碼字不易,點個贊再走唄
1. 中科院大學高清航拍目標資料集合(UCAS-AOD)-3.25G
1.1基本資訊
UCAS-AOD (Zhu et al.,2015)用于飛機和汽車的檢測,包含飛機與汽車2類樣本以及一定數量的反例樣本(背景),總共包含2420幅影像和14596個實體,論文中特別提到了目標檢測的方向健壯性,所以在資料集標注程序中作者對資料進行了一定程度的篩選,使得影像中的物體方向分布均勻,資料集具體內容如下:

1.2資料說明
1.2.1影像定義
本資料集中目標為航拍影像下的飛機和車輛,
1.2.2資料來源
使用Google Earth軟體在全球部磁區域中截取的影像
1.2.3資料格式
資料集分為CAR、PLANE、NEG三個檔案,CAR、PLANE為正例影像,NEG為反例影像,正例影像以P+數字序號命名,反例影像以N+數字序號命名,所有影像為PNG格式,尺寸為1280x659和1372x941,
1.2.4樣本標注
UCAS-AOD采用HBB(horizontal bounding box)的標注方法,影像的groundtruth采用txt格式保存,以影像的同名檔案方式存盤,對于整理好的txt檔案資料,每列的屬性分別為x1,y1,x2,y2,x3,y3,x4,y4,theta,x,y, width,height,屬性說明如下:

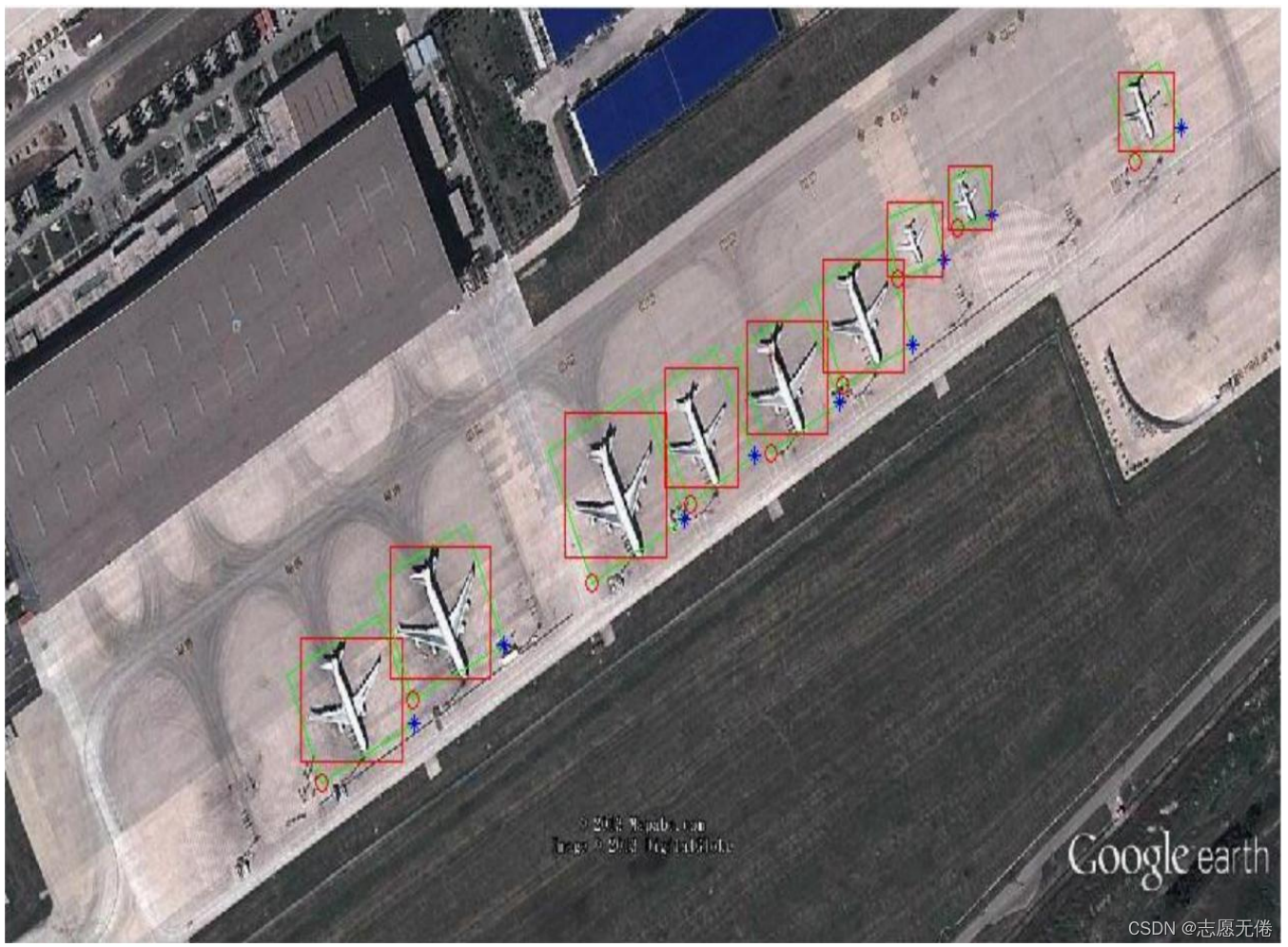
1.3資料示例
x1,y1,x2,y2,x3,y3,x4,y4為飛機的矩形框,即下圖中的綠色框;
theta為機尾指向機頭的向量與x軸正向的夾角;
x,y,width,height 為飛機的bounding box,即圖中的紅色矩形框,
具體的標注示意如下圖所示:

2. 西工大高解析度輪船識別資料集(HRSC2016)-3.86G
2.1基本資訊
HRSC2016 (Liu et al.,2016)是西北工業大學采集的用于輪船的檢測的資料,包含4個大類19個小類共2976個船只實體資訊,論文中特別指出他們的資料集是高解析度資料集,解析度介于0.4m和2m之間,資料集所有影像均來自六個著名的港口,包括海上航行的船只和靠近海岸的船只,船只影像的尺寸范圍從300到1500,大多數影像大于1000x600,
2.2資料說明
2.2.1目標影像定義
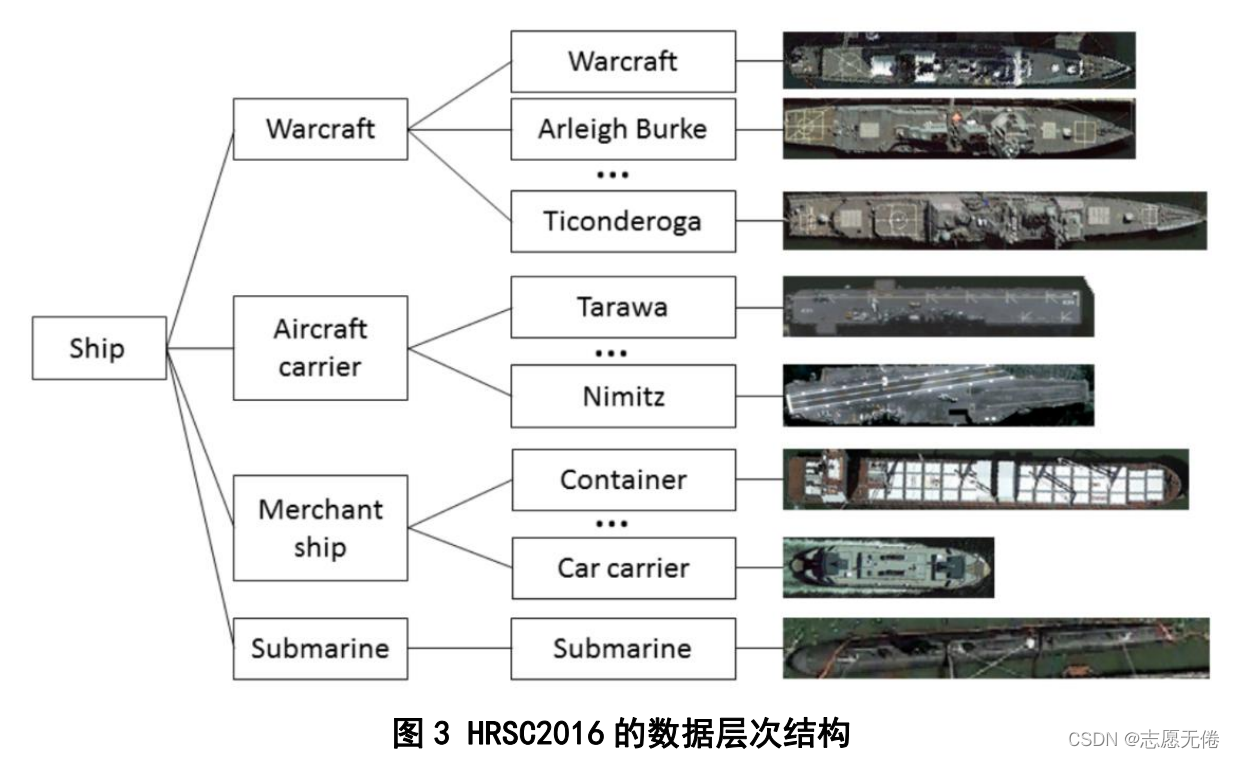
本資料集中目標為航拍影像下的船只,包括海上船只與近岸船只,作者在對船只模型進行分類時采用
了高度為3的樹形結構,L1層次為Class、L2層次為category、L3層次為Type,類似生物學的分類觀
點,具體表示如下:
2.2.2資料來源
使用Google Earth軟體在全球部磁區域中截取的影像,既包括Google Earth默認顯示的圖片,
又包括相同地點的歷史圖片,
2.2.3資料格式及規模
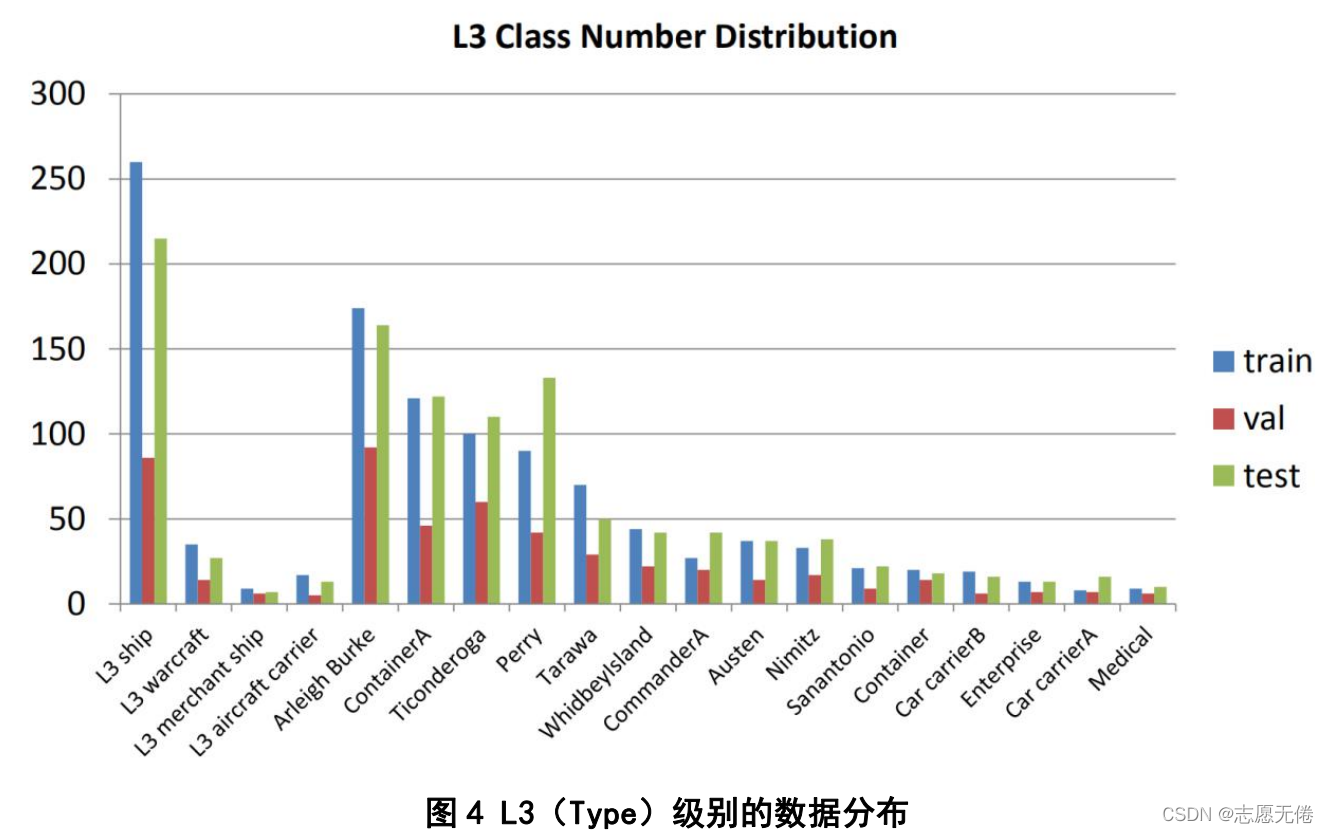
資料集分為Train、Test、ImageSets三個檔案,Train、Test目錄分為只包含船只影像的AllImages和只包含注釋資訊的Annotations,影像以港口序號順序命名、以bmp格式存盤,影像的注釋資訊以xml檔案存盤,此外,Test檔案下的Segmentations檔案還包含了船只分割影像,即語意分割的標簽,以png格式存盤,訓練、驗證和測驗集分別包含436個影像(包括1207個樣本)、181個影像(包括541個樣本)和444個影像(包括1228個樣本),ImageSets目錄下包含train.txt、val.txt、trainval.txt以及test.txt,保存了訓練集、驗證集、交叉驗證集、測驗集的圖片編號,各類樣本在訓練集、驗證集、測驗集中的分布如下所示:
2.2.4樣本標注資訊
HRSC2016采用OBB(oriented bounding box)的標注方法,提供了三類標注資訊,包括bounding box、rotated bounding box和pixel-based segmentation,還包括港口、資料源、拍攝時間等額外資訊,部分資料標注展示如下:
<HRSC_Image>
<Img_CusType>sealand</Img_CusType>
<Img_Location>69.040297,33.070036</Img_Location>
<Img_SizeWidth>1138</Img_SizeWidth>
<Img_SizeHeight>833</Img_SizeHeight>
<Img_SizeDepth>3</Img_SizeDepth>
<Img_Resolution>1.07</Img_Resolution>
<Img_Resolution_Layer>18</Img_Resolution_Layer>
<Img_Scale>100</Img_Scale>
<segmented>0</segmented>
<Img_Havemask>0</Img_Havemask>
<Img_Rotation>274d</Img_Rotation>
<HRSC_Objects>
<HRSC_Object>
<Object_ID>100000008</Object_ID>
<Class_ID>100000013</Class_ID>
<Object_NO>100000008</Object_NO>
<truncated>0</truncated>
<difficult>0</difficult>
<box_xmin>628</box_xmin>//bounding box坐標點
<box_ymin>40</box_ymin>
<box_xmax>815</box_xmax>
<box_ymax>783</box_ymax>
<mbox_cx>719.9324</mbox_cx>//旋轉后的左上角坐標
<mbox_cy>413.0048</mbox_cy>
<mbox_w>741.8246</mbox_w>
<mbox_h>172.6959</mbox_h>
<mbox_ang>1.499893</mbox_ang>//旋轉角度
<segmented>0</segmented>
<seg_color>
</seg_color>
<header_x>713</header_x>//船頭部資訊
<header_y>777</header_y>
</HRSC_Object>
</HRSC_Objects>
</HRSC_Image>
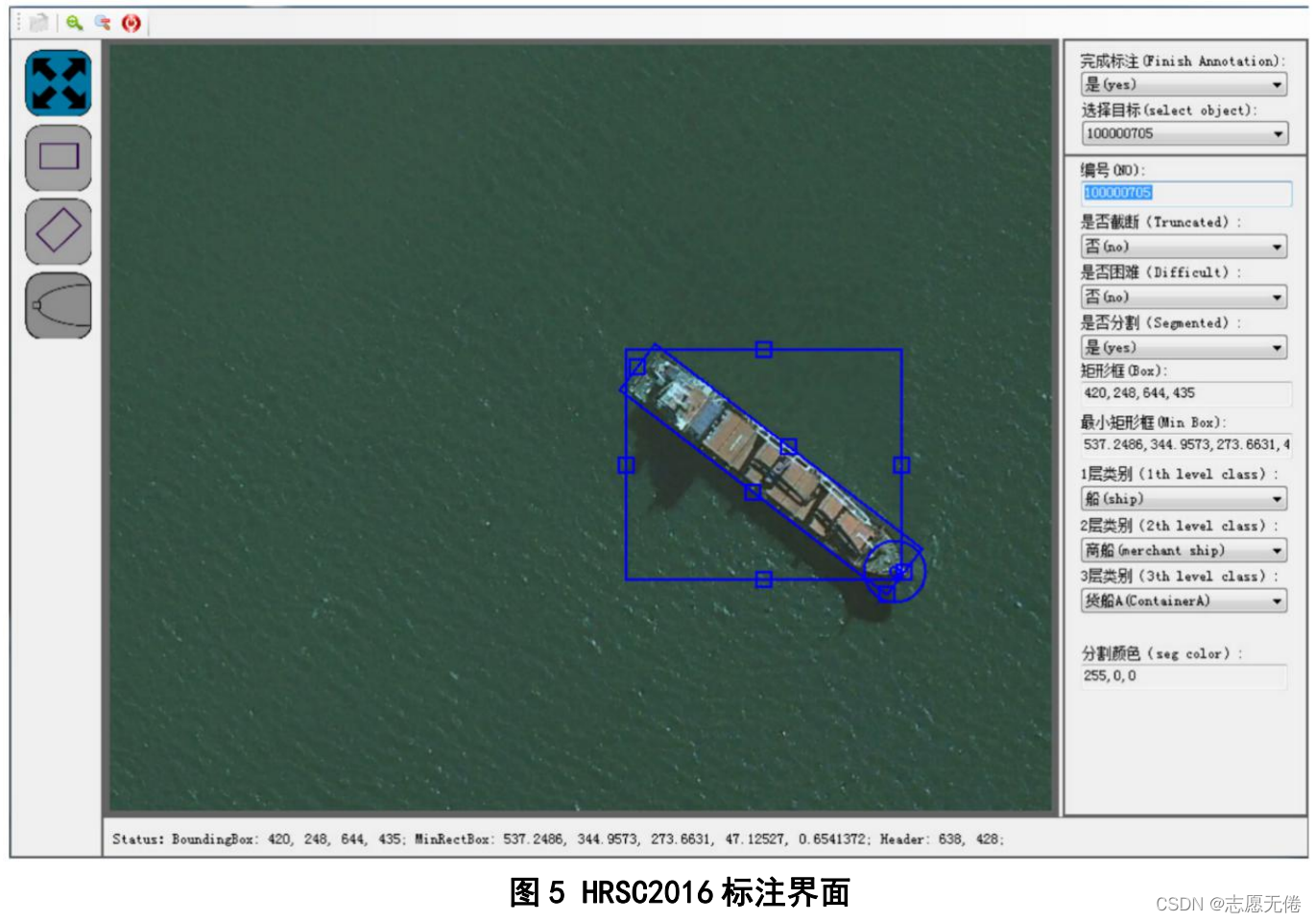
標注頁面如下圖所示:
2.3資料示例

3. 西工大高解析度遙感影像資料集(NWPU VHR-10)-73.1M
3.1基本資訊
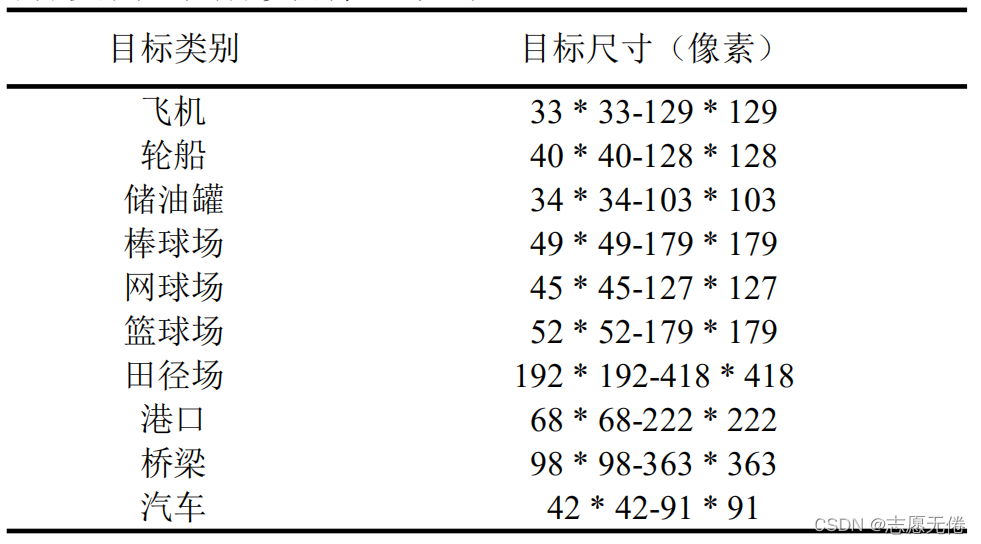
NWPU VHR-10 (Cheng et al.,2016) 這個高解析度(VHR)遙感影像資料集是由西北工業大學(NWPU)構建的,包含10類正例樣本650張以及不包含給定物件類的任何目標的150張反例影像(背景),正例影像中至少包含1個實體,總共有3651個目標實體,具體類別資訊如下:
3.2資料說明
3.2.1目標影像定義
本資料集中目標為航拍影像下的目標種類,包括飛機、艦船、油罐、棒球場、網球場、籃球場、田徑場、港口、橋梁和汽車共計10個類別,
3.2.2資料來源
715幅高解析度影像使用Google Earth軟體在全球部磁區域中截取,85幅超高解析度影像CIR由德國攝影測量、遙感和地理資訊學會(DGPF)提供,Google Earth截取影像的解析度介于0.5m到2m,CIR影像解析度為0.08m,
3.2.3資料格式
資料集分為positive image set、negative image set、ground truth三個檔案
positive image set目錄下為正例影像,negative image set目錄下為反例影像
正例、反例影像皆從001開始命名,所有影像為jpg格式,
3.2.4樣本標注資訊
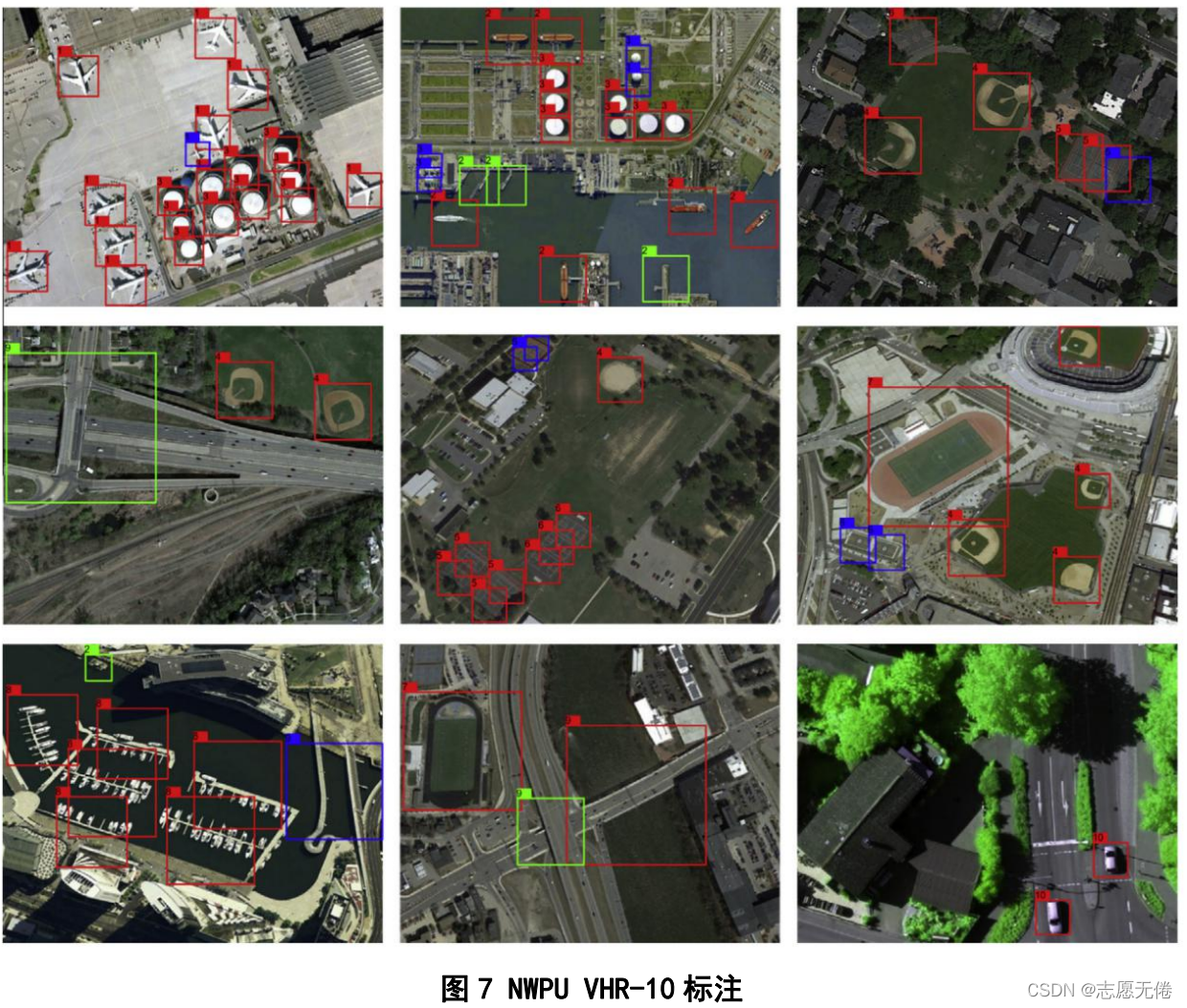
NWPU VHR-10采用HBB的標注方法,ground truth檔案夾包含650個單獨的txt檔案,每個檔案對應于positive image set檔案夾中的一個影像,這些文本檔案的每一行都定義了一個ground truth邊界框,格式如下:
其中(x1,y1)為bounding box的左上角坐標,(x2,y2)為bounding box的右下坐標,a為物件類別(1-飛機、2-輪船、3-儲油罐、4-棒球場、5-網球場、6-籃球場、7田徑場、8-港口、9-橋梁、10-汽車),
3.3資料示例

4. 武大大規模航空影像目標檢測資料集(DOTA)-18.8G
4.1基本資訊
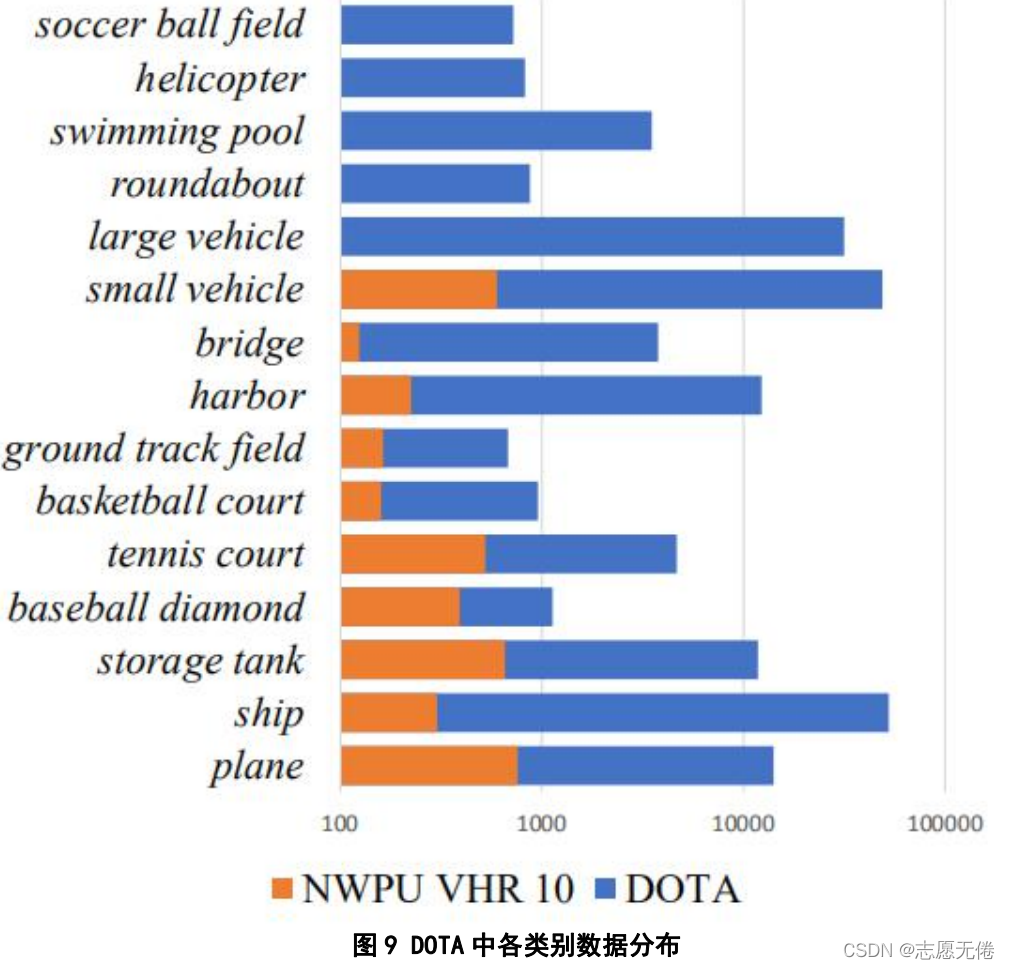
DOTA(Xia et al.,2018)是武大遙感國重實驗室和華科電信學院等合作的一個航拍影像資料集,包含2806張遙感影像(圖片尺寸800800到40004000),一共188282個實體,分為15個類別:飛機、船只、儲油罐、棒球場、網球場、籃球場、田徑場、海港、橋梁、大型車輛、小型車輛、直升飛機、足球場、立交路口、游泳池,資料集具體內容如下:
4.2資料說明
4.2.1目標影像定義
DOTA在提出之時可以稱得上規模最大的航空影像資料集,DOTA與NWPU VHR-10等資料集相比,前
10類資料雖然都有,但是DOTA的資料量更多、資料注釋更加豐富,此外,DOTA還將車輛資料分為大
型車輛與小型車輛,主要考慮兩者之間的明顯差異性;將直升飛機資料納入到資料集中,主要考慮移
動目標在航空圖片中也有十分顯著的作用;將立交路口納入到資料集中,主要考慮到它在道路分析中
的作用,
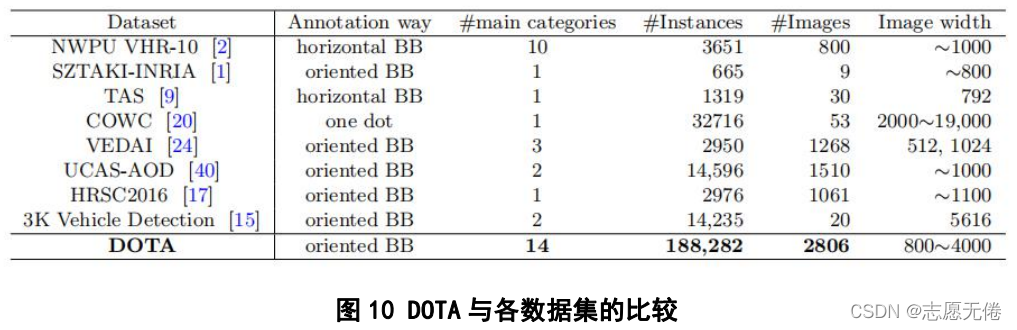
DOTA與當時的航空影像資料集進行了比較,指出了這些資料集普遍存在的缺點:1)資料規模小;
2)類別數量少;3)影像解析度低;4)注釋不豐富,并且無法形成資料與真實世界之間的映射,具體
比較如下所示:
4.2.2影像資料來源
使用Google Earth平臺和中國資源衛星資料和應用中心在全球部磁區域中截取影像,
4.2.3資料格式
資料集分為train、val、test三個檔案,三個檔案下都包含圖片資料images檔案夾,檔案中的圖片以
P+圖片編號命名,所有影像為PNG格式,影像尺寸介于800*800和4000*4000之間,實體尺寸介于0-
2500像素之間,具體實體尺寸分布如下圖所示:
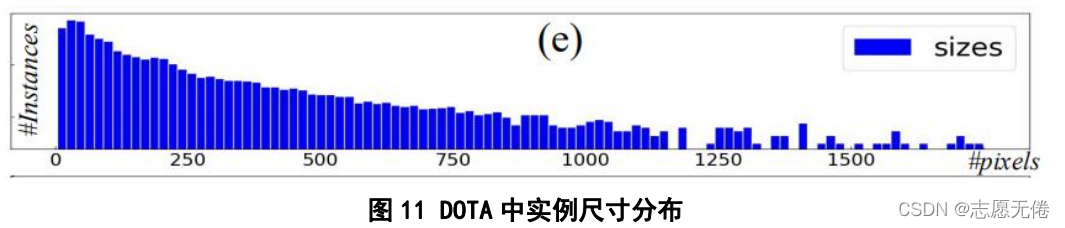
train、val檔案下還包含對應圖片的標注資訊,分為DOTA-v1.0和DOTA-v1.5版本, v1.5包含16個類別中的40萬個帶注釋的物件實體,是v1.0(15個類別)的更新版本,它們都使用相同的航拍影像,但是v1.5修改并更新了物件的注釋,主要對v1.0中標注的10像素以下的小物件實體進行了額外注釋,v1.5的類別也得到了擴展,增加了集裝箱起重機這一類別,
4.2.4樣本標注資訊
DOTA采用OBB的標注方法,影像的ground truth采用txt格式保存,以影像的同名txt檔案存盤,影像中
每個實體都由一個四點確定的任意形狀和方向的四邊形邊界框標注,頂點按順時針順序排列,檔案中
包含10列資訊,每列的屬性分別為x1,y1,x2,y2 x3,y3,x4,y4,category,difficult,屬性說明如下:

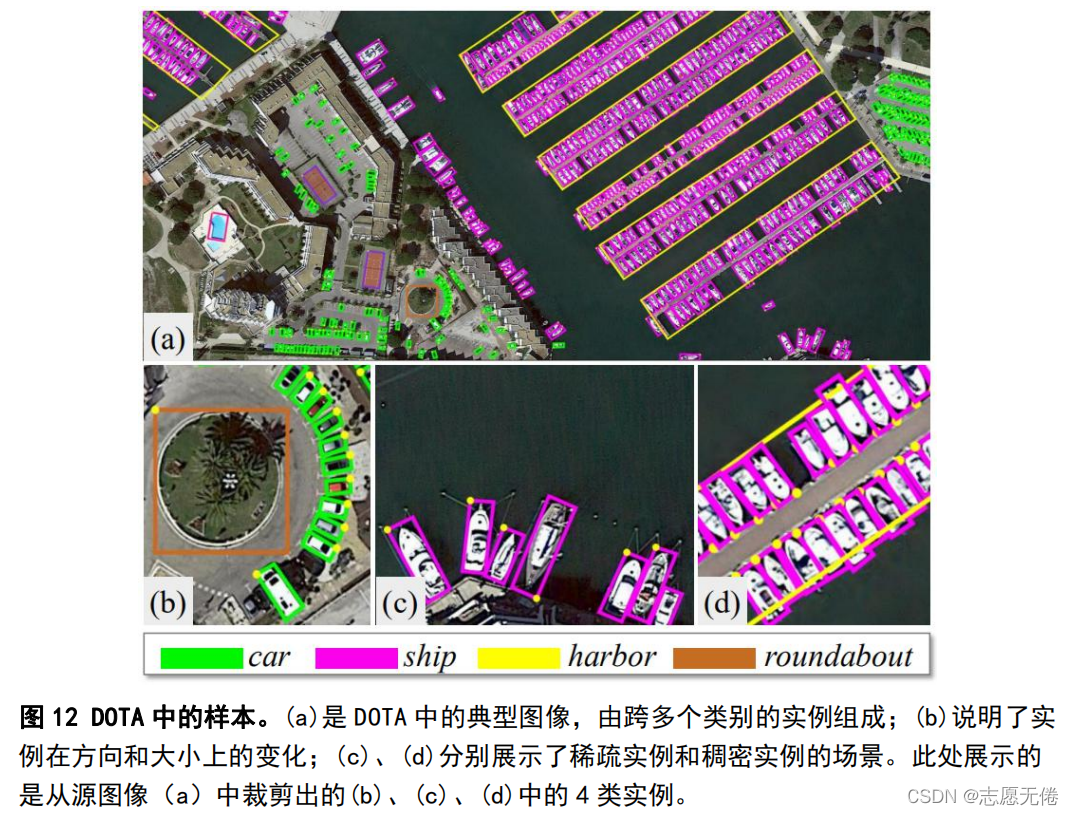
4.3資料示例

5. 光學遙感影像大規模基準資料集(DIOR)-7.19G
5.1基本資訊
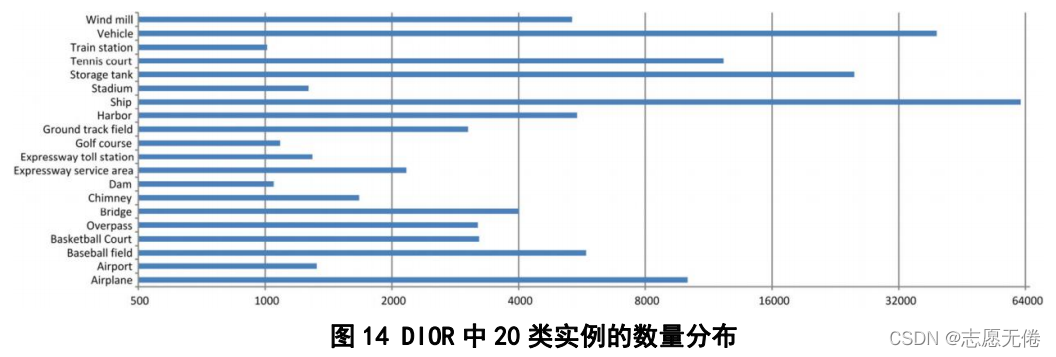
DIOR (Li e al.,2020)是由西工大韓軍偉課題組提出的一種用于光學遙感影像中目標檢測的大規模基準資料集,包含23463幅遙感影像(圖片尺寸為800*800)和190288個實體,同時論文也對近年來基于深度學習的目標檢測方法進行了綜述,資料集中的實體分為20個類別:飛機、飛機場、棒球場、籃球場、橋梁、煙囪(工業)、水壩、高速公路服務區、高速公路收費站、港口、高爾夫球場、田徑場、立交路口、體育館、儲油罐、網球場、火車站、汽車、風力發電機,各實體具體分布如下:
5.2資料說明
5.2.1目標類別選擇
DIOR資料集在選擇目標類別時,類似于DOTA采取的方法,既選擇了之前的資料集普遍存在的類別,
例如NWPU VHR-10中的10個類別,也考慮到了遙感影像目標監測任務的具體需求:
1) 交通基礎設施在運輸分析中至關重要,所以專案組將火車站、高速公路收費站、高速公路服務區等基礎設施納入進DIOR的類別中,
2) 大多數的目標類別是從市中心選取的,DIOR考慮了近郊地區的基礎設施,如水壩、風力發電機等設施,用以提高遙感資料的多樣性,
5.2.2資料來源
使用Google Earth軟體在全球部磁區域中截取的影像,
5.2.3資料格式
資料集分JPEGImages-trainval、JPEGImages-test、Annotations、ImageSets四個檔案夾,JPEGImages-trainval、JPEGImages-test中存放遙感影像(二者數量之比接近1:1),影像以5位序號命名,所有影像尺寸均為800*800、解析度介于0.5m到30m、格式均為JPG,Annotations中存放了23463張影像的注釋資訊,具體資訊如下:
<annotation>
<filename>00001.jpg</filename>
<source>
<database>DIOR</database>
</source>
<size>//圖片尺寸及深度
<width>800</width>
<height>800</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>golffield</name>//類別
<pose>Unspecified</pose>
<bndbox>
<xmin>133</xmin>//bounding box坐下角坐標(xmin,ymin)
<ymin>237</ymin>
<xmax>684</xmax>//右上角坐標(xmax,ymax)
<ymax>672</ymax>
</bndbox>
</object>
</annotation>
可以看得出,DIOR資料集規模雖然大,但是資料注釋比較簡略,采用了最基礎的Bounding box方法,
只包含兩個坐標點,ImageSets中存放的是訓練集、驗證集、測驗集的編號,以txt檔案存盤,用于制
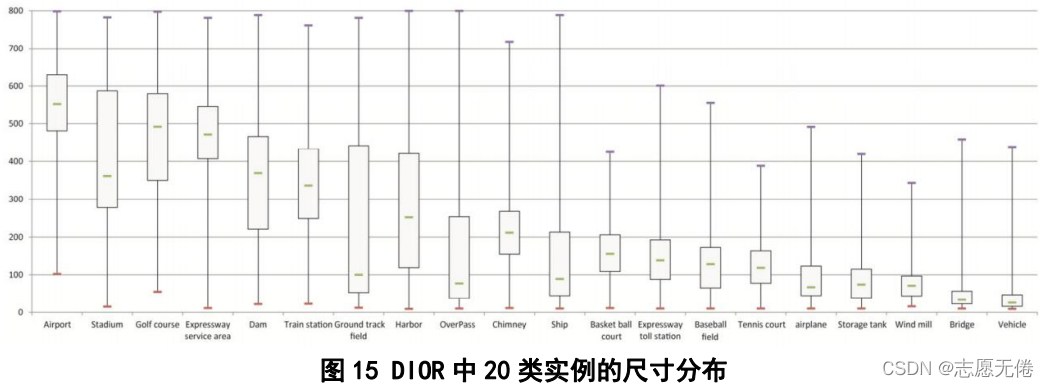
作DataLoader加載資料,另外,圖片中各實體的尺寸大小如下:
5.2.4樣本標注資訊
DIOR采用HBB的標注方法,使用Python腳本Labelme進行圖片標注,主要包含目標類別資訊及
Bounding Box左下角坐標和右上角坐標資訊,
5.2.5資料優勢
1)資料規模大,DIOR包含23463幅遙感影像及192472個目標實體,包含20類目標,
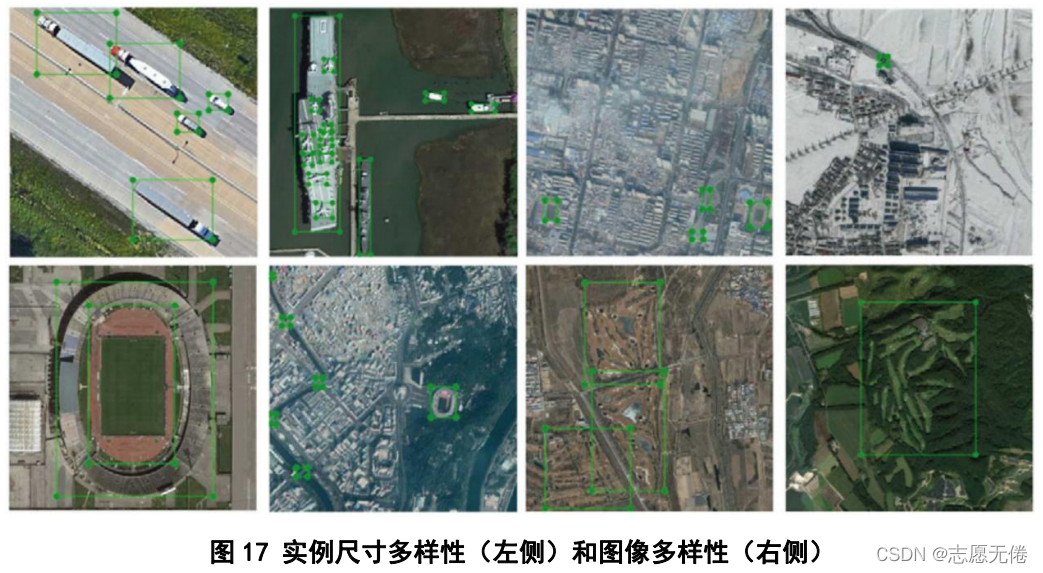
2)實體物件尺寸豐富,相同實體具有尺寸的多樣性,例如大型車輛與小型車輛、大型貨輪與小型游艇等,方便對不同尺寸的同類實體進行檢測,
3)影像多樣性豐富,DIOR資料集采集自全球80多個國家,覆寫了不同的天氣、季節、成像條件、影像質量等因素,能夠實作與現實世界的映射,
4)高類間(inter-class)相似性和高類內(intra-class)差異性,例如下圖所示的第一行圖片是不同類別的橋梁和水壩,二者具有類間相似性;第二行圖片是相同類別的工業煙囪,二者具有類內差異性, 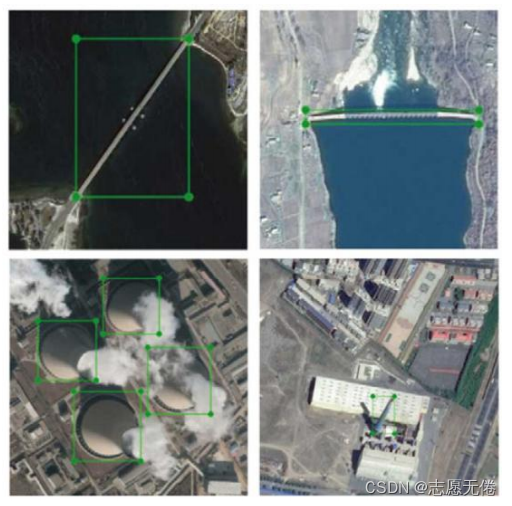
5.3資料示例

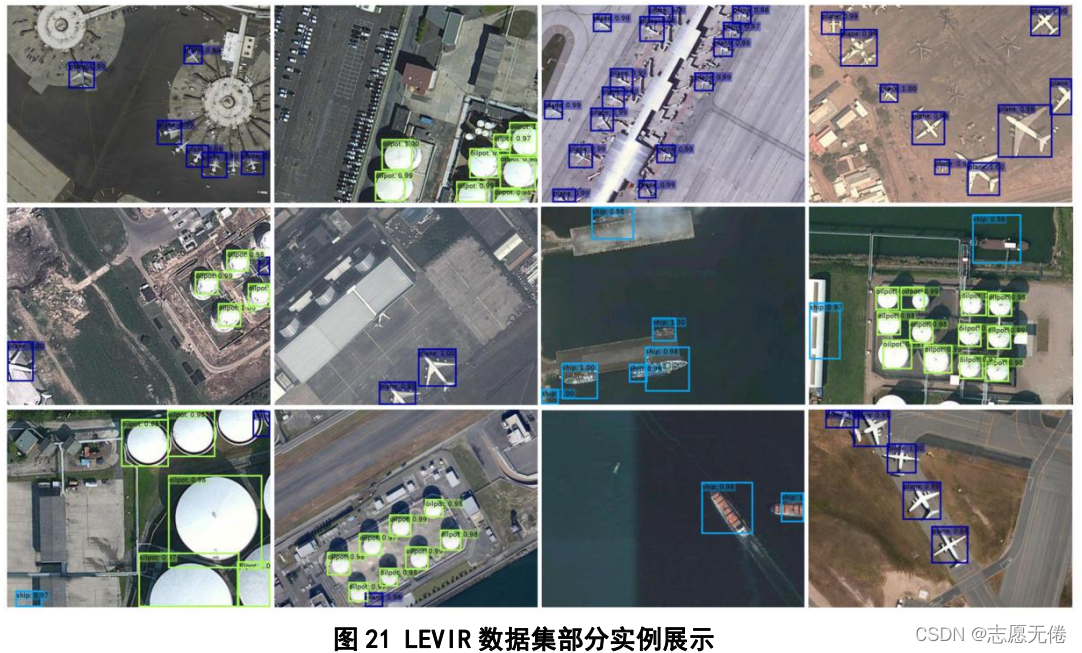
6. 北航遙感目標檢測資料集(LEVIR)-1.56G
6.1基本資訊
LEVIR (Shi et al.,2018)是由北航史振威教授領導的視覺與遙感實驗室提出的一種新的遙感目標檢測資料集,包含21952幅遙感影像(圖片尺寸為600*800)和11028個實體,資料集中的實體分為3個類別:飛機、船舶、儲油罐,其中,飛機實體有4724個、輪船實體有3025個、儲油罐實體有3279個,
6.2資料說明
6.2.1目標類別
LEVIR資料集容納了大多數人類居住環境的地表特征,例如城市、鄉村、山地和海洋等區域;不包含
極端的陸地環境,例如沙漠和冰川,資料集中有3種型別的目標:飛機、船舶(包括近海船只和離岸船
只)和儲油罐,
6.2.2資料來源
使用Google Earth軟體在全球部磁區域中截取的影像,
6.2.3資料格式
LEVIR資料集只包含imageWithLabel這1個檔案夾,檔案夾下是影像及對應的標注資訊,影像從00001開始順序命名,標注檔案格式為txt檔案,與對應的圖片同名,所有影像尺寸均為600*800、解析度介于0.2m到1m、格式均為JPG,注釋檔案中的標注資訊也很簡略,包含5列屬性,具體資訊如下:
label使用1、2、3標注,1代表飛機、2代表船舶、3代表儲油罐;
xmin-ymax即BB的左下角坐標和右上角坐標,
LEVIR資料集并沒有將正例和背景分開,所以雖然有20000+圖片,但是實體個數只有10000+,并且背景圖片也有相應的txt檔案所對應,且txt檔案中的內容為空,所以資料集中的txt檔案大多數是空檔案,
6.2.4資料優勢
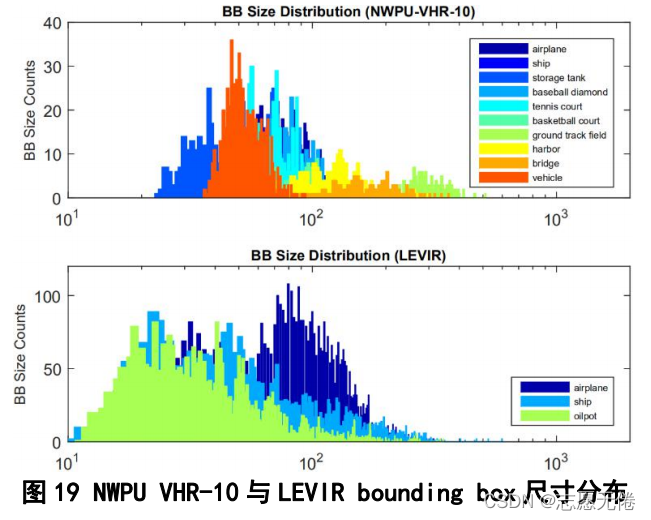
1)實體尺寸分布平衡,
與NWPU VHR-10資料集相比,LEVIR中的實體尺寸分布較為均勻,特別是在10-100像素的實體并沒有體現出較大的分布偏差;而NWPU VHR-10中的大尺寸實體與小尺寸實體存在明顯的分布間隔,
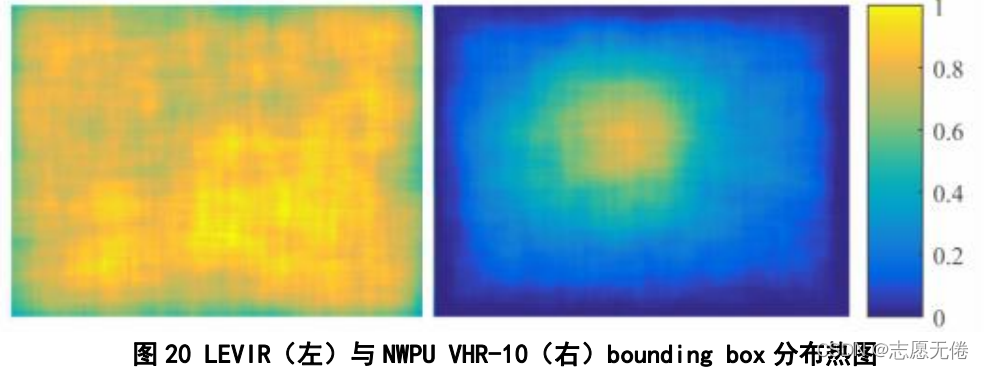
2)實體分布均勻,
與NWPU VHR-10資料集相比,LEVIR中的實體在影像中的位置比較均勻,各個位置都有分布;而NWPU VHR-10中的實體則過于集中在影像的中央,不能體現出實體的平衡性,
6.3資料示例
7. 遙感影像中語境物件細粒度識別資料集(xVi)-14.2G
7.1基本資訊
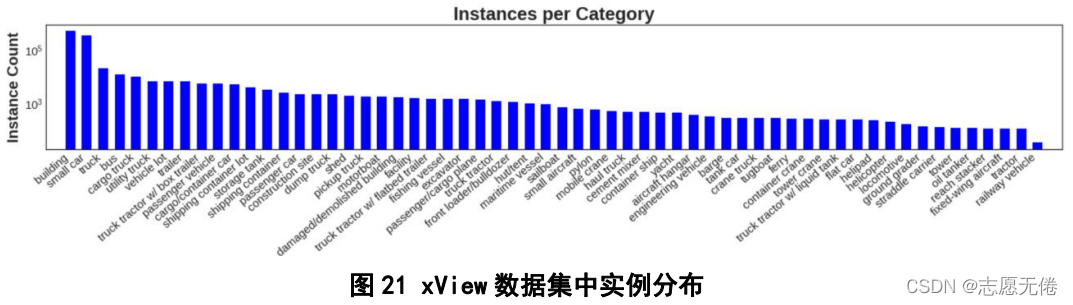
xView (lam et al.,2021)是由美國防部創新實驗部門舉行“xView探測挑戰賽”時,推出的一套遙感影像細粒度目標檢測資料集,包含1127幅遙感影像(圖片尺寸介于20002000和40004000之間)和超過1000000個實體,資料集中的實體分為7個大類和60個子類,7個大類包括飛機、客車、卡車、鐵路車輛、工程車輛、船舶和建筑物,部分子類并沒有包含在大類之下,如直升機停機坪等,大類具體資訊如下:
具體實體分布如下圖所示:
7.2資料說明
7.2.1目標類別選擇
xView選擇了60個類別,采用父類-子類的形式來描述這些類別,但是部分子類并沒有所屬的父類,在1400平方公里的影像中,有超過100萬個物件,
7.2.2資料來源
使用DigitalGlobal在全球部磁區域中截取的影像,
7.2.3資料格式
xView資料集被分割為訓練、驗證和測驗三個集合,按照3:1:1的比例劃分為訓練集、驗證集、測驗集,所有影像尺寸介于2000x2000和4000x4000之間、解析度為0.3m,
7.2.4資料標注
xView資料集的優勢很明顯,一是資料集大,有超過1M個實體物件;二是資料種類多,包含60個細粒度類別;三是解析度高,使用Digital Global的WorldView-3衛星采集到的圖片解析度都在0.3m,且解析度規格相同,
同樣,由于xView是以監測遙感影像中目標受損程度的比賽為導向的,資料集質量并不是很高,并且xView對于一些重要的類別的劃分比較粗糙,不適合作為細粒度的分析,
7.3資料示例
圖22 xView資料集標注示例

8. 遙感影像多尺度目標檢測資料集(SIMD)-1.07G
8.1基本資訊
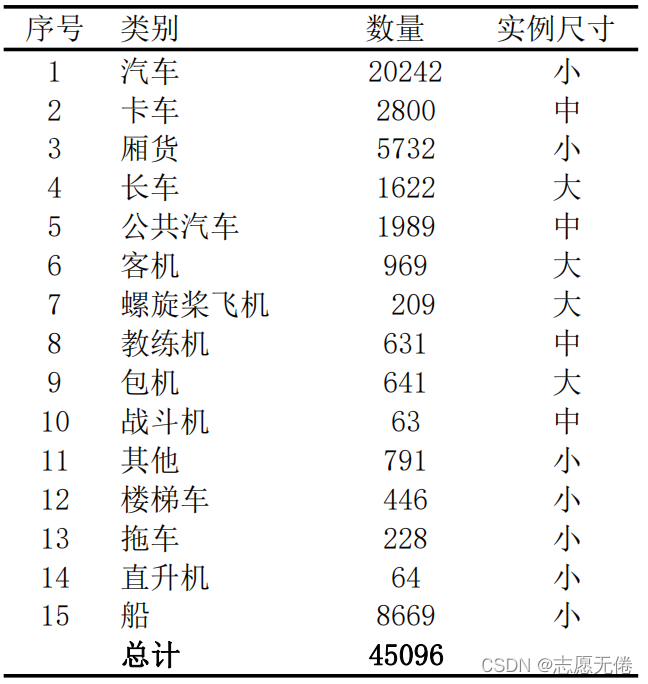
SIMD (haroon et al.,2020) 是由巴基斯坦國立科學技術大學提出的主要用于車輛檢測的目標檢測資料集,包含5000幅遙感影像(圖片尺寸:1024*768)和45096個實體,資料集中的實體分為15類,類別資訊如下:
8.2資料說明
8.2.1目標類別選擇
SIMD主要用于車輛的檢測,對車輛進行了細粒度類別的注釋;
同時也標注了一定數量的飛機,
8.2.2資料來源
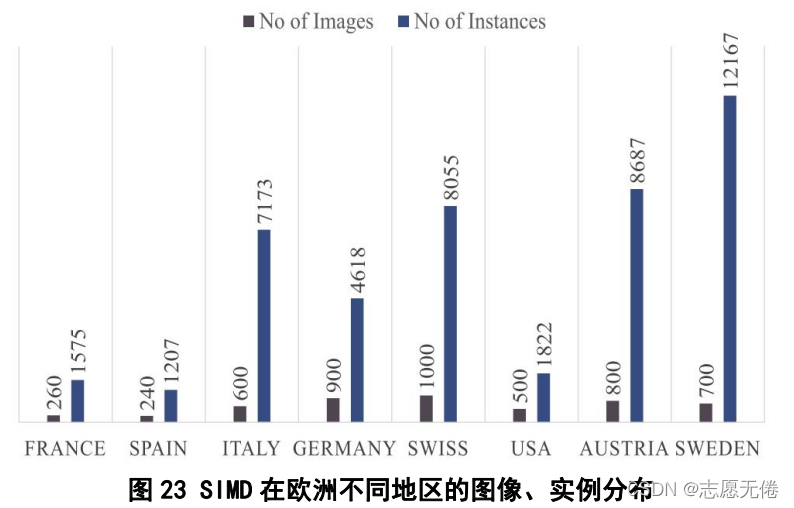
使用GoogleEarth在歐洲部分公共區域中截取的影像,具體分布如下圖:
8.2.3資料格式
SIMD資料集中的影像解析度都是1024*768的JPG格式,對于注釋檔案,SIMD以檢測演算法為導向,提
供了3種標準的注釋格式,
1) YOLO格式:注釋檔案為txt格式,包含(c,xi,yi,w,h)5列屬性資料,其中,c為目標物件的類別,(xi,yi)為物件的中心點,(w,h)為物件BB的寬和高,所有的數值都是與實際影像的百分比,
2) Faster
RCNN格式:資料保存在02XML格式的檔案中,包含(x1、y1、x2和y2)的邊界框資訊和類別資訊,其中第一個檔案中的xi和yi是x、y域中的精確坐標,第二個檔案包含用對應的型別別的名稱,即汽車、公共汽車、卡車等,
3) Pascal
VOC格式:注釋檔案為XML格式,類似于上文提到過的XML檔案,包含完整的影像資訊和每個實體的詳細資訊,影像資訊包括檔案名、檔案夾、影像解析度等,實體標簽包含實體型別名稱和以(xmin、xmax、ymin、ymax)描述的每個實體的坐標,
8.2.4資料優劣
SIMD資料集的優勢主要在于車輛資料集劃分較細致、數量較多,
但是SIMD有著較為嚴重的資料不平衡問題,僅汽車1個類別的實體數量就占到了總體實體的1/2,只有
少量的其他類別的實體,
8.3資料示例

9. 高解析度遙感影像細粒度識別資料集(FAIR1M)-42.8G
9.1基本資訊
FAIR1M (Sun et al.,2021)是由中國科學院空天資訊創新研究院研究團隊和國際攝影測量與遙感協會合作,構建的一套目前全球規模最大的遙感影像細粒度目標識別(Fine-grAined object recognItion in high-Resolution remote sensing imagery)資料集,包含15266幅遙感影像(圖片尺寸介于10001000和100001000之間)和超過100000(1 Million)個實體,資料集中的實體分為5個大類和37個子類,5個大類分別是:飛機、船舶、汽車、球場、道路,對于飛機這一大類,包含11個飛機型號:波音737、波音747、波音777、波音787、C919、ARJ21、空客A320、空客A220、空客A330、空客A350以及不屬于以上10種飛機型號的其他型號飛機,其他大類資訊如下:
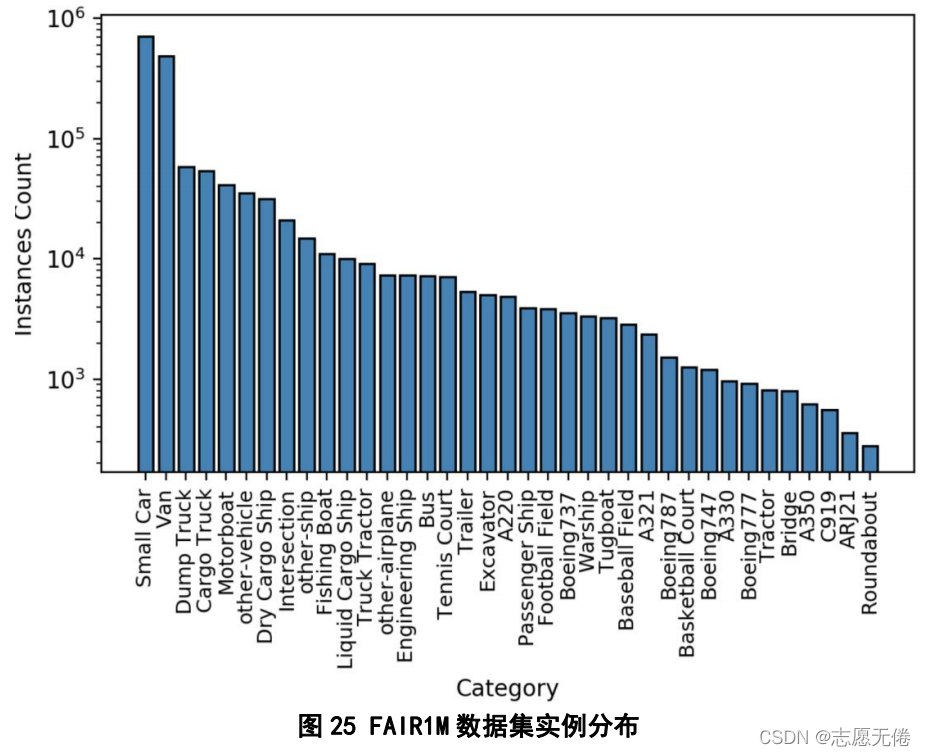
具體實體分布如下圖所示:
9.2資料說明
9.2.1資料來源
1)使用Google Earth軟體在全球部磁區域中截取的影像,
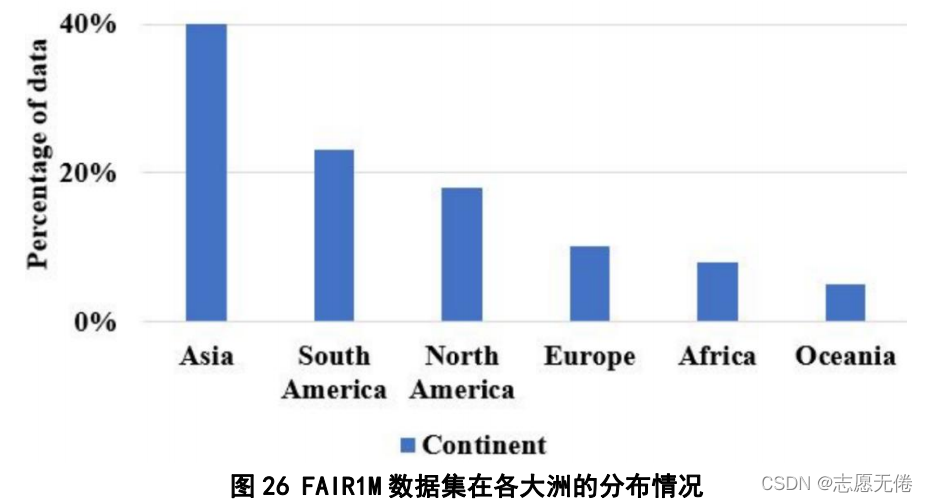
2)使用高分衛星在全球不同區域截取的影像,具體分布:
9.2.2資料預處理
為了獲得高解析度、高質量的遙感影像,FAIR1M進行了一定的資料預處理:
1)檢查原始資料的質量,并去除有許云彩、噪聲和亮點的影像,
2)為了確保同一區域的影像具有相同的定位精度,對多時態和多源影像進行了塊調整,
3)使用Pan Sharpening演算法融合全色影像來提高多光譜影像的空間解析度,并使用直方圖均衡來調整影像的色調分量,
9.2.3資料格式
FAIR1M資料集包含train、test兩個檔案夾,test檔案夾下只包含images檔案,即影像資訊;train檔案夾下包含images檔案和labelXml檔案,前者存有遙感影像,后者是對應的注釋資訊,
影像從1開始順序命名,標注檔案格式為xml檔案,與對應的影像同名,所有影像尺寸介于10001000和1000010000之間、解析度介于0.3m到0.8m、格式均為tif,注釋檔案中的標注資訊很豐富,具體內容如下:
<?xml version="1.0" encoding="utf-8"?>
<annotation>
<source>
<filename>0.tif</filename>
<origin>GF2/GF3</origin>
</source>
<research>
<version>1.0</version>
<provider>FAIR1M</provider>
<author>Cyber</author>
<pluginname>FAIR1M</pluginname>
<pluginclass>object detection</pluginclass>
<time>2021-07-21</time>
</research>
<size>
<width>1500</width>
<height>1500</height>
<depth>3</depth>
</size>
<objects>
<object>
<coordinate>pixel</coordinate>
<type>rectangle</type>
<description>None</description>
<possibleresult>
<name>Liquid Cargo Ship</name>//類別
</possibleresult>
<points>
<point>1275.000000,458.000000</point>//x1, y1
<point>1494.000000,88.000000</point>//x2, y2
<point>1417.000000,43.000000</point>//x3, y3
<point>1199.000000,414.000000</point>//x4, y4
<point>1275.000000,458.000000</point>//head,即x1,y1
</points>
</object>
</objects>
</annotation>
FAIR1M資料集采用OBB的標注方式,使用不規則四邊形進行目標注釋,四邊形的四個頂點分別為
{(xi,yi)|i=1,2,3,4},四個頂點按順時針排列,點(x1,y1)代表物體的頭部,
9.2.4資料優勢
1)類別細分全,類別資料較為平衡,
相較于其他粗糙的細粒度資料集而言,FAIR1M類別細分程度遠超現有資料集,例如xView中只將飛機這一大類分成了2類,而FAIR1M將其分為了11類;并且FAIR1M對于類別進行了一定的平衡處理,各類別數量差異并不太大,而包含15個類別FGSD資料集,單單汽車就占了資料集實體的一半,
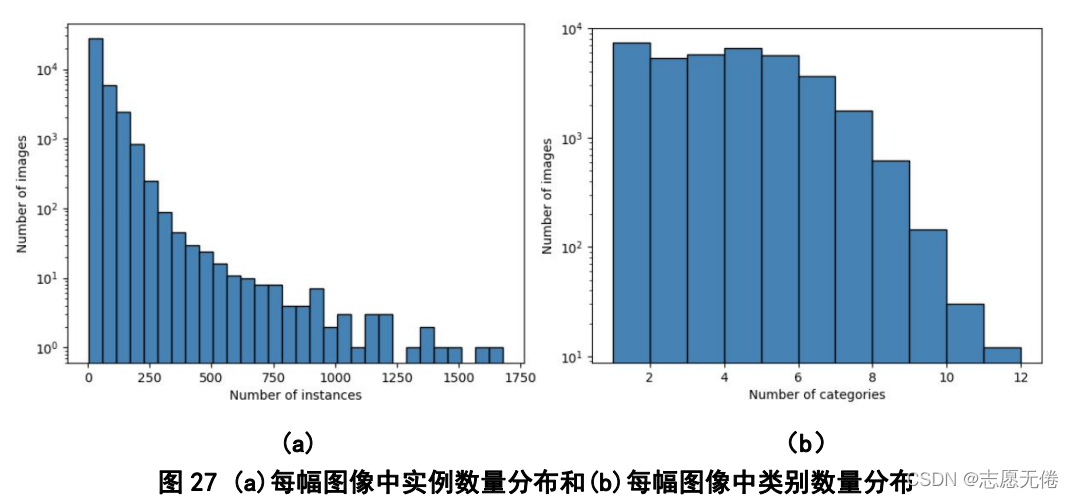
2)實體的尺寸、角度變化范圍大,
FAIR1M資料集具有超高的空間解析度,所以能夠分辨出不同尺度的物體,來擴展實體大小的變化范圍;同時,類內物體也存在角度的變化,
3)高度的類內差異性和類間相似性,
FAIR1M收集了不同季節和天氣環境下的相同場景,因此,同一類別的物體有不同的姿態、背景、顏色和光線;不同細粒度類別之間具有相似的外觀和形狀,
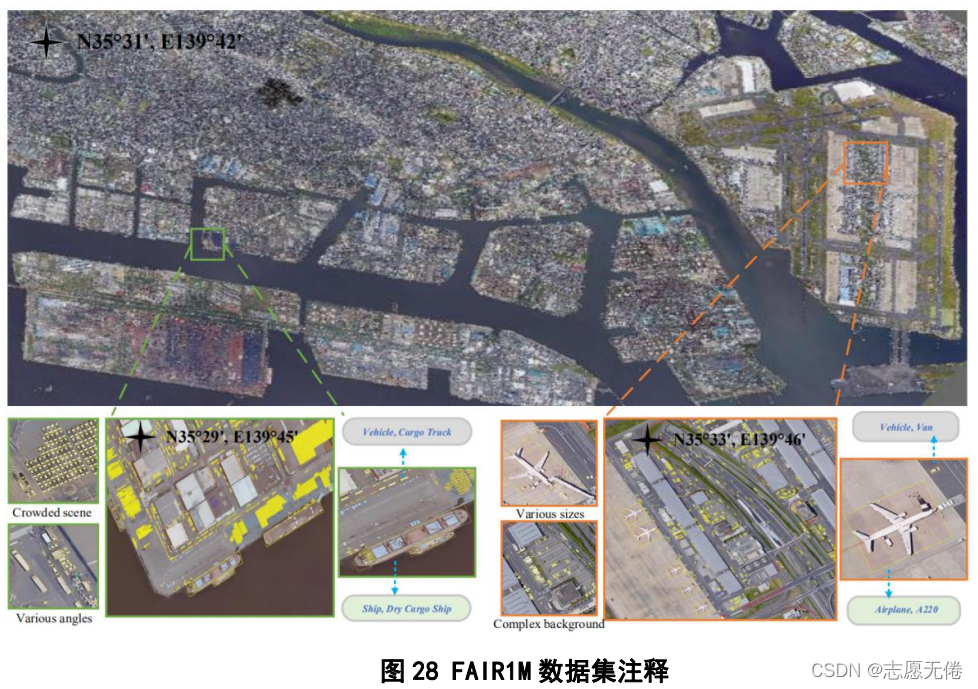
9.3資料示例

參考文獻
- H. Zhu, X. Chen, W. Dai, K. Fu, Q. Ye, and J. Jiao. Orientation robust object detection in aerial images using deep convolutional neural network. In ICIP, pages 3735–3739, 2015.
- Z. Liu, H. Wang, L. Weng, and Y. Yang. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sensing Lett.,13(8):1074–1078, 2016.
- G. Cheng, P. Zhou, and J. Han. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens., 54(12):7405–7415,2016.
- G. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, L. Zhang. DOTA: A large‐scale dataset for object detection in aerial images. In: Proc. IEEE Int. Conf. Comput. Vision Pattern Recognit., pp. 3974‐3983, 2018.
- K. Li, G. Wan, G. Cheng, L. Meng. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS Journal of Photogrammetry and Remote Sensing, 159():296–307,2020.
- Z. Zou, Z. Shi. Random Access Memories: A New Paradigm for Target Detection in High Resolution Aerial Remote Sensing Images. IEEE Transactions on Image Processing, 27(3), 1100–1111,2018.
- D. Lam, R. Kuzma, K. McGee, S. Dooley, M. Laielli, M. Klaric, Y. Bulatov, B. McCord. xview: Objects in context in overhead imagery. arXiv preprint arXiv:1802.07856,2018.
- M. Haroon, M. Shahzad, M. Fraz.Multi-sized object detection using spaceborne optical imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2020.
- X. Sun, P. Wang, Z. Yan, C. Wang, W. Diao et al. FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery[J]. arXiv preprint arXiv:2103.05569, 2021.
附錄
附錄1 資料集下載地址
資料集 百度云鏈接 提取碼
UCAS-AOD https://pan.baidu.com/s/1Vlp1_XPTAWxPsMUZwn4WvA kyio
HRSC2016 https://pan.baidu.com/s/1orVcudsa7h3Cw3g17GuuEQ vl67
NWPU VHR-10 https://pan.baidu.com/s/1MpowaoiCnujOveGpAL0uEg xz0y
DOTA https://pan.baidu.com/s/1bpwpYZMrQ7Jl7HWEfboRDw gvmr
DIOR https://pan.baidu.com/s/1WC5PF7VcUZAazao7XZLLiA j59z
LEVIR https://pan.baidu.com/s/1KjErcWrvAvDjC6qdeBkCOA
FAIR1M https://pan.baidu.com/s/1MzXz9nsDcPBpRJjlmAcjFA
附錄2 文獻下載地址
百度云鏈接:https://pan.baidu.com/s/1zgziOY5i097snrMKqra7Dg
提取碼:tdo5
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390511.html
標籤:其他
上一篇:JavaCV音視頻開發寶典:使用javacv讀取GB28181、海康大華平臺和網路攝像頭sdk回呼視頻碼流并轉碼推流rtmp流媒體服務
下一篇:C#:圣誕節內卷,鉛筆畫制作