有料,有料,微信搜索 【K同學啊】 關注這個分享干貨的博主,
本文 GitHub https://github.com/kzbkzb/Python-AI 已收錄,有 Python、深度學習的資料以及我的系列文章,
文章目錄
- 一、前期作業
- 1. 設定GPU
- 2. 匯入資料
- 3. 查看資料
- 二、資料預處理
- 1. 加載資料
- 2. 可視化資料
- 3. 再次檢查資料
- 4. 配置資料集
- 5. 歸一化
- 三、構建VGG-16網路
- 1. 官方模型(已打包好)
- 2. 自建模型
- 3. 網路結構圖
- 四、編譯
- 五、訓練模型
- 六、模型評估
一、前期作業
本文將實作海賊王中人物角色的識別,
🚀 我的環境:
- 語言環境:Python3.6.5
- 編譯器:jupyter notebook
- 深度學習環境:TensorFlow2.4.1
- 資料和代碼:📌【傳送門】
🚀 來自專欄:《深度學習100例》
如果你是一名深度學習小白可以先看看我這個專門為你寫的專欄:《小白入門深度學習》
- 小白入門深度學習 | 第一篇:配置深度學習環境
- 小白入門深度學習 | 第二篇:編譯器的使用-Jupyter Notebook
- 小白入門深度學習 | 第三篇:深度學習初體驗
- 小白入門深度學習 | 第四篇:配置PyTorch環境
🚀 往期精彩-卷積神經網路篇:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)彩色圖片分類 | 第2天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例-卷積神經網路(VGG-19)識別靈籠中的人物 | 第7天
- 深度學習100例-卷積神經網路(ResNet-50)鳥類識別 | 第8天
- 深度學習100例-卷積神經網路(AlexNet)手把手教學 | 第11天
- 深度學習100例-卷積神經網路(CNN)識別驗證碼 | 第12天
- 深度學習100例-卷積神經網路(Inception V3)識別手語 | 第13天
- 深度學習100例-卷積神經網路(Inception-ResNet-v2)識別交通標志 | 第14天
- 深度學習100例-卷積神經網路(CNN)實作車牌識別 | 第15天
- 深度學習100例-卷積神經網路(CNN)識別神奇寶貝小智一伙 | 第16天
- 深度學習100例-卷積神經網路(CNN)注意力檢測 | 第17天
- 深度學習100例-卷積神經網路(VGG-16)貓狗識別 | 第21天
- 深度學習100例-卷積神經網路(LeNet-5)深度學習里的“Hello Word” | 第22天
- 深度學習100例-卷積神經網路(CNN)3D醫療影像識別 | 第23天
- 深度學習100例 | 第24天-卷積神經網路(Xception):動物識別
🚀 往期精彩-回圈神經網路篇:
- 深度學習100例-回圈神經網路(RNN)實作股票預測 | 第9天
- 深度學習100例-回圈神經網路(LSTM)實作股票預測 | 第10天
🚀 往期精彩-生成對抗網路篇:
- 深度學習100例-生成對抗網路(GAN)手寫數字生成 | 第18天
- 深度學習100例-生成對抗網路(DCGAN)手寫數字生成 | 第19天
- 深度學習100例-生成對抗網路(DCGAN)生成動漫小姐姐 | 第20天
1. 設定GPU
如果使用的是CPU可以忽略這步
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #設定GPU顯存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
2. 匯入資料
import matplotlib.pyplot as plt
import os,PIL
# 設定隨機種子盡可能使結果可以重現
import numpy as np
np.random.seed(1)
# 設定隨機種子盡可能使結果可以重現
import tensorflow as tf
tf.random.set_seed(1)
from tensorflow import keras
from tensorflow.keras import layers,models
import pathlib
data_dir = "D:\jupyter notebook\DL-100-days\datasets\hzw_photos"
data_dir = pathlib.Path(data_dir)
3. 查看資料
資料集中一共有路飛、索隆、娜美、烏索普、喬巴、山治、羅賓等7個人物角色
| 檔案夾 | 含義 | 數量 |
|---|---|---|
| lufei | 路飛 | 117 張 |
| suolong | 索隆 | 90 張 |
| namei | 娜美 | 84 張 |
| wusuopu | 烏索普 | 77張 |
| qiaoba | 喬巴 | 102 張 |
| shanzhi | 山治 | 47 張 |
| luobin | 羅賓 | 105張 |
image_count = len(list(data_dir.glob('*/*.png')))
print("圖片總數為:",image_count)
圖片總數為: 621
二、資料預處理
1. 加載資料
使用image_dataset_from_directory方法將磁盤中的資料加載到tf.data.Dataset中
batch_size = 32
img_height = 224
img_width = 224
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 621 files belonging to 7 classes.
Using 497 files for training.
"""
關于image_dataset_from_directory()的詳細介紹可以參考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 621 files belonging to 7 classes.
Using 124 files for validation.
我們可以通過class_names輸出資料集的標簽,標簽將按字母順序對應于目錄名稱,
class_names = train_ds.class_names
print(class_names)
['lufei', 'luobin', 'namei', 'qiaoba', 'shanzhi', 'suolong', 'wusuopu']
2. 可視化資料
plt.figure(figsize=(10, 5)) # 圖形的寬為10高為5
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

plt.imshow(images[1].numpy().astype("uint8"))
<matplotlib.image.AxesImage at 0x2adcea36ee0>

3. 再次檢查資料
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 224, 224, 3)
(32,)
Image_batch是形狀的張量(32,180,180,3),這是一批形狀180x180x3的32張圖片(最后一維指的是彩色通道RGB),Label_batch是形狀(32,)的張量,這些標簽對應32張圖片
4. 配置資料集
- shuffle():打亂資料,關于此函式的詳細介紹可以參考:https://zhuanlan.zhihu.com/p/42417456
- prefetch():預取資料,加速運行,其詳細介紹可以參考我前兩篇文章,里面都有講解,
- cache():將資料集快取到記憶體當中,加速運行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
5. 歸一化
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalization_train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看歸一化后的資料
print(np.min(first_image), np.max(first_image))
0.0 0.9928046
三、構建VGG-16網路
在官方模型與自建模型之間進行二選一就可以啦,選著一個注釋掉另外一個,都是正版的VGG-16哈,
VGG優缺點分析:
- VGG優點
VGG的結構非常簡潔,整個網路都使用了同樣大小的卷積核尺寸(3x3)和最大池化尺寸(2x2),
- VGG缺點
1)訓練時間過長,調參難度大,2)需要的存盤容量大,不利于部署,例如存盤VGG-16權重值檔案的大小為500多MB,不利于安裝到嵌入式系統中,
1. 官方模型(已打包好)
官網模型呼叫這塊我放到后面幾篇文章中,下面主要講一下VGG-16
# model = keras.applications.VGG16()
# model.summary()
2. 自建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(1000, (img_width, img_height, 3))
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
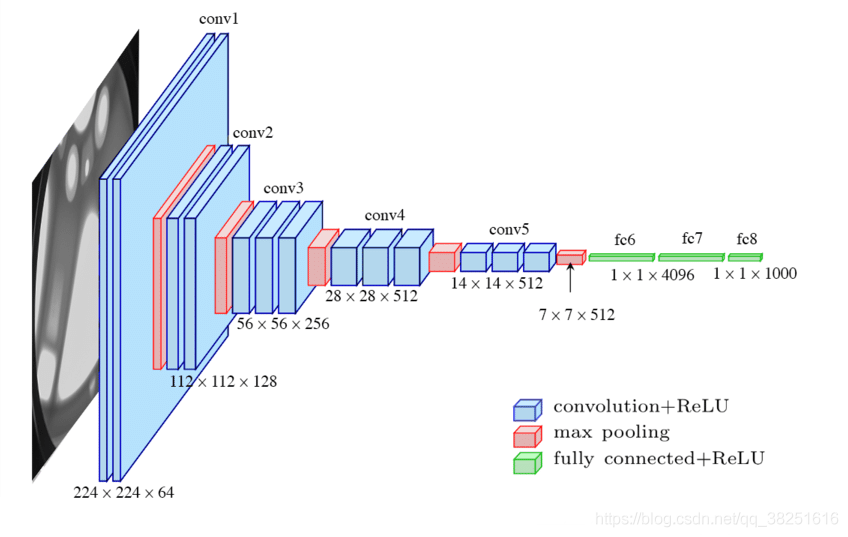
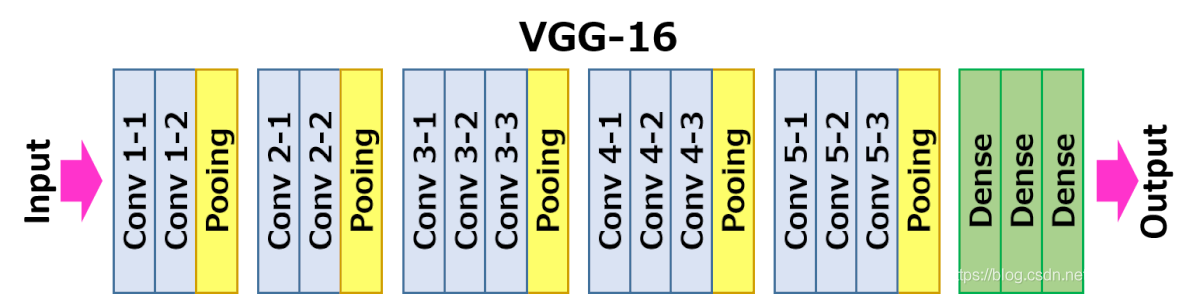
3. 網路結構圖
關于卷積的相關知識可以參考文章:https://mtyjkh.blog.csdn.net/article/details/114278995
結構說明:
- 13個卷積層(Convolutional Layer),分別用
blockX_convX表示 - 3個全連接層(Fully connected Layer),分別用
fcX與predictions表示 - 5個池化層(Pool layer),分別用
blockX_pool表示
VGG-16包含了16個隱藏層(13個卷積層和3個全連接層),故稱為VGG-16
四、編譯
在準備對模型進行訓練之前,還需要再對其進行一些設定,以下內容是在模型的編譯步驟中添加的:
- 損失函式(loss):用于衡量模型在訓練期間的準確率,
- 優化器(optimizer):決定模型如何根據其看到的資料和自身的損失函式進行更新,
- 指標(metrics):用于監控訓練和測驗步驟,以下示例使用了準確率,即被正確分類的影像的比率,
# 設定優化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
五、訓練模型
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/20
16/16 [==============================] - 14s 461ms/step - loss: 4.5842 - accuracy: 0.1349 - val_loss: 6.8389 - val_accuracy: 0.1129
Epoch 2/20
16/16 [==============================] - 2s 146ms/step - loss: 2.1046 - accuracy: 0.1398 - val_loss: 6.7905 - val_accuracy: 0.2016
Epoch 3/20
16/16 [==============================] - 2s 144ms/step - loss: 1.7885 - accuracy: 0.3531 - val_loss: 6.7892 - val_accuracy: 0.2903
Epoch 4/20
16/16 [==============================] - 2s 145ms/step - loss: 1.2015 - accuracy: 0.6135 - val_loss: 6.7582 - val_accuracy: 0.2742
Epoch 5/20
16/16 [==============================] - 2s 148ms/step - loss: 1.1831 - accuracy: 0.6108 - val_loss: 6.7520 - val_accuracy: 0.4113
Epoch 6/20
16/16 [==============================] - 2s 143ms/step - loss: 0.5140 - accuracy: 0.8326 - val_loss: 6.7102 - val_accuracy: 0.5806
Epoch 7/20
16/16 [==============================] - 2s 150ms/step - loss: 0.2451 - accuracy: 0.9165 - val_loss: 6.6918 - val_accuracy: 0.7823
Epoch 8/20
16/16 [==============================] - 2s 147ms/step - loss: 0.2156 - accuracy: 0.9328 - val_loss: 6.7188 - val_accuracy: 0.4113
Epoch 9/20
16/16 [==============================] - 2s 143ms/step - loss: 0.1940 - accuracy: 0.9513 - val_loss: 6.6639 - val_accuracy: 0.5968
Epoch 10/20
16/16 [==============================] - 2s 143ms/step - loss: 0.0767 - accuracy: 0.9812 - val_loss: 6.6101 - val_accuracy: 0.7419
Epoch 11/20
16/16 [==============================] - 2s 146ms/step - loss: 0.0245 - accuracy: 0.9894 - val_loss: 6.5526 - val_accuracy: 0.8226
Epoch 12/20
16/16 [==============================] - 2s 149ms/step - loss: 0.0387 - accuracy: 0.9861 - val_loss: 6.5636 - val_accuracy: 0.6210
Epoch 13/20
16/16 [==============================] - 2s 152ms/step - loss: 0.2146 - accuracy: 0.9289 - val_loss: 6.7039 - val_accuracy: 0.4839
Epoch 14/20
16/16 [==============================] - 2s 152ms/step - loss: 0.2566 - accuracy: 0.9087 - val_loss: 6.6852 - val_accuracy: 0.6532
Epoch 15/20
16/16 [==============================] - 2s 149ms/step - loss: 0.0579 - accuracy: 0.9840 - val_loss: 6.5971 - val_accuracy: 0.6935
Epoch 16/20
16/16 [==============================] - 2s 152ms/step - loss: 0.0414 - accuracy: 0.9866 - val_loss: 6.6049 - val_accuracy: 0.7581
Epoch 17/20
16/16 [==============================] - 2s 146ms/step - loss: 0.0907 - accuracy: 0.9689 - val_loss: 6.6476 - val_accuracy: 0.6452
Epoch 18/20
16/16 [==============================] - 2s 147ms/step - loss: 0.0929 - accuracy: 0.9685 - val_loss: 6.6590 - val_accuracy: 0.7903
Epoch 19/20
16/16 [==============================] - 2s 146ms/step - loss: 0.0364 - accuracy: 0.9935 - val_loss: 6.5915 - val_accuracy: 0.6290
Epoch 20/20
16/16 [==============================] - 2s 151ms/step - loss: 0.1081 - accuracy: 0.9662 - val_loss: 6.6541 - val_accuracy: 0.6613
六、模型評估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
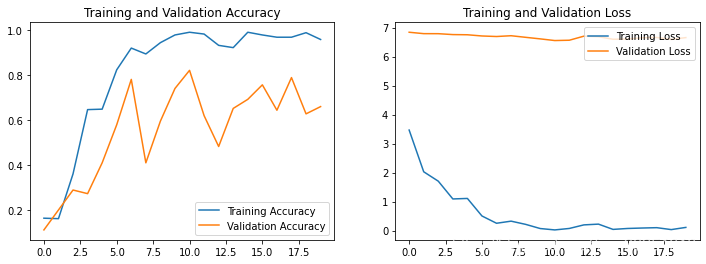
為體現原汁原味的VGG-16,本文并未對模型引數進行修改,可依據實際情況修改模型中的相關性引數,適應實際情況以便提升分類效果,
其他精彩內容:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)彩色圖片分類 | 第2天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
《深度學習100例》專欄直達:【傳送門】
如果覺得本文對你有幫助記得 點個關注,給個贊,加個收藏
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390554.html
標籤:AI
下一篇:seaborn可視化多水平分類變數分組箱圖boxplot并自定義多個箱體的順序(Manually Order Boxes in Boxplot with Seaborn)