寫在前面的話:
課程視頻地址:
https://www.bilibili.com/video/BV1C34y1d74a完整的筆記可在我的公眾號:manor的大資料之路 回復:"高級"獲取~
Mysql高級01
MySQL高級課程簡介
| 序號 | 01** | 02** | 03** | 04** |
|---|---|---|---|---|
| 1 | 基本硬體知識 | 體系結構 | 應用優化 | MySQL 常用工具 |
| 2 | 索引 | 存盤引擎 | 查詢快取優化 | MySQL 日志 |
| 3 | 視圖 | 優化SQL步驟 | 記憶體管理及優化 | MySQL 主從復制 |
| 4 | 存盤程序和函式 | 索引使用 | MySQL鎖問題 | |
| 5 | 觸發器 | SQL優化 | 常用SQL技巧 |
1.基本硬體知識(了解)
1.1計算機作業原理

1.中央處理器(英文Central Processing Unit,CPU)是一臺計算機的運算核心和控制核心,CPU、內部存盤器和輸入/輸出設備是電子計算機三大核心部件,其功能主要是解釋計算機指令以及處理計算機軟 件中的資料,
CPU核心組件:
1.算術邏輯單元(Arithmetic&logical Unit)是中 央處理器(CPU)的執行單元,是所有中央處理器的核
心組成部分,由"And Gate"(與門) 和"Or Gate"(或門)構成的算術邏輯單元,主要功能是進行二位元的算術運算,如加減乘(不包括整數除法),
2.PC:負責儲存記憶體地址,該地址指向下一條即將執行的指令,每解釋執行完一條指令,pc暫存器的值 就會自動被更新為下一條指令的地址,
3.暫存器(Register)是CPU內部的元件,所以在暫存器之間的資料傳送非常快, 用途:1.可將暫存器內的資料執行算術及邏輯運算,
2.存于暫存器內的地址可用來指向記憶體的某個位置,即尋址,
3.可以用來讀寫資料到電腦的周邊設備,4.Cache:快取
2.記憶體(Memory)是計算機的重要部件之一,也稱記憶體儲器和主 存盤器,它用于暫時存放CPU中的運算元
據,與硬碟等外 部存盤器交換的資料,它是外存與C PU進行溝通的橋梁,計算機中所有程式的運行都在
記憶體中進行,記憶體性能的強弱影響計算機整體發揮的水平,只要計算機開始運行,作業系統就會把需要 運算的資料從記憶體調到CPU中進行運算,當運算完成,CPU將結果傳送出來,
1.2磁盤的一些概念
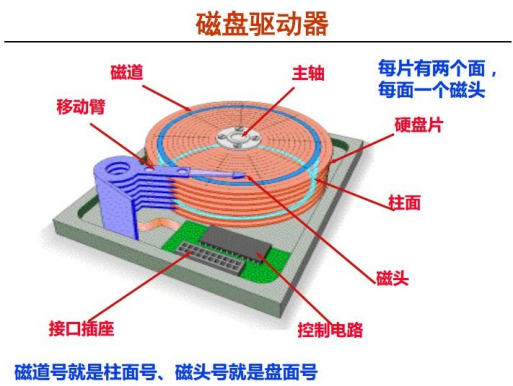
(1)盤片、片面 和 磁頭
硬碟中一般會有多個盤片組成,每個盤片包含兩個面,每個盤面都對應地有一個讀/寫磁頭,受到硬碟整 體體積和生產成本的限制,盤片數量都受到限制,一般都在5片以內,盤片的編號自下向上從0開始,如 最下邊的盤片有0面和1面,再上一個盤片就編號為2面和3面,
如下圖:
(2)扇區 和 磁道
下圖顯示的是一個盤面,盤面中一圈圈灰色同心圓為一條條磁道,從圓心向外畫直線,可以將磁道劃分 為若干個弧段,每個磁道上一個弧段被稱之為一個扇區(圖踐綠色部分),扇區是磁盤的最小組成單 元,通常是512位元組,(由于不斷提高磁盤的大小,部分廠商設定每個扇區的大小是4096位元組)
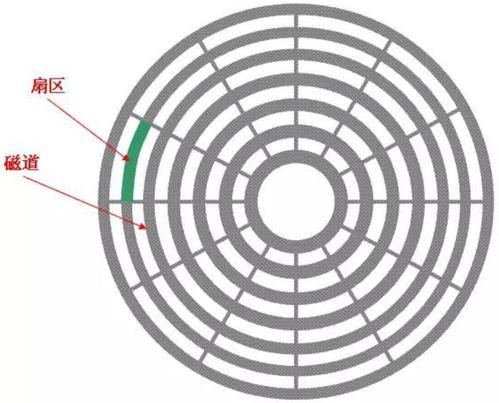
通過磁頭和磁道的接觸,然后我們進行資料的讀寫
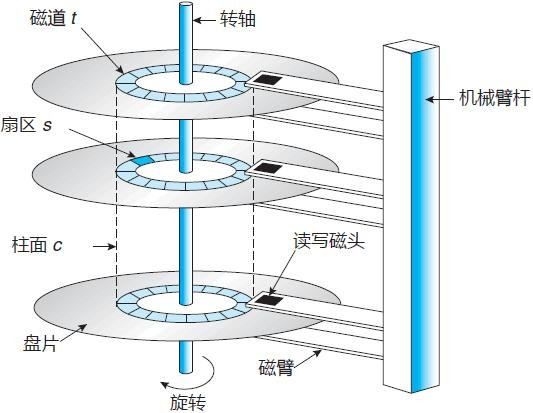
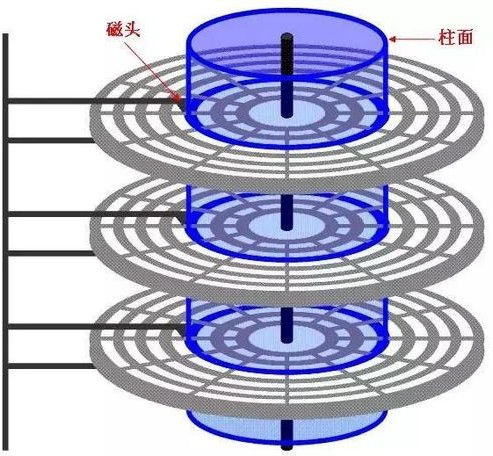
(3)磁頭 和 柱面
硬碟通常由重疊的一組盤片構成,每個盤面都被劃分為數目相等的磁道,并從外緣的“0”開始編號,具有 相同編號的磁道形成一個圓柱,稱之為磁盤的柱面,磁盤的柱面數與一個盤面上的磁道數是相等的,由 于每個盤面都有自己的磁頭,因此,盤面數等于總的磁頭數, 如下圖
3、磁盤容量計算
存盤容量 = 磁頭數 × 磁道(柱面)數 × 每道扇區數 × 每扇區位元組數圖3中磁盤是一個 3個圓盤6個磁頭,7
個柱面(每個盤片7個磁道) 的磁盤,上圖中每條磁道有12個扇區,所以此磁盤的容量為:存盤容量 6
- 7 * 12 * 512 = 258048
每個磁道的扇區數一樣是說的老的硬碟,外圈的密度小,內圈的密度大,每圈可存盤的資料量是一樣 的,新的硬碟資料的密度都一致,這樣磁道的周長越長,扇區就越多,存盤的資料量就越大,
4、磁盤讀取回應時間
1.尋道時間:磁頭從開始移動到資料所在磁道所需要的時間,尋道時間越短,I/O操作越快,目前磁 盤的平均尋道時間一般在3-15ms,一般都在10ms左右,
2.旋轉延遲:盤片旋轉將請求資料所在扇區移至讀寫磁頭下方所需要的時間,旋轉延遲取決于磁盤轉 速,普通硬碟一般都是7200rpm,慢的5400rpm,
3.資料傳輸時間:完成傳輸所請求的資料所需要的時間,
小結一下:從上面的指標來看、其實最重要的、或者說、我們最關心的應該只有兩個:尋道時間;旋轉 延遲
讀寫一次磁盤資訊所需的時間可分解為:尋道時間、延遲時間、傳輸時間,為提高磁盤傳輸效率,軟體 應著重考慮減少尋道時間和延遲時間,(類似于CPU快取行,把隨機讀改成順序讀寫)
5、塊/簇
磁盤塊/簇(虛擬出來的), 塊是作業系統中最小的邏輯存盤單位,作業系統與磁盤打交道的最小單位是磁盤塊,每個塊可以包括2、4、8、16、32、64…2的n次方個扇區,
為什么存在磁盤塊?
讀取方便:由于扇區的數量比較小,數目眾多在尋址時比較困難,所以作業系統就將相鄰的扇區組合在 一起,形成一個塊,再對塊進行整體的操作,分離對底層的依賴:作業系統忽略對底層物理存盤結構的 設計,通過虛擬出來磁盤塊的概念,在系統中認為塊是最小的單位,(就是類似于班級,小組等)
6、page
作業系統經常與記憶體和硬碟這兩種存盤設備進行通信,類似于“塊”的概念,都需要一種虛擬的基本單
位,所以,與記憶體操作,是虛擬一個頁的概念來作為最小單位,與硬碟打交道,就是以塊為最小單位,
7、扇區、塊/簇、page的關系
1.扇區: 硬碟的最小讀寫單元
2.塊/簇: 是作業系統針對硬碟讀寫的最小單元
3.page: 是記憶體與作業系統之間操作的最小單元,
扇區 <= 塊/簇 <= page
8、計算機讀取資料流程
當需要從磁盤讀取資料時,系統會將資料地址傳給磁盤,即確定要讀的資料在哪個磁道,哪個扇區,為 了讀取這個扇區的資料,需要將磁頭放到這個扇區上方,為了實作這一點,磁頭需要移動對準相應磁 道,這個程序叫做 尋道 ,所耗費時間叫做 尋道時間 ,然后磁盤旋轉將目標扇區旋轉到磁頭下,這個程序耗費的時間叫做旋轉時間,
1.3區域性原理,磁盤預讀,CPU快取行,磁盤IO
1、 由于存盤介質的特性,磁盤本身存取就比主存慢很多,再加上機械運動耗費,磁盤的存取速度往往是主存的十萬分之一,因此為了提高效率,要盡量減少磁盤I/O,為了達到這個目的,磁盤往往不是嚴格 按需讀取,而是每次都會預讀,即使只需要一個位元組,磁盤也會從這個位置開始,順序向后讀取一定長 度的資料放入記憶體,這樣做的理論依據是計算機科學中著名的區域性原理:
當一個資料被用到時,其附近的資料也通常會馬上被使用,程式運行期間所需要的資料通常比較集中, 由于磁盤順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對于具有區域性的程式 來說,預讀可以提高I/O效率,
預讀的長度一般為頁(page)的整倍數,頁是計算機管理存盤器的邏輯塊,硬體及作業系統往往將主存 和磁盤存盤區分割為連續的大小相等的塊,每個存盤塊稱為一頁(在許多作業系統中,頁得大小通常為4k),主存和磁盤以頁為單位交換資料,當程式要讀取的資料不在主存中時,會觸發一個缺頁例外,此 時系統會向磁盤發出讀盤信號,磁盤會找到資料的起始位置并向后連續讀取一頁或幾頁載入記憶體中,然 后例外回傳,程式繼續運行,
下圖是計算機硬體延遲的對比圖,供大家參考:

2、磁盤IO的問題
mysql的資料一般以檔案形式存盤在磁盤上,檢索需要磁盤I/O操作,與主存不同,磁盤I/O存在機械運 動耗費,因此磁盤I/O的時間消耗是巨大的,
2.索引
2.1索引概述
MySQL官方對索引的定義為:索引(index)是幫助MySQL高效獲取資料的資料結構(有序),在資料 之外,資料庫系統還維護者滿足特定查找演算法的資料結構,這些資料結構以某種方式參考(指向)數 據, 這樣就可以在這些資料結構上實作高級查找演算法,這種資料結構就是索引,如下面的示意圖所示 :

左邊是資料表,一共有兩列七條記錄,最左邊的是資料記錄的物理地址(注意邏輯上相鄰的記錄在磁盤 上也并不是一定物理相鄰的),為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點 分別包含索引鍵值和一個指向對應資料記錄物理地址的指標,這樣就可以運用二叉查找快速獲取到相應 資料,
一般來說索引本身也很大,不可能全部存盤在記憶體中,因此索引往往以索引檔案的形式存盤在磁盤上, 索引是資料庫中用來提高性能的最常用的工具,
2.2索引優勢劣勢
優勢
1)類似于書籍的目錄索引,提高資料檢索的效率,降低資料庫的IO成本,
2)通過索引列對資料進行排序,降低資料排序的成本,降低CPU的消耗,劣勢
1)實際上索引也是一張表,該表中保存了主鍵與索引欄位,并指向物體類的記錄,所以索引列也是要 占用空間的,
2)雖然索引大大提高了查詢效率,同時卻也降低更新表的速度,如對表進行INSERT、UPDATE、
DELETE,因為更新表時,MySQL 不僅要保存資料,還要保存一下索引檔案每次更新添加了索引列的欄位,都會調整因為更新所帶來的鍵值變化后的索引資訊,
2.3索引結構
索引是在MySQL的存盤引擎層中實作的,而不是在服務器層實作的,所以每種存盤引擎的索引都不一定 完全相同,也不是所有的存盤引擎都支持所有的索引型別的,MySQL目前提供了以下4種索引:
BTREE 索引 : 最常見的索引型別,大部分索引都支持 B 樹索引,
HASH 索引:只有Memory引擎支持 , 使用場景簡單 ,
R-tree 索引(空間索引):空間索引是MyISAM引擎的一個特殊索引型別,主要用于地理空間資料型別,通常使用較少,不做特別介紹,
Full-text (全文索引) :全文索引也是MyISAM的一個特殊索引型別,主要用于全文索引,
InnoDB從Mysql5.6版本開始支持全文索引,MySAM、InnoDB、Memory三種存盤引擎對各種索引型別的支持
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|---|
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我們平常所說的索引,如果沒有特別指明,都是指B+樹(多路搜索樹,并不一定是二叉的)結構組織的 索引,其中聚集索引、復合索引、前綴索引、唯一索引默認都是使用 B+tree 索引,統稱為索引,
2.3.1索引資料結構的選型
從第一塊內容中我們明白了磁盤是怎么存盤檔案的,而我們的mysql的資料檔案又是存盤在磁盤上的, 所以我們有必要去研究一下,mysql是怎么保障資料在磁盤上存盤,效率還能比較高的原因,首先,在 資料庫檔案存盤在磁盤時,為了提升查詢效率,一定會選用合適的資料結構進行檔案的存盤,
接下來咱們探討一下:
1、陣列和鏈表
肯定不能選,這種最基本的資料結構,各自的劣勢太明顯,資料庫對查詢要求是最很高的所以鏈表這種 查詢必須全表遍歷的基本資料結構是不能用的,陣列這種結構在添加資料時成本太大,插入資料時太過 于頻繁,
2、HASH
類似與咱們的hashmap,這樣行嗎? 速度快,但是只要是hash就會產生無序的問題,所以不常用但也有,
3、樹
看來看去也就是樹這種結構比較合理了,二叉查找樹可以嗎?在查找一個資料時,二叉樹是讀取根節 點,小則從左找,大則從右找,每次讀取一個資料,沒有辦法合理的利用區域性原理與磁盤預讀,IO次 數太多太多,其次就是樹的層次還是偏高,所以不適合,那每次讀多個資料,每一個節點存多個資料的 結構就只有B-樹和B+樹了;
接下來就討論這兩種資料結構的選型,
4、B-樹
B-樹,這里的 B 表示 balance( 平衡的意思),B-樹是一種多路自平衡的搜索樹
它類似普通的平衡二叉樹,不同的一點是B-樹允許每個節點有更多的子節點,下圖是 B-樹的簡化圖.
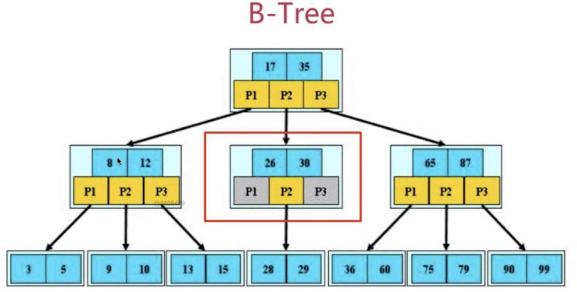
B-樹有如下特點:
1.所有鍵值分布在整顆樹中;
2.任何一個關鍵字出現且只出現在一個結點中;
3.搜索有可能在非葉子結點結束;
4.在關鍵字全集內做一次查找,性能逼近二分查找
5、B+ 樹
mysql默認是主鍵,如果沒有主鍵則使用唯一索引,唯一索引也沒有則使用rowid,行號,所以一定要建 立主鍵,
B+樹是B-樹的變體,也是一種多路搜索樹, 它與 B- 樹的不同之處在于:
1.所有關鍵字存盤在葉子節點出現,內部節點(非葉子節點并不存盤真正的 data)
2.為所有葉子結點增加了一個鏈指標
簡化 B+樹 如下圖
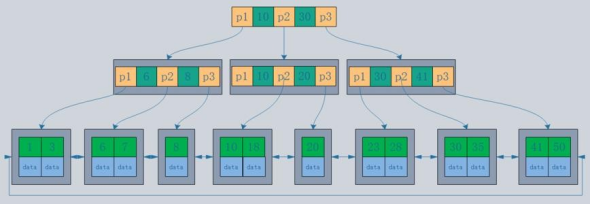
6、為什么使用B-/B+ Tree
紅黑樹等資料結構也可以用來實作索引,但是檔案系統及資料庫系統普遍采用B-/+Tree作為索引結構,
MySQL 是基于磁盤的資料庫系統,索引往往以索引檔案的形式存盤的磁盤上,索引查找程序中就要產生磁盤I/O消耗,相對于記憶體存取,I/O存取的消耗要高幾個數量級,索引的結構組織要盡量減少查找程序中磁盤I/O的存取次數,為什么使用B-/+Tree,還跟磁盤存取原理有關,
MySQL(默認使用InnoDB引擎),將記錄按照頁的方式進行管理,每頁大小默認為16K(這個值可以修 改).linux 默認頁大小為4K
7、為什么使用 B+樹
1.B+樹更適合外部存盤,由于內節點無 data 域,一個結點可以存盤更多的內結點,每個節點能索引的范圍更大更精確,也意味著 B+樹單次磁盤IO的資訊量大于B-樹,I/O效率更高,
2.Mysql是一種關系型資料庫,區間訪問是常見的一種情況,B+樹葉節點增加的鏈指標,加強了區間訪 問性,可使用在范圍區間查詢等,而B-樹每個節點 key 和 data 在一起,則無法區間查找,
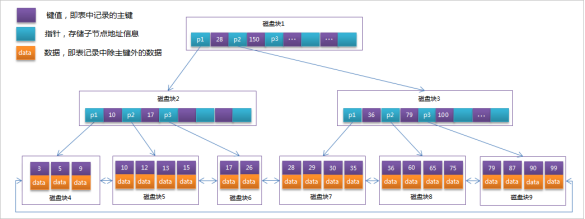
2.3.2MySQL中的B+Tree
MySql索引資料結構對經典的B+Tree進行了優化,在原B+Tree的基礎上,增加一個指向相鄰葉子節點的 鏈表指標,就形成了帶有順序指標的B+Tree,提高區間訪問的性能,
MySQL中的 B+Tree 索引結構示意圖:
2.4索引分類
1)單值索引 :即一個索引只包含單個列,一個表可以有多個單列索引
2)唯一索引 :索引列的值必須唯一,但允許有空值
3)復合索引 :即一個索引包含多個列
2.5索引語法
索引在創建表的時候,可以同時創建, 也可以隨時增加新的索引,準備環境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL, PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2); insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China'); insert into `country` (`country_id`, `country_name`) values(2,'America'); insert into `country` (`country_id`, `country_name`) values(3,'Japan'); insert into `country` (`country_id`, `country_name`) values(4,'UK');
2.5.1創建索引
語法 :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 為city表中的city_name欄位創建索引 ;

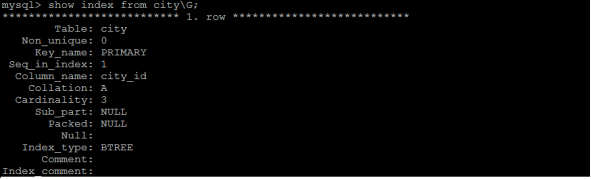
2.5.2查看索引
語法:
show index from table_name;
示例:查看city表中的索引資訊;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/392115.html
標籤:其他