什么是流水線
流水線是利用執行指令所需的操作之間的并行性,實作多條指令重疊執行的一種技術,流水線是一種在連續指令流中開發指令級并行性的技術,流水線的明顯長處是:它對編程者是透明的,
就像裝配線那樣,不同的步驟并行完成流水線中不同指令的不同部分,每一個步驟稱為一個流水節拍或一個流水段,指令沿流水線移動一次的時間間隔是一個時鐘周期,因為所有節拍同時作業,所以,機器周期取決于最慢的流水段,在理想情況下,流水線的加速比等于流水線的段數,但是通常情況下加速比與流水段之間不會有那么好的平衡,流水線需要一些附加的時間開銷,
流水線可以減少指令的平均執行時間,當從不同的角度看流水線時,這個減少量的含義也相應有所不同,可以認為是減少了每條指令的平均時鐘周期數(CPI),也可以認為是減少了時鐘周期的長度,還可以認為在這兩個方面都減少了,如果研究物件是一臺每條指令分為多個時鐘周期的機器,那么流水線可以看做是減少了CPI——這是我們將采納的基本觀點,如果研究物件為每條指令執行一個長時鐘周期,那么流水線減少的是機器的時鐘周期,
背景—RISC指令系統基礎
RISC機采用流水線技術,大部分指令在一個時鐘周期內完成,
RISC系統結構有以下幾個關鍵特點,這些特點明顯簡化了RISC的實作:
1)所有運算使用的資料都來自暫存器,運算結果也都寫入暫存器,每個暫存器的典型長度是32位或64位,
2)能夠訪問存盤器的操作只有兩種指令:從存盤器中讀取資料到暫存器的load指令和從暫存器向存盤器中寫資料的store指令,load和Istore指令可以對一個暫存器的一部分進行操作( 例如,一個位元組,16 位或者32位),
3)指令的數量比較少,所有指令的長度均相同,
這種結構使流水線的實作得到顯著的簡化,
大多數RISC指令系統都包括有三種型別的指令:ALU指令、load和store指令、轉移和跳轉,
非流水線情況下RISC指令系統的簡單實作
在此方案中,假設每條RISC指令的執行最多需要5個時鐘周期:
1)取指令周期(IF):
PC->MAR,1->R,M(MAR)->MDR,MDR->IR,(PC)+1->PC
2)指令譯碼/讀暫存器周期(ID):
對指令進行譯碼并訪問暫存器堆以讀出暫存器中的內容,
固定欄位譯碼:因為RISC指令系統中指定的暫存器位置是固定的,
可以對暫存器中的內容進行比較,判斷是否為轉移指令,若是則修改PC值,
需要擴展立即數操作也在此進行,
3)執行/有效地址周期(EX):
ALU指令對上一個時鐘周期準備好的運算元進行運算,執行訪問存盤器、暫存器-暫存器ALU指令、暫存器-立即數ALU指令三種功能中的一個,
4)訪問存盤器(MEM)
如果是load指令,將根據前一個周期計算得到的有效地址從存盤器中讀取資料如果是store指令,則根據有效地址將第二個暫存器中的資料寫人存盤器中,
5)寫回周期(WB)
暫存器-暫存器ALU指令或load指令,
將結果寫人暫存器堆,結果可能來自存盤器(對于load指令)或者來自ALU(對于ALU指令),
在這種實作下,轉移指令需要2個周期,store指令需要4個周期,其他指令需要5個周期,
經典的5段流水線RISC處理器(非完善)
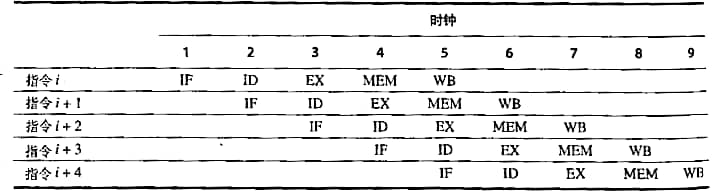
只需要簡單的在每一個時鐘周期啟動一條新的指令,
開始,我們需要確定處理器在每一個時鐘周期都進行什么樣的動作,并保證在同一個時鐘周期沒有兩條指令使用相同的資料通路資源,例如,一個ALU不能同時用于計算有效地址和做減法運算,因此,我們必須保證流水線中指令的重疊不會導致這樣的沖突,
多條指令的重疊引起的沖突很少:使用分開的指令和資料存盤器(Cache);為處理同一時鐘周期對同一個暫存器的讀和寫,我們在一個時鐘周期的前半部分對暫存器寫,該時鐘周期的后半部分進行讀暫存器操作;在IF段完成PC自加并寫回結果,在ID段為可能轉移的目標地址的計算提供一個加法器,
在流水線中引入流水線暫存器(用于在一個流水段和下一個流水段之間進行資料傳遞和資訊控制)保證流水線的不同段中的指令不會互相影響,
在此階段,只是簡單實作流水線,其中還有很多問題,后面進行優化處理,
流水線的基本性能問題
流水線增大了CPU的指令吞吐量——即單位時間完成的指令條數,但是它未減少指令各自的執行時間,實際上,流水線技術經常要對流水線附加一些控制,因而增加了開銷,使單條指令執行時間略有增加,
除了流水線時延引起的限制,流水段的不平衡和流水線的附加開銷也引入了某些限制,流水段的不平衡引起的限制,是因為時鐘不能快于最慢的流水段,流水線的附加開銷引起的限制是因為流水線暫存器的延遲和時鐘偏移,流水線暫存器增加了時鐘周期的啟動時間和傳輸延遲,其中啟動時間是指從暫存器輸入穩定開始,直到觸發寫操作的時鐘信號到達為止的時間之差,時鐘偏移是指在時鐘到達時任何兩個暫存器之間的延遲,而時鐘偏移的存在也導致了對時鐘周期的限制,一旦時鐘周期很小,以至于與時鐘偏移和鎖存器附加開銷相當時,流水就沒有用處了,
流水線的主要障礙——流水線冒險
三類冒險:結構冒險、資料冒險、控制冒險
■有停頓的流水線的CPI為∶
CPI=理想流水線CPI+(結構相關停頓 +資料相關停頓+控制相關停頓)/指令數
■有停頓的流水線的加速比為∶
加速比=流水線深度/(1+每條指令的流水線停頓周期)
消除相關、減少停頓是提高已有流水線性能最重要的手段,
結構冒險:
概念:如果因為資源沖突而無法使用某種指今的組合,那么該處理器就被稱為是有結構冒險的,(現有硬體達不到指令流水的需求)
情況一:最常見的結構冒險出現在部分功能單元沒有充分流水的時候,此時一系列使用該單元的指令不能按照每個時鐘周期前進一拍的速率流水,
解決辦法:將流水線設計的更合理,
情況二:另一種常見的結構冒險是因為某些資源沒有足夠多的副本,不能滿足讓流水線中的若干條指令同時執行,
解決方法:
1)增加資源副本:
存盤器沖突:哈佛結構
兩個ALU∶取指令一地址加法器
2)改變資源以便它們能并發的使用:
不相關的資料盡量使用不同的暫存器
暫存器重命名
3)通過延遲(或暫停)流水線的沖突段或在沖突段插入流水線氣泡(氣泡在流水線中只占資源不做實際操作),使各段"輪流"使用資源,
在某些時候,設計人員允許結構冒險存在,原因是可以降低成本或者減少單元延遲,
資料冒險:
概念:在同時執行的幾條指令中,一條指令依賴于前一條指令的資料卻得不到時,就會發生的冒險,
資料冒險產生的原因是流水線改變了非流水線情況下讀/寫運算元的順序,使其呈現出與在非流水線處理器上的執行時不一致的指令順序,
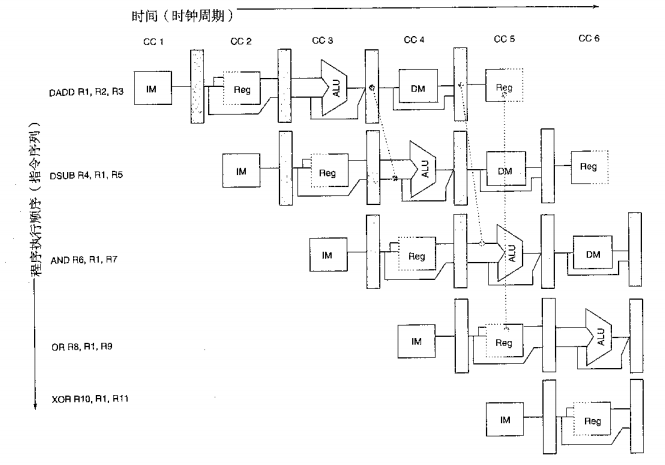
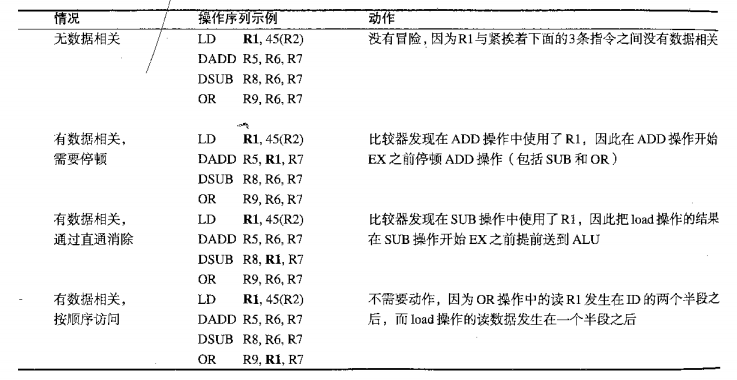
解決方法一:使用直通技術資料冒險引起的停頓
直通思想可以一般化,即把結果直接送到需要它的功能單元,一個結果能夠從一個單元輸出對應的流水線暫存器直接送到另一個單元的輸入,而不限制在同一單元的輸出到輸入,使用硬體技術解決,也稱旁路技術,
舉例:
解決方式二:需要停頓的資料冒險
并非所有的資料冒險都可以采用旁路的方法來解決,
舉例:load操作可以把結果直通給AND和OR操作,卻不能直通給SUB操作,
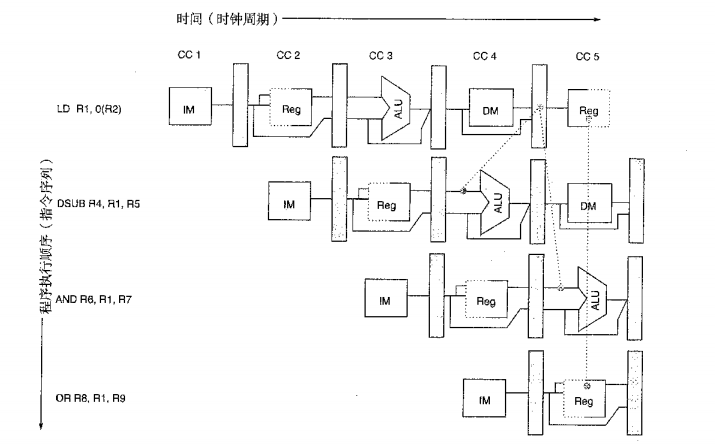
load操作有一種不能只用直通就能消除的延遲,這時,需要加入一種稱為流水線鎖定器的新硬體來保證正確運行,通常,流水線鎖定器發現冒險后就停頓流水線,直至冒險被消除,流水線鎖定器停頓流水線,讓需要某個結果的操作一直等到該結果產生時為止,
控制冒險
概念:流水線中的轉移指令或其他改寫PC的指令造成的冒險,損失比資料冒險更大,
如果一條轉移指令把PC改寫成它的目標地址,那么該轉移稱為選中轉移,否則稱為未選中轉移,如果某條指令i是選中轉移,那么,通常要到ID段的末尾在已經完成了地址計算和比較之后才能改變 PC,
有許多減少因為轉移延遲造成流水線停頓的方法,這里,我們介紹4種簡單的編譯時調度方法,在這4種方法中,對轉移的處理都是靜態的,即在整個程式執行程序中對每個轉移的處理都一樣,
1)凍結或沖刷流水線,即在轉移的目標地址確定之前保存或者洗掉所有緊隨轉移的指令,這種方法的優點是硬體和軟體兩方面都比較簡單,轉移的開銷固定,
2)對所有轉移都按未選中處理,因此必須注意在轉移結果產生前不要改變機器的狀態,因為不知道指令何時改變機器狀態,以及怎樣把變化改回去,在簡單的5段流水線中,采用預測未選中調度策略,實作方法就是直接取下一條指令,好像轉移指令只是一條普通的指令那樣,流水線看起來也沒有特殊之處,但是只要轉移指令被選中,就需要用空操作代替取來的指令(只需清除IF/ID暫存器),并到目標地址重新取指令,相較于第一種好處是在未選中時不必再重新取下一條指令,
3)預測轉移被選中,一旦完成轉移指令的譯碼并計算出目標地址后,就假設轉移被選中,到目標地址取指令,因為在我們的5段流水線中總是先得到轉移的結果(知道是轉移指令時就已經確定要轉移了),后得到目標地址,所以這種方法不適用于我們的5段流水線(沒有任何好處),在某些機器中,尤其是隱含條件碼和更強功能(于是也更慢)轉移條件的機器中,轉移的目標地址比其結果事早產生,這時,采用預測轉移被選中的方法比較合適,
4)提供利用編譯器進行優化的機會,在有些處理器中稱為轉移延遲,
后續指令放在轉移延遲槽內,不管轉移是否被選中,這條指今都要被流水,盡管延遲槽長度大于1是可能的,但實際上,所有帶轉移延遲的處理器一般只延遲一條指令,并使用其他的技術來處理有更多轉移開銷的情況,
流水線遇到分支指令時,按正常方式處理,同時執行延遲槽中的指令,
編譯器的任務就是在延遲槽中放入有用的指令,稱為延遲槽調度,有三種調度方法∶
從分支前(from before)調入
從目標處(from target)調入
從失敗處(from fall-through)調入
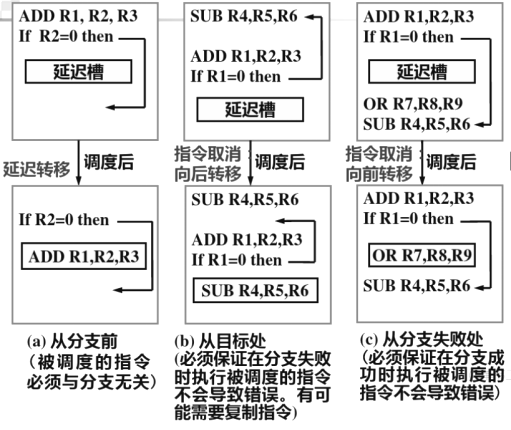
帶轉移延遲的機器通常不允許在延遲槽內有轉移指令,
延遲槽內可選指令:填入延遲槽的是轉移前的一條不相關指令;將轉移目標指令填入延遲槽;用延遲槽后的指令填入延遲槽等,
如何實作流水線
非流水線下指令沿資料通路的流動:
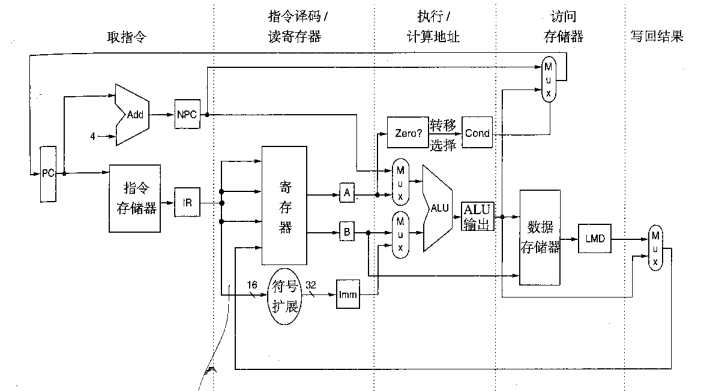
MIPS資料通路的實作,它允許在4個或5個時鐘周期內完成一條指令,除了上述多周期的設計,也可以讓每一條指令占用一個長的時鐘周期,在這種情況下,所有的臨時暫存器可以拋棄不用,因為在一條指令的內部時鐘周期之間無需通信,指令都在一個長的時鐘周期內執行,并在該時鐘結束時將結果寫入存盤器、暫存器或者PC,對于這種處理器來說,CPI將始終是1,但是其時鐘周期大致等于多周期處理器的5倍,因為每一條指令都要通過所有的功能單元,設計者不會使用這種單周期的實作方法,因為有兩方面的原因∶首先,對于大多數CPU來說,不同的指令需要的時鐘周期時間不同,單周期的實作方法效率很低,其次、單周期的實作方法需要重復的功能單元,而在多周期的實作中功能單元可以共享,不過,這個單周期的資料路徑可以用來說明流水線技術是如何改善處理器的時鐘周期而不是CPI的,
MIPS的基本流水線:
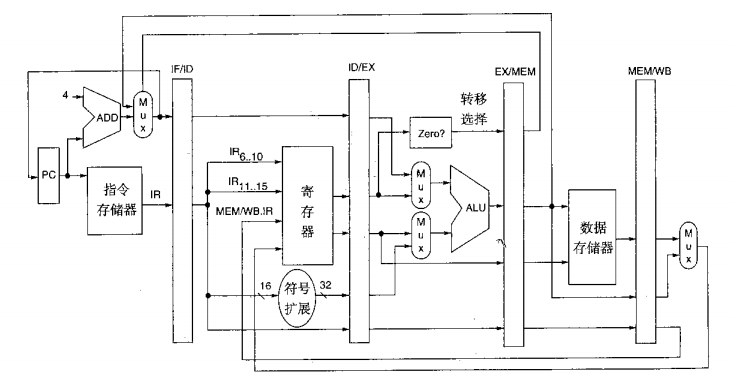
每個時刻每條指令都只在一個流水段上是活動的,因此任何指令所做的動作都發生在一對流水線暫存器之間,

MIPS流水線每一個流水段發生的事件,在IF段,除了取指令和計算新的PC之外,還將增加 PC存入流水線暫存器(NPC),以供后面計算轉移目標地址時使用,PC在IF段被一個或者兩個資料源更新,在ID段,執行讀暫存器操作,對IR的低16位進行符號擴展,并沿IR和NPC傳遞,在EX段,執行ALU操作或者進行地址計算,并沿IR 和B暫存器(如果是store指令)傳遞,同時,當指令選中轉移時,將條件碼的值設定為1,在 MEM段,更新存盤器,進行轉移決策,在需要時寫入 PC,并傳送在最后段所需的資料,最后,在WB段,用ALU的輸出或者裝入的值來更新暫存器,為了簡化起見,我們在流水段之間傳送整個IR,盡管隨著指令沿著流水線前程序序中IR有用的部分越來越少,
MIPS流水線控制的實作:
讓一條指令從譯碼段(ID)流動到執行段(EX)的操作通常稱為發射指令,經過了這一步的指今稱為已經被發射的指令,對 MIPS定點流水線,所有的資料冒險都可以在流水線的ID段檢查到,如果存在一個資料冒險,相應指令就在它發射前被停頓,同理,可以在ID段確定需要什么直通,從而再次添加適當的控制,通過較早檢測鎖定關系可以減少硬體的復雜性,因為除了整個流水線被停頓的情況外,硬體不需要停頓一條已經更新了機器狀態的指令,另一種方法是,在一個使用運算元(在流水線的EX和MEM段)的時鐘周期開始時檢測到冒隙訓直通,流水線冒險檢測硬體比較相鄰指令的源運算元和目的運算元即可,檢測的范圍僅限于一條寫指令之后的兩條指令的源運算元和目的運算元,
舉例:由load指令產生的資料冒險可以用檢查ID段的方法來消除,而對ALU輸入端的直通通路可以在EX段實行,
對于load指令產生的冒險:控制單元必須在流水線中插入停頓,當預測到一個冒險之后,只需要把ID/EX流水線暫存器的控制位清為0,
對于直通來說:所有旁路通常都是從ALU或資料存盤器的輸出端到ALU與資料存盤器的輸入端.或者是零檢測單元,于是,實作旁路時只需要比較IR中處于EX/MEM 與MEM/WB段的目標暫存器和處于ID/EX與EX/MEM段的源暫存器,
處理流水線中的轉移
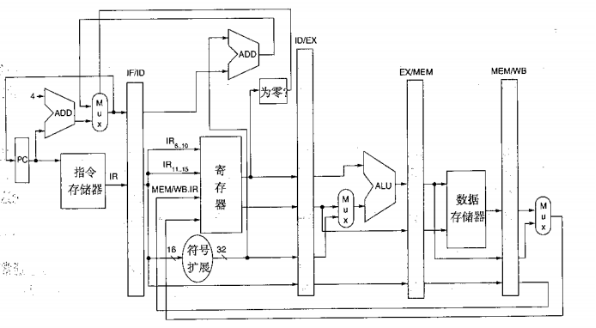
通過把零檢測和地址計算移到ID段來縮短轉移冒險引起的停頓,第一個變化是將轉移目標地址的計算和轉移條件的判斷都移入ID段來完成,第二個變化是在IF階段寫指令的PC,這個PC值可能是ID段計算的轉移目標地址,也可能是IF階段計算的PC增加值,作為比較,原圖示為從EX/MEM暫存器得到轉移目標地址,在MEM階段寫入結果,
在改動之后,如果在ALU指令后面跟著一條使用這個ALU指令結果的轉移,會只有一個資料冒險的停頓,在某些處理器中,轉移冒險要比所舉的例子使用更多的時鐘周期,例如,譯碼和讀暫存器分成不同段的處理器可能要增加轉移延遲,該延遲長度至少為一個時鐘周期,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/394066.html
標籤:其他
上一篇:將一個串列乘以其他串列的元素