關注并星標
從此不迷路
計算機視覺研究院



公眾號ID|ComputerVisionGzq
學習群|掃碼在主頁獲取加入方式
源代碼:https://arxiv.org/pdf/2112.08782.pdf
計算機視覺研究院專欄
作者:Edison_G
隨著世界邁向第四次工業革命,電動車越來越普遍,但是路上的交通標志也五花八門,如果利用計算機視覺技術可以全部檢測識別,那也是一大進步!
一、前言

交通標志檢測對于無人駕駛系統來說是一項具有挑戰性的任務,特別是對于多尺度目標的檢測和檢測的實時性問題,在交通標志檢測程序中,目標的尺度變化很大,會對檢測精度產生一定的影響,
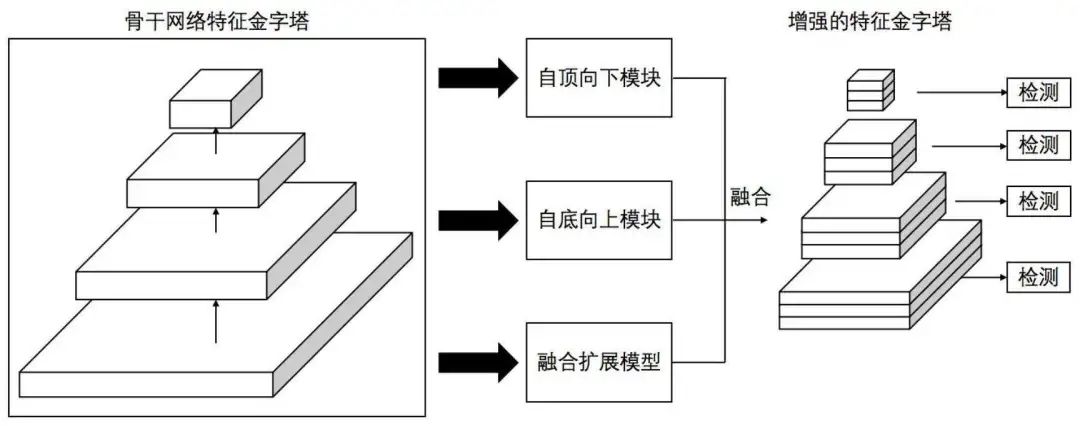
特征金字塔被廣泛用于解決這個問題,但它可能會破壞不同尺度交通標志的特征一致性,而且,在實際應用中,常用的方法很難在保證檢測實時性的同時提高多尺度交通標志的檢測精度,
在今天分享中,研究者提出了一種改進的特征金字塔模型,命名為AF-FPN,它利用自適應注意力模塊(AAM)和特征增強模塊(FEM)來減少特征圖生成程序中的資訊丟失并增強表示能力的特征金字塔,將YOLOv5中原有的特征金字塔網路替換為AF-FPN,在保證實時檢測的前提下提高了YOLOv5網路對多尺度目標的檢測性能,此外,提出了一種新的自動學習資料增強方法來豐富資料集并提高模型的魯棒性,使其更適合實際場景,在Tsinghua-Tencent 100K (TT100K) 資料集上的大量實驗結果證明了與幾種最先進的方法相比所提出的方法的有效性和優越性,
二、背景

交通標志識別系統化是自動駕駛中最重要的一部分,怎樣去提升交通標志檢測和識別技術的精度和實時性能,這個也是現在當技術實際落地時需要解決的重要問題,傳統的CNN通常需要大量的引數和浮點運算 (FLOP) 以達到準確性令人滿意的效果,例如ResNet-50有大約2560萬個引數和需要4.1B FLOPs來處理大小為224×224的影像,然而,移動設備(例如智能手機和自動駕駛汽車)有限的記憶體和計算資源不能用于大型網路的部署和推理,作為一個one-stage檢測器,使用YOLOv5是由于具有計算量小、速度快的優點,
三、新框架詳細分析
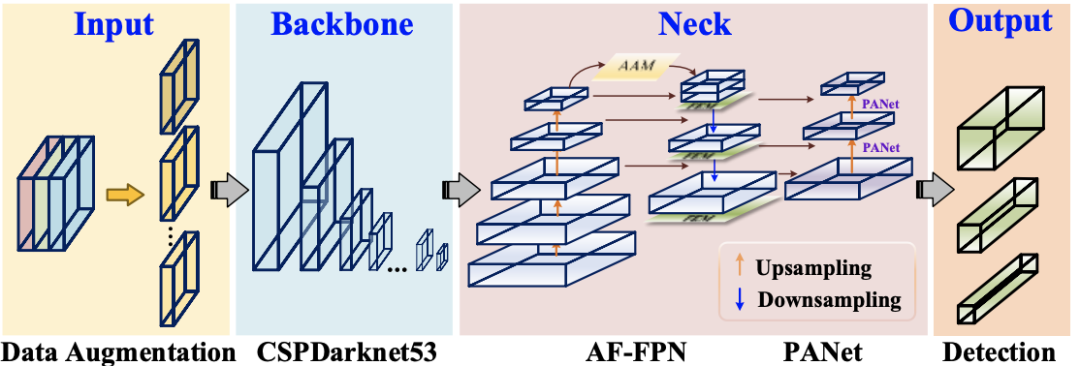
The improved YOLOv5s network framework
作為當前YOLO系列中的最新框架,卓越的YOLOv5其靈活性使其便于快速在車輛硬體方面進行部署,YOLOv5包含四個模型,分別是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,YOLOv5s是YOLO系列最小的模型,更適合部署在車載移動硬體平臺,由于其記憶體大小為14.10M,但識別精度達不到準確、高效識別的要求,尤其是用于識別小規模目標,YOLOv5的基本框架可以分為四個部分:input、backbone、neck和prediction,Input部分通過資料增強來豐富資料集,它具有對硬體設備要求低,計算量成本低,但是它會導致資料集中原來的小目標變小,從而導致資料集的惡化,降低模型的泛化性能,Backbone部分主要由CSP模塊組成,它們通過CSPDarknet53執行特征提取,FPN和PANet用于聚合Neck現階段的影像特征,最后,網路通過Prediction進行目標預測和輸出,
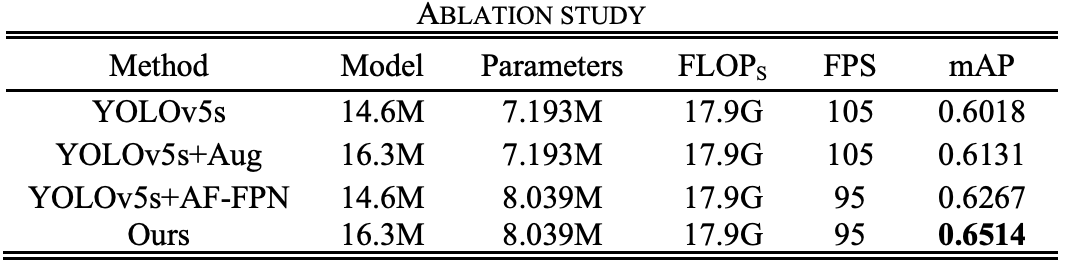
研究者引入AF-FPN和自動學習資料增強來解決模型大小和識別精度不兼容的問題,進一步提高模型的識別性能,將原有的FPN結構替換為AF-FPN,以提高識別多尺度目標的能力,并在識別速度和準確率之間做出有效的權衡,
此外,研究者去除原始網路中的mosaic augmentation,并根據自動學習資料增強策略使用最佳資料增強方法來豐富資料集并提高訓練效果,改進后的YOLOv5s網路結構如下圖所示,
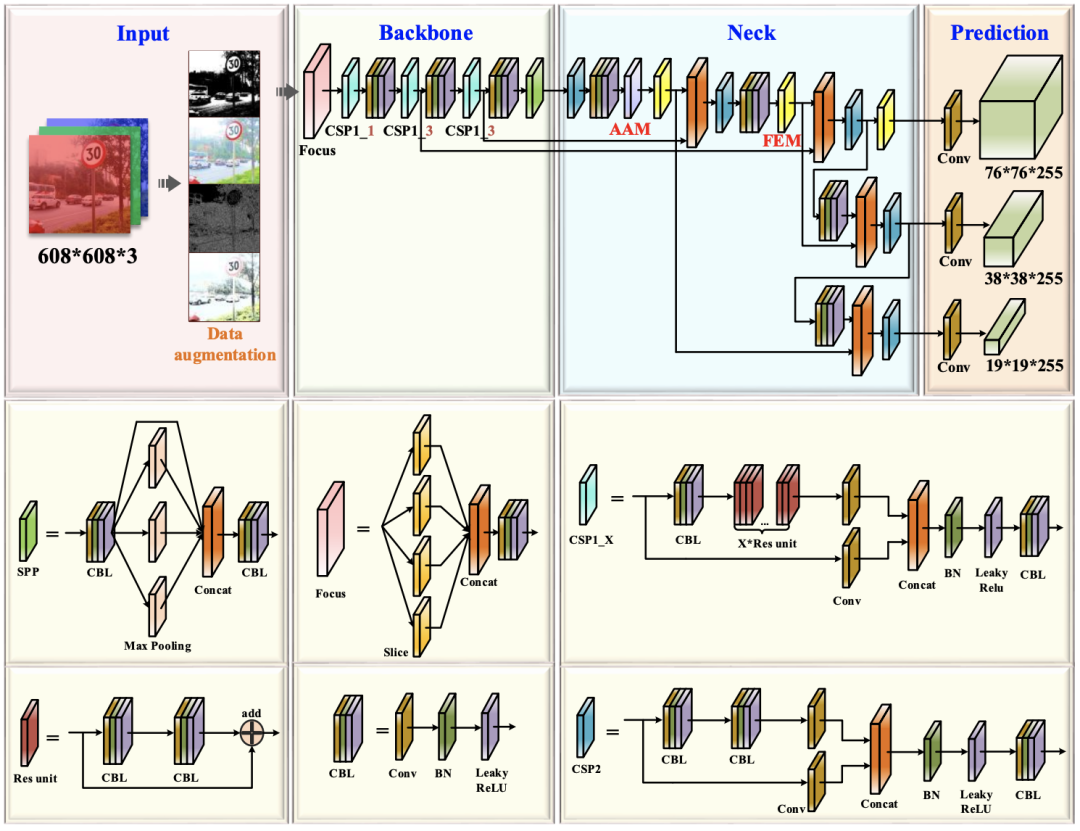
AF-FPN structure
AF-FPN在傳統特征金字塔網路的基礎上,增加了自適應注意力模塊(AAM)和特征增強模塊(FEM),前一部分由于減少了特征通道,減少了在高層特征圖中背景關系資訊的丟失;后一部分增強了特征金字塔的表示并加快了推理速度,同時實作了最先進的性能,AF-FPN的結構如下圖所示,
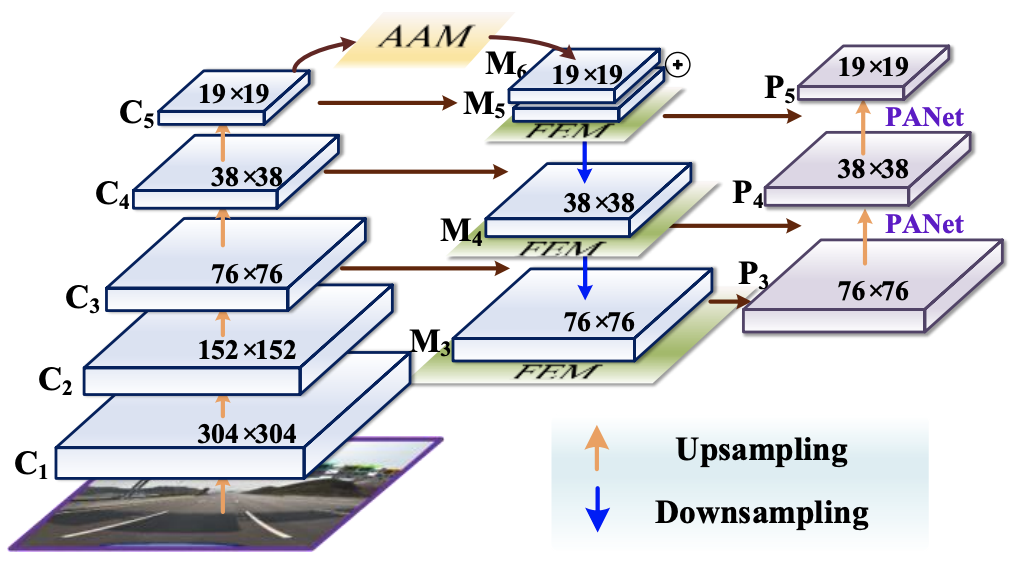
AAM的具體結構如下圖所示,作為自適應注意力模塊的輸入,C5的大小為S=h×w,它首先通過自適應池化層獲得不同尺度(β1×S,β2×S,β3×S)的背景關系特征,然后每個背景關系特征經過1×1卷積,得到相同的通道維度256,使用雙線性插值將它們上采樣到S的尺度,用于后續融合,
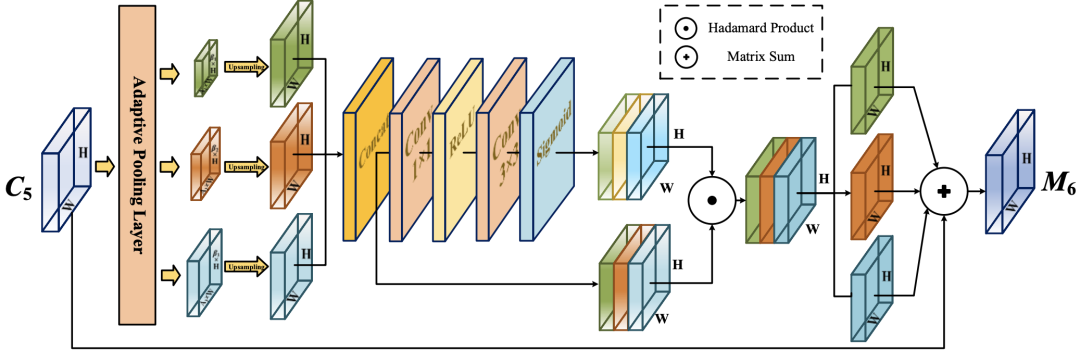
空間注意力機制通過一個Concat層將三個背景關系特征的通道合并,然后特征圖依次通過1×1卷積層、ReLU激活層、3×3卷積層和sigmoid激活層生成對應的空間權重,生成的權重圖和合并通道后的特征圖進行Hadamard乘積運算,分離后加入到輸入特征圖M5中,將背景關系特征聚合到M6中,最終的特征圖具有豐富的多尺度背景關系資訊,在一定程度上緩解了由于通道數減少而造成的資訊丟失,
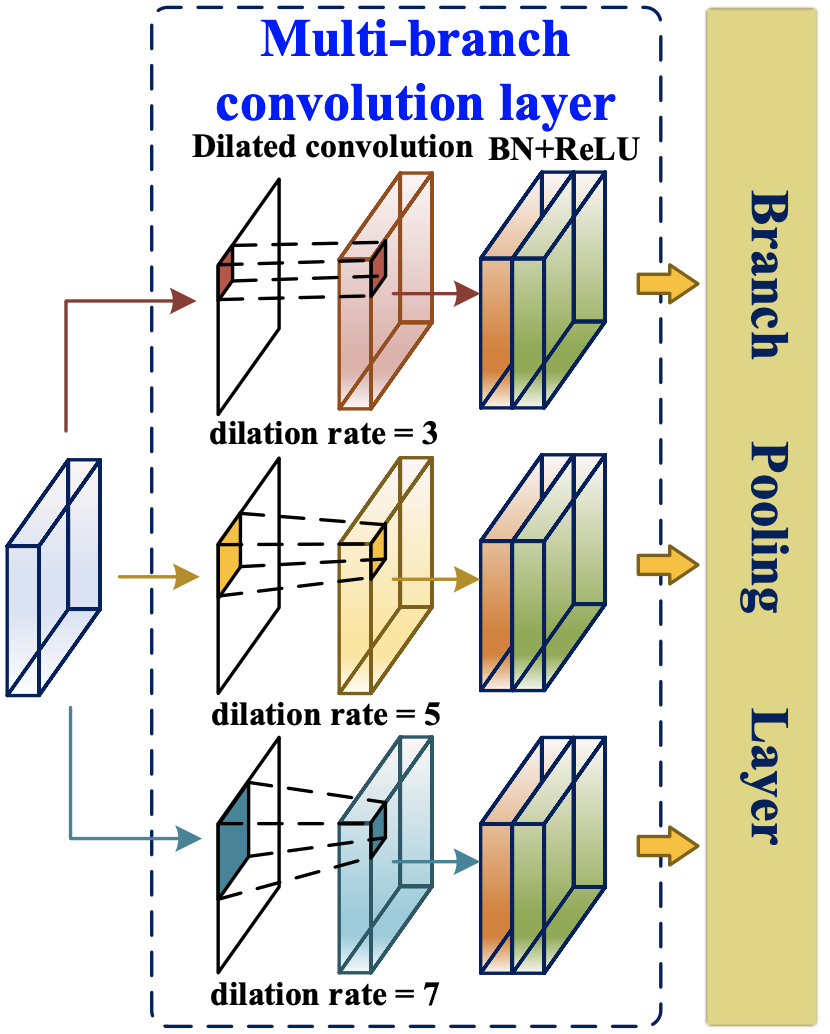
FEM主要利用空洞卷積根據檢測到的交通標志的不同尺度自適應學習每個特征圖中不同的感受野,從而提高多尺度目標檢測和識別的準確性,如上圖所示,它可以分為兩個部分:多分支卷積層和多分支池化層,多分支卷積層用于通過空洞卷積為輸入特征圖提供不同大小的感受野,并且平均池化層用于融合來自三個分支感受野的交通資訊,以提高多尺度預測的準確性,
Data Augmentation
資料增強我就簡單描述下,具體如下示例:

四、實驗結果及可視化
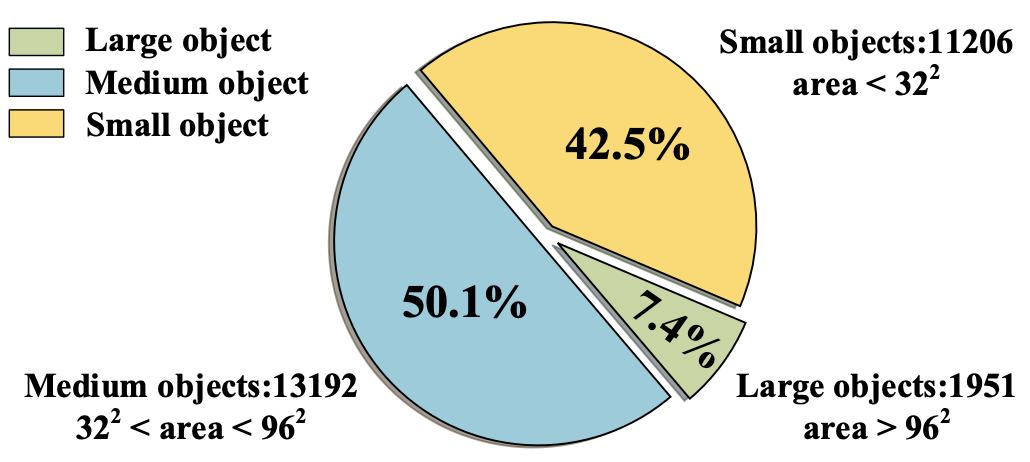
Size distribution of sign instances from the TT100K
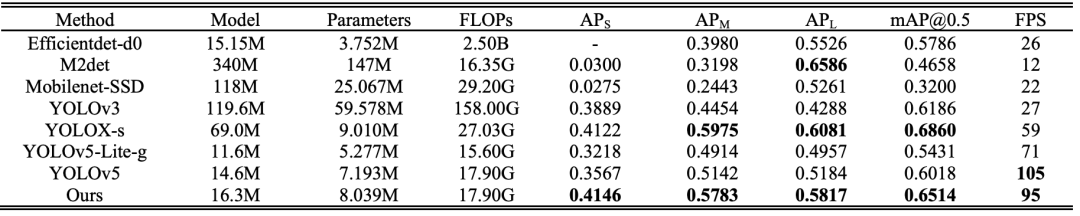
在TT100K資料集上與其他模型的性能比較
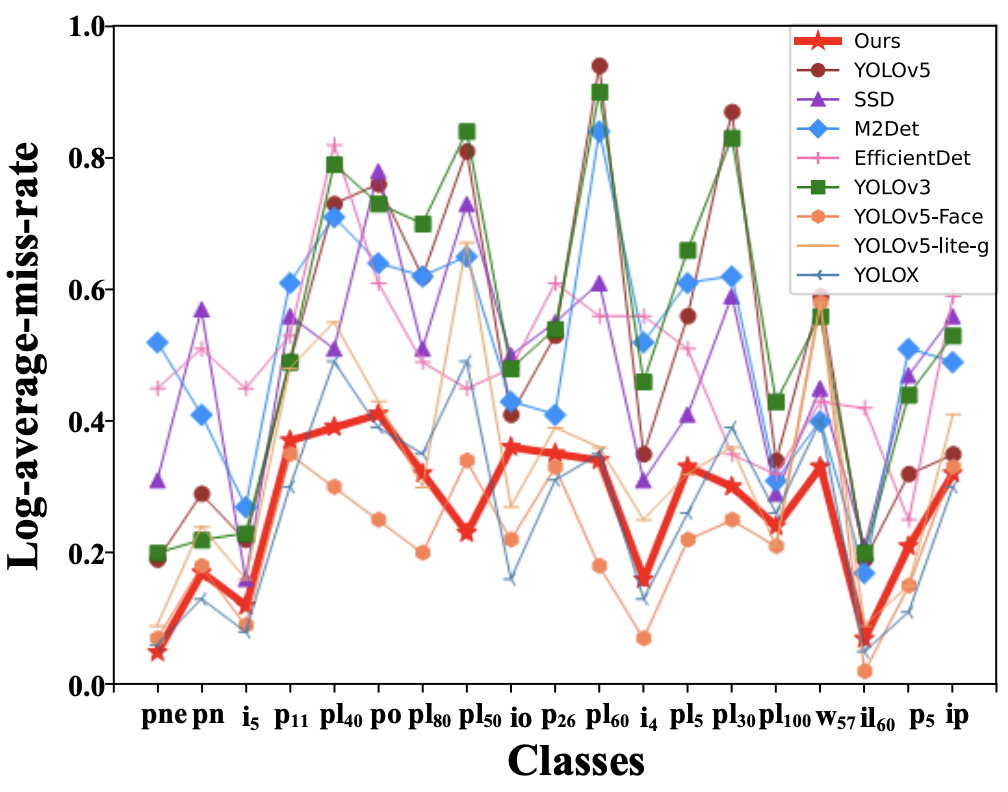
每種方法對19種交通標志的漏檢率比較

移動設備部署及通過攝像頭拍攝的檢測實體

? The Ending
轉載請聯系本公眾號獲得授權

計算機視覺研究院學習群等你加入!
計算機視覺研究院主要涉及深度學習領域,主要致力于人臉檢測、人臉識別,多目標檢測、目標跟蹤、影像分割等研究方向,研究院接下來會不斷分享最新的論文演算法新框架,我們這次改革不同點就是,我們要著重”研究“,之后我們會針對相應領域分享實踐程序,讓大家真正體會擺脫理論的真實場景,培養愛動手編程愛動腦思考的習慣!

掃碼關注
計算機視覺研究院
公眾號ID|ComputerVisionGzq
學習群|掃碼在主頁獲取加入方式
往期推薦
🔗
用于吸煙行為檢測的可解釋特征學習框架(附論文下載)
影像自適應YOLO:惡劣天氣下的目標檢測(附源代碼)
新冠狀病毒自動口罩檢測:方法的比較分析(附源代碼)
NüWA:女媧演算法,多模態預訓練模型,大殺四方!(附源代碼下載)
實用教程詳解:模型部署,用DNN模塊部署YOLOv5目標檢測(附源代碼)
LCCL網路:相互指導博弈來提升目標檢測精度(附源代碼)
Poly-YOLO:更快,更精確的檢測(主要解決Yolov3兩大問題,附源代碼)
ResNet超強變體:京東AI新開源的計算機視覺模塊!(附源代碼)
Double-Head:重新思考檢測頭,提升精度(附原論文下載)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390504.html
標籤:其他