tensor([[1, 2, 3], [-1, -2, -3]])
>>> a
tensor([[ 1, 2, 3],
[-1, -2, -3]])
>>> a.shape
torch.Size([2, 3])
>>> a.stride()
(3, 1)
# 使用轉置操作交換維度 (行轉列)
>>> b = a.transpose(0, 1)
>>> b
tensor([[ 1, -1],
[ 2, -2],
[ 3, -3]])
>>> b.shape
torch.Size([3, 2])
>>> b.stride()
(1, 3)
# 它們的儲存空間是一樣的
>>> a.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
>>> b.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
轉置操作內部就是交換了指定維度在 stride 中對應的值,你可以根據前面的描述想想物件在轉置后的矩陣中會如何劃分,
現在再想想,如果把轉置后的矩陣用 view 函式專為向量會變為什么?會變為 [1, -1, 2, -2, 3, -3] 嗎?
實際上這樣的操作會導致出錯??:
>>> b
tensor([[ 1, -1],
[ 2, -2],
[ 3, -3]])
>>> b.view(6)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
這是因為轉置后矩陣元素的自然順序和儲存空間中的順序不一致,我們可以用 is_contiguous 函式來檢測:
>>> a.is_contiguous()
True
>>> b.is_contiguous()
False
解決這個問題的方法是首先用 contiguous 函式把儲存空間另外復制一份使得順序一致,然后再用 view 函式改變維度;或者用更方便的 reshape 函式,reshape 函式會檢測改變維度的時候是否需要復制儲存空間,如果需要則復制,不需要則和 view 一樣只修改內部的 stride,
>>> b.contiguous().view(6)
tensor([ 1, -1, 2, -2, 3, -3])
>>> b.reshape(6)
tensor([ 1, -1, 2, -2, 3, -3])
pytorch 還支持截取儲存空間的一部分來作為一個新的 tensor 物件,基于內部的 storage_offset 與 size 屬性,同樣不需要復制:
# 截取向量的例子
>>> a = torch.tensor([1, 2, 3, -1, -2, -3])
>>> b = a[1:3]
>>> b
tensor([2, 3])
>>> b.storage_offset()
1
>>> b.size()
torch.Size([2])
>>> b.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
# 截取矩陣的例子
>>> a.view(3, 2)
tensor([[ 1, 2],
[ 3, -1],
[-2, -3]])
>>> c = a.view(3, 2)[1:] # 第一維度 (行) 截取 1~結尾, 第二維度不截取
>>> c
tensor([[ 3, -1],
[-2, -3]])
>>> c.storage_offset()
2
>>> c.size()
torch.Size([2, 2])
>>> c.stride()
(2, 1)
>>> c.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
# 截取轉置后矩陣的例子,更復雜一些
>>> a.view(3, 2).transpose(0, 1)
tensor([[ 1, 3, -2],
[ 2, -1, -3]])
>>> c = a.view(3, 2).transpose(0, 1)[:,1:] # 第一維度 (行) 不截取,第二維度 (列) 截取 1~結尾
>>> c
tensor([[ 3, -2],
[-1, -3]])
>>> c.storage_offset()
2
>>> c.size()
torch.Size([2, 2])
>>> c.stride()
(1, 2)
>>> c.storage()
1
2
3
-1
-2
-3
[torch.LongStorage of size 6]
好了,看完這一節你應該對 pytorch 如何儲存 tensor 物件有一個比較基礎的了解,為了容易理解本節最多只使用二維矩陣做例子,你可以自己試試更多維度的矩陣是否可以用同樣的方式操作,
矩陣乘法簡介
接下來我們看看矩陣乘法 (Matrix Multiplication),這是機器學習中最最最頻繁的操作,高中學過并且還記得的就當復習一下吧,
以下是一個簡單的例子,一個 2 行 3 列的矩陣乘以一個 3 行 4 列的矩陣可以得出一個 2 行 4 列的矩陣:
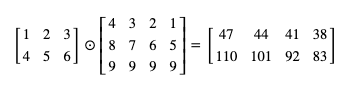
矩陣乘法會把第一個矩陣的每一行與第二個矩陣的每一列相乘的各個合計值作為結果,可以參考下圖理解:

按這個規則來算,一個 n 行 m 列的矩陣和一個 m 行 p 列的矩陣相乘,會得出一個 n 行 p 列的矩陣 (第一個矩陣的列數與第二個矩陣的行數必須相同),
那矩陣乘法有什么意義呢?矩陣乘法在機器學習中的意義是可以把對多個輸入輸出或者中間值的計算合并到一個操作中 (在數學上也可以大幅簡化公式),框架可以在內部并列化計算,因為高端的 GPU 有幾千個核心,把計算分布到幾千個核心中可以大幅提升運算速度,在接下來的例子中也可以看到如何用矩陣乘法實作批次訓練,
使用 pytorch 進行矩陣乘法計算
在 pytorch 中矩陣乘法可以呼叫 mm 函式:
>>> a = torch.tensor([[1,2,3],[4,5,6]])
>>> b = torch.tensor([[4,3,2,1],[8,7,6,5],[9,9,9,9]])
>>> a.mm(b)
tensor([[ 47, 44, 41, 38],
[110, 101, 92, 83]])
# 如果大小不匹配會出錯
>>> a = torch.tensor([[1,2,3],[4,5,6]])
>>> b = torch.tensor([[4,3,2,1],[8,7,6,5]])
>>> a.mm(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: size mismatch, m1: [2 x 3], m2: [2 x 4] at ../aten/src/TH/generic/THTensorMath.cpp:197
# mm 函式也可以用 @ 運算子代替,結果是一樣的
>>> a = torch.tensor([[1,2,3],[4,5,6]])
>>> b = torch.tensor([[4,3,2,1],[8,7,6,5],[9,9,9,9]])
>>> a @ b
tensor([[ 47, 44, 41, 38],
[110, 101, 92, 83]])
針對更多維度的矩陣乘法,pytorch 提供了 matmul 函式:
# n x m 的矩陣與 q x m x p 的矩陣相乘會得出 q x n x p 的矩陣
>>> a = torch.ones(2,3)
>>> b = torch.ones(5,3,4)
>>> a.matmul(b)
tensor([[[3., 3., 3., 3.],
[3., 3., 3., 3.]],
[[3., 3., 3., 3.],
[3., 3., 3., 3.]],
[[3., 3., 3., 3.],
[3., 3., 3., 3.]],
[[3., 3., 3., 3.],
[3., 3., 3., 3.]],
[[3., 3., 3., 3.],
[3., 3., 3., 3.]]])
>>> a.matmul(b).shape
torch.Size([5, 2, 4])
pytorch 的自動微分功能 (autograd)
pytorch 支持自動微分求導函式值 (即各個引數的梯度),利用這個功能我們不再需要通過數學公式求各個引數的導函式值,使得機器學習的門檻低了很多????,以下是這個功能的例子:
# 定義引數
# 創建 tensor 物件時設定 requires_grad 為 True 即可開啟自動微分功能
>>> w = torch.tensor(1.0, requires_grad=True)
>>> b = torch.tensor(0.0, requires_grad=True)
# 定義輸入和輸出的 tensor
>>> x = torch.tensor(2)
>>> y = torch.tensor(5)
# 計算預測輸出
>>> p = x * w + b
>>> p
tensor(2., grad_fn=<AddBackward0>)
# 計算損失
# 注意 pytorch 的自動微分功能要求損失不能為負數,因為 pytorch 只會考慮減少損失而不是讓損失接近 0
# 這里用 abs 讓損失變為絕對值
>>> l = (p - y).abs()
>>> l
tensor(3., grad_fn=<AbsBackward>)
# 從損失自動微分求導函式值
>>> l.backward()
# 查看各個引數對應的導函式值
# 注意 pytorch 會假設讓引數減去 grad 的值才能減少損失,所以這里是負數(引數會變大)
>>> w.grad
tensor(-2.)
>>> b.grad
tensor(-1.)
# 定義學習比率,即每次根據導函式值調整引數的比率
>>> learning_rate = 0.01
# 調整引數時需要用 torch.no_grad 來臨時禁止自動微分功能
>>> with torch.no_grad():
... w -= w.grad * learning_rate
... b -= b.grad * learning_rate
...
# 我們可以看到 weight 和 bias 分別增加了 0.02 和 0.01
>>> w
tensor(1.0200, requires_grad=True)
>>> b
tensor(0.0100, requires_grad=True)
# 最后我們需要清空引數的 grad 值,這個值不會自動清零(因為某些模型需要疊加導函式值)
# 你可以試試再調一次 backward,會發現 grad 把兩次的值疊加起來
>>> w.grad.zero_()
>>> b.grad.zero_()
我們再來試試前一節提到的讓損失等于相差值平方的方法:
# 定義引數
>>> w = torch.tensor(1.0, requires_grad=True)
>>> b = torch.tensor(0.0, requires_grad=True)
# 定義輸入和輸出的 tensor
>>> x = torch.tensor(2)
>>> y = torch.tensor(5)
# 計算預測輸出
>>> p = x * w + b
>>> p
tensor(2., grad_fn=<AddBackward0>)
# 計算相差值
>>> d = p - y
>>> d
tensor(-3., grad_fn=<SubBackward0>)
# 計算損失 (相差值的平方, 一定會是 0 或者正數)
>>> l = d ** 2
>>> l
tensor(9., grad_fn=<PowBackward0>)
# 從損失自動微分求導函式值
>>> l.backward()
# 查看各個引數對應的導函式值,跟我們上一篇用數學公式求出來的值一樣吧
# w 的導函式值 = 2 * d * x = 2 * -3 * 2 = -12
# b 的導函式值 = 2 * d = 2 * -3 = -6
>>> w.grad
tensor(-12.)
>>> b.grad
tensor(-6.)
# 之后和上一個例子一樣調整引數即可
膩害叭??,再復雜的模型只要呼叫 backward 都可以自動幫我們計算出導函式值,從現在開始我們可以把數學課本丟掉了 (這是開玩笑的,一些問題仍然需要用數學來理解,但大部分情況下只有基礎數學知識的人也能玩得起),
pytorch 的損失計算器封裝 (loss function)
pytorch 提供了幾種常見的損失計算器的封裝,我們最開始看到的也稱 L1 損失 (L1 Loss),表示所有預測輸出與正確輸出的相差的絕對值的平均 (有的場景會有多個輸出),以下是使用 L1 損失的例子:
# 定義引數
>>> w = torch.tensor(1.0, requires_grad=True)
>>> b = torch.tensor(0.0, requires_grad=True)
# 定義輸入和輸出的 tensor
# 注意 pytorch 提供的損失計算器要求預測輸出和正確輸出均為浮點數,所以定義輸入與輸出的時候也需要用浮點數
>>> x = torch.tensor(2.0)
>>> y = torch.tensor(5.0)
# 創建損失計算器
>>> loss_function = torch.nn.L1Loss()
# 計算預測輸出
>>> p = x * w + b
>>> p
tensor(2., grad_fn=<AddBackward0>)
# 計算損失
# 等同于 (p - y).abs().mean()
>>> l = loss_function(p, y)
>>> l
tensor(3., grad_fn=<L1LossBackward>)
而計算相差值的平方作為損失稱為 MSE 損失 (Mean Squared Error),有的地方又稱 L2 損失,以下是使用 MSE 損失的例子:
# 定義引數
>>> w = torch.tensor(1.0, requires_grad=True)
>>> b = torch.tensor(0.0, requires_grad=True)
# 定義輸入和輸出的 tensor
>>> x = torch.tensor(2.0)
>>> y = torch.tensor(5.0)
# 創建損失計算器
>>> loss_function = torch.nn.MSELoss()
# 計算預測輸出
>>> p = x * w + b
>>> p
tensor(2., grad_fn=<AddBackward0>)
# 計算損失
# 等同于 ((p - y) ** 2).mean()
>>> l = loss_function(p, y)
>>> l
tensor(9., grad_fn=<MseLossBackward>)
方便叭???,如果你想看更多的損失計算器可以參考以下地址:
- https://pytorch.org/docs/stable/nn.html#loss-functions
pytorch 的引數調整器封裝 (optimizer)
pytorch 還提供了根據導函式值調整引數的調整器封裝,我們在這兩篇文章中看到的方法 (隨機初始化引數值,然后根據導函式值 * 學習比率調整引數減少損失) 又稱隨機梯度下降法 (Stochastic Gradient Descent),以下是使用封裝好的調整器的例子:
# 定義引數
>>> w = torch.tensor(1.0, requires_grad=True)
>>> b = torch.tensor(0.0, requires_grad=True)
# 定義輸入和輸出的 tensor
>>> x = torch.tensor(2.0)
>>> y = torch.tensor(5.0)
# 創建損失計算器
>>> loss_function = torch.nn.MSELoss()
# 創建引數調整器
# 需要傳入引數串列和指定學習比率,這里的學習比率是 0.01
>>> optimizer = torch.optim.SGD([w, b], lr=0.01)
# 計算預測輸出
>>> p = x * w + b
>>> p
tensor(2., grad_fn=<AddBackward0>)
# 計算損失
>>> l = loss_function(p, y)
>>> l
tensor(9., grad_fn=<MseLossBackward>)
# 從損失自動微分求導函式值
>>> l.backward()
# 確認引數的導函式值
>>> w.grad
tensor(-12.)
>>> b.grad
tensor(-6.)
# 使用引數調整器調整引數
# 等同于:
# with torch.no_grad():
# w -= w.grad * learning_rate
# b -= b.grad * learning_rate
optimizer.step()
# 清空導函式值
# 等同于:
# w.grad.zero_()
# b.grad.zero_()
optimizer.zero_grad()
# 確認調整后的引數
>>> w
tensor(1.1200, requires_grad=True)
>>> b
tensor(0.0600, requires_grad=True)
>>> w.grad
tensor(0.)
>>> b.grad
tensor(0.)
SGD 引數調整器的學習比率是固定的,如果我們想在學習程序中自動調整學習比率,可以使用其他引數調整器,例如 Adam 調整器,此外,你還可以開啟沖量 (momentum) 選項改進學習速度,該選項開啟后可以在引數調整時參考前一次調整的方向 (正負),如果相同則調整更多,而不同則調整更少,
如果你對 Adam 調整器的實作和沖量的實作有興趣,可以參考以下文章 (需要一定的數學知識):
- https://mlfromscratch.com/optimizers-explained
如果你想查看 pytorch 提供的其他引數調整器可以訪問以下地址:
- https://pytorch.org/docs/stable/optim.html
使用 pytorch 實作上一篇文章的例子
好了,學到這里我們應該對 pytorch 的基本操作有一定了解,現在我們來試試用 pytorch 實作上一篇文章最后的例子,
上一篇文章最后的例子代碼如下:
# 定義引數
weight = 1
bias = 0
# 定義學習比率
learning_rate = 0.01
# 準備訓練集,驗證集和測驗集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
# 記錄 weight 與 bias 的歷史值
weight_history = [weight]
bias_history = [bias]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
for x, y in traning_set:
# 計算預測值
predicted = x * weight + bias
# 計算損失
diff = predicted - y
loss = diff ** 2
# 列印除錯資訊
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 計算導函式值
derivative_weight = 2 * diff * x
derivative_bias = 2 * diff
# 修改 weight 和 bias 以減少 loss
# diff 為正時代表預測輸出 > 正確輸出,會減少 weight 和 bias
# diff 為負時代表預測輸出 < 正確輸出,會增加 weight 和 bias
weight -= derivative_weight * learning_rate
bias -= derivative_bias * learning_rate
# 記錄 weight 和 bias 的歷史值
weight_history.append(weight)
bias_history.append(bias)
# 檢查驗證集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
使用 pytorch 實作后代碼如下:
# 參考 pytorch
import torch
# 定義引數
weight = torch.tensor(1.0, requires_grad=True)
bias = torch.tensor(0.0, requires_grad=True)
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD([weight, bias], lr=0.01)
# 準備訓練集,驗證集和測驗集
traning_set = [
(torch.tensor(2.0), torch.tensor(5.0)),
(torch.tensor(5.0), torch.tensor(11.0)),
(torch.tensor(6.0), torch.tensor(13.0)),
(torch.tensor(7.0), torch.tensor(15.0)),
(torch.tensor(8.0), torch.tensor(17.0))
]
validating_set = [
(torch.tensor(12.0), torch.tensor(25.0)),
(torch.tensor(1.0), torch.tensor(3.0))
]
testing_set = [
(torch.tensor(9.0), torch.tensor(19.0)),
(torch.tensor(13.0), torch.tensor(27.0))
]
# 記錄 weight 與 bias 的歷史值
weight_history = [weight.item()]
bias_history = [bias.item()]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
for x, y in traning_set:
# 計算預測值
predicted = x * weight + bias
# 計算損失
loss = loss_function(predicted, y)
# 列印除錯資訊
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄 weight 和 bias 的歷史值
weight_history.append(weight.item())
bias_history.append(bias.item())
# 檢查驗證集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight.item() + bias.item()
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight.item() + bias.item()
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
輸出如下:
epoch: 1
traning x: 2.0, y: 5.0, predicted: 2.0, loss: 9.0, weight: 1.0, bias: 0.0
traning x: 5.0, y: 11.0, predicted: 5.659999847412109, loss: 28.515602111816406, weight: 1.1200000047683716, bias: 0.05999999865889549
traning x: 6.0, y: 13.0, predicted: 10.090799331665039, loss: 8.463448524475098, weight: 1.6540000438690186, bias: 0.16679999232292175
traning x: 7.0, y: 15.0, predicted: 14.246713638305664, loss: 0.5674403309822083, weight: 2.0031042098999023, bias: 0.22498400509357452
traning x: 8.0, y: 17.0, predicted: 17.108564376831055, loss: 0.011786224320530891, weight: 2.1085643768310547, bias: 0.24004973471164703
validating x: 12.0, y: 25.0, predicted: 25.33220863342285
validating x: 1.0, y: 3.0, predicted: 2.3290724754333496
validating accuracy: 0.8815345764160156
epoch: 2
traning x: 2.0, y: 5.0, predicted: 4.420266628265381, loss: 0.3360907733440399, weight: 2.0911941528320312, bias: 0.2378784418106079
traning x: 5.0, y: 11.0, predicted: 10.821391105651855, loss: 0.03190113604068756, weight: 2.1143834590911865, bias: 0.24947310984134674
traning x: 6.0, y: 13.0, predicted: 13.04651165008545, loss: 0.002163333585485816, weight: 2.132244348526001, bias: 0.25304529070854187
traning x: 7.0, y: 15.0, predicted: 15.138755798339844, loss: 0.019253171980381012, weight: 2.1266629695892334, bias: 0.25211507081985474
traning x: 8.0, y: 17.0, predicted: 17.107236862182617, loss: 0.011499744839966297, weight: 2.1072371006011963, bias: 0.24933995306491852
validating x: 12.0, y: 25.0, predicted: 25.32814598083496
validating x: 1.0, y: 3.0, predicted: 2.3372745513916016
validating accuracy: 0.8829828500747681
epoch: 3
traning x: 2.0, y: 5.0, predicted: 4.427353858947754, loss: 0.32792359590530396, weight: 2.0900793075561523, bias: 0.24719521403312683
traning x: 5.0, y: 11.0, predicted: 10.82357406616211, loss: 0.0311261098831892, weight: 2.112985134124756, bias: 0.2586481273174286
traning x: 6.0, y: 13.0, predicted: 13.045942306518555, loss: 0.002110695466399193, weight: 2.1306276321411133, bias: 0.26217663288116455
traning x: 7.0, y: 15.0, predicted: 15.137059211730957, loss: 0.018785227090120316, weight: 2.1251144409179688, bias: 0.2612577974796295
traning x: 8.0, y: 17.0, predicted: 17.105924606323242, loss: 0.011220022104680538, weight: 2.105926036834717, bias: 0.2585166096687317
validating x: 12.0, y: 25.0, predicted: 25.324134826660156
validating x: 1.0, y: 3.0, predicted: 2.3453762531280518
validating accuracy: 0.8844133615493774
省略途中的輸出
epoch: 202
traning x: 2.0, y: 5.0, predicted: 4.950470924377441, loss: 0.0024531292729079723, weight: 2.0077908039093018, bias: 0.9348894953727722
traning x: 5.0, y: 11.0, predicted: 10.984740257263184, loss: 0.00023285974748432636, weight: 2.0097720623016357, bias: 0.9358800649642944
traning x: 6.0, y: 13.0, predicted: 13.003972053527832, loss: 1.5777208318468183e-05, weight: 2.0112979412078857, bias: 0.9361852407455444
traning x: 7.0, y: 15.0, predicted: 15.011855125427246, loss: 0.00014054399798624218, weight: 2.0108213424682617, bias: 0.9361057877540588
traning x: 8.0, y: 17.0, predicted: 17.00916290283203, loss: 8.39587883092463e-05, weight: 2.0091617107391357, bias: 0.9358686804771423
validating x: 12.0, y: 25.0, predicted: 25.028034210205078
validating x: 1.0, y: 3.0, predicted: 2.9433810710906982
validating accuracy: 0.9900028705596924
testing x: 9.0, y: 19.0, predicted: 19.004947662353516
testing x: 13.0, y: 27.0, predicted: 27.035730361938477
testing accuracy: 0.9992080926895142
同樣的訓練成功了??,你可能會發現輸出的值和前一篇文章的值有一些不同,這是因為 pytorch 默認使用 32 位浮點數 (float32) 進行運算,而 python 使用的是 64 位浮點數 (float64), 如果你把引數定義的部分改成這樣:
# 定義引數
weight = torch.tensor(1.0, dtype=torch.float64, requires_grad=True)
bias = torch.tensor(0.0, dtype=torch.float64, requires_grad=True)
然后計算損失的部分改成這樣,則可以得到和前一篇文章一樣的輸出:
# 計算損失
loss = loss_function(predicted, y.double())
使用矩陣乘法實作批次訓練
前面的例子雖然使用 pytorch 實作了訓練,但還是一個一個值的計算,我們可以用矩陣乘法來實作批次訓練,一次計算多個值,以下修改后的代碼:
# 參考 pytorch
import torch
# 定義引數
weight = torch.tensor([[1.0]], requires_grad=True) # 1 行 1 列
bias = torch.tensor(0.0, requires_grad=True)
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD([weight, bias], lr=0.01)
# 準備訓練集,驗證集和測驗集
traning_set_x = torch.tensor([[2.0], [5.0], [6.0], [7.0], [8.0]]) # 5 行 1 列,代表有 5 組,每組有 1 個輸入
traning_set_y = torch.tensor([[5.0], [11.0], [13.0], [15.0], [17.0]]) # 5 行 1 列,代表有 5 組,每組有 1 個輸出
validating_set_x = torch.tensor([[12.0], [1.0]]) # 2 行 1 列,代表有 2 組,每組有 1 個輸入
validating_set_y = torch.tensor([[25.0], [3.0]]) # 2 行 1 列,代表有 2 組,每組有 1 個輸出
testing_set_x = torch.tensor([[9.0], [13.0]]) # 2 行 1 列,代表有 2 組,每組有 1 個輸入
testing_set_y = torch.tensor([[19.0], [27.0]]) # 2 行 1 列,代表有 2 組,每組有 1 個輸出
# 記錄 weight 與 bias 的歷史值
weight_history = [weight[0][0].item()]
bias_history = [bias.item()]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 計算預測值
# 5 行 1 列的矩陣乘以 1 行 1 列的矩陣,會得出 5 行 1 列的矩陣
predicted = traning_set_x.mm(weight) + bias
# 計算損失
loss = loss_function(predicted, traning_set_y)
# 列印除錯資訊
print(f"traning x: {traning_set_x}, y: {traning_set_y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄 weight 和 bias 的歷史值
weight_history.append(weight[0][0].item())
bias_history.append(bias.item())
# 檢查驗證集
with torch.no_grad(): # 禁止自動微分功能
predicted = validating_set_x.mm(weight) + bias
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
with torch.no_grad(): # 禁止自動微分功能
predicted = testing_set_x.mm(weight) + bias
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
輸出如下:
epoch: 1
traning x: tensor([[2.],
[5.],
[6.],
[7.],
[8.]]), y: tensor([[ 5.],
[11.],
[13.],
[15.],
[17.]]), predicted: tensor([[2.],
[5.],
[6.],
[7.],
[8.]], grad_fn=<AddBackward0>), loss: 47.79999923706055, weight: tensor([[1.]], requires_grad=True), bias: 0.0
validating x: tensor([[12.],
[ 1.]]), y: tensor([[25.],
[ 3.]]), predicted: tensor([[22.0200],
[ 1.9560]])
validating accuracy: 0.7663999795913696
epoch: 2
traning x: tensor([[2.],
[5.],
[6.],
[7.],
[8.]]), y: tensor([[ 5.],
[11.],
[13.],
[15.],
[17.]]), predicted: tensor([[ 3.7800],
[ 9.2520],
[11.0760],
[12.9000],
[14.7240]], grad_fn=<AddBackward0>), loss: 3.567171573638916, weight: tensor([[1.8240]], requires_grad=True), bias: 0.13199999928474426
validating x: tensor([[12.],
[ 1.]]), y: tensor([[25.],
[ 3.]]), predicted: tensor([[24.7274],
[ 2.2156]])
validating accuracy: 0.8638148307800293
省略途中的輸出
epoch: 1103
traning x: tensor([[2.],
[5.],
[6.],
[7.],
[8.]]), y: tensor([[ 5.],
[11.],
[13.],
[15.],
[17.]]), predicted: tensor([[ 4.9567],
[10.9867],
[12.9966],
[15.0066],
[17.0166]], grad_fn=<AddBackward0>), loss: 0.0004764374461956322, weight: tensor([[2.0100]], requires_grad=True), bias: 0.936755359172821
validating x: tensor([[12.],
[ 1.]]), y: tensor([[25.],
[ 3.]]), predicted: tensor([[25.0564],
[ 2.9469]])
validating accuracy: 0.99001544713974
testing x: tensor([[ 9.],
[13.]]), y: tensor([[19.],
[27.]]), predicted: tensor([[19.0265],
[27.0664]])
testing accuracy: 0.998073160648346
嗯?這回怎么用了 1103 次才訓練成功?這是因為 weight 和 bias 調整的方向始終都是一致的,所以只用一個批次訓練反而會更慢,在之后的文章中,我們會用更多的引數 (神經元) 來訓練,而它們可以有不同的調整方向,所以不會出現這個例子中的問題,當然,業務上有的時候會出現因為引數調整方向全部一致導致訓練很慢,或者根本無法收斂的問題,這個時候我們可以通過更換模型,或者切分多個批次來解決,
劃分訓練集,驗證集和測驗集的例子
上面的例子定義訓練集,驗證集和測驗集的時候都是一個個 tensor 的定義,有沒有覺得很麻煩?我們可以通過 pytorch 提供的 tensor 操作來更方便的劃分它們:
# 原始資料集
>>> dataset = [(1, 3), (2, 5), (5, 11), (6, 13), (7, 15), (8, 17), (9, 19), (12, 25), (13, 27)]
# 轉換原始資料集到 tensor,并且指定數值型別為浮點數
>>> dataset_tensor = torch.tensor(dataset, dtype=torch.float32)
>>> dataset_tensor
tensor([[ 1., 3.],
[ 2., 5.],
[ 5., 11.],
[ 6., 13.],
[ 7., 15.],
[ 8., 17.],
[ 9., 19.],
[12., 25.],
[13., 27.]])
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
>>> torch.random.manual_seed(0)
<torch._C.Generator object at 0x10cc03070>
# 生成隨機索引值, 用于打亂資料順序防止分布不均
>>> dataset_tensor.shape
torch.Size([9, 2])
>>> random_indices = torch.randperm(dataset_tensor.shape[0])
>>> random_indices
tensor([8, 0, 2, 3, 7, 1, 4, 5, 6])
# 計算訓練集,驗證集和測驗集的索引值串列
# 60 % 的資料劃分到訓練集,20 % 的資料劃分到驗證集,20 % 的資料劃分到測驗集
>>> traning_indices = random_indices[:int(len(random_indices)*0.6)]
>>> traning_indices
tensor([8, 0, 2, 3, 7])
>>> validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
>>> validating_indices
tensor([1, 4])
>>> testing_indices = random_indices[int(len(random_indices)*0.8):]
>>> testing_indices
tensor([5, 6])
# 劃分訓練集,驗證集和測驗集
>>> traning_set_x = dataset_tensor[traning_indices][:,:1] # 第一維度不截取,第二維度截取索引值小于 1 的元素
>>> traning_set_y = dataset_tensor[traning_indices][:,1:] # 第一維度不截取,第二維度截取索引值大于或等于 1 的元素
>>> traning_set_x
tensor([[13.],
[ 1.],
[ 5.],
[ 6.],
[12.]])
>>> traning_set_y
tensor([[27.],
[ 3.],
[11.],
[13.],
[25.]])
>>> validating_set_x = dataset_tensor[validating_indices][:,:1]
>>> validating_set_y = dataset_tensor[validating_indices][:,1:]
>>> validating_set_x
tensor([[2.],
[7.]])
>>> validating_set_y
tensor([[ 5.],
[15.]])
>>> testing_set_x = dataset_tensor[testing_indices][:,:1]
>>> testing_set_y = dataset_tensor[testing_indices][:,1:]
>>> testing_set_x
tensor([[8.],
[9.]])
>>> testing_set_y
tensor([[17.],
[19.]])
寫成代碼如下:
# 原始資料集
dataset = [(1, 3), (2, 5), (5, 11), (6, 13), (7, 15), (8, 17), (9, 19), (12, 25), (13, 27)]
# 轉換原始資料集到 tensor
dataset_tensor = torch.tensor(dataset, dtype=torch.float32)
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
torch.random.manual_seed(0)
# 切分訓練集,驗證集和測驗集
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:1]
traning_set_y = dataset_tensor[traning_indices][:,1:]
validating_set_x = dataset_tensor[validating_indices][:,:1]
validating_set_y = dataset_tensor[validating_indices][:,1:]
testing_set_x = dataset_tensor[testing_indices][:,:1]
testing_set_y = dataset_tensor[testing_indices][:,1:]
注意改變資料分布可以影響訓練速度,你可以試試上面的代碼經過多少次訓練可以訓練成功 (達到 99 % 的正確率),不過,資料越多越均勻,分布對訓練速度的影響就越少,
定義模型類 (torch.nn.Module)
如果我們想把自己寫好的模型提供給別人用,或者用別人寫好的模型,應該怎么辦呢?pytorch 提供了封裝模型的基礎類 torch.nn.Module,上面例子中的模型可以改寫如下:
# 參考 pytorch 和顯示圖表使用的 matplotlib
import torch
from matplotlib import pyplot
# 定義模型
# 模型需要定義 forward 函式接收輸入并回傳預測輸出
# add_history 和 show_history 是自定義函式,它們僅用于幫助我們理解機器學習的原理,實際不需要這樣做
class MyModle(torch.nn.Module):
def __init__(self):
# 初始化基類
super().__init__()
# 定義引數
# 需要使用 torch.nn.Parameter 包裝,requires_grad 不需要設定 (會統一幫我們設定)
self.weight = torch.nn.Parameter(torch.tensor([[1.0]]))
self.bias = torch.nn.Parameter(torch.tensor(0.0))
# 記錄 weight 與 bias 的歷史值
self.weight_history = [self.weight[0][0].item()]
self.bias_history = [self.bias.item()]
def forward(self, x):
# 計算預測值
predicted = x.mm(self.weight) + self.bias
return predicted
def add_history(self):
# 記錄 weight 和 bias 的歷史值
self.weight_history.append(self.weight[0][0].item())
self.bias_history.append(self.bias.item())
def show_history(self):
# 顯示 weight 與 bias 的變化
pyplot.plot(self.weight_history, label="weight")
pyplot.plot(self.bias_history, label="bias")
pyplot.legend()
pyplot.show()
# 創建模型實體
model = MyModle()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
# 呼叫 parameters 函式可以自動遞回獲取模型中的引數串列 (注意是遞回獲取,嵌套模型也能支持)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 原始資料集
dataset = [(1, 3), (2, 5), (5, 11), (6, 13), (7, 15), (8, 17), (9, 19), (12, 25), (13, 27)]
# 轉換原始資料集到 tensor
dataset_tensor = torch.tensor(dataset, dtype=torch.float32)
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 切分訓練集,驗證集和測驗集
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:1]
traning_set_y = dataset_tensor[traning_indices][:,1:]
validating_set_x = dataset_tensor[validating_indices][:,:1]
validating_set_y = dataset_tensor[validating_indices][:,1:]
testing_set_x = dataset_tensor[testing_indices][:,:1]
testing_set_y = dataset_tensor[testing_indices][:,1:]
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
# 計算預測值
predicted = model(traning_set_x)
# 計算損失
loss = loss_function(predicted, traning_set_y)
# 列印除錯資訊
print(f"traning x: {traning_set_x}, y: {traning_set_y}, predicted: {predicted}, loss: {loss}, weight: {model.weight}, bias: {model.bias}")
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄 weight 和 bias 的歷史值
model.add_history()
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 顯示 weight 與 bias 的變化
model.show_history()
定義和使用模型類需要注意以下幾點:
- 必須在建構式
__init__中呼叫super().__init__()初始化基類 (一般 python 繼承類也需要這樣做) - 必須定義
forward函式接收輸入并回傳預測輸出 - 模型中定義引數需要使用
torch.nn.Parameter包裝,requires_grad不需要設定 (會統一幫我們設定) - 呼叫
model.parameters()可以遞回獲取引數串列 (支持嵌套模型),創建引數調整器時需要這個引數串列 - 在訓練前呼叫
model.train()開啟自動微分等功能 - 在驗證或者使用訓練好的模型前呼叫
model.eval關閉自動微分等功能
我們在后面繼續使用 pytorch 進行機器學習時,代碼的結構會基本和上面的例子一樣,只是模型和檢查驗證集測驗集的部分不同,此外,批次正規化與 Dropout 等功能會在后面的文章中介紹,
本篇就到此結束了,相信看到這里你已經掌握了用 pytorch 進行機器學習的基本模式??,
寫在最后
本篇介紹的東西也很基礎,但是這些基礎對應用機器學習必不可少,這兩篇的內容在很多機器學習教程中都沒有提到,它們直接就從多層線性模型開始講了,所以很多人會抱怨入門好難??,如果你看過 pytorch 出的官方書籍 《Deep Learning with Pytorch》可能會發現,這兩篇的介紹順序和這本書的介紹順序很接近,是的,寫這兩篇的時候我參考了這本書,按這個順序來理解是最容易的,
下一篇開始將會講解線性模型,激活函式和多層線性模型,并且會給出更接近實際的例子,但可能會需要更多時間,想看的耐心等等叭???,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/39011.html
標籤:其他
上一篇:計算機視覺影像預處理中的 Zero-mean(零均值化) 和 Normalization(歸一化)
下一篇:機器學習概述