論文地址:https://arxiv.org/abs/2111.12419
Github:https://github.com/Christian-lyc/NAM

摘要
識別不太顯著的特征是模型壓縮的關鍵, 然而,它尚未在革命性的注意力機制中進行研究, 在這項作業中,我們提出了一種新穎的基于歸一化的注意力模塊(NAM),它抑制了不太顯著的權重, 它將權重稀疏懲罰應用于注意力模塊,從而使它們在保持相似性能的同時具有更高的計算效率, 與 Resnet 和 Mobilenet 上的其他三種注意力機制的比較表明,我們的方法具有更高的準確性, 本文的代碼可以在 https://github.com/Christian-lyc/NAM 公開訪問,
1 簡介
注意力機制是近年來的熱門研究興趣之一(Wang et al.[2017], Hu et al. [2018], Park et al. [2018], Woo et al. [2018], Gao et al. [2018], [2019]),它幫助深度神經網路抑制不太顯著的像素或通道,許多先前的研究側重于通過注意力操作來捕捉顯著特征(Zhang 等人 [2020]、Misra 等人 [2021]),這些方法成功地利用了來自不同維度特征的互資訊,然而,他們沒有考慮權重的影響因素,這能夠進一步抑制不重要的通道或像素,受劉等人的啟發, [2017],我們的目標是利用權重的影響因素來改進注意力機制,我們使用批量歸一化的比例因子,它使用標準偏差來表示權重的重要性,這樣可以避免添加 SE、BAM 和 CBAM 中使用的全連接層和卷積層,因此,我們提出了一種有效的注意力機制——基于標準化的注意力模塊(NAM),
2 相關作業
許多先前的作業試圖通過抑制無關緊要的權重來提高神經網路的性能, Squeeze-and-Excitation Networks (SENet) (Hu et al. [2018]) 將空間資訊整合到通道特征回應中,并用兩個多層感知器 (MLP) 層計算相應的注意力,后來,瓶頸注意模塊(BAM)(Park et al. [2018])構建
并行分離的空間和通道子模塊,它們可以嵌入到每個瓶頸塊中,卷積塊注意模塊 (CBAM) (Woo et al. [2018]) 提供了一種將通道和空間注意子模塊順序嵌入的解決方案,為了避免忽略跨維度互動,三元組注意力模塊 (TAM)(Misra 等人 [2021])通過旋轉特征圖來考慮維度相關性,然而,這些作業忽略了來自訓練調整權重的資訊,因此,我們旨在通過利用訓練模型權重的方差測量來突出顯著特征,
3 方法
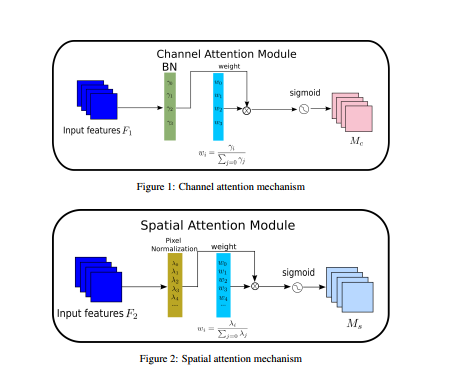
我們建議 NAM 作為一種高效且輕量級的注意力機制, 我們采用了 CBAM (Woo et al. [2018]) 的模塊集成并重新設計了通道和空間注意子模塊, 然后,在每個網路塊的末尾嵌入一個 NAM 模塊, 對于殘差網路,它嵌入在殘差結構的末尾, 對于通道注意力子模塊,我們使用批量歸一化 (BN)(Ioffe 和 Szegedy [2015])中的縮放因子,如等式 (1) 所示, 比例因子衡量通道的方差并表明它們的重要性,
B
out
=
B
N
(
B
in
)
=
γ
B
in
?
μ
B
σ
B
2
+
?
+
β
B_{\text {out }}=B N\left(B_{\text {in }}\right)=\gamma \frac{B_{\text {in }}-\mu_{B}}{\sqrt{\sigma_{B}^{2}+\epsilon}}+\beta
Bout ?=BN(Bin ?)=γσB2?+?
?Bin ??μB??+β
其中
μ
B
\mu_{B}
μB? 和
σ
B
\sigma_{B}
σB? 分別是小批量 $ {B}$ 的均值和標準差;
γ
\gamma
γ 和
β
\beta
β 是可訓練的仿射變換引數(尺度和位移)(Ioffe 和 Szegedy [2015]),通道注意力子模塊如圖1和等式(2)所示,其中Mc代表輸出特征,
γ
\gamma
γ 是每個通道的縮放因子,權重為
W
γ
=
γ
i
/
∑
j
=
0
γ
j
W_{\gamma}=\gamma_{i} / \sum_{j=0} \gamma_{j}
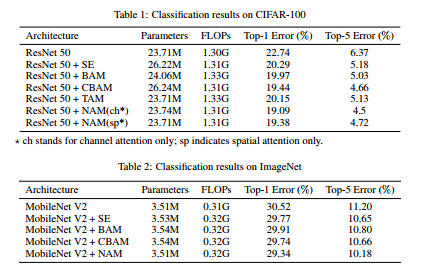
Wγ?=γi?/∑j=0?γj?,我們還將 BN 的比例因子應用于空間維度來衡量像素的重要性,我們將其命名為像素歸一化,相應的空間注意力子模塊如圖2和等式(3)所示,其中輸出表示為
M
s
M_{s}
Ms?,λ是縮放因子,權重為
W
λ
=
λ
i
/
∑
j
=
0
λ
j
W_{\lambda}=\lambda_{i} / \sum_{j=0} \lambda_{j}
Wλ?=λi?/∑j=0?λj?,
為了抑制不太顯著的權重,我們在損失函式中添加了一個正則化項,如等式 (4) (Liu et al. [2017]) 所示,其中 x 表示輸入; y 是輸出; W 代表網路權重; l(·)是損失函式; g(·)是l1范數懲罰函式; p 是平衡 g(γ) 和 g(λ) 的懲罰
M
c
=
sigmoid
?
(
W
γ
(
B
N
(
F
1
)
)
)
M
s
=
sigmoid
?
(
W
λ
(
B
N
s
(
F
2
)
)
)
Loss
=
∑
(
x
,
y
)
l
(
f
(
x
,
W
)
,
y
)
+
p
∑
g
(
γ
)
+
p
∑
g
(
λ
)
\begin{gathered} \mathbf{M}_{c}=\operatorname{sigmoid}\left(W_{\gamma}\left(B N\left(\mathbf{F}_{1}\right)\right)\right) \\ \mathbf{M}_{s}=\operatorname{sigmoid}\left(W_{\lambda}\left(B N_{s}\left(\mathbf{F}_{2}\right)\right)\right) \\ \text { Loss }=\sum_{(x, y)} l(f(x, W), y)+p \sum g(\gamma)+p \sum g(\lambda) \end{gathered}
Mc?=sigmoid(Wγ?(BN(F1?)))Ms?=sigmoid(Wλ?(BNs?(F2?))) Loss =(x,y)∑?l(f(x,W),y)+p∑g(γ)+p∑g(λ)?
4 實驗
在本節中,我們將 NAM 與 SE、BAM、CBAM 和 TAM 在 ResNet 和 MobileNet 上的性能進行比較, 我們使用集群上的四個 Nvidia Tesla V100 GPU 評估每種方法, 我們首先在 CIFAR-100(Krizhevsky 等人 [2009])上運行 ResNet50,并使用與 CBAM(Woo 等人 [2018])相同的預處理和訓練配置,p 為 0.0001, 表 1 中的比較表明,僅具有通道或空間注意力的 NAM 優于其他四種注意力機制, 然后我們在 ImageNet 上運行 MobileNet (Deng et al. [2009]),因為它是影像分類基準的標準資料集之一, 我們將 p 設定為 0.001,其余配置與 CBAM 相同, 表 2 中的比較表明,結合了通道和空間注意力的 NAM 優于具有相似計算復雜度的其他三個,
5 結論
我們提出了一個 NAM 模塊,它通過抑制不太顯著的特征來提高效率, 我們的實驗表明 NAM 在 ResNet 和 MobileNet 上都提供了效率增益, 我們正在對 NAM 的集成變化和超引數調整的性能進行詳細分析, 我們還計劃使用不同的模型壓縮技術優化 NAM,以提高其效率, 未來,我們將研究其對其他深度學習架構和應用程式的影響,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390521.html
標籤:其他