一. 面試題及剖析
1. 今日面試題
請說一下HashMap及其底層實作原理
HashMap中是如何計算key的hash值的?
HashMap是如何進行擴容的?
說說HashMap的擴容機制原理
HashMap擴容后是如何重新進行hash計算的?
......
2. 題目剖析
在前4篇文章中,壹哥 給大家介紹了HashMap的基本特點、底層資料結構、HashMap中的重要屬性,分析了HashMap的默認初始容量、負載因子,還有HashMap是如何保證其容量必須是2的N次方的,以及HashMap的put()方法執行流程,但在HashMap中,其底層內容非常的復雜,所以接下來在今天的文章中,壹哥 會繼續給大家剖析HashMap的底層原始碼,敬請關注哦,
前4篇文章地址如下:
高薪程式員&面試題精講系列39之說說HashMap的特點及其底層資料結構
高薪程式員&面試題精講系列40之HashMap默認初始容量、最大容量、負載因子是多少?鏈表轉紅黑樹閾值是多少?HashMap什么時候進行擴容?
高薪程式員&面試題精講系列41之HashMap的容量為什么必須是2的N次方?說說HashMap添加資料的流程吧
高薪程式員&面試題精講系列42之HashMap中如果出現沖突怎么解決?如何計算key的hash值、如何進行陣列索引定位?
二. HashMap的擴容機制(重點)
本節相關面試題:
HashMap的擴容機制是怎么樣的?
在HashMap的眾多面試題中,有一個題目始終無法被繞過去,那就是HashMap的擴容機制,
1. 擴容機制簡介
所謂的擴容(resize)機制,就是重新計算擴大陣列的容量,我們一直向HashMap陣列中添加新元素,當HashMap內部的陣列無法裝載更多的元素時,HashMap就需要擴大陣列原先的容量了,以便能裝入更多的元素,HashMap會遵循2倍擴容的原則,每次擴容之后陣列的大小都是擴容前的2倍,
2. 擴容觸發時機
那HashMap什么時候會進行擴容呢?壹哥 在這里給大家總結一下JDK 8中的HashMap,會在什么時候觸發resize()擴容方法,有以下幾種情況會觸發擴容機制:
①. 當HashMap中使用的位桶數量,達到 總容量*負載因子 的時候會觸發擴容;
②. 當某個位桶中的鏈表長度達到8,即將進行鏈表轉紅黑樹時,會檢查總位桶的數量是否小于64,如果總數量小于64也會進行擴容;
③. 當創建一個HashMap物件之后,第一次往HashMap里面進行put操作時,也會先進行擴容;
④. 另外在HashMap的put方法中,當HashMap的size(實際鍵值對個數)達到 threshold(閾值)時,也會觸發擴容操作,
3. resize()擴容方法原始碼
了解了HashMap的擴容時機之后,我們來看看這個擴容操作具體是怎么實作的,原始碼如下:
final Node<K,V>[] resize() {
//擴容前的Node陣列,先保存 table 副本,接下來 copy 到新陣列用
Node<K,V>[] oldTab = table;
//當前 table 的容量,是 length 而不是 size
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//當前桶的大小
int oldThr = threshold;
int newCap, newThr = 0;
// 計算新的容量值和下一次要擴展的容量
if (oldCap > 0) {
//如果當前容量大于 0,也就是非第一次初始化的情況(擴容場景下)
if (oldCap >= MAXIMUM_CAPACITY) {
// 當超過最大值,則直接使用最大值作為擴容最大限度,以后就不再擴充了
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 沒超過最大值,就擴充為原來的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 計算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 創建新的擴容后陣列,然后將舊的元素復制過去
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每個bucket都移動到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果位置上沒有元素,直接為null
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果只有一個元素,新的hash計算后放入新的陣列中
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是樹狀結構,使用紅黑樹保存
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//如果是鏈表形式
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//hash碰撞后高位為0,放入低Hash值的鏈表中
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//hash碰撞后高位為1,放入高Hash值的鏈表中
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 低hash值的鏈表放入陣列的原始位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 高hash值的鏈表放入陣列的原始位置 + 原始容量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}在這段原始碼中,壹哥 把核心代碼都做了中文注釋,大家可以參考著閱讀理解,
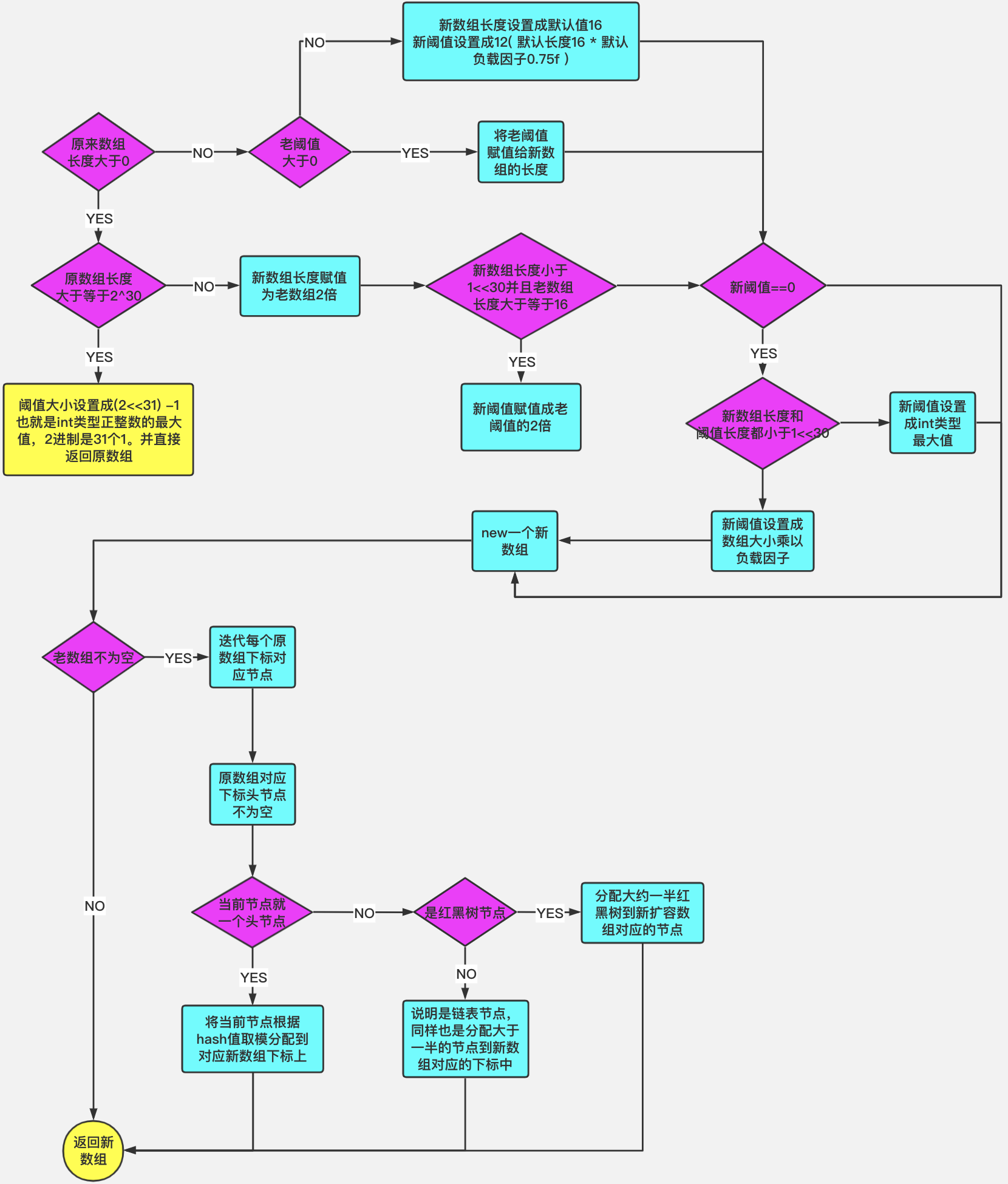
4. HashMap擴容流程
上面的resize原始碼看起來挺讓人頭疼的,所以我們可以對其進行簡單梳理,歸納如下圖所示,大家可以結合上面的原始碼和下圖理解resize擴容程序,
 ?
?
5. 擴容機制原理(重點)
對HashMap的擴容程序有了基本的了解之后,我們再來看看擴容機制的底層實作原理,
我們知道,HashMap存盤結構的主體是一個table陣列,但Java中沒有真正的動態陣列,也就是說,陣列初始化的時候是多大,那它就一直是多大,那擴容是怎么實作的呢?答案就是HashMap會創建一個新的更大的陣列,將舊陣列中的資料拷貝過去,用這個新陣列代替已有的舊陣列,這就好比一開始我們用一個小桶裝水,后來想要裝更多的水,就得換一個更大的水桶,就是基于這樣的思路,
HashMap的擴容機制實作的很巧妙,可以用最小的性能消耗來完成擴容作業,但其內部在進行資料拷貝的時候需要考慮如下幾種情況:
①. 如果節點的 next屬性 為null,則說明這是一個最正常的節點,不是桶內鏈表,也不是紅黑樹,這樣的節點可以直接計算索引位置,然后插入,
②. 如果是一顆紅黑樹,會使用split方法進行處理,原理就是將紅黑樹拆分成兩個TreeNode鏈表,然后判斷每個鏈表的長度是否<=6,如果是,就將TreeNode轉換成桶內鏈表,否則再轉換成紅黑樹,
③. 如果是桶內鏈表,則將鏈表拷貝到新陣列中,保證鏈表的順序不變,
三. 擴容后的rehash操作
1. rehash操作簡介
HashMap在陣列擴容后,還需要進行一次新的rehash操作,以此來重新確定元素的存放位置,在rehash之后,元素的存放位置要么是在原位置,要么是在原位置的基礎上 向下移動 之前容量個數 的位置,比如,上次容量是16,下次擴容后容量變成了16+16=32,如果一個元素原先在下標為7的位置上,那么擴容后,該元素要么還在7的位置上,要么就在7+16的位置上,
2. rehash實作程序(重點)
有的小伙伴可能會問,為什么要這樣呢?下面 壹哥 來解釋一下Java 8的擴容機制是怎么做到這一點的,
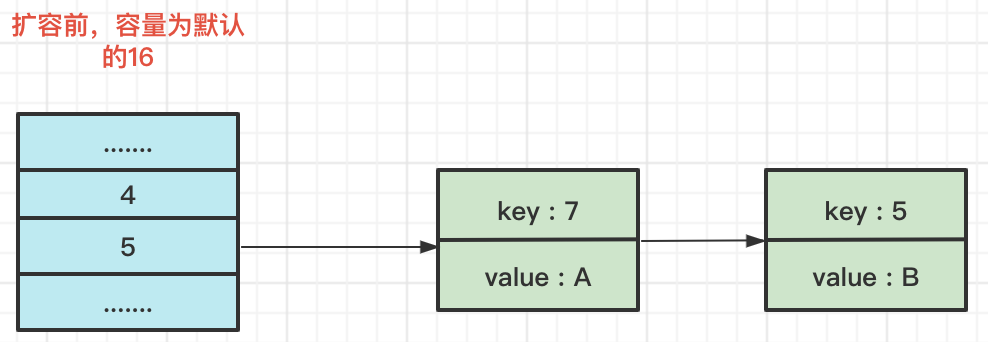
2.1 擴容之前的hash程序
假設擴容前的資料結構如下圖所示:
 ?
?
此時我們有一個HashMap,在陣列索引為5的位置上產生了一個鏈表,依次存盤著2個key,分別為7、5,
假設此時HashMap的容量是默認的16,我們把容量設定為n,即n=16,key1、key2分別表示7、5這兩個key,hash1、hash2分別是key1、key2對應的hash值,
那么此時在擴容之前,n-1與hash1進行與運算,n-1與hash2進行與運算的結果如下圖所示:
 ?
?
經過與運算,我們會發現,在HashMap容量為16時,key1與key2與運算的結果相同,最終的結果都是在5這個位置上,運算程序如下:
n-1 也就是二進制的 0000 1111 = 1+2+4+8 = 15
key1 哈希值的最后 8 位為 0001 0101;
key2 哈希值的最后 8 位為0000 0101(和 key1 不同);
與運算后發生了哈希沖突,索引都在 0000 0101 =5 位置上,
2.2 擴容之后的hash程序
接下來我們將HashMap進行2倍擴容,那么此時HashMap的容量變成32,即n=32,接下來繼續把n-1與hash1進行與運算,n-1與hash2進行與運算,
 ?
?
我們會發現,此時計算的結果,key1與運算的結果是21,key2與運算的結果依然是5,運算程序如下:
n-1 也就是二進制的 0001 1111 = 1+2+4+8+16 = 31,擴容前是 0000 1111 = 15;
key1 哈希值的低位為 0001 0101;
key2 哈希值的低位為 0000 0101(和 key1 不同);
key1 做與運算后,索引為 0001 0101 = 21,
key2 做與運算后,索引為 0000 0101 = 5,
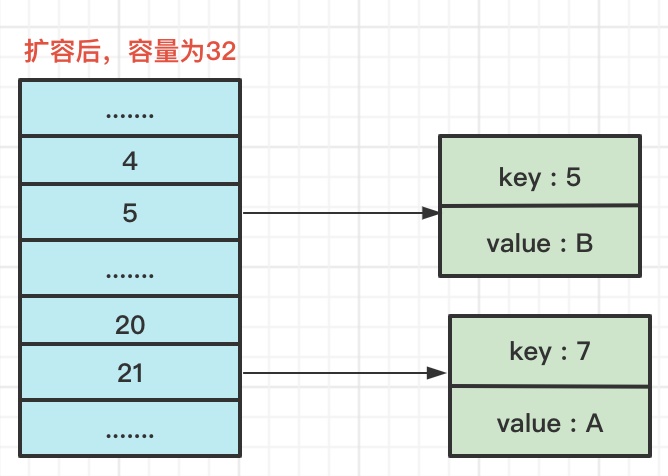
此時HashMap中存盤資料的結構圖如下所示:
 ?
?
所以擴容后,key1的索引就變成了 21 (1 0101),也就是 5+16,即 原來的索引+原來的容量,我們可以用下圖表示:
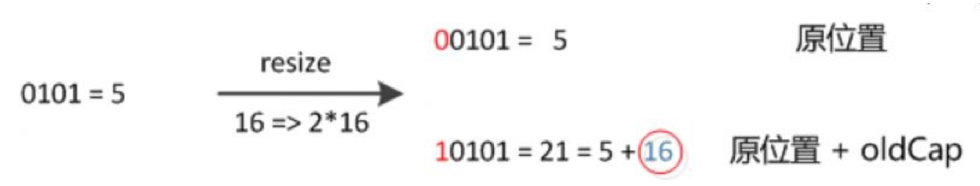 ?
?
因此,JDK 8中HashMap擴容時,不需要像JDK 7 那樣重新計算hash值,只需要看原來的hash值新增的bit位是1還是0就好了,是0,則表示索引沒變,是1,則表示索引變成了 “原索引+oldCap”,我們可以參照下圖中,容量16擴充為32的resize示意圖:
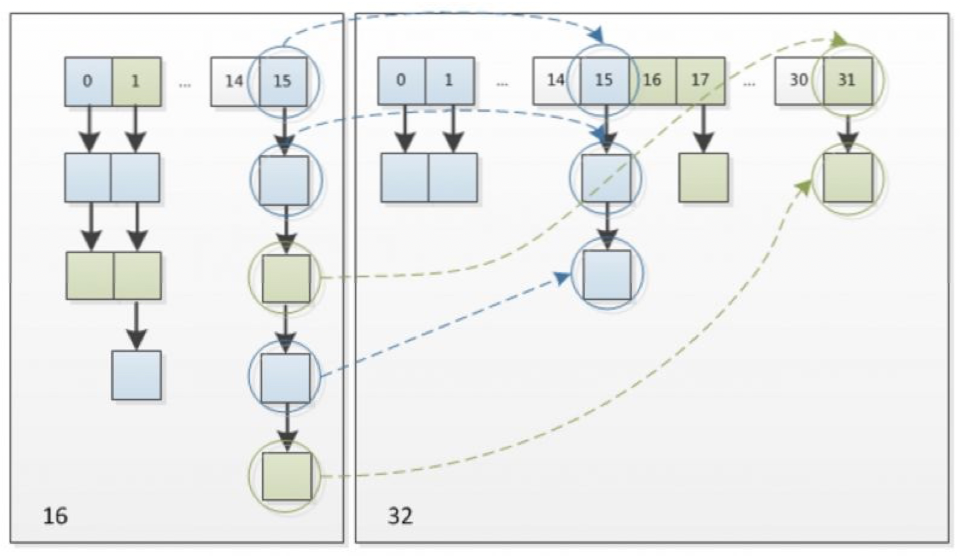 ?
?
對于hash值的高位是否為1,只需要和擴容后的長度 做 與運算 就可以知道了,因為擴容后的長度是2的n次方,所以高位必為1,低位必為0,如10000這種形式,原始碼中是通過 e.hash & oldCap 來實作這個邏輯的,
這個設計非常的巧妙,既省去了重新計算hash值的時間,同時由于新增的1 bit是0 還是1可以認為是隨機的,因此resize的程序中,也把之前出現沖突的節點均勻地分散到了新的位桶中,這一塊就是JDK 8中新增的優化點,
另外還有一點需要我們注意,JDK 7中進行rehash的時候,舊鏈表遷移到新鏈表的時候,如果新鏈表所在的陣列索引位置相同,則鏈表元素會倒置,但是JDK 8中不會出現倒置現象,
四. 結語
好了,到此為止,壹哥 就帶各位把HashMap的擴容機制、rehash的原理 復習完畢,可以說這是目前為止最難搞、也最復雜的一個知識點了,不知道你有么有看明白呢?若有識訓,請給壹哥點個贊吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390589.html
標籤:其他