目錄
前言
一、時間復雜度和空間復雜度
1,演算法效率
2,時間復雜度
①時間復雜度的概念
②大O的漸進表示法
③常見時間復雜度計算舉例
3,空間復雜度
二,線性表(單鏈表和雙鏈表)
1,概念
2,順序表
①概念
②介面實作
③創建順序表
④列印順序表
⑤獲取順序表有效長度
⑥在pos位置增加元素
⑦判斷是否由某個元素、查找某個元素對應的位置,找不到回傳-1
⑧獲取 pos 位置的元素、給 pos 位置的元素設為/更新 value
⑨洗掉第一次出現的關鍵字key
3,鏈表
①概念
②鏈表的實作
③創建節點
④創建鏈表、列印鏈表
⑤查找是否包含關鍵字key是否在單鏈表當中、得到單鏈表的長度
⑥頭插法、尾插法
⑦找到index-1位置的節點的地址、插入元素
⑧找到要洗掉的關鍵字的前驅、洗掉第一次出現關鍵字為key的節點
⑨ 洗掉所有值為key的節點
⑩清空鏈表
4,雙向鏈表
①鏈表的實作
②構造節點和鏈表
③列印鏈表、求鏈表長度
④查詢key
⑤頭插法
⑥尾插法
⑦尋找插入節點
⑧插入元素
⑨洗掉元素
⑩清空鏈表
5,筆試習題
①反轉一個單鏈表
②給定一個帶有頭結點 head 的非空單鏈表,回傳鏈表的中間結點
③輸入一個鏈表,輸出該鏈表中倒數第k個結點
?
④洗掉鏈表中的多個重復值
⑤鏈表的回文結構
⑥合并兩個鏈表
⑦輸入兩個鏈表,找出它們的第一個公共結點
⑧判斷一個鏈表是否有環
⑨求有環鏈表的環第一個結點
三,堆疊和佇列
1,堆疊
①概念
②堆疊的操作
③堆疊的實作
④實作mystack
2,佇列
①概念
②佇列的實作
③實作myqueue
四,二叉樹
1,樹
①概念
②樹的基礎概念
2,二叉樹
①概念
②兩種特殊的二叉樹
③二叉樹的性質
①二叉樹的遍歷
②前序遍歷
?③中序遍歷
④后序遍歷
3,二叉搜索樹
①概念
②操作-查找
③操作-插入
④操作-洗掉
⑤性能分析
4,筆試習題
①二叉樹前序遍歷
②二叉樹中序遍歷
③二叉樹后序遍歷
④檢查兩棵樹是否相同
⑤二叉樹的最大深度
⑥另一顆樹的子樹
⑦判斷一顆樹是否為一顆平衡二叉樹
⑧對稱二叉樹
⑨二叉樹鏡像
五,優先級佇列(堆)
1,二叉樹的順序存盤
①存盤方式
②下標關系
③二叉樹順序遍歷
2,堆
①概念
②操作-向下調整
③建堆(建大堆為例)
3,堆的應用-優先級佇列
①概念
②內部原理
③入佇列
④出佇列(優先級最高)
⑤回傳隊首元素(優先級最高)
4,堆排序
六,排序
1,概念
①排序
②穩定性
2,排序詳解
①直接插入排序
②希爾排序
③直接選擇排序
④堆排序
⑤冒泡排序
⑥快速排序
⑦歸并排序
七,List
1,ArrayList簡介
①ArrayList的構造
②ArrayList常見操作
③ ArrayList的遍歷
八,Map和Set
1,搜索
①概念及場景
②模型
2,Map的使用
①關于Map的說明
②關于Map.Entry的說明
③Map 的常用方法說明
3,Set的使用
①常見方法說明
②TreeSet的使用案例
前言
資料結構作為比較難學習的學科來說,它也是我們未來作為程式員必須要牢牢掌握的一門學科,我們應該多畫圖,多寫代碼,才能有所識訓,本篇博客可以作為入門級別的教學,里面會有圖解和詳細的代碼,總結的內容即代表個人觀點,還有部分資料結構內容沒有總結,但足夠作為一名資料結構的初學者學習,還有各種大廠的筆試題詳解,本篇博客內容較長,建議收藏,如果你認為本篇博客寫的不錯的話,求點贊,求收藏,制作不易,廢話不多說,讓我們學起來吧!!!
一、時間復雜度和空間復雜度
1,演算法效率
演算法效率分析分為兩種:第一種是時間效率,第二種是空間效率,時間效率被稱為時間復雜度,而空間效率被 稱作空間復雜度, 時間復雜度主要衡量的是一個演算法的運行速度,而空間復雜度主要衡量一個演算法所需要的額 外空間,在計算機發展的早期,計算機的存盤容量很小,所以對空間度很是在乎,但是經過計算機行業的 迅速發展,計算機的存盤容量已經達到了很高的程度,所以我們如今已經不需要再特別關注一個演算法的空間復雜度,
2,時間復雜度
①時間復雜度的概念
時間復雜度的定義:在計算機科學中,演算法的時間復雜度是一個函式,它定量描述了該演算法的運行時間,一個演算法執行所耗費的時間,從理論上說,是不能算出來的,只有你把你的程式放在機器上跑起來,才能知道,但 是我們需要每個演算法都上機測驗嗎?是可以都上機測驗,但是這很麻煩,所以才有了時間復雜度這個分析方 式,一個演算法所花費的時間與其中陳述句的執行次數成正比例,演算法中的基本操作的執行次數,為演算法的時間復雜度,
②大O的漸進表示法
void func1(int N){
int count = 0;
for (int i = 0; i < N ; i++) {
for (int j = 0; j < N ; j++) {
count++;
}
}
for (int k = 0; k < 2 * N ; k++) {
count++;
}
int M = 10;
while ((M--) > 0) {
count++;
}
System.out.println(count);
}請計算一下func1基本操作執行了多少次?

Func1 執行的基本操作次數 :
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010
實際中我們計算時間復雜度時,我們其實并不一定要計算精確的執行次數,而只需要大概執行次數,那么這里 我們使用大O的漸進表示法,
大O符號(Big O notation):是用于描述函式漸進行為的數學符號,
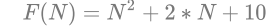
推導大O階方法:
1、用常數1取代運行時間中的所有加法常數,
2、在修改后的運行次數函式中,只保留最高階項,
3、如果最高階項存在且不是1,則去除與這個專案相乘的常數,得到的結果就是大O階,
使用大O的漸進表示法以后,Func1的時間復雜度為:
O(N^2)
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通過上面我們會發現大O的漸進表示法去掉了那些對結果影響不大的項,簡潔明了的表示出了執行次數, 另外有些演算法的時間復雜度存在最好、平均和最壞情況:
最壞情況:任意輸入規模的最大運行次數(上界)
平均情況:任意輸入規模的期望運行次數
最好情況:任意輸入規模的最小運行次數(下界)
在實際中一般情況關注的是演算法的最壞運行情況,所以陣列中搜索資料時間復雜度為O(N)
③常見時間復雜度計算舉例
void func2(int N) {
int count = 0;
for (int k = 0; k < 2 * N ; k++) {
count++;
}
int M = 10;
while ((M--) > 0) {
count++;
}
System.out.println(count);
}
void func3(int N, int M) {
int count = 0;
for (int k = 0; k < M; k++) {
count++;
}
for (int k = 0; k < N ; k++) {
count++;
}
System.out.println(count);
}
void func4(int N) {
int count = 0;
for (int k = 0; k < 100; k++) {
count++;
}
System.out.println(count);
}
void bubbleSort(int[] array) {
for (int end = array.length; end > 0; end--) {
boolean sorted = true;
for (int i = 1; i < end; i++) {
if (array[i -1] > array[i]) {
Swap(array, i - 1, i);
sorted = false;
}
}
if (sorted == true) {
break;
}
}
}
int binarySearch(int[] array, int value) {
int begin = 0;
int end = array.length - 1;
while (begin <= end) {
int mid = begin + ((end-begin) / 2);
if (array[mid] < value)
begin = mid + 1;
else if (array[mid] > value)
end = mid - 1;
else
return mid;
}
return -1;
}
long factorial(int N) {
return N < 2 ? N : factorial(N-1) * N;
}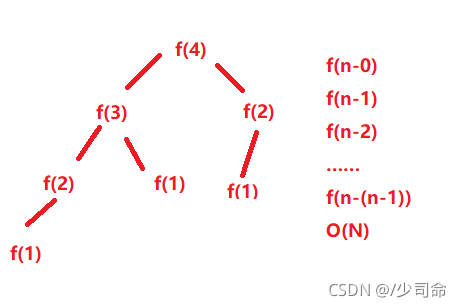

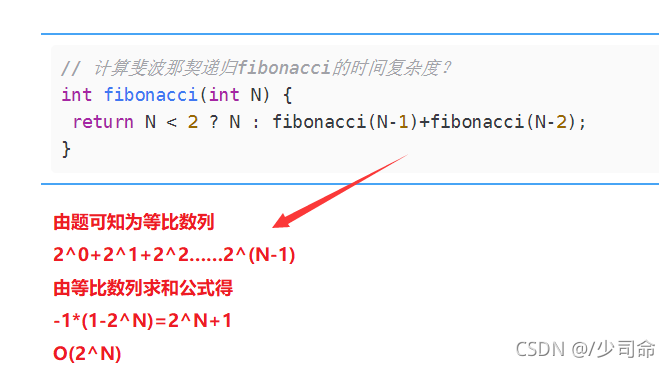
// 計算斐波那契遞回fibonacci的時間復雜度?
int fibonacci(int N) {
return N < 2 ? N : fibonacci(N-1)+fibonacci(N-2);
}
3,空間復雜度
空間復雜度是對一個演算法在運行程序中臨時占用存盤空間大小的量度 ,空間復雜度不是程式占用了多少bytes 的空間,因為這個也沒太大意義,所以空間復雜度算的是變數的個數,空間復雜度計算規則基本跟實踐復雜度 類似,也使用大O漸進表示法,
// 計算bubbleSort的空間復雜度?
void bubbleSort(int[] array) {
for (int end = array.length; end > 0; end--) {
boolean sorted = true;
for (int i = 1; i < end; i++) {
if (array[i - 1] > array[i]) {
Swap(array, i - 1, i);
sorted = false;
}
}
if (sorted == true) {
break;
}
}
}使用了常數個額外空間,所以空間復雜度為 O(1)
// 計算fibonacci的空間復雜度?
int[] fibonacci(int n) {
long[] fibArray = new long[n + 1];
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; i++) {
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}動態開辟了N個空間,空間復雜度為 O(N)
// 計算階乘遞回Factorial的時間復雜度?
long factorial(int N) {
return N < 2 ? N : factorial(N-1)*N;
}遞回呼叫了N次,開辟了N個堆疊幀,每個堆疊幀使用了常數個空間,空間復雜度為O(N)
二,線性表(單鏈表和雙鏈表)
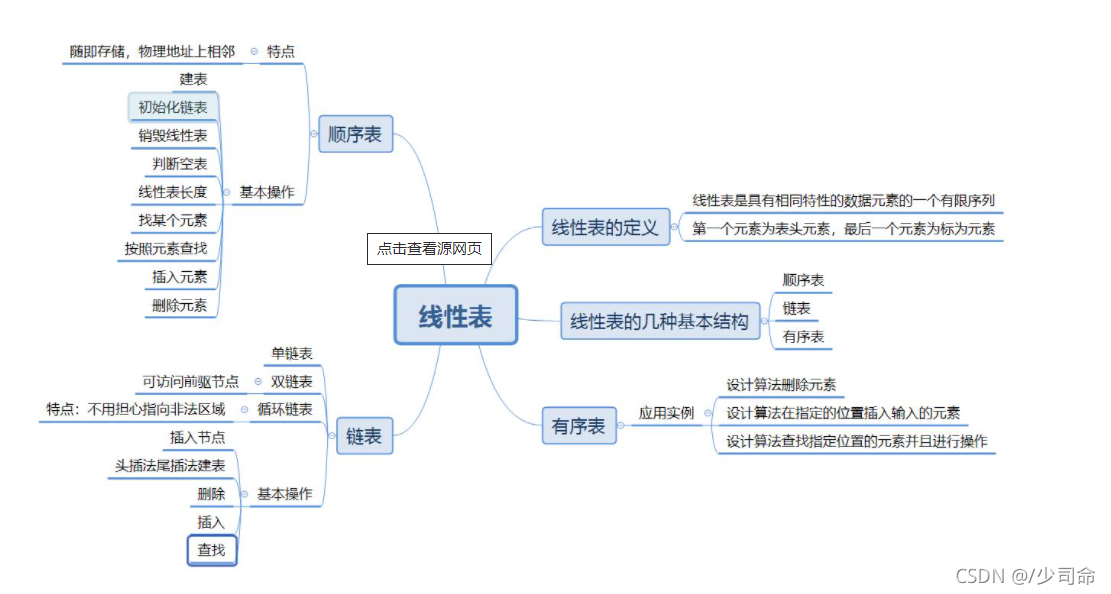
1,概念
線性表(linear list)是n個具有相同特性的資料元素的有限序列, 線性表是一種在實際中廣泛使用的資料結構,常見的線性表:順序表、鏈表、堆疊、佇列、字串.
線性表在邏輯上是線性結構,也就說是連續的一條直線,但是在物理結構上并不一定是連續的,線性表在物理上存盤 時,通常以陣列和鏈式結構的形式存盤,
2,順序表
①概念
順序表是用一段物理地址連續的存盤單元依次存盤資料元素的線性結構,一般情況下采用陣列存盤,在陣列上完成數 據的增刪查改,
順序表一般可以分為:
靜態順序表:使用定長陣列存盤,
動態順序表:使用動態開辟的陣列存盤,
靜態順序表適用于確定知道需要存多少資料的場景
靜態順序表的定長陣列導致N定大了,空間開多了浪費,開少了不夠用
相比之下動態順序表更靈活, 根據需要動態的分配空間大小,
②介面實作
class SeqList {
// 列印順序表
public void display() {
}
// 在 pos 位置新增元素
public void add(int pos, int data) {
}
// 判定是否包含某個元素
public boolean contains(int toFind) {
return true;
}
// 查找某個元素對應的位置
public int search(int toFind) {
return -1;
}
// 獲取 pos 位置的元素
public int getPos(int pos) {
return -1;
}
// 給 pos 位置的元素設為 value
public void setPos(int pos, int value) {
}
//洗掉第一次出現的關鍵字key
public void remove(int toRemove) {
}
// 獲取順序表長度
public int size() {
return 0;
}
// 清空順序表
public void clear() {
}
}③創建順序表
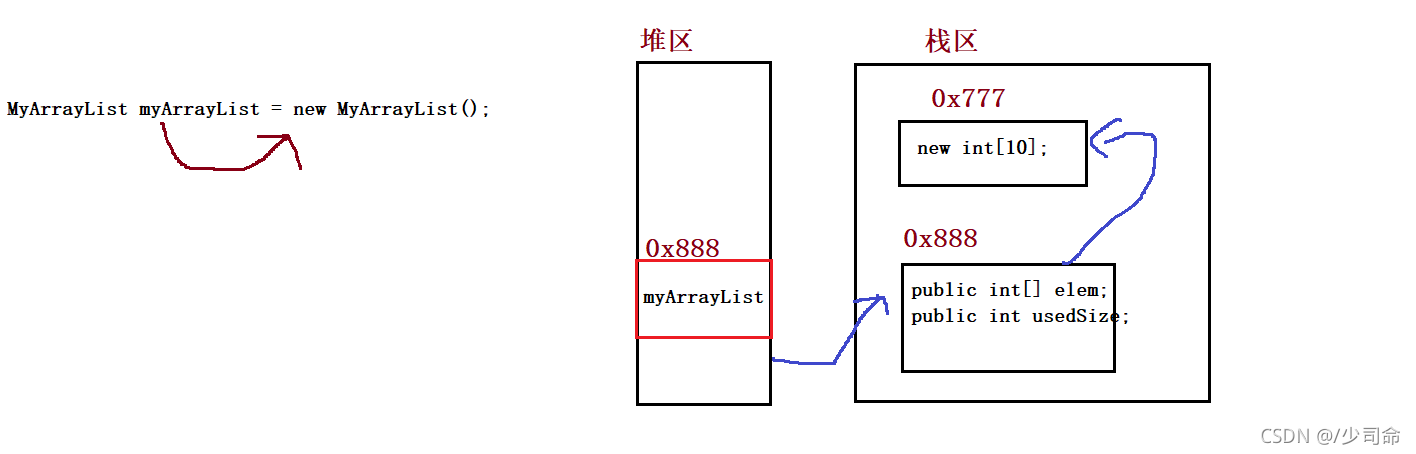
public int[] elem;
public int usedSize;//有效的資料個數
public MyArrayList() {
this.elem = new int[10];
}④列印順序表
// 列印順序表
public void display() {
for (int i = 0; i < this.usedSize; i++) {
System.out.print(this.elem[i]+" ");
}
System.out.println();
}⑤獲取順序表有效長度
// 獲取順序表的有效資料長度
public int size() {
return this.usedSize;
}⑥在pos位置增加元素

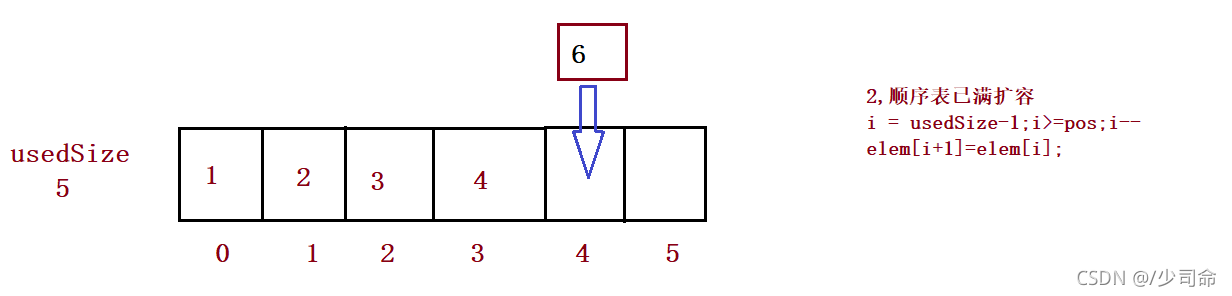
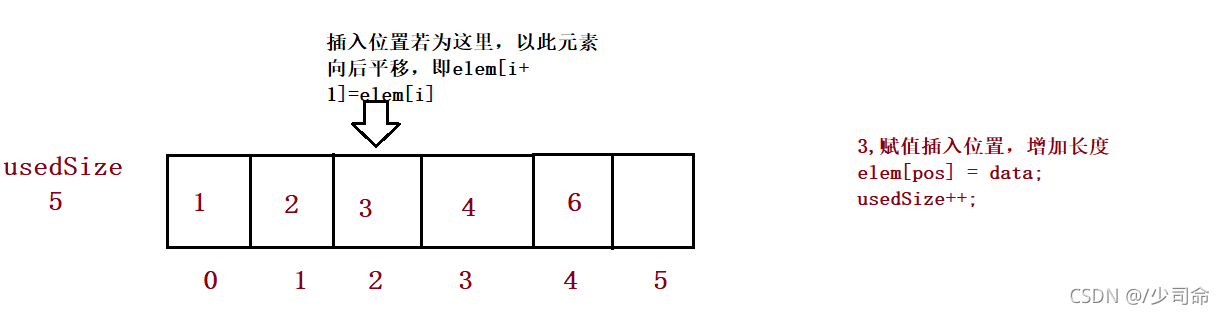
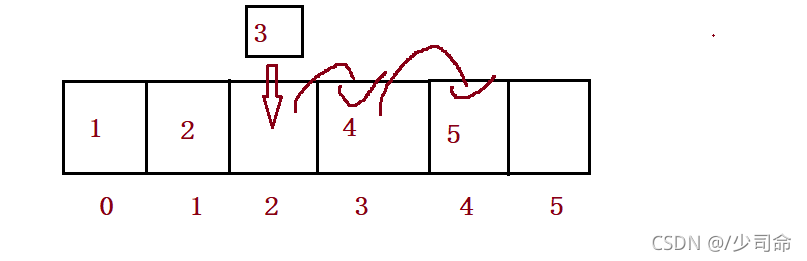
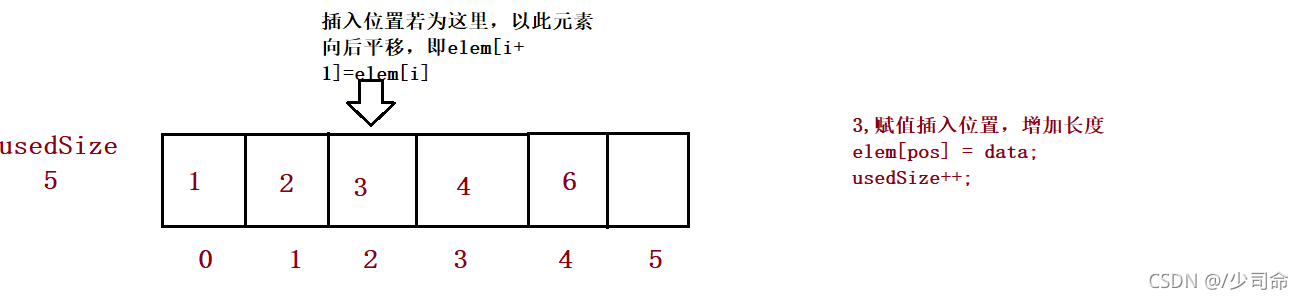
public boolean isFull() {
return this.usedSize == this.elem.length;
} // 在 pos 位置新增元素
public void add(int pos, int data) {
if(pos < 0 || pos > usedSize) {
System.out.println("pos 位置不合法!");
return;
}
if(isFull()) {
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
//3、
for (int i = this.usedSize-1; i >= pos ; i--) {
this.elem[i+1] = this.elem[i];
}
this.elem[pos] = data;
this.usedSize++;
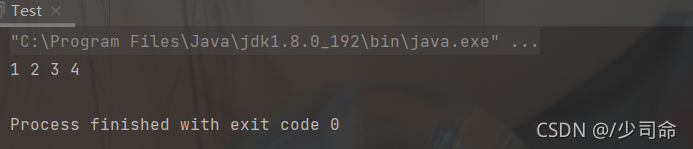
}public static void main(String[] args) {
MyArrayList myArrayList = new MyArrayList();
myArrayList.add(0,1);
myArrayList.add(1,2);
myArrayList.add(2,3);
myArrayList.add(3,4);
myArrayList.display();
}
⑦判斷是否由某個元素、查找某個元素對應的位置,找不到回傳-1
// 判定是否包含某個元素
public boolean contains(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if(this.elem[i] == toFind) {
return true;
}
}
return false;
} public int search(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if(this.elem[i] == toFind) {
return i;
}
}
return -1;
}⑧獲取 pos 位置的元素、給 pos 位置的元素設為/更新 value
public int getPos(int pos) {
if(pos < 0 || pos >= this.usedSize) {
System.out.println("pos 位置不合法");
return -1;//所以 這里說明一下,業務上的處理,這里不考慮 后期可以拋例外
}
if(isEmpty()) {
System.out.println("順序表為空!");
return -1;
}
return this.elem[pos];
}public boolean isEmpty() {
return this.usedSize==0;
} public void setPos(int pos, int value) {
if(pos < 0 || pos >= this.usedSize) {
System.out.println("pos位置不合法");
return;
}
if(isEmpty()) {
System.out.println("順序表為空!");
return;
}
this.elem[pos] = value;
}⑨洗掉第一次出現的關鍵字key
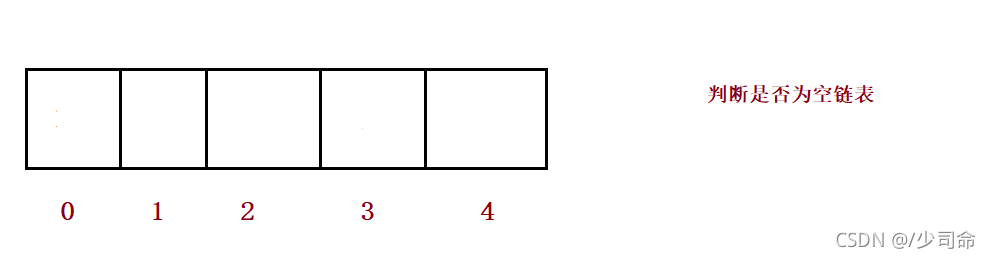
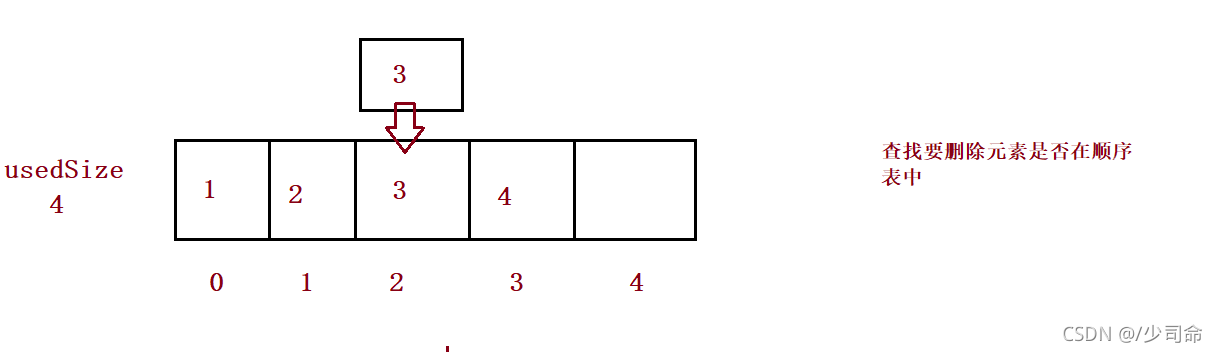
public void remove(int toRemove) {
if(isEmpty()) {
System.out.println("順序表為空!");
return;
}
int index = search(toRemove);
if(index == -1) {
System.out.println("沒有你要洗掉的數字!");
return;
}
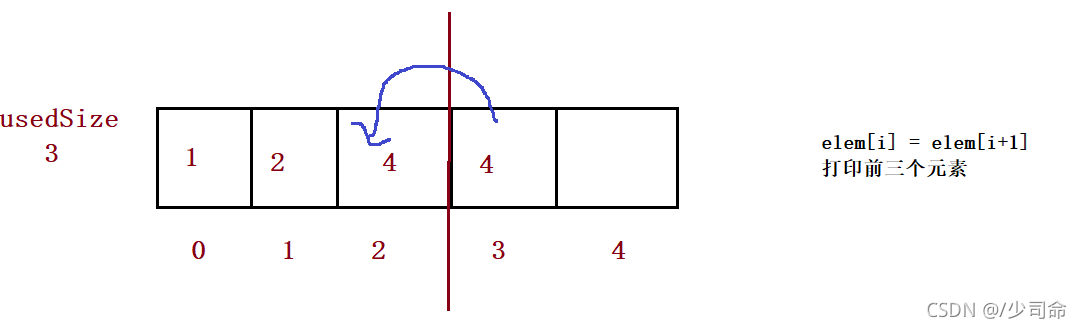
for (int i = index; i < this.usedSize-1; i++) {
this.elem[i] = this.elem[i+1];
}
this.usedSize--;
//this.elem[usedSize] = null; 如果陣列當中是參考資料型別,
}public static void main(String[] args) {
MyArrayList myArrayList = new MyArrayList();
myArrayList.add(0,1);
myArrayList.add(1,2);
myArrayList.add(2,3);
myArrayList.add(3,4);
myArrayList.remove(3);
myArrayList.display();
}
3,鏈表
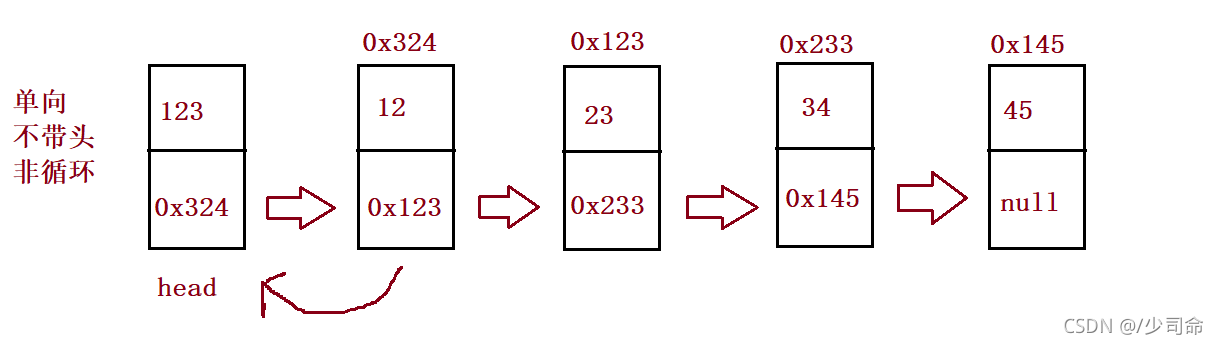
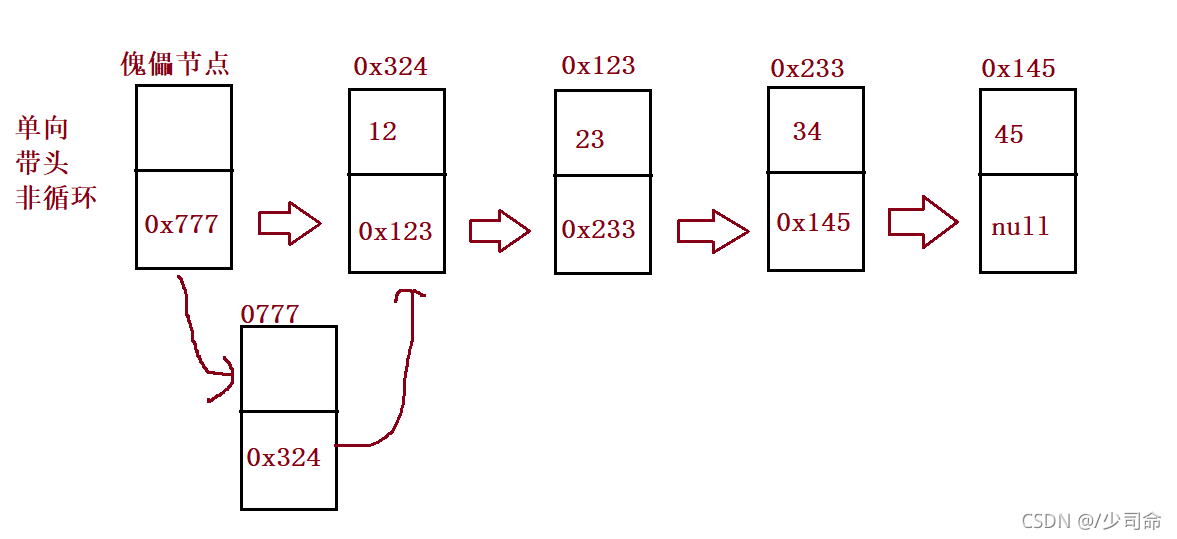
①概念
鏈表是一種物理存盤結構上非連續存盤結構,資料元素的邏輯順序是通過鏈表中的參考鏈接次序實作的 ,
鏈表分類

②鏈表的實作
// 1、無頭單向非回圈鏈表實作
public class SingleLinkedList {
//頭插法
}
public void addFirst(int data){
//尾插法
}
public void addLast(int data){
//任意位置插入,第一個資料節點為0號下標
}
public boolean addIndex(int index,int data){
//查找是否包含關鍵字key是否在單鏈表當中
}
public boolean contains(int key){
//洗掉第一次出現關鍵字為key的節點
}
public void remove(int key){
//洗掉所有值為key的節點
}
public void removeAllKey(int key){
//得到單鏈表的長度
}
public int size(){
}
public void display(){
}
public void clear(){
}
}③創建節點
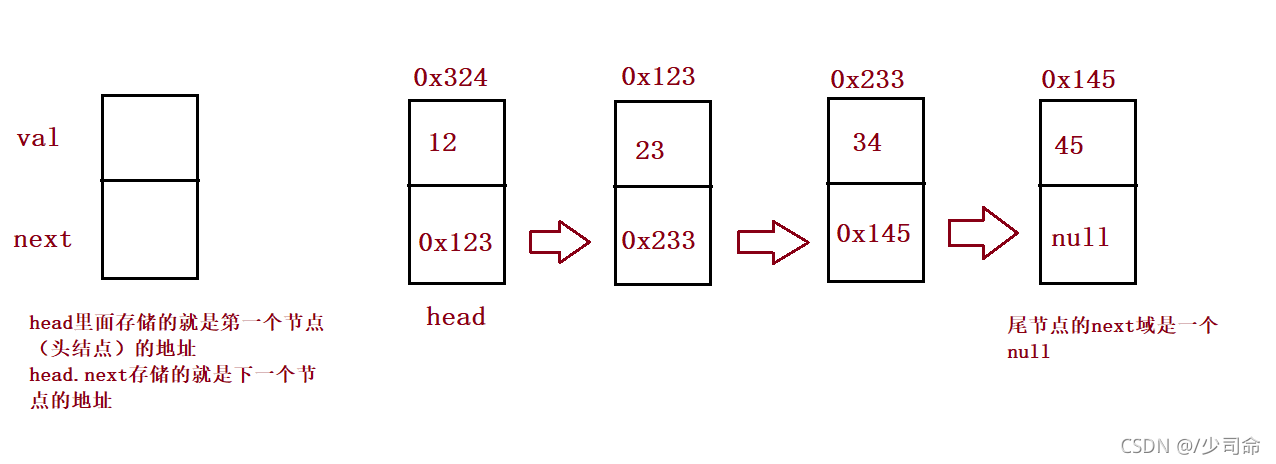
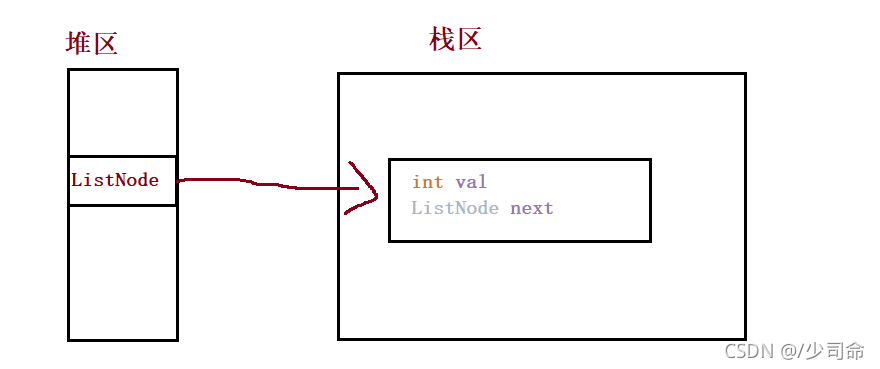
public ListNode head;//鏈表的頭參考lass ListNode {
public int val;
public ListNode next;//null
public ListNode(int val) {
this.val = val;
}
④創建鏈表、列印鏈表
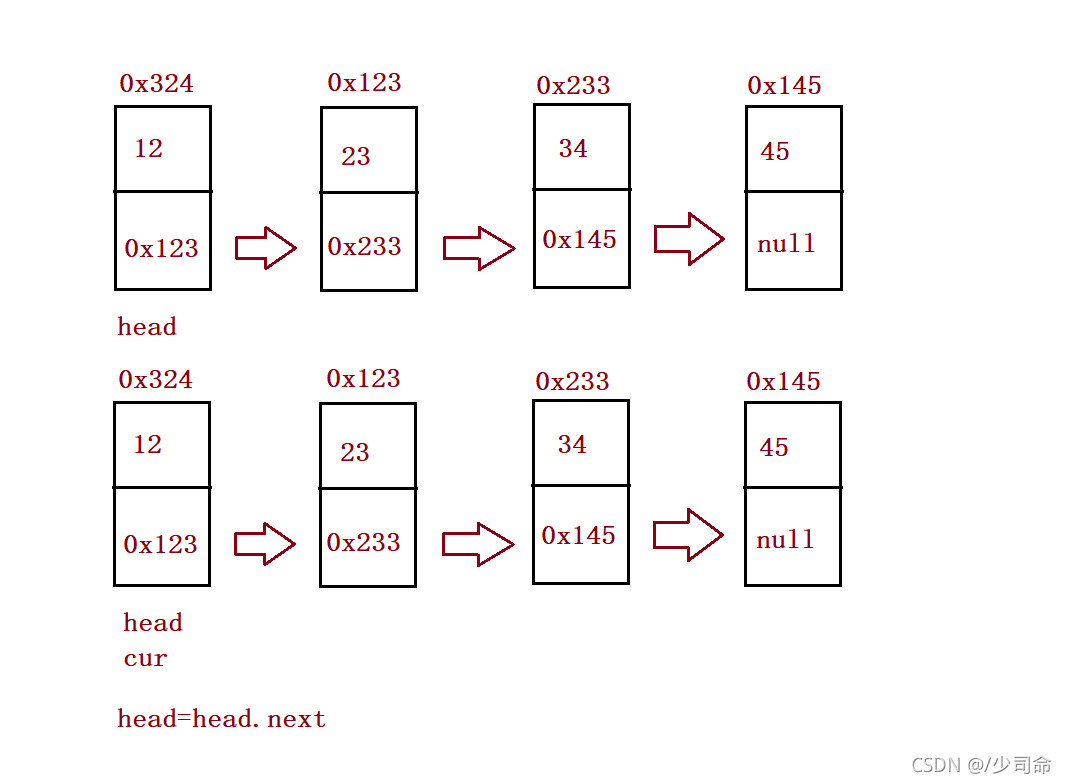
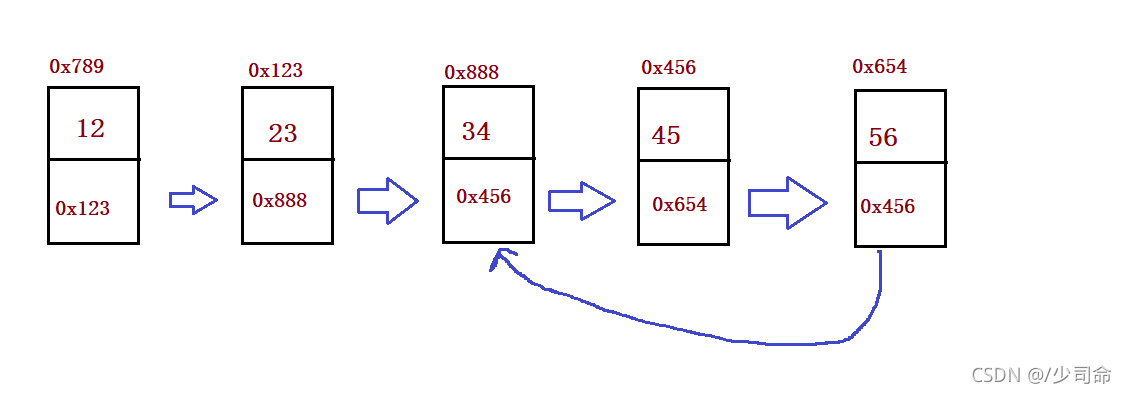
public void createList() {
ListNode listNode1 = new ListNode(12);
ListNode listNode2 = new ListNode(23);
ListNode listNode3 = new ListNode(34);
ListNode listNode4 = new ListNode(45);
ListNode listNode5 = new ListNode(56);
listNode1.next = listNode2;
listNode2.next = listNode3;
listNode3.next = listNode4;
listNode4.next = listNode5;
//listNode5.next = null;
this.head = listNode1;
}public void display() {
//this.head.next != null
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.display();
}
⑤查找是否包含關鍵字key是否在單鏈表當中、得到單鏈表的長度
public boolean contains(int key){
ListNode cur = this.head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.display();
boolean flg = myLinkedList.contains(56);
}public int size(){
int count = 0;
ListNode cur = this.head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
System.out.println(myLinkedList.size());
}
⑥頭插法、尾插法
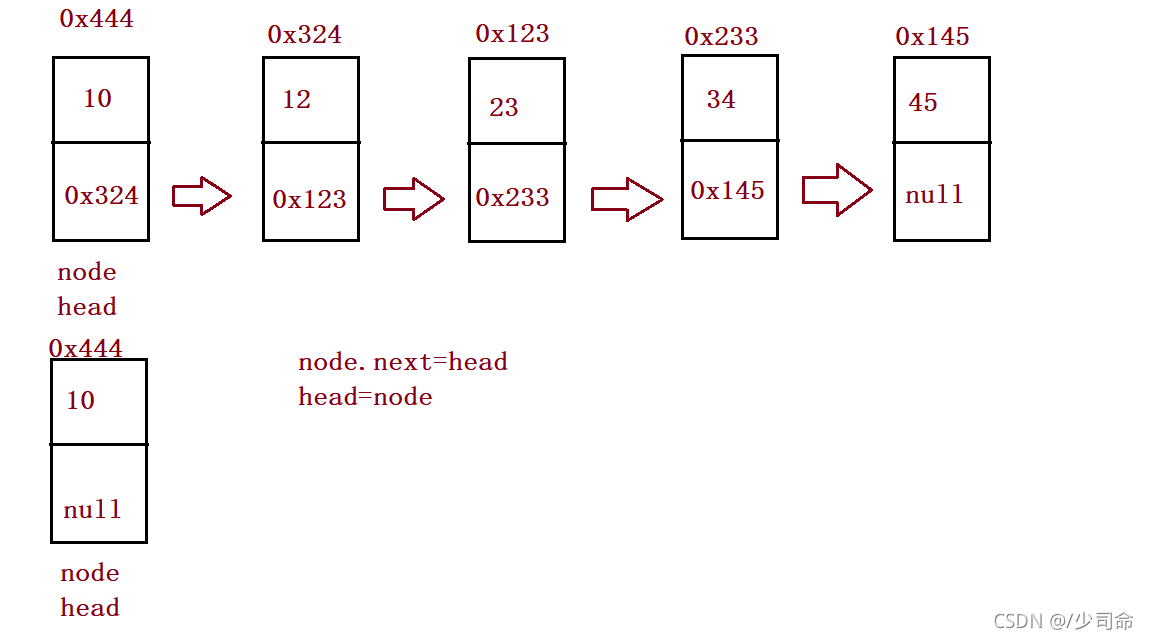
//頭插法
public void addFirst(int data){
ListNode node = new ListNode(data);
node.next = this.head;
this.head = node;
/*if(this.head == null) {
this.head = node;
}else {
node.next = this.head;
this.head = node;
}*/
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.addFirst(10);
myLinkedList.display();
}
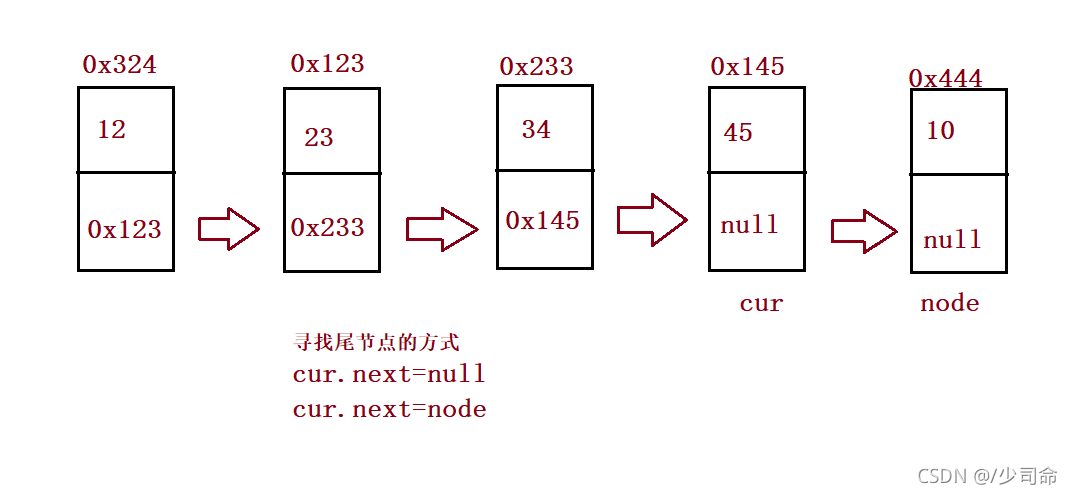
//尾插法
public void addLast(int data){
ListNode node = new ListNode(data);
if(this.head == null) {
this.head = node;
}else {
ListNode cur = this.head;
while (cur.next != null) {
cur = cur.next;
}
//cur.next == null;
cur.next = node;
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.addLast(90);
myLinkedList.display();
}
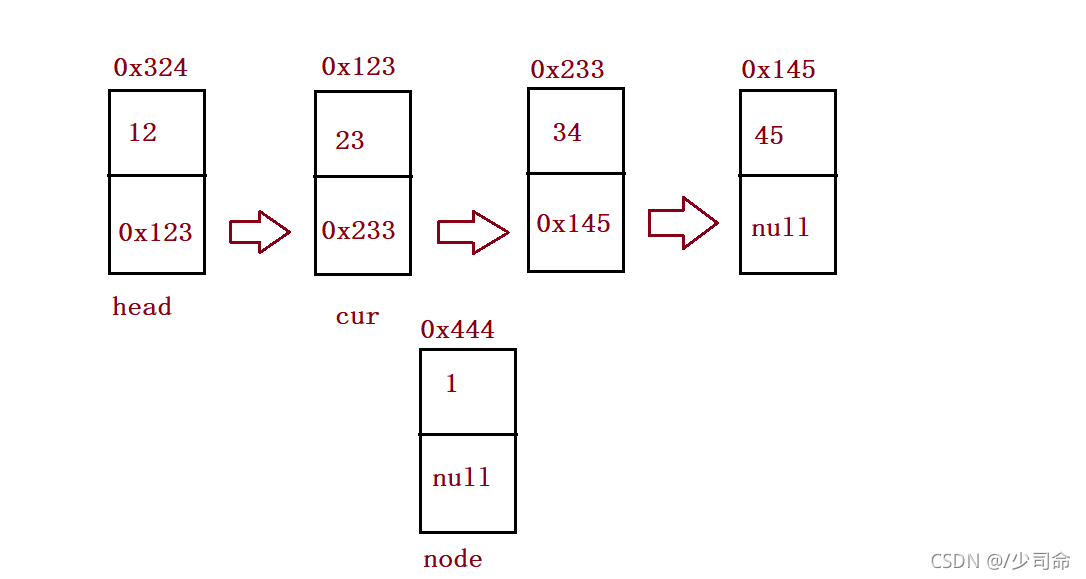
⑦找到index-1位置的節點的地址、插入元素
public ListNode findIndex(int index) {
ListNode cur = this.head;
while (index-1 != 0) {
cur = cur.next;
index--;
}
return cur;
}
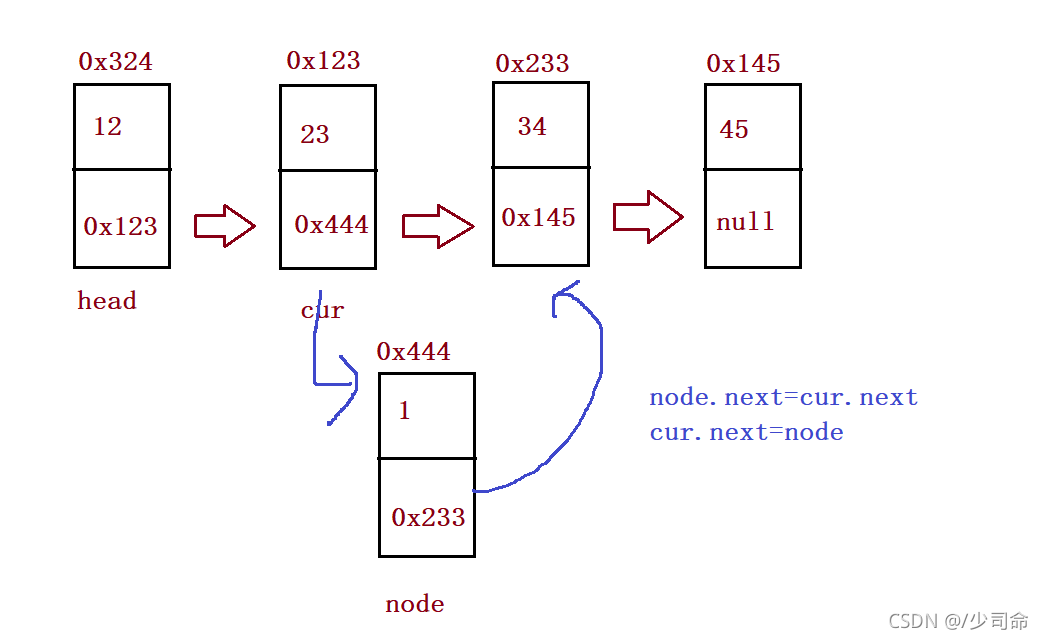
//任意位置插入,第一個資料節點為0號下標
public void addIndex(int index,int data){
if(index < 0 || index > size()) {
System.out.println("index位置不合法!");
return;
}
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = findIndex(index);
ListNode node = new ListNode(data);
node.next = cur.next;
cur.next = node;
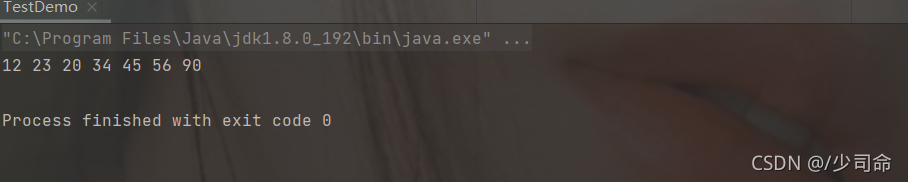
}public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.addLast(90);
myLinkedList.addIndex(2,20);
myLinkedList.display();
}
⑧找到要洗掉的關鍵字的前驅、洗掉第一次出現關鍵字為key的節點
public ListNode searchPerv(int key) {
ListNode cur = this.head;
while (cur.next != null) {
if(cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}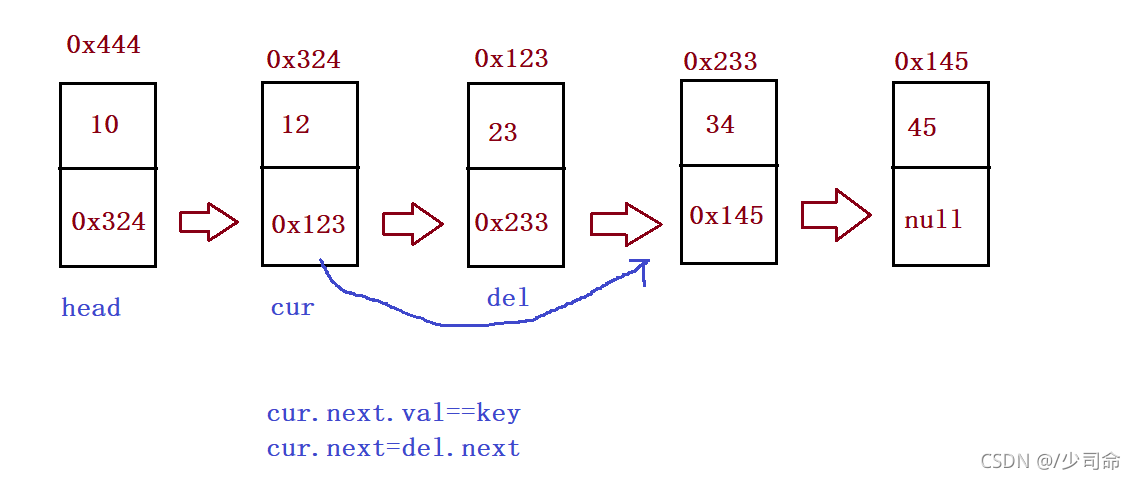
//洗掉第一次出現關鍵字為key的節點
public void remove(int key){
if(this.head == null) {
System.out.println("單鏈表為空,不能洗掉!");
return;
}
if(this.head.val == key) {
this.head = this.head.next;
return;
}
ListNode cur = searchPerv(key);
if(cur == null) {
System.out.println("沒有你要洗掉的節點!");
return;
}
ListNode del = cur.next;
cur.next = del.next;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.addLast(90);
myLinkedList.remove(23);
myLinkedList.display();
}
⑨ 洗掉所有值為key的節點
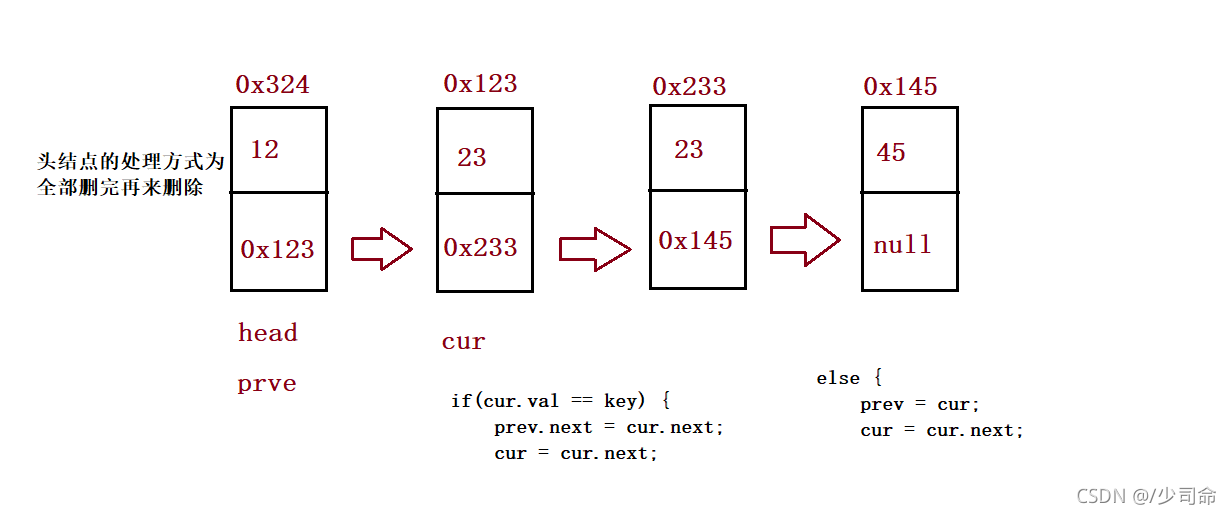
//洗掉所有值為key的節點
public ListNode removeAllKey(int key){
if(this.head == null) return null;
ListNode prev = this.head;
ListNode cur = this.head.next;
while (cur != null) {
if(cur.val == key) {
prev.next = cur.next;
cur = cur.next;
}else {
prev = cur;
cur = cur.next;
}
}
//最后處理頭
if(this.head.val == key) {
this.head = this.head.next;
}
return this.head;
}public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
//myLinkedList.createList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(23);
myLinkedList.addLast(23);
myLinkedList.addLast(56);
myLinkedList.addLast(90);
myLinkedList.removeAllKey(23);
myLinkedList.display();
}
⑩清空鏈表
public void clear(){
//this.head == null
while (this.head != null) {
ListNode curNext = head.next;
this.head.next = null;
this.head = curNext;
}
}4,雙向鏈表
①鏈表的實作
public class DoubleLinkedList {
//頭插法
public void addFirst(int data){
}
//尾插法
public void addLast(int data){
}
//任意位置插入,第一個資料節點為0號下標
public boolean addIndex(int index,int data){
}
//查找是否包含關鍵字key是否在單鏈表當中
public boolean contains(int key){
}
//洗掉第一次出現關鍵字為key的節點
public void remove(int key){
}
//洗掉所有值為key的節點
public void removeAllKey(int key){
}
//得到單鏈表的長度
public int size(){
}
public void display(){
}
public void clear(){
}
}②構造節點和鏈表
public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
} public ListNode head;//指向雙向鏈表的頭節點
//public ListNode head = new ListNode(-1);//指向雙向鏈表的頭節點
public ListNode last;//指向的是尾巴節點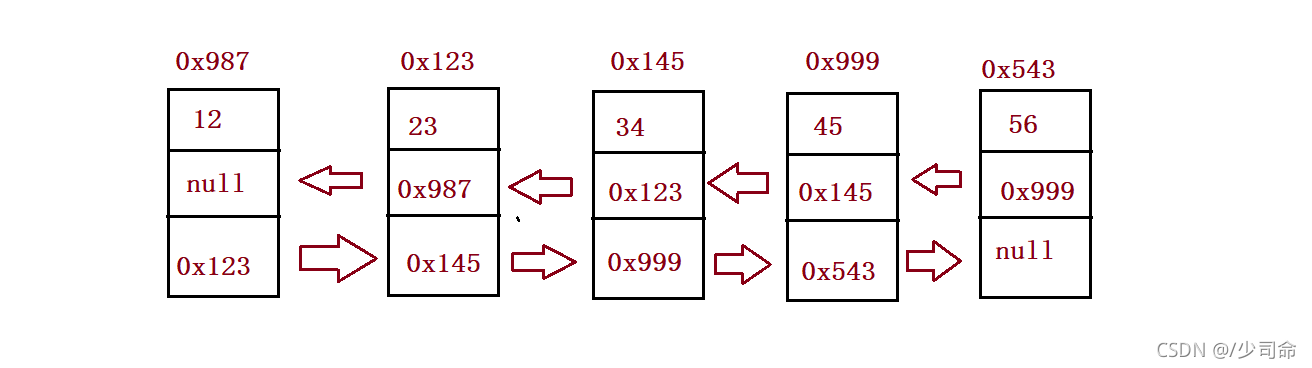
③列印鏈表、求鏈表長度
public void display() {
//和單鏈表的列印方式是一樣的
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();
}/得到單鏈表的長度
public int size() {
int count = 0;
ListNode cur = this.head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}④查詢key
public boolean contains(int key){
ListNode cur = this.head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}⑤頭插法
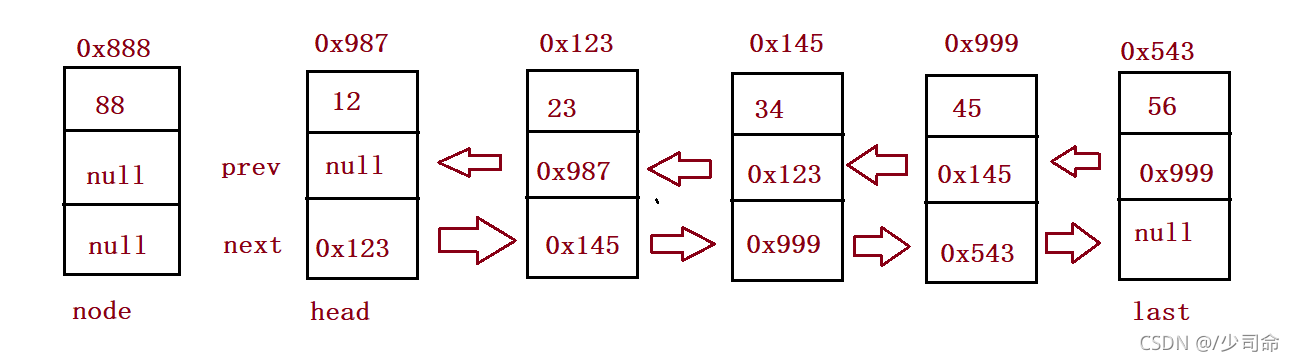
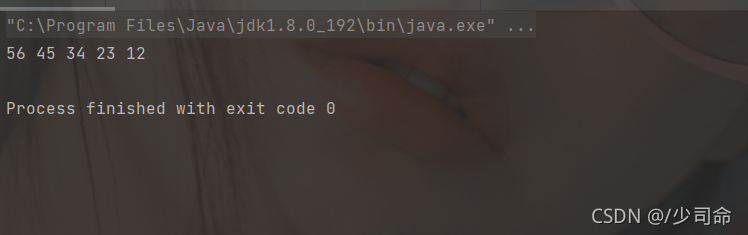
//頭插法
public void addFirst(int data) {
ListNode node = new ListNode(data);
if(this.head == null) {
this.head = node;
this.last = node;
}else {
node.next = this.head;
this.head.prev = node;
this.head = node;
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addFirst(12);
myLinkedList.addFirst(23);
myLinkedList.addFirst(34);
myLinkedList.addFirst(45);
myLinkedList.addFirst(56);
myLinkedList.display();
}
⑥尾插法
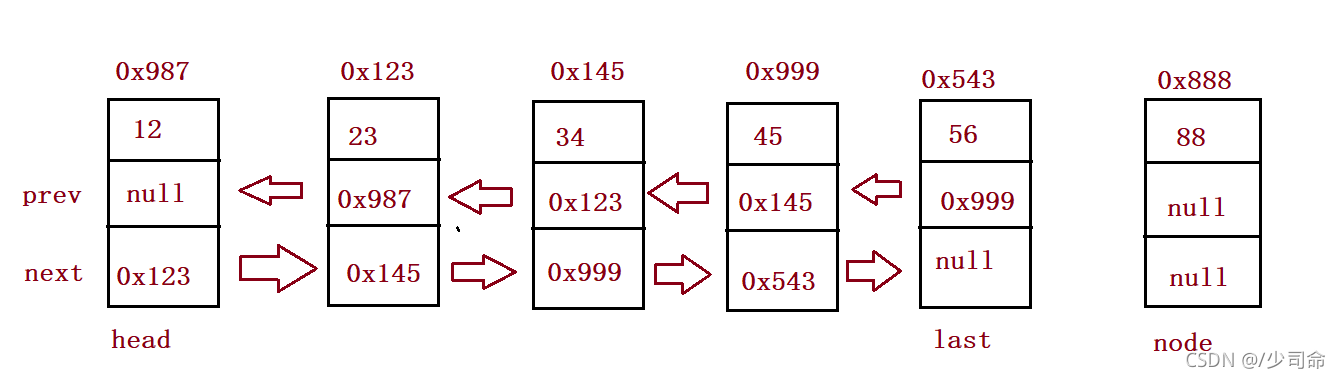
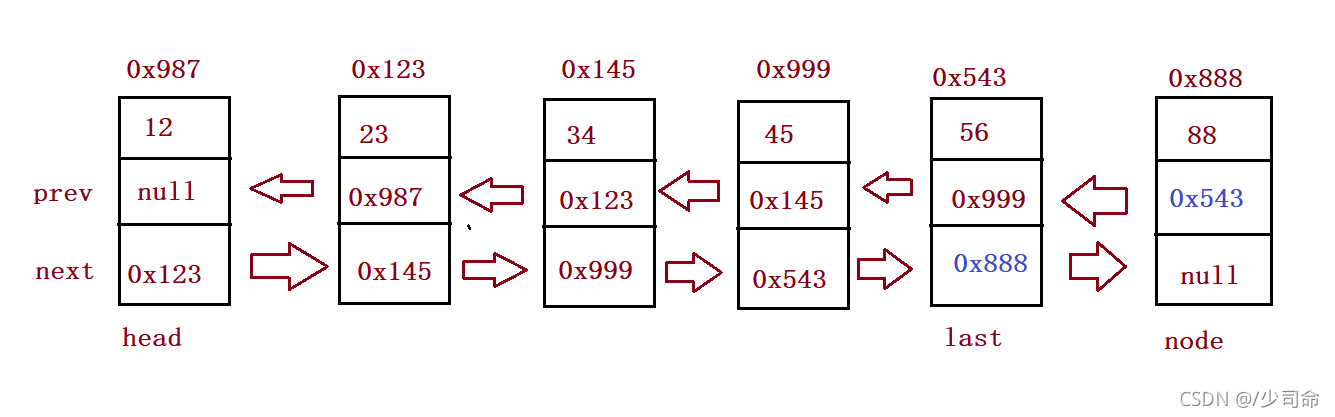
//尾插法
public void addLast(int data){
ListNode node = new ListNode(data);
if(this.head == null) {
this.head = node;
this.last = node;
}else {
this.last.next = node;
node.prev = this.last;
this.last = node;
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.display();
}
⑦尋找插入節點
public ListNode searchIndex (int index) {
ListNode cur = this.head;
while (index != 0) {
cur = cur.next;
index--;
}
return cur;
}⑧插入元素
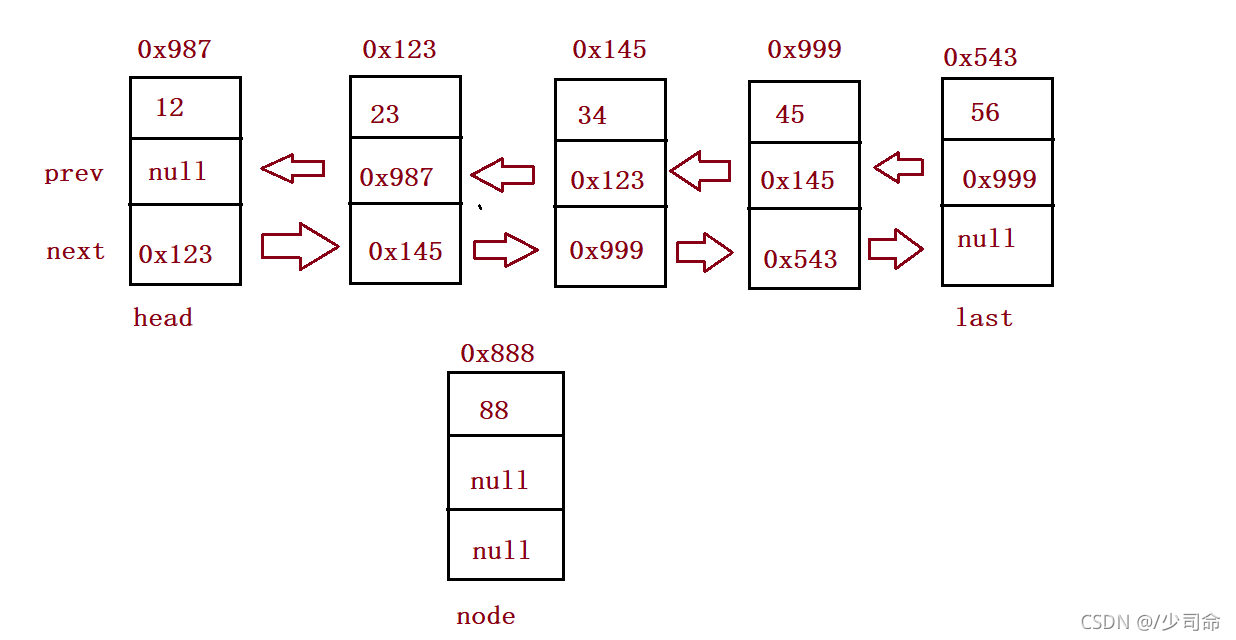
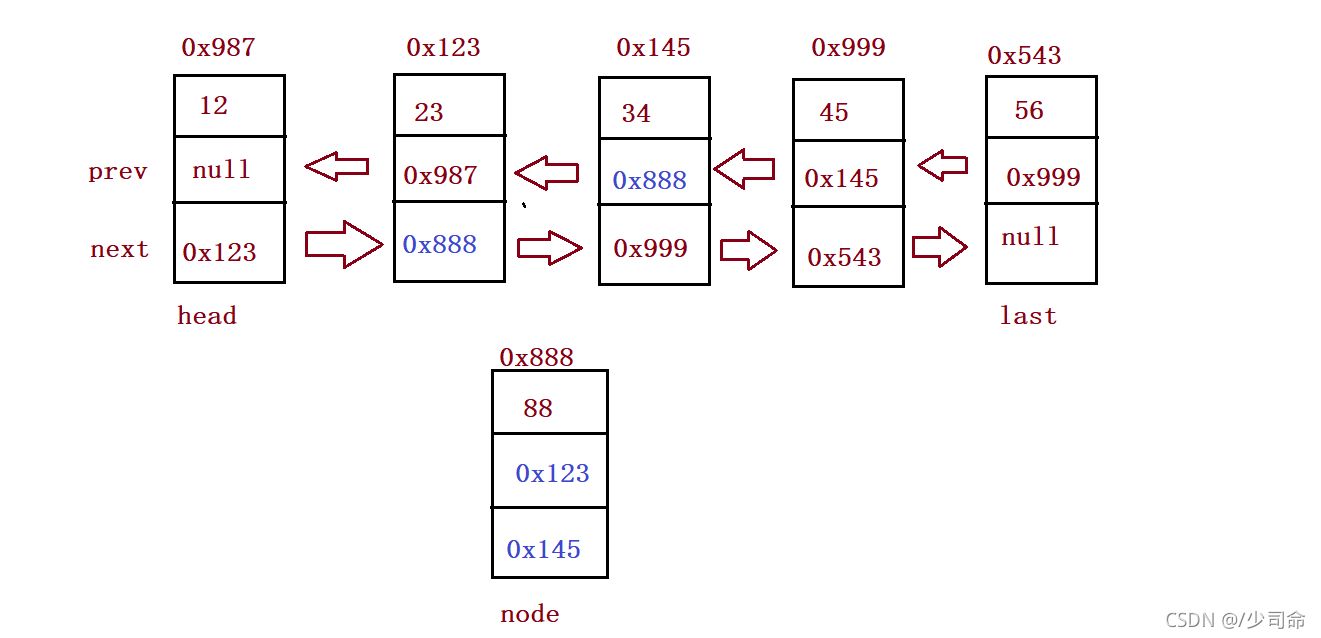
//任意位置插入,第一個資料節點為0號下標
public void addIndex(int index,int data){
ListNode node = new ListNode(data);
if(index < 0 || index > size()) {
System.out.println("index位置不合法!");
return;
}
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = searchIndex(index);
node.next = cur.prev.next;
cur.prev.next = node;
node.prev = cur.prev;
cur.prev = node;
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.display();
myLinkedList.addIndex(3,99);
myLinkedList.display();
}
⑨洗掉元素
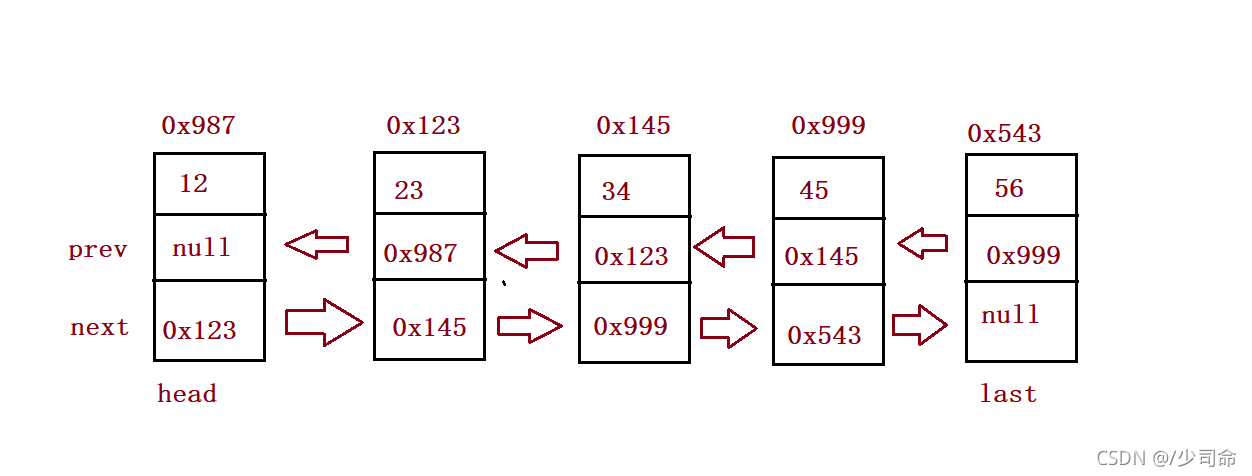
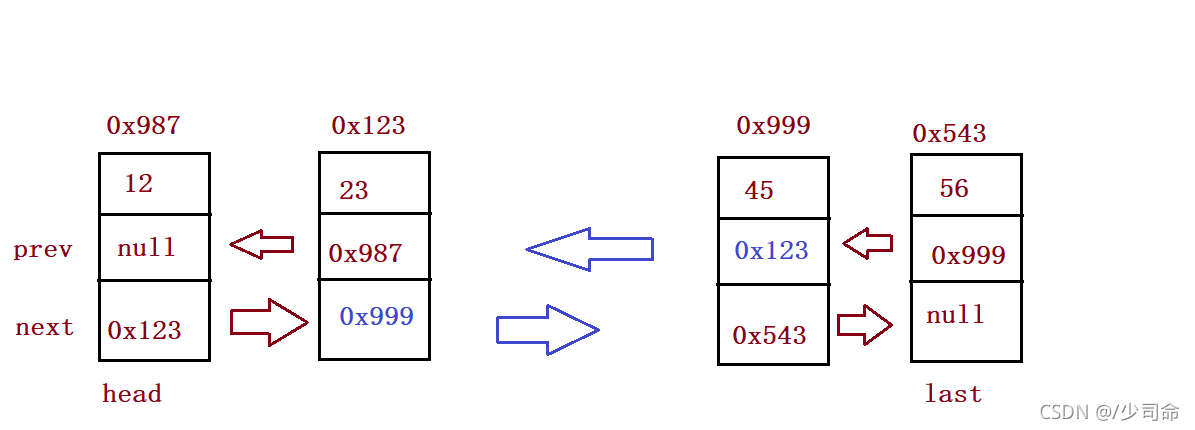
//洗掉第一次出現關鍵字為key的節點
public void remove(int key){
ListNode cur = this.head;
while (cur != null) {
if(cur.val == key) {
if(cur == head) {
head = head.next;
if(head != null) {
head.prev = null;
}else {
last = null;
}
}else {
cur.prev.next = cur.next;
if(cur.next != null) {
//中間位置
cur.next.prev = cur.prev;
}else {
last = last.prev;
}
}
return;
}
cur = cur.next;
}
} public static void main(String[] args) {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addLast(12);
myLinkedList.addLast(23);
myLinkedList.addLast(34);
myLinkedList.addLast(45);
myLinkedList.addLast(56);
myLinkedList.display();
myLinkedList.remove(23);
myLinkedList.display();
}
⑩清空鏈表
public void clear() {
while (head != null) {
ListNode curNext = head.next;
head.next = null;
head.prev = null;
head = curNext;
}
last = null;
}5,筆試習題
①反轉一個單鏈表
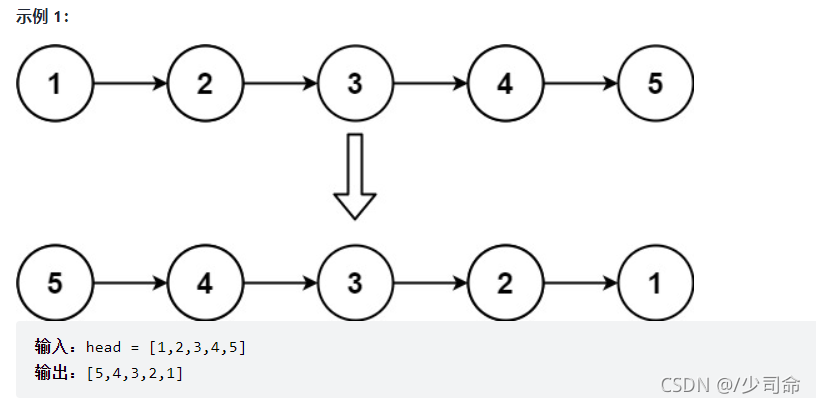
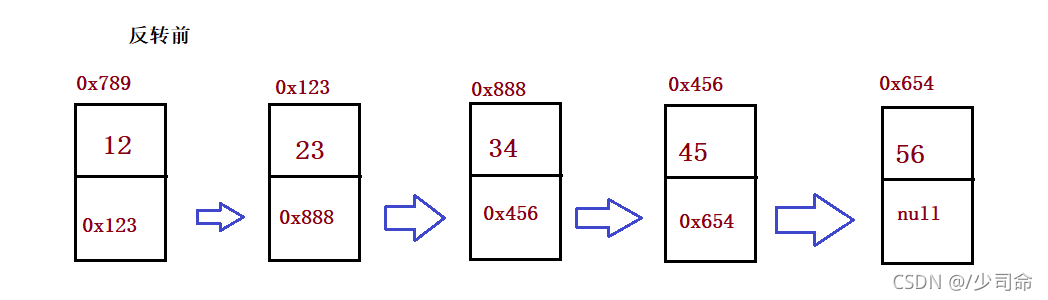
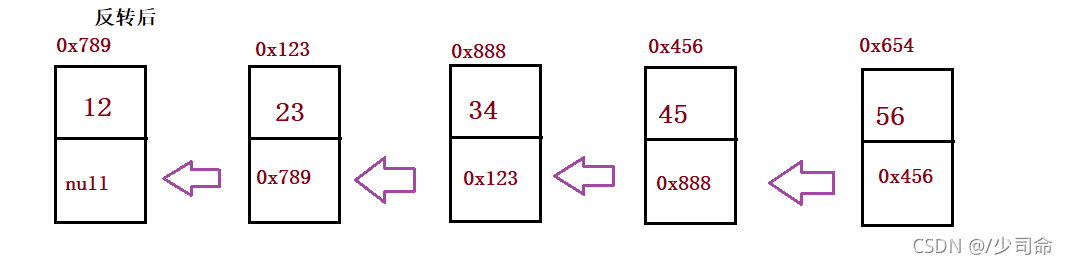
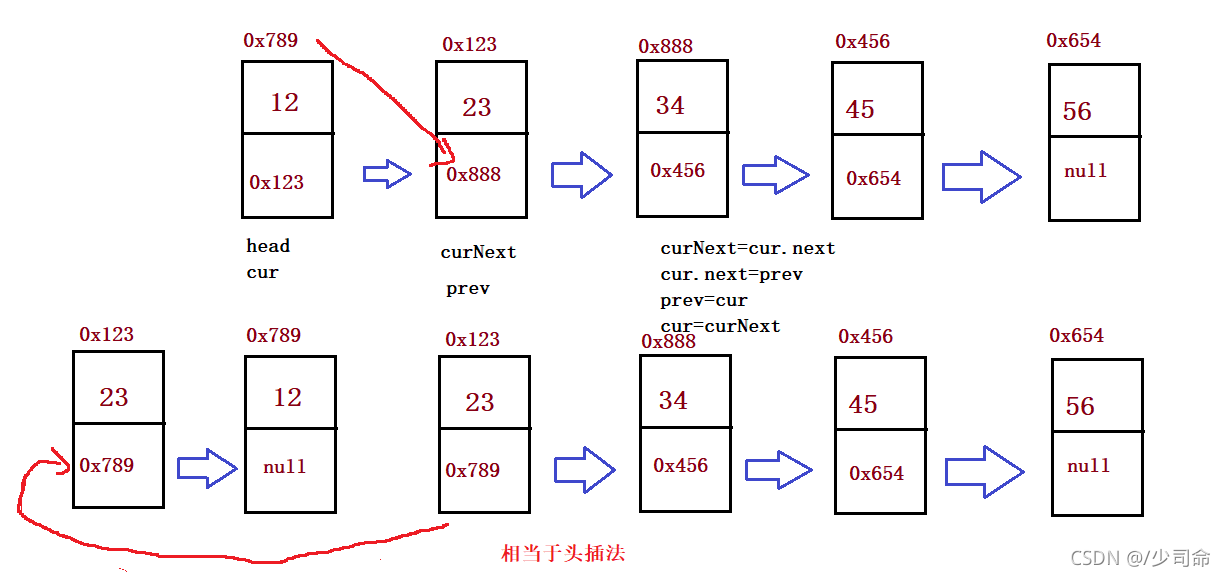
public ListNode reverseList() {
if(this.head == null) {
return null;
}
ListNode cur = this.head;
ListNode prev = null;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = prev;
prev = cur;
cur = curNext;
}
return prev;
}②給定一個帶有頭結點 head 的非空單鏈表,回傳鏈表的中間結點

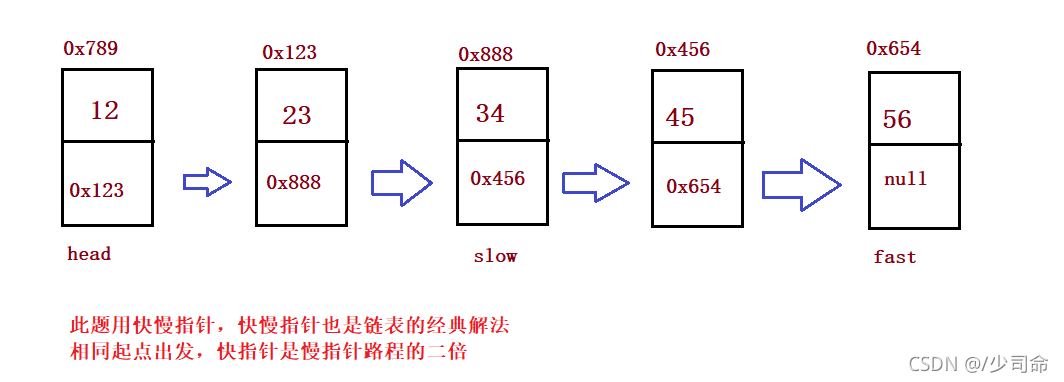
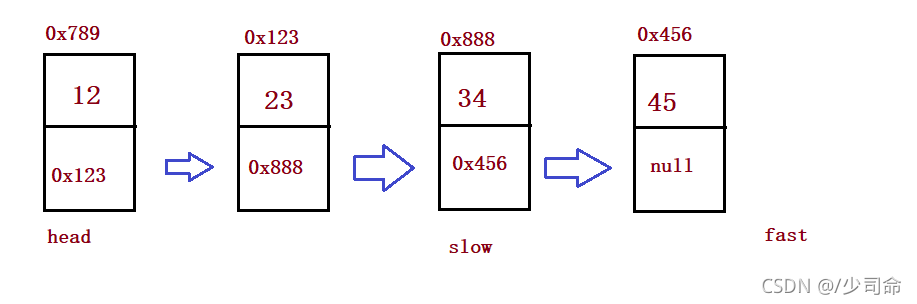
public ListNode middleNode() {
if(head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null){
fast = fast.next.next;
if(fast == null) {
return slow;
}
slow = slow.next;
}
return slow;
}③輸入一個鏈表,輸出該鏈表中倒數第k個結點
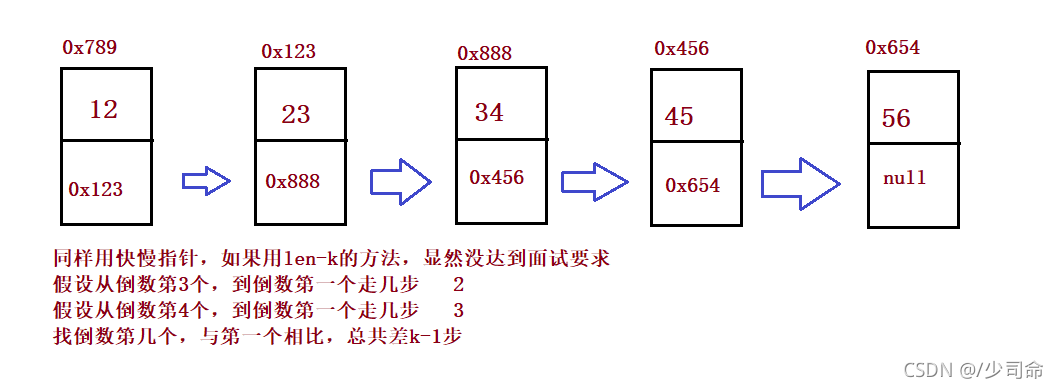
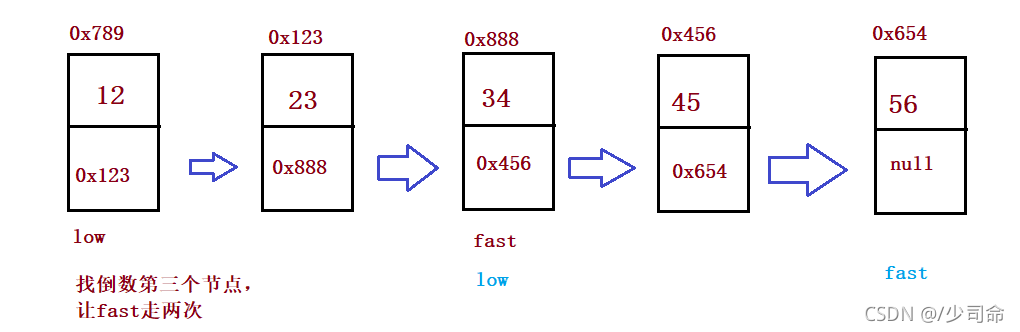
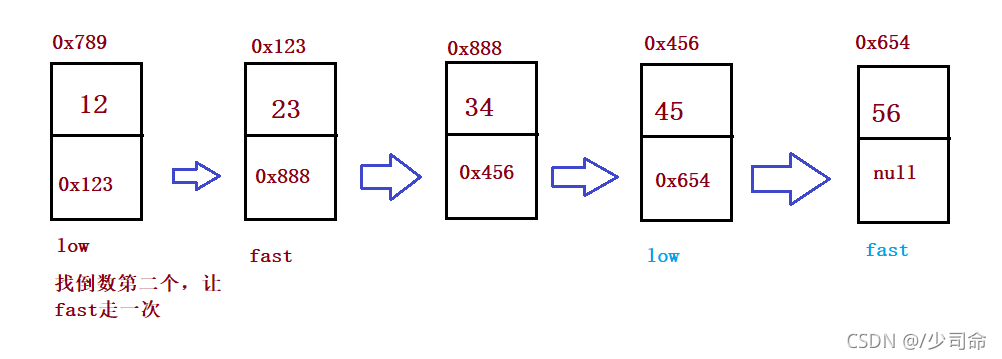
public ListNode findKthToTail(int k) {
if(k <= 0 || head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (k-1 != 0) {
fast = fast.next;
if(fast == null) {
return null;
}
k--;
}
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
return slow;
}④洗掉鏈表中的多個重復值
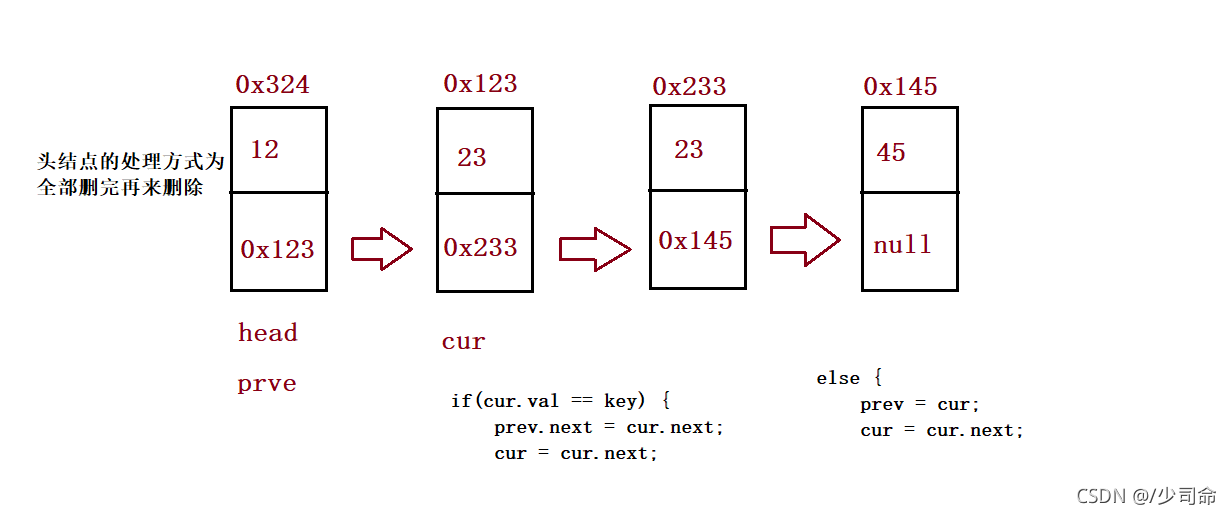
//洗掉所有值為key的節點
public ListNode removeAllKey(int key){
if(this.head == null) return null;
ListNode prev = this.head;
ListNode cur = this.head.next;
while (cur != null) {
if(cur.val == key) {
prev.next = cur.next;
cur = cur.next;
}else {
prev = cur;
cur = cur.next;
}
}
//最后處理頭
if(this.head.val == key) {
this.head = this.head.next;
}
return this.head;
}⑤鏈表的回文結構

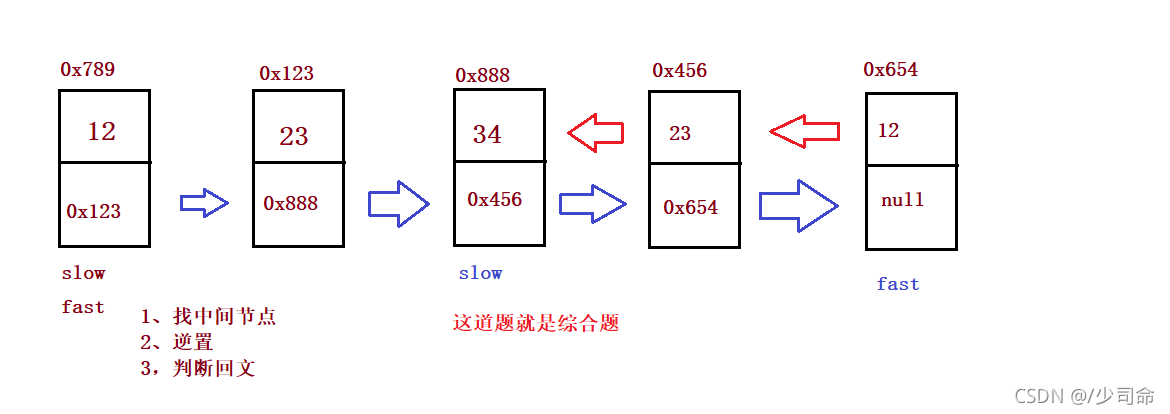
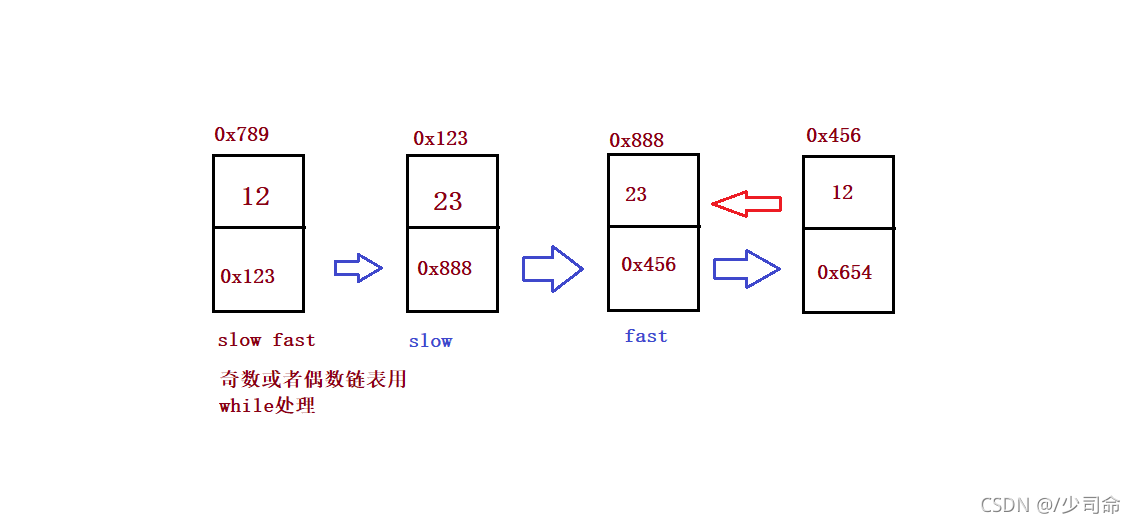
public boolean chkPalindrome(ListNode A) {
// write code here
if(head == null) return true;
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
//slow走到了中間位置-》反轉
ListNode cur = slow.next;
while(cur != null) {
ListNode curNext = cur.next;
cur.next = slow;
slow = cur;
cur = curNext;
}
//反轉完成
while(head != slow) {
if(head.val != slow.val) {
return false;
}
if(head.next == slow) {
return true;
}
head = head.next;
slow = slow.next;
}
return true;
}⑥合并兩個鏈表
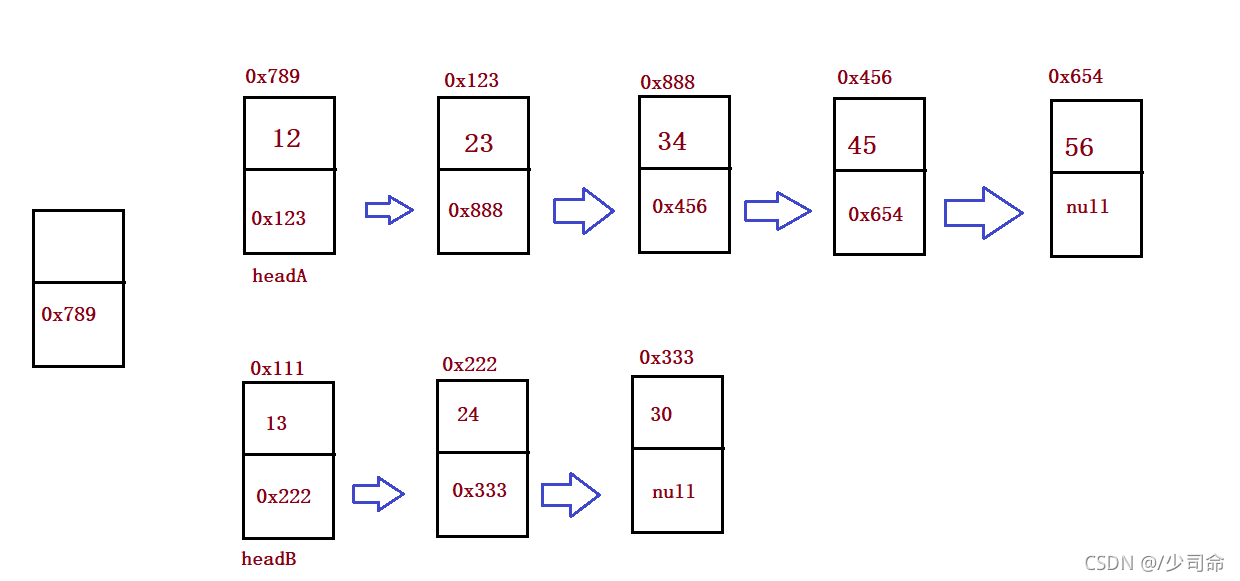
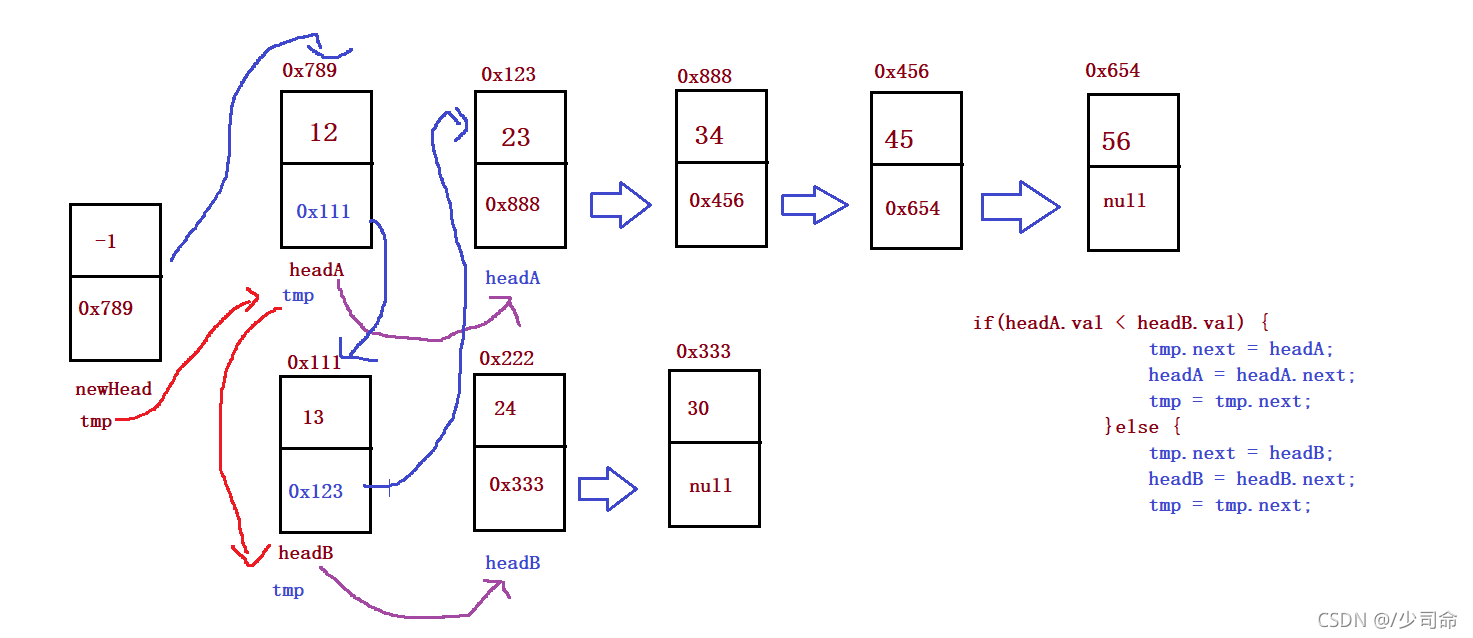
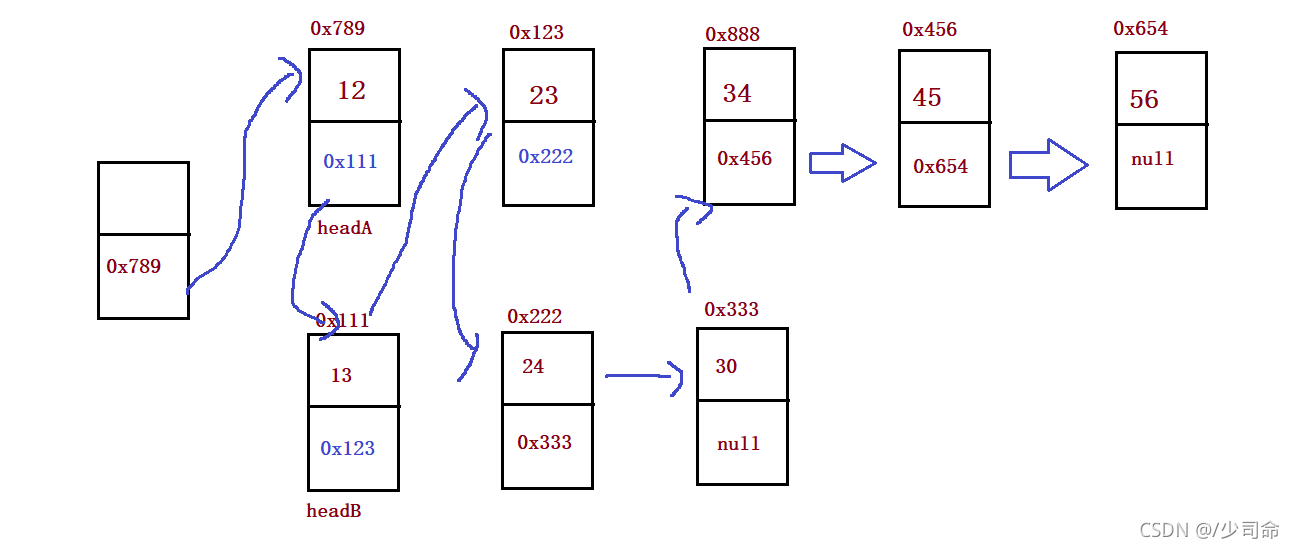
public static ListNode mergeTwoLists(ListNode headA, ListNode headB) {
ListNode newHead = new ListNode(-1);
ListNode tmp = newHead;
while (headA != null && headB != null) {
if(headA.val < headB.val) {
tmp.next = headA;
headA = headA.next;
tmp = tmp.next;
}else {
tmp.next = headB;
headB = headB.next;
tmp = tmp.next;
}
}
if(headA != null) {
tmp.next = headA;
}
if(headB != null) {
tmp.next = headB;
}
return newHead.next;
}⑦輸入兩個鏈表,找出它們的第一個公共結點
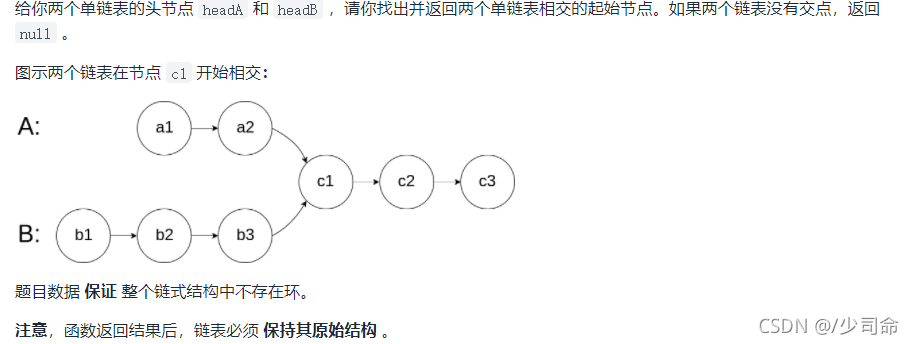
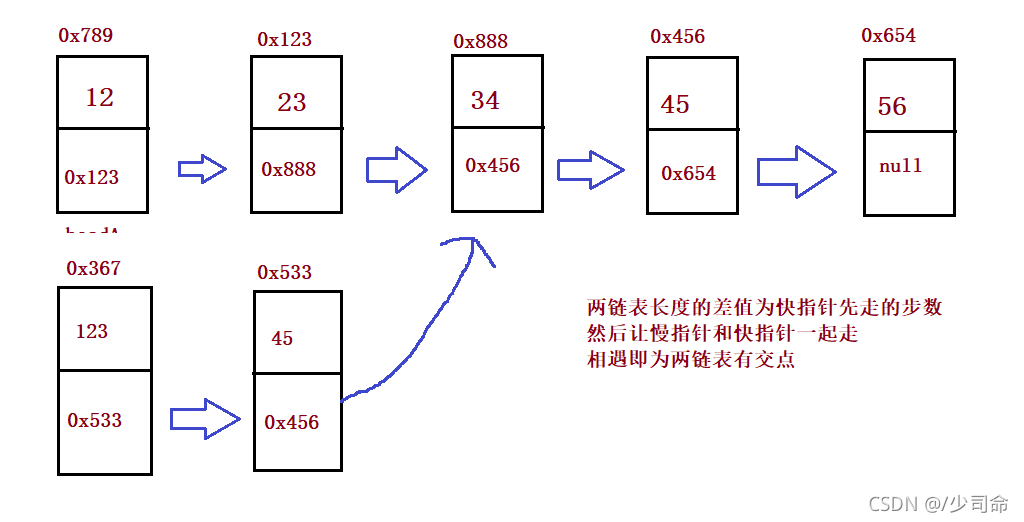
public static ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if(headA == null || headB == null) {
return null;
}
ListNode pl = headA;
ListNode ps = headB;
int lenA = 0;
int lenB = 0;
while (pl != null) {
lenA++;
pl = pl.next;
}
//pl==null
pl = headA;
while (ps != null) {
lenB++;
ps = ps.next;
}
//ps==null
ps = headB;
int len = lenA-lenB;//差值步
if(len < 0) {
pl = headB;
ps = headA;
len = lenB-lenA;
}
//1、pl永遠指向了最長的鏈表 ps 永遠指向了最短的鏈表 2、求到了差值len步
//pl走差值len步
while (len != 0) {
pl = pl.next;
len--;
}
//同時走 直到相遇
while (pl != ps) {
pl = pl.next;
ps = ps.next;
}
return pl;
}⑧判斷一個鏈表是否有環
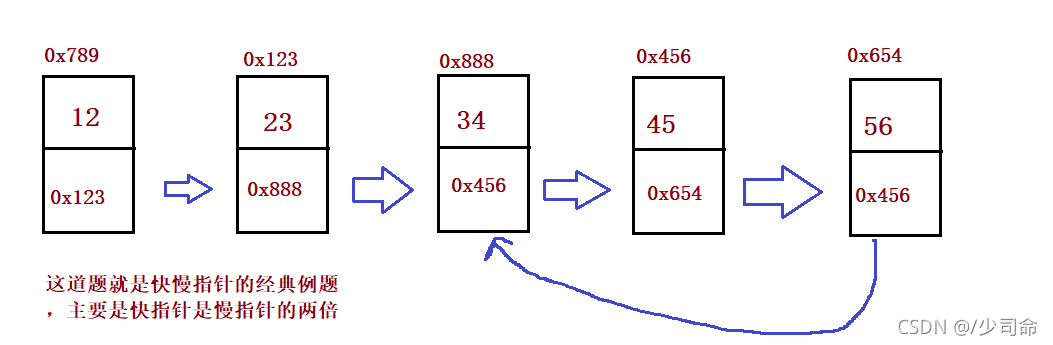
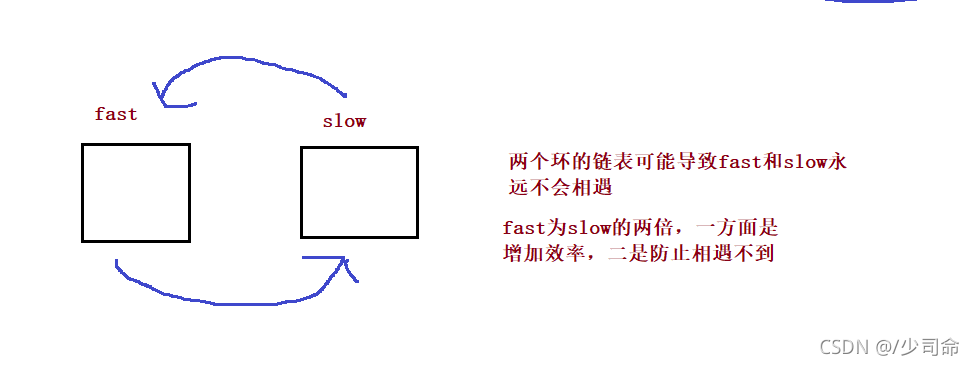
public boolean hasCycle() {
if(head == null) return false;
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if(fast == slow) {
return true;
}
}
return false;
}⑨求有環鏈表的環第一個結點
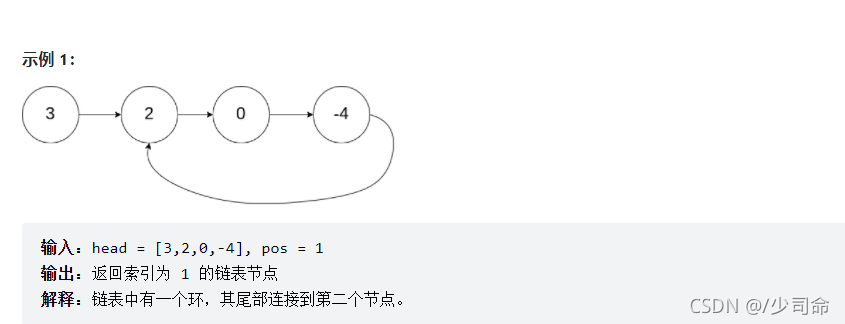
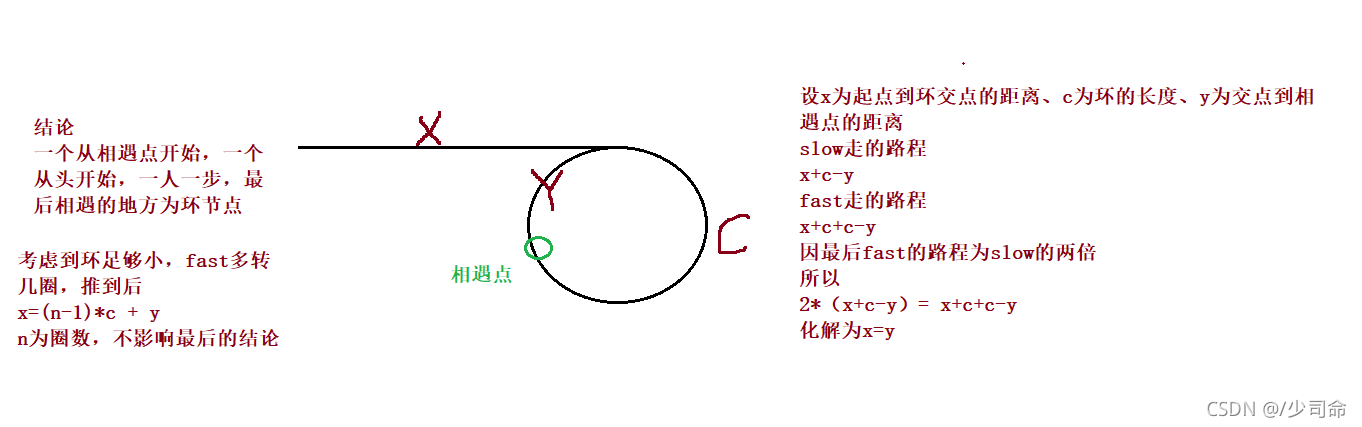
public ListNode detectCycle(ListNode head) {
if(head == null) return null;
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if(fast == slow) {
break;
}
}
if(fast == null || fast.next == null) {
return null;
}
fast = head;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}三,堆疊和佇列
1,堆疊
①概念
在我們軟體應用 ,堆疊這種后進先出資料結構的應用是非常普遍的,比如你用瀏 覽器上網時不管什么瀏覽器都有 個"后退"鍵,你點擊后可以接訪問順序的逆序加載瀏覽過的網頁,
很多類似的軟體,比如 Word Photoshop 等檔案或影像編 軟體中 都有撤銷 )的操作,也是用堆疊這種方式來實作的,當然不同的軟體具體實作會有很大差異,不過原理其實都是一樣的
堆疊( stack )是限定僅在表尾進行插入和洗掉的線性表
堆疊:一種特殊的線性表,其只允許在固定的一端進行插入和洗掉元素操作,進行資料插入和洗掉操作的一端稱為堆疊 頂,另一端稱為堆疊底,堆疊中的資料元素遵守后進先出LIFO(Last In First Out)的原則,

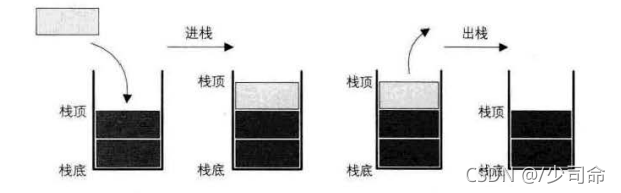
②堆疊的操作
壓堆疊:堆疊的插入操作叫做進堆疊/壓堆疊/入堆疊,入資料在堆疊頂,
出堆疊:堆疊的洗掉操作叫做出堆疊,出資料在堆疊頂,
③堆疊的實作
入堆疊
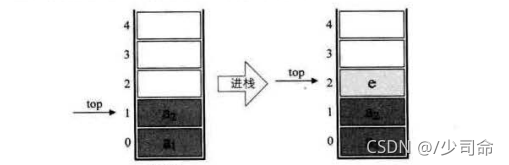
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
stack.push(4);
int ret = stack.push(4);
System.out.println(ret);
}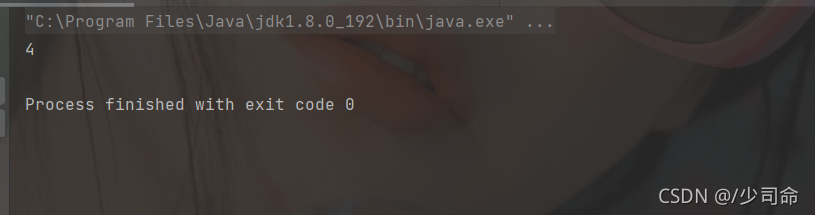
出堆疊
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
int ret1 = stack.pop();
int ret2 = stack.pop();
System.out.println(ret1);
System.out.println(ret2);
}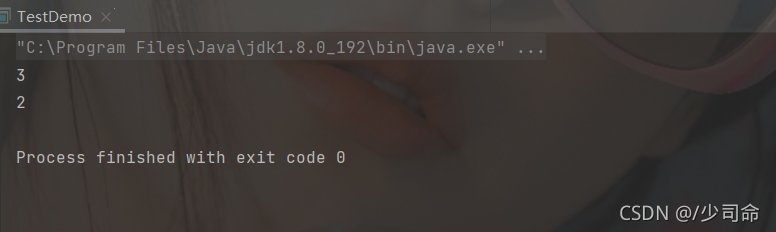
獲取堆疊頂元素
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
int ret1 = stack.pop();
int ret2 = stack.pop();
int ret3 = stack.peek();
System.out.println(ret1);
System.out.println(ret2);
System.out.println(ret3);
}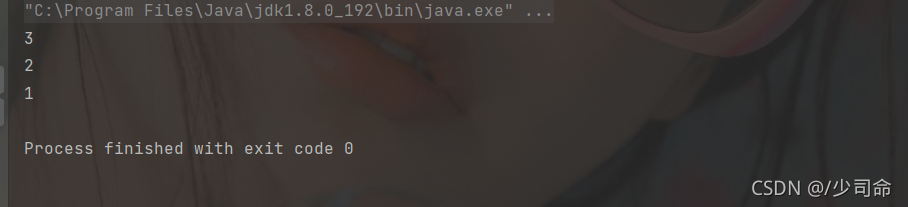
判斷堆疊是否為空
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
int ret1 = stack.pop();
int ret2 = stack.pop();
int ret3 = stack.peek();
System.out.println(ret1);
System.out.println(ret2);
System.out.println(ret3);
stack.pop();
boolean flag = stack.empty();
System.out.println(flag);
}
④實作mystack
public class MyStack<T> {
private T[] elem;//陣列
private int top;//當前可以存放資料元素的下標-》堆疊頂指標
public MyStack() {
this.elem = (T[])new Object[10];
}
/**
* 入堆疊操作
* @param item 入堆疊的元素
*/
public void push(T item) {
//1、判斷當前堆疊是否是滿的
if(isFull()){
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
//2、elem[top] = item top++;
this.elem[this.top++] = item;
}
public boolean isFull(){
return this.elem.length == this.top;
}
/**
* 出堆疊
* @return 出堆疊的元素
*/
public T pop() {
if(empty()) {
throw new UnsupportedOperationException("堆疊為空!");
}
T ret = this.elem[this.top-1];
this.top--;//真正的改變了top的值
return ret;
}
/**
* 得到堆疊頂元素,但是不洗掉
* @return
*/
public T peek() {
if(empty()) {
throw new UnsupportedOperationException("堆疊為空!");
}
//this.top--;//真正的改變了top的值
return this.elem[this.top-1];
}
public boolean empty(){
return this.top == 0;
}
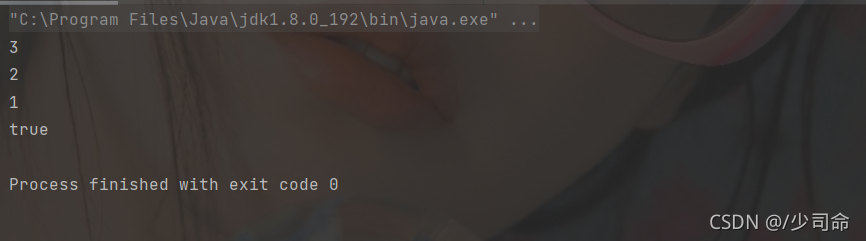
}public static void main(String[] args) {
MyStack<Integer> myStack = new MyStack<>();
myStack.push(1);
myStack.push(2);
myStack.push(3);
System.out.println(myStack.peek());
System.out.println(myStack.pop());
System.out.println(myStack.pop());
System.out.println(myStack.pop());
System.out.println(myStack.empty());
System.out.println("============================");
MyStack<String> myStack2 = new MyStack<>();
myStack2.push("hello");
myStack2.push("word");
myStack2.push("thank");
System.out.println(myStack2.peek());
System.out.println(myStack2.pop());
System.out.println(myStack2.pop());
System.out.println(myStack2.pop());
System.out.println(myStack2.empty());
}
2,佇列
①概念
像移動、聯通、電信等客服電話,客服人員與客戶相比總是少數,在所有的客服人員都占線的情況下,客戶會被要求等待,直到有某個客服人員空下來,才能讓最先等待的客戶接通電話,這里也是將所有當前撥打客服電話的客戶進行了排隊處理,
作業系統和客服系統中,都是應用了種資料結構來實作剛才提到的先進先出的排隊功能,這就是佇列,
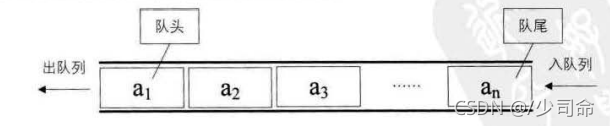
佇列(queue) 是只允許在一端進行插入操作,而在另一端進行洗掉操作的線性表

佇列:只允許在一端進行插入資料操作,在另一端進行洗掉資料操作的特殊線性表,佇列具有先進先出FIFO(First In First Out) 入佇列:進行插入操作的一端稱為隊尾(Tail/Rear) 出佇列:進行洗掉操作的一端稱為隊頭 (Head/Front)
②佇列的實作
入隊
public static void main(String[] args) {
Deque<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
queue.offer(4);
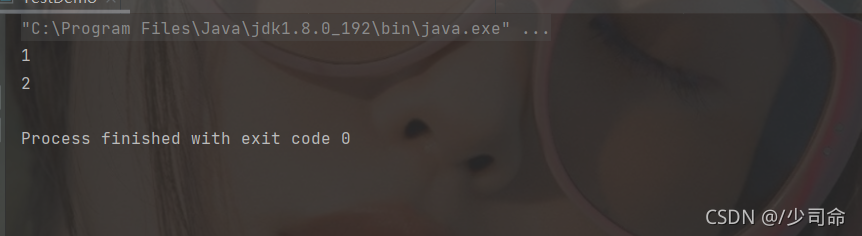
}出隊
public static void main(String[] args) {
Deque<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
queue.offer(4);
System.out.println(queue.poll());
System.out.println(queue.poll());
}
獲取隊首元素
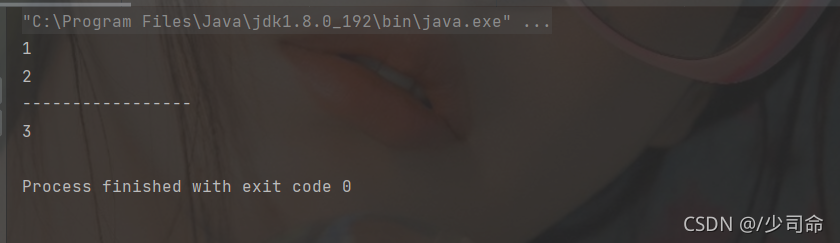
public static void main(String[] args) {
Deque<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
queue.offer(3);
queue.offer(4);
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println("-----------------");
System.out.println(queue.peek());
}
③實作myqueue
class Node {
private int val;
private Node next;
public int getVal() {
return val;
}
public void setVal(int val) {
this.val = val;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public Node(int val) {
this.val = val;
}
}
public class MyQueue {
private Node first;
private Node last;
//入隊
public void offer(int val) {
//尾插法 需要判斷是不是第一次插入
Node node = new Node(val);
if(this.first == null) {
this.first = node;
this.last = node;
}else {
this.last.setNext(node);//last.next = node;
this.last = node;
}
}
//出隊
public int poll() {
//1判斷是否為空的
if(isEmpty()) {
throw new UnsupportedOperationException("佇列為空!");
}
//this.first = this.first.next;
int ret = this.first.getVal();
this.first = this.first.getNext();
return ret;
}
//得到隊頭元素但是不洗掉
public int peek() {
//不要移動first
if(isEmpty()) {
throw new UnsupportedOperationException("佇列為空!");
}
return this.first.getVal();
}
//佇列是否為空
public boolean isEmpty() {
return this.first == null;
}
} public static void main(String[] args) {
MyQueue myQueue = new MyQueue();
myQueue.offer(1);
myQueue.offer(2);
myQueue.offer(3);
System.out.println(myQueue.peek());
System.out.println(myQueue.poll());
System.out.println(myQueue.poll());
System.out.println(myQueue.poll());
System.out.println(myQueue.isEmpty());
}
四,二叉樹
1,樹
①概念

樹是一種非線性的資料結構,它是由n(n>=0)個有限結點組成一個具有層次關系的集合,把它叫做樹是因為它看 起來像一棵倒掛的樹,也就是說它是根朝上,而葉朝下的,它具有以下的特點:
有一個特殊的節點,稱為根節點,根節點沒有前驅節點
除根節點外,其余節點被分成M(M > 0)個互不相交的集合T1、T2、......、Tm,其中每一個集合 Ti (1 <= i <= m) 又是一棵與樹類似的子樹,每棵子樹的根節點有且只有一個前驅,可以有0個或多個后繼
樹是遞回定義的,
②樹的基礎概念
節點的度:一個節點含有的子樹的個數稱為該節點的度
樹的度:一棵樹中,最大的節點的度稱為樹的度
葉子節點或終端節點:度為0的節點稱為葉節點
雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點
孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點
根結點:一棵樹中,沒有雙親結點的結點
節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推
樹的高度或深度:樹中節點的最大層次
2,二叉樹
①概念
一棵二叉樹是結點的一個有限集合,該集合或者為空,或者是由一個根節點加上兩棵別稱為左子樹和右子樹的二叉樹組成,
二叉樹的特點:
1. 每個結點最多有兩棵子樹,即二叉樹不存在度大于 2 的結點,
2. 二叉樹的子樹有左右之分,其子樹的次序不能顛倒,因此二叉樹是有序樹,
②兩種特殊的二叉樹
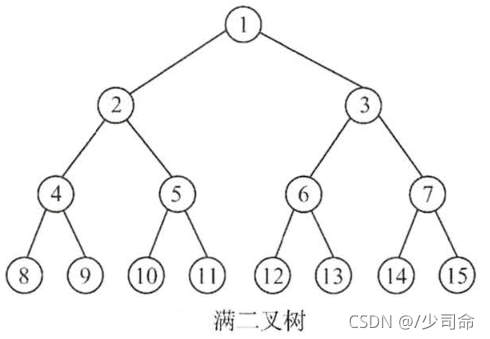
1. 滿二叉樹: 一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹,也就是說,如果 一個二叉樹的層數為K,且結點總數是 ,則它就是滿二叉樹,
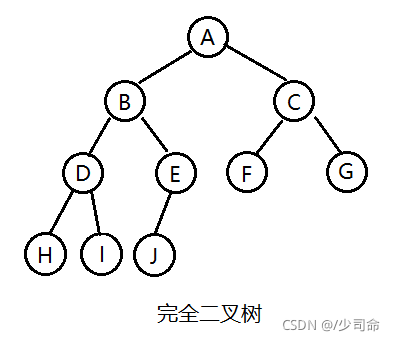
2. 完全二叉樹: 完全二叉樹是效率很高的資料結構,完全二叉樹是由滿二叉樹而引出來的,對于深度為K的,有n 個結點的二叉樹,當且僅當其每一個結點都與深度為K的滿二叉樹中編號從1至n的結點一一對應時稱之為完全 二叉樹, 要注意的是滿二叉樹是一種特殊的完全二叉樹,
③二叉樹的性質
1. 若規定根節點的層數為1,則一棵非空二叉樹的第i層上最多有2^(i-1) (i>0)個結點
2. 若規定只有根節點的二叉樹的深度為1,則深度為K的二叉樹的最大結點數是2^k-1 (k>=0)
3. 對任何一棵二叉樹, 如果其葉結點個數為 n0, 度為2的非葉結點個數為 n2,則有n0=n2+1
4. 具有n個結點的完全二叉樹的深度k為log2(n+1)上取整
3,二叉樹遍歷
①二叉樹的遍歷
所謂遍歷(Traversal)是指沿著某條搜索路線,依次對樹中每個結點均做一次且僅做一次訪問,訪問結點所做的操作 依賴于具體的應用問題(比如:列印節點內容、節點內容加1), 遍歷是二叉樹上最重要的操作之一,是二叉樹上進 行其它運算之基礎,
在遍歷二叉樹時,如果沒有進行某種約定,每個人都按照自己的方式遍歷,得出的結果就比較混亂,如果按照某種 規則進行約定,則每個人對于同一棵樹的遍歷結果肯定是相同的,如果N代表根節點,L代表根節點的左子樹,R代 表根節點的右子樹,則根據遍歷根節點的先后次序有以下遍歷方式:
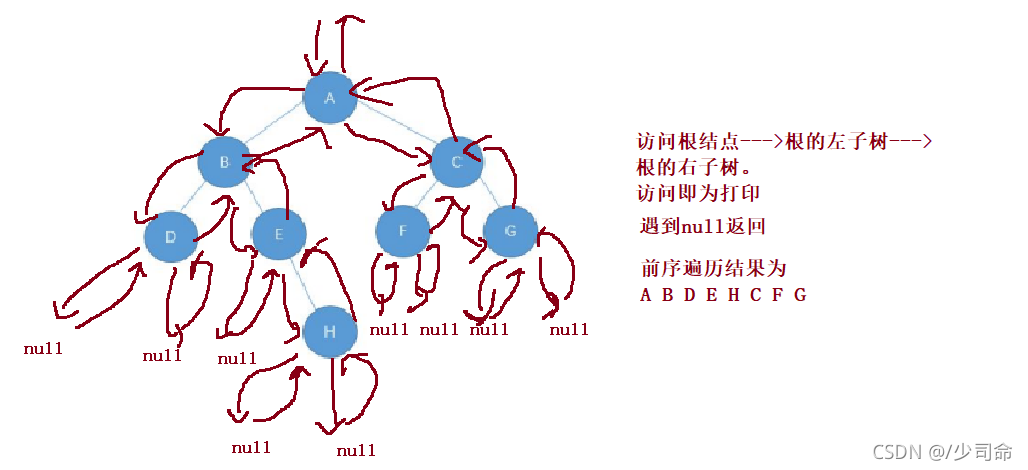
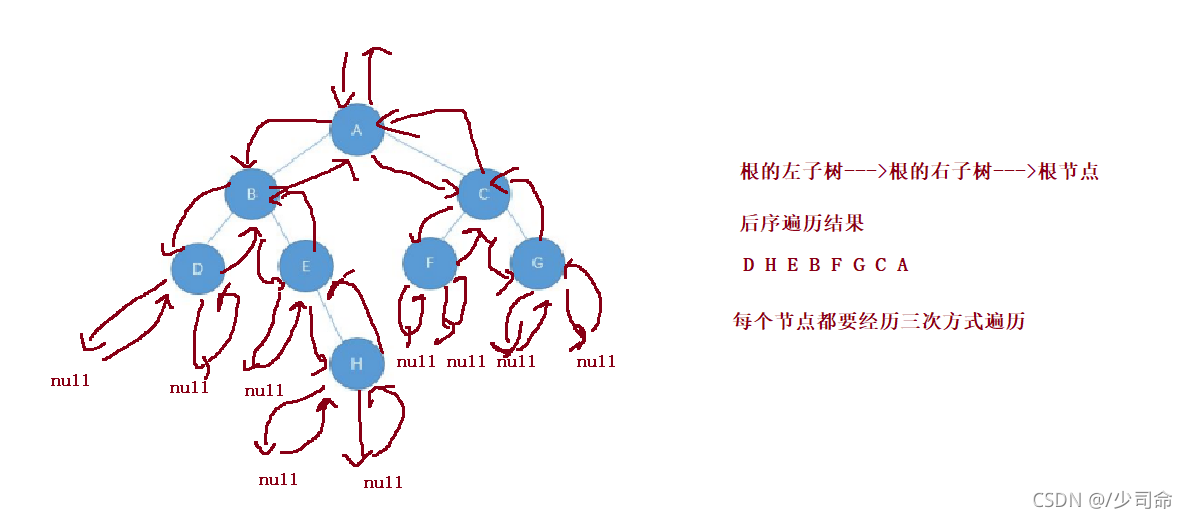
1. NLR:前序遍歷(Preorder Traversal 亦稱先序遍歷)——訪問根結點--->根的左子樹--->根的右子樹,
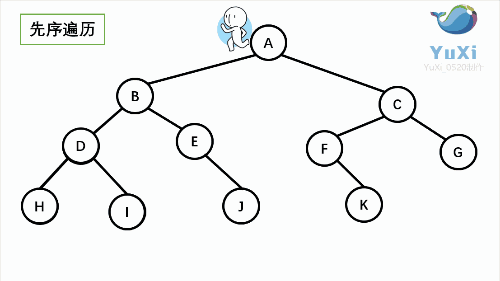
2. LNR:中序遍歷(Inorder Traversal)——根的左子樹--->根節點--->根的右子樹,
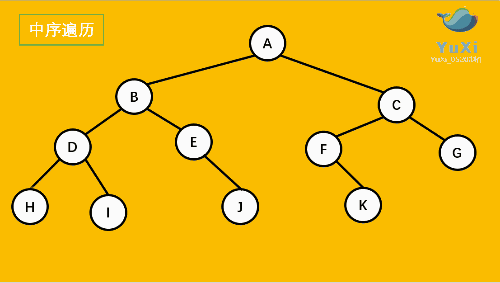
3. LRN:后序遍歷(Postorder Traversal)——根的左子樹--->根的右子樹--->根節點,
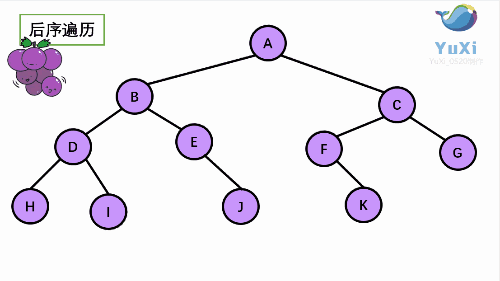
由于被訪問的結點必是某子樹的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解釋為根、根 的左子樹和根的右子樹,NLR、LNR和LRN分別又稱為先根遍歷、中根遍歷和后根遍歷,
注意:三種遍歷中只有訪問根節點列印,每一種遍歷當訪問到每一個節點都要有對應三種不同的遍歷方式,直到遍歷到null回傳到該根節點繼續完成遍歷!!!比如說前序遍歷,我每訪問一個節點都要執行問根結點--->根的左子樹--->根的右子樹這三步,中序后序遍歷一樣,
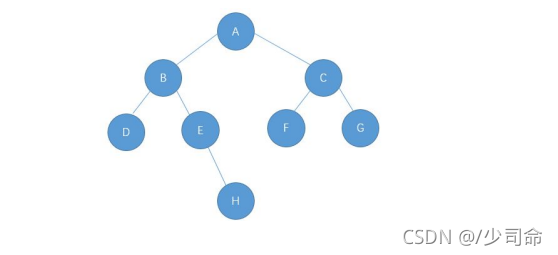
以下面這個二叉樹為例,接下來就是詳解
②前序遍歷
圖解
代碼分析
我們用列舉法創建這個二叉樹
public TreeNode createTree() {
TreeNode A = new TreeNode('A');
TreeNode B = new TreeNode('B');
TreeNode C = new TreeNode('C');
TreeNode D = new TreeNode('D');
TreeNode E = new TreeNode('E');
TreeNode F = new TreeNode('F');
TreeNode G = new TreeNode('G');
TreeNode H = new TreeNode('H');
A.left = B;
A.right = C;
B.left = D;
B.right = E;
C.left = F;
C.right = G;
E.right = H;
return A;
}// 前序遍歷
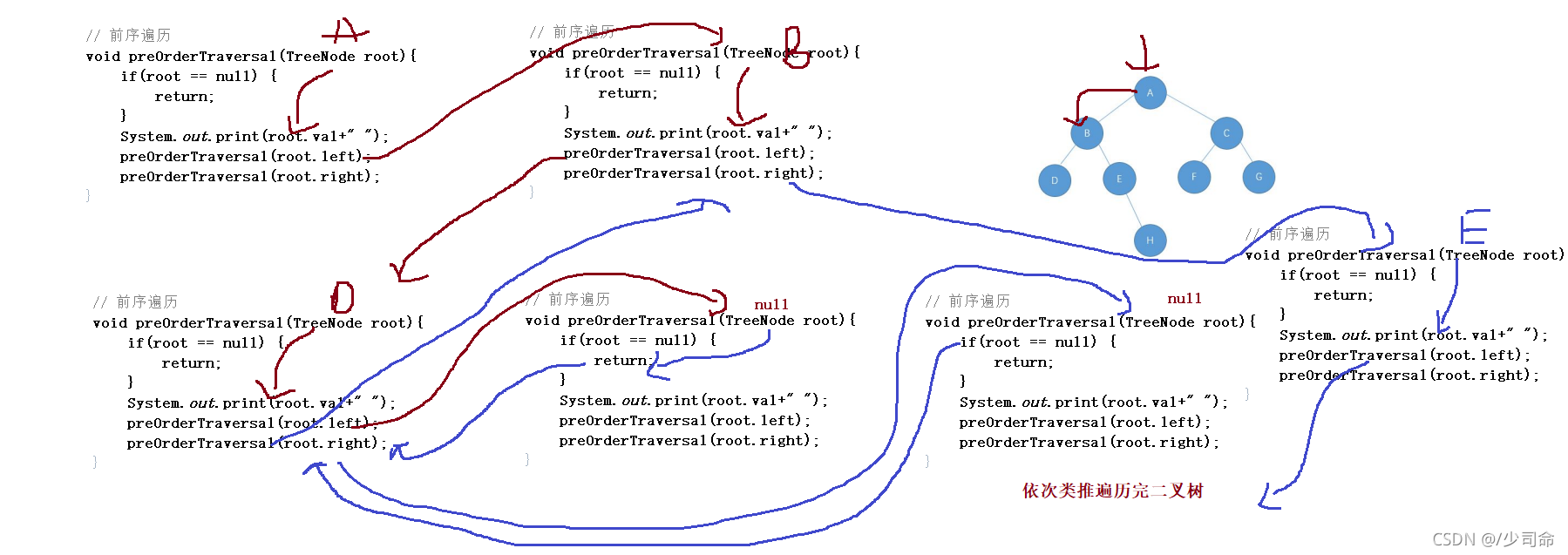
void preOrderTraversal(TreeNode root){
if(root == null) {
return;
}
System.out.print(root.val+" ");
preOrderTraversal(root.left);
preOrderTraversal(root.right);
}
DeBug分析
 ③中序遍歷
③中序遍歷
圖解
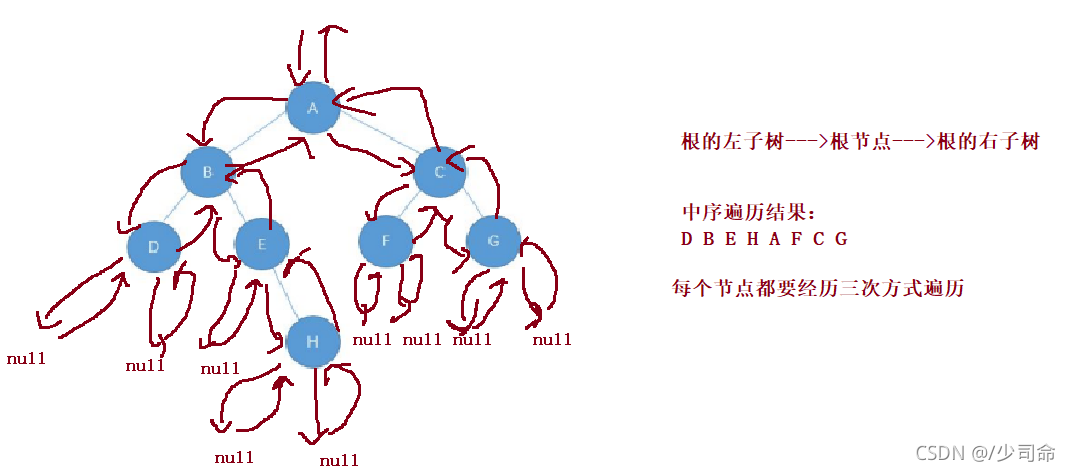
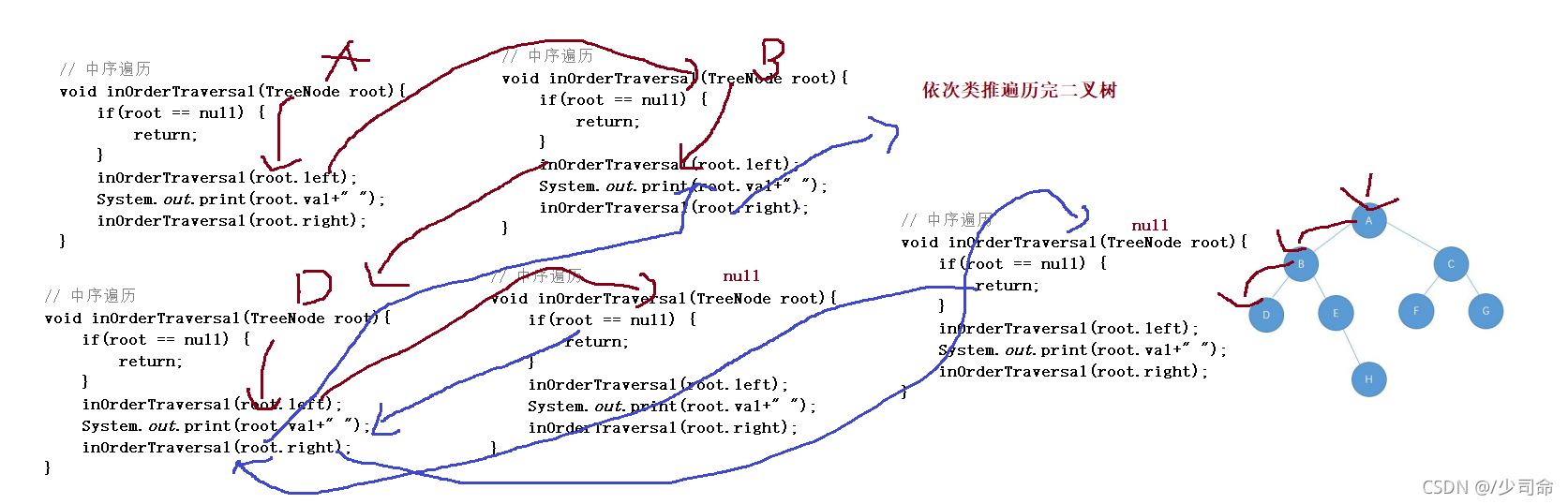
// 中序遍歷
void inOrderTraversal(TreeNode root){
if(root == null) {
return;
}
inOrderTraversal(root.left);
System.out.print(root.val+" ");
inOrderTraversal(root.right);
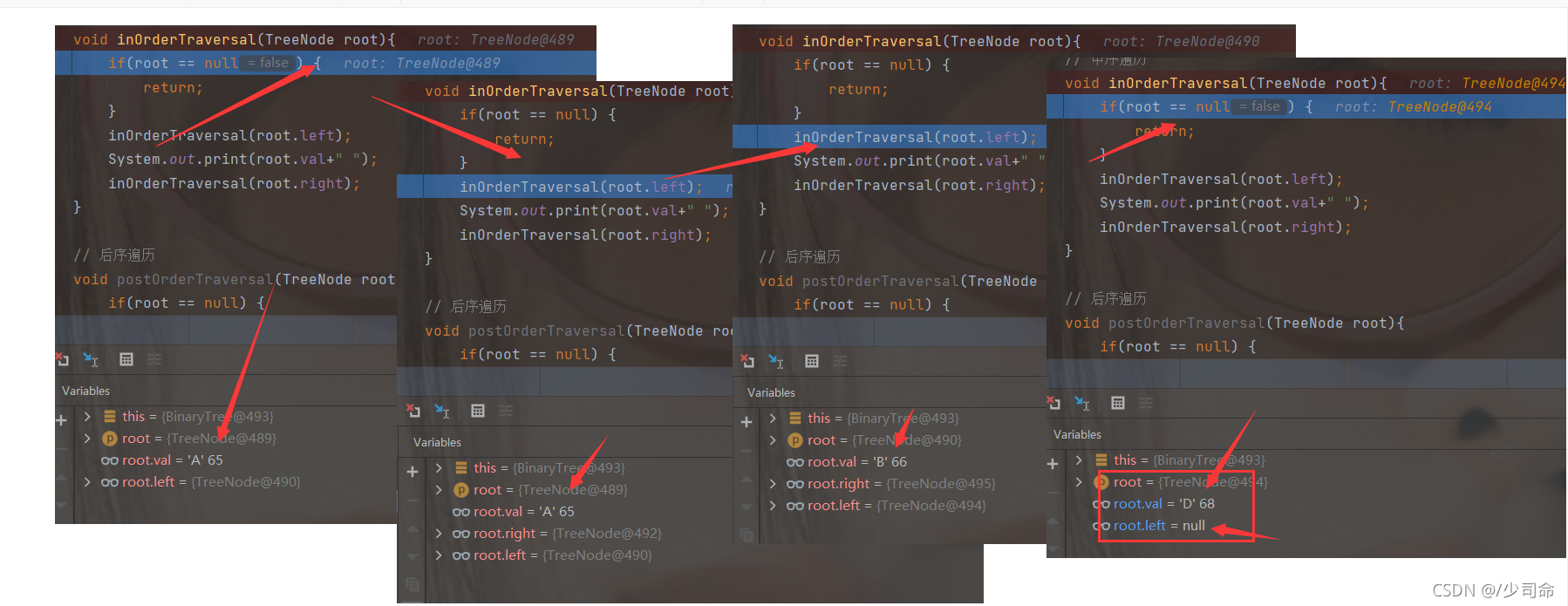
}
DeBug分析
④后序遍歷
圖解
// 后序遍歷
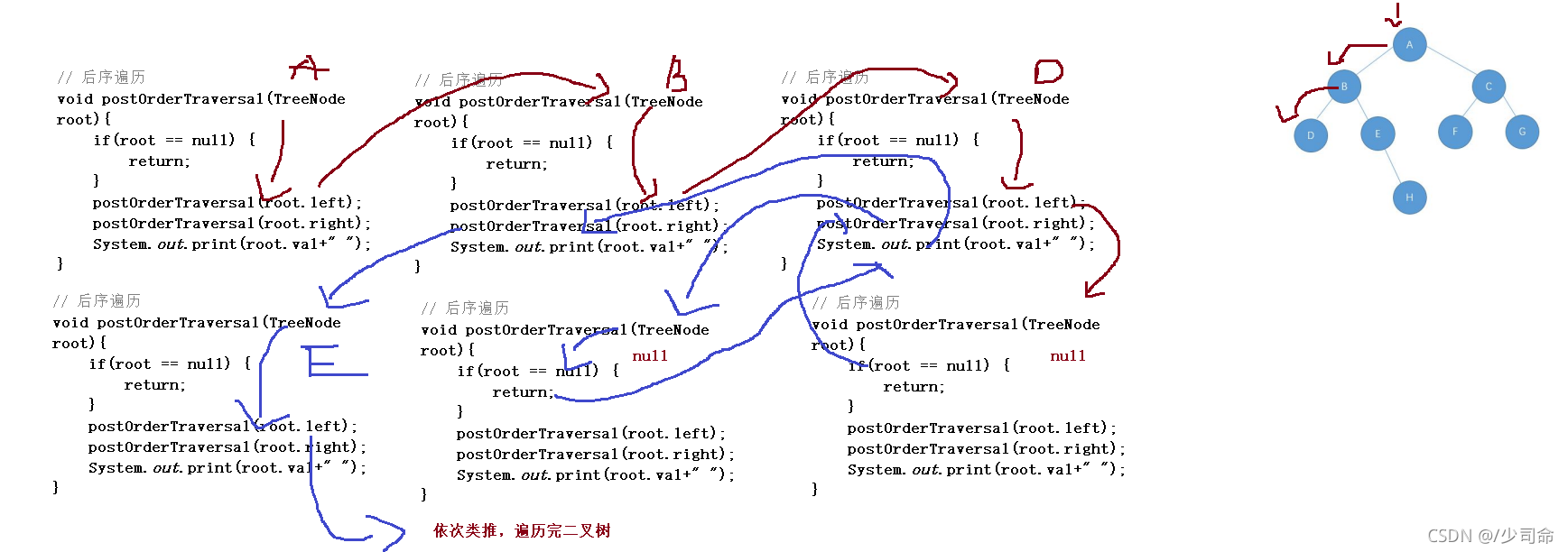
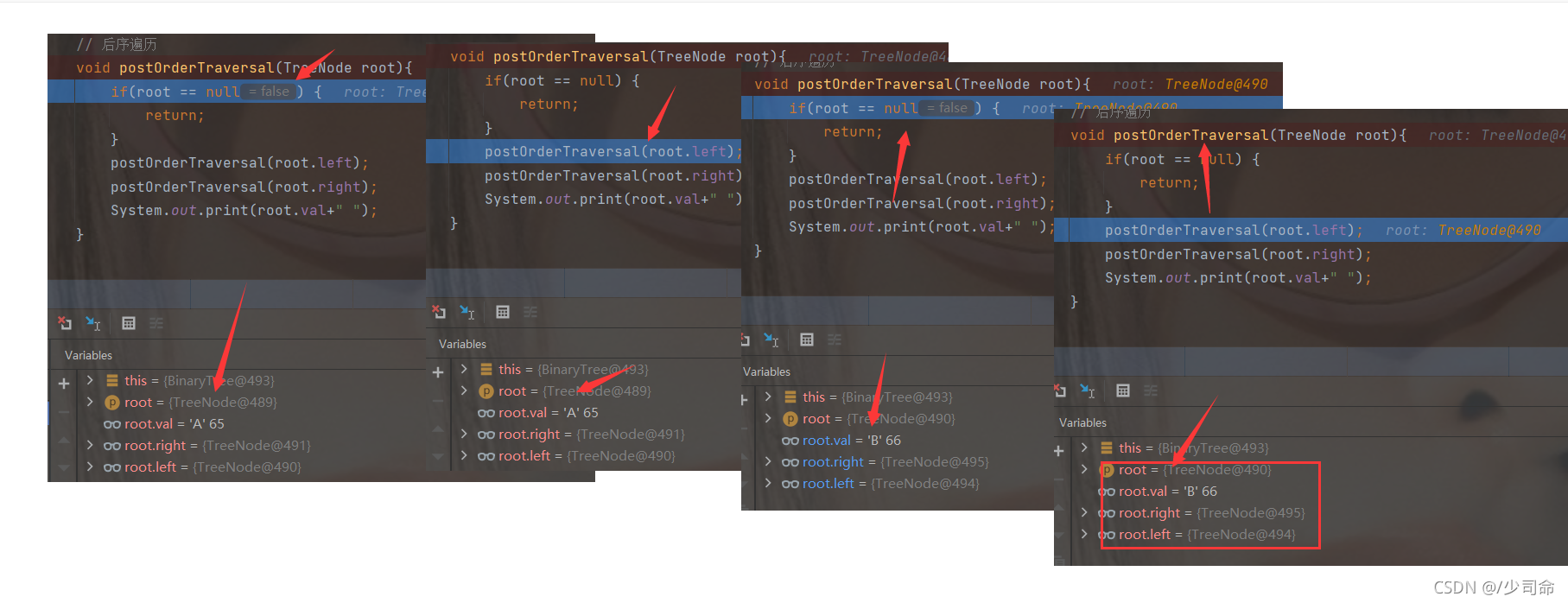
void postOrderTraversal(TreeNode root){
if(root == null) {
return;
}
postOrderTraversal(root.left);
postOrderTraversal(root.right);
System.out.print(root.val+" ");
}

DeBug分析
3,二叉搜索樹
①概念
二叉搜索樹又稱二叉排序樹,它或者是一棵空樹**,或者是具有以下性質的二叉樹:
若它的左子樹不為空,則左子樹上所有節點的值都小于根節點的值
若它的右子樹不為空,則右子樹上所有節點的值都大于根節點的值
它的左右子樹也分別為二叉搜索樹
②操作-查找
二叉搜索樹的查找類似于二分法查找
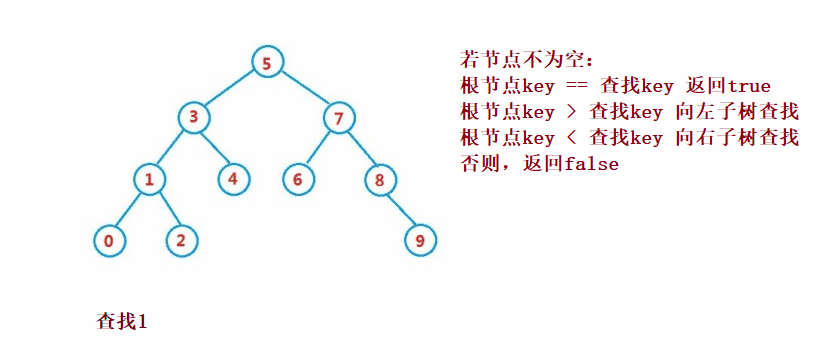
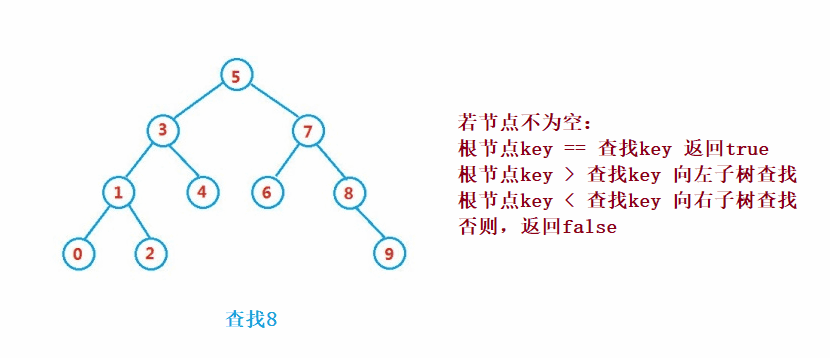
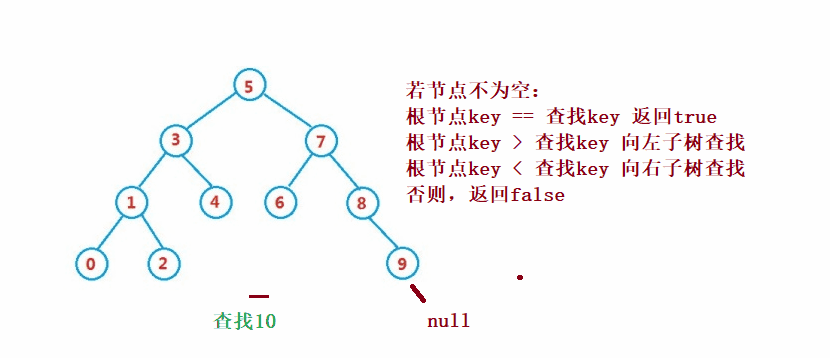
public Node search(int key) {
Node cur = root;
while (cur != null) {
if(cur.val == key) {
return cur;
}else if(cur.val < key) {
cur = cur.right;
}else {
cur = cur.left;
}
}
return null;
}③操作-插入
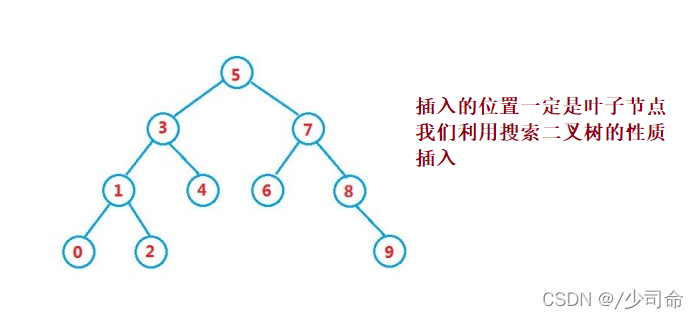
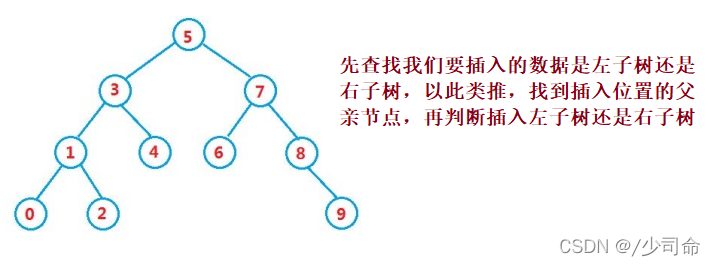
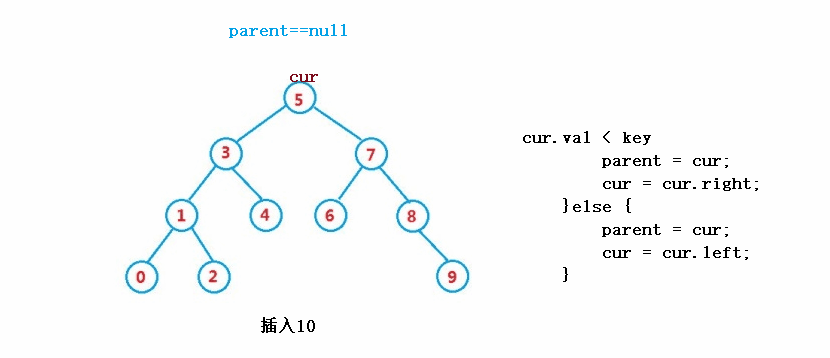
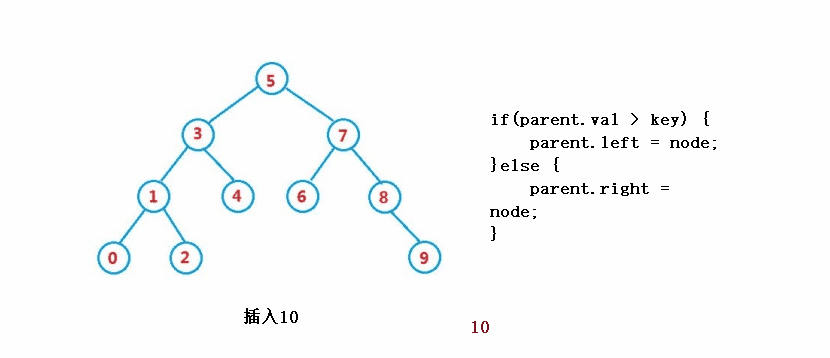
public boolean insert(int key) {
Node node = new Node(key);
if(root == null) {
root = node;
return true;
}
Node cur = root;
Node parent = null;
while(cur != null) {
if(cur.val == key) {
return false;
}else if(cur.val < key) {
parent = cur;
cur = cur.right;
}else {
parent = cur;
cur = cur.left;
}
}
//parent
if(parent.val > key) {
parent.left = node;
}else {
parent.right = node;
}
return true;
}④操作-洗掉
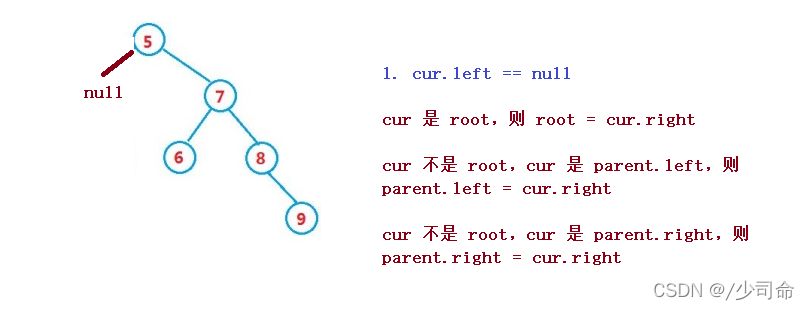
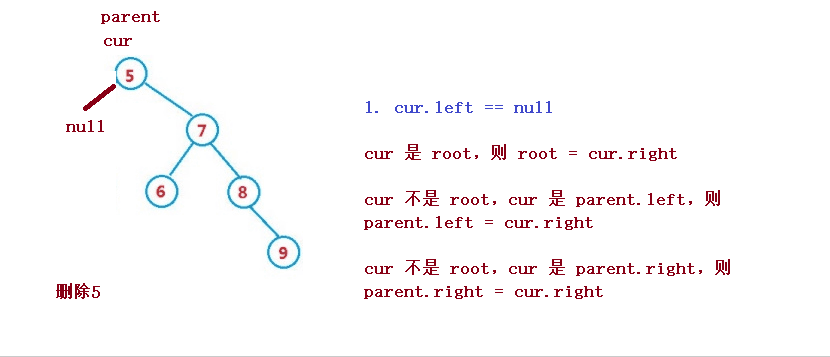
洗掉操作較為復雜,但理解了其原理還是比較容易
設待洗掉結點為 cur, 待洗掉結點的雙親結點為 parent
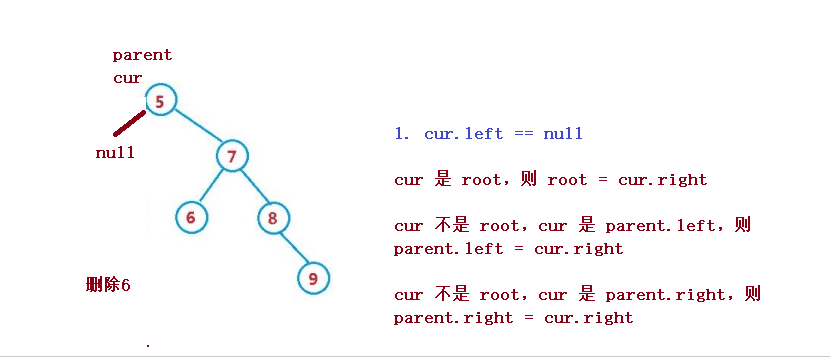
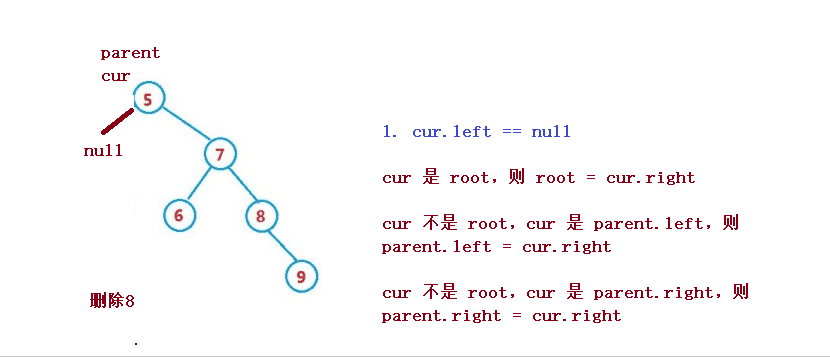
1. cur.left == null
1. cur 是 root,則 root = cur.right
2. cur 不是 root,cur 是 parent.left,則 parent.left = cur.right
3. cur 不是 root,cur 是 parent.right,則 parent.right = cur.right
2. cur.right == null
1. cur 是 root,則 root = cur.left
2. cur 不是 root,cur 是 parent.left,則 parent.left = cur.left
3. cur 不是 root,cur 是 parent.right,則 parent.right = cur.left
第二種情況和第一種情況相同,只是方向相反,這里不再畫圖
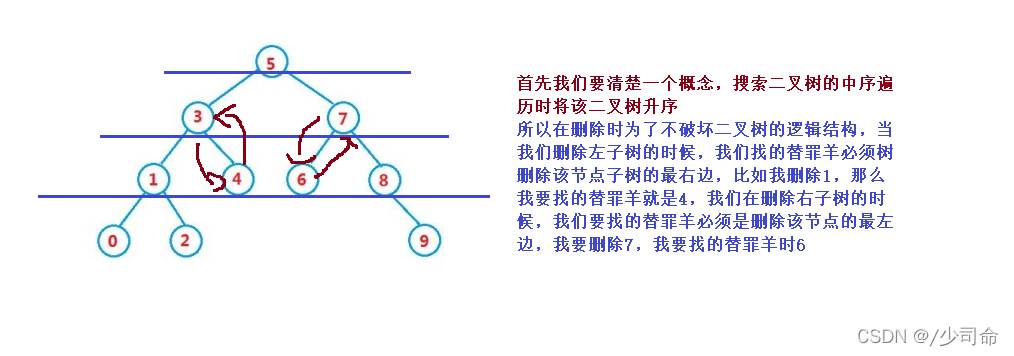
3. cur.left != null && cur.right != null
需要使用替換法進行洗掉,即在它的右子樹中尋找中序下的第一個結點(關鍵碼最小),用它的值填補到被洗掉節點中,再來處理該結點的洗掉問題
當我們在左右子樹都不為空的情況下進行洗掉,洗掉該節點會破壞樹的結構,因此用替罪羊的方法來解決,實際洗掉的程序還是上面的兩種情況,這里還是用到了搜索二叉樹的性質
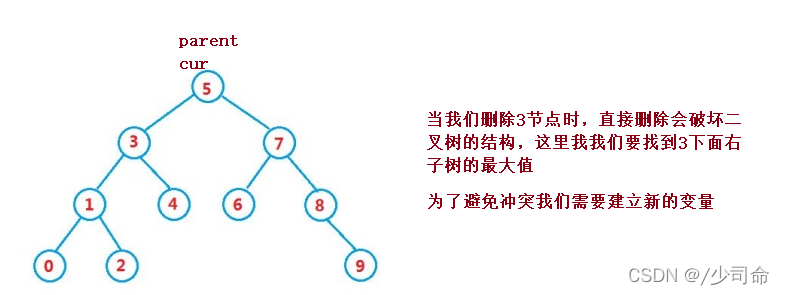

public void remove(Node parent,Node cur) {
if(cur.left == null) {
if(cur == root) {
root = cur.right;
}else if(cur == parent.left) {
parent.left = cur.right;
}else {
parent.right = cur.right;
}
}else if(cur.right == null) {
if(cur == root) {
root = cur.left;
}else if(cur == parent.left) {
parent.left = cur.left;
}else {
parent.right = cur.left;
}
}else {
Node targetParent = cur;
Node target = cur.right;
while (target.left != null) {
targetParent = target;
target = target.left;
}
cur.val = target.val;
if(target == targetParent.left) {
targetParent.left = target.right;
}else {
targetParent.right = target.right;
}
}
}
public void removeKey(int key) {
if(root == null) {
return;
}
Node cur = root;
Node parent = null;
while (cur != null) {
if(cur.val == key) {
remove(parent,cur);
return;
}else if(cur.val < key){
parent = cur;
cur = cur.right;
}else {
parent = cur;
cur = cur.left;
}
}
}⑤性能分析
插入和洗掉操作都必須先查找,查找效率代表了二叉搜索樹中各個操作的性能,
對有n個結點的二叉搜索樹,若每個元素查找的概率相等,則二叉搜索樹平均查找長度是結點在二叉搜索樹的深度 的函式,即結點越深,則比較次數越多,
但對于同一個關鍵碼集合,如果各關鍵碼插入的次序不同,可能得到不同結構的二叉搜索樹
最優情況下,二叉搜索樹為完全二叉樹,其平均比較次數為:
最差情況下,二叉搜索樹退化為單支樹,其平均比較次數為:
4,筆試習題
①二叉樹前序遍歷
void preOrderTraversal(TreeNode root){
if(root == null) {
return;
}
System.out.print(root.val+" ");
preOrderTraversal(root.left);
preOrderTraversal(root.right);
}②二叉樹中序遍歷
void inOrderTraversal(TreeNode root){
if(root == null) {
return;
}
inOrderTraversal(root.left);
System.out.print(root.val+" ");
inOrderTraversal(root.right);
}③二叉樹后序遍歷
void postOrderTraversal(TreeNode root){
if(root == null) {
return;
}
postOrderTraversal(root.left);
postOrderTraversal(root.right);
System.out.print(root.val+" ");
}④檢查兩棵樹是否相同
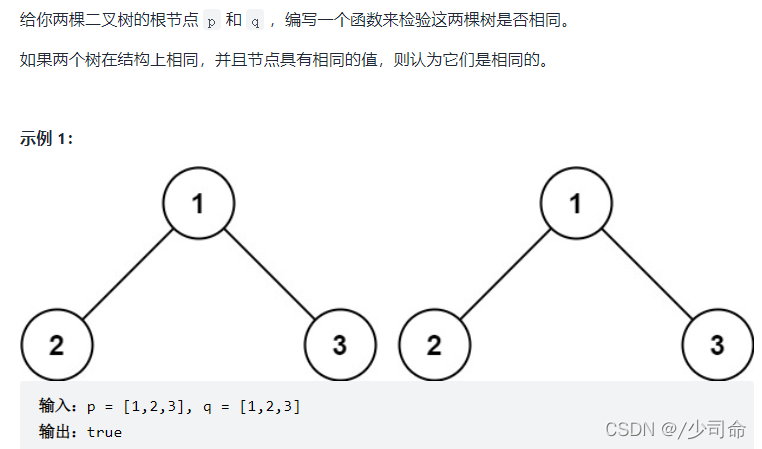
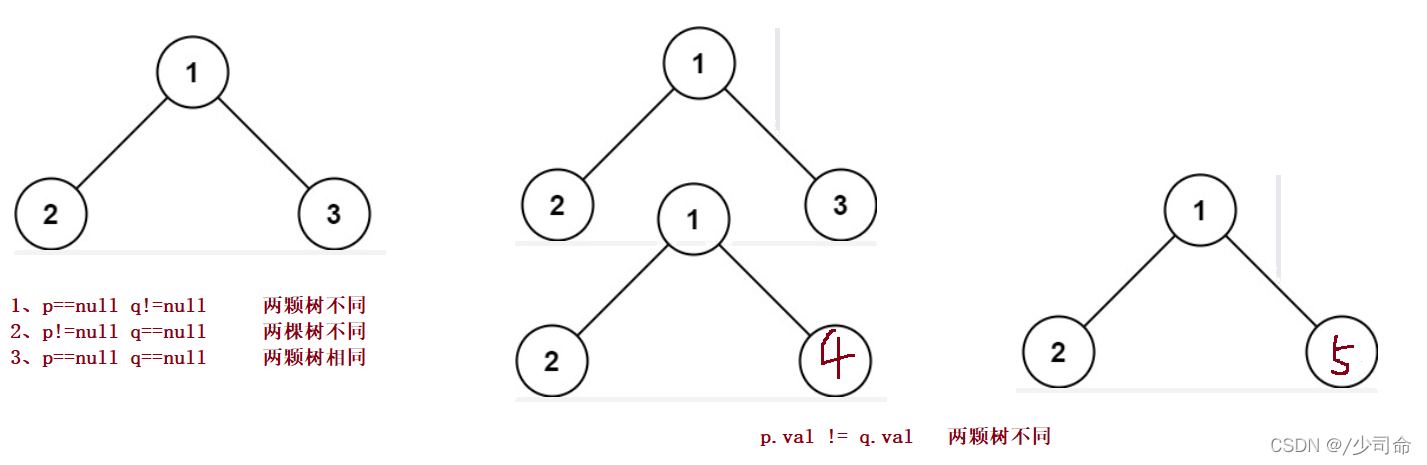

public boolean isSameTree(TreeNode p,TreeNode q){
if(p == null && q != null){
return false;
}
if(p != null && q == null){
return false;
}
if(p == null && q ==null){
return true;
}
if(p.val != q.val){
return false;
}
return isSameTree(p.left,q.left) && isSameTree(p.right,q.right);
}
⑤二叉樹的最大深度
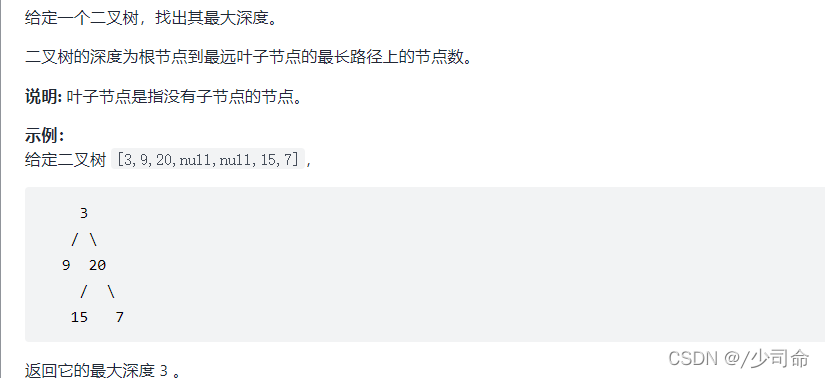

public int maxDepth(TreeNode root){
if(root == null){
return 0;
}
int leftHeight = maxDepth(root.left);
int rightHeight = maxDepth(root.right);
return Math.abs(leftHeight-rightHeight > 0? leftHeight + 1: rightHeight + 1);
}⑥另一顆樹的子樹
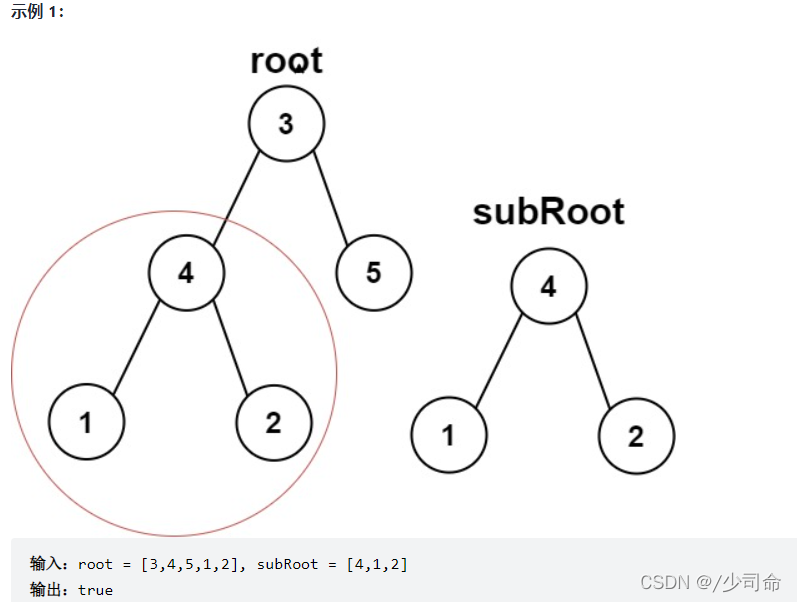
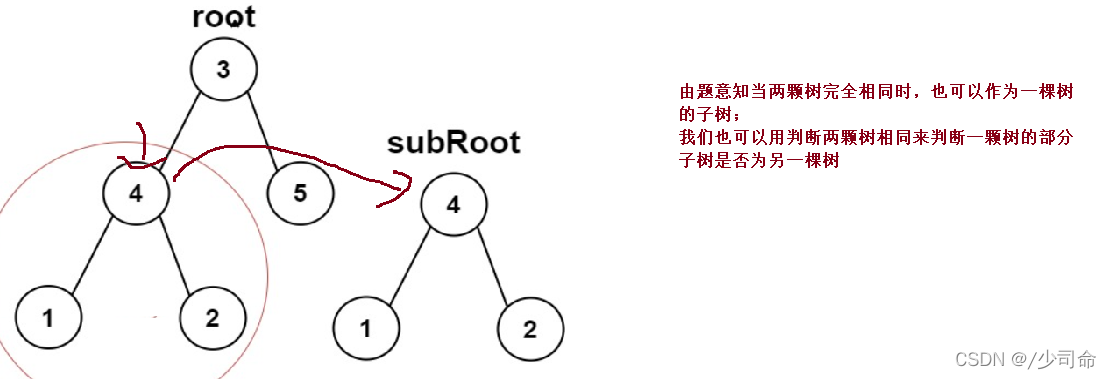
public boolean isSameTree(TreeNode p,TreeNode q){
if(p == null && q != null){
return false;
}
if(p != null && q == null){
return false;
}
if(p == null && q ==null){
return true;
}
if(p.val != q.val){
return false;
}
return isSameTree(p.left,q.left) && isSameTree(p.right,q.right);
}
public boolean isSubtree(TreeNode root, TreeNode suBroot){
if(root == null && suBroot == null){
return true;
}
if(isSameTree(root,suBroot)){
return true;
}
if(isSubtree(root.right,suBroot)){
return true;
}
if(isSubtree(root.left,suBroot)){
return true;
}
return false;
}⑦判斷一顆樹是否為一顆平衡二叉樹
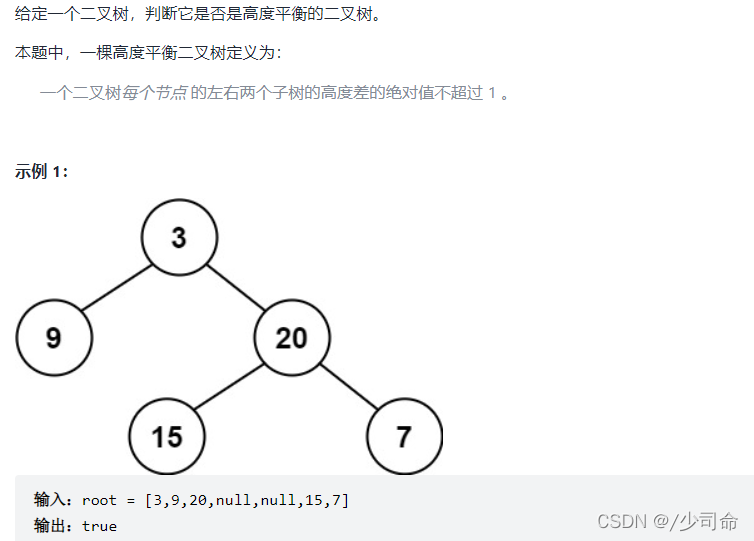
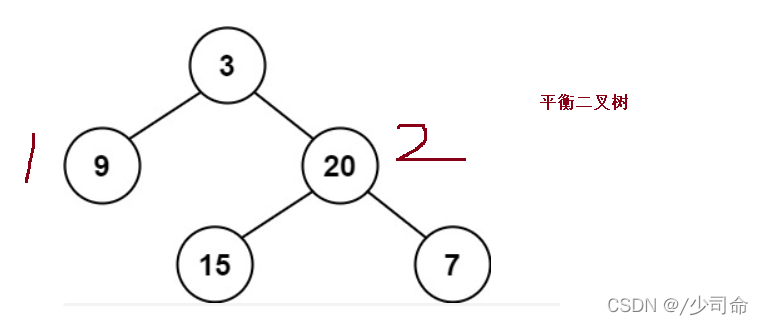
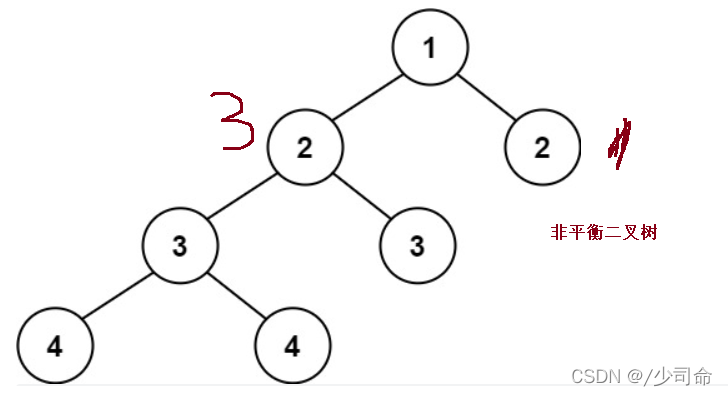
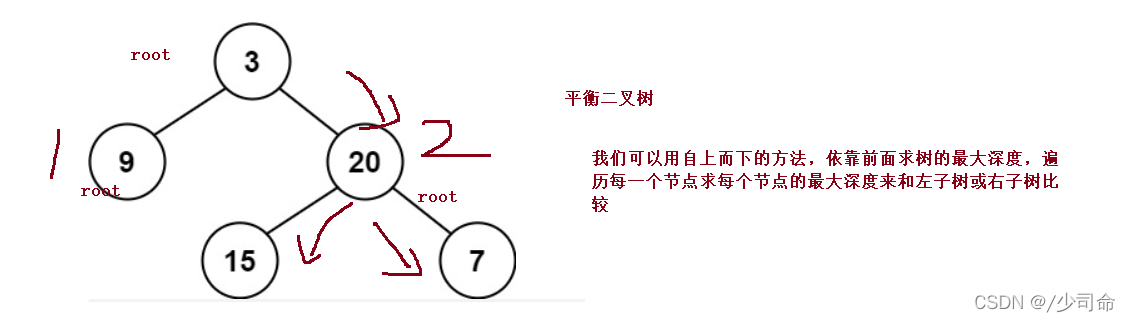
public int maxDepth(TreeNode root){
if(root == null){
return 0;
}
int leftHeight = maxDepth(root.left);
int rightHeight = maxDepth(root.right);
return Math.abs(leftHeight-rightHeight > 0? leftHeight + 1: rightHeight + 1);
}
public boolean isBalanced(TreeNode root) {
if(root == null) {
return true;
}
int leftHeight = maxDepth(root.left);
int rightHeight = maxDepth(root.right);
return
Math.abs(leftHeight-rightHeight) < 2 && isBalanced(root.left) && isBalanced(root.right);
}
public int hight(TreeNode root){
if(root == null){
return 0;
}
int leftHeight = hight(root.left);
int rightHeight = hight(root.right);
if(leftHeight >= 0 && rightHeight >= 0 && Math.abs(leftHeight-rightHeight) <= 1){
return Math.max(leftHeight,rightHeight)+1;
}else{
return -1;
}
}
public boolean isBalanced2(TreeNode root) {
return hight(root) >= 0;
}⑧對稱二叉樹
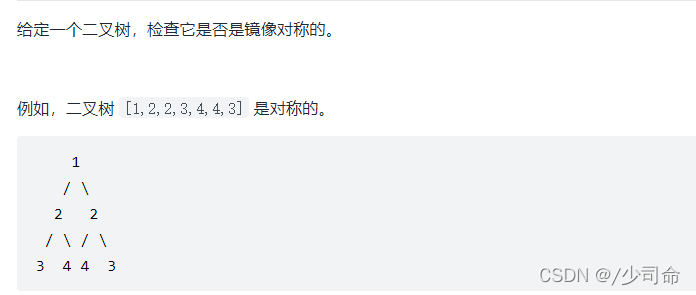


public boolean isSymmetricChild(TreeNode leftTree,TreeNode rightTree){
if(leftTree != null && rightTree == null){
return false;
}
if(leftTree == null && rightTree != null){
return false;
}
if(leftTree == null && rightTree == null){
return true;
}
if(leftTree.val != rightTree.val){
return false;
}
return isSymmetricChild(leftTree.left,rightTree.right) &&
isSymmetricChild(leftTree.left,rightTree.right);
}
public boolean isSymmetric(TreeNode root){
if(root == null){
return true;
}
return isSymmetricChild(root.left,root.right);
}⑨二叉樹鏡像
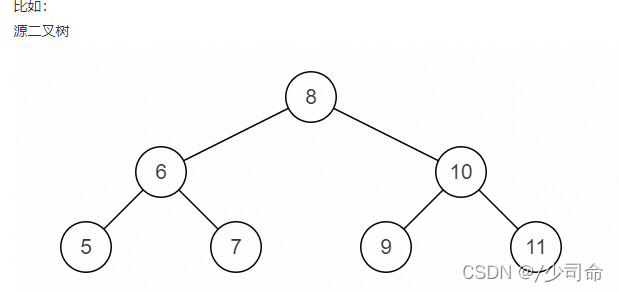
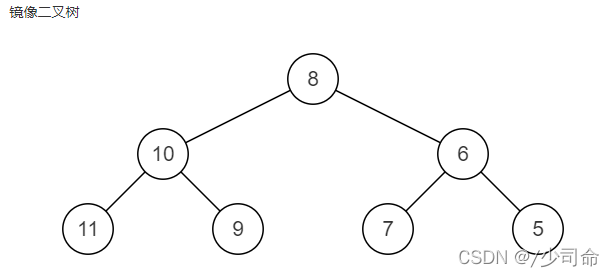

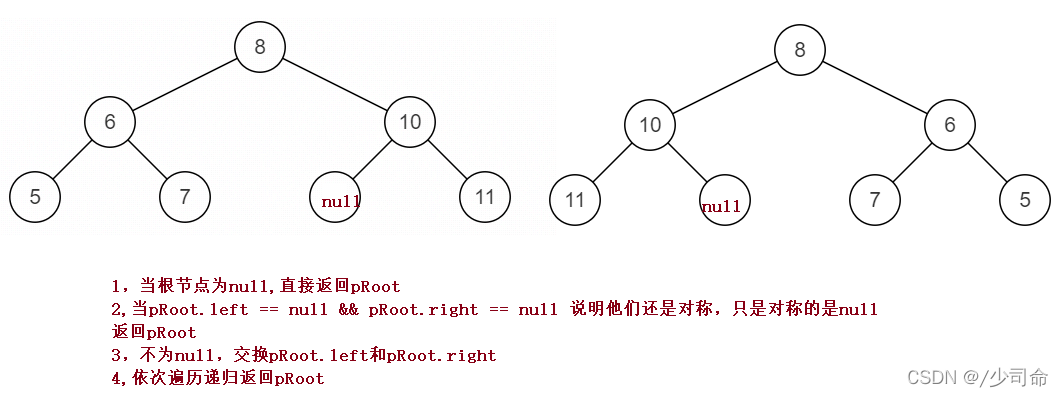
public TreeNode Mirror(TreeNode pRoot){
if(pRoot == null){
return pRoot;
}
if(pRoot.left == null && pRoot.right == null){
return pRoot;
}
TreeNode tmp = pRoot.left;
pRoot.left = pRoot.right;
pRoot.right = tmp;
if(pRoot.left != null){
Mirror(pRoot.left);
return pRoot;
}
if(pRoot.right != null){
Mirror(pRoot.right);
return pRoot;
}
return pRoot;
}五,優先級佇列(堆)
1,二叉樹的順序存盤
①存盤方式
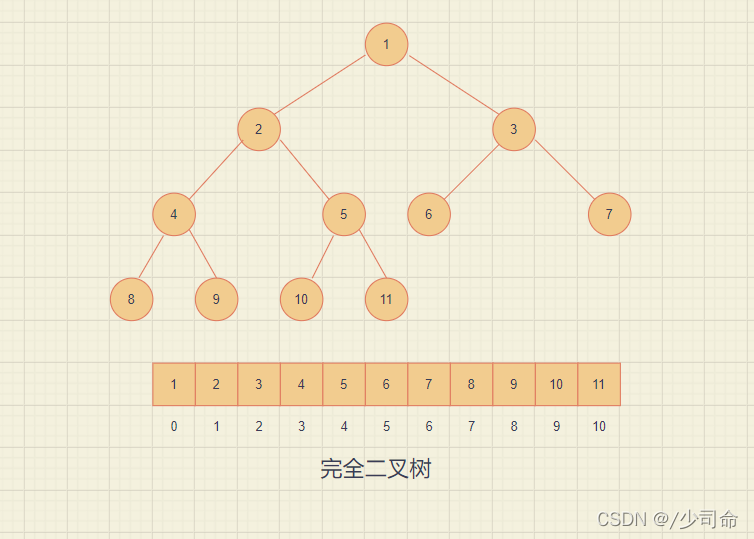
使用陣列保存二叉樹結構,方式即將二叉樹用層序遍歷方式放入陣列中, 一般只適合表示完全二叉樹,因為非完全二叉樹會有空間的浪費, 這種方式的主要用法就是堆的表示,
②下標關系
已知雙親(parent)的下標,則:
左孩子(left)下標 = 2 * parent + 1;
右孩子(right)下標 = 2 * parent + 2;
已知孩子(不區分左右)(child)下標,則:
雙親(parent)下標 = (child - 1) / 2;
③二叉樹順序遍歷
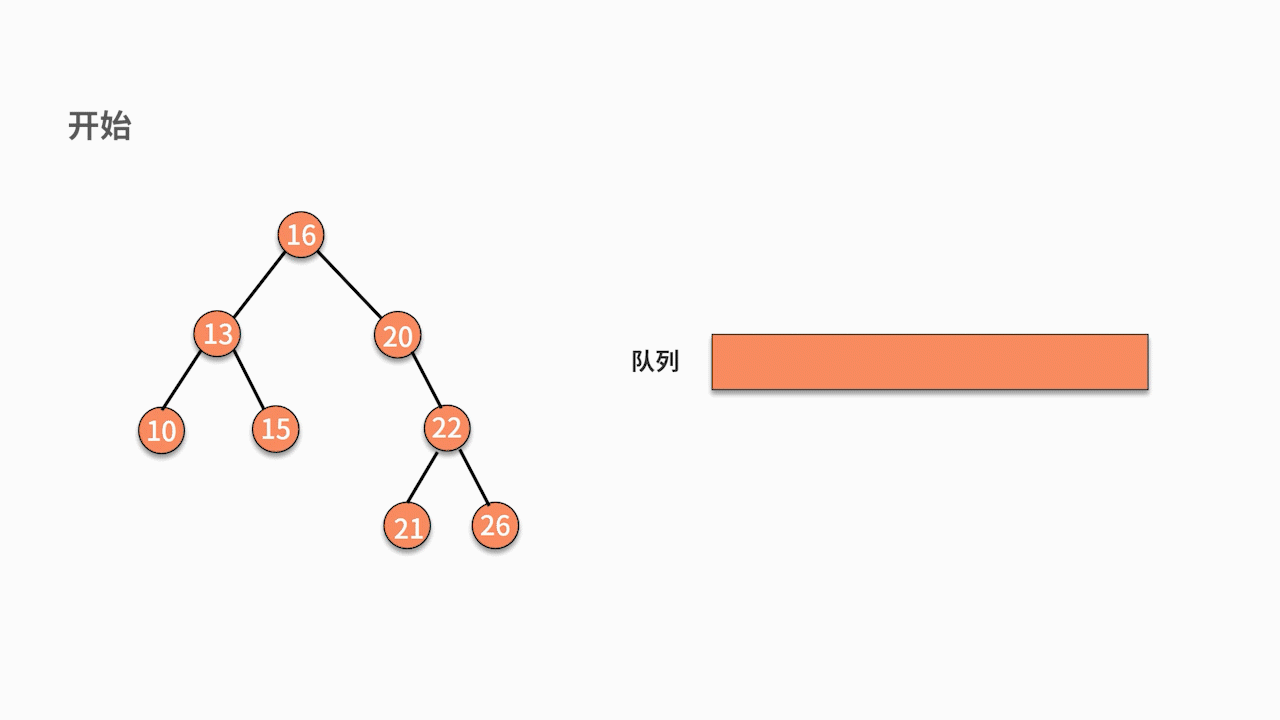
// 層序遍歷
void levelOrderTraversal(TreeNode root) {
if(root == null) {
return;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode top = queue.poll();
System.out.print(top.val+" ");
if(top.left != null) {
queue.offer(top.left);
}
if(top.right!=null) {
queue.offer(top.right);
}
}
System.out.println();
}2,堆
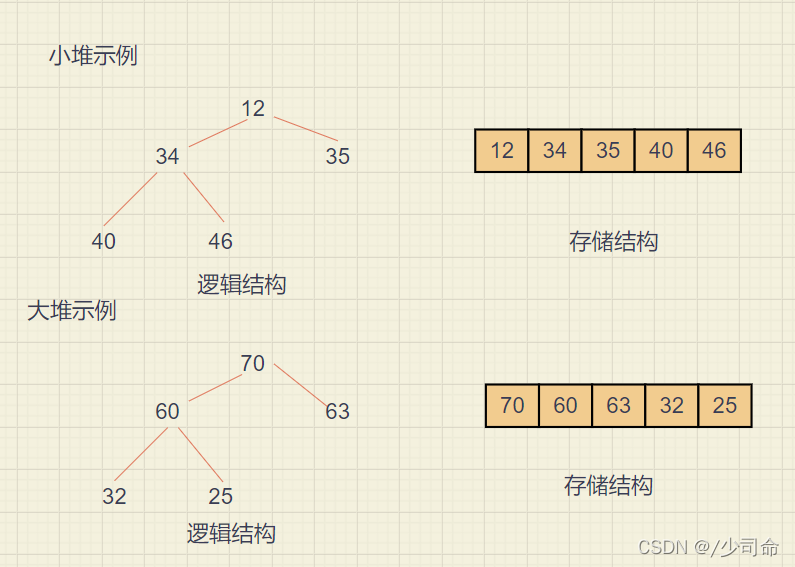
①概念
1. 堆邏輯上是一棵完全二叉樹
2. 堆物理上是保存在陣列中
3. 滿足任意結點的值都大于其子樹中結點的值,叫做大堆,或者大根堆,或者最大堆
4. 反之,則是小堆,或者小根堆,或者最小堆
②操作-向下調整
前提:
左右子樹必須已經是一個堆,才能調整,
說明:
1. array 代表存盤堆的陣列
2. size 代表陣列中被視為堆資料的個數
3. index 代表要調整位置的下標
4. left 代表 index 左孩子下標
5. right 代表 index 右孩子下標
6. min 代表 index 的最小值孩子的下標
程序(以小堆為例):
Ⅰ index 如果已經是葉子結點,則整個調整程序結束
1. 判斷 index 位置有沒有孩子
2. 因為堆是完全二叉樹,沒有左孩子就一定沒有右孩子,所以判斷是否有左孩子
3. 因為堆的存盤結構是陣列,所以判斷是否有左孩子即判斷左孩子下標是否越界,即 left >= size 越界
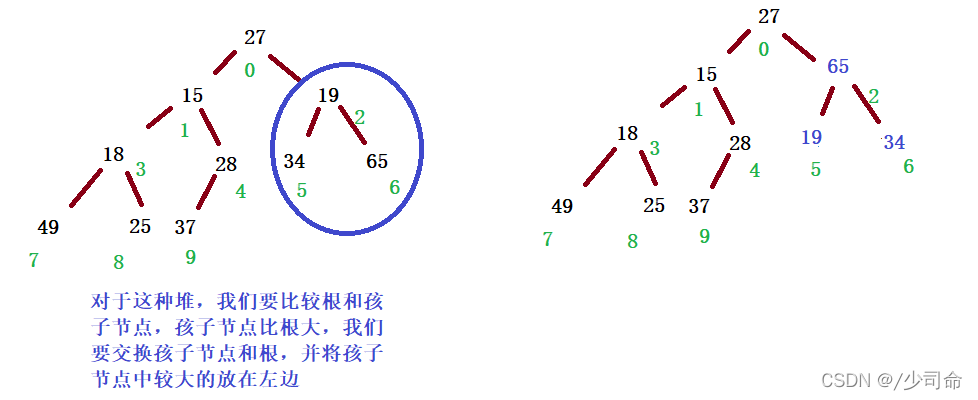
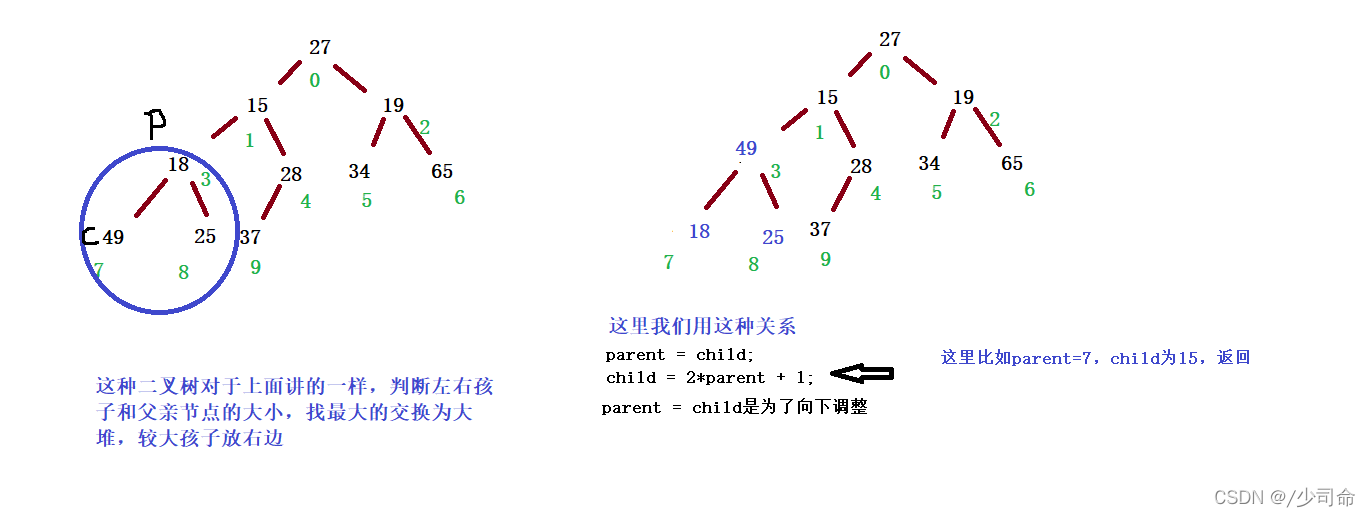
Ⅱ 確定 left 或 right,誰是 index 的最小孩子 min
1. 如果右孩子不存在,則 min = left
2. 否則,比較 array[left] 和 array[right] 值得大小,選擇小的為 min
Ⅲ比較 array[index] 的值 和 array[min] 的值,如果 array[index] <= array[min],則滿足堆的性質,調整結束
Ⅳ否則,交換 array[index] 和 array[min] 的值
Ⅴ然后因為 min 位置的堆的性質可能被破壞,所以把 min 視作 index,向下重復以上程序
向下調整是以層序遍歷的二叉樹為例來遍歷
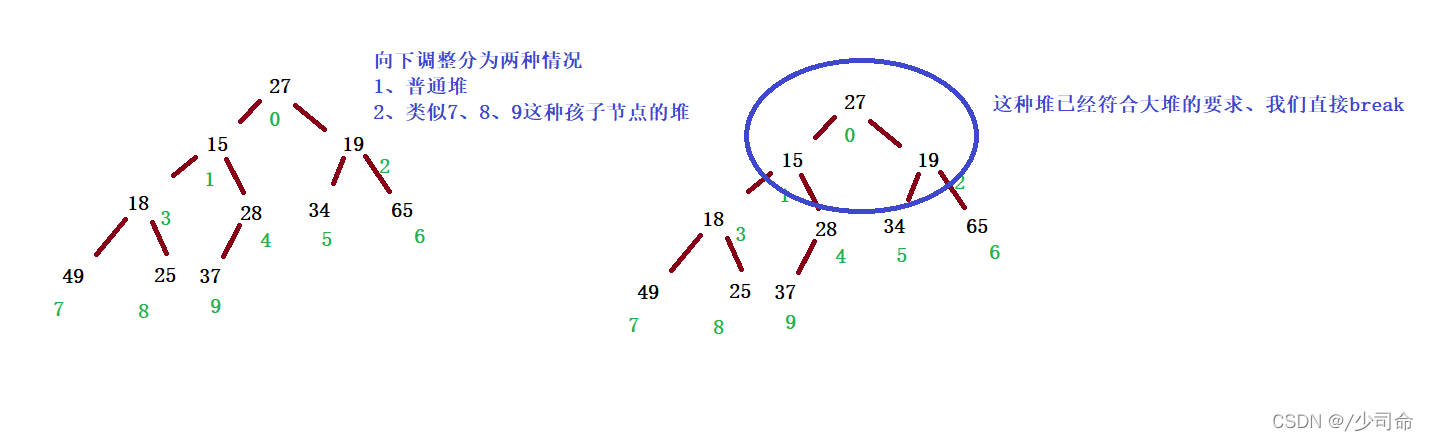
public void adjustDown(int root,int len){
int parent = root;
int child = 2*parent + 1;
while(child < len){
if (child + 1 < len && this.elem[child] < this.elem[child + 1] ){
child++;
}
if(this.elem[child] > this.elem[parent]){
int tmp = this.elem[parent];
this.elem[parent] = this.elem[child];
this.elem[child] = tmp;
parent = child;
child = 2*parent + 1;
}else{
break;
}
}
}③建堆(建大堆為例)
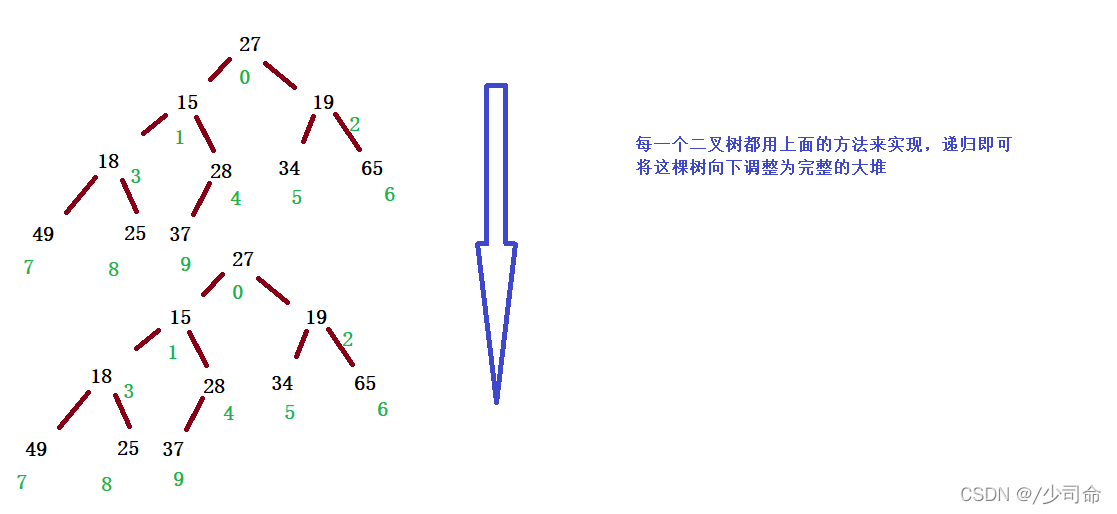
下面我們給出一個陣列,這個陣列邏輯上可以看做一顆完全二叉樹,但是還不是一個堆,現在我們通過演算法,把它構 建成一個堆,根節點左右子樹不是堆,我們怎么調整呢?這里我們從倒數的第一個非葉子節點的子樹開始調整,一直 調整到根節點的樹,就可以調整成堆,
//建大堆
public void creatHeap(int[] array){
for (int i = 0; i < array.length;i++){
this.elem[i] = array[i];
suedSize++;
}
for (int parent = (array.length - 1 - 1) / 2;parent >= 0;parent--){
adjustDown(parent,this.suedSize);
}3,堆的應用-優先級佇列
①概念
在很多應用中,我們通常需要按照優先級情況對待處理物件進行處理,比如首先處理優先級最高的物件,然后處理次 高的物件,最簡單的一個例子就是,在手機上玩游戲的時候,如果有來電,那么系統應該優先處理打進來的電話, 在這種情況下,我們的資料結構應該提供兩個最基本的操作,一個是回傳最高優先級物件,一個是添加新的物件,這 種資料結構就是優先級佇列(Priority Queue)
②內部原理
優先級佇列的實作方式有很多,但最常見的是使用堆來構建,
③入佇列
程序(以大堆為例):
1. 首先按尾插方式放入陣列
2. 比較其和其雙親的值的大小,如果雙親的值大,則滿足堆的性質,插入結束
3. 否則,交換其和雙親位置的值,重新進行 2、3 步驟 4. 直到根結點
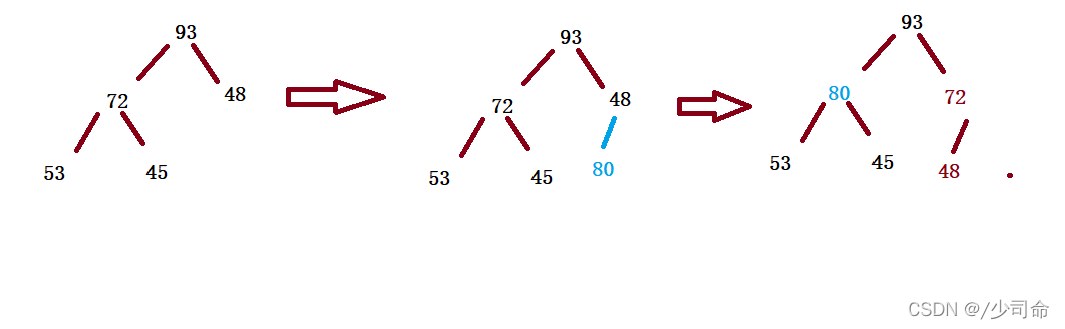
public void adjustUp(int child){
int parent = (child - 1) / 2;
while(child>0){
if(this.elem[child] > this.elem[parent]){
int tmp = this.elem[parent];
this.elem[parent] = this.elem[child];
this.elem[child] = tmp;
child = parent;
parent = (child - 1) / 2;
}else {
break;
}
}
}public void push(int val) {
if (isFull()) {
this.elem = Arrays.copyOf(this.elem, 2 * this.elem.length);
this.elem[this.suedSize] = val;
this.suedSize++;
adjustUp(this.suedSize - 1);
}
}④出佇列(優先級最高)
為了防止破壞堆的結構,洗掉時并不是直接將堆頂元素洗掉,而是用陣列的最后一個元素替換堆頂元素,然后通過向下調整方式重新調整成堆
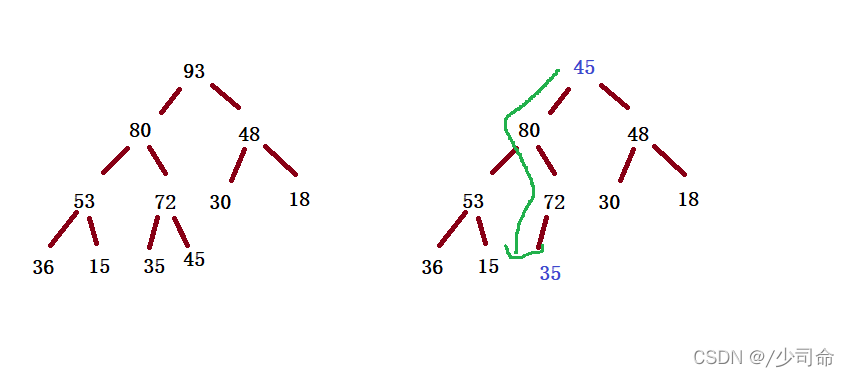
public boolean isEmpty(){
return this.suedSize == 0;
} public void pop(){
if(isEmpty()){
return;
}
int tmp = this.elem[0];
this.elem[0] = this.elem[this.suedSize-1];
this.elem[this.suedSize-1] = tmp;
this.suedSize--;
adjustDown(0,this.suedSize);
}⑤回傳隊首元素(優先級最高)
public int peek(){
if(isEmpty()){
return -1;
}
return this.elem[0];
} public boolean isFull(){
return this.suedSize == this.elem.length;
}4,堆排序
/**
* 一定是先創建大堆
* 調整每棵樹
* 開始堆排序:
* 先交換 后調整 直到 0下標
*/
public void heapSort(){
int end = this.suedSize-1;
while (end > 0){
int tmp = this.elem[0];
this.elem[0] = this.elem[end];
this.elem[end] = tmp;
adjustDown(0,end);
end--;
}
}六,排序
1,概念
①排序
排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作, 平時的背景關系中,如果提到排序,通常指的是排升序(非降序), 通常意義上的排序,都是指的原地排序(in place sort),
②穩定性
兩個相等的資料,如果經過排序后,排序演算法能保證其相對位置不發生變化,則我們稱該演算法是具備穩定性的排序演算法
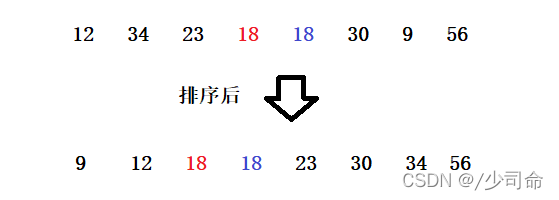
或者我們說沒有跳躍的排序也是穩定的排序

2,排序詳解
①直接插入排序
整個區間被分為
1. 有序區間
2. 無序區間
每次選擇無序區間的第一個元素,在有序區間內選擇合適的位置插入

public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
insertSort(array);
System.out.println(Arrays.toString(array));
} /**
* 時間復雜度:
* 最好:O(N) -> 資料是有序的
* 最壞:O(N^2) -> 無序的資料
* 空間復雜度:O(1)
* 穩定性:穩定排序
* @param array
*/
public static void insertSort(int[] array) {
for(int i = 1;i < array.length;i++) {//n-1
int tmp = array[i];
int j = i-1;
for(; j >= 0;j--) {//n-1
if(array[j] > tmp) {
array[j+1] = array[j];
}else{
//array[j+1] = tmp;
break;
}
}
array[j+1] = tmp;
}
}②希爾排序
希爾排序法又稱縮小增量法,希爾排序法的基本思想是:先選定一個整數,把待排序檔案中所有記錄分成個組,所有 距離為的記錄分在同一組內,并對每一組內的記錄進行排序,然后,取,重復上述分組和排序的作業,當到達=1時, 所有記錄在統一組內排好序,
1. 希爾排序是對直接插入排序的優化,
2. 當gap > 1時都是預排序,目的是讓陣列更接近于有序,當gap == 1時,陣列已經接近有序的了,這樣就會很 快,這樣整體而言,可以達到優化的效果,我們實作后可以進行性能測驗的對比,
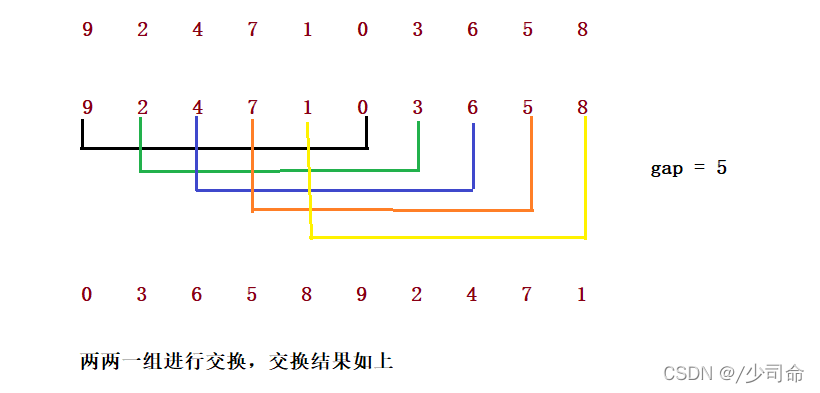

/**
* 時間復雜度:不好算 n^1.3 - n^1.5 之間
* 空間復雜度:O(1)
* 穩定性:不穩定的排序
* 技巧:如果在比較的程序當中 沒有發生跳躍式的交換 那么就是穩定的
* @param array
*
*
* @param array 排序的陣列
* @param gap 每組的間隔 -》 組數
*/
public static void shell(int[] array,int gap) {
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i-gap;
for (; j >= 0; j -= gap) {
if(array[j] > tmp) {
array[j+gap] = array[j];
}else {
break;
}
}
array[j+gap] = tmp;
}
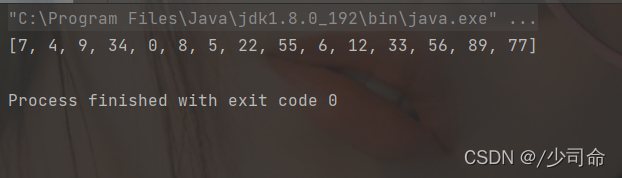
}public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
shell(array,5);
System.out.println(Arrays.toString(array));
}
③直接選擇排序
每一次從無序區間選出最大(或最小)的一個元素,存放在無序區間的最后(或最前),直到全部待排序的資料元素排完 ,

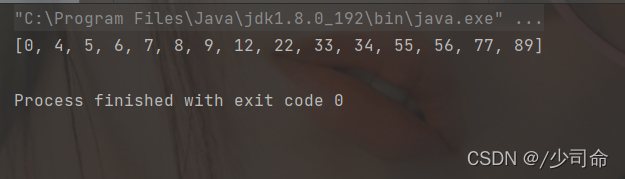
public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
selectSort(array);
System.out.println(Arrays.toString(array));
} /**
* 時間復雜度:
* 最好:O(N^2)
* 最壞:O(N^2)
* 空間復雜度:O(1)
* 穩定性:不穩定的
* @param array
*/
public static void selectSort(int[] array) {
for (int i = 0; i < array.length; i++) {
for (int j = i+1; j < array.length; j++) {
if(array[j] < array[i]) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
}
}
④堆排序
基本原理也是選擇排序,只是不在使用遍歷的方式查找無序區間的最大的數,而是通過堆來選擇無序區間的最大的數,
注意: 排升序要建大堆;排降序要建小堆,
public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
heapSort(array);
System.out.println(Arrays.toString(array));
} public static void siftDown(int[] array,int root,int len) {
int parent = root;
int child = 2*parent+1;
while (child < len) {
if(child+1 < len && array[child] < array[child+1]) {
child++;
}
//child的下標就是左右孩子的最大值下標
if(array[child] > array[parent]) {
int tmp = array[child];
array[child] = array[parent];
array[parent] = tmp;
parent = child;
child = 2*parent+1;
}else {
break;
}
}
}
public static void createHeap(int[] array) {
//從小到大排序 -》 大根堆
for (int i = (array.length-1 - 1) / 2; i >= 0 ; i--) {
siftDown(array,i,array.length);
}
}
/**
* 時間復雜度:O(N*logN) 都是這個時間復雜度
* 復雜度:O(1)
* 穩定性:不穩定的排序
* @param array
*/
public static void heapSort(int[] array) {
createHeap(array);//O(n)
int end = array.length-1;
while (end > 0) {//O(N*logN)
int tmp = array[end];
array[end] = array[0];
array[0] = tmp;
siftDown(array,0,end);
end--;
}
}
⑤冒泡排序
在無序區間,通過相鄰數的比較,將最大的數冒泡到無序區間的最后,持續這個程序,直到陣列整體有序
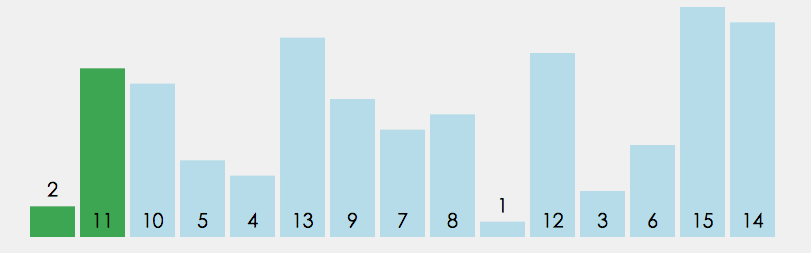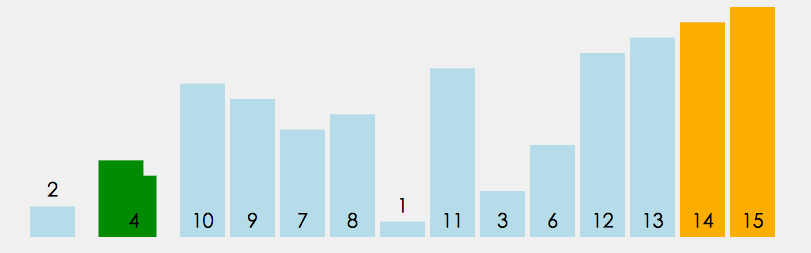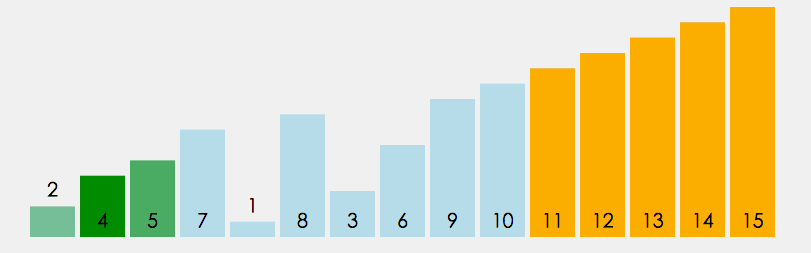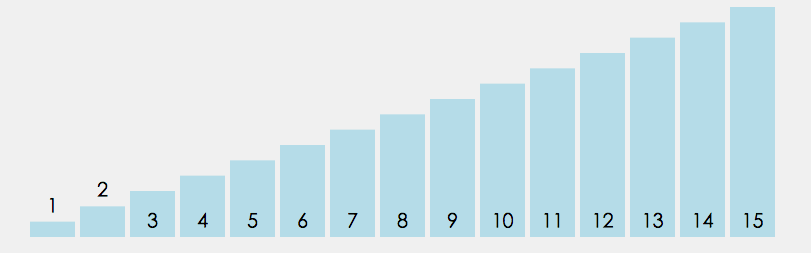
public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
bubbleSort(array);
System.out.println(Arrays.toString(array));
} /**
* 時間復雜度:
* 最好最壞都是O(n^2)
* 空間復雜度:O(1)
* 穩定性:穩定的排序
* 冒泡 直接插入
* @param array
*/
public static void bubbleSort(int[] array) {
for (int i = 0; i < array.length-1; i++) {
for (int j = 0; j < array.length-1-i; j++) {
if(array[j] > array[j+1]) {
int tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
}
}
}
}
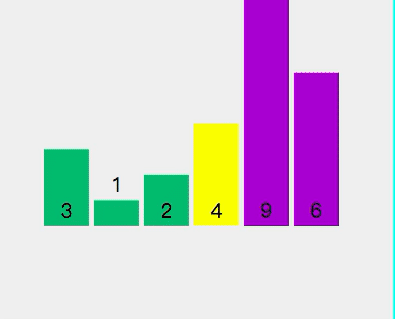
⑥快速排序
1. 從待排序區間選擇一個數,作為基準值(pivot);
2. Partition: 遍歷整個待排序區間,將比基準值小的(可以包含相等的)放到基準值的左邊,將比基準值大的(可 以包含相等的)放到基準值的右邊;
3. 采用分治思想,對左右兩個小區間按照同樣的方式處理,直到小區間的長度 == 1,代表已經有序,或者小區間 的長度 == 0,代表沒有資料
public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
quickSort1(array);
System.out.println(Arrays.toString(array));
}public static int partition(int[] array,int low,int high) {
int tmp = array[low];
while (low < high) {
while (low < high && array[high] >= tmp) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= tmp) {
low++;
}
array[high] = array[low];
}
array[low] = tmp;
return low;
}
public static void quick(int[] array,int start,int end) {
if(start >= end) {
return;
}
int mid = (start+end)/2;
int pivot = partition(array,start,end);
quick(array,start,pivot-1);
quick(array,pivot+1,end);
}
/**
* 時間復雜度:
* 最好:O(n*logn) 均勻的分割下
* 最壞:o(n^2) 資料有序的時候
* 空間復雜度:
* 最好:logn
* 最壞:O(n)
* 穩定性:不穩定的排序
*
* k*n*logn
* 2
* 1.2
* @param array
*/
public static void quickSort1(int[] array) {
quick(array,0,array.length-1);
}
⑦歸并排序
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide and Conquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子 序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
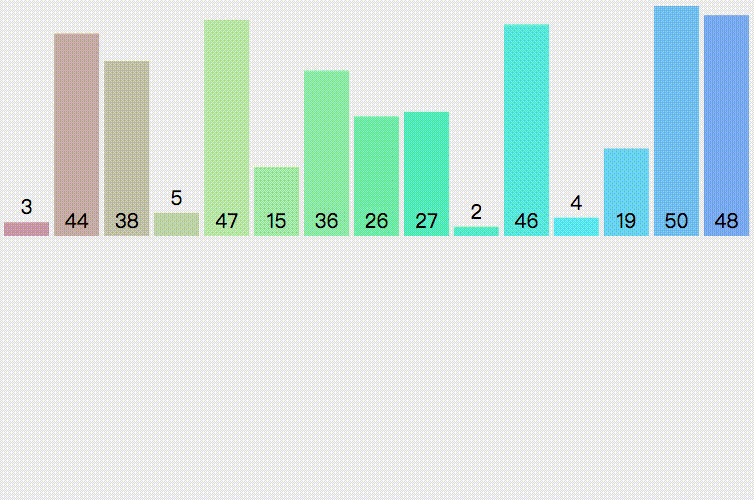
public static void main(String[] args) {
int[] array = {12,5,9,34,6,8,33,56,89,0,7,4,22,55,77};
mergeSort1(array);
System.out.println(Arrays.toString(array));
}public static void merge(int[] array,int low,int mid,int high) {
int s1 = low;
int e1 = mid;
int s2 = mid+1;
int e2 = high;
int[] tmp = new int[high-low+1];
int k = 0;//代表tmp陣列的下標
while (s1 <= e1 && s2 <= e2) {
if(array[s1] <= array[s2]) {
tmp[k++] = array[s1++];
}else {
tmp[k++] = array[s2++];
}
}
//有2種情況
while (s1 <= e1){
//說明第2個歸并段沒有了資料 把第1個歸并段剩下的資料 全部拷貝過來
tmp[k++] = array[s1++];
}
while (s2 <= e2) {
//說明第1個歸并段沒有了資料 把第2個歸并段剩下的資料 全部拷貝過來
tmp[k++] = array[s2++];
}
//tmp陣列當中 存盤的就是當前歸并好的資料
for (int i = 0; i < tmp.length; i++) {
array[i+low] = tmp[i];
}
}
public static void mergeSortInternal(int[] array,int low,int high) {
if(low >= high) {
return;
}
int mid = (low+high) / 2;
mergeSortInternal(array,low,mid);
mergeSortInternal(array,mid+1,high);
//合并的程序
merge(array,low,mid,high);
}
/**
* 時間復雜度: O(N*log n)
* 空間復雜度:O(N)
* 穩定性:穩定的
* @param array
*/
public static void mergeSort1(int[] array) {
mergeSortInternal(array, 0,array.length-1);
}
七,List
1,ArrayList簡介
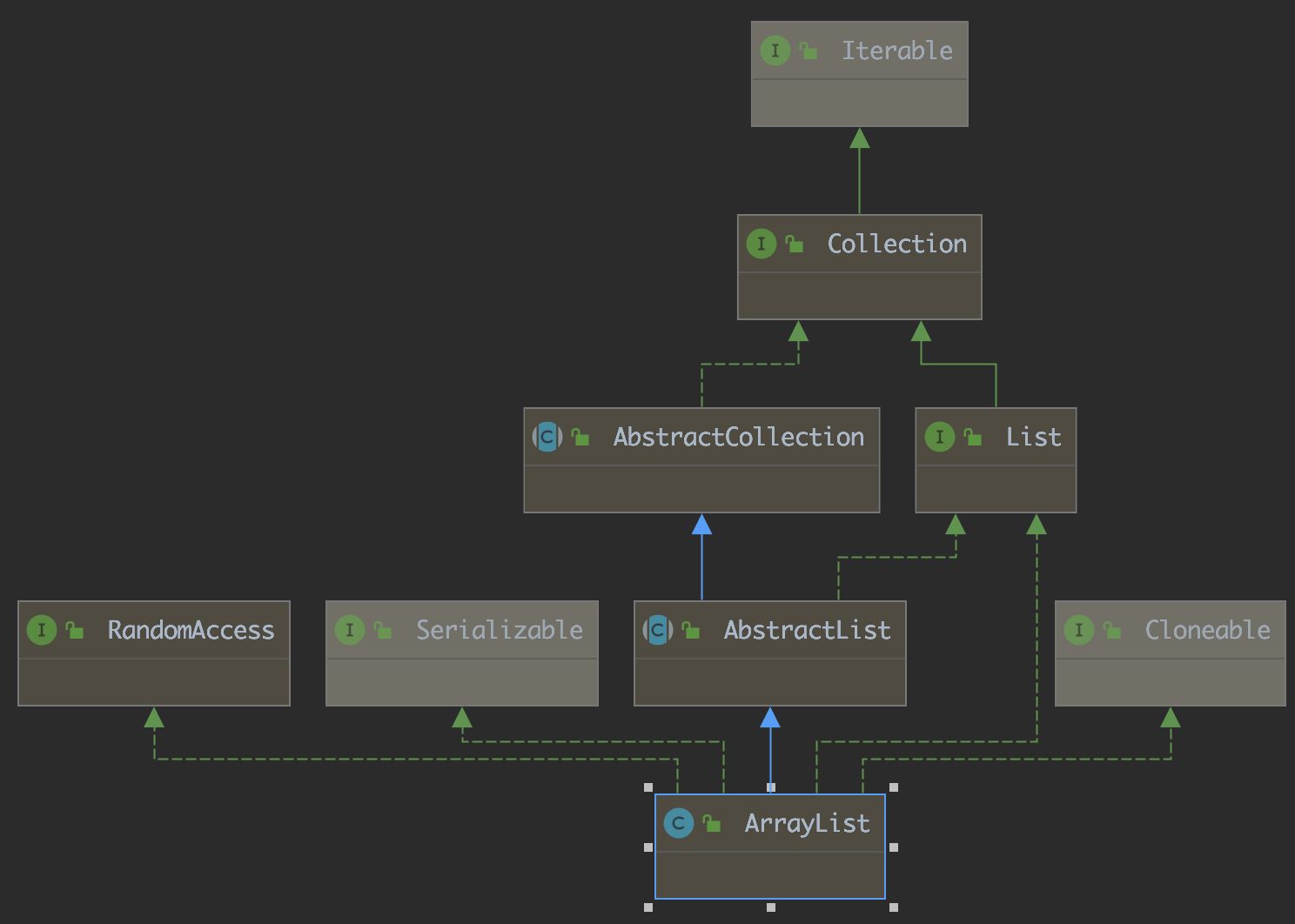
【說明】
1. ArrayList實作了RandomAccess介面,表明ArrayList支持隨機訪問
2. ArrayList實作了Cloneable介面,表明ArrayList是可以clone的
3. ArrayList實作了Serializable介面,表明ArrayList是支持序列化的
4. 和Vector不同,ArrayList不是執行緒安全的,在單執行緒下可以使用,在多執行緒中可以選擇Vector或者 CopyOnWriteArrayList
5. ArrayList底層是一段連續的空間,并且可以動態擴容,是一個動態型別的順序表
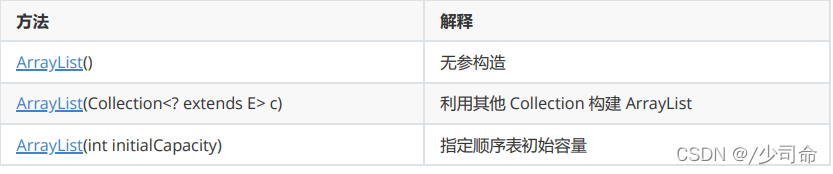
2. ArrayList使用
①ArrayList的構造
public static void main(String[] args) {
// ArrayList創建,推薦寫法
// 構造一個空的串列
List<Integer> list1 = new ArrayList<>();
// 構造一個具有10個容量的串列
List<Integer> list2 = new ArrayList<>(10);
list2.add(1);
list2.add(2);
list2.add(3);
// list2.add("hello"); // 編譯失敗,List<Integer>已經限定了,list2中只能存盤整形元素
// list3構造好之后,與list中的元素一致
ArrayList<Integer> list3 = new ArrayList<>(list2);
// 避免省略型別,否則:任意型別的元素都可以存放,使用時將是一場災難
List list4 = new ArrayList();
list4.add("111");
list4.add(100);
}②ArrayList常見操作
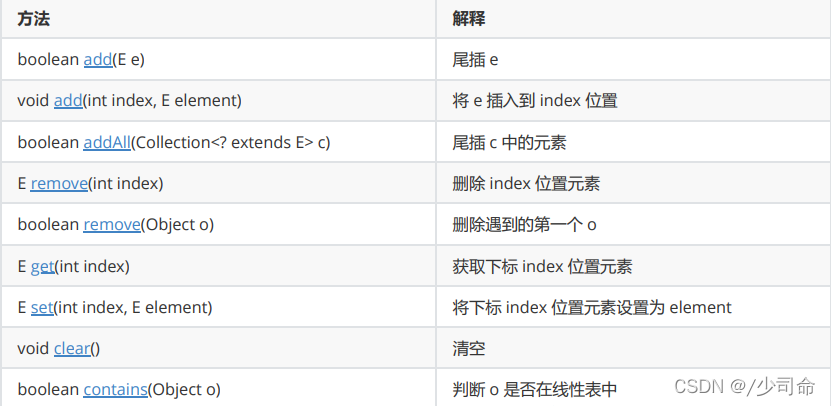
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("1234");
list.add("zhongguo");
list.add("aaaaa");
list.add("gao");
System.out.println(list);
}
//add原始碼
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
} public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("1234");
list.add("zhongguo");
list.add("aaaaa");
list.add("gao");
list.add(2,"ssss");
System.out.println(list);
}
//add插入原始碼
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
} public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("1234");
list.add("zhongguo");
list.add("aaaaa");
list.add("gao");
ArrayList<String> list2 = new ArrayList<>();
list2.add("111");
list2.add("44554");
list.addAll(list2);
System.out.println(list);
}
//addAll原始碼
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("1234");
list.add("zhongguo");
list.add("aaaaa");
list.add("gao");
list.remove(2);
System.out.println(list);
}
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("1234");
list.add("zhongguo");
list.add("aaaaa");
list.add("gao");
String a = list.get(1);
System.out.println(a);
System.out.println(list);
}
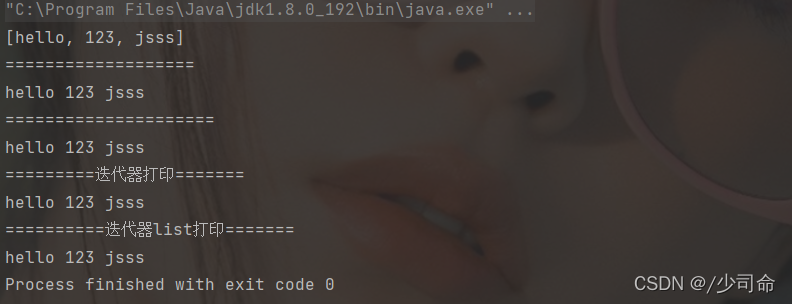
③ ArrayList的遍歷
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("123");
list.add("jsss");
System.out.println(list);
System.out.println("===================");
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " ");
}
System.out.println();
System.out.println("=====================");
for (String s : list) {
System.out.print(s + " ");
}
System.out.println();
System.out.println("=========迭代器列印=======");
Iterator<String> it = list.iterator();
while (it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println();
System.out.println("==========迭代器list列印=======");
ListIterator<String> it2 = list.listIterator();
while (it2.hasNext()){
System.out.print(it2.next() + " ");
}
}
八,Map和Set
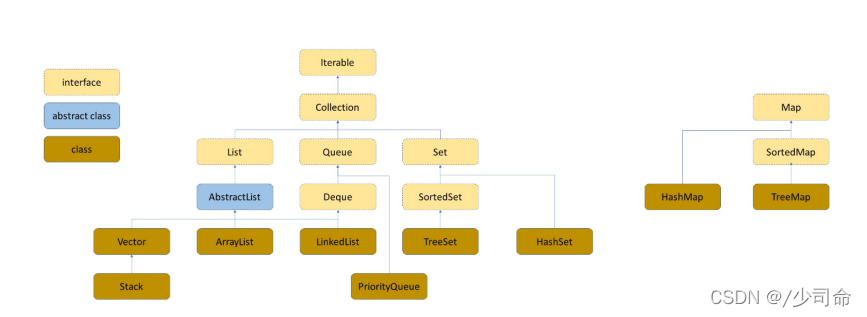
1,搜索
①概念及場景
Map和set是一種專門用來進行搜索的容器或者資料結構,其搜索的效率與其具體的實體化子類有關,
搜索方式有:
1. 直接遍歷,時間復雜度為O(N),元素如果比較多效率會非常慢
2. 二分查找,時間復雜度為 ,但搜索前必須要求序列是有序的 上述排序比較適合靜態型別的查找,即一般不會對區間進行插入和洗掉操作了,而現實中的查找比如:
1. 根據姓名查詢考試成績
2. 通訊錄,即根據姓名查詢聯系方式
3. 不重復集合,即需要先搜索關鍵字是否已經在集合中
②模型
一般把搜索的資料稱為關鍵字(Key),和關鍵字對應的稱為值(Value),將其稱之為Key-value的鍵值對,所以 模型會有兩種:
1. 純 key 模型,比如:
有一個英文詞典,快速查找一個單詞是否在詞典中 快速查找某個名字在不在通訊錄中
2. Key-Value 模型,比如:
統計檔案中每個單詞出現的次數,統計結果是每個單詞都有與其對應的次數: 梁山好漢的江湖綽號:每個好漢都有自己的江湖綽號
2,Map的使用
①關于Map的說明
Map是一個介面類,該類沒有繼承自Collection,該類中存盤的是結構的鍵值對,并且K一定是唯一的,不能重復,
②關于Map.Entry的說明
Map.Entry 是Map內部實作的用來存放鍵值對映射關系的內部類,該內部類中主要提供了 的獲取,value的設定以及Key的比較方式,
| 方法 | 解釋 |
| K getKey() | 回傳entry中key的值 |
| V getValue() | 回傳entry中的value |
| V setValue(V value) | 將鍵值對中的value替換為指定value |
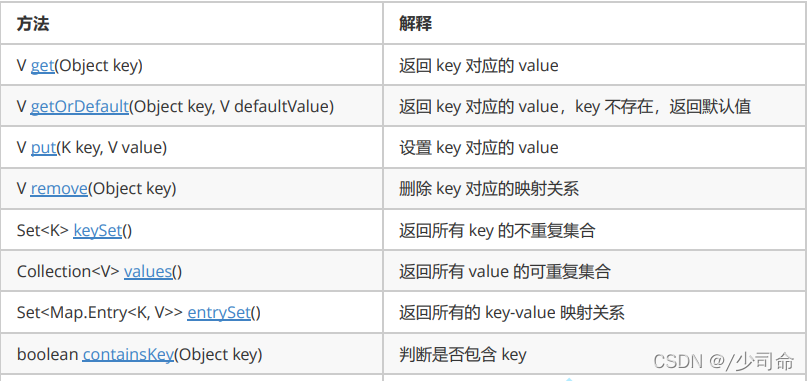
③Map 的常用方法說明
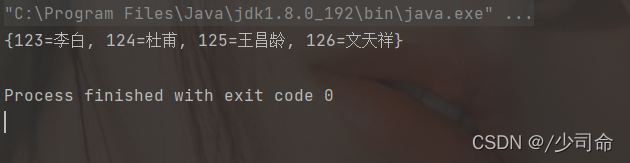
public static void main(String[] args) {
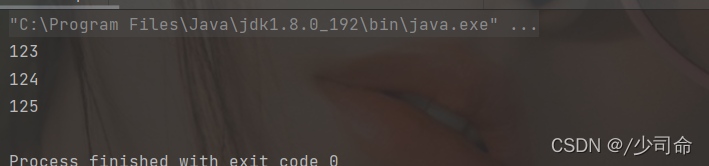
Map<String,String> map = new HashMap<>();
map.put("123","李白");
map.put("124","杜甫");
map.put("125","王昌齡");
map.put("126", "文天祥");
System.out.println(map);
}
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("123","李白");
map.put("124","杜甫");
map.put("125","王昌齡");
map.put("126", "文天祥");
String val = map.get("123");
System.out.println(val);
} public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("123","李白");
map.put("124","杜甫");
map.put("125","王昌齡");
map.put("126", "文天祥");
String val;
val = map.getOrDefault("123","李白");
System.out.println(val);
}

3,Set的使用
①常見方法說明
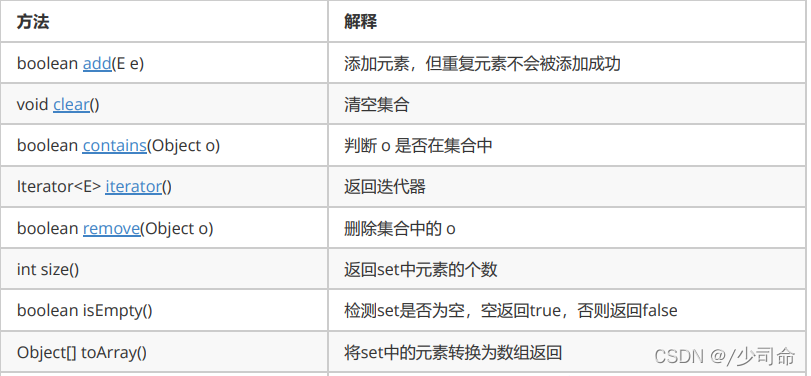
②TreeSet的使用案例
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("123");
set.add("124");
set.add("125");
System.out.println(set);
}
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("123");
set.add("124");
set.add("125");
boolean fla = set.contains("123");
System.out.println(fla);
}
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("123");
set.add("124");
set.add("125");
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/392124.html
標籤:其他