不經意間瞄了一眼日歷,驚覺2020年已所剩無幾,回望即將過去的一年,不禁感嘆唏噓,時光帶走了很多的煩惱和美好,也帶來了很多困惑和識訓,怎樣才能不被淹沒在時間的洪流里呢,唯有在風浪中保持清醒和方向,而不斷地學習和輸出就是那支駕馭風浪的槳,
從系統設計一頭扎進演算法的漩渦,經過了一陣子的蒙圈,然后一點一點摸索著理清思路和方向,在知識爆炸的時代,最好的積累就是把每一步記錄下來,變成自己的腳印,
前些天調研了人臉檢測演算法,這幾天在做人臉關鍵點定位和人臉對齊,在網上找了一個開源的人臉對齊專案,本地做了適當適配后驗證OK,本篇就單純記錄這個對齊演算法的實作,
專案地址:https://github.com/610265158/face_landmark
該專案基于Tensorflow2.0,比較簡單靈活,下面是一些Demo圖片:

專案運行環境:
- tensorflow2.0
- tensorpack (for data provider)
- opencv
- python 3.6
資料集:
訓練使用的是300W的資料集,資料集地址:i·bug - resources - Facial point annotations
該資料集涵蓋了大量變化的人臉資料,包括不同的主題、姿勢、光照、遮擋等,資料集采用68點標注,如下:

資料按照如下格式存放:
├── 300VW
│ ├── 001_annot
│ ├── 002_annot
│ ....
├── 300W
│ ├── 01_Indoor
│ └── 02_Outdoor
├── AFW
│ └── afw
├── HELEN
│ ├── testset
│ └── trainset
├── IBUG
│ └── ibug
├── LFPW
│ ├── testset
│ └── trainset訓練
如果想要訓練自己的模型,下載完資料集后,需要首先運行如下命令來生成訓練和驗證的JSON檔案:
python make_json.py需要注意的是,make_json.py檔案中,需要正確配置資料集的路徑,否則無法生成正確的train.json和val.json,
data_dir='300W' ########points to your director,300w完成以上步驟后,運行如下命令進行模型訓練:
python train.py默認情況下,會使用ShuffleNetV2_1.0進行訓練,如果想要修改網路,可在train_config.py檔案中的如下位置進行配置:

模型使用Demo
可使用訓練出來的模型進行推理,如果不想自己訓練,也可以直接下載已訓練好的模型:model (提取碼:rt7p)
運行如下命令列進行Demo測驗:
python vis.py --model ./model/keypoints其中,./model/keypoints是模型的存放位置,模型存放格式如下:
./model/
└── keypoints
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
也可以先將模型轉換為tflite格式,然后使用tflite模型進行推理,模型轉換命令:
python ./tools/convert_to_tflite.pytflite模型推理命令:
python vis.py --model ./model/converted_model.tflite下面是使用下載下來的模型的一些Demo結果:
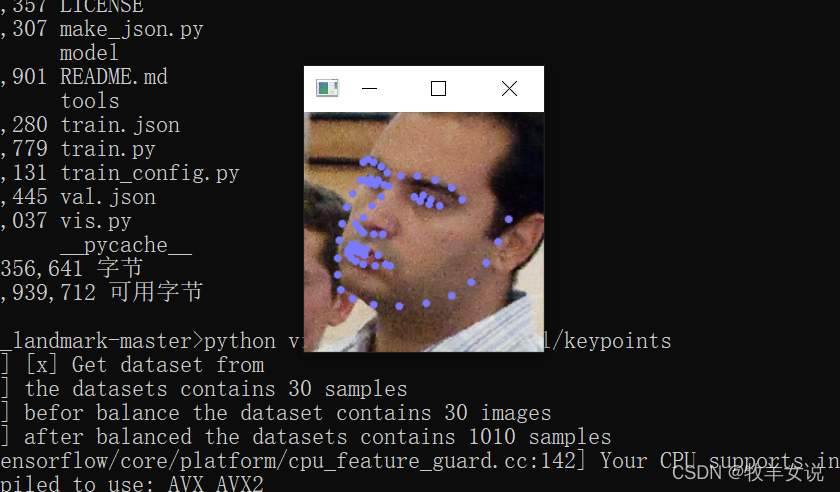
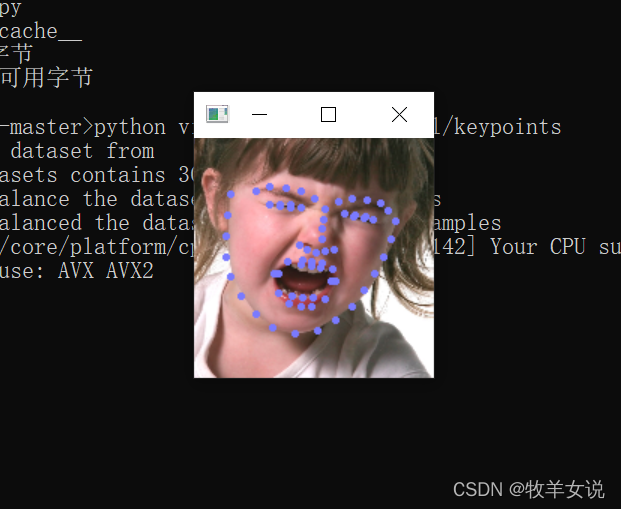
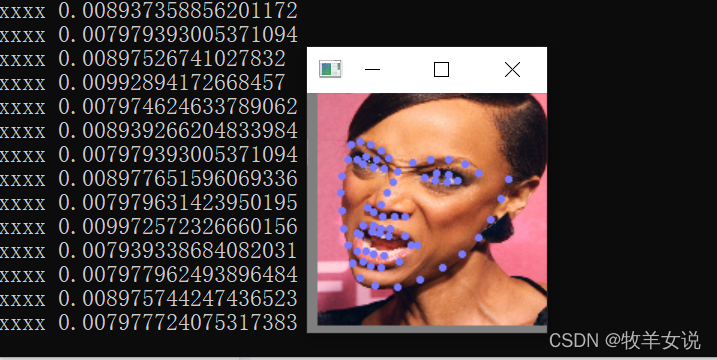
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/392279.html
標籤:其他
上一篇:濃淡補正演算法的研究
下一篇:【推薦系統論文精讀系列】(十五)--Examples-Rules Guided Deep Neural Network for Makeup Recommendation