一、HDFS分布式檔案系統概述
Hdfs Hadoop Distrabuted File System 分布式檔案系統
1、分布式:
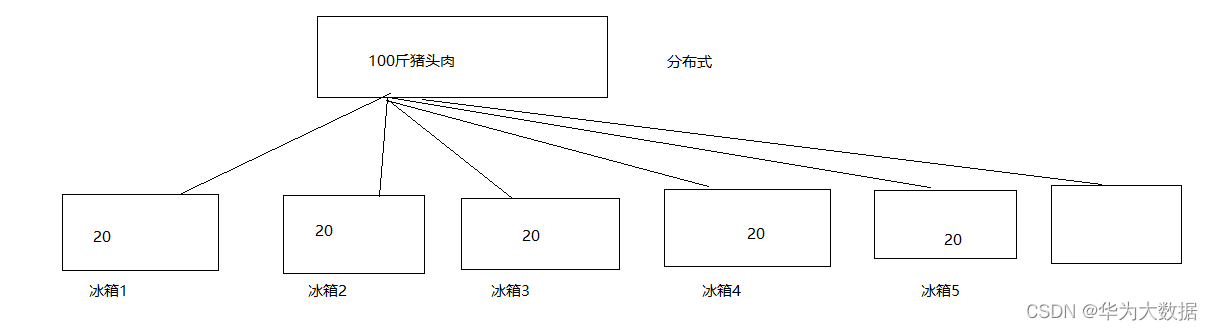
2、HDFS特點:
海量資料存盤(GB,TB,PB級的資料)1MB=1024KB 1 GB=1024MB
高容錯性:默認保存副本(3個),當一份資料丟失時,可以恢復資料,hdfs內部機制實作的,
資料冗余
高延時
不適合場景:
低延時:
不適合存放大量小檔案
多用戶輸入,不適合做任意修改,
了解幾個名詞
3、了解幾個名詞
1、POSIX:可移植作業系統介面(英語:Portable Operating System Interface)是IEEE為要在各種UNIX作業系統上運行軟體
2、什么是資料的流式訪問:
- 流式資料訪問:最小化磁盤的尋址開銷,只需要尋址一次,然后一直讀下去,適合一次寫,多次讀的資料訪問
- 隨機資料訪問:要求定位、查詢或修改資料的延遲較小,傳統關系型資料庫符合這一點
3、Nutch,Lucene,Avro
(1)Apache Nutch Web:Nutch是一個開源Java 實作的搜索引擎,包括全文搜索和Web爬蟲,
(2) Nutch的創始人是Doug Cutting(道格卡廷),他同時也是Lucene(全文檢索引擎)、Hadoop和Avro開源專案的創始人
(3)Avro是Hadoop下的子專案,是一個資料序列化系統,設計用于支持大批量資料交換的應用,主要特點有:支持二進制序列化方式,可以便捷,快速地處理大量資料;
二、HDFS的基本架構
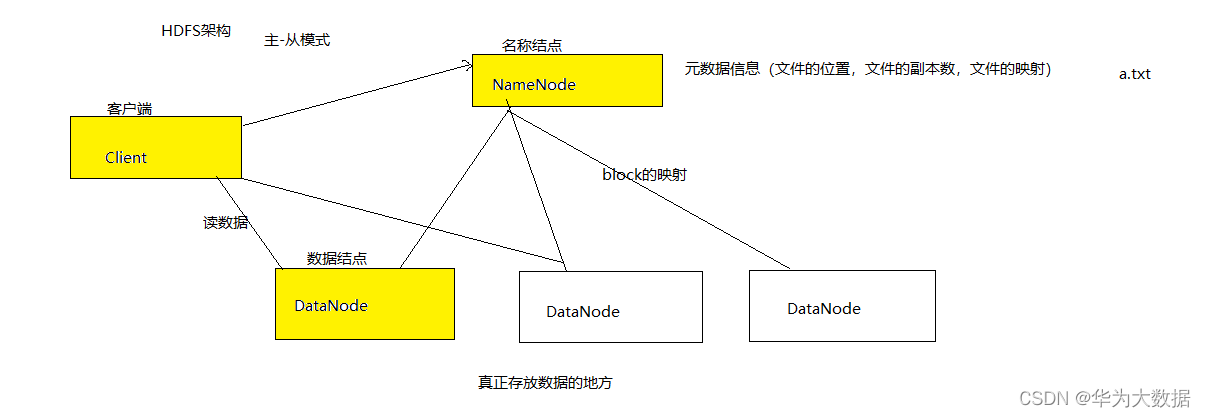 由三部分組成(Client NameNode DataNode)采用了Master-Slaver(主—從)模式
由三部分組成(Client NameNode DataNode)采用了Master-Slaver(主—從)模式
1、Client作用:
向NN發出請求,獲得檔案的位置,副本數
將檔案切分block,每個塊默認是128M(大小可以設定)
向DataNode讀寫檔案
2、NameNode作用:
管理元資料資訊(檔案名,位置,大小,副 本,屬組)
資料塊的映射
配置副本
和DN保持 心跳,如果10分鐘沒有收到,表示宕機了,則洗掉,資料轉移,
3、DataNode的作用:
真正存放資料
執行資料的讀寫
向NN發送心跳,3秒一次
4、NameNode 和DataNode 區別
| NameNode | DataNode |
| 存盤元資料 | 存盤資料內容 |
| 元資料保存在記憶體 | 檔案內容存在磁盤上 |
問題一:為什么不能存放大量小檔案?
因為一個集群只有一個NameNode,NameNode存放元資料資訊在記憶體,如果存放大量小檔案,會占用很大記憶體,成為集群的瓶頸,
問題二:如何理解元資料資訊
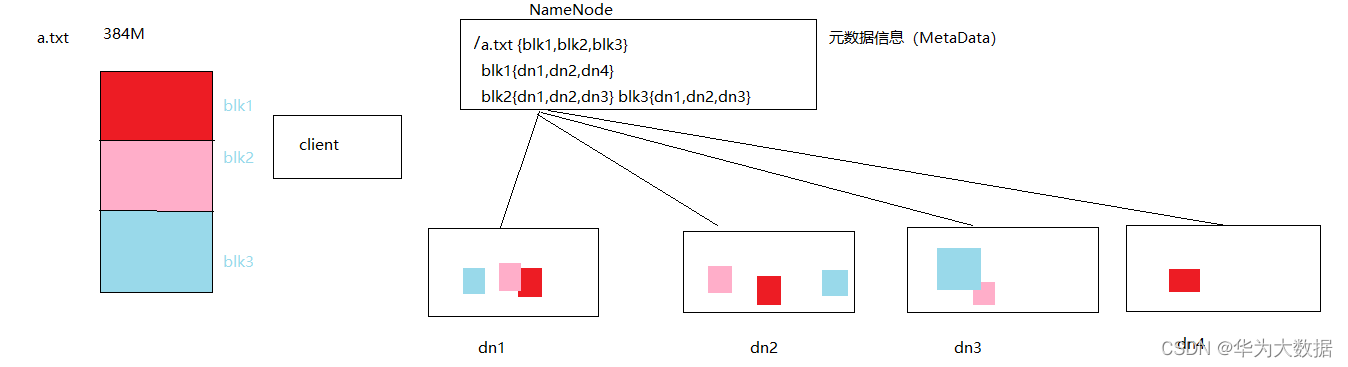 5、NameNode是如何存放資料
5、NameNode是如何存放資料
Fsimgage存放目錄
Editlog客戶端的操作(創建,洗掉,重命名)
三、HDFS的高可靠性(HA)
解決了只有一個NameNode可能會產生單 點故障問題-----------主備模式
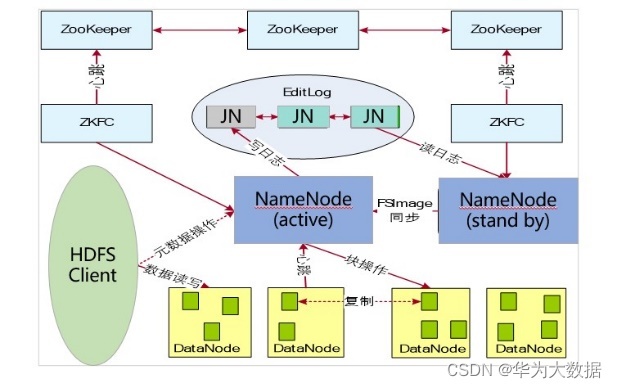
- 主NN和備NN的資料同步
主NN寫日志到JN上,同時備NN從JN上讀取日志
2.主備切換
ZKFC對主NN進行監控,當主NN出現錯誤或宕機時時,ZKFC發送給zookeeper,Zookeeper讓備NN成為主NN
四、元資料持久化
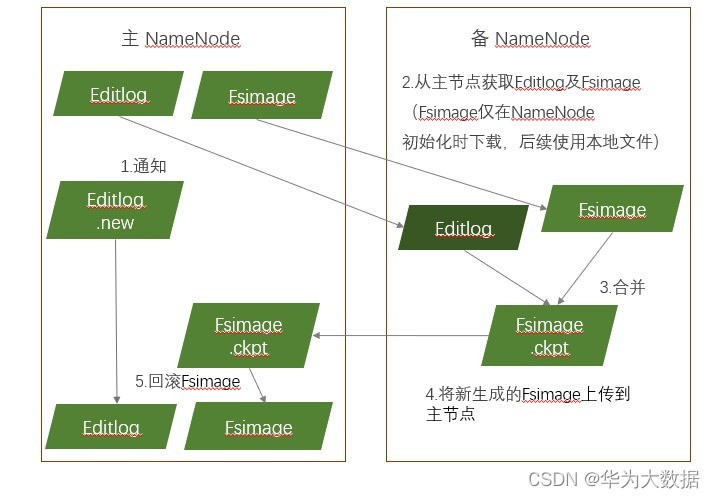
觸發條件:每隔1個小時,或editlog滿了64M時進行合并
- 備NN通知主NN生成EditLog.new檔案
- 從主結點獲取FsImage和Editlog
- 將獲得的檔案進行合并,生成新檔案fsimage.ckpt
- 將新檔案fsimage.ckpt上傳到主NN
- 重命名為fsimage,覆寫原來的fsimage
- 將Editlog.new命名為Editlog
- 根據觸發條件回圈1-6步驟,
-
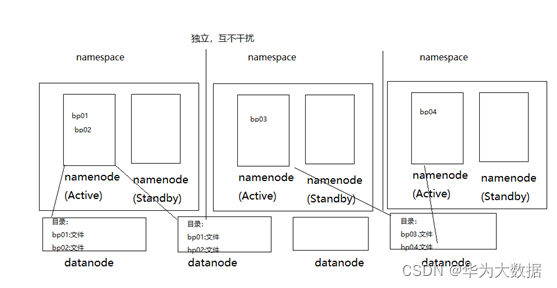
五、HDFS聯邦 (Federation)
-
-
在使用主Namenode中的元資料,而且是放在記憶體里面,當資料增到大一定時,會出現記憶體不夠用的狀態,namenode記憶體就成為整個集群的一個瓶頸,為了解決這個問題,將NameNode做一個橫向擴展,方案就是Federation,很好的解決了記憶體過高的問題,
六、HDFS副本策略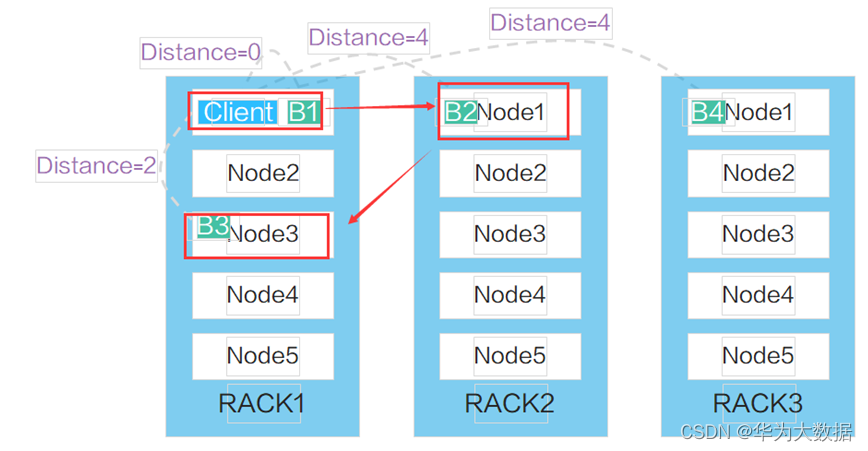
副本距離公式:同一臺服務器的距離是0
同一個機架不同的服務器距離為2
不同機架的服務器距離為4
七、HDFS讀取流程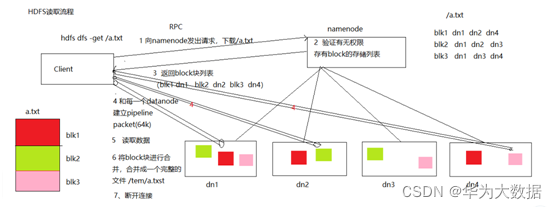
八、HDFS檔案寫入流程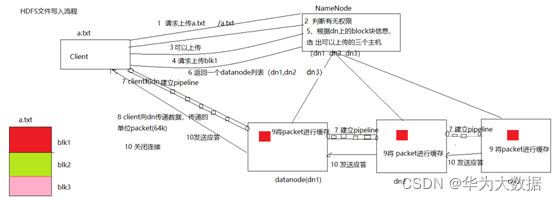
九、常用的shell命令
1、ls 顯示目錄資訊
2、 mkdir 創建目錄
3、put :上傳系統中的檔案到HDFS指定的目 錄
4、cat 顯示檔案的內容
5、text 以字符形式列印一個檔案的內容
6、moveFromLocal 從本地剪切到HDFS
7、appendToFile 追加一個檔案到已經存在的檔案的末尾
8、cp 拷貝
9、mv 移動
10、rm 洗掉檔案或檔案夾
11、getmerge 合并下載多個檔案
12、df 統計檔案系統的可用空間13、 du 統計檔案夾的大小
十、Zookeeper容災能力
ZooKeeper能夠完成選舉即能夠正常對外提供服務,
ZooKeeper選舉時,當某一個實體獲得了半數以上的票數時,則變為leader,
對于n個實體的服務,n可能為奇數或偶數,
n為奇數時,假定n=2*x+1 ,則成為leader的節點需獲得x+1票,容災能力為x,
n為偶數時,假定 n=2*x+2 ,則成為leader的節點需要獲得x+2票 (大于一半),容災能力為x,
注:由于5臺和6臺機器構成的集群容災能力是一樣的,所以建議使用奇數個服務器去構建集群,以免造成 浪費,
十一、思考題:
1.ZooKeeper為什么建議奇數部署?
答:容災能力相同,但部署成本低
2.HDFS的資料塊大小為什么一般比磁盤塊大?
塊比磁盤大(磁盤的塊一般為512位元組),目的是為了最小化尋址開銷,塊足夠大,那么從磁盤傳輸資料的時間會明顯大于定位這個塊開始位置所需的時間,但也不能太大,因為map通常只處理一個塊中的資料,如果Map數太少,則作業運行速度會比較慢
3.HDFS的資料在寫入時,能夠讀取到嗎?
當資料在寫入的時候,寫入資料不能立即可見,在命令空間是立即可見的,當寫入超過一個塊或者結束的時候,對一個新的reader就是可見的,當前正在寫入的塊,對其他reader是不可見的
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/390594.html
標籤:其他